【Hive实战】 HiveMetaStore的指标分析
HiveMetaStore的指标分析(一)
文章目录
- HiveMetaStore的指标分析(一)
- 背景
- 目标部署架构
- hive-site.xml相关配置
- 元数据服务的指标相关配置
- 源码部分(hive2.3系)
- `JvmPauseMonitor.java`
- `HiveMetaStore`的内部类`HMSHandler`
- MetricsFactory的init(conf)方法
- `CodahaleMetrics.java`
- 具体指标对象
- 指标导出
- JsonFileReporter输出的文件内容示例
- 其他
- 腾讯云的hive-metastore指标
- 参考资料
背景
对当前单独部署的HiveMetaStore服务进行指标监控。
目标部署架构
验证步骤
-
场景一:
Metastore服务开启监控,指标输出方式采用默认。HiveServer2采用直连数据库的方式创建MetaStoreClient,其配置文件中也开启了metastore指标监控,同时开启WebUI。
现象:每个HiveServer2服务都可以通过WebUI看到指标dump。但是,每个HiveServer2的实际访问的指标并非从Metastore组中获取的指标。是Client端侧的指标,且每个节点之间没有关联。
-
场景二:
Metastore服务开启监控,指标输出方式采用默认。。HiveServer2采用连接Metastore服务组的方式工作,其配置文件中也开启了metastore指标监控,同时开启WebUI。
现象:每个HiveServer2服务都可以通过WebUI看到指标dump。但是没有Metastore相关的指标。
结论:以上两种方式,通过HiveServer2的WebUI服务都无法获取到单独的Metastore的服务指标。
-
场景三:
单纯的开启Metastore服务的监控,并将指标输出json文件中。
现象:每个Metastore服务都生成自己的json文件,但是目前的版本在更新问价的时候会无法
.json文件,只会定时的更新.json.tmp文件。
说明,以目标部署架构为例,单纯的MetaStore服务的指标是单纯的自己输出的。要么读取json文件,通过开启服务的JMX,在通过分别访问各个Metastore节点的JMX服务获取指标。
hive-site.xml相关配置
元数据服务的指标相关配置
-
开启指标功能
hive.metastore.metrics.enabled:true -
指定指标功能实现类
hive.service.metrics.class:org.apache.hadoop.hive.common.metrics.metrics2.CodahaleMetrics -
指标输出的类型
hive.service.metrics.reporter:"JMX,CONSOLE,JSON_FILE,HADOOP2" -
指标输出的JSON文件位置
hive.service.metrics.file.location:“/tmp/report.json” -
指标输出的JSON文件更新频率
hive.service.metrics.file.frequency:5s -
指标输出到hadoop2组件指标中的名称
hive.service.metrics.hadoop2.component:"hivemetestore" -
指标输出到hadoop2组件指标中的时间间隔
hive.service.metrics.hadoop2.frequency:30s
源码部分(hive2.3系)
在HiveMetaStore.java文件中main方法内,会根据配置去决定是否启动指标服务类。
//Start Metrics for Standalone (Remote) Mode - hive.metastore.metrics.enabledif (conf.getBoolVar(ConfVars.METASTORE_METRICS)) {try {MetricsFactory.init(conf);} catch (Exception e) {// log exception, but ignore inability to startLOG.error("error in Metrics init: " + e.getClass().getName() + " "+ e.getMessage(), e);}}Lock startLock = new ReentrantLock();Condition startCondition = startLock.newCondition();AtomicBoolean startedServing = new AtomicBoolean();// 方法中会启动JvmPauseMonitor监控器startMetaStoreThreads(conf, startLock, startCondition, startedServing);// 方法中去实例化了HMSHandler,用户处理客户端过来的请求startMetaStore(cli.getPort(), ShimLoader.getHadoopThriftAuthBridge(), conf, startLock,startCondition, startedServing);
JvmPauseMonitor.java
用来监控JVM的暂停情况。通过Daemon线程,默认每隔500ms计算一次。jvm暂停统计级别分为warn和info级别。如果暂停超过1000ms则info级别次数+1,如果超过10000ms,则warn级别+1。
private class Monitor implements Runnable {@Overridepublic void run() {Stopwatch sw = new Stopwatch();// 获取GC情况,GC次数和GC耗时msMap<String, GcTimes> gcTimesBeforeSleep = getGcTimes();while (shouldRun) {sw.reset().start();try {// 监控线程自我休眠500msThread.sleep(SLEEP_INTERVAL_MS);} catch (InterruptedException ie) {return;}// 上次查询时间-减去休眠就是暂停的耗时long extraSleepTime = sw.elapsed(TimeUnit.MILLISECONDS) - SLEEP_INTERVAL_MS;Map<String, GcTimes> gcTimesAfterSleep = getGcTimes();// warnThresholdMs默认10000msif (extraSleepTime > warnThresholdMs) {++numGcWarnThresholdExceeded;LOG.warn(formatMessage(extraSleepTime, gcTimesAfterSleep, gcTimesBeforeSleep));// 指标jvm.pause.info-threshold进行+1incrementMetricsCounter(MetricsConstant.JVM_PAUSE_WARN, 1);} // infoThresholdMs默认1000ms else if (extraSleepTime > infoThresholdMs) {++numGcInfoThresholdExceeded;LOG.info(formatMessage(extraSleepTime, gcTimesAfterSleep, gcTimesBeforeSleep));// 指标jvm.pause.warn-threshold进行+1incrementMetricsCounter(MetricsConstant.JVM_PAUSE_INFO, 1);}// jvm.pause.extraSleepTime 累计时间? msincrementMetricsCounter(MetricsConstant.JVM_EXTRA_SLEEP, extraSleepTime);totalGcExtraSleepTime += extraSleepTime;gcTimesBeforeSleep = gcTimesAfterSleep;}}private void incrementMetricsCounter(String name, long count) {Metrics metrics = MetricsFactory.getInstance();if (metrics != null) {try {metrics.incrementCounter(name, count);} catch (Exception e) {LOG.warn("Error Reporting JvmPauseMonitor to Metrics system", e);}}}}
HiveMetaStore的内部类HMSHandler
startFunction和endFunction是包裹以下元数据的操作,进行指标的采集控制。由这两个包裹的方法,除了本身的Timer指标(增加前缀api_)外,还会增加counters类型指标,不过在Timer指标名的基础上再增加active_calls_前缀,即active_calls_api_。
以下指标还会增加前缀api_,
-
库相关
create_databaseget_databasealter_databasedrop_databaseget_databasesget_all_databases
-
表相关
create_tabledrop_tableget_tableget_tablesget_tables_by_typeget_all_tablesget_table_metasget_multi_tableget_table_names_by_filterget_table_statistics_reqalter_table
-
分区相关
append_partitionappend_partition_by_namedrop_partition_by_nameget_partitions_psget_partitions_ps_with_authget_partitions_names_psadd_partitionsadd_partitiondrop_partitionget_partitionalter_partitionget_partition_with_authget_partitions_pspecget_partition_namesget_partition_by_nameget_partitions_by_exprget_num_partitions_by_filterget_num_partitions_by_exprget_partitions_by_namesget_partitions_by_filterget_partitions_by_filter_pspecget_partitions_statistics_req
-
其他
create_typeget_typedrop_typedrop_constraintadd_primary_keyadd_foreign_keyget_column_privilege_setadd_indexalter_indexdrop_index_by_nameget_index_by_nameget_index_namesget_indexesget_column_statistics_by_tableget_fields_with_environment_contextget_schema_with_environment_contextget_column_statistics_by_partitionwrite_column_statisticswrite_partition_column_statisticsdelete_column_statistics_by_partitiondelete_column_statistics_by_tableget_config_valuedelete_column_statistics_by_partitioncancel_delegation_tokenrenew_delegation_tokenget_delegation_tokenadd_tokenremove_tokenget_token for+XXXget_all_token_identifiers.add_master_key.update_master_key.remove_master_key.get_master_keys.partition_name_has_valid_charactersget_functionsget_all_functionsget_functionget_aggr_stats_forget_foreign_keys
例如get_database操作
public Database get_database(final String name) throws NoSuchObjectException, MetaException {startFunction("get_database", ": " + name);Database db = null;Exception ex = null;try {db = get_database_core(name);firePreEvent(new PreReadDatabaseEvent(db, this));} catch (MetaException e) {ex = e;throw e;} catch (NoSuchObjectException e) {ex = e;throw e;} finally {endFunction("get_database", db != null, ex);}return db;}
MetricsFactory的init(conf)方法
/*** Initializes static Metrics instance. 目前默认的实现类是 org.apache.hadoop.hive.common.metrics.metrics2.CodahaleMetrics*/
public synchronized static void init(HiveConf conf) throws Exception {if (metrics == null) {Class metricsClass = conf.getClassByName(conf.getVar(HiveConf.ConfVars.HIVE_METRICS_CLASS));Constructor constructor = metricsClass.getConstructor(HiveConf.class);metrics = (Metrics) constructor.newInstance(conf);}
}
CodahaleMetrics.java
通过有参构造函数,实例化CodahaleMetrics。里面一共涉及4个指标类型。timers,counters,meters,gauges。
public CodahaleMetrics(HiveConf conf) {this.conf = conf;//Codahale artifacts are lazily-created.timers = CacheBuilder.newBuilder().build(new CacheLoader<String, com.codahale.metrics.Timer>() {@Overridepublic com.codahale.metrics.Timer load(String key) {Timer timer = new Timer(new ExponentiallyDecayingReservoir());metricRegistry.register(key, timer);return timer;}});counters = CacheBuilder.newBuilder().build(new CacheLoader<String, Counter>() {@Overridepublic Counter load(String key) {Counter counter = new Counter();metricRegistry.register(key, counter);return counter;}});meters = CacheBuilder.newBuilder().build(new CacheLoader<String, Meter>() {@Overridepublic Meter load(String key) {Meter meter = new Meter();metricRegistry.register(key, meter);return meter;}});gauges = new ConcurrentHashMap<String, Gauge>();//register JVM metrics - java虚拟机的相关指标集registerAll("gc", new GarbageCollectorMetricSet());registerAll("buffers", new BufferPoolMetricSet(ManagementFactory.getPlatformMBeanServer()));registerAll("memory", new MemoryUsageGaugeSet());registerAll("threads", new ThreadStatesGaugeSet());registerAll("classLoading", new ClassLoadingGaugeSet());//Metrics reporter -进行指标的输出Set<MetricsReporting> finalReporterList = new HashSet<MetricsReporting>();// 默认的导出类型是JSON_FILE, JMX。List<String> metricsReporterNames = Lists.newArrayList(Splitter.on(",").trimResults().omitEmptyStrings().split(conf.getVar(HiveConf.ConfVars.HIVE_METRICS_REPORTER)));if (metricsReporterNames != null) {for (String metricsReportingName : metricsReporterNames) {try {MetricsReporting reporter = MetricsReporting.valueOf(metricsReportingName.trim().toUpperCase());finalReporterList.add(reporter);} catch (IllegalArgumentException e) {LOGGER.warn("Metrics reporter skipped due to invalid configured reporter: " + metricsReportingName);}}}initReporting(finalReporterList);}
具体指标对象
GarbageCollectorMetricSet:一组用于垃圾收集计数和运行时间的仪表。BufferPoolMetricSet:一组测量JVM的直接和映射缓冲池的计数、使用情况和容量的指标。这些JMX对象仅在Java 7及以上版本上可用。MemoryUsageGaugeSet:一组用于JVM内存使用的指标,包括堆与非堆内存的统计信息,以及特定于gc的内存池。ThreadStatesGaugeSet:一组用于各种状态和死锁检测的线程数量的量规。ClassLoadingGaugeSet:JVM类加载器使用情况的一组指标。
指标导出
/*** Should be only called once to initialize the reporters*/private void initReporting(Set<MetricsReporting> reportingSet) {for (MetricsReporting reporting : reportingSet) {switch (reporting) {case CONSOLE:final ConsoleReporter consoleReporter = ConsoleReporter.forRegistry(metricRegistry).convertRatesTo(TimeUnit.SECONDS).convertDurationsTo(TimeUnit.MILLISECONDS).build();consoleReporter.start(1, TimeUnit.SECONDS);reporters.add(consoleReporter);break;case JMX:final JmxReporter jmxReporter = JmxReporter.forRegistry(metricRegistry).convertRatesTo(TimeUnit.SECONDS).convertDurationsTo(TimeUnit.MILLISECONDS).build();jmxReporter.start();reporters.add(jmxReporter);break;case JSON_FILE:final JsonFileReporter jsonFileReporter = new JsonFileReporter();jsonFileReporter.start();reporters.add(jsonFileReporter);break;case HADOOP2:String applicationName = conf.get(HiveConf.ConfVars.HIVE_METRICS_HADOOP2_COMPONENT_NAME.varname);long reportingInterval = HiveConf.toTime(conf.get(HiveConf.ConfVars.HIVE_METRICS_HADOOP2_INTERVAL.varname),TimeUnit.SECONDS, TimeUnit.SECONDS);final HadoopMetrics2Reporter metrics2Reporter = HadoopMetrics2Reporter.forRegistry(metricRegistry).convertRatesTo(TimeUnit.SECONDS).convertDurationsTo(TimeUnit.MILLISECONDS).build(DefaultMetricsSystem.initialize(applicationName), // The application-level nameapplicationName, // Component nameapplicationName, // Component description"General"); // Name for each metric recordmetrics2Reporter.start(reportingInterval, TimeUnit.SECONDS);break;}}}
在hive2版本有4类导出器
ConsoleReporter:通过调度线程,按周期将指标输出到日志里面。JmxReporter:一个报告器,用于监听新指标,并将发送其作为名称标注的 MBeans。JsonFileReporter:通过Timer,定时调度,将指标写入目标文件中。HadoopMetrics2Reporter:通过调度线程,按周期将指标更新到度量对象dropwizardGauges,dropwizardCounters,dropwizardHistograms,dropwizardMeters,dropwizardTimers中,再由hadoop2的指标系统去获取转换由 dropwizard 收集的当前指标,并将其添加到Hadoop2的指标系统中。
JsonFileReporter输出的文件内容示例
-
回收
- gc.PS-MarkSweep.count:标记次数
- gc.PS-MarkSweep.time:标记耗时ms
- gc.PS-Scavenge.count:清除次数
- gc.PS-Scavenge.time:清除耗时ms
-
内存
-
memory.heap.committed:JVM 已经提交的 HeapMemory 的大小, byte
-
memory.heap.init:JVM 初始 HeapMem 的大小
-
memory.heap.usage:已使用内存占比
-
memory.heap.max:JVM 配置的 HeapMemory 的大小
-
memory.heap.used:已使用堆内存大小, byte
-
memory.non-heap.committed:JVM 当前已经提交的 NonHeapMemory 的大小, byte
-
memory.non-heap.init:JVM 初始 NonHeapMem 的大小, byte
-
memory.non-heap.max:JVM 配置的 NonHeapMemory 的数大小, byte
-
memory.non-heap.usage:已使用NonHeapMemory 内存占比
-
memory.non-heap.used:JVM 当前已经使用的 NonHeapMemory 的大小, byte
-
memory.pools.Code-Cache.usage:代码缓存区使用占比
-
memory.pools.Compressed-Class-Space.usage:压缩类空间空间使用占比
-
memory.pools.Metaspace.usage:Metaspace 区内存使用占比
-
memory.pools.PS-Eden-Space.usage:Eden区内存使用占比
-
memory.pools.PS-Old-Gen.usage:Old区内存使用占比
-
memory.pools.PS-Survivor-Space.usage:Survivo区内存使用占比
-
memory.total.committed:保证可用于堆或非堆的总内存量
-
memory.total.init:堆或非堆初始化的内存量
-
memory.total.max:堆或非堆配置的最大中内存量
-
memory.total.used:堆或非堆使用的总内存量
-
-
线程
- threads.count:总线程数
- threads.daemon.count:常驻线程数
- threads.deadlock.count:死锁线程数
-
counters下
active_calls_*系列:正在执行的方法的个数,方法主要在HiveMetaStore的内部类HMSHandler中。 -
timers下
api_系列:执行的方法响应(个数,平均、最大、最小、中位数耗时等等),方法主要在HiveMetaStore的内部类HMSHandler中。
{"version" : "3.0.0","gauges" : {"buffers.direct.capacity" : {"value" : 0},"buffers.direct.count" : {"value" : 0},"buffers.direct.used" : {"value" : 0},"buffers.mapped.capacity" : {"value" : 0},"buffers.mapped.count" : {"value" : 0},"buffers.mapped.used" : {"value" : 0},"classLoading.loaded" : {"value" : 6932},"classLoading.unloaded" : {"value" : 0},"gc.PS-MarkSweep.count" : {"value" : 2},"gc.PS-MarkSweep.time" : {"value" : 250},"gc.PS-Scavenge.count" : {"value" : 5},"gc.PS-Scavenge.time" : {"value" : 92},"init_total_count_dbs" : {"value" : 489},"init_total_count_partitions" : {"value" : 51089},"init_total_count_tables" : {"value" : 13733},"memory.heap.committed" : {"value" : 991428608},"memory.heap.init" : {"value" : 1073741824},"memory.heap.max" : {"value" : 991428608},"memory.heap.usage" : {"value" : 0.22776332070498415},"memory.heap.used" : {"value" : 225811072},"memory.non-heap.committed" : {"value" : 62717952},"memory.non-heap.init" : {"value" : 2555904},"memory.non-heap.max" : {"value" : -1},"memory.non-heap.usage" : {"value" : -6.1740872E7},"memory.non-heap.used" : {"value" : 61740872},"memory.pools.Code-Cache.usage" : {"value" : 0.04560165405273438},"memory.pools.Compressed-Class-Space.usage" : {"value" : 0.004726290702819824},"memory.pools.Metaspace.usage" : {"value" : 0.9850643484933036},"memory.pools.PS-Eden-Space.usage" : {"value" : 0.5518231919863521},"memory.pools.PS-Old-Gen.usage" : {"value" : 0.07657499299391471},"memory.pools.PS-Survivor-Space.usage" : {"value" : 0.9316617525540866},"memory.total.committed" : {"value" : 1054146560},"memory.total.init" : {"value" : 1076297728},"memory.total.max" : {"value" : 991428607},"memory.total.used" : {"value" : 287551944},"threads.blocked.count" : {"value" : 0},"threads.count" : {"value" : 27},"threads.daemon.count" : {"value" : 16},"threads.deadlock.count" : {"value" : 0},"threads.deadlocks" : {"value" : [ ]},"threads.new.count" : {"value" : 0},"threads.runnable.count" : {"value" : 4},"threads.terminated.count" : {"value" : 0},"threads.timed_waiting.count" : {"value" : 7},"threads.waiting.count" : {"value" : 16}},"counters" : {"active_calls_api_get_database" : {"count" : 0},"active_calls_api_get_tables" : {"count" : 0},"active_calls_api_init" : {"count" : 0},"active_calls_api_set_ugi" : {"count" : 0},"jvm.pause.extraSleepTime" : {"count" : 6},"open_connections" : {"count" : 1}},"histograms" : { },"meters" : { },"timers" : {"api_get_database" : {"count" : 54,"max" : 99.228759,"mean" : 11.107232182804301,"min" : 10.091598,"p50" : 11.098374,"p75" : 11.503314,"p95" : 12.130782,"p98" : 12.130782,"p99" : 12.130782,"p999" : 12.913863,"stddev" : 0.6771821794059291,"m15_rate" : 0.0,"m1_rate" : 0.0,"m5_rate" : 0.0,"mean_rate" : 0.0,"duration_units" : "milliseconds","rate_units" : "calls/millisecond"},"api_get_tables" : {"count" : 18,"max" : 31.114395,"mean" : 9.939109200622983,"min" : 9.404240999999999,"p50" : 9.841852,"p75" : 10.122354,"p95" : 10.122354,"p98" : 10.122354,"p99" : 10.122354,"p999" : 10.203377999999999,"stddev" : 0.18434488642295546,"m15_rate" : 0.0,"m1_rate" : 0.0,"m5_rate" : 0.0,"mean_rate" : 0.0,"duration_units" : "milliseconds","rate_units" : "calls/millisecond"},"api_init" : {"count" : 1,"max" : 3225.4620339999997,"mean" : 3225.4620339999997,"min" : 3225.4620339999997,"p50" : 3225.4620339999997,"p75" : 3225.4620339999997,"p95" : 3225.4620339999997,"p98" : 3225.4620339999997,"p99" : 3225.4620339999997,"p999" : 3225.4620339999997,"stddev" : 0.0,"m15_rate" : 0.0,"m1_rate" : 0.0,"m5_rate" : 0.0,"mean_rate" : 0.0,"duration_units" : "milliseconds","rate_units" : "calls/millisecond"},"api_set_ugi" : {"count" : 1,"max" : 0.284408,"mean" : 0.284408,"min" : 0.284408,"p50" : 0.284408,"p75" : 0.284408,"p95" : 0.284408,"p98" : 0.284408,"p99" : 0.284408,"p999" : 0.284408,"stddev" : 0.0,"m15_rate" : 0.0,"m1_rate" : 0.0,"m5_rate" : 0.0,"mean_rate" : 0.0,"duration_units" : "milliseconds","rate_units" : "calls/millisecond"}}
}
其他
#这个类定义了Hive进程生成的一些指标。
org.apache.hadoop.hive.common.metrics.common.MetricsConstant#可以用来度量和记录一段代码所花费的时间。
org.apache.hadoop.hive.ql.log.PerfLogger
腾讯云的hive-metastore指标
| 标题 | 指标名称 | 指标单位 | 指标含义 |
|---|---|---|---|
| GC 次数 | YGC | 次 | Young GC 次数 |
| FGC | 次 | Full GC 次数 | |
| GC 时间 | FGCT | s | Full GC 消耗时间 |
| GCT | s | 垃圾回收时间消耗 | |
| YGCT | s | Young GC 消耗时间 | |
| 内存区域占比 | S0 | % | Survivor 0区内存使用占比 |
| E | % | Eden 区内存使用占比 | |
| CCS | % | Compressed class space 区内存使用占比 | |
| S1 | % | Survivor 1区内存使用占比 | |
| O | % | Old 区内存使用占比 | |
| M | % | Metaspace 区内存使用占比 | |
| JVM 内存 | MemHeapUsedM | MB | JVM 当前已经使用的 HeapMemory 的数量 |
| MemHeapCommittedM | MB | JVM 已经提交的 HeapMemory 的数量 | |
| MemHeapMaxM | MB | JVM 配置的 HeapMemory 的数量 | |
| MemHeapInitM | MB | JVM 初始 HeapMem 的数量 | |
| MemNonHeapUsedM | MB | JVM 当前已经使用的 NonHeapMemory 的数量 | |
| MemNonHeapCommittedM | MB | JVM 当前已经提交的 NonHeapMemory 的数量 | |
| MemNonHeapInitM | MB | JVM 初始 NonHeapMem 的数量 | |
| 文件描述符数 | OpenFileDescriptorCount | 个 | 已打开文件描述符数量 |
| MaxFileDescriptorCount | 个 | 最大文件描述符数 | |
| CPU 利用率 | ProcessCpuLoad | % | 进程 CPU 利用率 |
| SystemCpuLoad | % | 系统 CPU 利用率 | |
| CPU 使用时间占比 | CPURate | seconds/second | CPU 使用时间占比 |
| 工作线程数 | DaemonThreadCount | 个 | 守护线程数 |
| ThreadCount | 个 | 线程总数 | |
| CPU 累计使用时间 | ProcessCpuTime | ms | CPU 累计使用时间 |
| 进程运行时长 | Uptime | s | 进程运行时长 |
| GC 额外睡眠时间 | ExtraSleepTime | ms/s | GC 额外睡眠时间 |
| alter table 请求时间 | HIVE.HMS.API_ALTER_TABLE | ms | alter table 请求平均时间 |
| alter table with env context 请求时间 | HIVE.HMS.API_ALTER_TABLE_WITH_ENV_CONTEXT | ms | alter table with env context 请求平均时间 |
| create table 请求时间 | HIVE.HMS.API_CREATE_TABLE | ms | create table 请求平均时间 |
| create table with env context 请求时间 | HIVE.HMS.API_CREATE_TABLE_WITH_ENV_CONTEXT | ms | create table with env context 请求平均时间 |
| drop table 请求时间 | HIVE.HMS.API_DROP_TABLE | ms | drop table 平均请求时间 |
| drop table with env context 请求时间 | HIVE.HMS.API_DROP_TABLE_WITH_ENV_CONTEXT | ms | drop table with env context 平均请求时间 |
| get table 请求时间 | HIVE.HMS.API_GET_TABLE | ms | get table 平均请求时间 |
| get tables 请求时间 | HIVE.HMS.API_GET_TABLES | ms | get tables 平均请求时间 |
| get multi table 请求时间 | HIVE.HMS.API_GET_MULTI_TABLE | ms | get multi table 平均请求时间 |
| get table req 请求时间 | HIVE.HMS.API_GET_TABLE_REQ | ms | get table req 平均请求时间 |
| get database 请求时间 | HIVE.HMS.API_GET_DATABASE | ms | get database 平均请求时间 |
| get databases 请求时间 | HIVE.HMS.API_GET_DATABASES | ms | get databases 平均请求时间 |
| get all database 请求时间 | HIVE.HMS.API_GET_ALL_DATABASES | ms | get all databases 平均请求时间 |
| get all functions 请求时间 | HIVE.HMS.API_GET_ALL_FUNCTIONS | ms | get all functions 平均请求时间 |
| 当前活跃 create table 请求数 | HIVE.HMS.ACTIVE_CALLS_API_CREATE_TABLE | 个 | 当前活跃 create table 请求数 |
| 当前活跃 drop table 请求数 | HIVE.HMS.ACTIVE_CALLS_API_DROP_TABLE | 个 | 当前活跃 drop table 请求数 |
| 当前活跃 alter table 请求数 | HIVE.HMS.ACTIVE_CALLS_API_ALTER_TABLE | 个 | 当前活跃 alter table 请求数 |
参考资料
相关CWiki
-
Hive+Metrics:指标的总览页。提供部分指标的issues链接。
-
WebUIforHiveServer2:介绍WebUI可以查询展示指标。
-
ConfigurationProperties-Metrics :介绍指标的部分配置。
相关文章:

【Hive实战】 HiveMetaStore的指标分析
HiveMetaStore的指标分析(一) 文章目录 HiveMetaStore的指标分析(一)背景目标部署架构 hive-site.xml相关配置元数据服务的指标相关配置 源码部分(hive2.3系)JvmPauseMonitor.javaHiveMetaStore的内部类HMS…...

【Linux系统】CUDA的安装与graspnet环境配置遇到的问题
今天在安装环境时遇到报错: The detected CUDA version (10.1) mismatches the version that was used to compile PyTorch (11.8). Please make sure to use the same CUDA versions. 报错原因:安装的cuda版本不对应,我需要安装cuda的版本…...
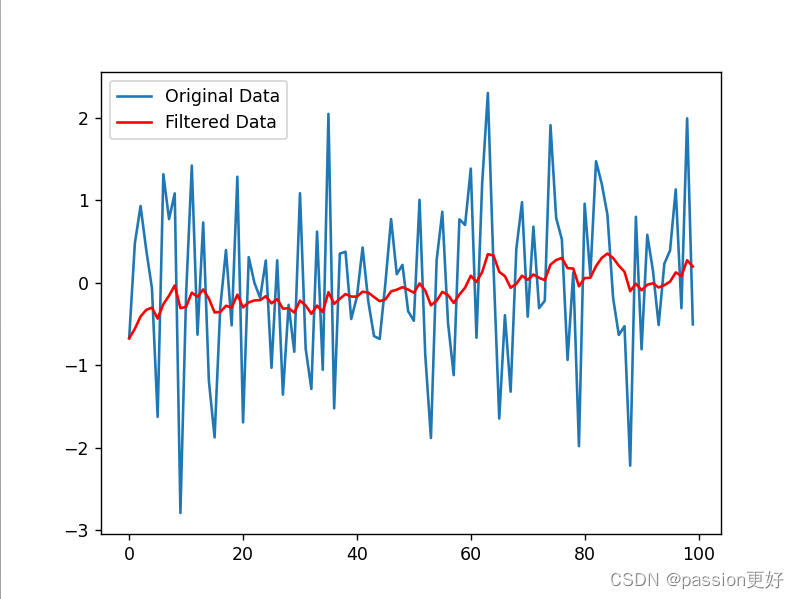
滤波算法学习笔记
目录 引言 一、定义 二、分类 三、常见滤波算法 四、应用与优势 五、发展趋势 例程 1. 均值滤波(Moving Average Filter) 2. 中值滤波(Median Filter) 3. 高斯滤波(Gaussian Filter) 4.指数移动…...
【机器学习】机器学习的重要方法——线性回归算法深度探索与未来展望
欢迎来到 破晓的历程博客 引言 在数据科学日益重要的今天,线性回归算法以其简单、直观和强大的预测能力,成为了众多领域中的基础工具。本文将详细介绍线性回归的基本概念、核心算法,并通过五个具体的使用示例来展示其应用,同时探…...

百度云智能媒体内容分析一体机(MCA)建设
导读 :本文主要介绍了百度智能云MCA产品的概念和应用。 媒体信息海量且复杂,采用人工的方式对视频进行分析处理,面临着效率低、成本高的困难。于是,MCA应运而生。它基于百度自研的视觉AI、ASR、NLP技术,为用户提供音视…...

笔记本电脑部署VMware ESXi 6.0系统
正文共:888 字 18 图,预估阅读时间:1 分钟 前面我们介绍了在笔记本上安装Windows 11操作系统(Windows 11升级不了?但Win10就要停服了啊!来,我教你!),也介绍了…...
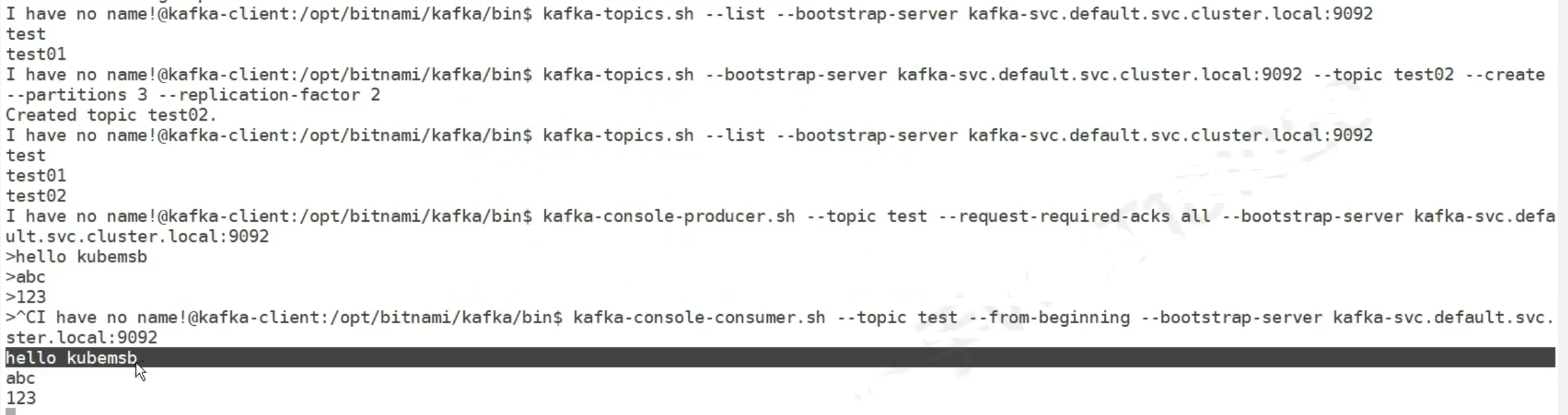
k8s 中间件
1. zookeeper 是的,Zookeeper 和 Kafka 经常一起使用,Zookeeper 在 Kafka 中扮演了关键角色。以下是 Zookeeper 和 Kafka 在实际项目中的结合使用及其作用的详细说明。 项目背景 假设我们有一个分布式数据处理系统,该系统需要高吞吐量的实…...

如何 提升需求确定性
提升需求确定性是确保项目成功的关键之一。以下是一些方法和策略可以帮助你提升需求的确定性: 积极的利益相关者参与: 确保所有关键利益相关者(包括最终用户、业务所有者、开发团队等)参与需求收集和确认过程。他们的参与可以提供…...

探索Sui的面向对象模型和Move编程语言
Sui区块链作为一种新兴的一层协议(L1),采用先进技术来解决常见的一层协议权衡问题。Cointelegraph Research详细剖析了这一区块链新秀。 Sui使用Move编程语言,该语言专注于资产表示和访问控制。本文探讨了Sui的对象中心数据存储模…...

【vue动态组件】VUE使用component :is 实现在多个组件间来回切换
VUE使用component :is 实现在多个组件间来回切换 component :is 动态父子组件传值 相关代码实现: <component:is"vuecomponent"></component>import componentA from xxx; import componentB from xxx; import componentC from xxx;switch(…...
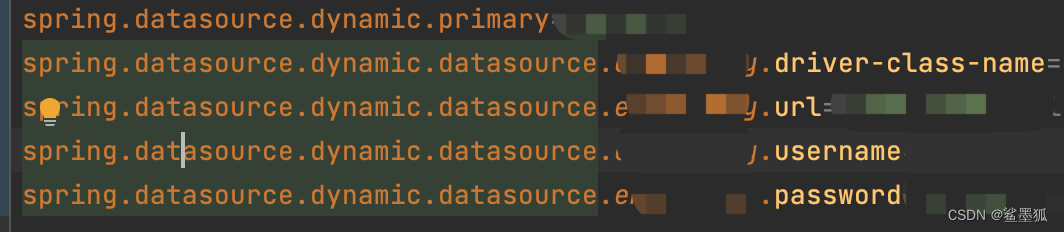
springboot dynamic配置多数据源
pom.xml引入jar包 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.2</version> </dependency> application配置文件配置如下 需要主要必须配置…...
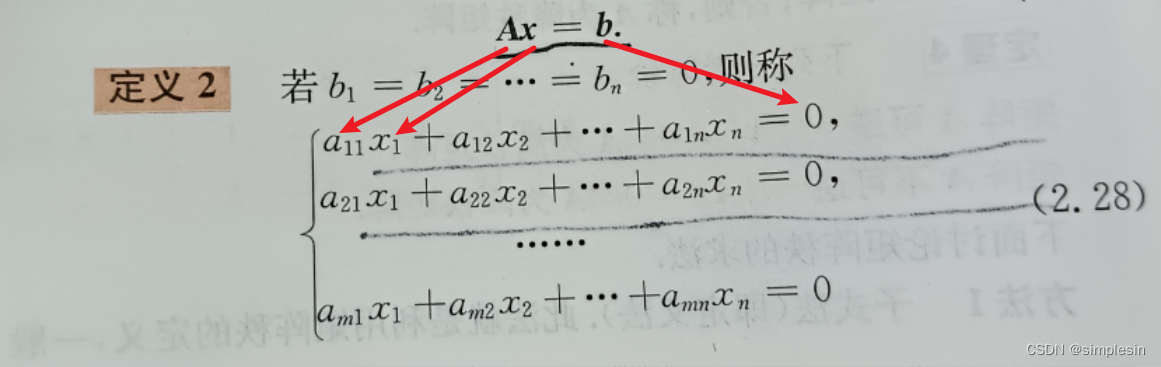
线性代数知识点搜刮
求你别考太细... 目录 异乘变零定理 行列式转置 值不变 重要关系 中间相等,取两头 特征值公式 向量正交 点积为0 拉普拉斯定理 矩阵的秩 特征值和特征向量 |A|特征值的乘积 & tr(A)特征值的和 要记要背 增广矩阵 异乘变零定理 某行(…...

景区智能厕所系统,打造智能化,人性化公共空间
在智慧旅游的大潮中,景区智能厕所系统正逐渐成为提升公共空间智能化、人性化水平的关键载体。作为智慧城市建设的重要组成部分,智能厕所系统不仅解决了传统公厕存在的诸多问题,更通过科技的力量,为游客创造了更加舒适、便捷的如厕…...

Windows中Git的使用(2024最新版)
Windows中Git的使用 获取ssh keys本地绑定邮箱初始化本地仓库添加到本地缓存区提交到本地缓存区切换本地分支为main关联远程分支推送到GitHub查看推送日志 Git 2020年发布了新的默认分支名称"main",取代了"master"作为主分支的名称。操作有了些…...
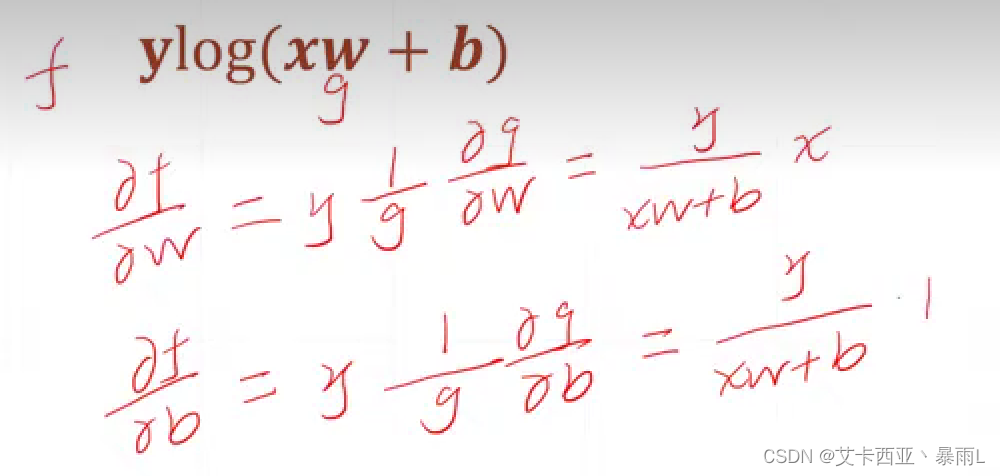
【pytorch12】什么是梯度
说明 导数偏微分梯度 梯度:是一个向量,向量的每一个轴是每一个方向上的偏微分 梯度是有方向也有大小,梯度的方向代表函数在当前点的一个增长的方向,然后这个向量的长度代表了这个点增长的速率 蓝色代表比较小的值,红色…...

南京,协同开展“人工智能+”行动
南京,作为江苏省的省会城市,一直以来都是科技创新和产业发展的高地。近日,南京市政府正式印发了《南京市进一步促进人工智能创新发展行动计划(2024—2026 年)》和《南京市促进人工智能创新发展若干政策措施》的“11”文…...
Selenium IDE 的使用指南
Selenium IDE 的使用指南 在自动化测试的领域中,Selenium 是一个广为人知且强大的工具集。而 Selenium IDE 作为其中的一个组件,为测试人员提供了一种便捷且直观的方式来创建和执行自动化测试脚本。 一、Selenium IDE 简介 Selenium IDE 是一个用于录…...

vue配置sql规则
vue配置sql规则 实现效果组件完整代码父组件 前端页面实现动态配置sql条件,将JSON结构给到后端,后端进行sql组装。 这里涉及的分组后端在组装时用括号将这块规则括起来就行,分组的sql连接符(并且/或者)取组里的第一个。…...

面试官:Redis执行lua脚本能保证原子性吗?
核心问题 Redis执行lua脚本是否能确保原子性? 面试经历 面试者在面试中自信回答Redis执行lua脚本能保证原子性,但未能深入解释原因。 原子性概念 原子性:一个事务的所有命令要么全部执行成功,要么全部执行失败。 Redis官方说…...

基于Chrome扩展的浏览器可信事件与网页离线PDF导出
基于Chrome扩展的浏览器可信事件与网页离线PDF导出 Chrome扩展是一种可以在浏览器中添加新功能和修改浏览器行为的软件程序,我们可以基于Manifest规范的API实现对于浏览器和Web页面在一定程度上的修改,例如广告拦截、代理控制等。Chrome DevTools Proto…...

终极指南:快速重置JetBrains IDE试用期的完整方案
终极指南:快速重置JetBrains IDE试用期的完整方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾为JetBrains IDE试用期到期而烦恼?面对复杂的评估机制和分散的系统文件ÿ…...

从文本到流程:NLP与LLM驱动的业务流程模型自动提取技术
1. 项目概述与核心价值在业务流程管理(BPM)的日常工作中,我们经常遇到一个经典难题:业务部门或客户给出一大段文字描述,比如一份操作手册、一封需求邮件或一次会议纪要,我们需要从中梳理出清晰、可执行的业…...

AutoIRT:融合AutoML与IRT,实现自适应测试题目参数的自动化高效校准
1. 项目概述与核心价值在语言能力测评、职业资格认证乃至教育领域的个性化学习路径规划中,计算机化自适应测试(CAT)正扮演着越来越核心的角色。它的魅力在于“千人千面”——系统能根据考生上一题的作答表现,实时调整下一题的难度…...

SSH连接报kex_exchange_identification的4步根因定位法
1. 这个报错不是SSH客户端的问题,而是服务器在“拒之门外” “kex_exchange_identification”——这串字符第一次出现在终端里时,我正帮一位刚转行做运维的同事排查一台新部署的Ubuntu云服务器。他反复执行 ssh userip ,每次都在输入密码前…...

【AI Agent游戏行业应用实战指南】:20年资深架构师亲授7大落地场景与避坑清单
更多请点击: https://intelliparadigm.com 第一章:AI Agent游戏行业应用全景图谱 AI Agent 正在重塑游戏开发、运营与玩家体验的全生命周期。从智能NPC的行为建模,到自动化测试与关卡生成,再到实时个性化内容推荐与跨平台玩家陪伴…...

Keil MDK中自定义CMSIS代码模板实战指南
1. 自定义CMSIS用户代码模板的完整指南作为一名嵌入式开发老手,我经常需要在Keil MDK环境中创建各种RTOS任务模板。官方提供的模板虽然好用,但实际项目中我们往往需要根据公司编码规范或特定硬件平台定制专属模板。今天我就来分享如何在CMSIS环境中添加自…...

ARTX实时操作系统任务监控与调试实践
1. 实时任务监控需求解析在嵌入式实时操作系统(RTOS)开发中,任务调度监控是调试复杂系统的关键手段。ARTX-166作为一款面向C166架构的高级实时操作系统,其任务调度机制直接影响系统实时性能。当系统出现响应延迟或死锁时ÿ…...

ERR_CONNECTION_REFUSED 根本原因与四步定位法
1. 这个报错不是网络问题,而是本地服务没跑起来的“心跳停止”信号你刚在终端敲下npm run dev,浏览器自动打开http://localhost:3000,页面一片空白,F12 打开 Console,赫然一行红字:Failed to load resource…...

RuoYi接口调试:Postman作为Spring Boot权限系统可信信使
1. 为什么RuoYi项目里Postman不是“配角”,而是调试生命线在RuoYi开发实战中,很多人把Postman当成一个“临时工具”——写完接口顺手点一下,成功了就扔一边,失败了就切回IDE疯狂加日志、重启服务、反复试错。我带过三届实习生&…...

3个PDF编辑痛点,用这个免费工具轻松搞定!PDF补丁丁全面解析
3个PDF编辑痛点,用这个免费工具轻松搞定!PDF补丁丁全面解析 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目…...