【mindspore进阶】02-ResNet50迁移学习
Mindspore 应用(2)ResNet50迁移学习
在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。
迁移学习详细内容见Stanford University CS231n。
数据准备
下载数据集
下载案例所用到的狗与狼分类数据集,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验证图像。使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。
def say_hi(name: str) -> str:return f'Hi {name}'greeting = say_hi(123)
print(greeting)
Hi 123
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by:
from download import downloaddataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)
Creating data folder...
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip (11.3 MB)file_sizes: 100%|██████████████████████████| 11.9M/11.9M [00:00<00:00, 92.3MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./datasets-Canidae'./datasets-Canidae'
数据集的目录结构如下:
datasets-Canidae/data/
└── Canidae├── train│ ├── dogs│ └── wolves└── val├── dogs└── wolves
加载数据集
狼狗数据集提取自ImageNet分类数据集,使用mindspore.dataset.ImageFolderDataset接口来加载数据集,并进行相关图像增强操作。
首先执行过程定义一些输入:
batch_size = 18 # 批量大小
image_size = 224 # 训练图像空间大小
num_epochs = 50 # 训练周期数
lr = 0.001 # 学习率
momentum = 0.9 # 动量
workers = 4 # 并行线程个数
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"# 创建训练数据集def create_dataset_canidae(dataset_path, usage):"""数据加载"""data_set = ds.ImageFolderDataset(dataset_path,num_parallel_workers=workers,shuffle=True,)# 数据增强操作mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]std = [0.229 * 255, 0.224 * 255, 0.225 * 255]scale = 32if usage == "train":# Define map operations for training datasettrans = [vision.RandomCropDecodeResize(size=image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),vision.RandomHorizontalFlip(prob=0.5),vision.Normalize(mean=mean, std=std),vision.HWC2CHW()]else:# Define map operations for inference datasettrans = [vision.Decode(),vision.Resize(image_size + scale),vision.CenterCrop(image_size),vision.Normalize(mean=mean, std=std),vision.HWC2CHW()]# 数据映射操作data_set = data_set.map(operations=trans,input_columns='image',num_parallel_workers=workers)# 批量操作data_set = data_set.batch(batch_size)return data_setdataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()
数据集可视化
从mindspore.dataset.ImageFolderDataset接口中加载的训练数据集返回值为字典,用户可通过 create_dict_iterator 接口创建数据迭代器,使用 next 迭代访问数据集。本章中 batch_size 设为18,所以使用 next 一次可获取18个图像及标签数据。
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]print("Tensor of image", images.shape)
print("Labels:", labels)
Tensor of image (18, 3, 224, 224)
Labels: [0 1 0 1 0 0 0 0 1 1 0 0 0 1 1 0 0 1]
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。
import matplotlib.pyplot as plt
import numpy as np# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}plt.figure(figsize=(5, 5))
for i in range(4):# 获取图像及其对应的labeldata_image = images[i].asnumpy()data_label = labels[i]# 处理图像供展示使用data_image = np.transpose(data_image, (1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])data_image = std * data_image + meandata_image = np.clip(data_image, 0, 1)# 显示图像plt.subplot(2, 2, i+1)plt.imshow(data_image)plt.title(class_name[int(labels[i].asnumpy())])plt.axis("off")plt.show()

训练模型
本章使用ResNet50模型进行训练。搭建好模型框架后,通过将pretrained参数设置为True来下载ResNet50的预训练模型并将权重参数加载到网络中。
构建Resnet50网络
from typing import Type, Union, List, Optional
from mindspore import nn, train
from mindspore.common.initializer import Normalweight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
class ResidualBlockBase(nn.Cell):expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等def __init__(self, in_channel: int, out_channel: int,stride: int = 1, norm: Optional[nn.Cell] = None,down_sample: Optional[nn.Cell] = None) -> None:super(ResidualBlockBase, self).__init__()if not norm:self.norm = nn.BatchNorm2d(out_channel)else:self.norm = normself.conv1 = nn.Conv2d(in_channel, out_channel,kernel_size=3, stride=stride,weight_init=weight_init)self.conv2 = nn.Conv2d(in_channel, out_channel,kernel_size=3, weight_init=weight_init)self.relu = nn.ReLU()self.down_sample = down_sampledef construct(self, x):"""ResidualBlockBase construct."""identity = x # shortcuts分支out = self.conv1(x) # 主分支第一层:3*3卷积层out = self.norm(out)out = self.relu(out)out = self.conv2(out) # 主分支第二层:3*3卷积层out = self.norm(out)if self.down_sample is not None:identity = self.down_sample(x)out += identity # 输出为主分支与shortcuts之和out = self.relu(out)return out
class ResidualBlock(nn.Cell):expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍def __init__(self, in_channel: int, out_channel: int,stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channel, out_channel,kernel_size=1, weight_init=weight_init)self.norm1 = nn.BatchNorm2d(out_channel)self.conv2 = nn.Conv2d(out_channel, out_channel,kernel_size=3, stride=stride,weight_init=weight_init)self.norm2 = nn.BatchNorm2d(out_channel)self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,kernel_size=1, weight_init=weight_init)self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)self.relu = nn.ReLU()self.down_sample = down_sampledef construct(self, x):identity = x # shortscuts分支out = self.conv1(x) # 主分支第一层:1*1卷积层out = self.norm1(out)out = self.relu(out)out = self.conv2(out) # 主分支第二层:3*3卷积层out = self.norm2(out)out = self.relu(out)out = self.conv3(out) # 主分支第三层:1*1卷积层out = self.norm3(out)if self.down_sample is not None:identity = self.down_sample(x)out += identity # 输出为主分支与shortcuts之和out = self.relu(out)return out
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],channel: int, block_nums: int, stride: int = 1):down_sample = None # shortcuts分支if stride != 1 or last_out_channel != channel * block.expansion:down_sample = nn.SequentialCell([nn.Conv2d(last_out_channel, channel * block.expansion,kernel_size=1, stride=stride, weight_init=weight_init),nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)])layers = []layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))in_channel = channel * block.expansion# 堆叠残差网络for _ in range(1, block_nums):layers.append(block(in_channel, channel))return nn.SequentialCell(layers)
from mindspore import load_checkpoint, load_param_into_netclass ResNet(nn.Cell):def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],layer_nums: List[int], num_classes: int, input_channel: int) -> None:super(ResNet, self).__init__()self.relu = nn.ReLU()# 第一个卷积层,输入channel为3(彩色图像),输出channel为64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)self.norm = nn.BatchNorm2d(64)# 最大池化层,缩小图片的尺寸self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')# 各个残差网络结构块定义,self.layer1 = make_layer(64, block, 64, layer_nums[0])self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)# 平均池化层self.avg_pool = nn.AvgPool2d()# flattern层self.flatten = nn.Flatten()# 全连接层self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)def construct(self, x):x = self.conv1(x)x = self.norm(x)x = self.relu(x)x = self.max_pool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avg_pool(x)x = self.flatten(x)x = self.fc(x)return xdef _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str,input_channel: int):model = ResNet(block, layers, num_classes, input_channel)if pretrained:# 加载预训练模型download(url=model_url, path=pretrianed_ckpt, replace=True)param_dict = load_checkpoint(pretrianed_ckpt)load_param_into_net(model, param_dict)return modeldef resnet50(num_classes: int = 1000, pretrained: bool = False):"ResNet50模型"resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,pretrained, resnet50_ckpt, 2048)
固定特征进行训练
使用固定特征进行训练的时候,需要冻结除最后一层之外的所有网络层。通过设置 requires_grad == False 冻结参数,以便不在反向传播中计算梯度。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import timenet_work = resnet50(pretrained=True)# 全连接层输入层的大小
in_channels = net_work.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net_work.fc = head# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net_work.avg_pool = avg_pool# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():if param.name not in ["fc.weight", "fc.bias"]:param.requires_grad = False# 定义优化器和损失函数
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=lr, momentum=0.5)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')def forward_fn(inputs, targets):logits = net_work(inputs)loss = loss_fn(logits, targets)return lossgrad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)def train_step(inputs, targets):loss, grads = grad_fn(inputs, targets)opt(grads)return loss# 实例化模型
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt (97.7 MB)file_sizes: 100%|█████████████████████████████| 102M/102M [00:00<00:00, 137MB/s]
Successfully downloaded file to ./LoadPretrainedModel/resnet50_224_new.ckpt
训练和评估
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()num_epochs = 5# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
# 开始循环训练
print("Start Training Loop ...")best_acc = 0for epoch in range(num_epochs):losses = []net_work.set_train()epoch_start = time.time()# 为每轮训练读入数据for i, (images, labels) in enumerate(data_loader_train):labels = labels.astype(ms.int32)loss = train_step(images, labels)losses.append(loss)# 每个epoch结束后,验证准确率acc = model1.eval(dataset_val)['Accuracy']epoch_end = time.time()epoch_seconds = (epoch_end - epoch_start) * 1000step_seconds = epoch_seconds/step_size_trainprint("-" * 20)print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (epoch+1, num_epochs, sum(losses)/len(losses), acc))print("epoch time: %5.3f ms, per step time: %5.3f ms" % (epoch_seconds, step_seconds))if acc > best_acc:best_acc = accif not os.path.exists(best_ckpt_dir):os.mkdir(best_ckpt_dir)ms.save_checkpoint(net_work, best_ckpt_path)print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "f"save the best ckpt file in {best_ckpt_path}", flush=True)
Start Training Loop ...
--------------------
Epoch: [ 1/ 5], Average Train Loss: [0.667], Accuracy: [0.583]
epoch time: 175554.276 ms, per step time: 12539.591 ms
--------------------
Epoch: [ 2/ 5], Average Train Loss: [0.572], Accuracy: [0.817]
epoch time: 1043.899 ms, per step time: 74.564 ms
--------------------
Epoch: [ 3/ 5], Average Train Loss: [0.506], Accuracy: [0.983]
epoch time: 849.647 ms, per step time: 60.689 ms
--------------------
Epoch: [ 4/ 5], Average Train Loss: [0.439], Accuracy: [0.983]
epoch time: 885.925 ms, per step time: 63.280 ms
--------------------
Epoch: [ 5/ 5], Average Train Loss: [0.418], Accuracy: [0.983]
epoch time: 1015.336 ms, per step time: 72.524 ms
================================================================================
End of validation the best Accuracy is: 0.983, save the best ckpt file in ./BestCheckpoint/resnet50-best-freezing-param.ckpt
可视化模型预测
使用固定特征得到的best.ckpt文件对对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。
import matplotlib.pyplot as plt
import mindspore as msdef visualize_model(best_ckpt_path, val_ds):net = resnet50()# 全连接层输入层的大小in_channels = net.fc.in_channels# 输出通道数大小为狼狗分类数2head = nn.Dense(in_channels, 2)# 重置全连接层net.fc = head# 平均池化层kernel size为7avg_pool = nn.AvgPool2d(kernel_size=7)# 重置平均池化层net.avg_pool = avg_pool# 加载模型参数param_dict = ms.load_checkpoint(best_ckpt_path)ms.load_param_into_net(net, param_dict)model = train.Model(net)# 加载验证集的数据进行验证data = next(val_ds.create_dict_iterator())images = data["image"].asnumpy()labels = data["label"].asnumpy()class_name = {0: "dogs", 1: "wolves"}# 预测图像类别output = model.predict(ms.Tensor(data['image']))pred = np.argmax(output.asnumpy(), axis=1)# 显示图像及图像的预测值plt.figure(figsize=(5, 5))for i in range(4):plt.subplot(2, 2, i + 1)# 若预测正确,显示为蓝色;若预测错误,显示为红色color = 'blue' if pred[i] == labels[i] else 'red'plt.title('predict:{}'.format(class_name[pred[i]]), color=color)picture_show = np.transpose(images[i], (1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])picture_show = std * picture_show + meanpicture_show = np.clip(picture_show, 0, 1)plt.imshow(picture_show)plt.axis('off')plt.show()
visualize_model(best_ckpt_path, dataset_val)


import time
L = time.localtime()
print(time.
心得
迭代50次,效果还是很显著的,不错不错。
相关文章:
【mindspore进阶】02-ResNet50迁移学习
Mindspore 应用(2)ResNet50迁移学习 在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化…...

智能决策的艺术:揭秘决策树的奇妙原理与实战应用
引言 决策树(Decision Tree)是一种常用的监督学习算法,适用于分类和回归任务。它通过学习数据中的规则生成树状模型,从而做出预测决策。决策树因其易于理解和解释、无需大量数据预处理等优点,广泛应用于各种机器学习任…...

基于AOP的数据字典实现:实现前端下拉框的可配置更新
作者:后端小肥肠 创作不易,未经允许严禁转载。 目录 1. 前言 2. 数据字典 2.1. 数据字典简介 2.2. 数据字典如何管理各模块的下拉框 3. 数据字典核心内容解读 3.1. 表结构 3.2. 核心代码 3.2.1. 根据实体类名称获取下属数据字典 3.2.2. 数据字…...

基于CentOS Stream 9平台搭建RabbitMQ3.13.4以及开机自启
1. erlang与RabbitMQ对应版本参考:https://www.rabbitmq.com/which-erlang.html 2. 安装erlang 官网:https://www.erlang.org/downloads GitHub: https://github.com/rabbitmq/erlang-rpm/releases 2.1 安装依赖: yum -y install gcc glib…...

9、Redis 高级数据结构 HyperLogLog 和事务
1. HyperLogLog 简介 HyperLogLog 是一种用于基数估计的概率数据结构。它并不是一种新的数据结构,而是 Redis 中的一种字符串类型。HyperLogLog 的主要优点是能够利用极少的内存空间完成对独立总数的统计,适用于统计大量数据的独立元素数量,…...
如何在 MyBatis 中使用 XML 和注解混合配置方式)
MyBatis(30)如何在 MyBatis 中使用 XML 和注解混合配置方式
在MyBatis中,你可以灵活地选择XML配置方式、注解方式,或者将这两种方式混合使用来配置你的映射器(Mapper)。使用混合配置方式,你可以结合两者的优势,例如,利用XML配置复杂查询和动态SQL…...

强化学习与控制模型结合例子
强化学习与模型控制结合 强化学习(Reinforcement Learning, RL)与控制模型结合,可以通过整合传统控制理论和现代RL算法,利用控制模型提供的动态信息和稳定性保障,同时利用RL的学习能力优化控制策略。这种结合的方式被称为模型辅助强化学习(Model-Assisted Reinforcement…...

RKNN3588——利用推理YOLOv8推理图片
1. yolov8_test.py import os import cv2 import numpy as np from class_type import CLASSES# 设置对象置信度阈值和非极大值抑制(NMS)阈值。 OBJ_THRESH 0.25 NMS_THRESH 0.45 IMG_SIZE (640, 640)def filter_boxes(boxes, box_confidences, box_…...

【ARMv8/v9 GIC 系列 1.7 -- GIC PPI | SPI | SGI | LPI 中断使能配置介绍】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 GIC 各种中断使能配置PPIs(每个处理器私有中断)SPIs(共享外设中断)SGIs(软件生成的中断)LPIs(局部中断)GIC 各种中断使能配置 在ARM GICv3和GICv4架构中,不同类型的中断(如PPIs、SPIs、SGIs和LPIs)可以通过不同的方式进…...

uniapp开发射击类小游戏
使用 UniApp 开发射击类小游戏可以遵循以下步骤: 项目规划 确定游戏的主题、玩法、关卡设计等。规划游戏的界面布局,包括游戏主界面、游戏场景、得分显示等。 技术准备 熟悉 UniApp 的开发文档和相关 API。准备所需的开发工具,如 HBuilderX。…...

spring6框架解析(by尚硅谷)
文章目录 spring61. 一些基本的概念、优势2. 入门案例实现maven聚合工程创建步骤分析实现过程 3. IoC(Inversion of Control)基于xml的bean环境搭建获取bean获取接口创建实现类依赖注入 setter注入 和 构造器注入原生方式的setter注入原生方式的构造器注…...

Open3D 计算点云的马氏距离
目录 一、概述 1.1原理 1.2应用 二、代码实现 三、实现效果 3.1原始点云 3.2计算后点云 一、概述 1.1原理 马氏距离(Mahalanobis Distance)是一种度量多维数据点与数据分布中心之间距离的方法。与欧几里得距离不同,马氏距离考虑了数据…...
Java事务(Transaction)
Java事务(Transaction)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列组成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务的引入主要是为了解决并发操作数据…...

算法 —— 二分查找
目录 二分查找 在排序数组中查找元素的第一个和最后一个位置 搜索插入位置 x的平方根 山峰数组的峰顶索引 寻找峰值 搜索旋转排序数组中的最⼩值 点名 二分查找模板分为三种:1、朴素的二分模板 2、查找左边界的二分模板 3、查找右边界的二分模板…...

Mysql explain语句详解与实例展示
首先简单介绍sql: SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句…...

Python基础问题汇总
为什么学习Python? 易学易用:Python语法简洁清晰,易于学习。广泛的应用领域:适用于Web开发、数据科学、人工智能、自动化脚本等多种场景。强大的库支持:拥有丰富的第三方库,如NumPy、Pandas、TensorFlow等…...

【讲解下iOS语言基础】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...
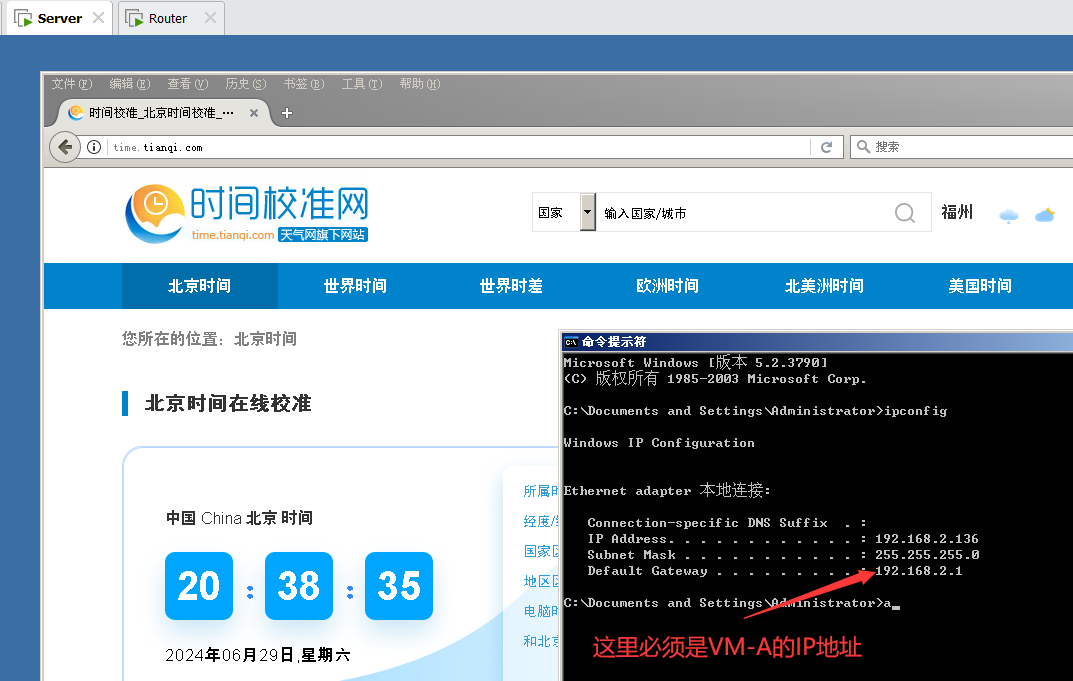
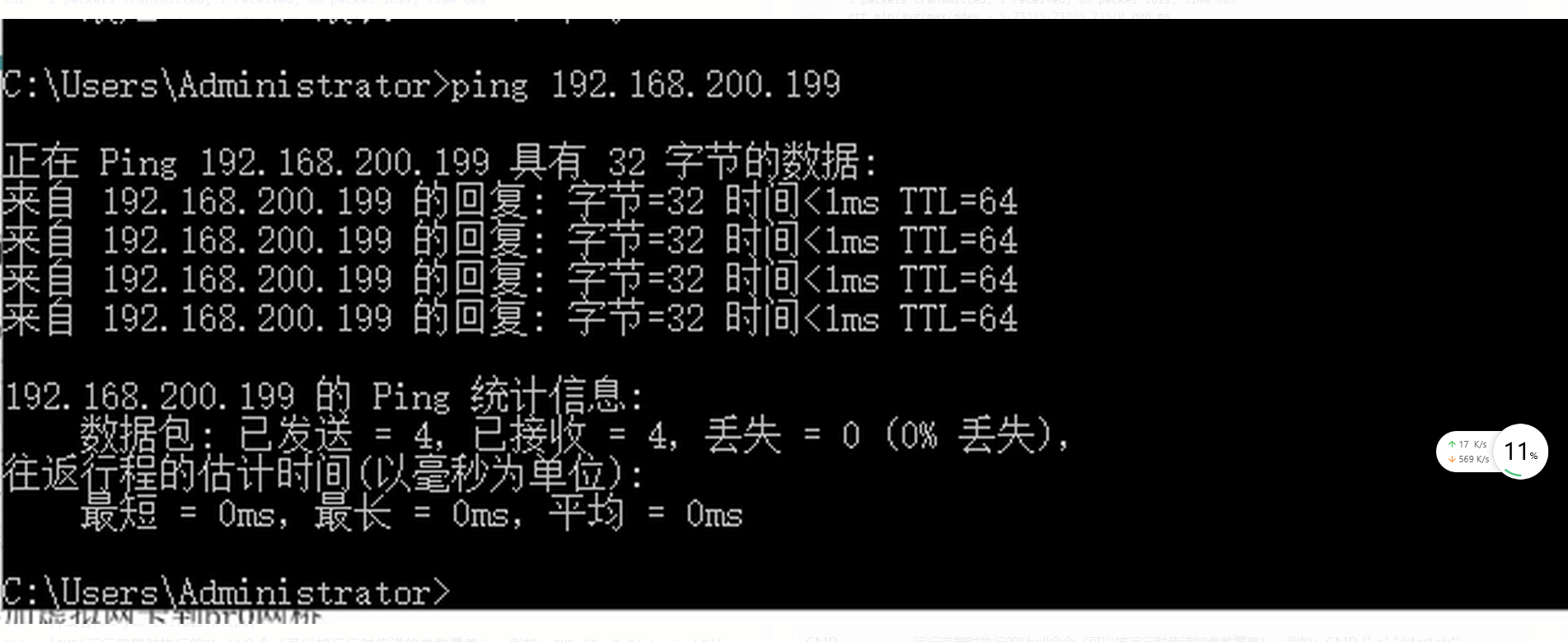
【网络安全】实验一(网络拓扑环境的搭建)
一、本次实验的实验目的 学习利用 VMware 创建虚拟环境 学习利用 VMware 搭建各自网络拓扑环境 二、创建虚拟机 三、克隆虚拟机 选择克隆的系统必须处于关机状态。 方法一: 方法二: 需要修改克隆计算机的名字,避免产生冲突。 四、按照要求完…...
Docker-基础
一,Docker简介,功能特性与应用场景 1.1 Docker简介 Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器…...
《昇思25天学习打卡营第14天|onereal》
第14天学习内容如下: Diffusion扩散模型 本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。 本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,…...

免费Figma中文界面插件终极指南:3分钟告别英文设计工具
免费Figma中文界面插件终极指南:3分钟告别英文设计工具 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 你是否曾经因为Figma的英文界面而感到困惑?每天在设计时不…...

破局Windows Defender:重构系统防护管理的黑科技方案
破局Windows Defender:重构系统防护管理的黑科技方案 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-control 当…...

如何快速解锁QQ音乐加密格式:面向普通用户的完整音频解密指南
如何快速解锁QQ音乐加密格式:面向普通用户的完整音频解密指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump …...

Windows Cleaner智能清理引擎:全方位提速系统的开源解决方案
Windows Cleaner智能清理引擎:全方位提速系统的开源解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 在数字化办公环境中,系统优化…...

Air8101:低功耗-WiFi-UI_SoC模组介绍
一、模组概述 Air8101 是高性能 WiFi SoC 模组,支持2.4G WiFi6与BLE 5.4双模通信,兼容DVP/UVC摄像头接口,可实现200W像素拍照、100W像素录像(支持H.264编码及RTMP推流),搭载LuatOS,降低二次开发…...

intv_ai_mk11惊艳输出集:RAG技术通俗解释、电商详情页开头、朋友圈爆款文案
intv_ai_mk11惊艳输出集:RAG技术通俗解释、电商详情页开头、朋友圈爆款文案 1. 什么是intv_ai_mk11 AI对话机器人 intv_ai_mk11是一款基于7B参数Llama架构的AI对话助手,运行在GPU服务器上。它能够理解自然语言并生成高质量的文本回复,适用于…...

IL-21蛋白在肿瘤靶向治疗中的作用机制研究
一、研究背景与科学问题肿瘤微环境中功能性肿瘤浸润淋巴细胞的缺乏是导致肿瘤免疫疗法效果欠佳的重要原因。即使在富含肿瘤浸润淋巴细胞的肿瘤组织中,功能异常的PD-1阳性Tim-3阳性CD8阳性T细胞的存在仍是肿瘤患者预后不良的主要指标。IL-21蛋白是由CD4阳性T细胞和自…...
)
国产化服务器上,手把手教你用TongHttpServer V6.0搭建静态资源站(含麒麟/统信系统适配指南)
国产化环境实战:TongHttpServer V6.0静态资源站部署全攻略 在信创产业快速发展的背景下,国产化软硬件生态已逐步成熟。对于需要在国产CPU和操作系统环境中部署Web服务的工程师而言,选择一款性能优异且兼容性良好的国产Web服务器软件至关重要。…...

Android音频设备切换背后的秘密:AudioPolicyService与HAL交互全解析
Android音频设备切换机制深度解析:从AudioPolicyService到HAL的完整链路 在移动设备的多媒体体验中,音频设备切换的流畅性直接影响用户体验。当用户插入耳机、连接蓝牙设备或切换扬声器时,系统如何在毫秒级完成音频路由的重构?本文…...
)
Fedora 40 虚拟机避坑指南:VMware 17.5 安装与内核降级实战(解决卡顿与兼容性问题)
Fedora 40 虚拟机性能优化全攻略:从内核调优到图形加速的深度实践 当你在VMware Workstation 17.5上运行Fedora 40时,是否遇到过系统卡顿、响应迟缓的问题?这并非个例——最新Linux发行版与虚拟化平台间的兼容性挑战,往往让开发者…...