Python基础问题汇总
为什么学习Python?
- 易学易用:Python语法简洁清晰,易于学习。
- 广泛的应用领域:适用于Web开发、数据科学、人工智能、自动化脚本等多种场景。
- 强大的库支持:拥有丰富的第三方库,如NumPy、Pandas、TensorFlow等。
- 跨平台:可在多种操作系统上运行。
- 社区支持:拥有活跃的开发者社区,易于获取帮助和资源。
通过什么途径学习的Python?
- 在线教程和课程:如Coursera、edX、Udemy等平台提供的Python课程。
- 书籍:入门书籍如《Python Crash Course》和《Automate the Boring Stuff with Python》。
- 官方文档:Python官方文档是学习标准库和语言特性的宝贵资源。
- 实践项目:通过实际编写代码和参与项目来学习。
- 社区和论坛:Stack Overflow、Reddit等社区可以提供帮助和交流。
Python和其他语言的对比?
- Java:编译型语言,性能较高,适用于大型企业级应用,语法相对复杂。
- PHP:主要用作服务器端脚本语言,适合Web开发,但应用范围相对有限。
- C:底层语言,性能高,但语法复杂,没有面向对象的特性。
- C#:由微软开发,主要用于Windows平台,支持.NET框架,适用于企业应用。
- C++:支持面向对象编程,性能优异,但学习曲线陡峭。
解释型和编译型编程语言?
- 解释型语言:代码在运行时逐行解释执行,通常不需要编译,如Python和JavaScript。
- 编译型语言:代码在执行前需要被编译成机器语言,如C、C++和Java。
Python解释器种类以及特点?
- CPython:官方Python解释器,使用C语言编写。
- Jython:运行在Java平台上的Python解释器,使用Java语言编写。
- IronPython:.NET平台上的Python实现,使用C#和VB编写。
- PyPy:使用即时编译(JIT)技术的Python解释器,可以提供更快的执行速度。
位和字节的关系?
- 1字节(Byte)= 8位(bit)。
b、B、KB、MB、GB 的关系?
- 1B(Byte)= 8b(bit)
- 1KB(千字节)= 1024B
- 1MB(兆字节)= 1024KB
- 1GB(吉字节)= 1024MB
PEP8 规范
- Indentation: 使用4个空格进行缩进。
- Line length: 每行不超过79个字符,确保代码可读性。
- Blank lines: 逻辑上相关的代码块之间使用空行分隔。
- Imports: 每个导入应该独占一行,并且分组顺序通常是:标准库导入、相关第三方导入、本地应用/库特定导入。
- Variable names: 变量名使用小写字母和下划线分隔。
- Function names: 函数名同样使用小写字母和下划线。
- Class names: 类名使用首字母大写的驼峰式命名。
- Underscores: 单下划线(_)前缀用于受保护的实例属性和方法,双下划线(__)前缀用于私有属性和方法。
- Documentation strings: 为每个模块、函数、类和方法提供文档字符串。
代码实现转换:
# 二进制转十进制
v_bin_to_dec = int("0b1111011", 2)# 十进制转二进制
v_dec_to_bin = bin(18)[2:]# 八进制转十进制
v_oct_to_dec = int("011", 8)# 十进制转八进制
v_dec_to_oct = oct(30)[2:]# 十六进制转十进制
v_hex_to_dec = int("0x12", 16)# 十进制转十六进制
v_dec_to_hex = hex(87)[2:]print(f"二进制转十进制: {v_bin_to_dec}")
print(f"十进制转二进制: {v_dec_to_bin}")
print(f"八进制转十进制: {v_oct_to_dec}")
print(f"十进制转八进制: {v_dec_to_oct}")
print(f"十六进制转十进制: {v_hex_to_dec}")
print(f"十进制转十六进制: {v_dec_to_hex}")IP地址转整数:
def ip_to_int(ip_address):parts = ip_address.split('.')integer = 0for part in parts:integer = integer * 256 + int(part)return integer# 示例
ip_address = "10.3.9.12"
print(f"IP地址 {ip_address} 转换成整数为: {ip_to_int(ip_address)}")这段代码将IP地址的每个部分转换为整数,并按照二进制的字节顺序拼接起来,计算最终的十进制整数。
Python递归的最大层数?
Python中递归的最大层数默认是1000,但可以通过sys模块的setrecursionlimit函数进行调整。
求逻辑运算结果:
v1 = 1 or 3的结果是3(在Python中非0即真)。v2 = 1 and 3的结果是1(在Python中and操作符会返回第一个假值,1是真值)。v3 = 0 and 2 and 1的结果是0(and操作符会从左到右计算,遇到第一个假值停止计算)。v4 = 0 and 2 or 1的结果是1(and操作符在第一个操作数为假时停止计算,or操作符会返回第一个真值)。v5 = 0 and 2 or 1 or 4的结果是1(同上,0为假,2和1为真,4也是真,但or操作符在遇到第一个真值时停止)。v6 = 0 or False and 1的结果是0(or操作符从左到右计算,and操作符在第一个操作数为假时停止计算)。
ASCII、Unicode、UTF-8、GBK的区别?
- ASCII:最早的字符编码标准,使用7位编码,能表示128个字符,只能表示英文字符。
- Unicode:一种国际标准,使用更多的位来编码世界上大多数语言的字符,可以看作是字符的"字典"。
- UTF-8:Unicode的一种实现方式,是一种变长编码,英文字符使用1字节,其他语言可能使用2-4字节。
- GBK:主要用于简体中文的字符编码,是GB2312的扩展,使用双字节编码。
字节码和机器码的区别?
- 字节码:是源代码编译后的中间形式,是一种与平台无关的代码,可以在虚拟机上运行。
- 机器码:是编译器将源代码转换成的二进制指令,是CPU可以直接执行的代码,与特定硬件平台相关。
三元运算规则以及应用场景?
三元运算符是Python中的一种简洁的条件表达式,格式为:a if condition else b。当条件condition为真时,表达式的结果为a,否则为b。常用于简单的条件赋值。
Python 2和Python 3的区别?
- print语句:Python 3中
print是一个函数,需要括号。 - 整数除法:Python 3中的除法
/总是返回浮点数,Python 2中返回整数。 - Unicode:Python 3默认字符串为Unicode,Python 2默认为ASCII。
- 迭代器:Python 3中
range返回迭代器,Python 2返回列表。 - 异常链:Python 3中使用
raise X from Y来链式异常,Python 2中没有这个语法。
一行代码实现数值交换:
a, b = b, a
Python 3和Python 2中int和long的区别?
- 在Python 2中,
int是有固定大小的整数,long是无限大小的整数。 - Python 3中,
long类型被移除,所有的整数都是int类型,且int类型可以是任意大小。
xrange和range的区别?
xrange是Python 2中的一个函数,它返回一个迭代器,逐个产生数值,节省内存。range在Python 2中返回一个列表,在Python 3中返回一个与xrange类似的迭代器。
文件操作时xreadlines和readlines的区别?
xreadlines是Python 2中的一个方法,用于返回文件的所有行的迭代器。readlines在Python 2中读取整个文件内容到一个列表中,可能会消耗大量内存。- 在Python 3中,
xreadlines不存在,readlines保持与Python 2中的readlines相同的行为。
Python 3鼓励使用上下文管理器(with语句)来处理文件操作,它可以自动关闭文件,同时提供迭代文件行的能力。
布尔值为False的常见值:
None- 任何数值类型的零值:
0,0.0,0j - 空集合:
(),[],{},set() - 空字符串:
"",'',b''
字符串常用方法:
str.lower(): 转换为小写。str.upper(): 转换为大写。str.strip(): 移除首尾空白字符。str.split(sep=None): 按照分隔符分隔字符串。str.join(iterable): 将序列中的元素以字符串连接生成一个新的字符串。
列表常用方法:
list.append(x): 在列表末尾添加元素x。list.extend(iterable): 在列表末尾一次性追加多个元素。list.insert(i, x): 在指定位置i插入元素x。list.remove(x): 移除列表中的元素x。list.pop([i]): 移除列表中的一个元素(默认最后一个),并返回该元素。
元组常用方法:
tuple.count(x): 统计元素x在元组中出现的次数。tuple.index(x): 返回元素x在元组中首次出现的索引。tuple + tuple: 连接两个元组。element in tuple: 检查元素是否在元组中。tuple * n: 将元组复制n次。
字典常用方法:
dict.get(key, default=None): 获取指定键的值,如果不存在返回默认值。dict.keys(): 返回字典中所有的键。dict.values(): 返回字典中所有的值。dict.items(): 返回字典中所有的键值对。dict.update(other): 将另一个字典的键值对更新到当前字典。
lambda表达式格式以及应用场景:
格式:lambda arguments: expression 应用场景:通常用在需要简单函数对象的地方,如map(), filter(), sorted()函数中。
pass的作用:
pass是一个空操作符,不做任何事情。它用在语法上需要一个语句但程序逻辑不需要任何操作的地方。
*args和**kwargs作用:
*args:可变位置参数,允许你传递任意数量的位置参数给函数。**kwargs:可变关键字参数,允许你传递任意数量的命名参数给函数。
is和==的区别:
is:检查两个引用是否指向同一个对象。==:比较两个值是否相等。
Python的深浅拷贝以及应用场景:
- 浅拷贝:创建一个新集合,添加原始集合中对象的引用。适用于拷贝引用不可变类型或需要保持原始对象和拷贝对象间引用关系的场景。
- 深拷贝:创建原始对象的副本,不共享原始对象中的任何引用。适用于拷贝可变类型或需要完全独立的对象副本的场景。
Python垃圾回收机制:
Python使用引用计数和标记-清除机制进行垃圾回收。引用计数为0的对象会被垃圾收集器回收。标记-清除机制用于处理循环引用。
Python的可变类型和不可变类型:
- 可变类型:对象的内容可以改变,如列表、字典、集合。
- 不可变类型:对象的内容不能改变,如整数、浮点数、字符串、元组。
求结果:
v = dict.fromkeys(['k1', 'k2'], [])
v['k1'].append(666)
print(v) # 输出: {'k1': [666], 'k2': []}
v['k1'] = 777
print(v) # 输出: {'k1': 777, 'k2': []}在这个例子中,fromkeys创建了一个字典,其中的键是列表['k1', 'k2']中的元素,初始值是空列表[]。然后,向'k1'的值(一个空列表)中添加了666,之后将'k1'的值替换为777。
常见的内置函数:
abs(x): 返回x的绝对值。all(iterable): 如果iterable中的所有元素都为真,则返回True。any(iterable): 如果iterable中至少有一个元素为真,则返回True。bool(x): 将x转换为布尔值。chr(i): 将整数i转换为对应的ASCII字符。enumerate(iterable): 返回一个包含元素索引和值的迭代器。filter(function, iterable): 过滤序列,返回使function返回值为True的元素集合。input([prompt]): 从用户那里获取输入,返回一个字符串。len(s): 返回对象s的长度。list(iterable): 将iterable转换为列表。map(function, iterable, ...): 将function应用于iterable的每个元素,并返回一个map对象。max(iterable, ...): 返回iterable中的最大值。min(iterable, ...): 返回iterable中的最小值。next(object): 返回迭代器的下一个项目。open(file, mode='r', ...): 打开一个文件并返回文件对象。ord(c): 将单个字符c转换为它的整数表示。print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False): 打印对象。range(start, stop, step): 产生一个起始值为start、结束值为stop、步长的序列。repr(object): 获取对象的字符串表示,通常用于调试。round(number[, ndigits]): 对number进行四舍五入到ndigits位小数。set(iterable): 将iterable转换为集合。sorted(iterable, key=None, reverse=False): 返回iterable的排序列表。sum(iterable[, start]): 求和iterable中的元素,start是求和的初始值。type(object): 获取对象的类型。zip(*iterables): 将多个iterables中对应的元素打包成一个个元组,然后返回由这些元组组成的迭代器。
filter、map、reduce的作用:
filter(function, iterable): 过滤出满足条件的元素。map(function, iterable, ...): 对每个元素应用函数,返回一个map对象。reduce(function, sequence[, initial]): 将序列的元素组合为单个值,应用二元函数到元素对。
一行代码实现9*9乘法表:
for i in range(1, 10): print(' '.join(f'{i * j}' for j in range(1, i+1)))如何安装第三方模块?
使用pip工具安装第三方模块,命令如下:
pip install module_name
用过哪些第三方模块?
numpy: 科学计算。pandas: 数据分析。matplotlib: 绘图。scikit-learn: 机器学习。flask: Web开发。django: Web开发框架。requests: HTTP库。beautifulsoup4: 解析HTML和XML文档。
至少列举8个常用模块:
sys: 与Python解释器密切相关的变量和函数。os: 操作系统接口。json: JSON编码和解码。datetime: 日期和时间类型。collections: 高级数据类型,如defaultdict、namedtuple。itertools: 迭代器工具。math: 数学函数。re: 正则表达式。
re的match和search区别?
match: 从字符串的起始位置匹配模式,如果匹配成功则返回Match对象,否则返回None。search: 扫描整个字符串,查找第一个位置的匹配项,如果找到匹配项则返回Match对象,否则返回None。
什么是正则的贪婪匹配?
贪婪匹配是指正则表达式尽可能多地匹配字符。例如,正则表达式a*在字符串"aaaa"中会匹配所有'a'字符,因为它尽可能多地匹配了。
求结果:
a. [ i % 2 for i in range(10) ] 结果:[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
b. ( i % 2 for i in range(10) ) 结果:这是一个生成器表达式,不会立即求值,而是每次迭代时计算下一个值。
c. 1 or 2 结果:1(因为1在布尔上下文中为真,所以不会评估or右边的表达式)
d. 1 and 2 结果:2(因为1在布尔上下文中为真,and操作符会返回最后一个真值)
e. 1 < (2==2) 结果:False(因为2==2为真,类型转换为整数是1,1小于1不成立)
f. 1 < 2 == 2 结果:True(这是链式比较,首先2 == 2为真,然后1 < True,布尔值True在比较时相当于1)
求结果:
a. 1 or 2 结果:1(因为1为真值,在布尔上下文中or操作符会返回第一个真值) b. 1 and 2 结果:2(因为1和2都为真值,在布尔上下文中and操作符会返回最后一个真值) c. 1 < (2==2) 结果:False(因为2==2为真,即True,而1 < True在布尔上下文中等同于1 < 1,结果为False) d. 1 < 2 == 2 结果:True(这是Python中的链式比较,等同于(1 < 2) and (2 == 2),结果为True)
def func(a, b=[]) 这种写法的坑:
- 将列表作为函数的默认参数值,如果函数被多次调用,列表会被重复使用,之前的修改都会保留。
如何实现 "1,2,3" 变成 ['1','2','3']?
s = "1,2,3" result = s.split(',')如何实现 ['1','2','3'] 变成 [1,2,3]?
lst = ['1', '2', '3'] result = [int(item) for item in lst]比较 a = [1,2,3] 和 b = [(1),(2),(3)] 以及 b = [(1,),(2,),(3,)] 的区别:
a是一个列表,包含整数1, 2, 3。b = [(1),(2),(3)]是一个列表,包含三个元组,每个元组中只有一个元素1, 2, 3。b = [(1,),(2,),(3,)]同样是包含三个单元素元组的列表,但每个元组后面都有一个逗号,这是Python中单元素元组的语法要求。
如何用一行代码生成 [1,4,9,16,25,36,49,64,81,100]?
result = [i**2 for i in range(1, 11)]一行代码实现删除列表中重复的值?
result = list(set([1, 2, 2, 3, 4, 4, 5]))如何在函数中设置一个全局变量?
在函数内部使用global关键字声明变量,使其引用的是全局作用域中的变量。
x = 10 def func(): global x x = 20 func() print(x) # 输出20logging模块的作用以及应用场景:
logging模块用于记录程序运行时的信息,可以配置不同的日志级别(DEBUG, INFO, WARNING, ERROR, CRITICAL),并输出到不同的目的地(控制台、文件等)。常用于调试、记录程序运行状态、审计等。
用代码简答实现stack:
class Stack:def __init__(self):self.items = []def is_empty(self):return len(self.items) == 0def push(self, item):self.items.append(item)def pop(self):if not self.is_empty():return self.items.pop()raise IndexError("pop from empty stack")常用字符串格式化:
- 百分号格式化:
'%s: %d' % (name, num) str.format()方法:'{}: {}'.format(name, num)- f-string(Python 3.6+):
f'{name}: {num}'
生成器、迭代器、可迭代对象
-
可迭代对象(Iterable):
- 是可以被
for循环迭代的对象,如列表、元组、字典、集合以及字符串。 - 它们实现了
__iter__()方法,返回一个迭代器。
- 是可以被
-
迭代器(Iterator):
- 是一个有
__next__()和__iter__()方法的对象,用于逐个访问可迭代对象中的元素。 - 迭代器允许你遍历容器中的内容而不需要关心容器的内部实现。
- 是一个有
-
生成器(Generator):
- 是一种特殊的迭代器,通过使用
yield语句返回一个值并记住产生值时的状态。 - 生成器非常适合于大数据集的懒加载(lazy evaluation),因为它不需要一次性将所有数据加载到内存中。
- 是一种特殊的迭代器,通过使用
应用场景:
- 当你需要逐个处理数据集中的元素时,使用迭代器。
- 当你想懒加载大量数据或创建自定义的迭代逻辑时,使用生成器。
- 当你需要一个可以重复访问的元素集合时,使用可迭代对象。
二分查找函数实现:
def binary_search(arr, x):low = 0high = len(arr) - 1mid = 0while low <= high:mid = (high + low) // 2if arr[mid] < x:low = mid + 1elif arr[mid] > x:high = mid - 1else:return midreturn -1闭包的理解:
闭包是一个函数,它记住了其创建环境中的变量。即使函数在外部作用域被调用,它仍然可以访问这些变量。在Python中,闭包通常通过在函数内部定义另一个函数来实现,内层函数引用了外层函数的变量。
os和sys模块的作用:
-
os模块:
- 提供了一种方便的方式来使用操作系统依赖的功能。
- 可以执行路径操作、文件系统操作、环境变量访问等。
-
sys模块:
- 与Python解释器及其环境交互。
- 可以访问命令行参数、执行环境变量、退出程序等。
生成一个随机数:
import random random_number = random.randint(1, 10) # 生成1到10之间的随机整数使用Python删除文件:
import os os.remove('file_name.txt') # 删除指定的文件面向对象的理解:
面向对象编程(OOP)是一种编程范式,它使用“对象”来设计软件。对象可以包含数据(属性)和代码(方法)。面向对象的核心概念是数据和功能的封装、继承和多态。
继承的特点:
- 允许新创建的类(子类)继承现有类(父类)的属性和方法。
- 子类可以扩展或修改父类的行为。
- 支持代码复用。
面向对象深度优先和广度优先:
-
深度优先:
- 在继承层次结构中,先完全探索一个分支,然后再转到下一个分支。
- 在方法解析顺序(MRO)中,先查找子类的方法,然后逐级向上查找父类的方法。
-
广度优先:
- 在继承层次结构中,先探索同一继承层级的类,然后再逐级向下探索。
- 在实际的Python类继承中不常见,因为Python通常采用深度优先的策略。
super的作用:
super()函数用于调用父类的方法。在子类覆盖父类的方法时,可以使用super()来保持父类方法的调用,确保继承链中方法的正确执行。这在多重继承的情况下特别有用,可以明确指定调用哪个父类的方法。
使用过functools模块吗?它的作用是什么?
functools模块是Python的一个内置模块,提供了一系列高阶函数和函数工具,用于操作或扩展函数的功能。例如:
partial: 用于固定函数的某些参数,创建一个新的函数。reduce: 对序列的元素进行累积,并返回一个单一的值。lru_cache: 为函数提供自动缓存机制,避免重复计算。total_ordering: 快速实现类的比较魔术方法。cmp_to_key: 将比较函数转换为key函数,用于排序。
面向对象中带下划线的特殊方法:
__new__(cls, ...): 创建实例的方法,返回一个实例。__init__(self, ...): 初始化实例的方法,设置初始状态。__del__(self): 实例销毁时调用的方法。__str__(self): 当使用print()或str()时调用,返回对象的字符串表示。__repr__(self): 当使用repr()时调用,返回对象的官方字符串表示,便于调试。__len__(self): 当使用len()时调用,返回容器类型的长度。__getitem__(self, key): 用于索引,如obj[key]。__setitem__(self, key, value): 用于赋值索引,如obj[key] = value。__delitem__(self, key): 用于删除索引,如del obj[key]。__iter__(self): 返回对象的迭代器,用于迭代操作,如for x in obj。__next__(self): 返回迭代器的下一个元素。__call__(self, ...): 允许一个对象像函数那样被调用,如obj()。
如何判断是函数还是方法?
在Python中,可以通过检查self参数来区分函数和方法。方法定义时通常包含self作为第一个参数,而函数则没有。可以使用inspect模块的isfunction()和ismethod()函数来判断:
import inspectdef my_function():passclass MyClass:def my_method(self):passprint(inspect.isfunction(my_function)) # 输出: True
print(inspect.ismethod(MyClass.my_method)) # 输出: True静态方法和类方法的区别?
-
静态方法(使用
@staticmethod装饰器):- 不接收类或实例的引用作为第一个参数。
- 可以看作是类内部的普通函数。
-
类方法(使用
@classmethod装饰器):- 第一个参数是类本身,通常命名为
cls。 - 可以用来访问类的属性或调用类的方法。
- 第一个参数是类本身,通常命名为
面向对象中的特殊成员以及应用场景:
__init__: 构造器,用于初始化新创建的对象。__del__: 析构器,用于在对象被销毁前进行清理。__str__和__repr__: 分别用于返回对象的非正式和正式字符串表示,常用于调试。__len__: 当对象用作for循环或len()函数时调用,返回对象的长度。__getitem__,__setitem__,__delitem__: 用于支持索引操作,如获取、设置和删除元素。__iter__和__next__: 支持迭代协议,允许对象在for循环中被迭代。
1、2、3、4、5 组成的互不相同且无重复的三位数数量:
这是一个排列问题,因为有4个数字(1, 2, 3, 4, 5),要选出3个数字组成三位数,每个数字只能使用一次,所以有P(4, 3) = 4! / (4-3)! = 24种排列方式。
什么是反射?以及应用场景?
反射是指程序在运行时能够访问、检查和修改它自己的行为或结构的能力。在Python中,反射可以通过type(), isinstance(), getattr(), setattr(), dir()等内置函数实现。应用场景包括:
- 动态创建对象或调用方法。
- 读取和修改类的属性。
- 实现依赖注入框架。
metaclass作用?以及应用场景?
Metaclass是类的“类”,即用于创建类的类。它定义了类的创建和行为方式。应用场景包括:
- 自定义类的创建过程,例如修改类属性或方法。
- 实现单例模式或其他特殊的类模式。
- 创建ORM(对象关系映射)框架,自动将类映射到数据库表。
实现单例模式的方法:
-
使用模块: 模块级别的变量可以确保全局只有一个实例。
-
使用装饰器: 创建一个装饰器,用于封装类,确保只有一个实例被创建。
-
使用
__new__方法: 在类的__new__方法中控制实例的创建。 -
使用类属性: 类属性用于存储类的唯一实例。
-
使用局部变量: 在类内部使用局部变量存储实例。
装饰器的写法以及应用场景:
装饰器是一个函数,它接受一个函数作为参数并返回一个函数。装饰器可以用来修改或增强函数的行为。
def my_decorator(func):def wrapper(*args, **kwargs):# 执行一些操作result = func(*args, **kwargs)# 执行一些操作return resultreturn wrapper# 使用装饰器
@my_decorator
def my_function():pass应用场景包括:
- 日志记录:在函数执行前后添加日志。
- 性能测试:测量函数执行时间。
- 事务处理:确保数据库操作的原子性。
- 权限检查:在函数执行前检查用户权限。
异常处理写法及主动抛出异常:
异常处理使用try...except语句。可以主动抛出异常使用raise关键字。
try:# 尝试执行的代码result = 10 / 0
except ZeroDivisionError as e:# 处理特定异常print("发生错误:", e)
finally:# 无论是否发生异常都会执行的代码print("这是 finally 子句")# 主动抛出异常
if some_condition:raise ValueError("这是一个主动抛出的异常")应用场景:当某个条件不满足时,需要终止程序流程并通知调用者有错误发生。
面向对象的 MRO(Method Resolution Order):
MRO 是解析方法查找顺序的算法,用于确定在多继承情况下,应该按照什么顺序查找方法。Python 使用 C3 线性化算法来实现 MRO。
isinstance 作用及应用场景:
isinstance(object, classinfo) 用于判断一个对象是否是一个类或类的子类的实例。
if isinstance(obj, list):# 如果 obj 是 list 类型或其子类的实例pass应用场景:需要对不同类型的对象执行不同操作时,进行类型检查。
寻找两个数的索引:
def two_sum(nums, target):num_to_index = {}for i, num in enumerate(nums):complement = target - numif complement in num_to_index:return [num_to_index[complement], i]num_to_index[num] = ireturn []# 示例
nums = [2, 7, 11, 15]
target = 9
print(two_sum(nums, target)) # 输出: [0, 1]JSON 序列化支持的数据类型及定制:
JSON 序列化可以处理以下数据类型:
- 字符串
- 整数
- 浮点数
- 布尔值
- 列表
- 字典
None
定制支持 datetime 类型:
import json
from datetime import datetimedef datetime_handler(obj):if isinstance(obj, datetime):return obj.isoformat()raise TypeError("Unknown type")json_str = json.dumps({'date': datetime.now()}, default=datetime_handler)JSON 序列化保留中文:
在序列化时指定 ensure_ascii=False 参数:
json_str = json.dumps(data, ensure_ascii=False)断言:
assert 语句用于调试目的,检查条件是否为真,如果为假,则抛出 AssertionError。
assert condition, "错误信息"
应用场景:确保程序在某个条件下满足预期,通常用于开发和测试阶段。
with statement:
with 语句用于包裹执行代码的上下文,确保资源的正确管理,如文件操作。
with open('file.txt', 'r') as file:data = file.read()# 文件会在 with 代码块结束时自动关闭好处:自动管理资源,无需手动关闭文件或其他资源。
查看列举目录下的所有文件:
import osdirectory = '/path/to/directory'
for filename in os.listdir(directory):filepath = os.path.join(directory, filename)if os.path.isfile(filepath):print(filepath)yield 和 yield from 关键字:
yield用于在函数中产生一个值,该函数就变成了一个生成器。每次迭代调用next()时执行到yield表达式,返回一个值并暂停,直到下一次迭代。
def my_generator():yield 1yield 2yield from用于在生成器中委派给另一个生成器或迭代器,将另一个生成器的输出合并到当前生成器中。
def my_outer_generator():yield from my_generator()yield 3使用 yield from 可以简化嵌套生成器的实现。
相关文章:

Python基础问题汇总
为什么学习Python? 易学易用:Python语法简洁清晰,易于学习。广泛的应用领域:适用于Web开发、数据科学、人工智能、自动化脚本等多种场景。强大的库支持:拥有丰富的第三方库,如NumPy、Pandas、TensorFlow等…...

【讲解下iOS语言基础】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...
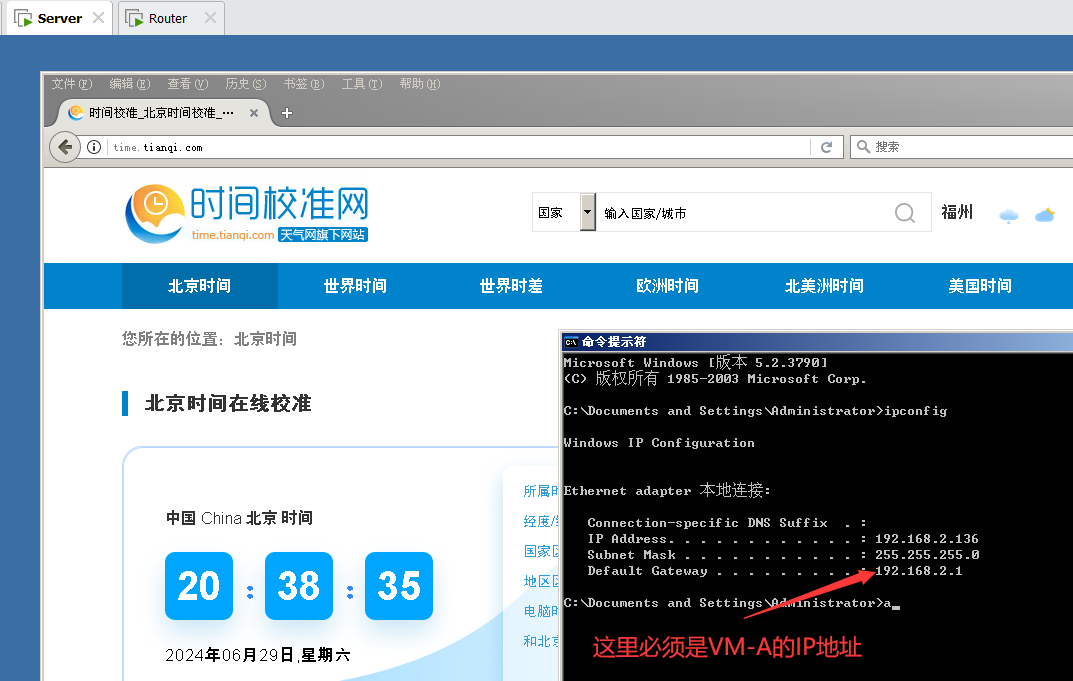
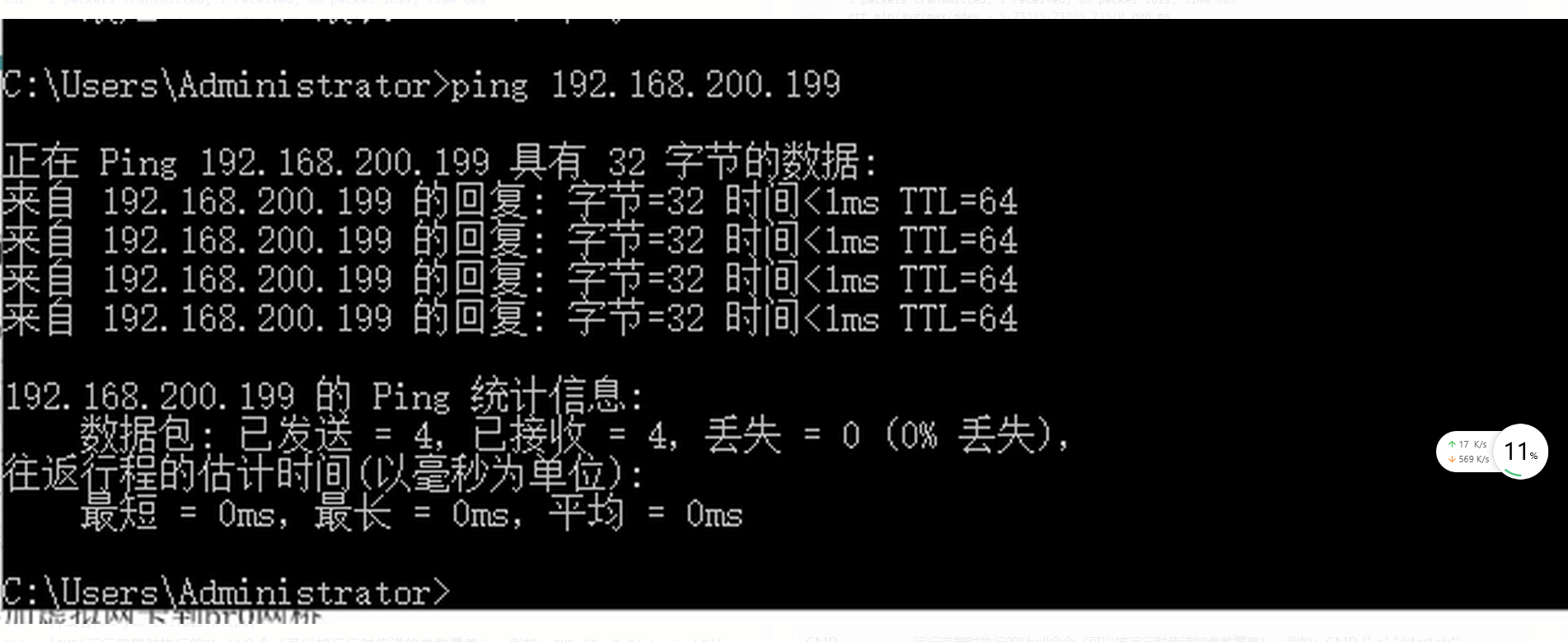
【网络安全】实验一(网络拓扑环境的搭建)
一、本次实验的实验目的 学习利用 VMware 创建虚拟环境 学习利用 VMware 搭建各自网络拓扑环境 二、创建虚拟机 三、克隆虚拟机 选择克隆的系统必须处于关机状态。 方法一: 方法二: 需要修改克隆计算机的名字,避免产生冲突。 四、按照要求完…...
Docker-基础
一,Docker简介,功能特性与应用场景 1.1 Docker简介 Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器…...
《昇思25天学习打卡营第14天|onereal》
第14天学习内容如下: Diffusion扩散模型 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,…...

LeetCode 744, 49, 207
目录 744. 寻找比目标字母大的最小字母题目链接标签思路代码 49. 字母异位词分组题目链接标签思路代码 207. 课程表题目链接标签思路代码 744. 寻找比目标字母大的最小字母 题目链接 744. 寻找比目标字母大的最小字母 标签 数组 二分查找 思路 本题比 基础二分查找 难的一…...
【AI资讯】可以媲美GPT-SoVITS的低显存开源文本转语音模型Fish Speech
Fish Speech是一款由fishaudio开发的全新文本转语音工具,支持中英日三种语言,语音处理接近人类水平,使用Flash-Attn算法处理大规模数据,提供高效、准确、稳定的TTS体验。 Fish Audio...

微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南
微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南 在构建基于Spring Cloud的微服务架构时,服务发现和数据流处理是两个关键的组成部分。Eureka作为服务发现工具,而Spring Cloud Data Flow提供了数据流处理的能力。本文将详细介绍…...

java生成json格式文件(包含缩进等格式)
生成json文件的同时保留原json格式,拥有良好的格式(如缩进等),提供友善阅读支持。 pom.xml依赖增加: <dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactI…...

Python面试题:如何在 Python 中读取和写入 JSON 文件?
在 Python 中读取和写入 JSON 文件可以使用 json 模块。以下是具体的示例,展示了如何读取和写入 JSON 文件。 读取 JSON 文件 要读取 JSON 文件,可以使用 json.load() 方法。下面是一个示例代码: import json# 假设有一个名为 data.json 的…...

FlutterWeb渲染模式及提速
背景 在使用Flutter Web开发的网站过程中,常常会遇到不同浏览器之间的兼容性问题。例如,在Google浏览器中动画和交互都非常流畅,但在360浏览器中却会出现卡顿现象;在Google浏览器中动态设置图标颜色正常显示,而在Safa…...

群体优化算法----化学反应优化算法介绍,解决蛋白质-配体对接问题示例
介绍 化学反应优化算法(Chemical Reaction Optimization, CRO)是一种新兴的基于自然现象的元启发式算法,受化学反应过程中分子碰撞和反应机制的启发而设计。CRO算法模拟了分子在化学反应过程中通过能量转换和分子间相互作用来寻找稳定结构的…...

Go语言如何入门,有哪些书推荐?
Go 语言之所以如此受欢迎,其编译器功不可没。Go 语言的发展也得益于其编译速度够快。 对开发者来说,更快的编译速度意味着更短的反馈周期。大型的 Go 应用程序总是能在几秒钟之 内完成编译。而当使用 go run编译和执行小型的 Go 应用程序时,其…...
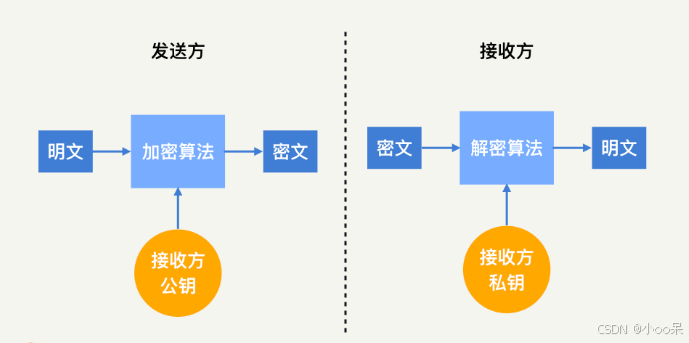
【密码学】密码学体系
密码学体系是信息安全领域的基石,它主要分为两大类:对称密码体制和非对称密码体制。 一、对称密码体制(Symmetric Cryptography) 在对称密码体制中,加密和解密使用相同的密钥。这意味着发送方和接收方都必须事先拥有这…...

Bean的管理
1.主动获取Bean spring项目在需要时,会自动从IOC容器中获取需要的Bean 我们也可以自己主动的得到Bean对象 (1)获取bean对象,首先获取SpringIOC对象 private ApplicationContext applicationContext //IOC容器对象 (2 )方法…...
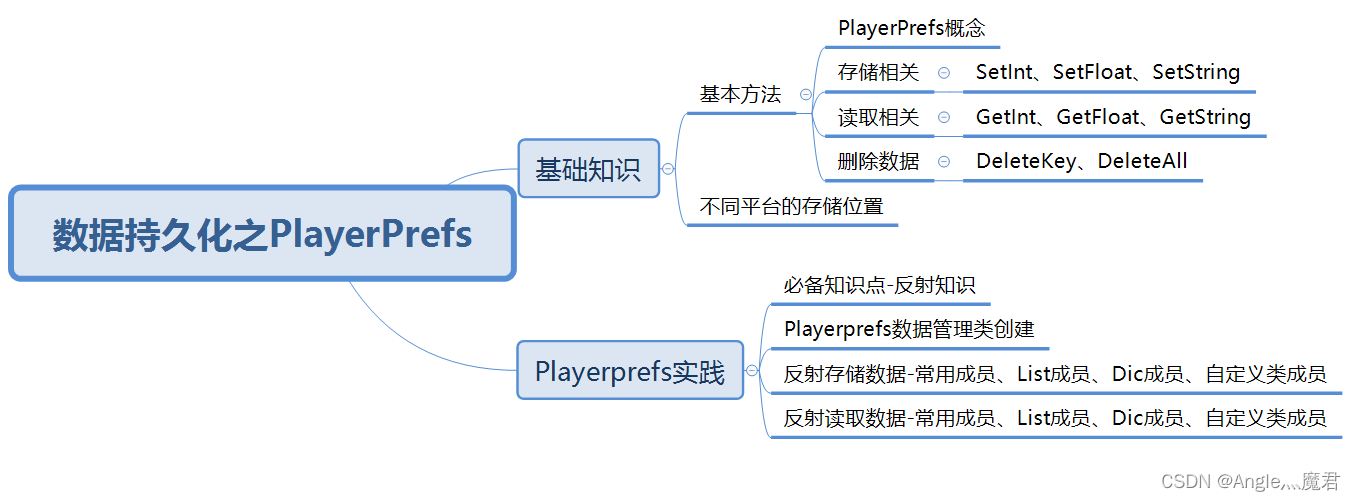
Unity 数据持久化【PlayerPrefs】
1、数据持久化 文章目录 1、数据持久化PlayerPrefs基本方法1、PlayerPrefs概念2、存储相关3、读取相关4、删除数据思考 信息的存储和读取 PlayerPrefs存储位置1、PlayerPrefs存储的数据在哪个位置2、PlayerPrefs 数据唯一性思考 排行榜功能 2、Playerprefs实践1、必备知识点-反…...
linux-虚拟内存-虚拟cpu
1、进程: 计算机中的程序关于某数据集合上的一次运行活动。 狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。广义定义:进程是一个具有一定独立功能的程序关于某个…...
某某市信息科技学业水平测试软件打开加载失败逆向分析(笔记)
引言:笔者在工作过程中,用户上报某某市信息科技学业水平测试软件在云电脑上打开初始化的情况下出现了加载和绑定机器失败的问题。一般情况下,在实体机上用户进行登录后,用户的账号信息跟主机的机器码进行绑定然后保存到配置文件&a…...
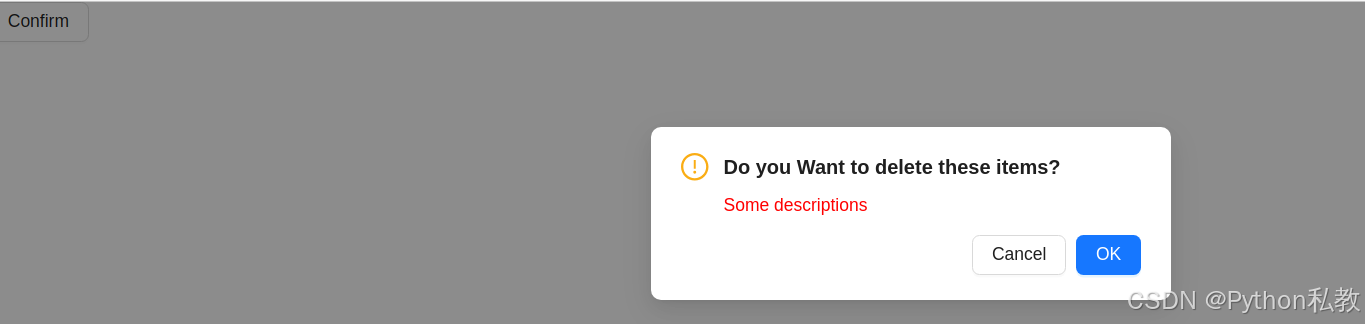
vue3+antd 实现点击按钮弹出对话框
格式1:确认对话框 按钮: 点击按钮之后: 完整代码: <template><div><a-button click"showConfirm">Confirm</a-button></div> </template> <script setup> import {Mod…...

Python一些可能用的到的函数系列130 UCS-Time Brick
说明 UCS对象是基于GFGoLite进行封装,且侧重于实现UCS规范。 内容 1 函数 我发现pydantic真是一个特别好用的东西,可以确保在数据传递时的可靠,以及对某个数据模型的描述。 以下,UCS给出了id、time相关的brick映射࿰…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

Redis 客户端连接详解
Redis 客户端连接详解 引言 Redis 是一款高性能的内存数据结构存储系统,常用于缓存、会话管理、实时排行榜等功能。客户端连接是 Redis 生态系统中的重要组成部分,本文将详细介绍 Redis 客户端连接的相关知识,包括连接方式、连接配置、连接管理等方面。 Redis 客户端连接…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...

还在手动触发Lindy子任务?这6个隐藏API+3个低代码集成技巧,今天就能上线全自动流水线
更多请点击: https://kaifayun.com 第一章:Lindy多步骤任务自动化的价值与演进路径 Lindy效应指出,一项技术的预期剩余寿命与其当前已存在时间正相关;在自动化领域,Lindy原则催生了对“经久验证、语义稳定、可组合性强…...