【python】随机森林预测汽车销售
目录
引言
1. 数据收集与预处理
2. 划分数据集
3. 构建随机森林模型
4. 模型训练
5. 模型评估
6. 模型调优
数据集
代码及结果
独热编码
随机森林模型训练
特征重要性图
混淆矩阵
ROC曲线
引言
随机森林(Random Forest)是一种集成学习方法,它通过构建多个决策树并将它们的预测结果进行综合来改进模型的预测准确性和鲁棒性。在预测汽车销售方面,随机森林可以有效地处理包含多种特征(如车辆品牌、型号、年份、里程数、配置、价格等)的数据集,并预测销售数量、价格或顾客购买意向等。
以下是使用随机森林模型预测汽车销售的基本步骤:
1. 数据收集与预处理
- 收集数据:首先,需要收集汽车销售的相关数据。这些数据可能包括车辆的技术规格、历史销售价格、市场需求数据、客户反馈等。
- 数据清洗:去除重复项、缺失值处理(可以通过插值、删除或使用预测模型填补缺失值)、异常值处理等。
- 特征选择:选择对汽车销售有显著影响的特征,比如车型、品牌、年份、配置、价格等。
- 特征工程:对特征进行编码(如将分类变量转换为数值型),可能还需要进行特征缩放(如归一化或标准化)。
2. 划分数据集
- 将数据集划分为训练集和测试集(通常按70%-30%或80%-20%的比例划分)。训练集用于训练模型,测试集用于评估模型的性能。
3. 构建随机森林模型
- 使用训练集构建随机森林模型。随机森林模型的关键参数包括决策树的数量(n_estimators)、每个决策树分裂时考虑的特征数(max_features)、树的深度(如果设置了)等。
- 通过交叉验证(如网格搜索)来优化这些参数,以找到最佳的模型配置。
4. 模型训练
- 使用训练集数据训练随机森林模型。
5. 模型评估
- 使用测试集评估模型的性能。评估指标可能包括准确率、召回率、F1分数、均方误差(MSE)等,具体取决于预测目标(如销售数量、价格或购买意向)。
6. 模型调优
- 根据评估结果调整模型参数或进行特征工程,以进一步提高模型性能。
数据集
数据集如下图所示:

代码及结果
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score # 加载数据集
data = pd.read_csv('D:/项目/汽车销售/汽车销售财务业绩.csv',encoding='GBK')
# 查看数据集的维度
print(data.shape)
# 查看数据集的前几行
print(data.head())
独热编码
独热编码(One-Hot Encoding)是一种常用的将类别型数据(Categorical Data)转换为数值型数据(Numerical Data)的方法,特别适用于机器学习算法中。在独热编码中,每个类别值都会被转换成一个新的二进制列(也称为哑变量),这些列中只有一个为1(表示该样本属于该类别),其余为0。这种方法能够确保模型能够正确处理类别型数据,并且每个类别都被视为完全独立的特征。
#文本分析,使用独热编码将文本型数据转换为数值型数据# 对'销售类型'进行独热编码
sales_type_onehot = pd.get_dummies(data['销售类型'], prefix='销售类型') # 对'销售模式'进行独热编码
sales_mode_onehot = pd.get_dummies(data['销售模式'], prefix='销售模式') # 将独热编码的DataFrame与原始DataFrame(除去'销售类型'、'销售模式'和'输出'列)合并
data_without_categorical = data.drop(['销售类型', '销售模式', '输出'], axis=1)
data_encoded = pd.concat([data_without_categorical, sales_type_onehot, sales_mode_onehot], axis=1) # 将最后一列作为目标变量(y)
y = data['输出'].map({'正常': 0, '异常': 1}) # 其余作为特征(X)
X = data_encoded 随机森林模型训练
# 机器学习选择随机森林算法
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建随机森林分类器
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, random_state=42) # 训练模型
clf.fit(X_train, y_train) # 预测测试集
y_pred = clf.predict(X_test) # 评估模型
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f'Model accuracy: {accuracy}')特征重要性图
import matplotlib.pyplot as plt
import numpy as np# 获取特征重要性
importances = clf.feature_importances_
std = np.std([tree.feature_importances_ for tree in clf.estimators_], axis=0)
indices = np.argsort(importances)[::-1] # 绘制特征重要性
plt.figure()
plt.title("Feature importances")
plt.bar(range(X_train.shape[1]), importances[indices], color="r", yerr=std[indices], align="center")
plt.xticks(range(X_train.shape[1]), indices)
plt.xlim([-1, X_train.shape[1]])
plt.show()
混淆矩阵
from sklearn.metrics import confusion_matrix
from sklearn.metrics import plot_confusion_matrix # 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
disp = plot_confusion_matrix(clf, X_test, y_test, display_labels=['正常', '异常'], cmap=plt.cm.Blues, normalize=None)
disp.ax_.set_title('Confusion Matrix')
plt.show()
ROC曲线
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import plot_roc_curve # 计算ROC曲线和AUC
fpr, tpr, thresholds = roc_curve(y_test, clf.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr) # 绘制ROC曲线
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic Example')
plt.legend(loc="lower right")
plt.show()
相关文章:
【python】随机森林预测汽车销售
目录 引言 1. 数据收集与预处理 2. 划分数据集 3. 构建随机森林模型 4. 模型训练 5. 模型评估 6. 模型调优 数据集 代码及结果 独热编码 随机森林模型训练 特征重要性图 混淆矩阵 ROC曲线 引言 随机森林(Random Forest)是一种集成学习方法…...

Stable Diffusion教程|练丹师是如何炼丹的Lora模型训练
前言 还记得我们之前就讲过学习SD成为炼丹师不?那么今天就来手把手教大家炼丹,看看同一个角色或某种风格的小模型是如何制作出来的。 目录 1 炼丹介绍 2 环境准备 3 Lora模型训练 **一、**炼丹介绍 什么是炼丹? 早在学习SD地第一篇就…...

QT--SQLite
配置类相关的表,所以我使用sqlite,且QT自带该组件; 1.安装 sqlite-tools-win-x64-3460000、SQLiteExpert5.4.31.575 使用SQLiteExpert建好数据库.db文件,和对应的表后把db文件放在指定目录 ./db/program.db; 2.选择sql组件 3.新…...

【深度学习入门篇 ②】Pytorch完成线性回归!
🍊嗨,大家好,我是小森( ﹡ˆoˆ﹡ )! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。 易编橙:一个帮助编程小…...

Syslog 管理工具
Syslog常被称为系统日志或系统记录,是一种用来在互联网协议(TCP/IP)的网上中传递记录档消息的标准,常用来指涉实际的Syslog 协议,或者那些提交syslog消息的应用程序或数据库。 系统日志协议(Syslog&#x…...

硅纪元AI应用推荐 | 百度橙篇成新宠,能写万字长文
“硅纪元AI应用推荐”栏目,为您精选最新、最实用的人工智能应用,无论您是AI发烧友还是新手,都能在这里找到提升生活和工作的利器。与我们一起探索AI的无限可能,开启智慧新时代! 百度橙篇,作为百度公司在202…...

Codeforces Round 954 (Div. 3)
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,彩笔ACMer一枚。 🏀所属专栏:Codeforces 本文用于记录回顾本彩笔的解题思路便于加深理解。 📢📢📢传送阵 A. X Axis解…...

【Django】报错‘staticfiles‘ is not a registered tag library
错误截图 错误原因总结 在django3.x版本中staticfiles被static替换了,所以这地方换位static即可完美运行 错误解决...
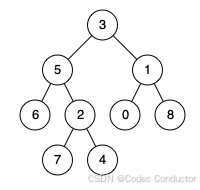
LeetCode 算法:二叉树的最近公共祖先 III c++
原题链接🔗:二叉树的最近公共祖先 难度:中等⭐️⭐️ 题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点…...

Windows CMD 命令汇总表
Windows CMD 命令汇总表 Windows CMD 命令汇总表目录操作磁盘操作文件操作其他命令FTP 命令高级系统命令批处理命令网络命令安全和权限命令 Windows CMD 命令指南目录操作MD - 创建子目录CD - 切换当前目录RD - 删除子目录DIR - 显示目录内容PATH - 设置可执行文件的搜索路径TR…...

【python+appium】自动化测试
pythonappium自动化测试系列就要告一段落了,本篇博客咱们做个小结。 首先想要说明一下,APP自动化测试可能很多公司不用,但也是大部分自动化测试工程师、高级测试工程师岗位招聘信息上要求的,所以为了更好的待遇,我们还…...
vue 数据类型
文章目录 ref 创建:基本类型的响应式数据reactive 创建:对象类型的响应式数据ref 创建:对象类型的响应式数据ref 对比 reactive将一个响应式对象中的每一个属性,转换为ref对象(toRefs 与 toRef)computed (根据计算进行修改) ref 创…...
)
MySQL(基础篇)
DDL (Data Definition Language) 数据定义语言,用来定义数据库对象(数据库,表, 字段) DML (Data Manipulation Languag) 数据操作语言,用来对数据库表中的数据进行增删改 DQL (Data Query Language) 数据查询语言,用…...
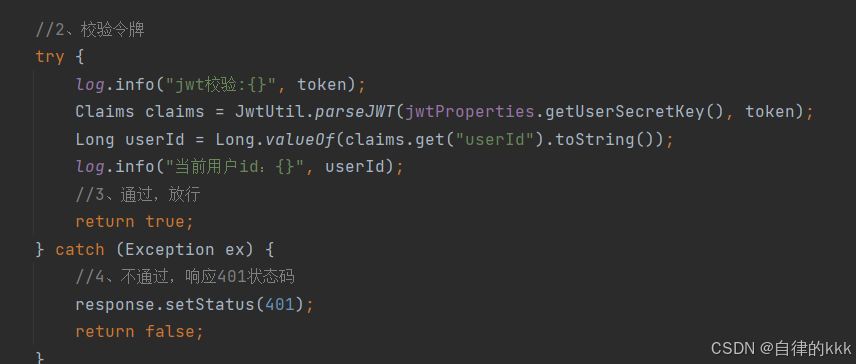
springboot中通过jwt令牌校验以及前端token请求头进行登录拦截实战
前言 大家从b站大学学习的项目侧重点好像都在基础功能的实现上,反而一个项目最根本的登录拦截请求接口都不会写,怎么拦截?为什么拦截?只知道用户登录时我后端会返回一个token,这个token是怎么生成的,我把它…...

从零开始开发视频美颜SDK:实现直播美颜效果
因此,开发一款从零开始的视频美颜SDK,不仅可以节省成本,还能根据具体需求进行个性化调整。本文将介绍从零开始开发视频美颜SDK的关键步骤和实现思路。 一、需求分析与技术选型 在开发一款视频美颜SDK之前,首先需要进行详细的需求…...

极验语序点选验证码识别(一)
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 极验文字点选验证码不必多说,很多小伙伴,借助标注工具或者打码平台标注完数据集后,使用开源的目标检测网络即可完成,欢迎收看我之前的文章: Pytorch利用ddddocr辅助识别点选验证码 或者使…...
什么是 HTTP POST 请求?初学者指南与示范
在现代网络开发领域,理解并应用 HTTP 请求 方法是基本的要求,其中 "POST" 方法扮演着关键角色。 理解 POST 方法 POST 方法属于 HTTP 协议的一部分,主旨在于向服务器发送数据以执行资源的创建或更新。它与 GET 方法区分开来&…...
第一次作业
任务需求:1.DMz区内的服务器,办公区仅能在办公时间内(9-18)可以访问,生产区的设备全天可以访问 2.生产区不允许访问互联网,办公区和游客区可以访问互联网 3.办公区设备10.0.2.10不允许访问DMZ区的FTP服务器和http服务器,仅能ping通…...

【机器学习】12.十大算法之一支持向量机(SVM - Support Vector Machine)算法原理讲解
【机器学习】12.十大算法之一支持向量机(SVM - Support Vector Machine)算法原理讲解 一摘要二个人简介三基本概念四支持向量与超平面4.1 超平面(Hyperplane)4.2 支持向量(Support Vectors)4.3 核技巧&…...

使用 `useAppConfig` :轻松管理应用配置
title: 使用 useAppConfig :轻松管理应用配置 date: 2024/7/11 updated: 2024/7/11 author: cmdragon excerpt: 摘要:本文介绍了Nuxt开发中useAppConfig的使用,它便于访问和管理应用配置,支持动态加载资源、环境配置切换、权限…...

终极免费二维码修复方案:QRazyBox专业工具完全指南
终极免费二维码修复方案:QRazyBox专业工具完全指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox这款强大的QR二维码修…...

WinSW实战:除了开机自启,这样配置还能监控你的Nacos服务状态与日志
WinSW进阶实战:构建Nacos服务的全方位监控体系 对于许多使用Nacos作为注册中心和配置中心的团队来说,确保其稳定运行是系统可靠性的基石。虽然通过WinSW将Nacos注册为Windows服务并实现开机自启解决了基础问题,但真正的挑战在于服务运行后的状…...

技术博主都在悄悄用的Perplexity高级搜索语法,11个未公开符号组合全曝光
更多请点击: https://kaifayun.com 第一章:Perplexity高级搜索语法的底层逻辑与设计哲学 Perplexity 的高级搜索语法并非简单的关键词匹配扩展,而是基于语义意图建模与查询图谱重构的设计实践。其核心在于将用户自然语言查询实时编译为可执行…...

2025最权威的十大AI科研工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术研讨范畴正在历经深度的变动,人工智能论文工具现身,极大地提高了…...

透明计费如何帮助精准预测与控制AI功能月度开支
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费如何帮助精准预测与控制AI功能月度开支 1. 项目背景:深度集成AI的网站 我们负责一个内容创作辅助网站&#x…...

如何为本地音乐库批量下载同步歌词:LRCGET终极指南
如何为本地音乐库批量下载同步歌词:LRCGET终极指南 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 还在为海量本地音乐文件找不到歌词而烦恼…...

AI 系统多模型路由与降级架构设计:从流量调度到无感切换的工程实践
背景 / 现象 在一个典型的 AI 应用系统中,主模型(如 GPT-4o、Claude 3.5 等)通常承担核心推理任务。但在生产环境中,主模型可能因额度耗尽、响应超时、服务不可用或突发限流等原因导致调用失败。此时,用户侧可能表现为…...

从 SAP Easy Access Menu 到 FLP 一体化入口:重新理解经典事务在 SAP Fiori 中的价值
在很多企业的数字化项目里,SAP Fiori 往往被理解为一套全新的体验层,而 SAP GUI 则被视为必须逐步替换掉的传统界面。这个判断只说对了一半。真正成熟的 Fiori 落地,不是把旧世界一刀切掉,而是让新旧能力在同一个入口里顺滑协作。SAP Easy Access Menu 的意义,恰恰就在这里…...

WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案
WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的种种限制而烦恼吗…...

用RP2350微控制器实现《黑客帝国》数字雨:嵌入式图形系统实战
1. 项目概述与核心价值如果你和我一样,对《黑客帝国》里那些从屏幕顶端倾泻而下的绿色字符雨有着难以言喻的情结,同时又是个喜欢动手鼓捣硬件的开发者,那么这个项目绝对能让你兴奋起来。它不是一个简单的屏幕保护程序,而是一个完整…...