【在大模型RAG系统中应用知识图谱】
【引子】 关于大模型及其应用方面的文章层出不穷,聚焦于自己面对的问题,有针对性的阅读会有很多的启发,本文源自Whyhow.ai 上的一些文字和示例。对于在大模型应用过程中如何使用知识图谱比较有参考价值,特汇总分享给大家。
在基于大模型的RAG应用中,可能会出现不同类型的问题,通过知识图谱的辅助可以在不同阶段增强RAG的效果,并具体说明在每个阶段如何改进答案和查询。知识图谱更类似于结构化数据存储,而不是仅仅是一个用于各种目的的结构化数据的一般存储,可以利用它在 RAG 系统中战略性地注入人类推理。
1. RAG简介
对于复杂的 RAG 和多跳数据检索的一般场景,如下图所示, 关于RAG的更多信息可以参考《[大模型系列——解读RAG]》。
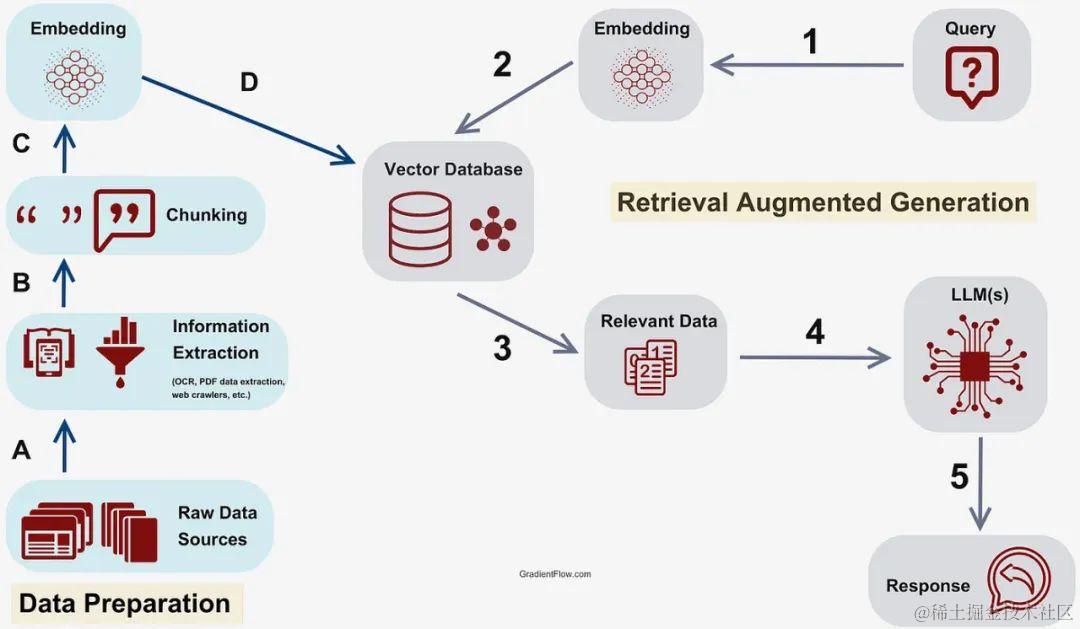
使用上图所示的阶段来介绍知识图谱支持的 RAG 过程中不同的步骤:
- 阶段1——预处理: 这指的是在查询被用于帮助从向量数据库中提取数据块之前对其进行处理
- 阶段2/D——数据块提取: 这是指从数据库中检索最相关的信息块
- 阶段3-5——后处理: 这指的是为准备检索到的信息以生成答案而执行的过程
在不同阶段应该使用哪些知识图谱技术呢?
2.知识图谱在RAG各阶段的应用
2.1 阶段一:查询增强
查询增强是 在从向量数据库中进行检索之前,向查询添加上下文。此策略用于在缺少上下文的情况下增加查询并修复错误查询。这也可以用来注入一个我们的世界观,明确如何定义或看待某些共同或基础术语。
在许多情况下,我们可能对特定术语有自己的世界观。例如,一家旅游科技公司可能希望确保开箱即用 LLM 能够理解“海滨”住宅和“靠近海滩”住宅代表非常不同类型的房产,不能互换使用。在预处理阶段注入这个上下文有助于确保 RAG系统中的这种区别能够提供准确的响应。
从历史上看,知识图谱在企业搜索系统中的一个常见应用是帮助建立首字母缩略词词典,以便搜索引擎能够有效地识别提出的问题或文档/数据存储中的首字母缩略词。这在第一阶段可以用于多跳推理。

2.2 阶段二:数据块提取
文档层次结构是指创建文档层次结构和在向量数据库中导航块的规则。这用于快速识别文档层次结构中的相关块,并使我们能够使用自然语言创建规则,规定查询在生成响应之前必须引用哪些文档/块。
2.3 阶段三:递归知识图谱查询
这是用来结合信息提取和存储连贯的答案。LLM 向知识图谱查询答案。这在功能上类似于CoT过程,其中外部信息存储在知识图谱中,以帮助确定下一步的调查。
2.4 阶段四之一:响应增强
响应增强是根据最初从矢量数据库生成的查询添加上下文。这用于添加必须存在于任何答案中的附加信息,这些附加信息涉及一个未能检索到或在矢量数据库中不存在的特定概念。这对于在基于提到或触发的某些概念的回答中包含免责声明或警告特别有用。
一个有趣的推测途径也可以包括使用答案增强作为一种方式,对于面向消费者的 RAG 系统,当某些答案提到某些产品时,可以包含个性化广告的答案。
2.5 阶段四之二:响应规则
响应规则是根据知识图谱设置的规则重新排序。这是用来强制执行关于可以生成的答案的一致规则。这对信任和安全有影响,我们可能希望消除已知的错误或危险的答案。
Llamaindex 有一个有趣的例子,它使用维基百科的知识图谱来复核一个 LLM 的基本真理。尽管 Wikipedia 不能作为内部 RAG 系统的基本事实的来源,但是您可以使用客观的行业或常识知识图谱来防止 LLM 的幻觉。
2.6 阶段五:数据块访问控制和个性化
知识图谱可以强制执行关于用户可以根据其权限检索哪些块的规则。例如,假设一家医疗保健公司正在构建一个 RAG 系统,该系统包含对敏感临床试验数据的访问。他们只希望拥有特权的员工能够从向量存储中检索敏感数据。通过将这些访问规则作为属性存储在知识图谱的数据上,它们可以告诉 RAG 系统只检索特权块(如果允许用户这样做的话)。
3.一个用例
用医学领域的一个例子来进一步阐述RAG系统中如何应用知识图谱。示例问题如下: “阿尔茨海默病治疗的最新研究是什么?” 然后可以采取以下步骤,以知识图谱增强RAG 系统。我们不认为每个 RAG 系统都必须需要以下所有步骤,但这些用例在复杂的 RAG 用例中相对常见。
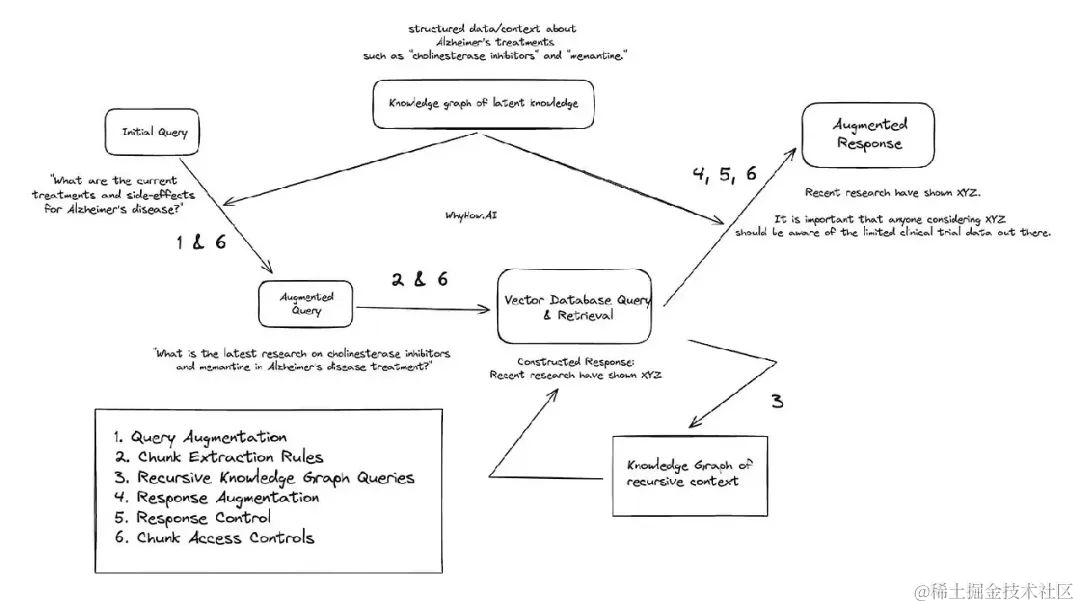
在这里,描述知识图谱在所有技术(查询增强、数据块提取规则、递归知识图谱查询、响应增强、响应控制、块访问控制)环节的应用示例。
3.1 查询增强
对于“阿尔茨海默氏症治疗的最新研究是什么?” 这个query,通过访问知识图谱,LLM 代理可以持续检索关于最新的阿尔茨海默病治疗的结构化数据,如“胆碱酯酶抑制剂”和“盐酸美金胺”,RAG 系统将进一步提出更具体的问题: “关于胆碱酯酶抑制剂和盐酸美金胺治疗阿尔茨海默病的最新研究是什么?”
3.2 文件层次和矢量数据库检索
使用文档层次结构,识别哪些文档和数据块与“胆碱酯酶抑制剂”和“盐酸美金胺”最相关,并返回相关的答案。
3.3 递归知识图谱查询
使用递归知识图谱查询,初始查询返回称为“ XYZ 效应”的“记忆时间”的副作用。“ XYZ 效应”作为上下文存储在一个单独的知识图中,用于递归上下文。LLM 被要求使用 XYZ 效果的附加上下文检查新增加的查询。根据过去格式化的答案来衡量结果,它确定需要更多关于 XYZ 效应的信息来构成一个令人满意的答案。然后,它在知识图谱中的 XYZ 效应节点内执行更深入的搜索,从而执行多跳查询。
在 XYZ 效应节点中,它发现关于临床试验 A 和临床试验 B 的信息,它可以包括在答案中。
3.4 数据块控制访问
尽管临床试验 A & B 都包含有益的上下文,但是与临床试验 B 节点相关的元数据标签指出,用户对该节点的访问受到限制。因此,一个常设的控制访问规则可以防止临床试验 B 节点被包含在对用户的响应中。
只有关于临床试验 A 的信息才会返回给 LLM,以帮助其制定返回的答案。
3.5 响应增强
作为后处理步骤,还可以选择使用特定于医疗行业的知识图谱来增强后处理输出。例如,您可以包括特定于盐酸美金胺治疗的默认健康警告,或包括与临床试验 A 相关的任何其他信息。
3.6 数据块个性化
由于用户是研发部门的初级员工,临床试验 B 的信息不对用户开放,所以附加了一个说明,禁止用户访问临床试验 B 的信息,并要求向高级经理询问更多信息。
4. 一点思考
使用知识图谱而非向量数据库进行查询增强的一个优点是,知识图可以对已知关系的某些关键主题和概念进行一致性检索。我们把个性化定义为用户和矢量数据库之间信息流的控制,但是个性化也可以理解为用户特征的封装。
知识图谱可以反映更广泛的用户特征集合的存储,可以用于一系列的个性化工作。在某种程度上,一个知识图谱是一个外部数据存储(即外部 LLM 模型) ,它更容易以一致的形式提取(即知识图谱数据能够以一种更模块化的方式插入,播放和删除)。如果实现了物联网中的数字孪生,知识图谱很可能成为代表这种系统和模型之间的模型个性化的最佳手段。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~ , 【保证100%免费】

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥《中国大模型落地应用案例集》 收录了52个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

💥《2024大模型行业应用十大典范案例集》 汇集了文化、医药、IT、钢铁、航空、企业服务等行业在大模型应用领域的典范案例。

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


相关文章:
【在大模型RAG系统中应用知识图谱】
【引子】 关于大模型及其应用方面的文章层出不穷,聚焦于自己面对的问题,有针对性的阅读会有很多的启发,本文源自Whyhow.ai 上的一些文字和示例。对于在大模型应用过程中如何使用知识图谱比较有参考价值,特汇总分享给大家。 在基于…...

第二十条:与抽象类相比,优先选择接口
要定义多种实现的类型:JAVA有两种机制:接口和抽象类。这两种机制都支持为某些实例方法提供实现,但二者有个重要的区别:要实现由抽象类定义的类型,这个类必须是抽象类的子类。因为Java只允许单继承,对抽象类…...

20240705
Nacos Service Discovery 通过nacos实现的服务发现平台 Spring Cloud Alibaba Sentinel 提供 Sentinel 自动接入和配置支持,提供 Spring Web/WebFlux、Feign、RestTemplate、注解等适配 Spring Cloud Alibaba Sentinel DataSource 提供 Sentinel 动态数据源接入支…...

【2023ICPC网络赛I 】E. Magical Pair
当时在做洛谷U389682 最大公约数合并的时候我就想到把每个质因子分解出来然后跑高维前缀和,但是那一道题不是用这个方法,所有我也一直在思考这种做法是不是真的有用。因为昨天通过2024上海大学生程序设计竞赛I-六元组计数这道题我了解到了不少关于原根的…...
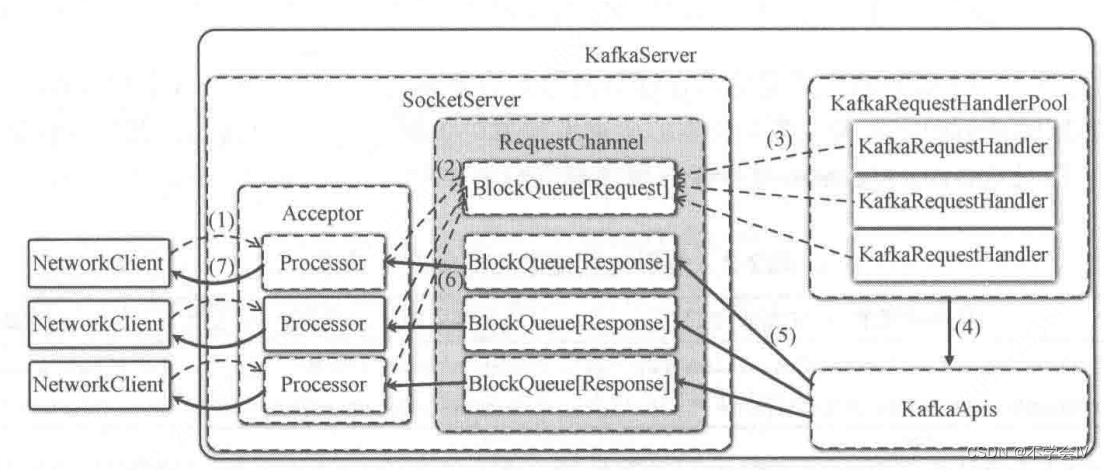
Kafka-服务端-网络层-源码流程
整体架构如下所示: responseQueue不在RequestChannel中,在Processor中,每个Processor内部有一个responseQueue 客户端发送的请求被Acceptor转发给Processor处理处理器将请求放到RequestChannel的requestQueue中KafkaRequestHandler取出reque…...

百日筑基第十一天-看看SpringBoot
百日筑基第十一天-看看SpringBoot 创建项目 Spring 官方提供了 Spring Initializr 的方式来创建 Spring Boot 项目。网址如下: https://start.spring.io/ 打开后的界面如下: 可以将 Spring Initializr 看作是 Spring Boot 项目的初始化向导ÿ…...

Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution 本文介绍宋飏提出的带噪声扰动的基于得分的生成模型。首先介绍基本的基于得分的生成模型的训练方法(得分匹配)和采样方法(朗之万动力学)。然后基于流形假…...

vector与list的简单介绍
1. 标准库中的vector类的介绍: vector是表示大小可以变化的数组的序列容器。 就像数组一样,vector对其元素使用连续的存储位置,这意味着也可以使用指向其元素的常规指针上的偏移量来访问其元素,并且与数组中的元素一样高效。但与数…...

四种线程池的使用,优缺点分析
池化思想:线程池、字符串常量池、数据库连接池 提高资源的利用率 下面是手动创建线程和执行任务过程,可见挺麻烦的,而且线程利用率不高。 手动创建线程对象执行任务执行完毕,释放线程对象 线程池的优点: 提高线程的…...

什么是 BEM 规范
BEM(Block, Element, Modifier)是一种 CSS 命名规范,旨在提高代码的可读性和可维护性。BEM 规范通过明确的命名规则来定义组件和组件的各个部分,使开发者能够更容易地理解和维护代码。 BEM 命名规范的基本概念 Block(…...

【Node.JS】入门
文章目录 Node.js的入门涉及对其基本概念、特点、安装、以及基本使用方法的了解。以下是对Node.js入门的详细介绍: 一、Node.js基本概念和特点 定义:Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它使得JavaScript能够运行在服务器…...

Amazon SageMaker 机器学习之旅的助推器
一、前言 在当今的数字化时代,人工智能和机器学习已经成为推动社会进步的重要引擎。亚马逊云科技在 2023 re:Invent 全球大会上,宣布推出五项 Amazon SageMaker 新功能: Amazon SageMaker HyperPod 通过为大规模分布式训练提供专用的基础架构…...

TransMIL:基于Transformer的多实例学习
MIL是弱监督分类问题的有力工具。然而,目前的MIL方法通常基于iid假设,忽略了不同实例之间的相关性。为了解决这个问题,作者提出了一个新的框架,称为相关性MIL,并提供了收敛性的证明。基于此框架,还设计了一…...

3.用户程序与驱动交互
驱动程序请使用第二章https://blog.csdn.net/chenhequanlalala/article/details/140034424 用户app与驱动交互最常见的做法是insmod驱动后,生成一个设备节点,app通过open,read等系统调用去操作这个设备节点,这里先用mknode命令调…...
尽量不写一行if...elseif...写出高质量可持续迭代的项目代码
背景 无论是前端代码还是后端代码,都存在着定位困难,不好抽离,改造困难的问题,造成代码开发越来越慢,此外因为代码耦合较高,总是出现改了一处地方,然后影响其他地方,要么就是要修改…...

xcrun: error: unable to find utility “simctl“, not a developer tool or in PATH
目录 前言 一、问题详情 二、解决方案 1.确认Xcode已安装 2.安装Xcode命令行工具 3.指定正确的开发者目录 4. 确认命令行工具路径 5. 更新PATH环境变量 前言 今天使用cocoapods更新私有库的时候,遇到了"xcrun: error: unable to find utility &…...

【linux高级IO(一)】理解五种IO模型
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux高级IO 1. 前言2. 重谈对…...

前端引用vue/element/echarts资源等引用方法Blob下载HTML
前端引用下载vue/element/echarts资源等引用方法 功能需求 需求是在HTML页面中集成Vue.js、Element Plus(Element UI的Vue 3版本)、ECharts等前端资源,使用Blob下载HTML。 解决方案概述 直接访问线上CDN地址:简单直接,…...

昇思MindSpore学习笔记2-01 LLM原理和实践 --基于 MindSpore 实现 BERT 对话情绪识别
摘要: 通过识别BERT对话情绪状态的实例,展现在昇思MindSpore AI框架中大语言模型的原理和实际使用方法、步骤。 一、环境配置 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下…...

uniapp实现图片懒加载 封装组件
想要的效果就是窗口滑动到哪里,哪里的图片进行展示 主要原理使用IntersectionObserver <template><view><image error"HandlerError" :style"imgStyle" :src"imageSrc" :id"randomId" :mode"mode&quo…...

编写团队创意迭代记录程序,记录创意修改优化过程,形成完整创新迭代档案。
一、实际应用场景描述在真实团队创新过程中,常见如下场景:- 头脑风暴产生大量创意- 评审后不断修改、合并、推翻- 半年后再回顾,“谁提的?为什么改?最初长什么样?”已经模糊- 新成员加入,无法理…...

QiLink/道息实验室创始人简介:跨界工程师的“道息”实践录
QiLink/道息实验室创始人简介:跨界工程师的“道息”实践录我是徐玉生,一个用厨师的火候、瑜伽师的呼吸、教师的逻辑,搭建技术社区的“非典型工程师”。2013年,我同时拿到中式烹调师一级(高级技师)和高级瑜伽…...

如何彻底解锁你的加密音乐:终极免费浏览器解决方案
如何彻底解锁你的加密音乐:终极免费浏览器解决方案 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://…...

终极指南:用BG3 Mod Manager轻松管理《博德之门3》模组
终极指南:用BG3 Mod Manager轻松管理《博德之门3》模组 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经因为《博德之门3》的模…...

VideoSrt:重新定义本地化视频字幕生成的技术架构与实践范式
VideoSrt:重新定义本地化视频字幕生成的技术架构与实践范式 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 在多媒体内容创…...

Marvis 1+5 智能体协作架构深度解析:六大 Agent 各司何职?底层又如何“对话“?
Marvis 15 智能体协作架构深度解析:六大 Agent 各司何职?底层又如何"对话"? 前言 2026 年 5 月 20 日,腾讯正式上线了操作系统级 AI 助手马维斯(Marvis)。它不走传统 AI 助手的"对话框&quo…...

GNSS欺骗干扰检测算法与实验验证方法【附仿真】
✨ 长期致力于GNSS欺骗干扰检测、信号检测、伪距差分、捷联惯性导航、IMU信号生成、四元数、对偶四元数、惯性辅助、单星紧组合、欺骗干扰场景模拟研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,…...
)
Gemini SQL查询生成落地手册(企业级生产环境已验证)
更多请点击: https://kaifayun.com 第一章:Gemini SQL查询生成落地手册(企业级生产环境已验证) 在大型金融与电商客户的真实生产环境中,Gemini 模型已被成功集成至自助分析平台,日均稳定生成超 12,000 条符…...

Win11Debloat:Windows系统终极清理与优化完全指南
Win11Debloat:Windows系统终极清理与优化完全指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

DeepLX开源翻译方案架构分析与性能对比指南
DeepLX开源翻译方案架构分析与性能对比指南 【免费下载链接】DeepLX Powerful Free DeepL API, No Token Required 项目地址: https://gitcode.com/gh_mirrors/de/DeepLX 在当今全球化开发环境中,高效的翻译API成为技术团队不可或缺的工具。DeepLX作为一款开…...