Mysql explain语句详解与实例展示
首先简单介绍sql:
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:SELECT <字段名表>FROM <表或视图名>WHERE <查询条件>
2 .数据操纵语言DML
数据操纵语言DML主要有三种形式:
1) 插入:INSERT
2) 更新:UPDATE
3) 删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:CREATE TABLE / VIEW / INDEX / SYN / CLUSTER| 表 视图 索引 同义词 簇。DDL操作是隐性提交的!不能rollback
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。回滚---ROLLBACK回滚命令使数据库状态回到上次最后提交的状态。其格式为:SQL>ROLLBACK;
3) COMMIT [WORK]:提交。在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。
关于授权语句
数据库授权命令:
GRANT<权限> on 表名(或列名) to 用户
正确答案选项B: insert,select: 权限 表名: user 用户:nkw
补充知识点-回收权限
REVOKE <权限> on 表名(或列名) FROM 用户
explain 语句介绍
explain 语句相信大家都不陌生,作为查看执行计划的语句。explain在sql优化分析中会经常会用到。
这里值得注意的是:explain并没有真正执行语句,只是展示执行计划。
可以看到哪些信息?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引实际被使用
- 表之间的引用
- 每张表有多少行被优化器查询
基本语法介绍
EXPLAIN SELECT select具体语句
如:
EXPLAIN SELECT * FROM userpro
explain各个列的作用介绍
| 列名 | 描述 | 补充 |
| id | 每个SELECT关键字都对应一个id | |
| select_type | SELECT关键字对应的查询类型 | |
| table | 表名 | |
| partitions | 匹配的分区信息 | |
| type | 针对单表的访问方法 | |
| possible_keys | 可能用到的索引 | |
| key | 实际用到的索引 | |
| key_len | 实际用到的索引长度 | |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 | |
| rows | 预估需要读取的记录条数 | |
| filtered | 经过搜索条件过滤后剩余记录条数的百分比 |
|
| Extra | 额外信息 |
EXPLAIN各列详细介绍
1,id
每个SELECT关键字都对应一个id
id值越大,优先级越高,越先执行
id如果相同,可以认为是一组,从上往下顺序执行
id号每个号码,表示一次独立的查询, 一个sql的查询趟数越少越好
2,select_type
| 类别 | 说明 |
| SIMPLE | 单表查询,没有子查询或者 UNION 查询。 |
| PRIMARY | 查询中最外层的 SELECT 语句。 |
| SUBQUERY | 在 WHERE 子句中使用了子查询。 |
| DERIVED | 在 FROM 子句中包含的子查询,MySQL会将其标记为 DERIVED(派生),并且会为其结果集生成一个临时表,以供外层查询使用。 |
| UNION | 在 UNION 查询中第二个及以后的查询语句。 |
| UNION RESULT | UNION 查询的结果集。 |
| DEPENDENT SUBQUERY | 子查询的结果依赖外层查询的值,并且对于每个外层查询中的行都执行一次子查询 |
| DEPENDENT UNION | UNION 查询的第二个及以后的查询语句,且其结果依赖于外层查询的值 |
| UNCACHEABLE SUBQUERY | 子查询不能被缓存,每次引用时都会执行 |
3,table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
4,partitions (可略)
5. type ☆
常见type如下
| type | 说明 |
| system | 表中只有一行,通常为 SELECT ... FROM DUAL 查询优化。 |
| const | 查询通过索引一次就找到了,仅有一行结果(常量表)。 |
| eq_ref | 使用唯一索引或主键从其他表中找出一行。 |
| ref | 使用非唯一索引从其他表中找出一行或多行。 |
| range | 使用索引返回一个范围内的行。 |
| index | 完全扫描索引以找到行,而非扫描整个表。 |
| all | 全表扫描,对表中的每一行进行检查。 |
一般情况尽量避免all
6, key和possible_keys
-
key:
key字段显示了查询实际使用的索引。如果该字段的值为NULL,则表示没有使用索引。如果该字段有值,则表示 MySQL 使用了指定的索引来执行查询。
-
possible_keys:
possible_keys字段显示了 MySQL 能够使用的索引列表。这些索引是查询中可以考虑的索引,但不一定会被实际使用。通常,possible_keys中列出的索引是根据查询条件和表结构来决定的。
-
如果
key字段有一个索引名,而possible_keys中列出了多个索引名,表示 MySQL 选择了key字段列出的索引来执行查询,而其他索引列在possible_keys中表示也可以考虑,但最终没有使用。 -
如果
key字段为NULL,而possible_keys中列出了多个索引名,表示 MySQL 在执行查询时没有使用任何索引,这可能导致全表扫描或者其它非索引优化访问方法。
7,key_len
key_len 是描述索引键长度的一个字段。它指示了 MySQL 在使用特定索引执行查询时,索引的使用情况和索引键的长度。
-
单列索引:
- 如果使用了单列索引,并且该列的类型是固定长度的(例如
INT),则key_len的值就是该列的长度。 - 如果使用了变长字段(例如
VARCHAR),则key_len的值是该字段的最大长度。
- 如果使用了单列索引,并且该列的类型是固定长度的(例如
-
复合索引:
- 对于复合索引(即包含多个列的索引),
key_len表示索引中所有列的总长度。
- 对于复合索引(即包含多个列的索引),
-
组合索引:
- 如果查询中使用了多个列的组合索引,
key_len是组合索引中所有列的总长度。
- 如果查询中使用了多个列的组合索引,
-
索引前缀:
- 在某些情况下,MySQL 可能只使用索引的一部分。例如,可以使用索引的前缀作为索引的一部分来执行查询。在这种情况下,
key_len将显示实际使用的索引部分的长度。
- 在某些情况下,MySQL 可能只使用索引的一部分。例如,可以使用索引的前缀作为索引的一部分来执行查询。在这种情况下,
8,ref
ref 是描述表之间的连接条件或者使用非唯一索引进行查找的一个字段。它指示了 MySQL 在执行查询时使用了哪些连接条件或者哪些索引来访问表。
9,rows
rows 是一个估计值,表示执行查询时所访问的行数或者要检查的行数。
- 对于简单的
SELECT查询,rows表示估计的返回行数。 - 对于连接查询(
JOIN)或者子查询,rows可能表示连接操作期间访问的行数。 - 对于表扫描(全表扫描或索引扫描),
rows可能表示扫描的行数。
10,filtered
表示根据 WHERE 条件和索引条件过滤后的行的百分比。filtered反映了优化器估计的查询优化效果。
当 filtered 接近 100% 时,表示查询条件有效地过滤了大部分不符合条件的行,这通常是一个好的优化指标。
反之,如果 filtered 值较低,可能表示查询条件不够精确或者优化器未能有效地利用索引来过滤数据。
11,Extra
额外信息字段
以下是一些常见的 Extra 字段及其含义:
-
Using index:
- 表示查询使用了覆盖索引,即查询的结果可以完全通过索引返回,而不需要访问表的实际数据行。
-
Using where:
- 表示MySQL服务器将在存储引擎检索行之后再进行条件过滤,而不是在索引中完成。
-
Using temporary:
- 表示MySQL在内存中创建了临时表来处理查询。常见于排序操作或者包含聚合函数的查询。
-
Using filesort:
- 表示MySQL执行了文件排序以处理查询。这通常发生在无法使用索引完成排序的情况下。
-
Range checked for each record (index map: ...):
- 表示MySQL使用了索引来检查每个记录是否在指定的范围内。这通常发生在
range查询类型中。
- 表示MySQL使用了索引来检查每个记录是否在指定的范围内。这通常发生在
-
Full scan on NULL key:
- 表示MySQL在某个索引中进行了全表扫描,以找到匹配 NULL 值的行。
-
Distinct:
- 表示MySQL将在找到第一匹配的行之后停止查找重复的行。
-
Using join buffer (Block Nested Loop):
- 表示MySQL正在使用连接缓冲区来处理连接操作,通常在连接表数量较多或者连接表大小较大时出现。
-
Impossible WHERE:
- 表示MySQL优化器确定了 WHERE 子句中的条件不可能满足,因此不会扫描任何行。
-
No tables used:
- 表示查询不涉及任何表,例如
SELECT NOW()。
- 表示查询不涉及任何表,例如
explain实际执行展示
数据准备
建表s1
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;建表s2
CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
数据自行准备。
样例执行与结果
简单查询
单表查询
EXPLAIN SELECT * FROM `s1`;
连接查询
EXPLAIN SELECT * FROM `s1` INNER JOIN `s2`;
子查询
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field
= 'a');
特别展示
展示select_type
#Union 去重
EXPLAIN SELECT * FROM `s1` UNION SELECT * FROM `s2`;
#Union 全查
EXPLAIN SELECT * FROM `s1` UNION ALL SELECT * FROM `s2`;
最后一步为去重操作,所以会使用临时表进行。而UNION ALL则为全部查询,则不会出现临时表查消息。

type类
const(索引一次就找到,仅有一行结果)
EXPLAIN SELECT * FROM s1 WHERE id = 10002;eq_ref(使用唯一索引或主键从其他表中找出一行)
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;
ref(使用非唯一索引从其他表中找出一行或多行)
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
range(使用索引返回一个范围内的行)
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');
index(完全扫描索引以找到行)
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';
其它展示
filtered小数时
EXPLAIN SELECT * FROM s1 WHERE key1 > 'za' AND common_field = 'la'
相关文章:
Mysql explain语句详解与实例展示
首先简单介绍sql: SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句…...

Python基础问题汇总
为什么学习Python? 易学易用:Python语法简洁清晰,易于学习。广泛的应用领域:适用于Web开发、数据科学、人工智能、自动化脚本等多种场景。强大的库支持:拥有丰富的第三方库,如NumPy、Pandas、TensorFlow等…...

【讲解下iOS语言基础】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...
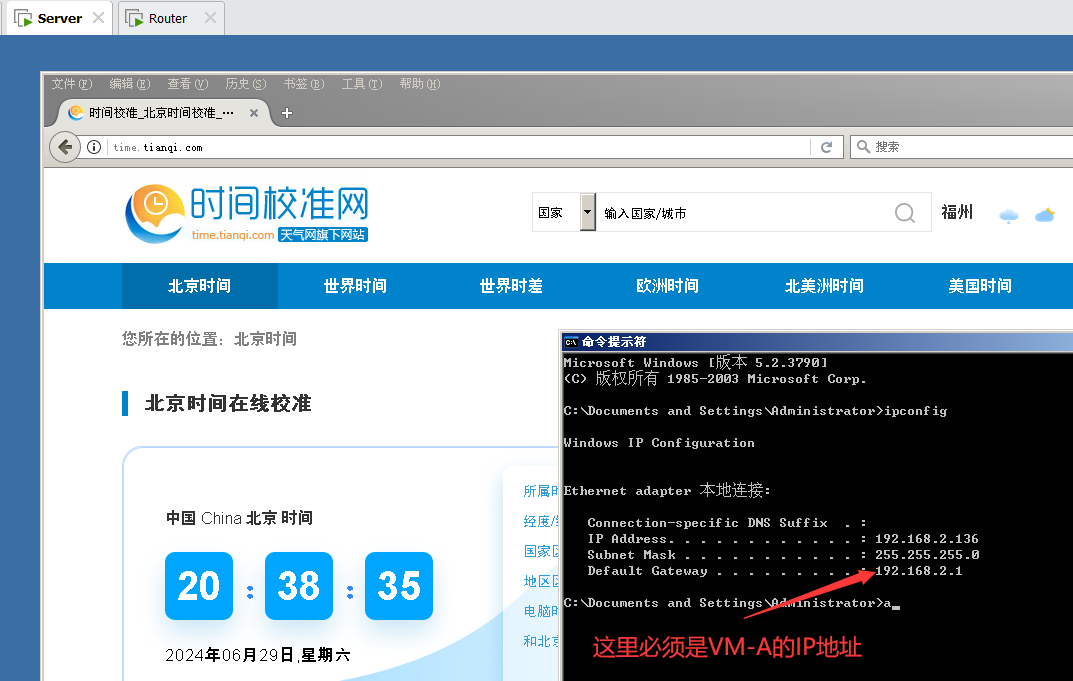
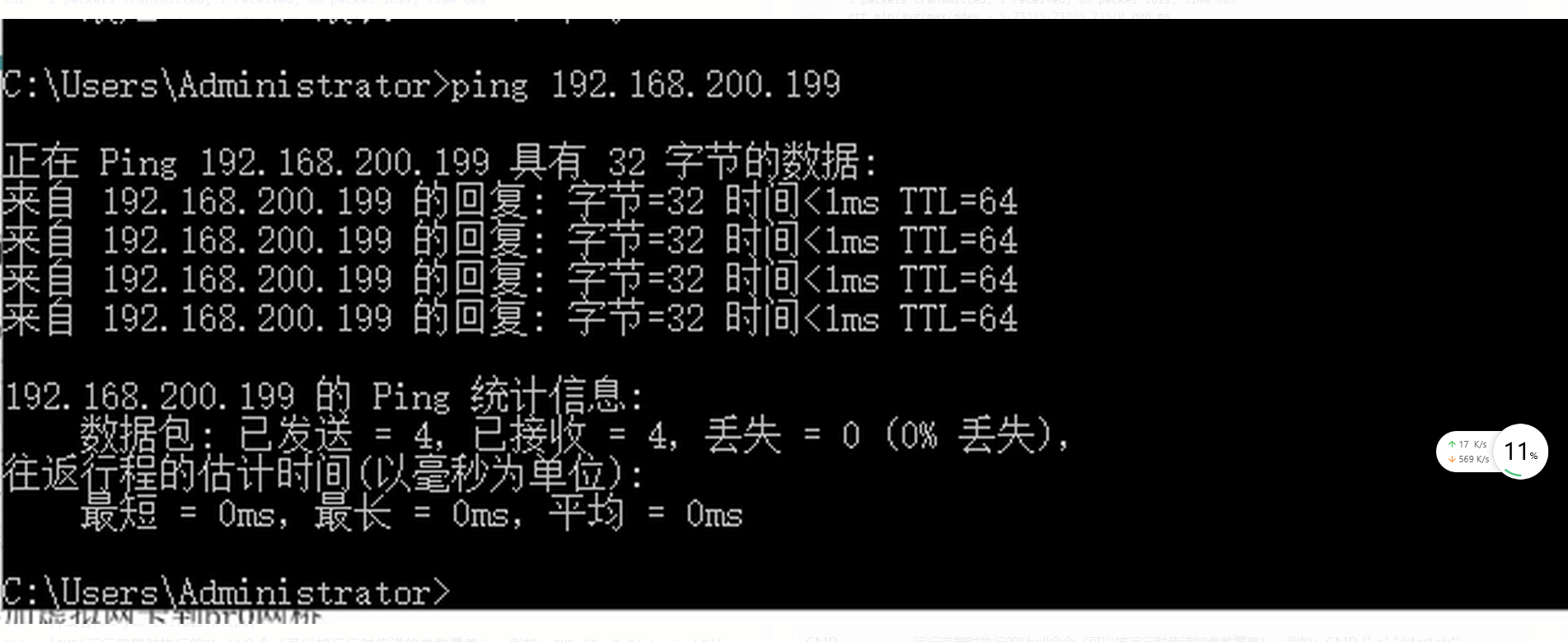
【网络安全】实验一(网络拓扑环境的搭建)
一、本次实验的实验目的 学习利用 VMware 创建虚拟环境 学习利用 VMware 搭建各自网络拓扑环境 二、创建虚拟机 三、克隆虚拟机 选择克隆的系统必须处于关机状态。 方法一: 方法二: 需要修改克隆计算机的名字,避免产生冲突。 四、按照要求完…...
Docker-基础
一,Docker简介,功能特性与应用场景 1.1 Docker简介 Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器…...
《昇思25天学习打卡营第14天|onereal》
第14天学习内容如下: Diffusion扩散模型 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,…...

LeetCode 744, 49, 207
目录 744. 寻找比目标字母大的最小字母题目链接标签思路代码 49. 字母异位词分组题目链接标签思路代码 207. 课程表题目链接标签思路代码 744. 寻找比目标字母大的最小字母 题目链接 744. 寻找比目标字母大的最小字母 标签 数组 二分查找 思路 本题比 基础二分查找 难的一…...
【AI资讯】可以媲美GPT-SoVITS的低显存开源文本转语音模型Fish Speech
Fish Speech是一款由fishaudio开发的全新文本转语音工具,支持中英日三种语言,语音处理接近人类水平,使用Flash-Attn算法处理大规模数据,提供高效、准确、稳定的TTS体验。 Fish Audio...

微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南
微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南 在构建基于Spring Cloud的微服务架构时,服务发现和数据流处理是两个关键的组成部分。Eureka作为服务发现工具,而Spring Cloud Data Flow提供了数据流处理的能力。本文将详细介绍…...

java生成json格式文件(包含缩进等格式)
生成json文件的同时保留原json格式,拥有良好的格式(如缩进等),提供友善阅读支持。 pom.xml依赖增加: <dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactI…...

Python面试题:如何在 Python 中读取和写入 JSON 文件?
在 Python 中读取和写入 JSON 文件可以使用 json 模块。以下是具体的示例,展示了如何读取和写入 JSON 文件。 读取 JSON 文件 要读取 JSON 文件,可以使用 json.load() 方法。下面是一个示例代码: import json# 假设有一个名为 data.json 的…...

FlutterWeb渲染模式及提速
背景 在使用Flutter Web开发的网站过程中,常常会遇到不同浏览器之间的兼容性问题。例如,在Google浏览器中动画和交互都非常流畅,但在360浏览器中却会出现卡顿现象;在Google浏览器中动态设置图标颜色正常显示,而在Safa…...

群体优化算法----化学反应优化算法介绍,解决蛋白质-配体对接问题示例
介绍 化学反应优化算法(Chemical Reaction Optimization, CRO)是一种新兴的基于自然现象的元启发式算法,受化学反应过程中分子碰撞和反应机制的启发而设计。CRO算法模拟了分子在化学反应过程中通过能量转换和分子间相互作用来寻找稳定结构的…...

Go语言如何入门,有哪些书推荐?
Go 语言之所以如此受欢迎,其编译器功不可没。Go 语言的发展也得益于其编译速度够快。 对开发者来说,更快的编译速度意味着更短的反馈周期。大型的 Go 应用程序总是能在几秒钟之 内完成编译。而当使用 go run编译和执行小型的 Go 应用程序时,其…...
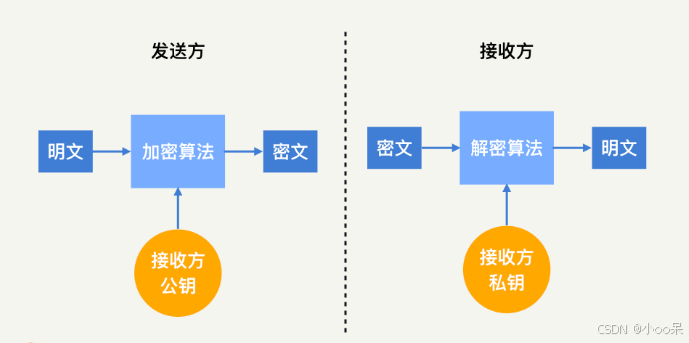
【密码学】密码学体系
密码学体系是信息安全领域的基石,它主要分为两大类:对称密码体制和非对称密码体制。 一、对称密码体制(Symmetric Cryptography) 在对称密码体制中,加密和解密使用相同的密钥。这意味着发送方和接收方都必须事先拥有这…...

Bean的管理
1.主动获取Bean spring项目在需要时,会自动从IOC容器中获取需要的Bean 我们也可以自己主动的得到Bean对象 (1)获取bean对象,首先获取SpringIOC对象 private ApplicationContext applicationContext //IOC容器对象 (2 )方法…...
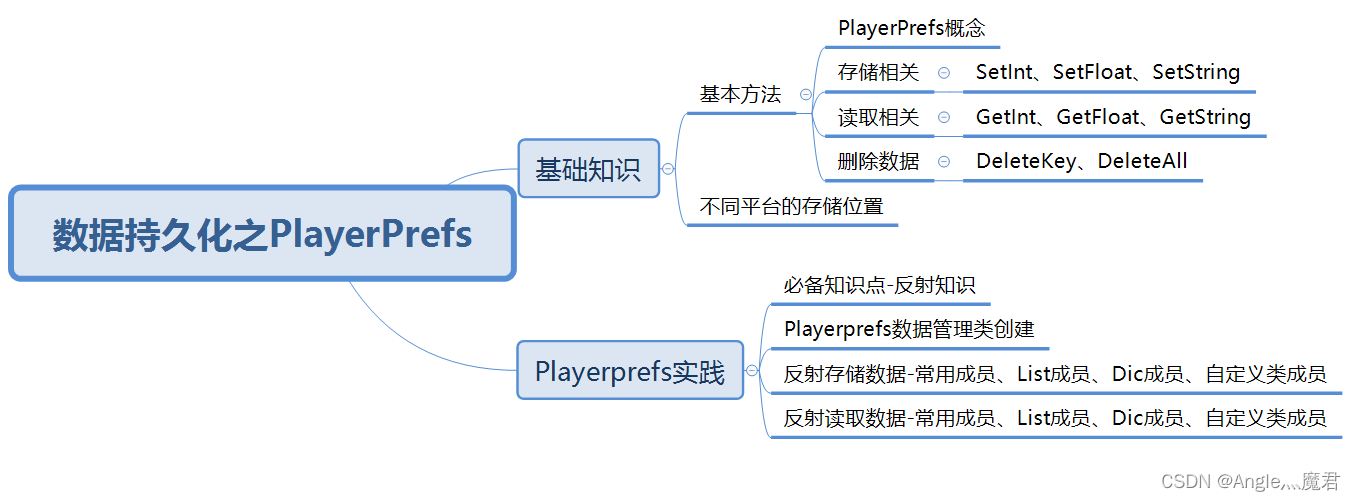
Unity 数据持久化【PlayerPrefs】
1、数据持久化 文章目录 1、数据持久化PlayerPrefs基本方法1、PlayerPrefs概念2、存储相关3、读取相关4、删除数据思考 信息的存储和读取 PlayerPrefs存储位置1、PlayerPrefs存储的数据在哪个位置2、PlayerPrefs 数据唯一性思考 排行榜功能 2、Playerprefs实践1、必备知识点-反…...
linux-虚拟内存-虚拟cpu
1、进程: 计算机中的程序关于某数据集合上的一次运行活动。 狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。广义定义:进程是一个具有一定独立功能的程序关于某个…...
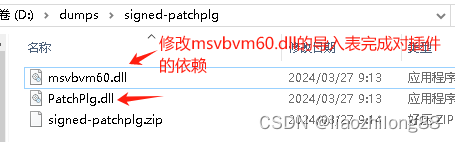
某某市信息科技学业水平测试软件打开加载失败逆向分析(笔记)
引言:笔者在工作过程中,用户上报某某市信息科技学业水平测试软件在云电脑上打开初始化的情况下出现了加载和绑定机器失败的问题。一般情况下,在实体机上用户进行登录后,用户的账号信息跟主机的机器码进行绑定然后保存到配置文件&a…...
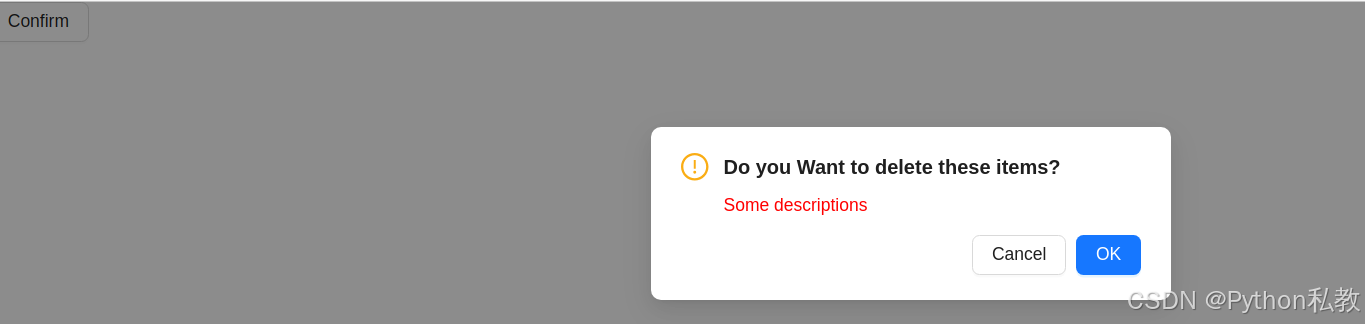
vue3+antd 实现点击按钮弹出对话框
格式1:确认对话框 按钮: 点击按钮之后: 完整代码: <template><div><a-button click"showConfirm">Confirm</a-button></div> </template> <script setup> import {Mod…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...