数据统计与数据分组18-25题(30 天 Pandas 挑战)
数据统计与数据分组
- 1. 知识点
- 1.18 分箱与统计个数
- 1.19 分组与求和统计
- 1.20 分组获取最小值
- 1.21 分组获取值个数
- 1.22 分组与条件查询
- 1.23 分组与条件查询及获取最大值
- 1.24 分组及自定义函数
- 1.25 分组+lambda函数统计
- 2. 题目
- 2.18 按分类统计薪水(数据统计)
- 2.19 查找每个员工花费的总时间(数据分组)
- 2.20 游戏玩法分析 I(数据分组)
- 2.21 每位教师所教授的科目种类的数量(数据分组)
- 2.22 超过5名学生的课(数据分组)
- 2.23 订单最多的客户(数据分组)
- 2.24 按日期分组销售产品(数据分组)
- 2.25 每天的领导和合伙人(数据分组)
1. 知识点
1.18 分箱与统计个数
- 分箱操作
# float('inf')正无穷 bins=[0,20000,50001,float('inf')] labels=['Low Salary', 'Average Salary', 'High Salary'] accounts['category']=pd.cut(accounts['income'],bins=bins,labels=labels,right=False) - 数值统计
accounts_new=accounts['category'].value_counts().reset_index()
1.19 分组与求和统计
- 分组统计
employees=employees.groupby(['event_day','emp_id']).agg({'total_time':'sum'}).reset_index() - 多种数值统计
employees=employees.groupby(['event_day','emp_id']).agg( total_add=('total_time','sum'), total_mean=('total_time','mean') ).reset_index()
1.20 分组获取最小值
- 分组获取最小值
activity=activity.groupby('player_id').agg(first_login=('event_date','min')).reset_index()
1.21 分组获取值个数
- 分组获取最小值
teacher=teacher.groupby('teacher_id').agg(cnt=('subject_id','count')).reset_index()
1.22 分组与条件查询
courses=courses.groupby('class').agg(counts=('student','count')).reset_index() # 分组
courses=courses.query('`counts`>5')[['class']] # 条件查询
1.23 分组与条件查询及获取最大值
- 分组统计
orders=orders.groupby('customer_number').agg(counts=('order_number','count')).reset_index() - 最大值
max_orders=orders['counts'].max() - 条件查询
results=orders.query(f'`counts`=={max_orders}')[['customer_number']]
1.24 分组及自定义函数
def get_join(x):x_list=sorted(list(set(x)))return ','.join(x_list)def get_count(x):x_list=set(x)return len(x_list)activities=activities.groupby(['sell_date']).agg(num_sold=('product',get_count),products=('product',get_join)).reset_index()
1.25 分组+lambda函数统计
daily_sales=daily_sales.groupby(['date_id','make_name']).agg(unique_leads=('lead_id',lambda x:len(set(x))),unique_partners=('partner_id',lambda x:len(set(x)))).reset_index()
2. 题目
2.18 按分类统计薪水(数据统计)


import pandas as pddef count_salary_categories(accounts: pd.DataFrame) -> pd.DataFrame:# float('inf')bins=[0,20000,50001,float('inf')]labels=['Low Salary', 'Average Salary', 'High Salary']accounts['category']=pd.cut(accounts['income'],bins=bins,labels=labels,right=False)accounts_new=accounts['category'].value_counts().reset_index()accounts_new=accounts_new.rename(columns={'count':'accounts_count'})accounts_new=accounts_new.sort_values('category',ascending=False)return accounts_new
2.19 查找每个员工花费的总时间(数据分组)



import pandas as pddef total_time(employees: pd.DataFrame) -> pd.DataFrame:# pandas流employees=employees.assign(total_time = employees.out_time-employees.in_time).groupby(['event_day','emp_id']).agg({'total_time':'sum'}).reset_index().rename(columns = {'event_day':'day'})# employees['total_time']=employees['out_time']-employees['in_time']# employees=employees.groupby(['event_day','emp_id'])['total_time'].sum().reset_index()# employees=employees.rename(columns={'event_day':'day'})# employees.sort_values('emp_id',inplace=True)return employees
2.20 游戏玩法分析 I(数据分组)


import pandas as pddef game_analysis(activity: pd.DataFrame) -> pd.DataFrame:activity=activity.groupby('player_id').agg(first_login=('event_date','min')).reset_index()return activity
2.21 每位教师所教授的科目种类的数量(数据分组)



import pandas as pddef count_unique_subjects(teacher: pd.DataFrame) -> pd.DataFrame:teacher.drop_duplicates(['teacher_id','subject_id'],inplace=True)teacher=teacher.groupby('teacher_id').agg(cnt=('subject_id','count')).reset_index()return teacher
2.22 超过5名学生的课(数据分组)



import pandas as pddef find_classes(courses: pd.DataFrame) -> pd.DataFrame:courses=courses.groupby('class').agg(counts=('student','count')).reset_index()return courses.query('`counts`>5')[['class']]
2.23 订单最多的客户(数据分组)


import pandas as pddef largest_orders(orders: pd.DataFrame) -> pd.DataFrame:orders=orders.groupby('customer_number').agg(counts=('order_number','count')).reset_index()max_orders=orders['counts'].max()results=orders.query(f'`counts`=={max_orders}')[['customer_number']]return results
2.24 按日期分组销售产品(数据分组)



import pandas as pddef categorize_products(activities: pd.DataFrame) -> pd.DataFrame:activities=activities.groupby(['sell_date']).agg(num_sold=('product',lambda x:len(set(x))),products=('product',lambda x:','.join(sorted(list(set(x)))))).reset_index()return activities2.25 每天的领导和合伙人(数据分组)



import pandas as pddef daily_leads_and_partners(daily_sales: pd.DataFrame) -> pd.DataFrame:daily_sales=daily_sales.groupby(['date_id','make_name']).agg(unique_leads=('lead_id',lambda x:len(set(x))),unique_partners=('partner_id',lambda x:len(set(x)))).reset_index()return daily_sales
相关文章:
数据统计与数据分组18-25题(30 天 Pandas 挑战)
数据统计与数据分组 1. 知识点1.18 分箱与统计个数1.19 分组与求和统计1.20 分组获取最小值1.21 分组获取值个数1.22 分组与条件查询1.23 分组与条件查询及获取最大值1.24 分组及自定义函数1.25 分组lambda函数统计 2. 题目2.18 按分类统计薪水(数据统计)…...
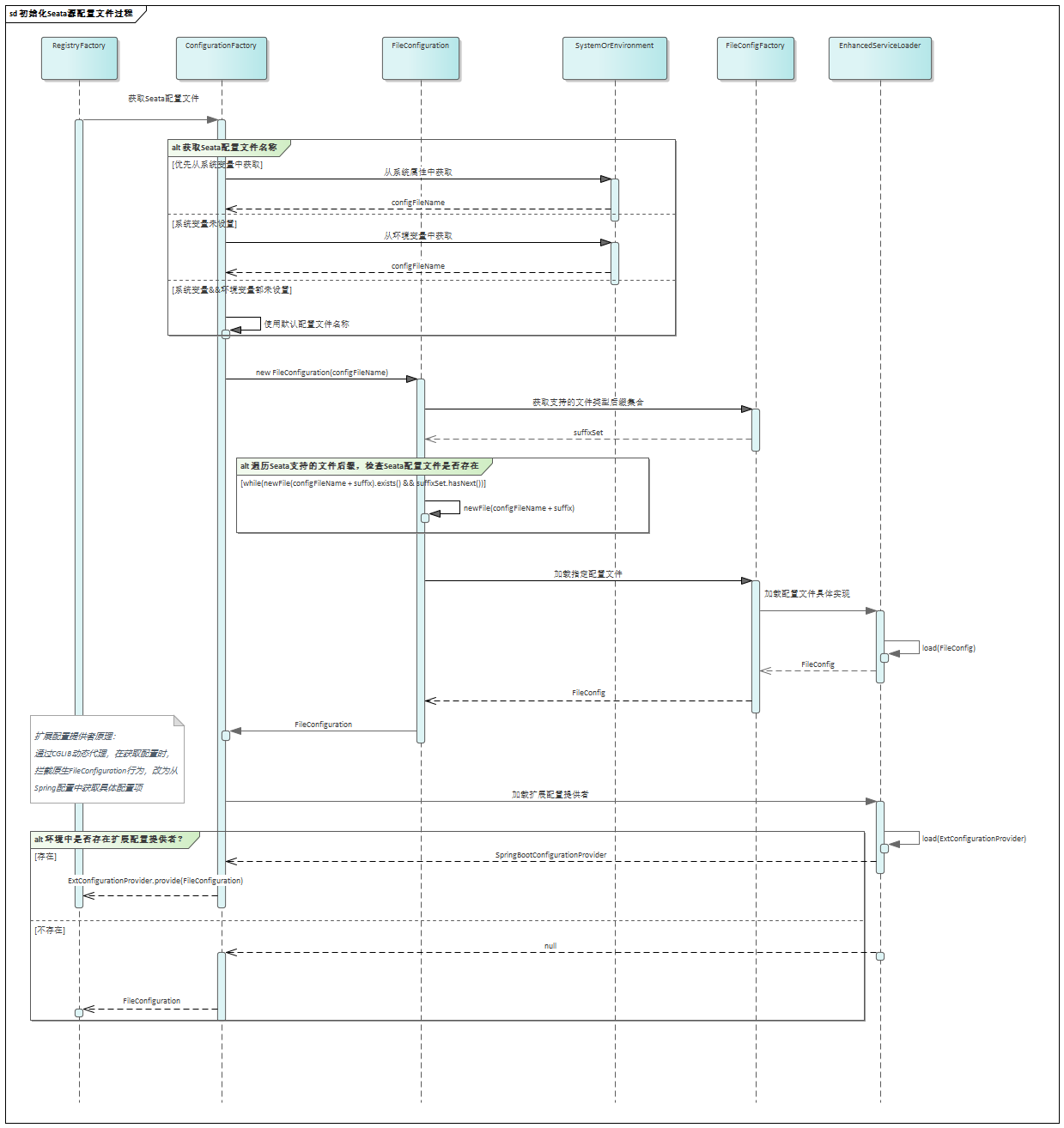
Apache Seata应用侧启动过程剖析——注册中心与配置中心模块
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 Apache Seata应用侧启动过程剖析——注册中心与配置中心模块 前言 在Seata的应用侧…...

大话光学原理:1.“实体泛光说”、反射与折射
一、实体泛光说 在古希腊,那些喜好沉思的智者们中,曾流传着一个奇妙的设想:他们认为,我们的眼睛仿佛伸出无数触手般的光线,这些光线能向四面八方延伸,紧紧抓住周围的每一个物体。于是,当我们凝视…...

住宅代理、移动代理和数据中心代理之间的区别
如果您是一名认真的互联网用户,可能需要反复访问某个网站或服务器,可能是为了数据抓取、价格比较、SEO 监控等用例,而不会被 IP 列入黑名单或被 CAPTCHA 阻止。 代理的工作原理是将所有传出数据发送到代理服务器,然后代理服务器将…...
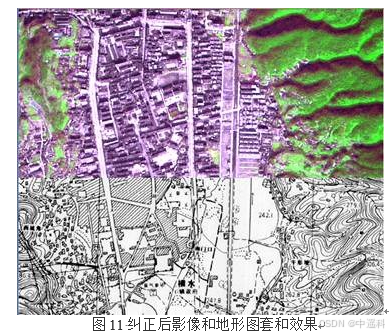
光学传感器图像处理流程(一)
光学传感器图像处理流程(一) 1. 处理流程总览2. 详细处理流程2.1. 图像预处理2.1.1. 降噪处理2.1.2. 薄云处理2.1.3. 阴影处理 2.2. 辐射校正2.2.1. 辐射定标2.2.2. 大气校正2.2.3. 地形校正 2.3. 几何校正2.3.1. 图像配准2.3.2. 几何粗校正2.3.3. 几何精…...

el-table 树状表格查询符合条件的数据
需要对el-table的树状表格根据输入机构名称,筛选出符合条件的数据,可用如下方法: 页面内容如下: <el-input v-model"ogeName" placeholder"请输入机构名称"><el-table :data"list" row…...
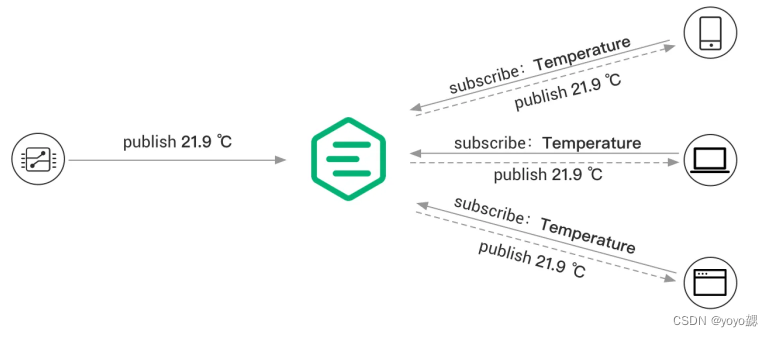
MQTT教程--服务器使用EMQX和客户端使用MQTTX
什么是MQTT MQTT(Message Queuing Telemetry Transport)是一种轻量级、基于发布-订阅模式的消息传输协议,适用于资源受限的设备和低带宽、高延迟或不稳定的网络环境。它在物联网应用中广受欢迎,能够实现传感器、执行器和其它设备…...

326. 3 的幂
哈喽!大家好,我是奇哥,一位专门给面试官添堵的职业面试员 文章持续更新,可以微信搜索【小奇JAVA面试】第一时间阅读,回复【资料】更有我为大家准备的福利哟! 文章目录 一、题目二、答案三、总结 一、题目 …...
多标签问题
一、多标签问题与单标签问题的区别: 多标签问题是单标签问题的推广。 举个例子,同时识别图片中的小汽车,公交车,行人时,标签值有三个:小汽车,公交车,行人。 单标签问题仅对一个标签…...
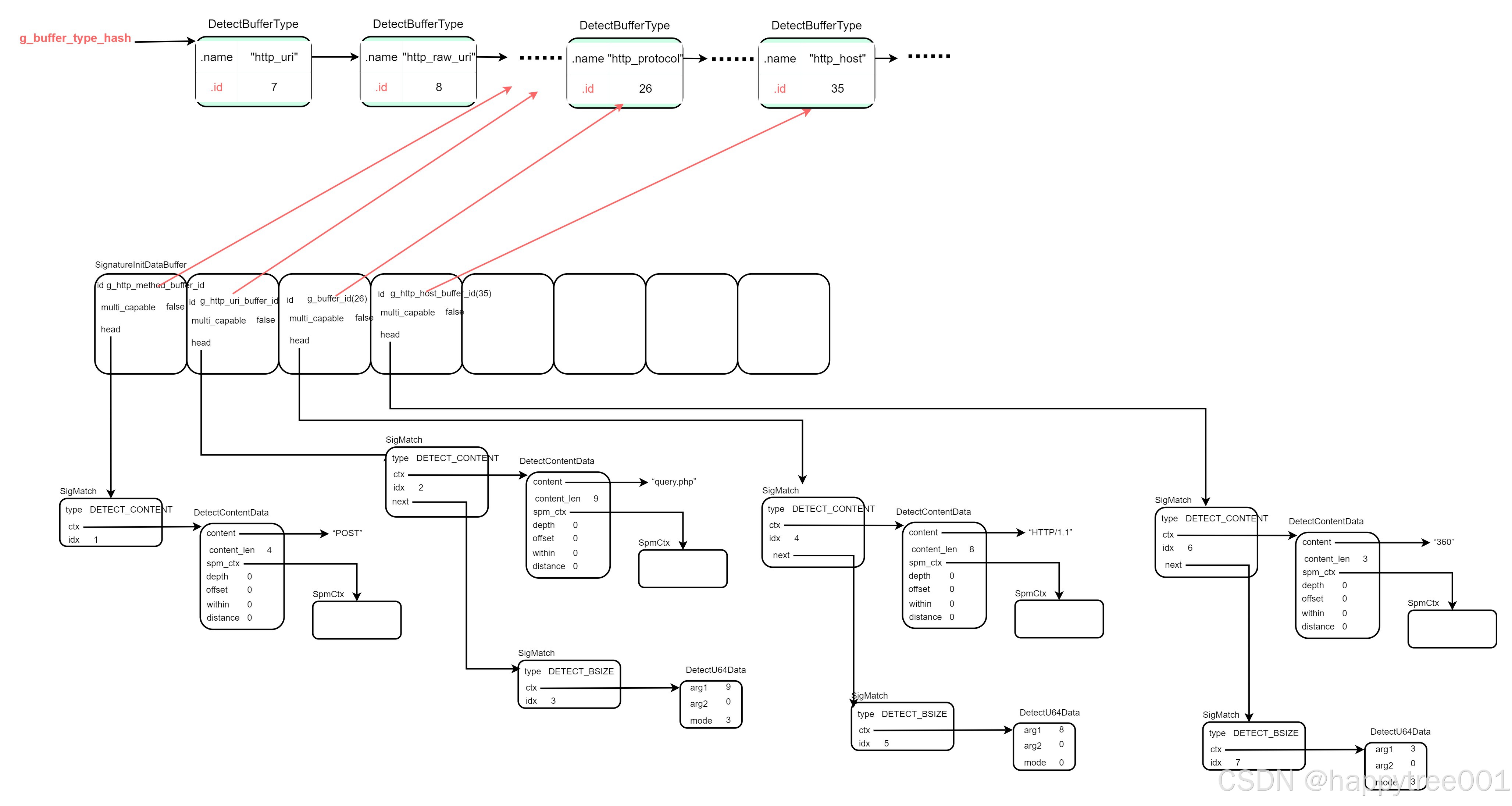
suricata7 rule加载(三)加载options
suricata7.0.5 加载options (msg:“HTTP Request Example”; flow:established,to_server; http.method; content:“POST”; http.uri; content:“query.php”; bsize:>9; http.protocol; content:“HTTP/1.1”; bsize:8; http.host; content:“360”; bsize:>3; class…...

【电路笔记】-C类放大器
C类放大器 文章目录 C类放大器1、概述2、C类放大介绍3、C类放大器的功能4、C 类放大器的效率5、C类放大器的应用:倍频器6、总结1、概述 尽管存在差异,但我们在之前有关 A 类、B 类和 AB 类放大器的文章中已经看到,这三类放大器是线性或部分线性的,因为它们在放大过程中再现…...

c++语法之函数重载
引例 我们在C语言里面写add函数的时候,只能支持一种类型的相加,除非我们创建多个add函数: 但是这样写并不方便,于是就有了c的函数重载。 函数重载 函数重载就是可以将多个参数类型、顺序、数量不同,实现逻辑相同的函…...

EtherCAT主站IGH-- 11 -- IGH之fmmu_config.h/c文件解析
EtherCAT主站IGH-- 11 -- IGH之fmmu_config.h/c文件解析 0 预览一 该文件功能`fmmu_config.c` 文件功能函数预览二 函数功能介绍1. `ec_fmmu_config_init`2. `ec_fmmu_set_domain_offset_size`3. `ec_fmmu_config_page`示例用法示例详细说明三 h文件翻译四 c文件翻译该文档修改…...
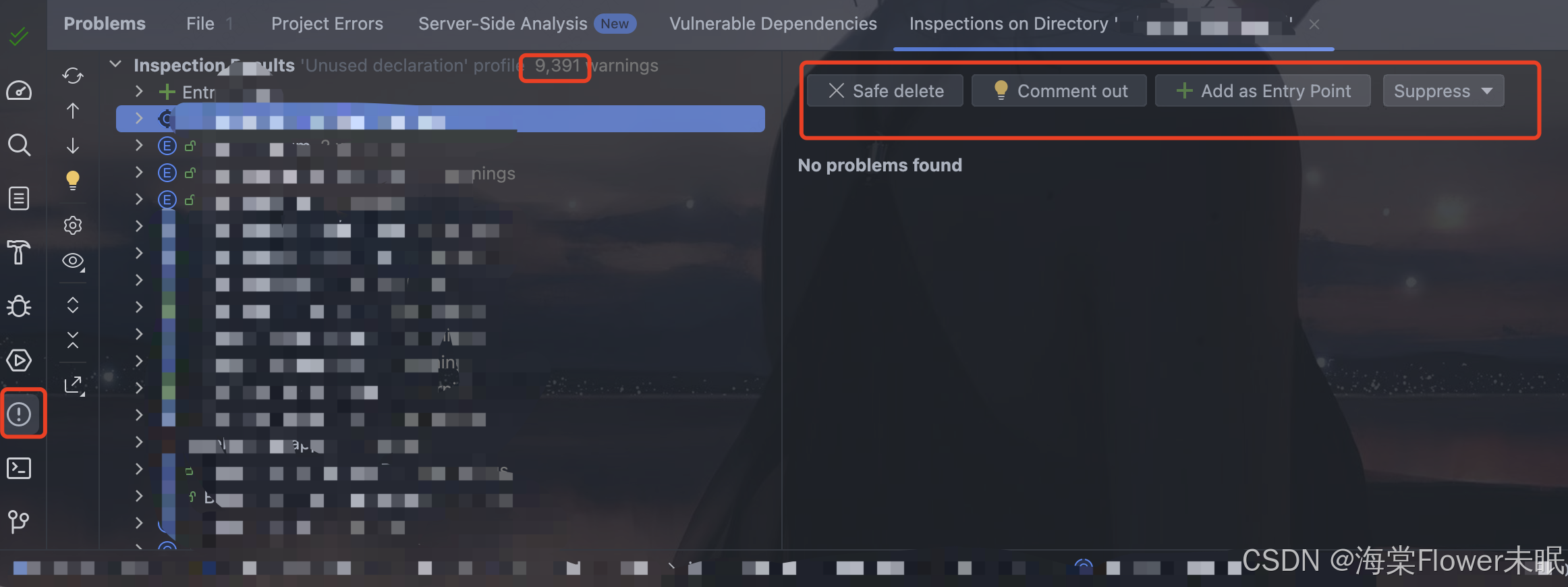
如何使用IDEA快速清理无效代码(荣耀典藏版)
大家好,我是月夜枫。 今天分享一下IDEA中很有实用价值的Analyze,那么Analyze是用来做什么的呢? 主要用来清理没有引用的代码,包括方法、实体类以及没有使用的Mapper和Service等。 为了是项目更加整洁,可以使用Idea中…...
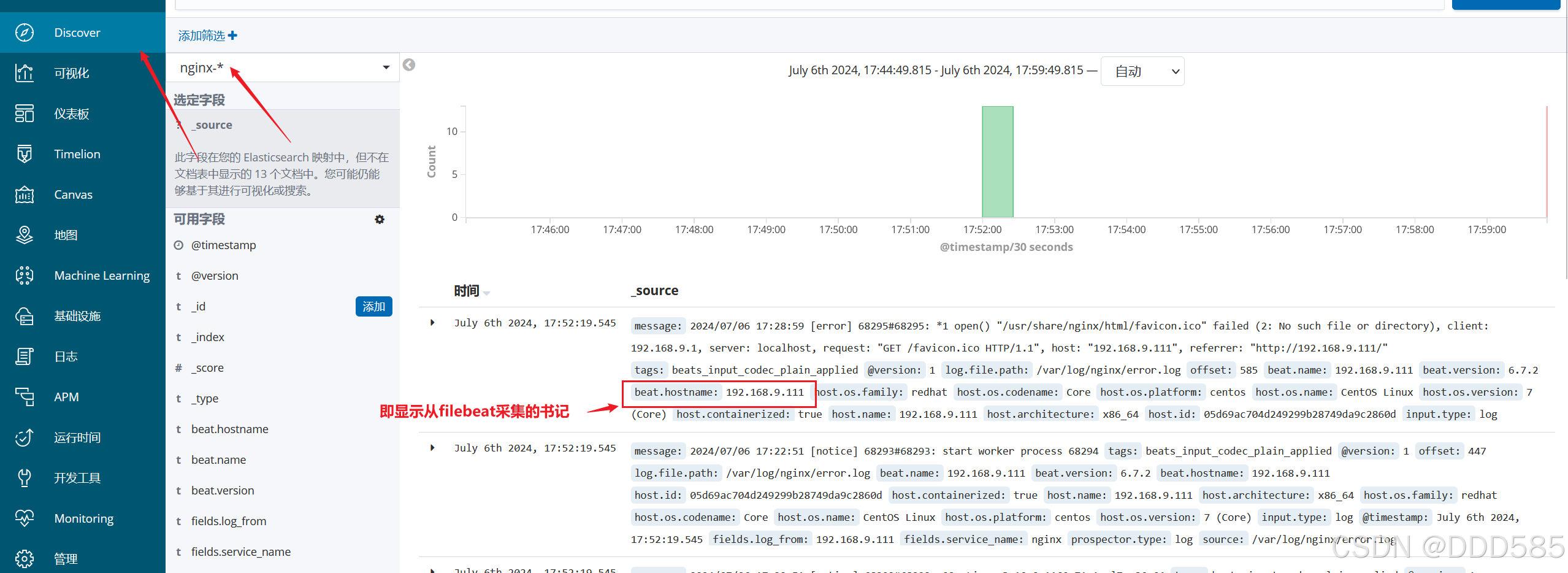
ELK优化之Filebeat部署
目录 1.安装配置Nginx 2.安装 Filebeat 3.设置 filebeat 的主配置文件 4.修改Logstash配置 5.启动配置 6.kibana验证 主机名ip地址主要软件es01192.168.9.114ElasticSearches02192.168.9.115ElasticSearches03192.168.9.116ElasticSearch、Kibananginx01192.168.9.113ng…...
及其Python和MATLAB实现)
蝙蝠优化算法(Bat Algorithm,BA)及其Python和MATLAB实现
蝙蝠优化算法(Bat Algorithm,简称BA)是一种基于蝙蝠群体行为的启发式优化算法,由Xin-She Yang于2010年提出。该算法模拟了蝙蝠捕食时在探测目标、适应环境和调整自身位置等过程中的行为,通过改进搜索过程来实现优化问题…...

vscode运行java中文乱码,引发的mac配置问题
文章目录 问题 vscode 安装 java环境之后 public class Main{ public static void main(String[] args) { System.out.println(“哈哈”); } } ➜ .leetcode cd “/Users/leesin/.leetcode/.vscode/” && javac -encoding utf-8 Main.java && java Main &am…...
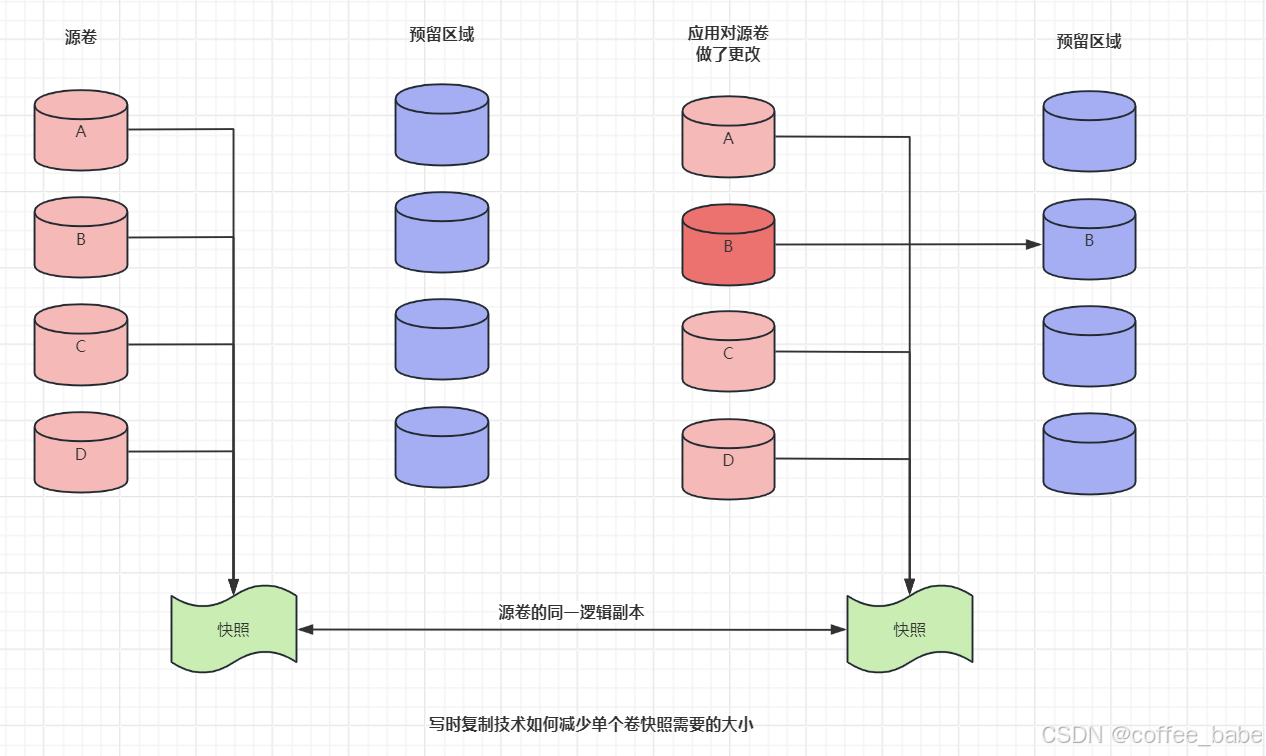
MySQL之备份与恢复(五)
备份与恢复 备份数据 符号分隔文件备份 可以使用SQL命令SELECT INTO OUTFILE以符号分隔文件格式创建数据的逻辑备份。(可以用mysqldump的 --tab选项导出到符号分隔文件中)。符号分隔文件包含以ASCII展示的原始数据,没有SQL、注释和列名。下面是一个导出为逗号分隔…...

离线运行Llama3:本地部署终极指南_liama2 本地部署
4月18日,Meta在官方博客官宣了Llama3,标志着人工智能领域迈向了一个重要的飞跃。经过笔者的个人体验,Llama3 8B效果已经超越GPT-3.5,最为重要的是,Llama3是开源的,我们可以自己部署! 本文和大家…...

【YOLO8系列】(二)YOLOv8环境配置,手把手嘴对嘴保姆教学
目录 一. 准备环境 1.Anaconda下载 2.创建yolov8虚拟环境 3.pytorch安装 4.CUDA下载 5.CUDNN下载 二、yolov8模型下载 1.clone模型 2.pycharm配置 ①解释器配置 ②终端配置 3.安装必要库 4.下载训练模型 三、 环境验证 四、总结 YOLOv8 是 YOLO 系列最新的目标…...

IntelliJ IDEA突然无法启动的快速修复指南
1. IntelliJ IDEA突然无法启动的常见原因 作为一名常年与IntelliJ IDEA打交道的开发者,我遇到过无数次IDE突然罢工的情况。最让人头疼的是,明明昨天还用得好好的,今天双击图标却毫无反应。这种情况通常由以下几个原因导致: 首先是…...

【实战指南】如何用nvitop解决GPU资源监控与管理难题
【实战指南】如何用nvitop解决GPU资源监控与管理难题 【免费下载链接】nvitop An interactive NVIDIA-GPU process viewer and beyond, the one-stop solution for GPU process management. 项目地址: https://gitcode.com/gh_mirrors/nv/nvitop 在深度学习训练、科学计…...

音频标注:从原理到产业,AI听懂世界的“翻译官”
音频标注:从原理到产业,AI听懂世界的“翻译官” 引言 在人工智能的浪潮中,计算机视觉的“看”和自然语言处理的“读”已广为人知,而让机器学会“听”——理解并解析复杂的声音世界,正成为新的前沿。这一切的基石&…...

超级AI数字员工源码系统,支持贴牌OEM,独立部署交付
温馨提示:文末有资源获取方式最近“龙虾AI”概念很火,到处都在讨论。但说实话,这类技术对普通用户而言存在明显门槛,部署要代码、配置要工程师、日常运行的Token成本也不低——轻度使用每月100-200元,重度甚至单日上千…...
)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例) 在智能驾驶技术快速发展的今天,功能安全已成为汽车电子系统设计的核心考量。作为汽车电子工程师,我们面临的挑战不仅在于实现复杂功…...

4 种可靠的 OPPO 手机联系人备份到电脑的方法
OPPO 手机的全球出货量常年位居前五,足以见得它已经获得了越来越多用户的认可。对于年轻群体而言,入手一款高性价比的 OPPO Reno4 SE 这类机型是非常不错的选择。但日常使用中,误操作、进水等意外都可能导致数据丢失,为了避免这类…...
)
MATLAB实战:用BEMD算法分解图像并提取特征(附完整代码)
MATLAB实战:二维经验模态分解(BEMD)在图像特征提取中的创新应用 当我们需要从一张X光片中识别微小病灶,或是从卫星图像中提取城市道路网络时,传统图像处理方法往往力不从心。二维经验模态分解(BEMD)就像给图像做"CT扫描"࿰…...

ai辅助开发:让快马生成智能助手,链接notepad下载与个性化代码推荐
今天想和大家分享一个有趣的实践:如何用AI辅助开发的方式,让Notepad这个老牌文本编辑器焕发新生。我们平时下载Notepad可能只是简单获取软件,但如果结合AI能力,就能把"下载-使用"的流程升级成"智能助手"体验。…...

ElasticSearch查询集群及设置
Elasticsearch查询集群API示例 查看集群状态及监控 参考资料 https://www.elastic.co/guide/en/elasticsearch/reference/6.6/cluster-health.html https://www.elastic.co/guide/en/elasticsearch/reference/6.6/cluster-nodes-stats.html 查看集群状态 健康状态 curl -XGE…...

谈谈你对springAop动态代理的理解?
面试 你要调用目标方法,不直接调用,而是交给代理对象,代理对象会先做额外功能,再调用原方法,最后再收尾。 至于叫动态代理的原因,是因为这个代理不是你手动写死的,而是程序在运行期间动态生成…...