实例演示Kafka-Stream消息流式处理流程及原理
以下结合案例:统计消息中单词出现次数,来测试并说明kafka消息流式处理的执行流程
Maven依赖
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency></dependencies>
准备工作
首先编写创建三个类,分别作为消息生产者、消息消费者、流式处理者
KafkaStreamProducer:消息生产者
public class KafkaStreamProducer {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties properties = new Properties();//kafka的连接地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092");//发送失败,失败的重试次数properties.put(ProducerConfig.RETRIES_CONFIG, 5);//消息key的序列化器properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kafka-stream-topic-input", "hello kafka");producer.send(producerRecord);}producer.close();}
}
该消息生产者向主题kafka-stream-topic-input发送五次hello kafka
KafkaStreamConsumer:消息消费者
public class KafkaStreamConsumer {public static void main(String[] args) {Properties properties = new Properties();//kafka的连接地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092");//消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");//消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//手动提交偏移量properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);//订阅主题consumer.subscribe(Collections.singletonList("kafka-stream-topic-output"));try {while (true) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println("consumerRecord.key() = " + consumerRecord.key());System.out.println("consumerRecord.value() = " + consumerRecord.value());}// 异步提交偏移量consumer.commitAsync();}} catch (Exception e) {e.printStackTrace();} finally {// 同步提交偏移量consumer.commitSync();}}
}
KafkaStreamQuickStart:流式处理类
public class KafkaStreamQuickStart {public static void main(String[] args) {Properties properties = new Properties();properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092");properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-quickstart");StreamsBuilder streamsBuilder = new StreamsBuilder();//流式计算streamProcessor(streamsBuilder);KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), properties);kafkaStreams.start();}/*** 消息格式:hello world hello world* 配置并处理流数据。* 使用StreamsBuilder创建并配置KStream,对输入的主题中的数据进行处理,然后将处理结果发送到输出主题。* 具体处理包括:分割每个消息的值,按值分组,对每个分组在10秒的时间窗口内进行计数,然后将结果转换为KeyValue对并发送到输出主题。** @param streamsBuilder 用于构建KStream对象的StreamsBuilder。*/private static void streamProcessor(StreamsBuilder streamsBuilder) {// 从"kafka-stream-topic-input"主题中读取数据流KStream<String, String> stream = streamsBuilder.stream("kafka-stream-topic-input");System.out.println("stream = " + stream);// 将每个值按空格分割成数组,并将数组转换为列表,以扩展单个消息的值stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> {String[] valAry = value.split(" ");return Arrays.asList(valAry);})// 按消息的值进行分组,为后续的窗口化计数操作做准备.groupBy((key, value) -> value)// 定义10秒的时间窗口,在每个窗口内对每个分组进行计数.windowedBy(TimeWindows.of(Duration.ofSeconds(10))).count()// 将计数结果转换为流,以便进行进一步的处理和转换.toStream()// 显示键值对的内容,并将键和值转换为字符串格式.map((key, value) -> {System.out.println("key = " + key);System.out.println("value = " + value);return new KeyValue<>(key.key().toString(), value.toString());})// 将处理后的流数据发送到"kafka-stream-topic-output"主题.to("kafka-stream-topic-output");}}
该处理类首先从主题kafka-stream-topic-input中获取消息数据,经处理后发送到主题kafka-stream-topic-output中,再由消息消费者KafkaStreamConsumer进行消费
执行结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-leHqMQFF-1720347997120)(https://i-blog.csdnimg.cn/direct/b3d481c37658429fb7da09bf25b2be8f.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pohj73CM-1720347997122)(https://i-blog.csdnimg.cn/direct/decf96e181f1475c8a829cd126d033a4.png)]
流式处理流程及原理说明
初始阶段
当从输入主题kafka-stream-topic-input读取数据流时,每个消息都是一个键值对。假设输入消息的键是null或一个特定的字符串,这取决于消息是如何被发送到输入主题的。
KStream<String, String> stream = streamsBuilder.stream("kafka-stream-topic-input");
分割消息值
使用flatMapValues方法分割消息的值,但这个操作不会改变消息的键。如果输入消息的键是null,那么在这个阶段消息的键仍然是null。
stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> {String[] valAry = value.split(" ");return Arrays.asList(valAry);
})
按消息的值进行分组
在 Kafka Streams 中,当使用groupBy方法对流进行分组时,实际上是在指定一个新的键,这个键将用于后续的窗口化操作和聚合操作。在这个案例中groupBy方法被用来按消息的值进行分组:
.groupBy((key, value) -> value)
这意味着在分组操作之后,流中的每个消息的键被设置为消息的值。因此,当你在后续的map方法中看到key参数时,这个key实际上是消息的原始值,因为在groupBy之后,消息的值已经变成了键。
定义时间窗口并计数
在这个阶段,消息被窗口化并计数,但是键保持不变。
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
.count()
将计数结果转换为流
当将计数结果转换为流时,键仍然是之前分组时的键
.toStream()
处理和转换结果
在map方法中,你看到的key参数实际上是分组后的键,也就是消息的原始值:
.map((key, value) -> {System.out.println("key = " + key);System.out.println("value = " + value);return new KeyValue<>(key.key().toString(), value.toString());
})
map方法中的key.key().toString()是为了获取键的字符串表示,而value.toString()是为了将计数值转换为字符串。
将处理后的数据发送到输出主题
.to("kafka-stream-topic-output");
相关文章:

实例演示Kafka-Stream消息流式处理流程及原理
以下结合案例:统计消息中单词出现次数,来测试并说明kafka消息流式处理的执行流程 Maven依赖 <dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusio…...
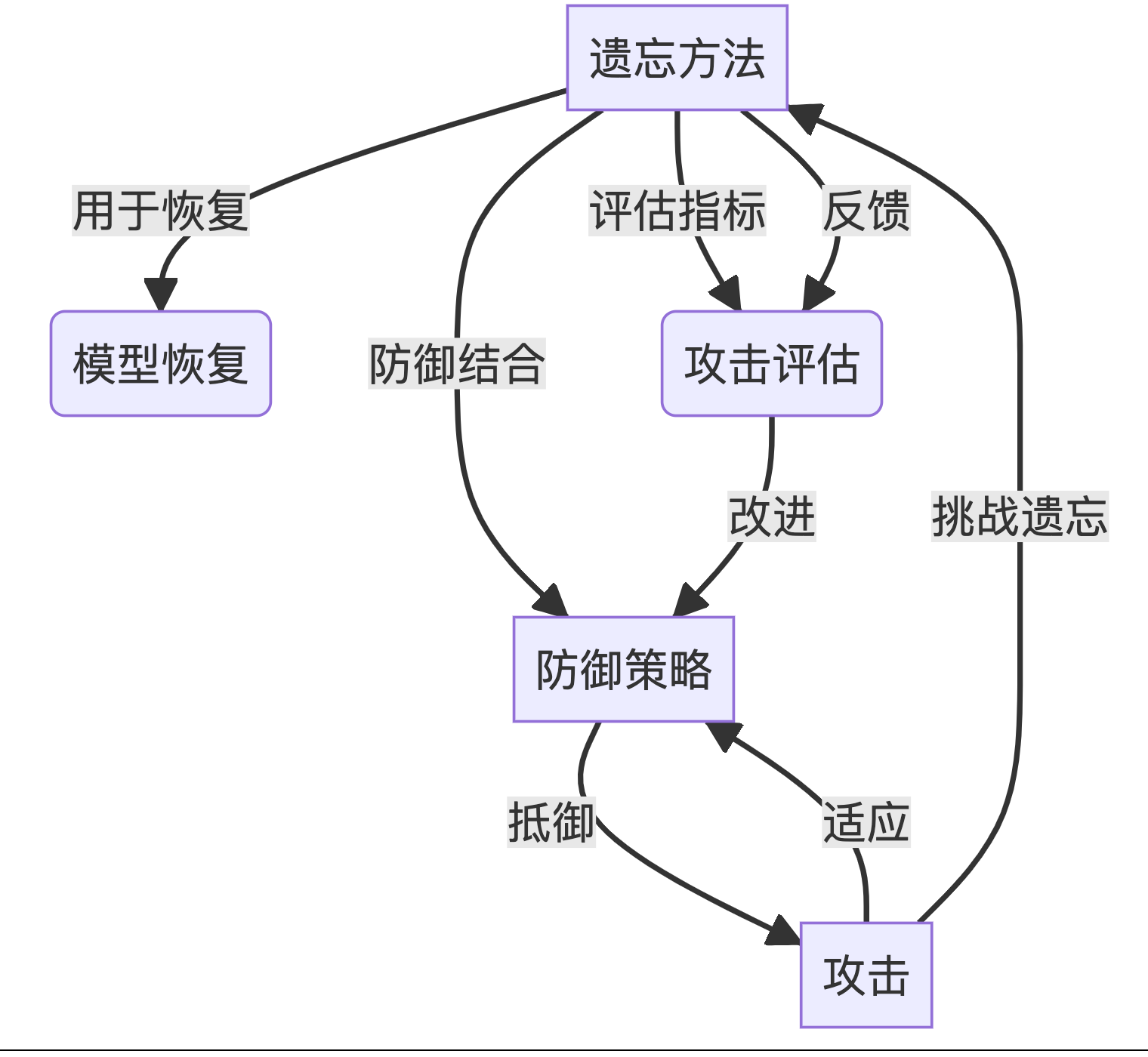
【博士每天一篇文献-综述】Threats, Attacks, and Defenses in Machine Unlearning A Survey
1 介绍 年份:2024 作者:刘子耀,陈晨,南洋理工大学 期刊: 未发表 引用量:6 Liu Z, Ye H, Chen C, et al. Threats, attacks, and defenses in machine unlearning: A survey[J]. arXiv preprint arXiv:2403…...

Python数据分析实战,运输车辆驾驶行为分析,案例教程编程实例课程详解
引言 运输车辆的安全驾驶行为分析是确保道路安全、提高运输效率的重要环节。随着数据采集技术的发展和数据分析工具的普及,利用Python进行数据分析已成为这一领域的重要工具。本文将详细介绍如何使用Python进行运输车辆驾驶行为分析,涵盖数据采集、数据预处理、数据分析及结果…...

网络安全法对等级保护中的权利和义务有何规范?
在数字时代的交响乐章中,网络安全法与等级保护共同编织了一曲关于权利与义务的和谐旋律。《中华人民共和国网络安全法》作为我国网络安全领域的基本法,对等级保护提出了明确的规范,旨在构建一个安全、有序的网络空间。本文将深入解析网络安全…...

苹果清理软件:让你的设备焕然一新
随着时间的推移,无论是Mac电脑还是iOS设备,都可能会因为积累的垃圾文件、缓存、未使用的应用和其他冗余数据而开始表现出性能下降。这不仅会占用宝贵的存储空间,还可能影响设备的响应速度和电池寿命。幸运的是,有多种苹果清理软件…...

vue前端通过sessionStorage缓存字典
正常来说,一个vue项目前端需要用到的一些翻译字典对象保存方式一般有多重, 新建js文件方式保存通过vuex方式保存通过sessionStorage保存通过localStorage保存 正常以上几点的保存方式是够用了。 但是,当有字典不能以文件方式保存并且字典量…...

React Redux使用@reduxjs/toolkit的hooks
关于redux的学习过程需要几个官网,有redux官网,React Redux官网和Redux Toolkit的官网。 其中后者的中文没有找到,不过其中的使用在React Redux官网的快速入门中有介绍。 现在一般不使用connect借接口了。 对于借助Redux Toolkit的React Redu…...

Rejetto HFS 服务器存在严重漏洞受到攻击
AhnLab 报告称 ,黑客正在针对旧版本的 Rejetto HTTP 文件服务器 (HFS) 注入恶意软件和加密货币挖矿程序。 然而,由于存在错误, Rejetto 警告用户不要使用 2.3 至 2.4 版本。 2.3m 版本在个人、小型团队、教育机构和测试网络文件共享的开发…...

Electron开发 - 如何在主进程Main中让node-fetch使用系统代理
背景 开发过程中,用户设置的系统代理是不同的,比如公司内的服务器,所以就要动态地使用系统代理来访问,但是主进程默认为控制台级别的请求,不走系统代理,除非你指定系统代理配置,这个就就有了这…...

vue2 webpack使用optimization.splitChunks分包,实现按需引入,进行首屏加载优化
optimization.splitChunks的具体功能和配置信息可以去网上自行查阅。 这边简单讲一下他的使用场景、作用、如何使用: 1、没用使用splitChunks进行分包之前,所有模块都揉在一个文件里,那么当这个文件足够大、网速又一般的时候,首…...

深入理解 Docker 容器技术
一、引言 在当今的云计算和软件开发领域,Docker 容器技术已经成为了一项不可或缺的工具。它极大地改变了应用程序的部署和运行方式,为开发者和运维人员带来了诸多便利。 二、Docker 容器是什么? Docker 容器是一种轻量级、可移植、自包含的…...

redis并发、穿透、雪崩
Redis如何实现高并发 首先是单线程模型:redis采用单线程可以避免多线程下切换和竞争的开销,提高cpu的利用率,如果是多核cpu,可以部署多个redis实例。基于内存的数据存储:redis将数据存储在内存中,相比于硬…...

【架构设计】-- ACK 机制
1、ACK 机制的定义 ACK(全称:acknowledgement) 机制是一种确认机制,起源于TCP报文到达确认(ACK)机制(参考:TCP报文到达确认(ACK)机制_tcp接收方在收到一个报文…...

这些网络安全知识,请务必牢记!
#网络安全# 随着“互联网”时代的到来,人们的生活变得更加便利,但电信诈骗、信息泄露、恶意软件等也随之而来。面对网络这把双刃剑,如何绷紧思想“安全弦”,正确安全使用网络呢?今天,让我们跟随泰顺网信IP…...

学习笔记——交通安全分析11
目录 前言 当天学习笔记整理 4信控交叉口交通安全分析 结束语 前言 #随着上一轮SPSS学习完成之后,本人又开始了新教材《交通安全分析》的学习 #整理过程不易,喜欢UP就点个免费的关注趴 #本期内容接上一期10笔记 #最近确实太懒了,接受…...

Python 3 编程第一步
Python 3 编程第一步 Python 是一种广泛使用的高级编程语言,以其简洁明了的语法和强大的功能而闻名。Python 3 是该语言的最新版本,它在许多方面对早期的 Python 2 进行了改进和更新。本篇文章将作为 Python 3 编程的入门指南,带你迈出编程的第一步。 Python 3 的安装 首…...

【eMTC】eMTC 窄带以及带宽的关系
1 概述 eMTC 传输进行通信时,一般采用1.4M带宽,在和LTE小区联合部署时,需要将LTE的带宽分割成以1.4M带宽为粒度的单位,这个单位在协议上叫做窄带。 2 窄带定义 3 参考文献 36.211...

【MySQL】mysqldumpslow工具 -- 总结慢查询日志文件
1. 作用 在平时使用MySQL数据库时,经常进行查询操作,有些查询语句执行的时间非常长,当执行时间超过设定的阈值时,我们称这个查询为慢查询,慢查询的相关信息通常需要用日志记录下来称为慢查询日志,mysqldum…...

【mindspore进阶】02-ResNet50迁移学习
Mindspore 应用(2)ResNet50迁移学习 在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化…...

智能决策的艺术:揭秘决策树的奇妙原理与实战应用
引言 决策树(Decision Tree)是一种常用的监督学习算法,适用于分类和回归任务。它通过学习数据中的规则生成树状模型,从而做出预测决策。决策树因其易于理解和解释、无需大量数据预处理等优点,广泛应用于各种机器学习任…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...