基于AOP的数据字典实现:实现前端下拉框的可配置更新
作者:后端小肥肠
创作不易,未经允许严禁转载。
目录
1. 前言
2. 数据字典
2.1. 数据字典简介
2.2. 数据字典如何管理各模块的下拉框
3. 数据字典核心内容解读
3.1. 表结构
3.2. 核心代码
3.2.1. 根据实体类名称获取下属数据字典
3.2.2. 数据字典AOP切面
3.2.2.1. 场景模拟
3.2.2.2. 数据字典交互流程
3.2.2.3. AOP代码
4. 数据字典使用
4.1. 新增Student类对应数据字典值
4.2. 新增学生数据
4.3. 根据id查询学生数据详细信息
5. 结语
6. 参考链接
1. 前言
在现代软件开发中,数据字典作为管理系统常量和配置项的重要工具,其灵活性和可维护性对系统的健壮性起着至关重要的作用。然而,传统的数据字典与业务模块的整合方式往往存在着严重的耦合问题。通常情况下,为了在业务模块中使用数据字典的标签(label),我们不得不在VO类中添加字段,并通过查询数据字典来获取对应的标签值,这种做法不仅增加了代码的复杂性,还使得业务模块与数据字典的耦合度过高,不利于系统的模块化和扩展。
本文将探讨如何利用面向切面编程(AOP)的思想,通过注解的方式实现数据字典与其他业务模块的无侵入性整合。我们将重点关注如何通过AOP技术,使数据字典的值(value)在业务模块中自动转换为其对应的标签(label),从而实现业务逻辑与数据字典的松耦合,为系统的可维护性和拓展性提供新的解决方案。
2. 数据字典
2.1. 数据字典简介
数据字典是软件系统中用于管理常量、配置项或者枚举值的集合。它通常包括标签(label)和值(value)两部分,标签用于展示给用户或者其他系统模块,而值则是实际的业务逻辑中使用的数据标识。我举个例子吧,比如前端下拉框的渲染:

我们来看一下前端代码:
<template><el-select v-model="value" placeholder="请选择"><el-optionv-for="item in options":key="item.value":label="item.label":value="item.value"></el-option></el-select>
</template><script>export default {data() {return {options: [{value: '选项1',label: '黄金糕'}, {value: '选项2',label: '双皮奶'}, {value: '选项3',label: '蚵仔煎'}, {value: '选项4',label: '龙须面'}, {value: '选项5',label: '北京烤鸭'}],value: ''}}}
</script>从前端代码可看出 下拉框的渲染主要依靠value和label,常规的做法有枚举,或者后端建表后从表中获取,这两种方法都有许多弊端,枚举的话需要开发人员写死在代码中,再来看建表,如果每个下拉框都建表,那就会浪费大量后端资源,采用数据字典,统一管理各个功能模块的下拉框是较优的选择。
2.2. 数据字典如何管理各模块的下拉框
数据字典中是如何把各模块的下拉框管理起来的,在数据字典中一共管理三块内容,分别是实体类(表),属性字段,属性字段值(数据字典value和label);以前端的视角来看就是表单,下拉框,下拉框的值(数据字典label和value)。

3. 数据字典核心内容解读
3.1. 表结构
数据字典一共涵盖两张表,分别为dictionary_type和dictionary_value,下面将分别对这两张表进行解释。

dictionary_type
CREATE TABLE "public"."dictionary_type" ("id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,"type_name" varchar(50) COLLATE "pg_catalog"."default","type_description" varchar(100) COLLATE "pg_catalog"."default","parent_id" varchar(32) COLLATE "pg_catalog"."default","create_time" timestamp(6),"update_time" timestamp(6),"version" int4 DEFAULT 1,"type_label" varchar(50) COLLATE "pg_catalog"."default","is_deleted" int2 DEFAULT 0,CONSTRAINT "dictionary_type_pkey" PRIMARY KEY ("id")
)
;ALTER TABLE "public"."dictionary_type" OWNER TO "postgres";COMMENT ON COLUMN "public"."dictionary_type"."id" IS '主键ID';COMMENT ON COLUMN "public"."dictionary_type"."type_name" IS '字典类型名称';COMMENT ON COLUMN "public"."dictionary_type"."type_description" IS '字典类型描述';COMMENT ON COLUMN "public"."dictionary_type"."parent_id" IS '父节点id';COMMENT ON COLUMN "public"."dictionary_type"."create_time" IS '创建时间';COMMENT ON COLUMN "public"."dictionary_type"."update_time" IS '更新时间';COMMENT ON COLUMN "public"."dictionary_type"."version" IS '乐观锁';COMMENT ON COLUMN "public"."dictionary_type"."type_label" IS '字典类型标签';COMMENT ON TABLE "public"."dictionary_type" IS '字典类型表';dictionary_type表管理实体类和属性字段,当parent_id为null时则该数据为实体类,否则为归属某实体类下的属性字段。
dictionary_value
CREATE TABLE "public"."dictionary_value" ("id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,"value_name" varchar(50) COLLATE "pg_catalog"."default","type_id" varchar(32) COLLATE "pg_catalog"."default","create_time" timestamp(6),"update_time" timestamp(6),"version" int4 DEFAULT 1,"value_label" varchar(50) COLLATE "pg_catalog"."default","value_sort" int4,"is_deleted" int2,CONSTRAINT "dictionary_value_pkey" PRIMARY KEY ("id")
)
;ALTER TABLE "public"."dictionary_value" OWNER TO "postgres";COMMENT ON COLUMN "public"."dictionary_value"."id" IS '主键ID';COMMENT ON COLUMN "public"."dictionary_value"."value_name" IS '字典值名称';COMMENT ON COLUMN "public"."dictionary_value"."type_id" IS '字典类型id';COMMENT ON COLUMN "public"."dictionary_value"."create_time" IS '创建时间';COMMENT ON COLUMN "public"."dictionary_value"."update_time" IS '更新时间';COMMENT ON COLUMN "public"."dictionary_value"."version" IS '乐观锁';COMMENT ON COLUMN "public"."dictionary_value"."value_label" IS '字典值标签';COMMENT ON COLUMN "public"."dictionary_value"."value_sort" IS '字典值排序';COMMENT ON TABLE "public"."dictionary_value" IS '字典值表';dictionary_value 中管理某实体类下属性字段多对应的数据字典(label和value)。dictionary_value 和dictionary_type为多对一的关系(一个属性字段下对应多个数据字典值)。
3.2. 核心代码
3.2.1. 根据实体类名称获取下属数据字典
controller层
/*** 获取模块数据字典* @param typeName* @return*/@ApiOperation("获取某个模块下的数据字典")@GetMapping("/parameter/{typeName}")Map<String, Object> getCompleteParameter(@PathVariable("typeName") String typeName){return iDictionaryValueService.getParameters(typeName);}在上述代码中typeName为实体类名称。
service层
public Map<String, Object> getParameters(String typeName) {List<Map<String, Object>> dictParameters=baseMapper.getDictParameters(typeName);Set<Object> typeSet= new HashSet<>();Map<String,Object>resParam=new HashMap<>();for (Map<String, Object> dictParameter : dictParameters) {typeSet.add(dictParameter.get("type_name").toString());}for (Object o : typeSet) {List<ParameterVO> parameterVoList = new ArrayList<>();for (Map<String, Object> dictParameter : dictParameters) {if(dictParameter.get("type_name").toString().equals(o.toString())){ParameterVO parameterVO=new ParameterVO(dictParameter.get("value_name").toString(),dictParameter.get("value_label").toString());parameterVoList.add(parameterVO);}}resParam.put(o.toString(),parameterVoList);}return resParam;}mapper层
@Select("select a.value_name,a.value_label,a.type_name from dictionary_type d JOIN (select v.value_name,v.value_label,t.type_name,t.parent_id from dictionary_value v,dictionary_type t where v.type_id=t.id and v.is_deleted = 0 and t.is_deleted = 0)a on a.parent_id=d.id where d.type_name =#{typeName} AND d.is_deleted = 0")List<Map<String, Object>> getDictParameters(@Param("typeName") String typeName);3.2.2. 数据字典AOP切面
3.2.2.1. 场景模拟
先预设一个场景,假设有一张学生表需要整合数据字典,表结构如下:
CREATE TABLE "public"."student" ("id" varchar(32) COLLATE "pg_catalog"."default" NOT NULL,"name" varchar(50) COLLATE "pg_catalog"."default","blood_type" varchar(10) COLLATE "pg_catalog"."default","constellation_type" varchar(10) COLLATE "pg_catalog"."default","create_time" timestamp(6),"update_time" timestamp(6),"version" int4 DEFAULT 1,"is_deleted" int2 DEFAULT 0,CONSTRAINT "student_pkey" PRIMARY KEY ("id")
)
;ALTER TABLE "public"."student" OWNER TO "postgres";COMMENT ON COLUMN "public"."student"."blood_type" IS '血型';COMMENT ON COLUMN "public"."student"."constellation_type" IS '星座类型';在上表中星座和血型为需要和数据字典集成的字段。
3.2.2.2. 数据字典交互流程
AOP切面主要使用在分页查询和查询详情时。与数据字典有交集的实体类(Student)在分页或查询详情时技术流程图如下:

在上图中可看出与数据字典有交集的模块要进行分页或查询详情时,需要远程调用数据字典模块的相关接口,通过数据表中的value查询数据字典对应的label,最后封装为vo类返回给前端,如果把这个逻辑以硬编码的形式内嵌到查询详情代码中的话,有个比较致命的缺点就是代码的耦合性太高了,不利于模块的迁移复用。

上述代码为查看详情的部分代码,在封装VO类时进行了硬编码,可以看出,在耦合性极高的同时,代码的可读性也较差,故引入AOP切面,将远程调用label和将label值更新至VO类写入AOP切面。
3.2.2.3. AOP代码
数据字典AOP注解,它的作用是用于标记类的字段,指示字段的字典类型,并且在序列化过程中使用自定义的序列化器进行处理。
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@JacksonAnnotationsInside
@JsonSerialize(using = DictSerializer.class)
public @interface Dict {/** 字典类型 */String type();
}
通过 @JsonSerialize(using = DictSerializer.class),我们告诉 Jackson 在对带有 @Dict 注解的字段进行序列化时,使用 DictSerializer 类来处理序列化过程。
数据字典序列化类:
@Component
public class DictSerializer extends StdSerializer<Object> implements ContextualSerializer {private IDictionaryValueService dictionaryValueService;private String type;@Autowiredpublic DictSerializer(IDictionaryValueService dictionaryValueService) {super(Object.class);this.dictionaryValueService = dictionaryValueService;}public DictSerializer(String type, IDictionaryValueService dictionaryValueService) {super(Object.class);this.type = type;this.dictionaryValueService = dictionaryValueService;}@Overridepublic void serialize(Object value, JsonGenerator gen, SerializerProvider provider) throws IOException {if (Objects.isNull(value)) {gen.writeObject(value);return;}String label = null;if (dictionaryValueService != null && type != null) {try {String response = dictionaryValueService.getLabelByValue(value.toString());label = response; // 设置为空时返回 "null"} catch (RuntimeException e) {label = null;}}gen.writeObject(value);gen.writeFieldName(gen.getOutputContext().getCurrentName() + "Label");gen.writeObject(label);}@Overridepublic JsonSerializer<?> createContextual(SerializerProvider prov, BeanProperty property) throws JsonMappingException {if (property != null) {Dict dict = property.getAnnotation(Dict.class);if (dict != null) {return new DictSerializer(dict.type(), dictionaryValueService);}}return this;}}DictSerializer 是一个用于处理带有 @Dict 注解字段的自定义 Jackson 序列化器。它利用注入的 IDictionaryValueService 接口,根据字段值获取对应的标签,并将原始值与标签作为新字段输出,实现了动态字典值的序列化处理。
我写的示例代码把AOP相关代码写到了数据字典模块,但是实际项目中应当放到common模块,方便所有和数据字典有交集的业务模块调用。
4. 数据字典使用
基于第3章预设的场景,我们这章直接实操来看一下如何使用数据字典(ps,我将Student类相关代码写到了数据字典中,实际应该是在别的模块,这里为了方便我就写到了一个模块)。
4.1. 新增Student类对应数据字典值
新增dictionary_type表数据:

新增dictionary_value 表数据:

根据实体类名获取该实体类对应的数据字典,返回至前端进行下拉框动态渲染:

4.2. 新增学生数据
这里新增和平时操作无异:
@PostMapping("")public boolean saveStudent(@RequestBody Student student){return studentService.save(student);}在传数据字典值时只需要传入value值即可:

4.3. 根据id查询学生数据详细信息
编写VO类:
@Data
public class StudentVO {private String id;private String name;@Dict(type = "bloodType")private String bloodType;@Dict(type = "constellationType")private String constellationType;@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone="GMT+8")private Date createTime;
}
查看详情方法:
public StudentVO getStudentInfoById(String id) {Student student = baseMapper.selectById(id);StudentVO studentVO= BeanCopyUtils.copyBean(student,StudentVO.class);return studentVO;}运行结果:

5. 结语
本文探讨了如何通过面向切面编程(AOP)实现数据字典与业务模块的无侵入整合。通过自定义注解和序列化器,我们有效地降低了系统中业务模块与数据字典的耦合度,提升了系统的灵活性和可维护性。希望本文能为读者在实际项目中应用这些技术提供启发,进一步提升软件开发的效率和质量。若本文对你有帮助,别忘记三连哦~

6. 参考链接
基于Springboot,一个注解搞定数据字典问题 - 掘金 (juejin.cn)
相关文章:
基于AOP的数据字典实现:实现前端下拉框的可配置更新
作者:后端小肥肠 创作不易,未经允许严禁转载。 目录 1. 前言 2. 数据字典 2.1. 数据字典简介 2.2. 数据字典如何管理各模块的下拉框 3. 数据字典核心内容解读 3.1. 表结构 3.2. 核心代码 3.2.1. 根据实体类名称获取下属数据字典 3.2.2. 数据字…...

基于CentOS Stream 9平台搭建RabbitMQ3.13.4以及开机自启
1. erlang与RabbitMQ对应版本参考:https://www.rabbitmq.com/which-erlang.html 2. 安装erlang 官网:https://www.erlang.org/downloads GitHub: https://github.com/rabbitmq/erlang-rpm/releases 2.1 安装依赖: yum -y install gcc glib…...

9、Redis 高级数据结构 HyperLogLog 和事务
1. HyperLogLog 简介 HyperLogLog 是一种用于基数估计的概率数据结构。它并不是一种新的数据结构,而是 Redis 中的一种字符串类型。HyperLogLog 的主要优点是能够利用极少的内存空间完成对独立总数的统计,适用于统计大量数据的独立元素数量,…...
如何在 MyBatis 中使用 XML 和注解混合配置方式)
MyBatis(30)如何在 MyBatis 中使用 XML 和注解混合配置方式
在MyBatis中,你可以灵活地选择XML配置方式、注解方式,或者将这两种方式混合使用来配置你的映射器(Mapper)。使用混合配置方式,你可以结合两者的优势,例如,利用XML配置复杂查询和动态SQL…...

强化学习与控制模型结合例子
强化学习与模型控制结合 强化学习(Reinforcement Learning, RL)与控制模型结合,可以通过整合传统控制理论和现代RL算法,利用控制模型提供的动态信息和稳定性保障,同时利用RL的学习能力优化控制策略。这种结合的方式被称为模型辅助强化学习(Model-Assisted Reinforcement…...

RKNN3588——利用推理YOLOv8推理图片
1. yolov8_test.py import os import cv2 import numpy as np from class_type import CLASSES# 设置对象置信度阈值和非极大值抑制(NMS)阈值。 OBJ_THRESH 0.25 NMS_THRESH 0.45 IMG_SIZE (640, 640)def filter_boxes(boxes, box_confidences, box_…...

【ARMv8/v9 GIC 系列 1.7 -- GIC PPI | SPI | SGI | LPI 中断使能配置介绍】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 GIC 各种中断使能配置PPIs(每个处理器私有中断)SPIs(共享外设中断)SGIs(软件生成的中断)LPIs(局部中断)GIC 各种中断使能配置 在ARM GICv3和GICv4架构中,不同类型的中断(如PPIs、SPIs、SGIs和LPIs)可以通过不同的方式进…...

uniapp开发射击类小游戏
使用 UniApp 开发射击类小游戏可以遵循以下步骤: 项目规划 确定游戏的主题、玩法、关卡设计等。规划游戏的界面布局,包括游戏主界面、游戏场景、得分显示等。 技术准备 熟悉 UniApp 的开发文档和相关 API。准备所需的开发工具,如 HBuilderX。…...

spring6框架解析(by尚硅谷)
文章目录 spring61. 一些基本的概念、优势2. 入门案例实现maven聚合工程创建步骤分析实现过程 3. IoC(Inversion of Control)基于xml的bean环境搭建获取bean获取接口创建实现类依赖注入 setter注入 和 构造器注入原生方式的setter注入原生方式的构造器注…...

Open3D 计算点云的马氏距离
目录 一、概述 1.1原理 1.2应用 二、代码实现 三、实现效果 3.1原始点云 3.2计算后点云 一、概述 1.1原理 马氏距离(Mahalanobis Distance)是一种度量多维数据点与数据分布中心之间距离的方法。与欧几里得距离不同,马氏距离考虑了数据…...
Java事务(Transaction)
Java事务(Transaction)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列组成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务的引入主要是为了解决并发操作数据…...

算法 —— 二分查找
目录 二分查找 在排序数组中查找元素的第一个和最后一个位置 搜索插入位置 x的平方根 山峰数组的峰顶索引 寻找峰值 搜索旋转排序数组中的最⼩值 点名 二分查找模板分为三种:1、朴素的二分模板 2、查找左边界的二分模板 3、查找右边界的二分模板…...

Mysql explain语句详解与实例展示
首先简单介绍sql: SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句…...

Python基础问题汇总
为什么学习Python? 易学易用:Python语法简洁清晰,易于学习。广泛的应用领域:适用于Web开发、数据科学、人工智能、自动化脚本等多种场景。强大的库支持:拥有丰富的第三方库,如NumPy、Pandas、TensorFlow等…...

【讲解下iOS语言基础】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...
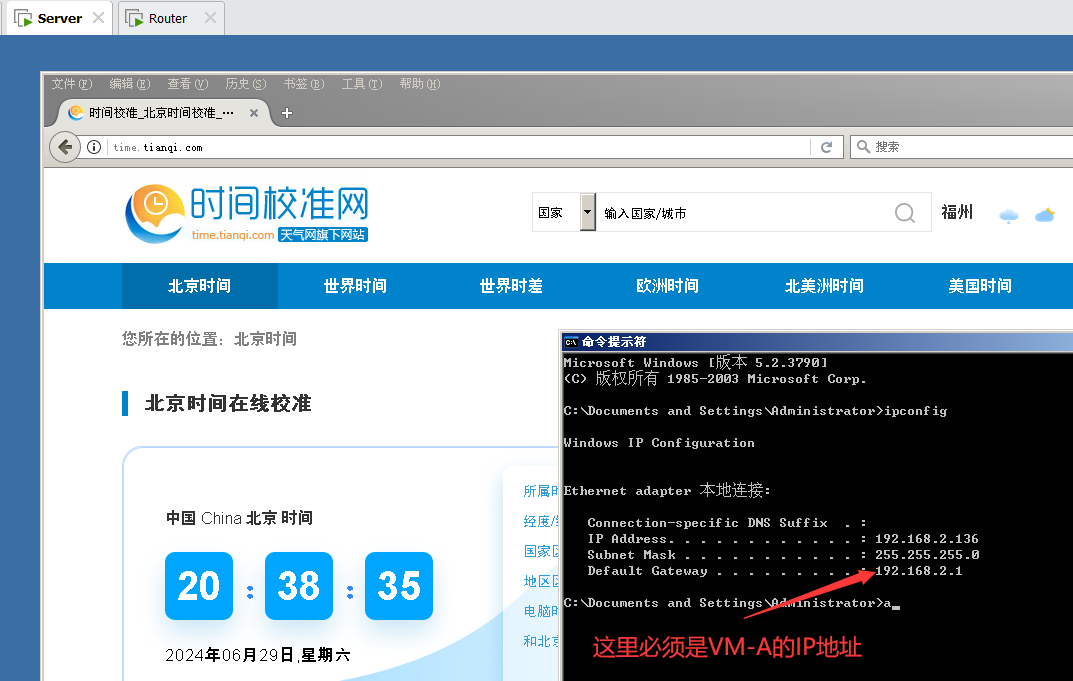
【网络安全】实验一(网络拓扑环境的搭建)
一、本次实验的实验目的 学习利用 VMware 创建虚拟环境 学习利用 VMware 搭建各自网络拓扑环境 二、创建虚拟机 三、克隆虚拟机 选择克隆的系统必须处于关机状态。 方法一: 方法二: 需要修改克隆计算机的名字,避免产生冲突。 四、按照要求完…...
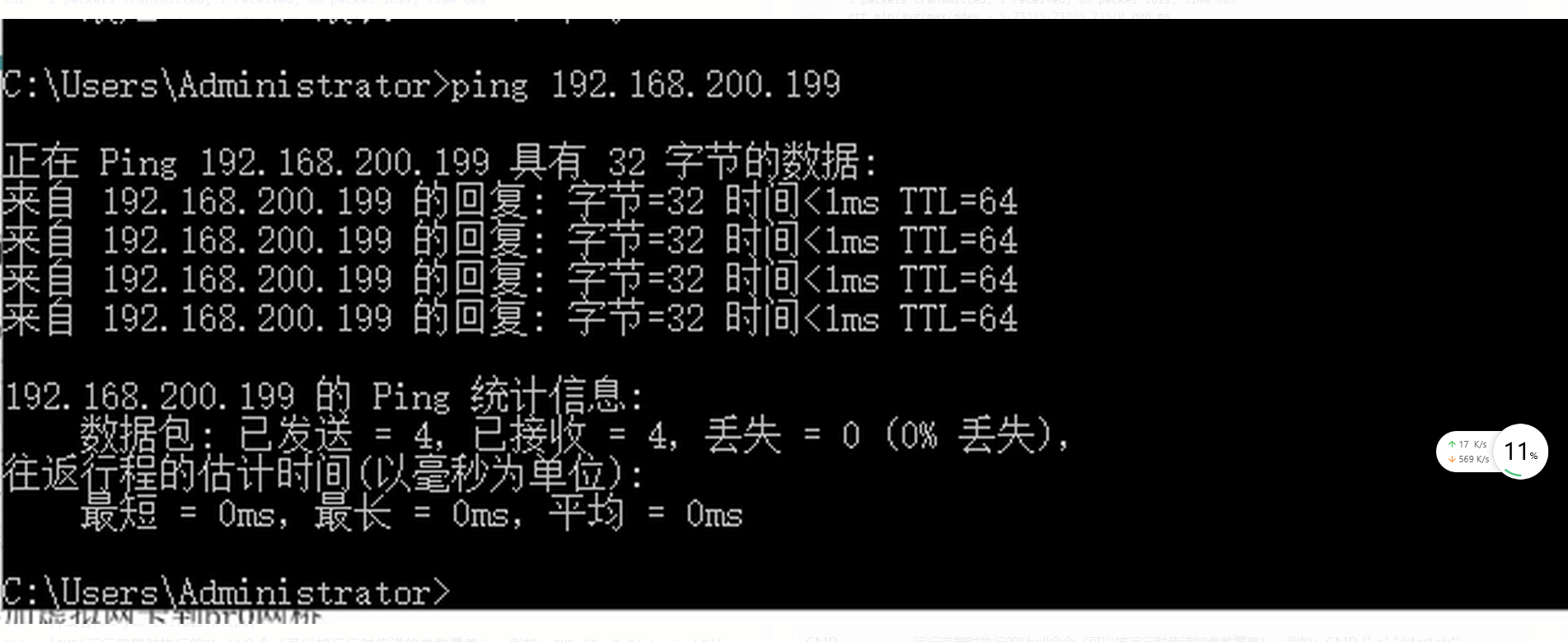
Docker-基础
一,Docker简介,功能特性与应用场景 1.1 Docker简介 Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器…...
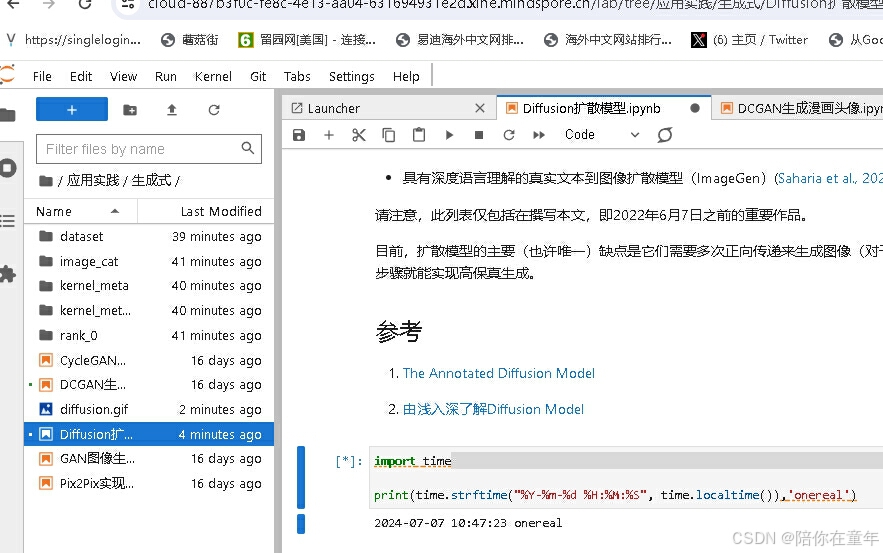
《昇思25天学习打卡营第14天|onereal》
第14天学习内容如下: Diffusion扩散模型 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,…...

LeetCode 744, 49, 207
目录 744. 寻找比目标字母大的最小字母题目链接标签思路代码 49. 字母异位词分组题目链接标签思路代码 207. 课程表题目链接标签思路代码 744. 寻找比目标字母大的最小字母 题目链接 744. 寻找比目标字母大的最小字母 标签 数组 二分查找 思路 本题比 基础二分查找 难的一…...
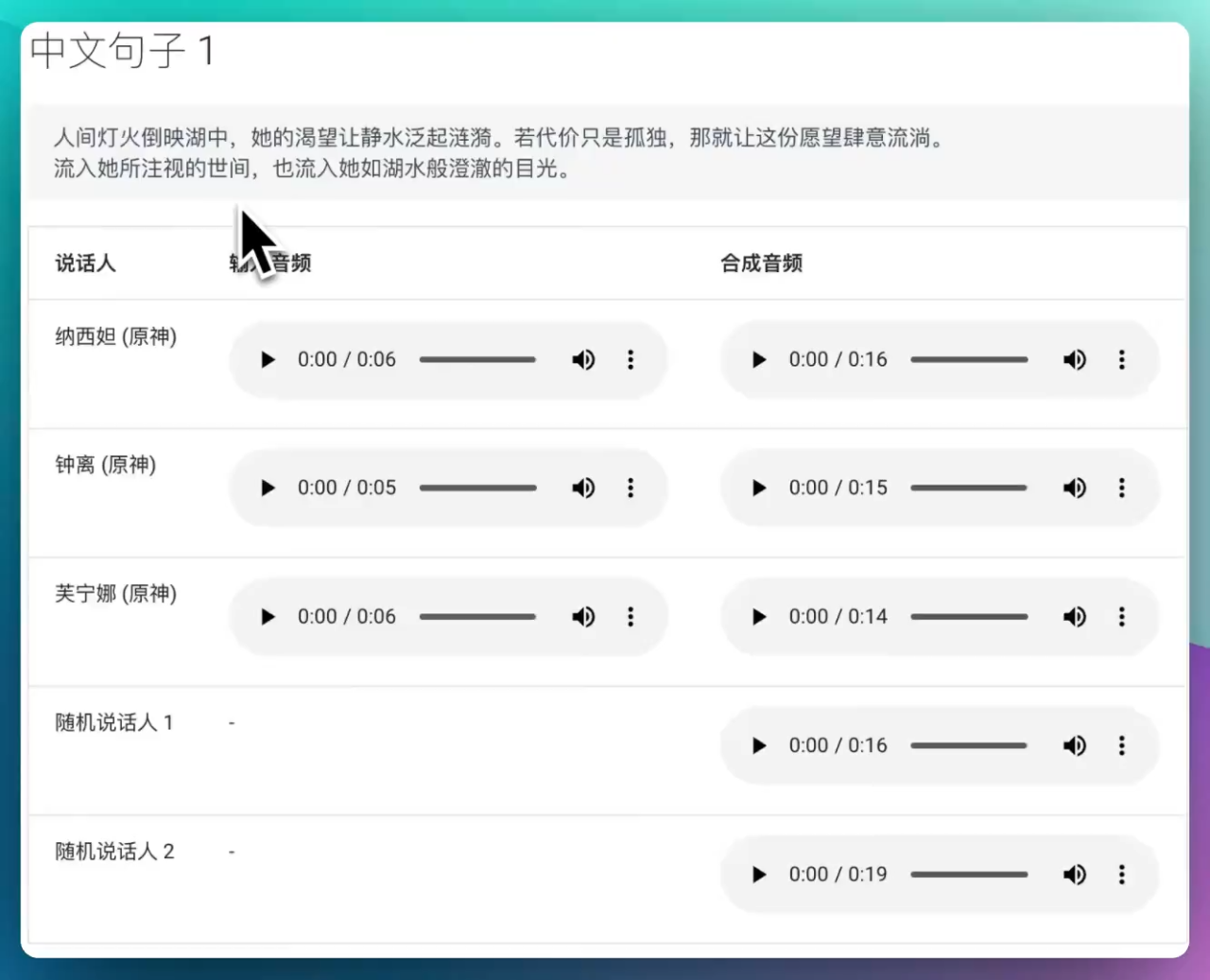
【AI资讯】可以媲美GPT-SoVITS的低显存开源文本转语音模型Fish Speech
Fish Speech是一款由fishaudio开发的全新文本转语音工具,支持中英日三种语言,语音处理接近人类水平,使用Flash-Attn算法处理大规模数据,提供高效、准确、稳定的TTS体验。 Fish Audio...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

3PEAK思瑞浦 TPA6531-S5TR SOT23-5 运算放大器
特性 供电电压:1.75V至5.5V 偏移电压:1.5mV(最大值) 最大可调工作频率:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1赫兹至10赫兹电压噪声:1伏峰值 开关电源时无显著输出抖动 低功耗:每通道最大25安培 工作温度范围:-40C至125C...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环
更多请点击: https://codechina.net 第一章:LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环 核心架构概览 Claude端到端测试架构采用三层解耦设计:输入层(动态用…...

暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南
暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要轻松修改暗黑破坏神2存档却不懂十六进制?d2s-editor是你的完美解决方案!这款基于…...