力扣喜刷刷--day1
1.无重复字符的最长子串

知识点:滑动窗口
基本概念
- 窗口:窗口是一个连续的子序列,可以是固定长度或可变长度。
- 滑动:窗口在数据序列上移动,可以是向左或向右。
- 边界:窗口的起始和结束位置。
应用场景
- 字符串匹配:如KMP算法中的部分匹配表就是利用滑动窗口来优化字符串搜索。
- 最大/最小子数组:例如Kadane算法,通过滑动窗口找到数组中的最大子数组和。
- 窗口内元素的统计:如统计窗口内元素的个数、总和、平均值等。
- 数据流的实时处理:在数据流中,滑动窗口可以用来处理固定时间范围内的数据。
- 滑动窗口协议:在网络通信中,滑动窗口用于流量控制和拥塞避免。
实现方式
- 固定窗口:窗口大小不变,通过移动窗口的起始或结束位置来遍历整个数据序列。
- 可变窗口:窗口大小可以根据需要变化,通常用于处理动态数据集合。
示例代码(Python)
def max_subarray_sum(nums):max_sum = float('-inf')current_sum = 0start = 0for end in range(len(nums)):current_sum += nums[end]while current_sum > max_sum and start <= end:max_sum = current_sumcurrent_sum -= nums[start]start += 1return max_sum if max_sum != float('-inf') else 0# 使用示例
nums = [-2, 1, -3, 4, -1, 2, 1, -5, 4]
print(max_subarray_sum(nums)) # 输出应该是6,对应子数组[4, -1, 2, 1]
代码:
#include <stdio.h>
#include <string.h>int lengthOfLongestSubstring(char *s) {int n = strlen(s);int charIndex[128]; // ASCII 128字符的索引表for (int i = 0; i < 128; i++) {charIndex[i] = -1; // 初始化索引表为-1}int left = 0, maxLength = 0;for (int right = 0; right < n; right++) {char currentChar = s[right];if (charIndex[currentChar] >= left) {left = charIndex[currentChar] + 1; // 更新左边界}charIndex[currentChar] = right; // 更新当前字符的最新索引int currentLength = right - left + 1;if (currentLength > maxLength) {maxLength = currentLength;}}return maxLength;
}int main() {char s[] = "abcabcbb";int length = lengthOfLongestSubstring(s);printf("最长不重复子串长度是: %d\n", length);return 0;
}
代码解释
-
初始化:
charIndex:一个数组,用于存储每个字符的最新出现位置。我们假定字符串只包含ASCII字符(共128个)。- 将
charIndex数组初始化为-1,表示字符尚未出现。
-
滑动窗口:
left:滑动窗口的左边界。maxLength:记录最长子串的长度。- 遍历字符串
s的每个字符,right表示滑动窗口的右边界。 - 如果当前字符
s[right]在charIndex中的值大于等于left,说明遇到了重复字符,需要更新左边界left。 - 将当前字符的索引更新到
charIndex中。 - 计算当前窗口的长度
right - left + 1,并更新maxLength。
-
返回结果:
- 遍历完成后,
maxLength即为最长不含重复字符的子串的长度。
- 遍历完成后,
提交结果

2.前k个高频元素

知识点: 哈希表和快速排序算法
哈希表(Hash Table)
哈希表是一种数据结构,它提供了快速的数据插入和查找功能。以下是哈希表的一些关键点:
- 基本思想:哈希表通过使用哈希函数将输入(例如字符串或者数字)映射到一个大数组的索引上,这个数组称为哈希表的“桶”。
- 哈希函数:哈希函数的设计对于哈希表的性能至关重要,它应该能够均匀地分布元素,以减少冲突。
- 冲突解决:当两个不同的输入通过哈希函数映射到同一个索引时,称为“冲突”。解决冲突的常见方法包括链地址法(每个桶包含一个链表来存储具有相同哈希值的元素)和开放寻址法(寻找空的数组位置来存储元素)。
- 动态扩容:随着元素的增加,哈希表可能需要扩容以保持操作的效率,扩容通常涉及到重新计算现有元素的哈希值并将它们重新分配到新的更大的数组中。
- 时间复杂度:理想情况下,哈希表的插入和查找操作可以达到平均时间复杂度O(1),但在最坏情况下(例如,所有元素都映射到同一个桶中)可能退化到O(n)。
快速排序算法(Quick Sort)
快速排序是一种高效的排序算法,采用分治法的策略来把一个序列分为较小和较大的两个子序列,然后递归地排序两个子序列。以下是快速排序的一些关键点:
- 选择基准:算法首先选择一个元素作为“基准”(pivot),然后重新排列数组,使得所有比基准小的元素都在基准的左边,所有比基准大的元素都在基准的右边。
- 分区操作:通过分区操作,数组被分为两个部分,然后递归地对这两个部分进行快速排序。
- 递归:递归是快速排序的核心,它将问题分解为更小的子问题,直到子问题足够小,可以直接解决。
- 时间复杂度:在平均情况下,快速排序的时间复杂度为O(n log n),但在最坏情况下(例如,数组已经排序或所有元素相等)时间复杂度会退化到O(n^2)。
- 原地排序:快速排序是一种原地排序算法,它不需要额外的存储空间,除了递归调用的栈空间。
- 稳定性:快速排序不是稳定的排序算法,相同的元素在排序后可能会改变它们原来的顺序。
代码解释
#include <stdio.h>
#include <stdlib.h>typedef struct Node {int key;int value;struct Node* next;
} Node;Node** createHashTable(int size) {Node** hashTable = (Node**)malloc(sizeof(Node*) * size);for (int i = 0; i < size; i++) {hashTable[i] = NULL;}return hashTable;
}int getHashValue(int key, int size) {return abs(key % size);
}void insert(Node** hashTable, int key, int size) {int index = getHashValue(key, size);Node* node = hashTable[index];Node* prev = NULL;while (node != NULL) {if (node->key == key) {node->value++;return;}prev = node;node = node->next;}Node* newNode = (Node*)malloc(sizeof(Node));newNode->key = key;newNode->value = 1;newNode->next = NULL;if (prev == NULL) {hashTable[index] = newNode;} else {prev->next = newNode;}
}int partition(Node** nums, int left, int right) {int pivot = nums[right]->value;int i = left - 1;for (int j = left; j < right; j++) {if (nums[j]->value >= pivot) {i++;Node* temp = nums[i];nums[i] = nums[j];nums[j] = temp;}}Node* temp = nums[i+1];nums[i+1] = nums[right];nums[right] = temp;return i + 1;
}void quickSort(Node** nums, int left, int right) {if (left < right) {int pivotIndex = partition(nums, left, right);quickSort(nums, left, pivotIndex - 1);quickSort(nums, pivotIndex + 1, right);}
}int* topKFrequent(int* nums, int numsSize, int k, int* returnSize) {int hashSize = numsSize * 2;Node** hashTable = createHashTable(hashSize);for (int i = 0; i < numsSize; i++) {insert(hashTable, nums[i], hashSize);}int uniqueNums = 0;for (int i = 0; i < hashSize; i++) {Node* node = hashTable[i];while (node != NULL) {uniqueNums++;node = node->next;}}Node** frequencyArray = (Node**)malloc(sizeof(Node*) * uniqueNums);int index = 0;for (int i = 0; i < hashSize; i++) {Node* node = hashTable[i];while (node != NULL) {frequencyArray[index++] = node;node = node->next;}}quickSort(frequencyArray, 0, uniqueNums - 1);*returnSize = k;int* result = (int*)malloc(sizeof(int) * k);for (int i = 0; i < k; i++) {result[i] = frequencyArray[i]->key;}return result;
}
-
包含标准输入输出头文件
stdio.h和标准库头文件stdlib.h。 -
定义了一个结构体
Node,包含一个整数key,一个整数value和一个指向Node的指针next。 -
定义了一个函数
createHashTable,它接受一个整数size作为参数,创建一个大小为size的哈希表,并初始化所有元素为NULL。 -
定义了一个辅助函数
getHashValue,它接受一个整数key和一个整数size,返回哈希表中对应的索引位置。 -
定义了一个
insert函数,它接受一个哈希表指针、一个整数key和一个整数size,用于将键值对插入到哈希表中。如果键已经存在,则增加其值。 -
定义了一个
partition函数,用于快速排序中的分区操作。 -
定义了一个
quickSort函数,用于对节点数组进行快速排序。 -
定义了主要的函数
topKFrequent,它接受一个整数数组nums、数组的大小numsSize、需要找出的前k个最频繁元素的数量以及一个指向整数的指针returnSize。这个函数首先创建一个哈希表,然后统计每个元素出现的次数,接着将统计结果放入一个数组中,对数组进行快速排序,最后返回出现次数最多的前k个元素。
提交结果
3.百马百担
100 匹马驮 100 担货,已知一匹大马驮 3 担,一匹中马驮 2 担,两匹小马驮 1 担。试编写 程序计算大、中、小马的所有可能组合数目。
#include <stdio.h>int main() {int count = 0;for (int big = 0; big <= 100 / 3; big++) {for (int medium = 0; medium <= 100 / 2; medium++) {int small = 100 - big - medium;if ((3 * big + 2 * medium + small) == 100) {// Valid combination foundprintf("大马:%d 匹,中马:%d 匹,小马:%d 匹\n", big, medium, small);count++;}}}printf("共有 %d 种可能的组合。\n", count);return 0;
}代码解释
-
定义了一个
count变量,用于统计有效组合的数量。 -
外层循环变量
big从0开始,到100 / 3结束,因为每匹大马的重量是3单位,所以最多有33匹大马(100 / 3向上取整)。 -
内层循环变量
medium从0开始,到100 / 2结束,因为每匹中马的重量是2单位,所以最多有50匹中马。 -
计算
small的值,它是100减去big和medium的总和。 -
使用一个
if语句检查3 * big + 2 * medium + small是否等于100。如果等于,说明找到了一个有效的组合,并打印出来。 -
每次找到有效组合时,
count变量增加1。 -
循环结束后,打印出所有有效组合的总数。
相关文章:
力扣喜刷刷--day1
1.无重复字符的最长子串 知识点:滑动窗口 基本概念 窗口:窗口是一个连续的子序列,可以是固定长度或可变长度。滑动:窗口在数据序列上移动,可以是向左或向右。边界:窗口的起始和结束位置。 应用场景 字符…...

配置linux的yum镜像为阿里镜像源
1.备份当前的yum源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup 2.下载新的CentOS-Base.repo 到/etc/yum.repos.d wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo 3.清空并生成缓存 yum clean …...

react使用markdown进行展示
有一些文档非常长,但是又要挨个设置样式,直接用 组件库 - marked 注意文档要放在public下才能读取。但非常方便 import { marked, Renderer } from "marked".....const [html, setHtml] useState<any>("")const renderer:…...

实时温湿度监测系统:Micropython编码ESP32与DHT22模块的无线数据传输与PC端接收项目
实时温湿度监测系统 前言项目目的项目材料项目步骤模拟ESP32接线连接测试搭建PC端ESP32拷录环境对ESP32进行拷录PC端搭建桌面组件本地数据接收桌面小组件部分 实验总结 前言 人生苦短,我用Python。 由于我在日常工作中经常使用Python,因此在进行该项目…...

CloudWatch Logs Insights 详解
CloudWatch Logs Insights 是 AWS 提供的强大日志分析工具,允许您快速、交互式地搜索和分析日志数据。本文将详细介绍使用 CloudWatch Logs Insights 所需的权限、常用查询方法,以及一些实用的查询示例。 1. 所需权限 要使用 CloudWatch Logs Insights,用户需要具备以下 I…...
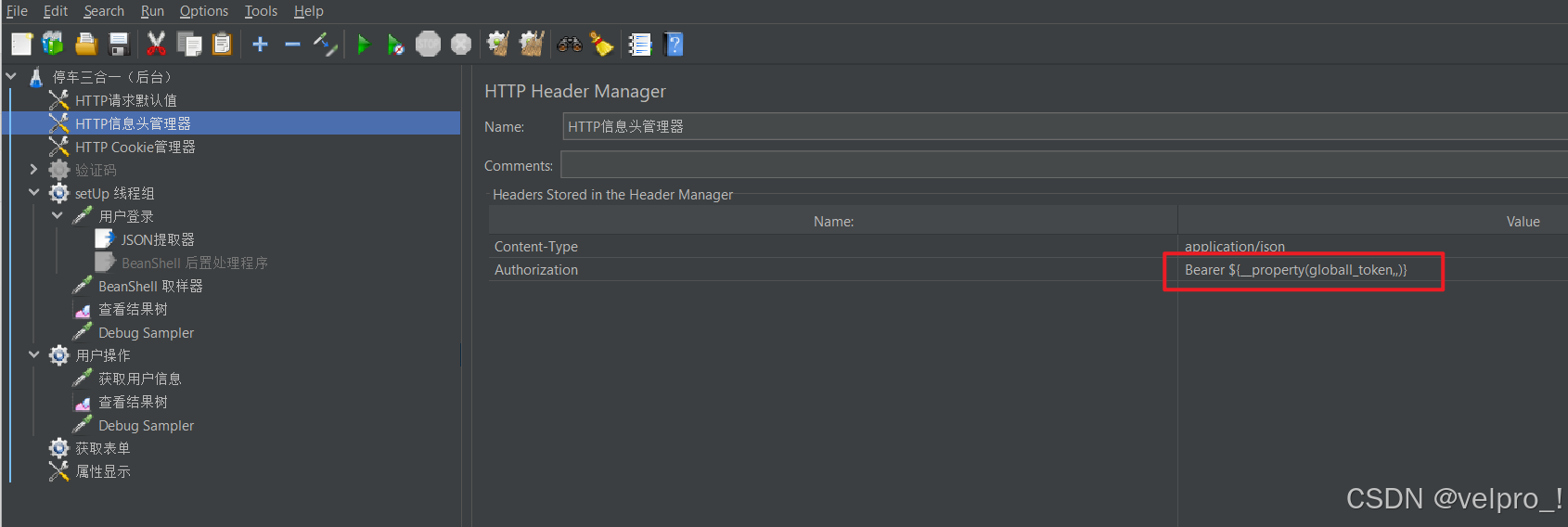
Jmeter在信息头中设置Bearer与 token 的拼接值
思路:先获取token,将token设置成全局变量,再与Bearer拼接。 第一步:使用提取器将token值提取出来,使用setProperty函数将提取的token值设置成全局变量,在登录请求后面添加BeanShell取样器 或者 BeanShell后…...

C#程序调用Sql Server存储过程异常处理:调用存储过程后不返回、不抛异常的解决方案
目录 一、代码解析: 二、解决方案 1、增加日志记录 2、异步操作 注意事项 3、增加超时机制 4、使用线程池 5、使用信号量或事件 6、监控数据库连接状态 在C#程序操作Sql Server数据库的实际应用中,若异常就会抛出异常,我们还能找到异…...

数据统计与数据分组18-25题(30 天 Pandas 挑战)
数据统计与数据分组 1. 知识点1.18 分箱与统计个数1.19 分组与求和统计1.20 分组获取最小值1.21 分组获取值个数1.22 分组与条件查询1.23 分组与条件查询及获取最大值1.24 分组及自定义函数1.25 分组lambda函数统计 2. 题目2.18 按分类统计薪水(数据统计)…...
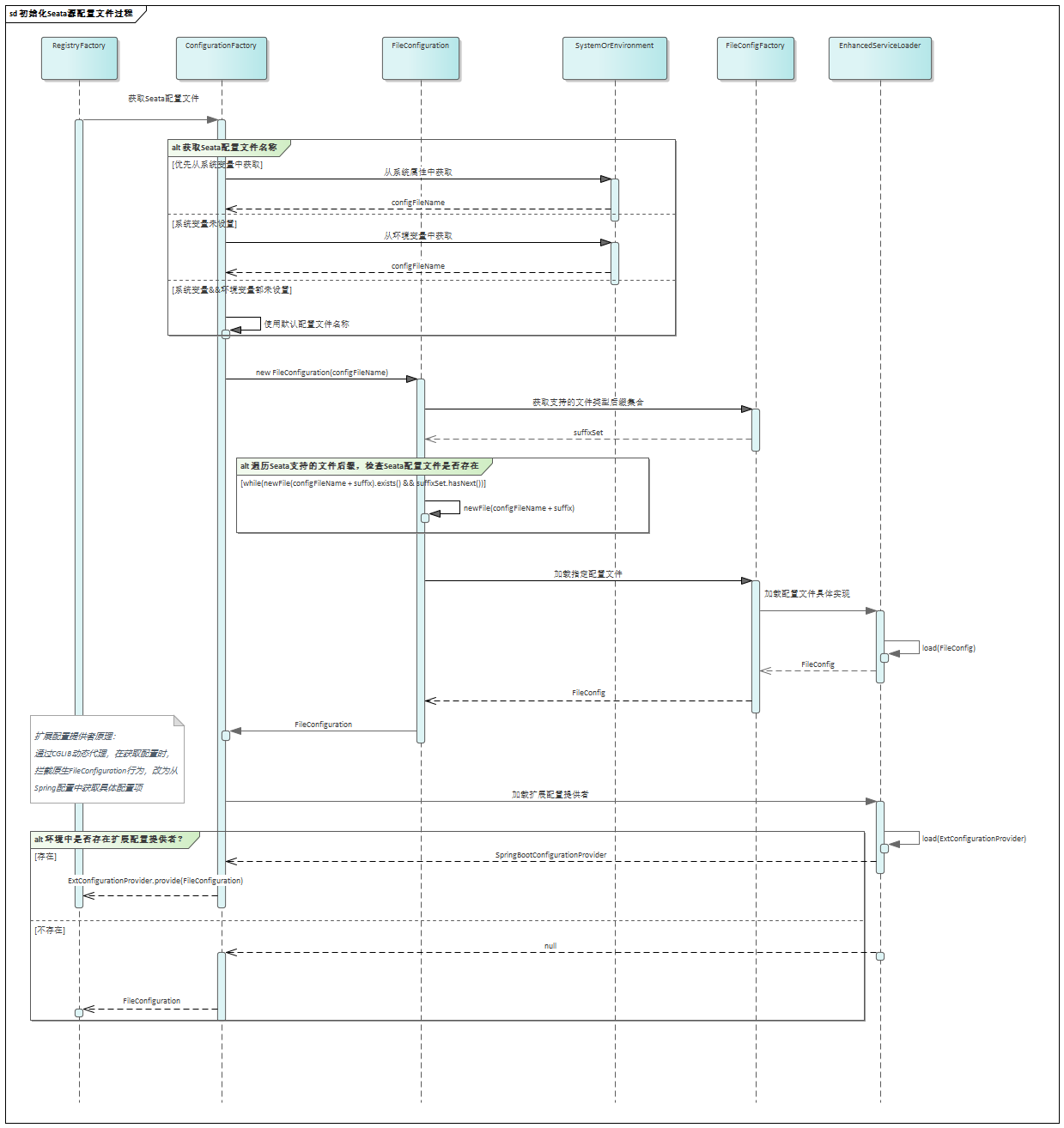
Apache Seata应用侧启动过程剖析——注册中心与配置中心模块
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 Apache Seata应用侧启动过程剖析——注册中心与配置中心模块 前言 在Seata的应用侧…...

大话光学原理:1.“实体泛光说”、反射与折射
一、实体泛光说 在古希腊,那些喜好沉思的智者们中,曾流传着一个奇妙的设想:他们认为,我们的眼睛仿佛伸出无数触手般的光线,这些光线能向四面八方延伸,紧紧抓住周围的每一个物体。于是,当我们凝视…...

住宅代理、移动代理和数据中心代理之间的区别
如果您是一名认真的互联网用户,可能需要反复访问某个网站或服务器,可能是为了数据抓取、价格比较、SEO 监控等用例,而不会被 IP 列入黑名单或被 CAPTCHA 阻止。 代理的工作原理是将所有传出数据发送到代理服务器,然后代理服务器将…...
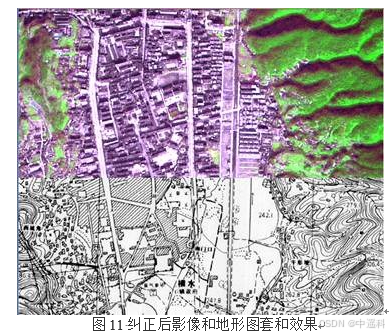
光学传感器图像处理流程(一)
光学传感器图像处理流程(一) 1. 处理流程总览2. 详细处理流程2.1. 图像预处理2.1.1. 降噪处理2.1.2. 薄云处理2.1.3. 阴影处理 2.2. 辐射校正2.2.1. 辐射定标2.2.2. 大气校正2.2.3. 地形校正 2.3. 几何校正2.3.1. 图像配准2.3.2. 几何粗校正2.3.3. 几何精…...

el-table 树状表格查询符合条件的数据
需要对el-table的树状表格根据输入机构名称,筛选出符合条件的数据,可用如下方法: 页面内容如下: <el-input v-model"ogeName" placeholder"请输入机构名称"><el-table :data"list" row…...
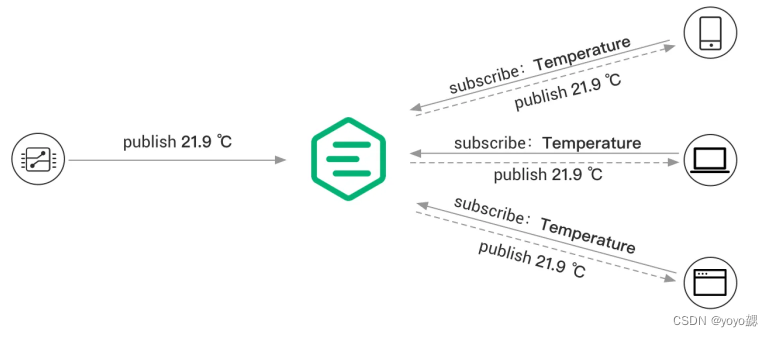
MQTT教程--服务器使用EMQX和客户端使用MQTTX
什么是MQTT MQTT(Message Queuing Telemetry Transport)是一种轻量级、基于发布-订阅模式的消息传输协议,适用于资源受限的设备和低带宽、高延迟或不稳定的网络环境。它在物联网应用中广受欢迎,能够实现传感器、执行器和其它设备…...

326. 3 的幂
哈喽!大家好,我是奇哥,一位专门给面试官添堵的职业面试员 文章持续更新,可以微信搜索【小奇JAVA面试】第一时间阅读,回复【资料】更有我为大家准备的福利哟! 文章目录 一、题目二、答案三、总结 一、题目 …...
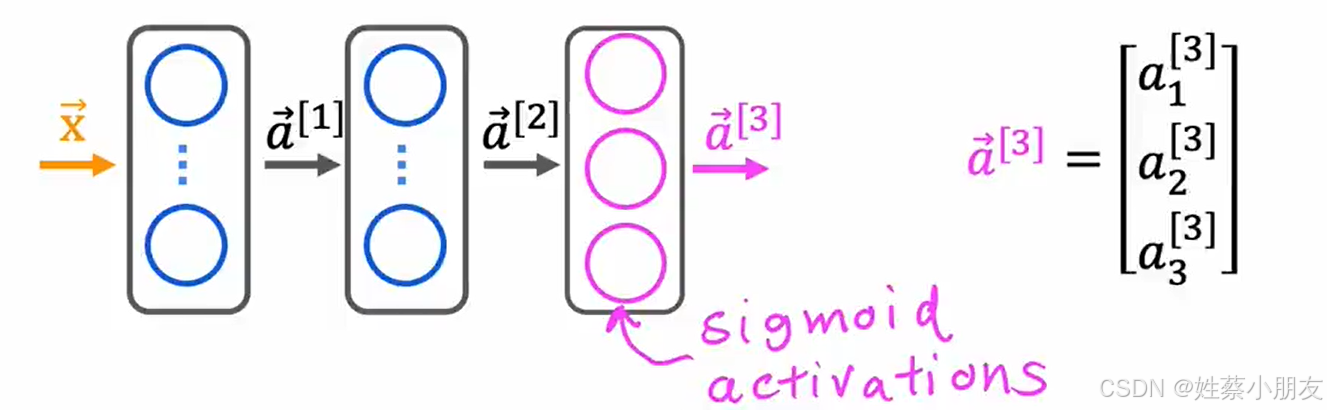
多标签问题
一、多标签问题与单标签问题的区别: 多标签问题是单标签问题的推广。 举个例子,同时识别图片中的小汽车,公交车,行人时,标签值有三个:小汽车,公交车,行人。 单标签问题仅对一个标签…...
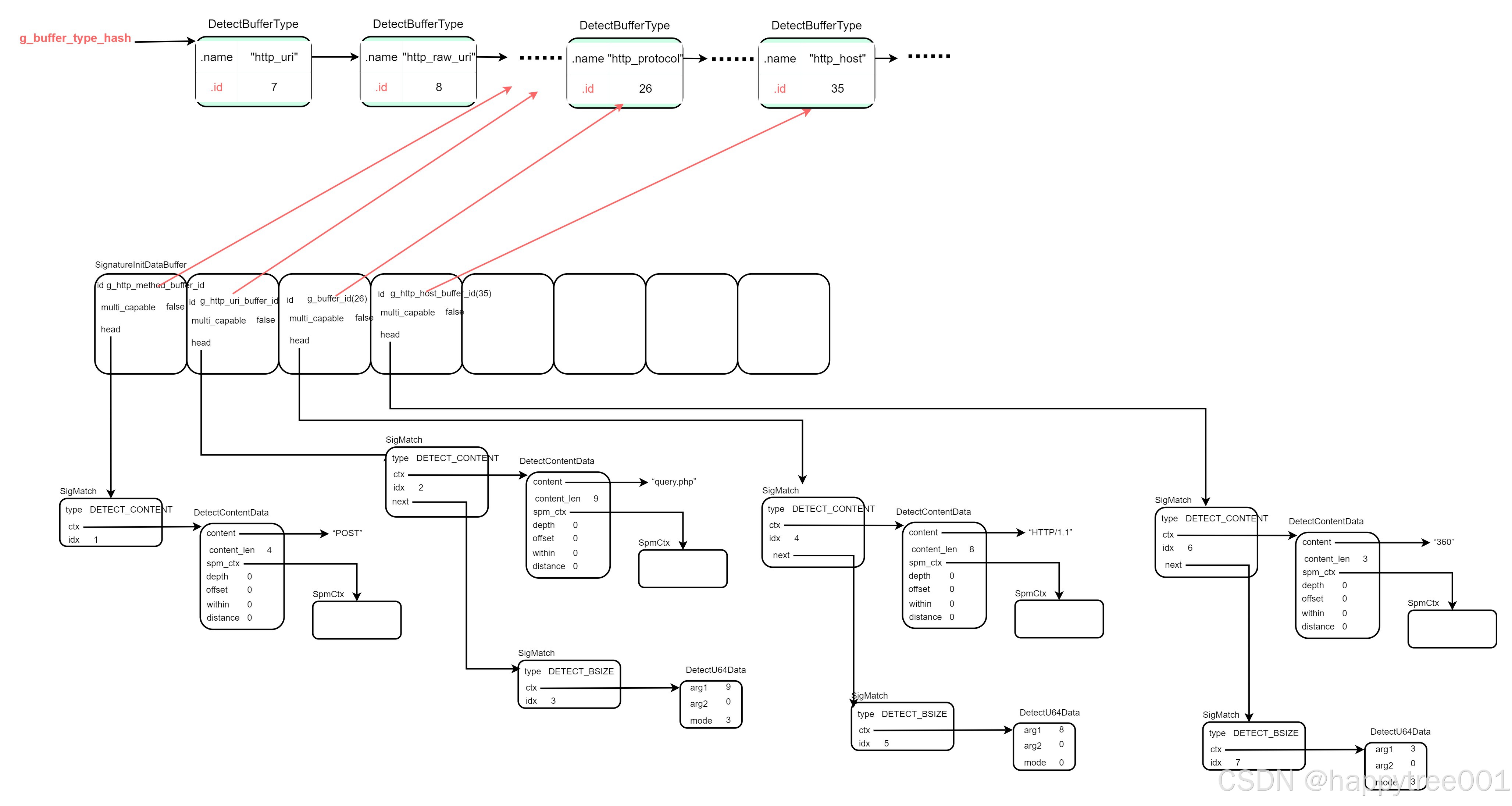
suricata7 rule加载(三)加载options
suricata7.0.5 加载options (msg:“HTTP Request Example”; flow:established,to_server; http.method; content:“POST”; http.uri; content:“query.php”; bsize:>9; http.protocol; content:“HTTP/1.1”; bsize:8; http.host; content:“360”; bsize:>3; class…...

【电路笔记】-C类放大器
C类放大器 文章目录 C类放大器1、概述2、C类放大介绍3、C类放大器的功能4、C 类放大器的效率5、C类放大器的应用:倍频器6、总结1、概述 尽管存在差异,但我们在之前有关 A 类、B 类和 AB 类放大器的文章中已经看到,这三类放大器是线性或部分线性的,因为它们在放大过程中再现…...

c++语法之函数重载
引例 我们在C语言里面写add函数的时候,只能支持一种类型的相加,除非我们创建多个add函数: 但是这样写并不方便,于是就有了c的函数重载。 函数重载 函数重载就是可以将多个参数类型、顺序、数量不同,实现逻辑相同的函…...

EtherCAT主站IGH-- 11 -- IGH之fmmu_config.h/c文件解析
EtherCAT主站IGH-- 11 -- IGH之fmmu_config.h/c文件解析 0 预览一 该文件功能`fmmu_config.c` 文件功能函数预览二 函数功能介绍1. `ec_fmmu_config_init`2. `ec_fmmu_set_domain_offset_size`3. `ec_fmmu_config_page`示例用法示例详细说明三 h文件翻译四 c文件翻译该文档修改…...
)
Burp Suite实战进阶:用LingJing内置的burp-labs靶机打通从入门到专家22关(含解题思路)
Burp Suite实战进阶:用LingJing内置的burp-labs靶机打通从入门到专家22关(含解题思路) 在网络安全领域,Burp Suite无疑是渗透测试工程师最得力的工具之一。然而,很多学习者在掌握了基础操作后,往往会陷入&q…...
)
告别手推雅可比!用Ceres自动求导搞定SLAM中的BA优化(附完整代码)
告别手推雅可比!用Ceres自动求导搞定SLAM中的BA优化(附完整代码) 在视觉SLAM系统的开发中,Bundle Adjustment(BA)优化是提升定位与建图精度的关键环节。传统实现需要手动推导复杂的雅可比矩阵,不…...

目标检测实战:从VOC XML到YOLO格式的自动化数据流水线
1. 为什么需要VOC转YOLO格式 在目标检测任务中,数据格式的统一性直接影响着模型训练的效率。VOC(PASCAL VOC)和YOLO是两种最常见的标注格式,但它们的存储方式截然不同。VOC采用XML文件记录目标的类别和边界框坐标,而YO…...

OpCore-Simplify智能构建:OpenCore EFI自动化生成的效率提升实践
OpCore-Simplify智能构建:OpenCore EFI自动化生成的效率提升实践 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 用户场景:黑苹…...

高效获取数字资源工具:Internet Archive下载器全方位应用指南
高效获取数字资源工具:Internet Archive下载器全方位应用指南 【免费下载链接】internet_archive_downloader A chrome/firefox extension that download books from Internet Archive(archive.org) and HathiTrust Digital Library (hathitrust.org) 项目地址: h…...

Trae平台实战:我如何教会一个AI智能体应对动态网页和反爬虫?
Trae平台实战:动态网页抓取与反爬策略的智能应对之道 在数据驱动的商业环境中,网页抓取技术已成为企业获取竞争优势的关键能力。然而,随着网站防护技术的升级,传统爬虫在面对动态加载内容和复杂反爬机制时往往力不从心。本文将分享…...

Wan2.2-I2V-A14B极限测试:高分辨率与长视频生成的稳定性挑战
Wan2.2-I2V-A14B极限测试:高分辨率与长视频生成的稳定性挑战 1. 开场白:当AI视频生成遇上极限挑战 最近在测试Wan2.2-I2V-A14B模型时,我突发奇想:这个在常规场景下表现优秀的视频生成模型,如果被推到极限会怎样&…...

Qt官网抽风连不上?亲测有效的Qt6在线安装网络问题终极解决手册
Qt6在线安装网络问题终极解决手册:从反复失败到一次成功 看着Qt安装器上那个刺眼的"无法连接服务器"提示,我第27次点击了重试按钮。作为一名有十年经验的开发者,我从未想过会在安装环境这一步耗费整整一个下午。这不是个例——根据…...

OpenClaw安全加固:nanobot镜像的权限控制最佳实践
OpenClaw安全加固:nanobot镜像的权限控制最佳实践 1. 为什么需要关注OpenClaw的安全配置 去年夏天,我在本地部署OpenClaw时犯过一个致命错误——直接以管理员权限运行了未经审查的自动化脚本。结果这个脚本在半夜执行时误删了我整个项目目录的源码&…...

大数据领域数据科学与云计算的结合应用
大数据领域数据科学与云计算的结合应用 关键词:大数据、数据科学、云计算、结合应用、数据分析 摘要:本文深入探讨了大数据领域中数据科学与云计算的结合应用。首先介绍了数据科学和云计算的背景知识,然后详细解释了这两个核心概念及其相互关系。通过具体的算法原理、数学模…...