普通集群与镜像集群配置
目录
一. 环境准备
二. 开始配置集群
三. RabbitMQ镜像集群配置
四. 安装并配置负载均衡器HA
一. 环境准备
关闭防火墙和selinux,进行时间同步
| 主机名 | 系统 | IP | 服务 |
|---|---|---|---|
| rabbitmq-1 | Rocky_linux9.4 | 192.168.226.22 | RabbitMQ,MySQL |
| rabbitmq-2 | Rocky_linux9.4 | 192.168.226.23 | RabbitMQ |
| rabbitmq-3 | Rocky_linux9.4 | 192.168.226.24 | RabbitMQ |
修改主机名#192.168.226.22
hostnamectl set-hostname rabbitmq-1#192.168.226.22
hostnamectl set-hostname rabbitmq-2#192.168.226.22
hostnamectl set-hostname rabbitmq-3注:修改完后都手动断开重新连接,不要使用bash配置域名解析,三台虚拟机都配置
cat >> /etc/hosts <<EOF
192.168.226.22 rabbitmq-1
192.168.226.23 rabbitmq-2
192.168.226.24 rabbitmq-3
EOF
参考博文RabbitMQ消息中间件介绍与安装-CSDN博客
三台虚拟机都安装RabbitMQ,并进入到web管理界面,如下图:
二. 开始配置集群
1.首先创建好数据存放目录和日志存放目录
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/data
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/logs
[root@rabbitmq-1 ~]# chmod 777 -R /data/rabbitmq
[root@rabbitmq-1 ~]# chown rabbitmq.rabbitmq /data/ -R创建配置文件:
[root@rabbitmq-1 ~]#cat > /etc/rabbitmq/rabbitmq-env.conf <<EOF
RABBITMQ_MNESIA_BASE=/data/rabbitmq/data
RABBITMQ_LOG_BASE=/data/rabbitmq/logs
EOF重启服务
[root@rabbitmq-1 ~]# systemctl restart rabbitmq-server2. 拷⻉erlang.cookie
Rabbitmq的集群是依附于erlang的集群来⼯作的,所以必须先构建起erlang的集群景象。Erlang的集群中
各节点是经由过程⼀个magic cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中,⽂件是400的权限。所以必须保证各节点cookie⼀致,不然节点之间就⽆法通信.
(官方在介绍集群的文档中提到过.erlang.cookie 一般会存在这两个地址:第一个是home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie。如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在{home}目录下,也就是$home/.erlang.cookie。如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。)
[root@rabbitmq-1 ~]# cat /var/lib/rabbitmq/.erlang.cookie
HVYPGZCOFCYBEZHGUHQB⽤scp的⽅式将rabbitmq-1节点的.erlang.cookie的值复制到其他两个节点中,一次保证cookie一致。
[root@rabbitmq-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.226.23:/var/lib/rabbitmq/
[root@rabbitmq-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.226.24:/var/lib/rabbitmq/3.将rabbitmq-2、rabbitmq-3作为内存节点加⼊rabbitmq-1节点集群中
在rabbitmq-2、rabbitmq-3执⾏如下命令:
[root@rabbitmq-2 ~]# systemctl restart rabbitmq-server
[root@rabbitmq-2 ~]# rabbitmqctl stop_app #停止节点
[root@rabbitmq-2 ~]# rabbitmqctl reset #如果有数据需要重置,没有则不用
[root@rabbitmq-2 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq-1 #添加到内存节点
Clustering node 'rabbit@rabbitmq-2' with 'rabbit@rabbitmq-1' ...
[root@rabbitmq-2 ~]# rabbitmqctl start_app #启动节点
Starting node 'rabbit@rabbitmq-2' ...======================================================================(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,
mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使⽤命令rabbitmqctl change_cluster_node_type
disc(ram),前提是必须停掉rabbit应⽤
注:
#如果有需要使用磁盘节点加入集群,使用下述命令格式,默认即为磁盘节点,内存节点是加上--ram参数
rabbitmqctl join_cluster rabbit@rabbitmq-1#如果执行rabbitmqctl stop_app 这条命令报错:需要执行
#chmod 400 .erlang.cookie
#chown rabbitmq.rabbitmq .erlang.cookie4. 查看集群状态
在 RabbitMQ 集群任意节点上执行 rabbitmqctl cluster_status来查看是否集群配置成功。
这里我在rabbitmq-1磁盘节点上面查看
[root@rabbitmq-1 ~]# rabbitmqctl cluster_status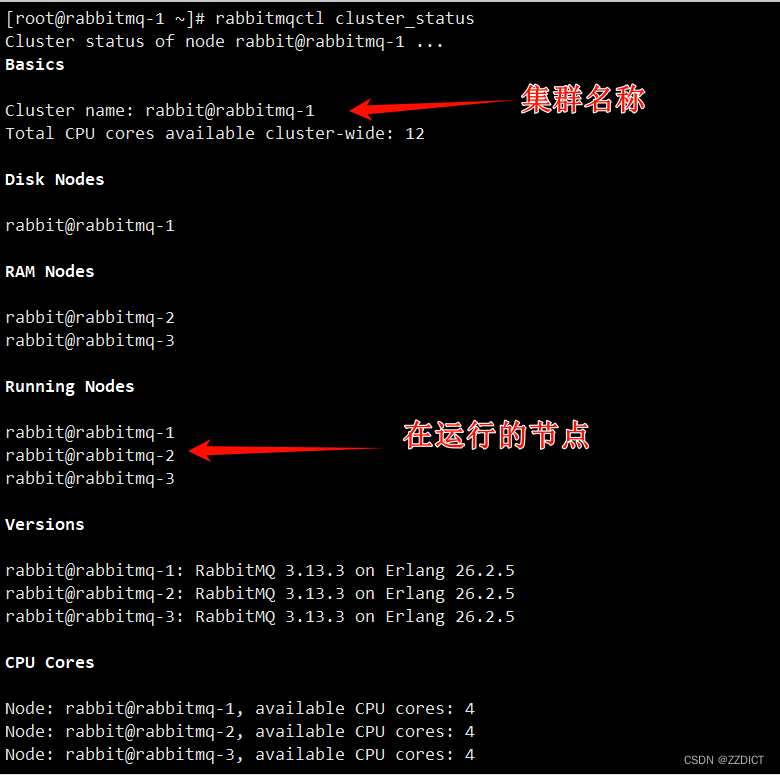
每台机器显示出三台节点,表示已经添加成功!
(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使用命令rabbitmqctl change_cluster_node_type disc(ram),前提是必须停掉
rabbit应用
在RabbitMQ集群集群中,必须⾄少有⼀个磁盘节点,否则队列元数据⽆法写⼊到集群中,当磁盘节点宕掉时,集群将⽆法写⼊新的队列元数据信息。5.登录rabbitmq web管理控制台,创建新的队列
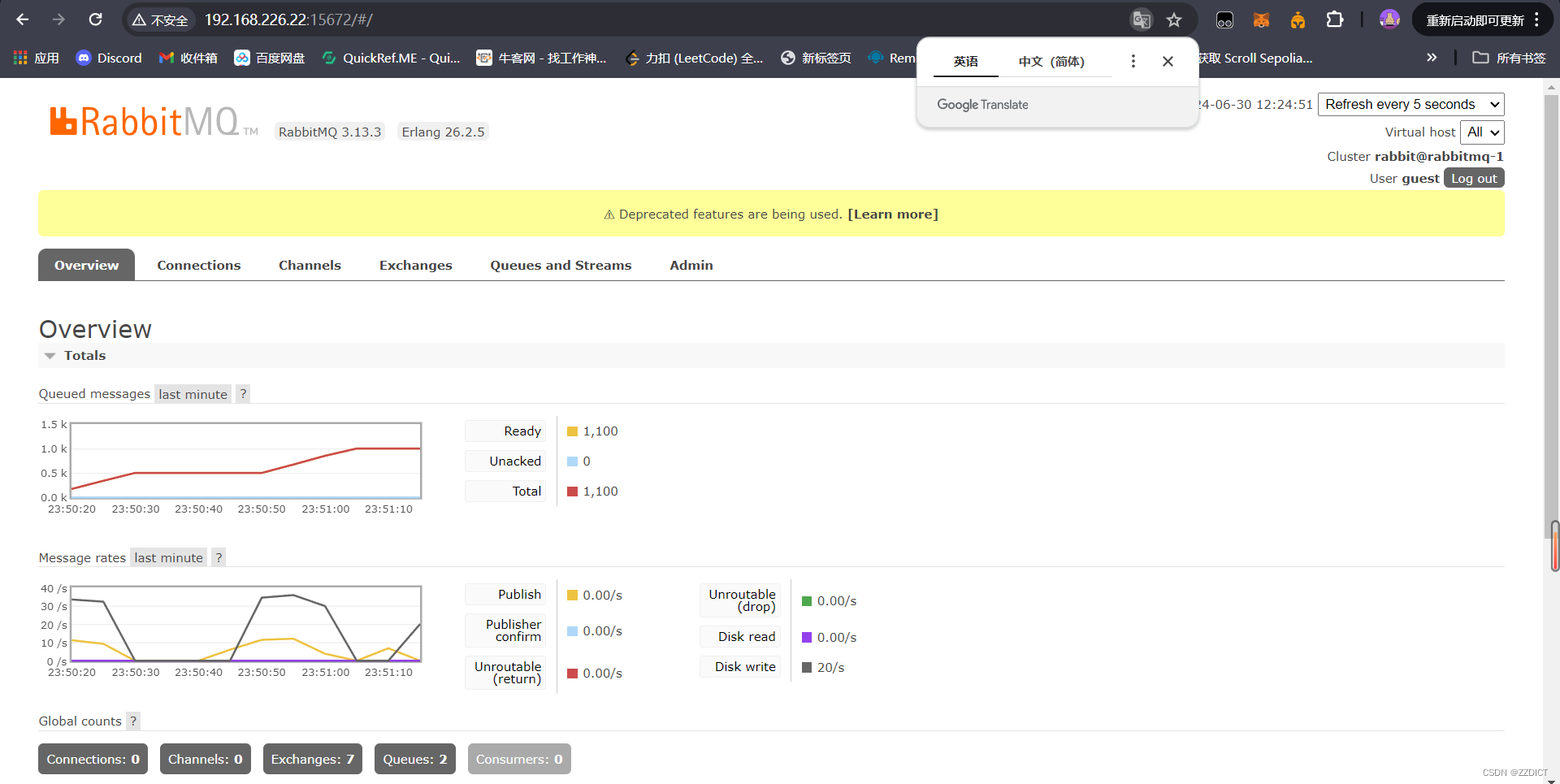
打开浏览器输⼊http://192.168.226.22:15672 输入用户名密码进入
登录后出现如图所示的界⾯执行操作。
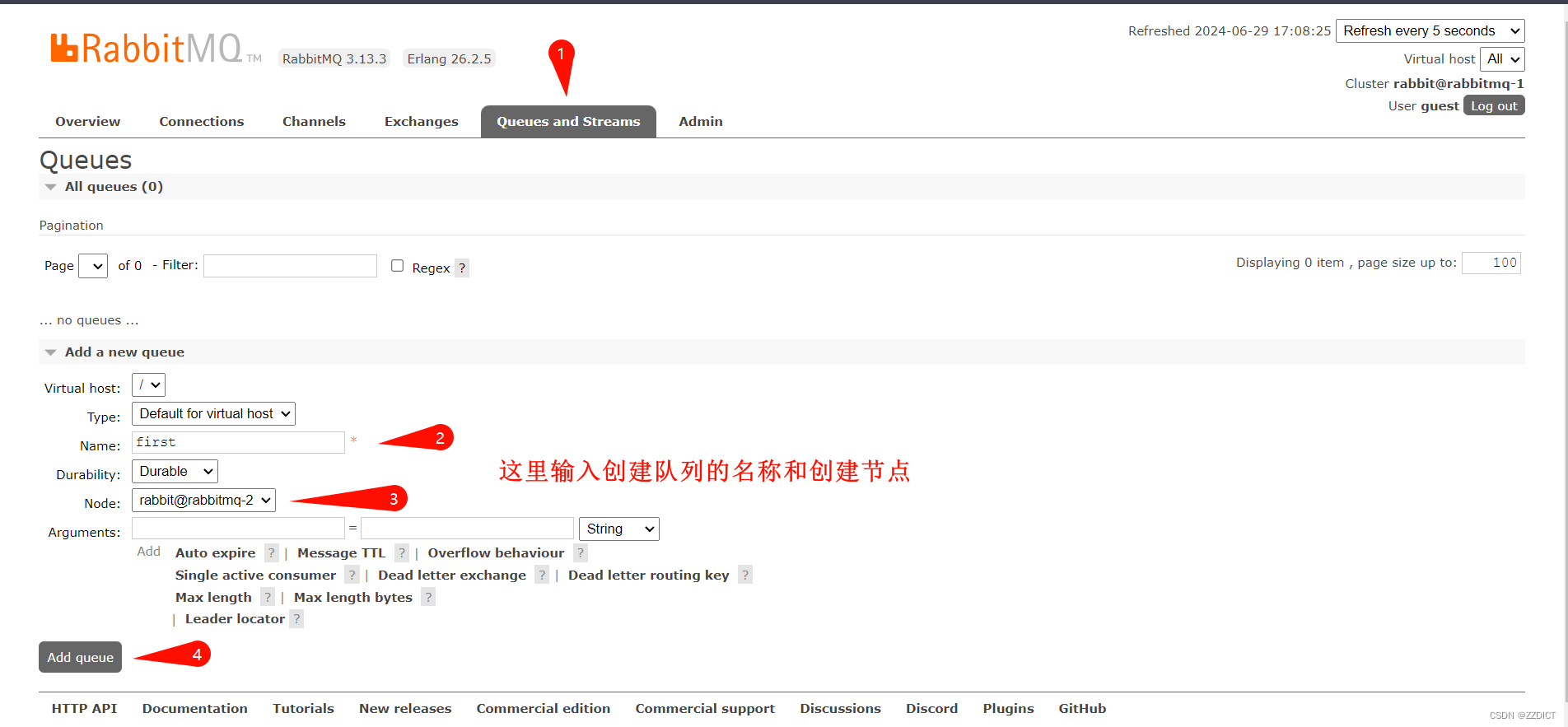
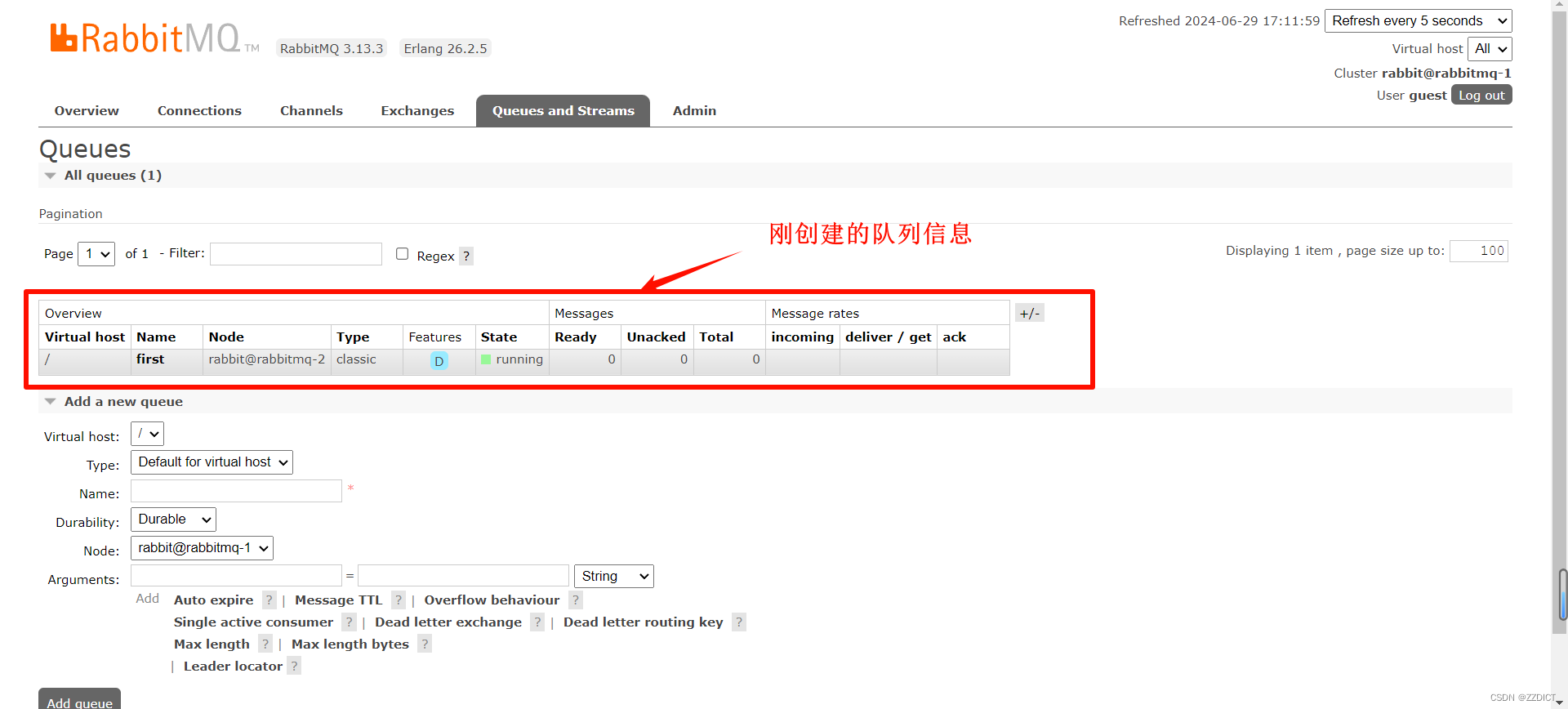
在RabbitMQ集群集群中,必须⾄少有⼀个磁盘节点,否则队列元数据⽆法写⼊到集群中,当
磁盘节点宕掉时,集群将⽆法写⼊新的队列元数据信息。
三. RabbitMQ镜像集群配置
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。 保证各个节点之间数据同步;
1. 创建镜像集群
[root@rabbitmq-1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'参数解释:
rabbitmqctl set_policy:这是RabbitMQ的命令行工具rabbitmqctl中设置策略的命令。
ha-all:这是策略定义的名称,可以为任何你选择的名称,这里选择的是"ha-all"。
"^":这是策略模式,这里的"^"代表这个策略将应用到所有的队列和交换器上。
'{"ha-mode":"all"}':这是策略的定义,这里设置的是ha-mode(高可用模式)为all。这意味着所有的队列将在所有的节点上进行镜像,来提供一个高可用的队列。
"0":这是策略的优先级。如果一个队列同时匹配多个策略,那么优先级高的策略将被使用。这里设置的优先级为0。
for vhost "/":这是策略应用的虚拟主机,这里是应用到了默认的虚拟主机上。
则此时镜像队列设置成功。(这里的虚拟主机是代码中需要用到的虚拟主机,虚拟主机的作用是做一个消息的隔离,本质上可认为是一个rabbitmq-server,是否增加虚拟主机,增加几个,这是由开发中的业务决定,即有哪几类服务,哪些服务用哪一个虚拟主机,这是一个规划)。
再次查看队列已经同步到其他两台节点:
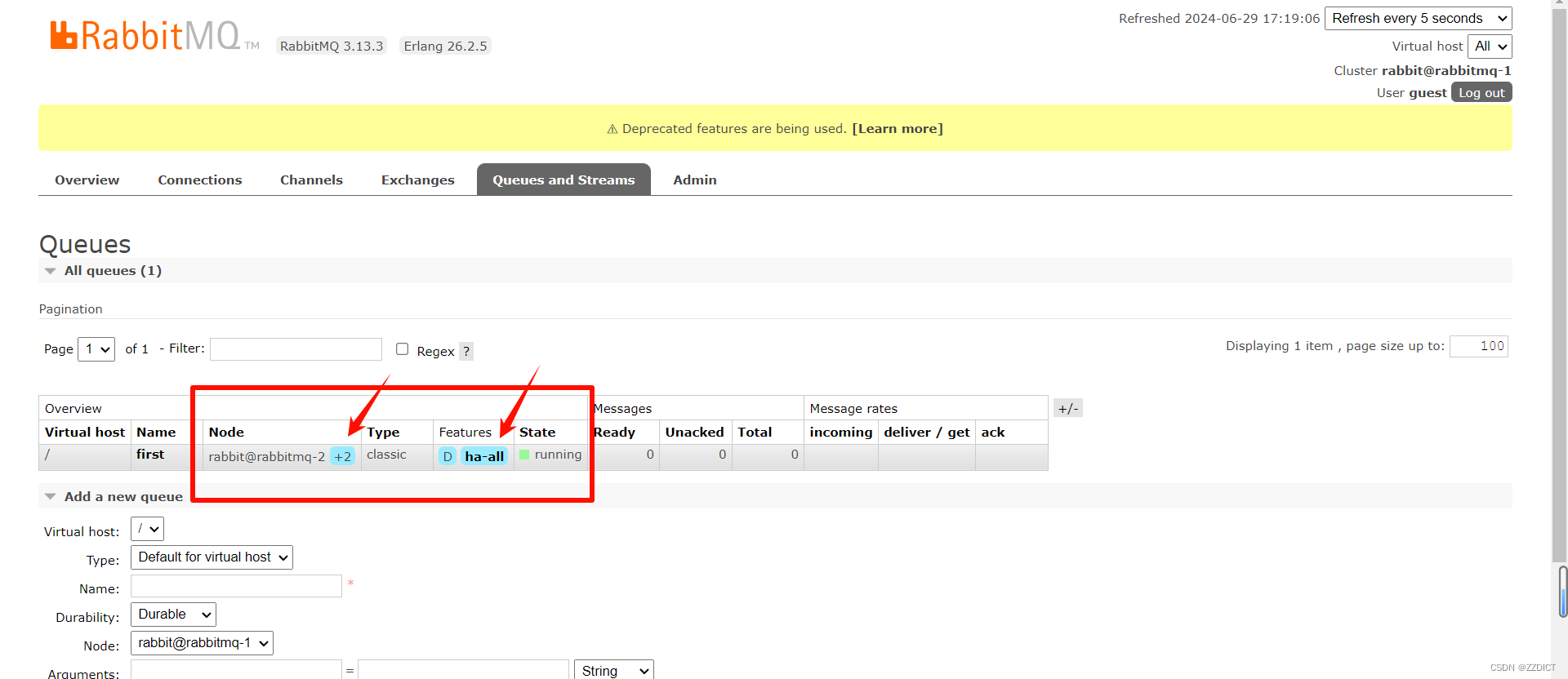
这样就设置完成了
2. 镜像队列策略设置说明
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-modeha-mode:指明镜像队列的模式,有效值为 all/exactly/nodesall:表示在集群中所有的节点上进行镜像exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定ha-params:ha-mode模式需要用到的参数ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级3. 准备测试
#在192.168.226.22上下载一个mysql
[root@rabbitmq-1 ~]# yum install -y mysql-server git unzip
[root@rabbitmq-1 ~]# systemctl enable --now mysqld
[root@rabbitmq-1 ~]# mysqladmin -uroot password "1234"[root@rabbitmq-1 rabbitmq-test]# mysql -uroot -p1234
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 8.0.36 Source distributionCopyright (c) 2000, 2024, Oracle and/or its affiliates.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> CREATE USER 'root'@'%' IDENTIFIED BY '1234';
Query OK, 0 rows affected (0.02 sec)mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
Query OK, 0 rows affected (0.00 sec)mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)mysql> exit
Bye#上传rabbitmq-test-main.zip
[root@rabbitmq-1 ~]# git clone https://gitea.beyourself.org.cn/newrain001/rabbitmq-test.git
[root@rabbitmq-1 ~]# ll
total 18300
-rw-------. 1 root root 815 Jun 6 14:00 anaconda-ks.cfg
-rw-r--r-- 1 root root 18713463 Jun 29 14:28 rabbitmq-server-3.13.3-1.el8.noarch.rpm
-rw-r--r-- 1 root root 8221 Jun 29 16:05 rabbitmq-test-main.zip
-rw-r--r--. 1 root root 4747 Jun 24 19:46 rocky_linux.sh
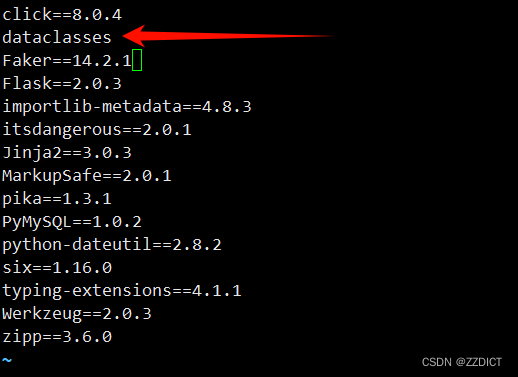
[root@rabbitmq-1 ~]# unzip rabbitmq-test-main.zip[root@rabbitmq-1 ~]# vim rabbitmq-test/requirements.txt
#修改如下图所示,要把版本号去掉,原因是因为当前系统没有这个版本,去掉让其自行安装别的版本即可修改成图中所示即可。
然后视情况修改这个配置文件,改对应的IP,如果对应的IP在本机可以使用localhost不用改,不在本机上的话就必须改,用户名和密码也要改成你自己的。
[root@rabbitmq-1 ~]# vim rabbitmq-test/settings.py 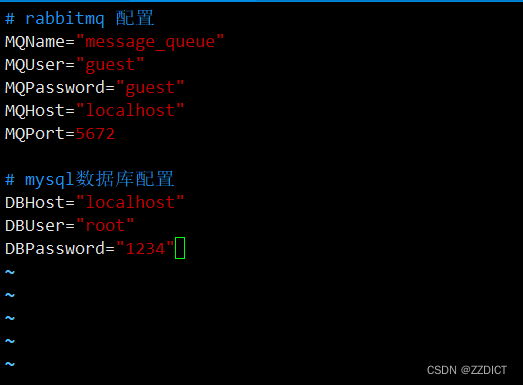
下载工具并启动Flask应用
[root@rabbitmq-1 ~]# yum install -y python3 python3-devel
[root@rabbitmq-1 ~]# pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
[root@rabbitmq-1 ~]# export FLASK_ENV=development ; flask run --reload -p 80 -h 0.0.0.0
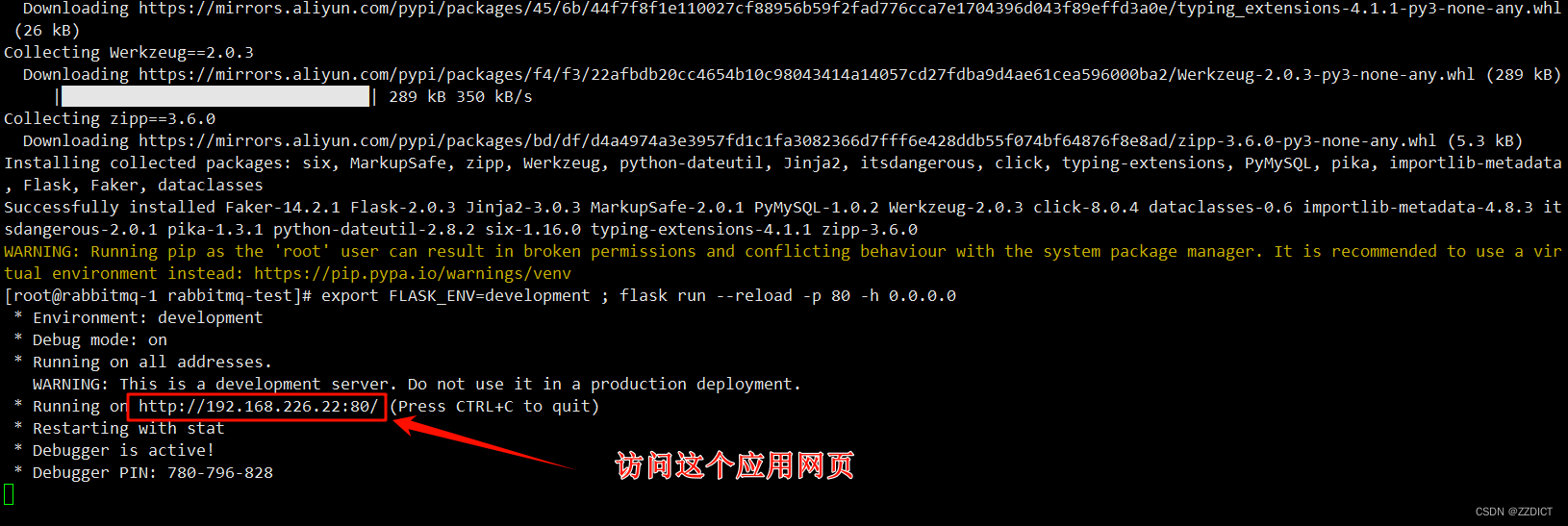
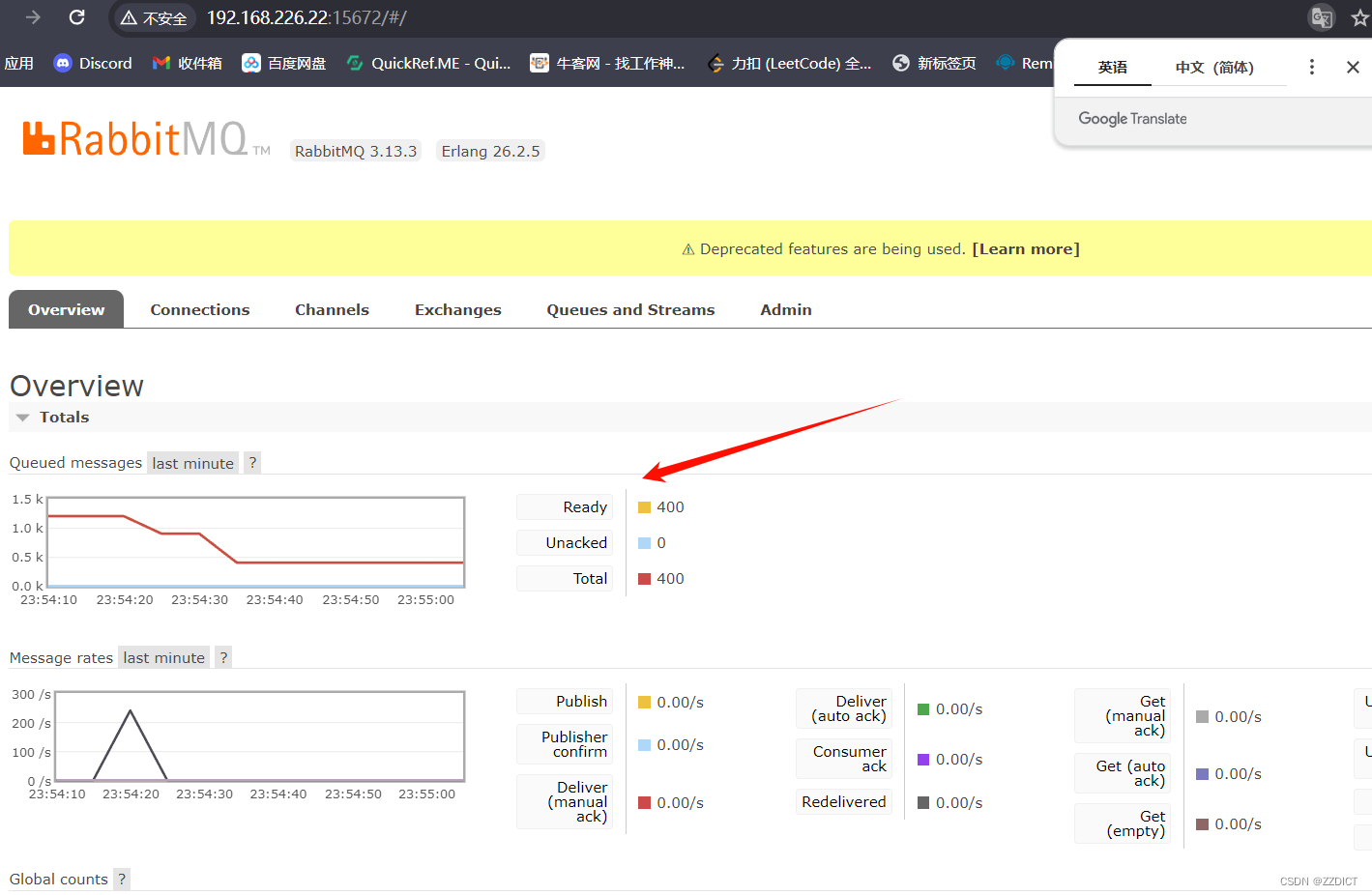
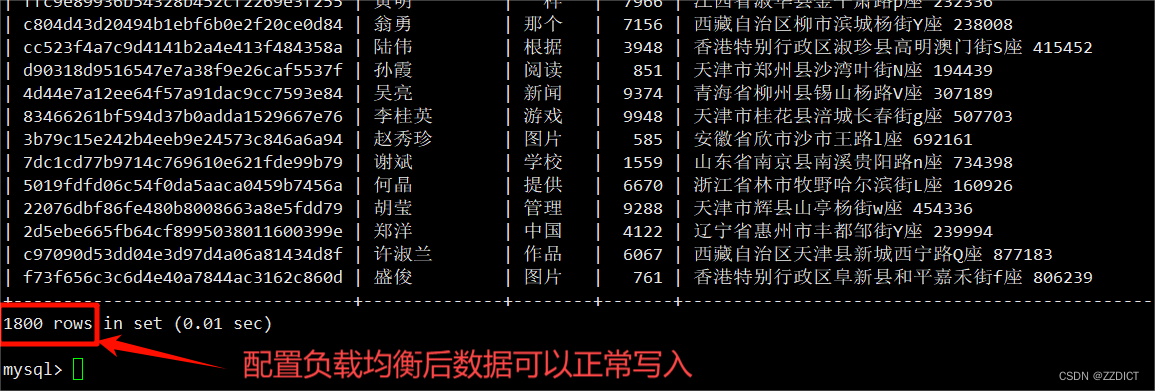
访问框选的web网页,打开后下1000单。
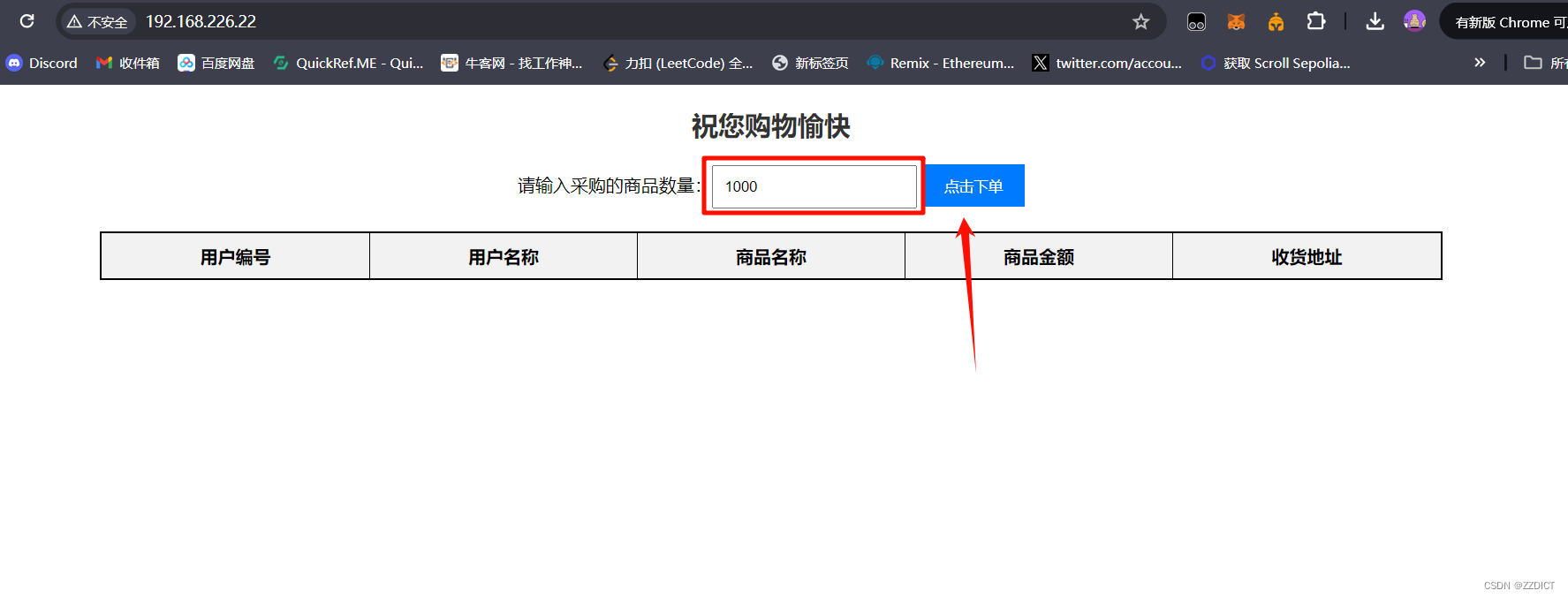
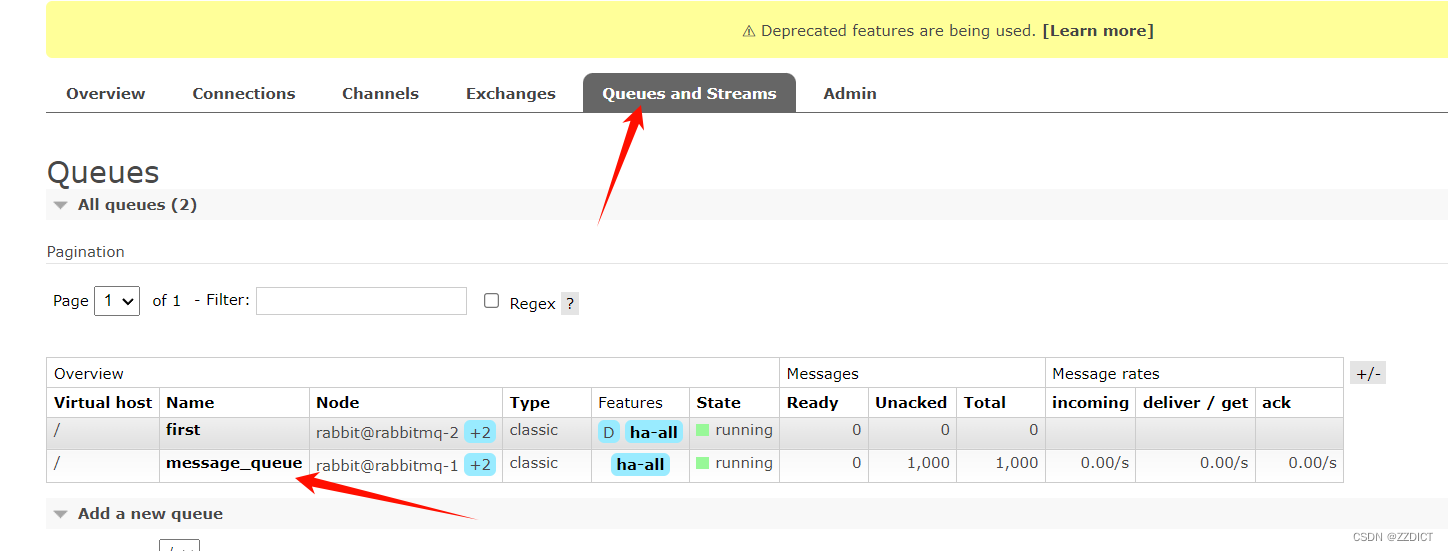
下单后可以看到rabbit mq集群队列中开始记录下单的数据,这时,由于下单但是还没有付费成交,数据并没有写入到数据库中,可以查看下mysql数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
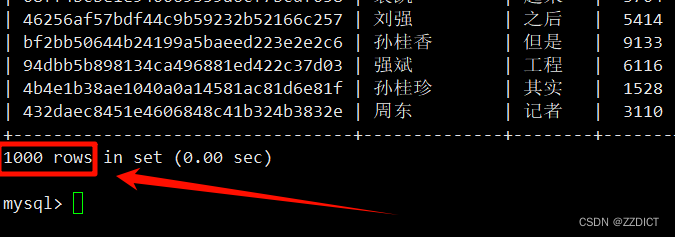
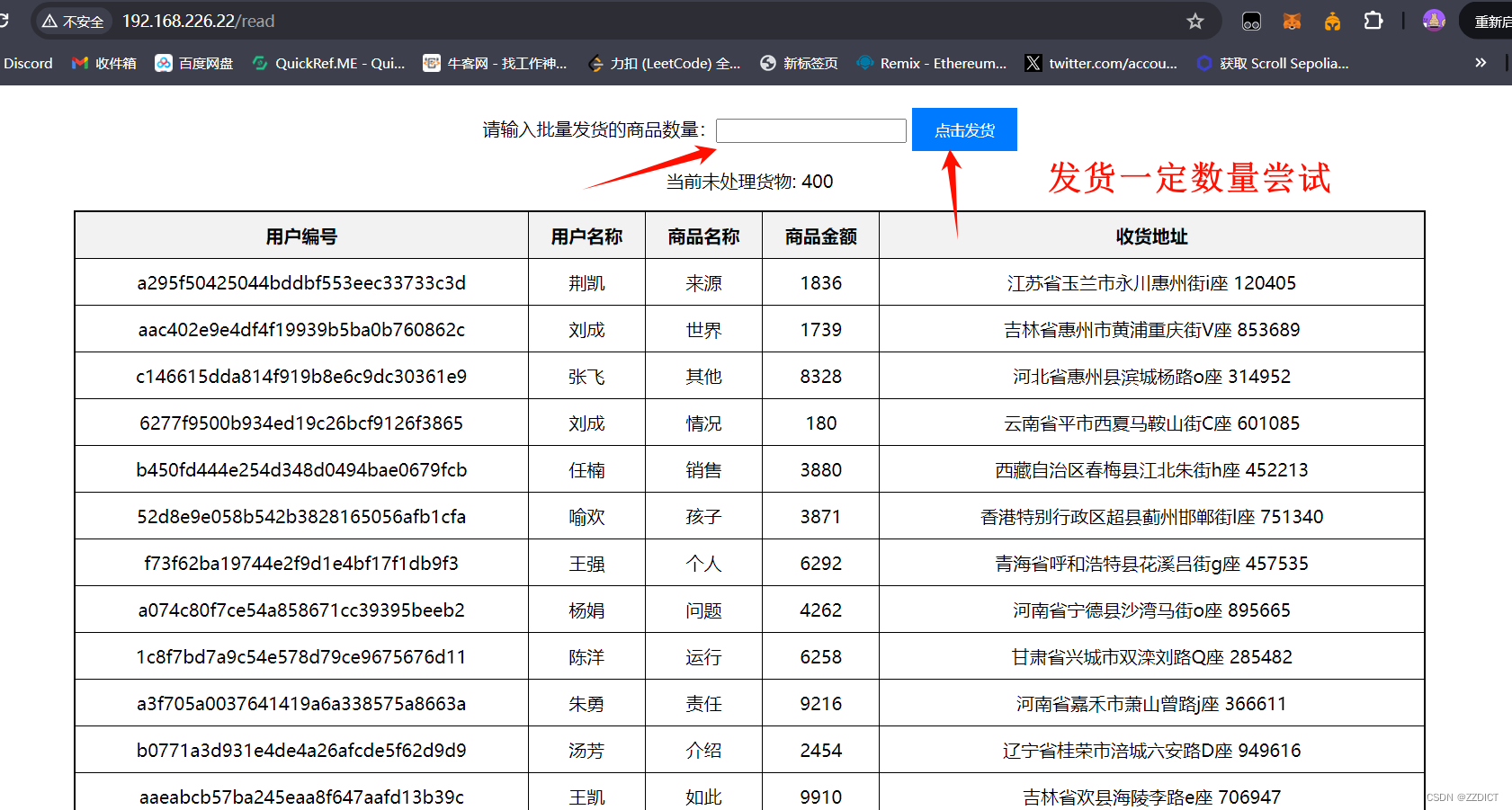
现在模式成交后的数据,来到http://192.168.226.22/read 页面进行模拟成交发货,这时数据就要写入到数据库中。
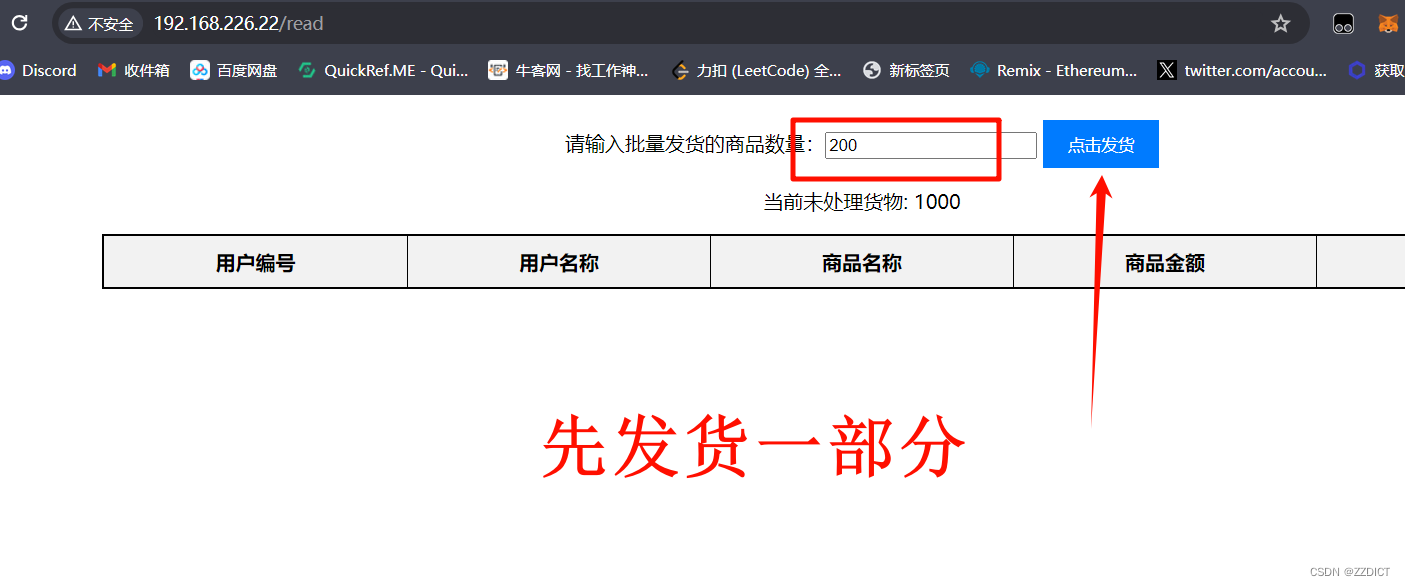
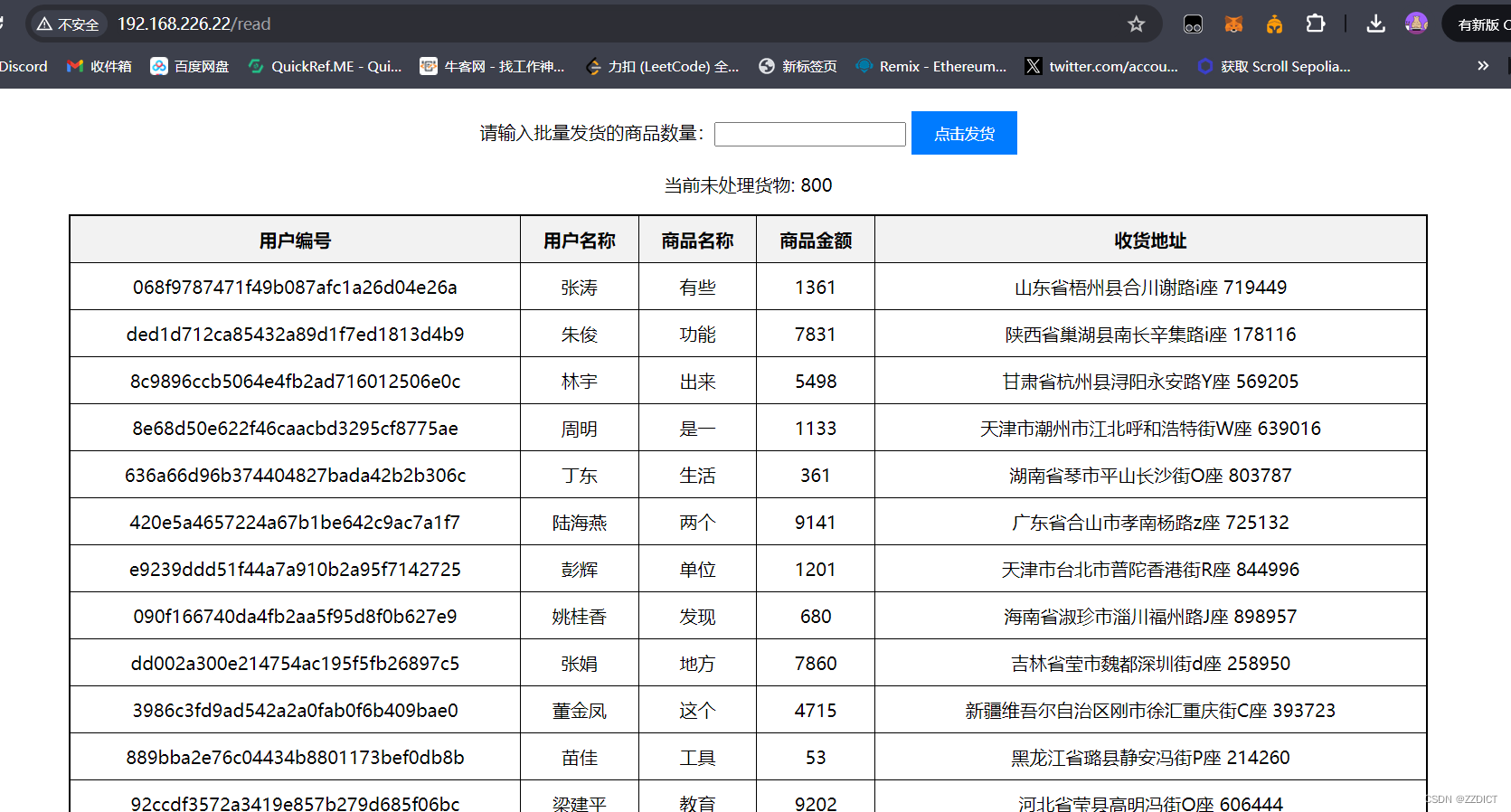
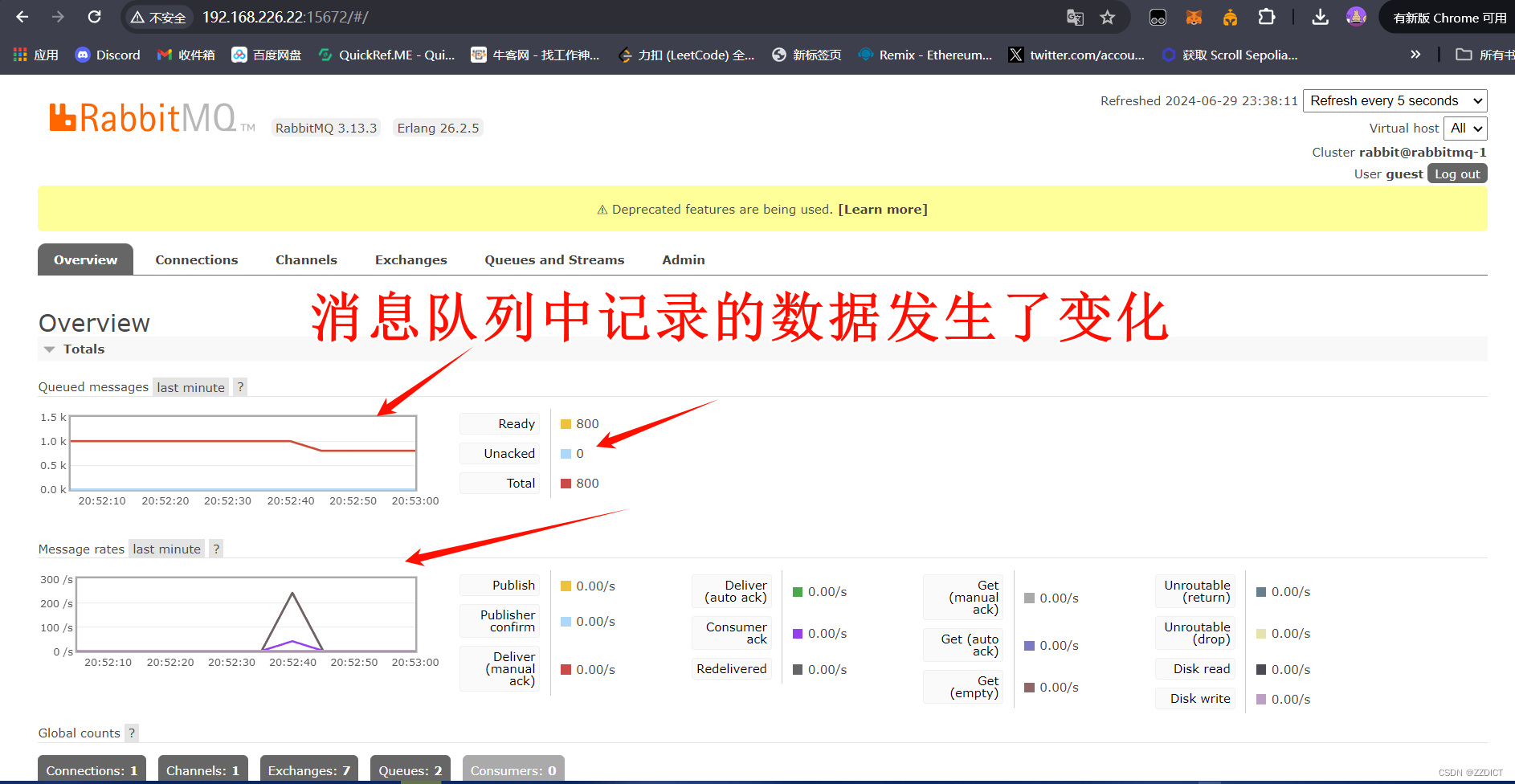
再次查看mysql,发现数据这时才会写入下数据库中,由于前面我们点击发货的是200,也就是模拟正式交易成功的数据数量是200,此时查看这个库中记录也是200
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shop |
| sys |
+--------------------+
5 rows in set (0.00 sec)
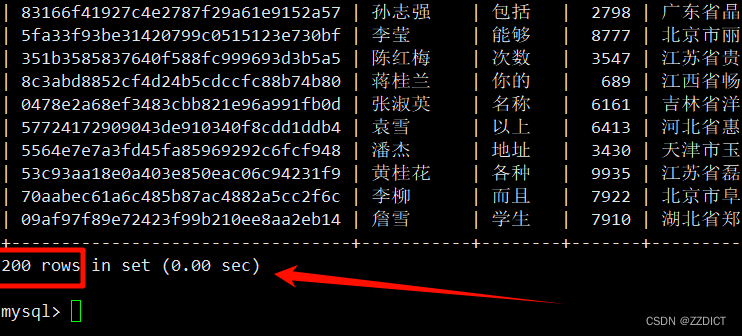
这个时候我们去把剩下的800发完
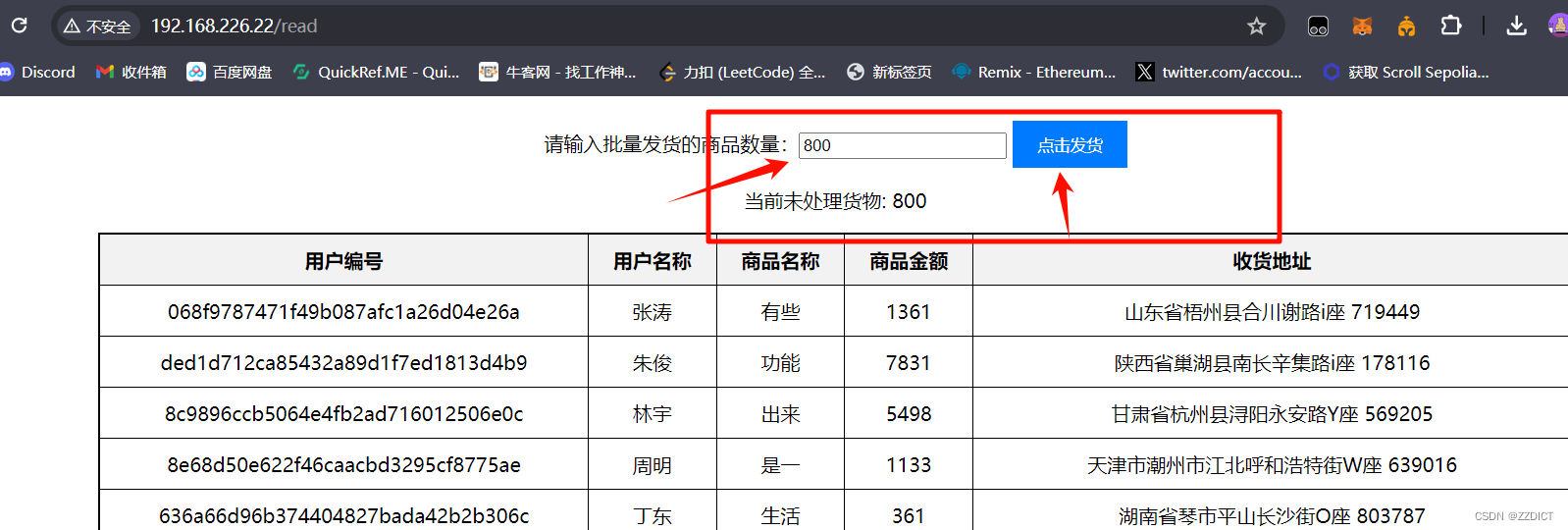
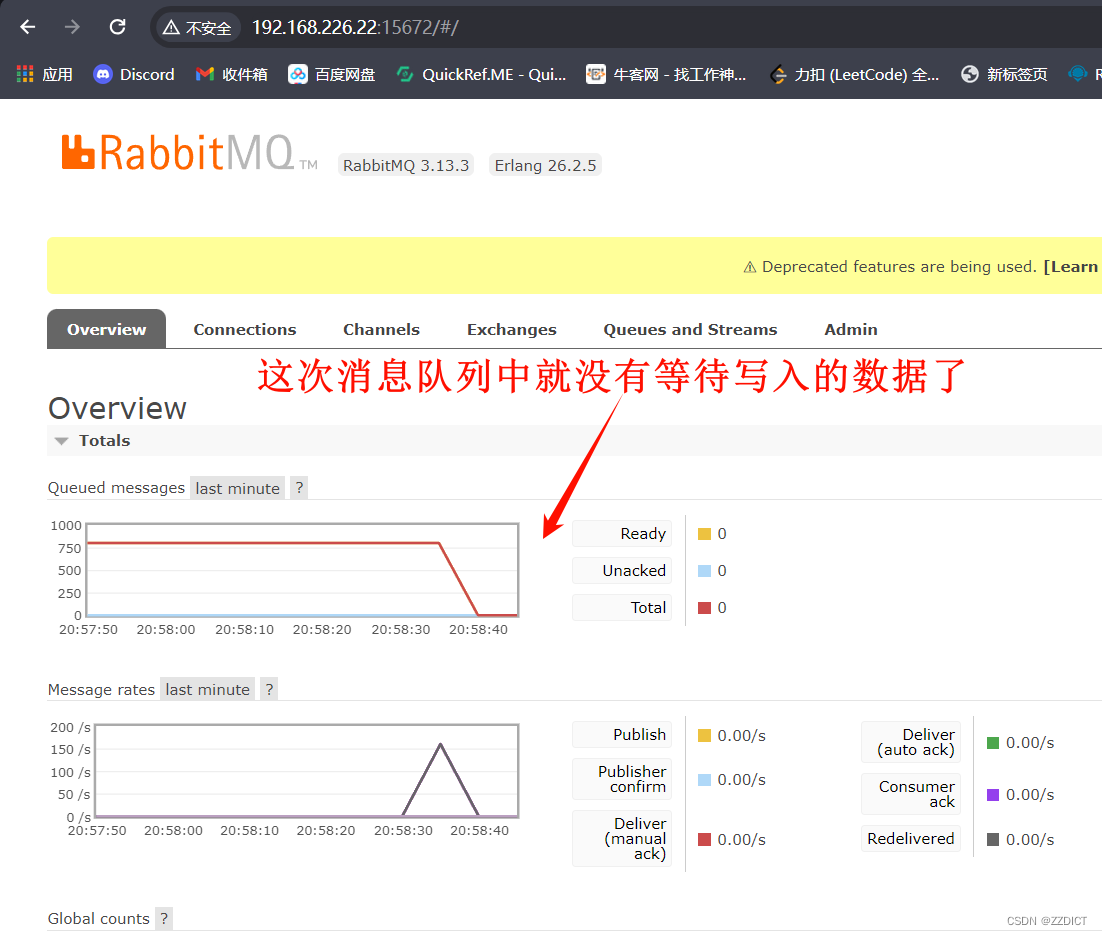
四. 安装并配置负载均衡器HA
注意:如果使用阿里云,可以使用阿里云的内网slb来实现负载均衡,不用自己搭建HA。
新增一个虚拟机进行时间同步,关闭防火墙和selinux
| 主机名 | 系统 | IP | 服务 |
|---|---|---|---|
| haproxy | Rocky_linux | 192.168.226.25 | HAProxy |
#修改主机名
[root@localhost ~]# hostnamectl set-hostname haproxy安装并配置负载均衡器HA
1. 在192.168.226.25安装HAProxy
[root@haproxy ~]# yum install -y haproxy2. 修改 /etc/haproxy/haproxy.cfg
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
在该配置文件,删除其中所有内容,复制下面的配置信息粘贴进去,保存退出,注意你做的需要把最后三行的主机名和IP修改成你对应的主机名和IP
globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxynbproc 4daemon# turn on stats unix socketstats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
defaultsmode httplog globalretries 3timeout connect 10stimeout client 1mtimeout server 1mtimeout check 10smaxconn 2048
#---------------------------------------------------------------------
##监控查看本地状态#####
listen admin_statsbind *:80mode httpoption httplogoption httpcloselog 127.0.0.1 local0 errstats uri /haproxystats auth newrain:123456stats refresh 30s
####################################
###反代监控
frontend serverbind *:5670log globalmode tcp#option forwardfordefault_backend rabbitmqmaxconn 3
backend rabbitmqmode tcplog globalbalance roundrobin
#这里三行配置对应的主机名和IP需要改成你对应的server rabbitmq-1 192.168.226.22:5672 check inter 2000s rise 2 fall 3 server rabbitmq-2 192.168.226.23:5672 check inter 2000s rise 2 fall 3server rabbitmq-3 192.168.226.24:5672 check inter 2000s rise 2 fall 3#启动haproxy并设置开机自启
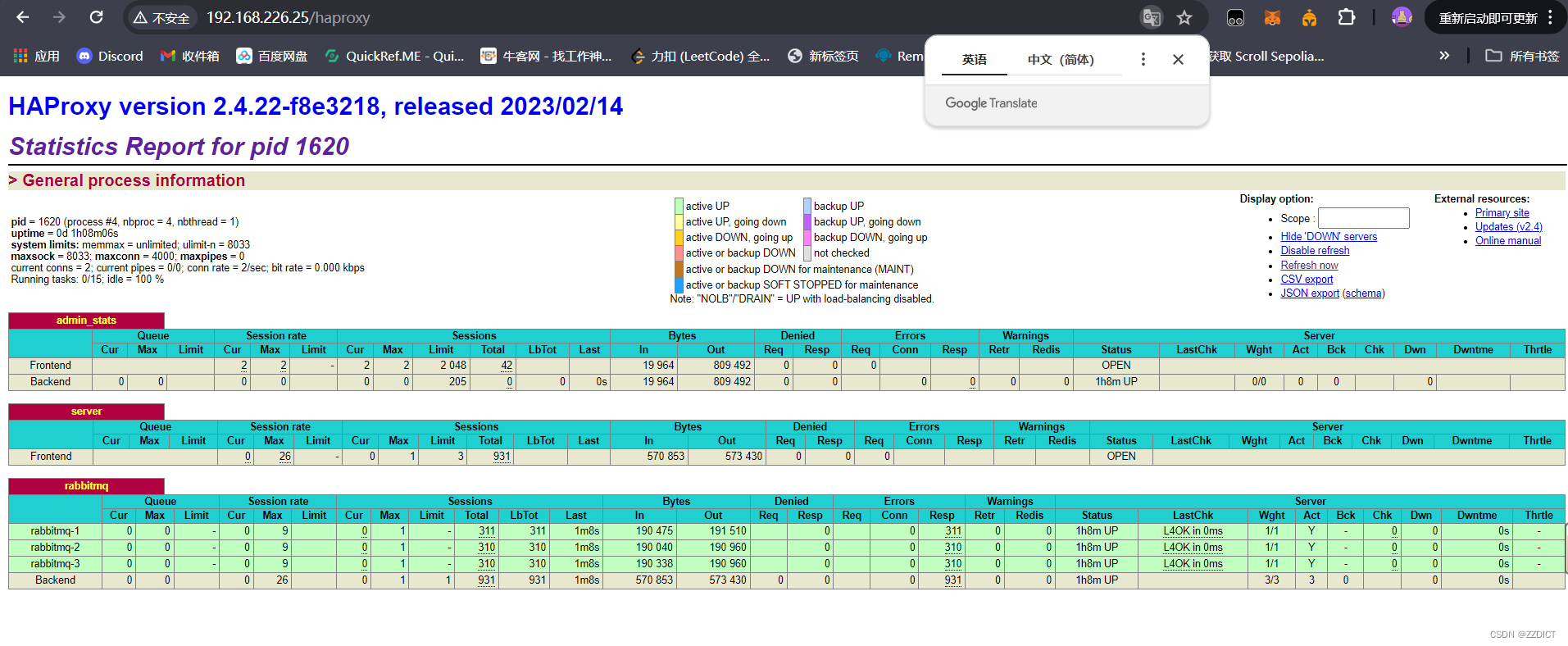
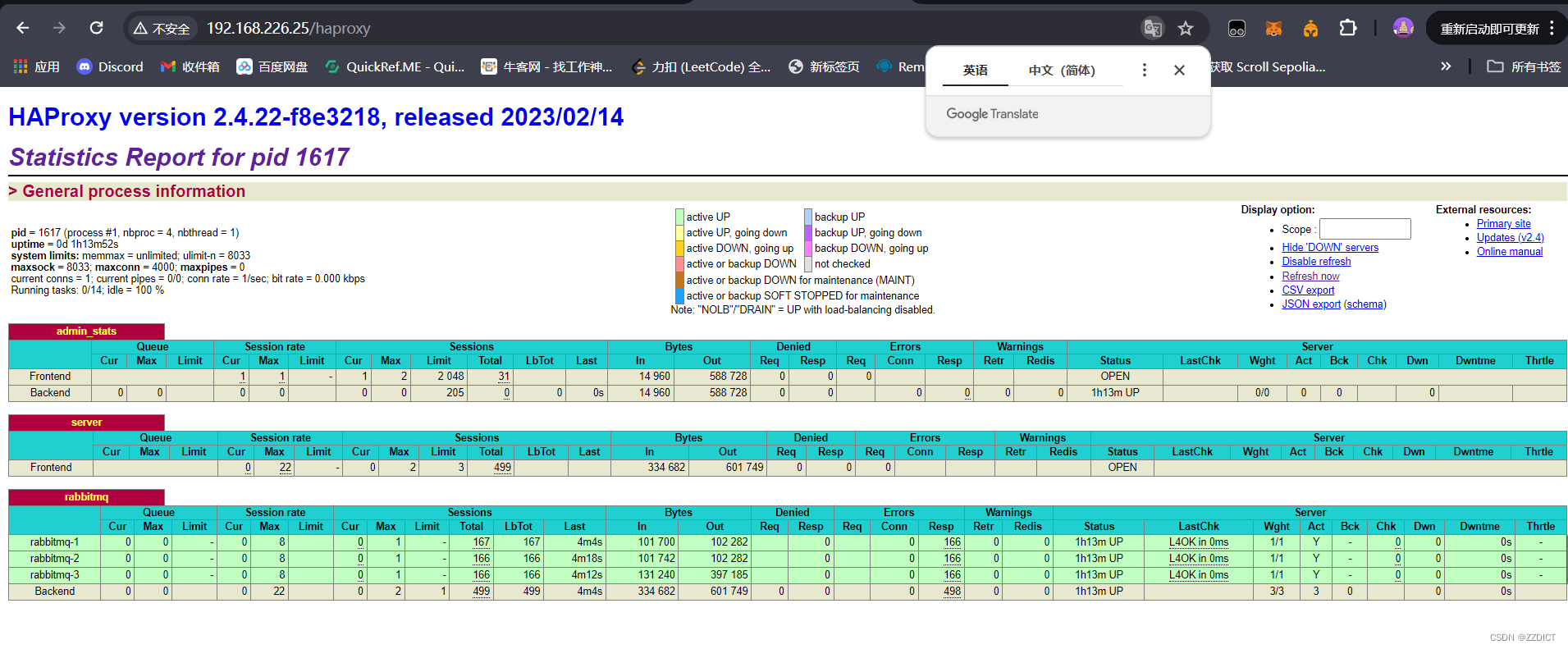
[root@haproxy ~]# systemctl enable --now haproxy浏览器输入http://192.168.226.25/haproxy查看rabbitmq的状态。
访问该页面的初始用户名:newrain 密码:123456
这个用户名和密码是在上面配置文件定义的。
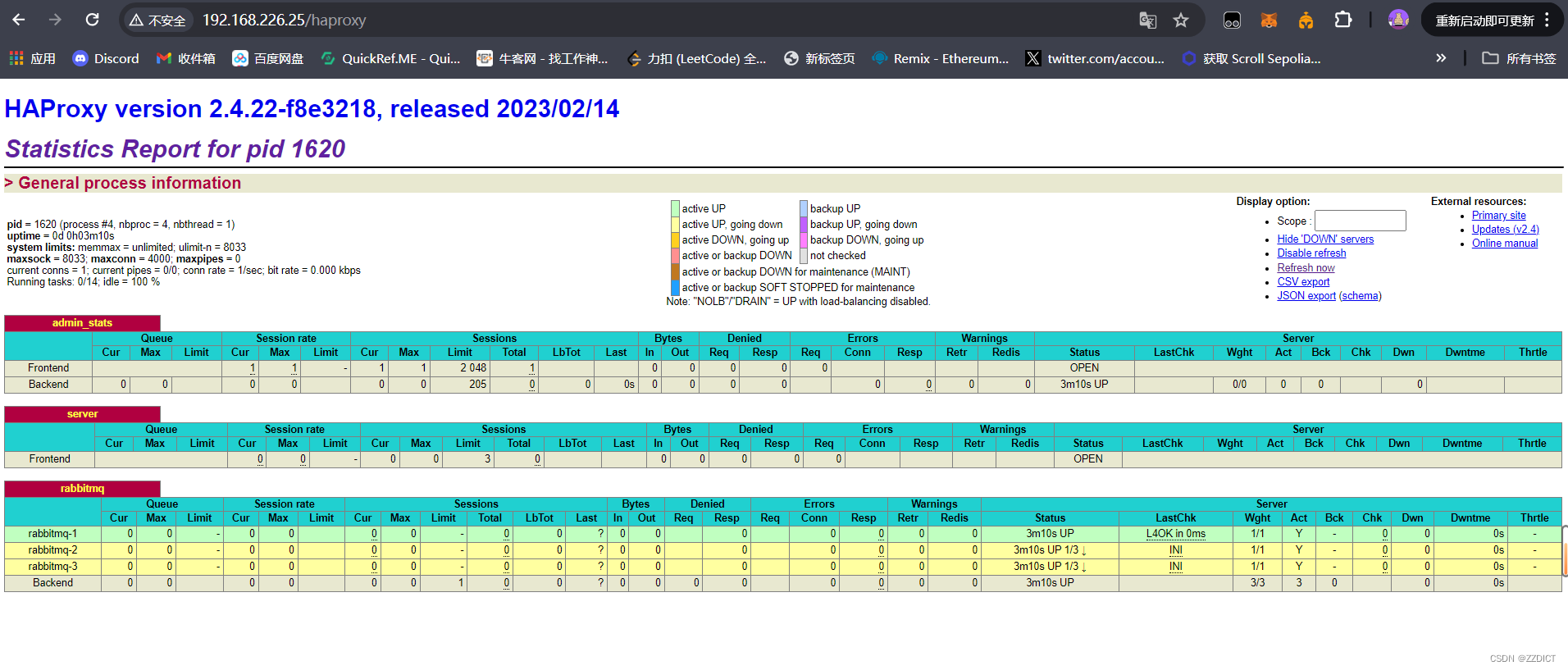
现在重新配置Flask应用的配置,改成负载均衡的IP,端口也改成负载均衡监听的端口,然后换个队列名实验。
[root@rabbitmq-1 ~]# vim rabbitmq-test/settings.py 
需要先把前面启动的flask应用ctrl + c 关掉再启动
[root@rabbitmq-1 ~]# cd rabbitmq-test
[root@rabbitmq-1 rabbitmq-test]# flask run --reload -p 80 -h 0.0.0.0http://192.168.226.22:80/ 再次访问下单也,看能否正常下单
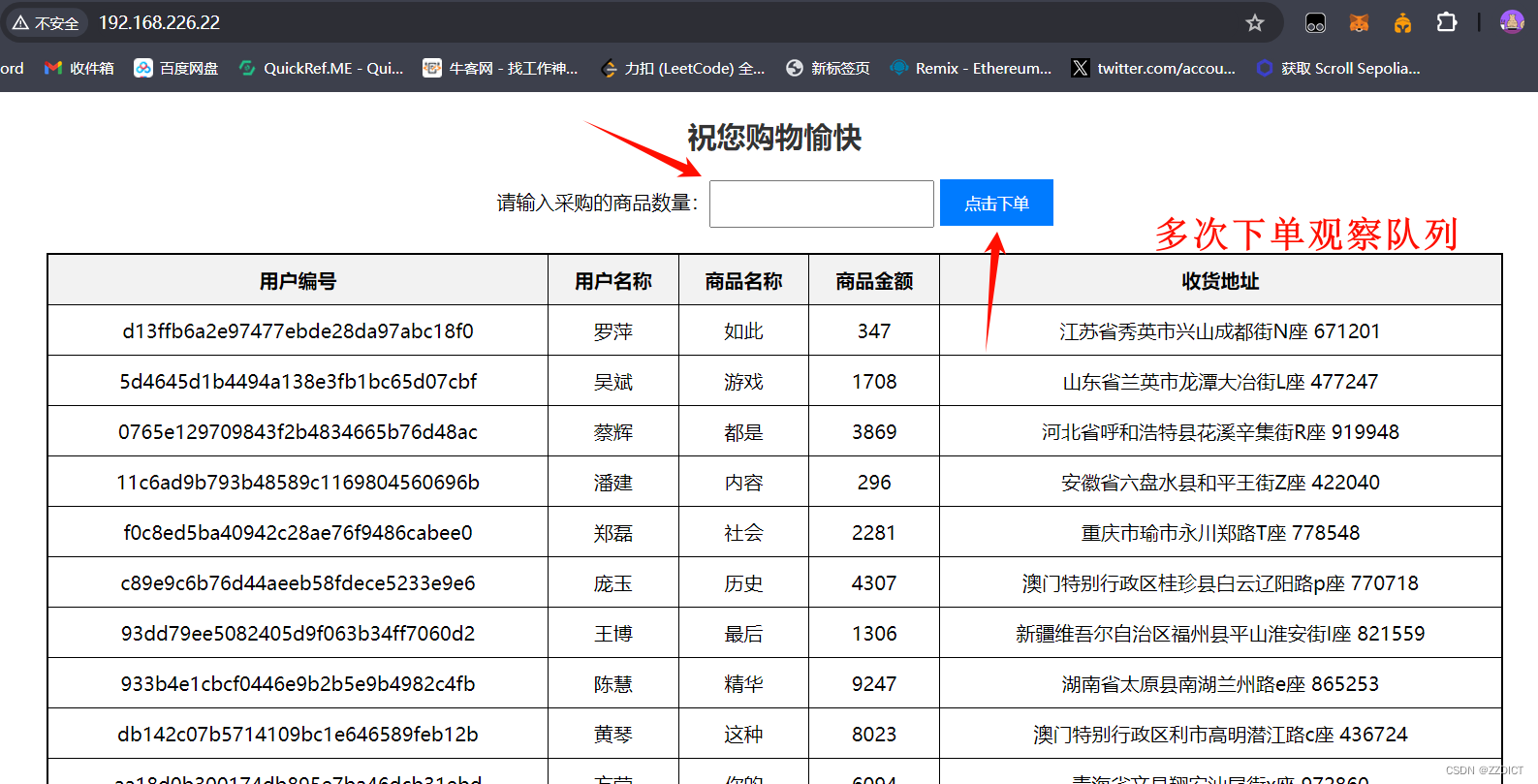
负载均衡监控页面也在数据变化正常工作
现在开始模拟正式成交订单时数据写入数据库
http://192.168.226.22/read
查看mysql数据写入记录
相关文章:
普通集群与镜像集群配置
目录 一. 环境准备 二. 开始配置集群 三. RabbitMQ镜像集群配置 四. 安装并配置负载均衡器HA 一. 环境准备 关闭防火墙和selinux,进行时间同步 主机名系统IP服务rabbitmq-1 Rocky_linux9.4 192.168.226.22RabbitMQ,MySQLrabbitmq-2Rocky_linux9.41…...
2024科技文化节程序设计竞赛
补题链接 https://www.luogu.com.cn/contest/178895#problems A. 签到题 忽略掉大小为1的环,答案是剩下环的大小和减环的数量 #include<bits/stdc.h> #include<iostream> #include<cstdio> #include<vector> #include<map> #incl…...

玩转Easysearch语法
Elasticsearch 是一个基于Apache Lucene的开源分布式搜索和分析引擎,广泛应用于全文搜索、结构化搜索、分析等多种场景。 Easysearch 作为Elasticsearch 的国产化替代方案,不仅保持了与原生Elasticsearch 的高度兼容性,还在功能、性能、稳定性…...

【密码学】RSA公钥加密算法
文章目录 RSA定义RSA加密与解密加密解密 生成密钥对一个例子密钥对生成加密解密 对RSA的攻击通过密文来求得明文通过暴力破解来找出D通过E和N求出D对N进行质因数分解通过推测p和q进行攻击 中间人攻击 一些思考公钥密码比对称密码的机密性更高?对称密码会消失&#x…...

【ARMv8/v9 GIC 系列 5.1 -- GIC GICD_CTRL Enable 1 of N Wakeup Function】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 GIC Enable 1 of N Wakeup Function基本原理工作机制配置方式应用场景小结GIC Enable 1 of N Wakeup Function 在ARM GICv3(Generic Interrupt Controller第三代)规范中,引入了一个名为"Enable 1 of N Wakeup"的功能。…...

C++怎么解决不支持字符串枚举?
首先,有两种方法:使用命名空间和字符串常量与使用 enum class 和辅助函数。 表格直观展示 特性使用命名空间和字符串常量使用 enum class 和辅助函数类型安全性低 - 编译器无法检查字符串有效性,运行时发现错误高 - 编译期类型检查…...
)
中英双语介绍四大会计师事务所(Big Four accounting firms)
中文版 “四大会计师事务所”(Big Four accounting firms)是全球最具影响力和规模最大的四家专业服务公司,它们在审计、税务、咨询和财务咨询等领域占据着主导地位。这四家公司分别是普华永道(PwC)、德勤(…...

ubuntu 查看联网配置
在Ubuntu中,你可以使用多种命令来查看联网配置。以下是一些常用的方法和命令: 查看网络接口配置: 使用 ip 命令可以查看网络接口的配置信息,包括IP地址、子网掩码等。 ip addr show或者,你也可以使用传统的 ifconfig 命…...

【数据分享】全国乡村旅游重点镇(乡)数据(Excel/Shp格式/免费获取)
之前我们分享过从我国文化和旅游部官网整理的2018-2023年我国50个重点旅游城市星级饭店季度经营状况数据(可查看之前发布的文章)!文化和旅游部官网上也分享有很多与旅游相关的常用数据,我们基于官网发布的名单文件整理得到全国乡村…...

停车场小程序的设计
管理员账户功能包括:系统首页,个人中心,车主管理,商家管理,停车场信息管理,预约停车管理,商场收费管理,留言板管理 微信端账号功能包括:系统首页,停车场信息…...
绿色金融相关数据合集(2007-2024年 具体看数据类型)
数据类型: 1.绿色债券数据:2014-2023 2.绿色信贷相关数据:2007-2022 3.全国各省及地级市绿色金融指数:1990-2022 4.碳排放权交易明细数据:2013-2024 5.绿色金融试点DID数据:2010-2023 数据来源&#…...

【matlab 项目工期优化】基于NSGA2/3的项目工期多目标优化(时间-成本-质量-安全)
一 背景介绍 本文分享了一个通用的项目工期优化的案例,决策变量是每个子项目的工期,优化目标是项目的完成时间最小,项目的总成本现值最小,项目的总安全水平最高,项目的总质量水平最高。采用的算法是NSGA2和NSGA3算法。…...

Python考前复习
选择题易错: python3不能完全兼容python2内置函数是python的内置对象之一,无需导入其他模块python中汉字变量合法,如“小李123”合法;但T-C不合法,因为有“-”集合无顺序,不能索引;range(5)[2]…...

虚拟机交叉编译基于ARM平台的opencv(ffmpeg/x264)
背景: 由于手上有一块rk3568的开发板,需要运行yolov5跑深度学习模型,但是原有的opencv不能对x264格式的视频进行解码,这里就需要将ffmpegx264编译进opencv。 但是开发板算力有限,所以这里采用在windows下,安…...

react之错误边界
错误边界实质是指什么 实际上是组件 错误边界捕获什么时候的错误 在渲染阶段的错误 错误边界捕获的是谁的错误 捕获的是子组件的错误 错误边界不能捕获什么错误 1、不能捕获异步代码 2、不能捕获事件处理函数 3、不能捕获服务端渲染 4、不能捕获自身抛出的错误 错误…...

openEuler系统之使用Keepalived+Nginx部署高可用Web集群
Linux系统之使用Keepalived+Nginx部署高可用Web集群 一、本次实践介绍1.1 本次实践简介1.2 本次实践环境规划二、keepalived介绍2.1 keepalived简介2.2 keepalived主要特点和功能2.3 使用场景三、Keepalived和Nginx介绍3.1 Nginx简介3.2 Nginx特点四、master节点安装nginx4.1 安…...

基于图像处理的滑块验证码匹配技术
滑块验证码是一种常见的验证码形式,通过拖动滑块与背景图像中的缺口进行匹配,验证用户是否为真人。本文将详细介绍基于图像处理的滑块验证码匹配技术,并提供优化代码以提高滑块位置偏移量的准确度,尤其是在背景图滑块阴影较浅的情…...

【JavaEE精炼宝库】文件操作(1)——基本知识 | 操作文件——打开实用性编程的大门
目录 一、文件的基本知识1.1 文件的基本概念:1.2 树型结构组织和目录:1.3 文件路径(Path):1.4 二进制文件 VS 文本文件:1.5 其它: 二、Java 操作文件2.1 方法说明:2.2 使用演示&…...

常用排序算法_06_归并排序
1、基本思想 归并排序采用分治法 (Divide and Conquer) 的一个非常典型的应。归并排序的思想就是先递归分解数组,再合并数组。归并排序是一种稳定的排序方法。 将数组分解最小之后(数组中只有一个元素,数组有序);然后…...
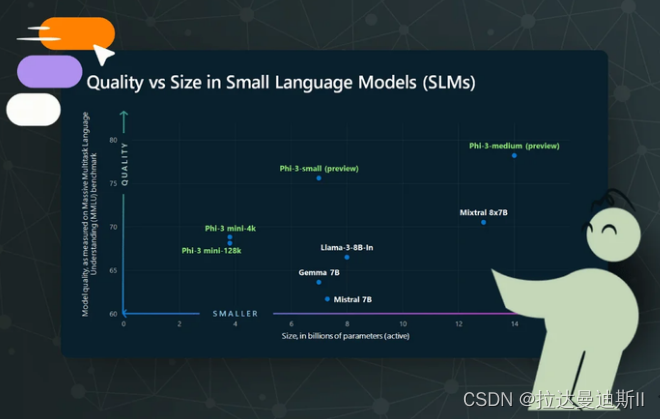
14-8 小型语言模型的兴起
过去几年,我们看到人工智能能力呈爆炸式增长,其中很大一部分是由大型语言模型 (LLM) 的进步推动的。GPT-3 等模型包含 1750 亿个参数,已经展示了生成类似人类的文本、回答问题、总结文档等能力。然而,虽然 LLM 的能力令人印象深刻…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...