数据结构第20节 快速排序以及优化
快速排序是一种非常高效的排序算法,由英国计算机科学家托尼·霍尔(Tony Hoare)在1960年代发明。它使用分治法(Divide and Conquer)策略来把一个序列分为较小的部分,然后递归地排序这些部分。
快速排序的基本步骤:
- 选择基准值(Pivot Selection):从序列中选择一个元素作为基准值。通常选择序列的第一个、最后一个或中间的元素,也可以随机选择。
- 分区操作(Partitioning):重新排列序列,使得所有小于基准值的元素都位于基准值的左边,所有大于基准值的元素都位于基准值的右边。完成这个操作后,基准值就位于最终排序后的位置。
- 递归排序子序列:递归地对基准值左边和右边的子序列应用快速排序算法。
分区操作细节:
- 设置两个指针
left和right,left指针从序列的起始位置开始,right指针从序列的结束位置开始。 - 移动
right指针,直到找到一个小于或等于基准值的元素。 - 移动
left指针,直到找到一个大于或等于基准值的元素。 - 如果
left指针在right指针的左边,交换两个指针所指向的元素。 - 重复上述步骤,直到
left和right指针相遇或交叉。 - 当指针交叉时,将基准值与
right指针所指向的元素交换,完成分区操作。
Java代码实现:
下面是一个简单的快速排序算法的Java实现:
public class QuickSort {public static void quickSort(int[] arr, int low, int high) {if (low < high) {// pi is partitioning index, arr[pi] is now at right placeint pi = partition(arr, low, high);// Recursively sort elements before and after partitionquickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high]; // pivotint i = (low - 1); // Index of smaller elementfor (int j = low; j < high; j++) {// If current element is smaller than the pivotif (arr[j] < pivot) {i++;// swap arr[i] and arr[j]int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// swap arr[i+1] and arr[high] (or pivot)int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return i + 1;}// Function to print an arraypublic static void printArray(int[] arr) {for (int value : arr) {System.out.print(value + " ");}System.out.println();}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;quickSort(arr, 0, n - 1);System.out.println("Sorted array:");printArray(arr);}
}
时间复杂度:
- 最佳和平均情况:O(n log n)
- 最差情况:O(n^2),当输入数组已经是排序好的或逆序的,基准值每次都是最小或最大值。
空间复杂度:
- O(log n),由于递归调用栈的空间。
快速排序在实际应用中非常广泛,尤其是在大规模数据集上,因为它能够提供非常好的性能。然而,在某些情况下,例如数据已经接近排序的情况下,快速排序的性能可能会退化,这时可以考虑使用其他排序算法,如堆排序或归并排序。
要优化快速排序算法,我们可以采取几种不同的策略来提高其效率和稳定性。以下是一些常见的改进方法:
-
三数取中法(Median-of-three)选择基准值:
在选择基准值时,使用数组的第一个元素、中间元素和最后一个元素中的中位数作为基准值,这有助于避免最坏情况的发生,特别是在数组已经部分排序的情况下。 -
插入排序小数组:
对于小规模的子数组,使用插入排序替换快速排序。插入排序在小数组上的性能通常优于快速排序,因为它的常数因子较小。 -
尾递归优化:
可以优化递归调用,减少栈空间的使用。具体来说,你可以先递归处理较大的子数组,然后迭代处理较小的子数组,或者使用循环结构替代递归。 -
非递归版本:
使用显式栈来模拟递归调用,这样可以避免系统调用栈的开销。
下面是使用三数取中法和插入排序小数组的优化版快速排序示例代码:
public class OptimizedQuickSort {public static void quickSort(int[] arr, int low, int high) {while (low < high) {// Partition and get the partition index.int pi = partition(arr, low, high);// Recursively sort the left part, but only if it's larger than the right.if (pi - low < high - pi) {quickSort(arr, low, pi - 1);low = pi + 1;} else {quickSort(arr, pi + 1, high);high = pi - 1;}}}private static int partition(int[] arr, int low, int high) {// Median-of-three pivot selectionint mid = (low + high) / 2;if (arr[mid] > arr[high]) {swap(arr, mid, high);}if (arr[low] > arr[high]) {swap(arr, low, high);}if (arr[mid] > arr[low]) {swap(arr, mid, low);}int pivot = arr[low];int i = low + 1;int j = high;while (true) {while (i <= j && arr[i] <= pivot) {i++;}while (i <= j && arr[j] >= pivot) {j--;}if (i <= j) {swap(arr, i, j);} else {break;}}swap(arr, low, j);return j;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void insertionSort(int[] arr, int low, int high) {for (int i = low + 1; i <= high; i++) {int key = arr[i];int j = i - 1;while (j >= low && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;// Optimize: Use insertion sort for small subarraysfor (int i = 0; i < n; i += 16) {insertionSort(arr, i, Math.min((i + 15), (n - 1)));}quickSort(arr, 0, n - 1);System.out.println("Sorted array:");for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
在这个优化版本中,我们使用了三数取中法来选择更合理的基准值,并且对于小于16个元素的小数组使用插入排序进行排序。此外,我们还通过循环结构代替递归来减少栈的使用。这些修改可以帮助提高快速排序在各种情况下的性能和稳定性。
尾递归优化
尾递归优化是指在递归函数中,如果递归调用是函数执行的最后一个操作,那么可以通过一些技巧将其转换为迭代,从而避免栈溢出的风险和减少递归调用的开销。对于快速排序而言,可以优先递归处理较小的子数组,然后返回处理较大的子数组,这样可以保证递归深度不会过大。
下面是一个利用尾递归优化的快速排序Java实现示例:
public class TailRecursiveQuickSort {public static void quickSort(int[] arr, int low, int high) {while (low < high) {// Partitioning indexint pi = partition(arr, low, high);// Recursively sort elements before partition and after partitionif (pi - low < high - pi) {// Sort the smaller part firstquickSort(arr, low, pi - 1);// Update the range for the larger partlow = pi + 1;} else {// Sort the larger part firstquickSort(arr, pi + 1, high);// Update the range for the smaller parthigh = pi - 1;}}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = (low - 1); // index of smaller elementfor (int j = low; j < high; j++) {// If current element is smaller than or equal to pivotif (arr[j] <= pivot) {i++;// swap arr[i] and arr[j]int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// swap arr[i+1] and arr[high] (or pivot)int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return i + 1;}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;quickSort(arr, 0, n - 1);System.out.println("Sorted array:");for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
在这个版本中,quickSort 函数使用了一个循环来处理子数组的排序。在每次循环中,它首先对当前的子数组进行分区操作,然后根据左右两部分的大小决定先递归处理哪一部分。这样做可以确保每次递归调用之后,剩余需要处理的子数组的大小总是比前一次小,从而减少了递归的深度。
然而,值得注意的是,尽管这种优化减少了递归调用的次数,但在最坏情况下,如果每次分区都偏向一侧,递归深度仍然可能较大。因此,结合其他优化策略,如三数取中法选择基准值,可以进一步提高算法的稳定性和性能。
为了进一步提高快速排序的稳定性和性能,可以结合多种优化策略。以下是几种常见的改进方法:
-
三数取中法选择基准值:选取第一个、中间的和最后一个元素中的中值作为基准值,以减少最坏情况的发生。
-
插入排序小数组:对于小规模的子数组,使用插入排序。插入排序在小数组上的效率高于快速排序。
-
随机化基准值选择:随机选择数组中的一个元素作为基准值,可以避免最坏情况的发生,尤其是当数组已部分排序时。
-
双路快速排序(Dual-Pivot QuickSort):同时使用两个基准值,可以减少比较和交换的次数,从而提高性能。
-
尾递归优化:减少递归调用的深度,使用循环结构替代递归。
-
并行化:利用多核处理器的优势,使用并行计算技术对子数组进行排序。
下面是一个结合了三数取中法、插入排序小数组和尾递归优化的快速排序Java实现:
public class OptimizedQuickSort {private static final int INSERTION_SORT_THRESHOLD = 16; // 阈值用于插入排序public static void quickSort(int[] arr, int low, int high) {while (low < high) {// 使用三数取中法选择基准值int pivotIndex = medianOfThree(arr, low, high);int pivot = arr[pivotIndex];// 将基准值放到最后swap(arr, pivotIndex, high);// Partitioning indexint pi = partition(arr, low, high);// Recursively sort elements before partition and after partitionif (pi - low < high - pi) {// Sort the smaller part firstquickSort(arr, low, pi - 1);// Update the range for the larger partlow = pi + 1;} else {// Sort the larger part firstquickSort(arr, pi + 1, high);// Update the range for the smaller parthigh = pi - 1;}}}private static int medianOfThree(int[] arr, int low, int high) {int mid = (low + high) >>> 1; // 使用无符号右移获得中间索引if (arr[mid] > arr[high]) {swap(arr, mid, high);}if (arr[low] > arr[high]) {swap(arr, low, high);}if (arr[mid] > arr[low]) {swap(arr, mid, low);}return low; // 返回中位数的索引}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void insertionSort(int[] arr, int low, int high) {for (int i = low + 1; i <= high; i++) {int key = arr[i];int j = i - 1;while (j >= low && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};int n = arr.length;// 使用插入排序处理小数组for (int i = 0; i < n; i += INSERTION_SORT_THRESHOLD) {insertionSort(arr, i, Math.min(i + INSERTION_SORT_THRESHOLD - 1, n - 1));}// 使用快速排序处理大数组quickSort(arr, 0, n - 1);System.out.println("Sorted array:");for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
这个版本的快速排序算法结合了多种优化策略,提高了排序的性能和稳定性。在实际应用中,根据数据的特点和环境的限制,还可以尝试其他的优化策略以达到最佳效果。例如,对于大规模数据集,可以考虑使用并行快速排序来充分利用多核处理器的能力。
在Java中,利用并行流(parallel streams)或java.util.concurrent包中的工具可以实现并行快速排序。这里,我将展示如何使用Fork/Join框架来实现并行快速排序。
Fork/Join框架是Java 7引入的一种并行编程模型,它允许任务被分割成更小的任务,然后并行执行。在快速排序中,我们可以将大的数组分割成小的子数组,并在不同的线程上并行地对它们进行排序。
下面是一个使用Fork/Join框架的并行快速排序实现:
import java.util.Arrays;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;public class ParallelQuickSort {public static void main(String[] args) {int[] arr = new int[1_000_000];// 初始化数组...for (int i = 0; i < arr.length; i++) {arr[i] = (int)(Math.random() * 1000);}long startTime = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();pool.invoke(new SortTask(arr, 0, arr.length - 1));long endTime = System.currentTimeMillis();System.out.println("Sorting took " + (endTime - startTime) + " ms");// 检查排序是否正确boolean isSorted = true;for (int i = 1; i < arr.length; i++) {if (arr[i] < arr[i - 1]) {isSorted = false;break;}}System.out.println("Is sorted: " + isSorted);}static class SortTask extends RecursiveAction {private final int[] arr;private final int low;private final int high;public SortTask(int[] arr, int low, int high) {this.arr = arr;this.low = low;this.high = high;}@Overrideprotected void compute() {if (low < high) {int pi = partition(arr, low, high);invokeAll(new SortTask(arr, low, pi - 1), new SortTask(arr, pi + 1, high));}}private int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = (low - 1); // index of smaller elementfor (int j = low; j < high; j++) {// If current element is smaller than or equal to pivotif (arr[j] <= pivot) {i++;// swap arr[i] and arr[j]int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// swap arr[i+1] and arr[high] (or pivot)int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return i + 1;}}
}
在上述代码中,SortTask继承自RecursiveAction类,这是Fork/Join框架中的一个抽象类,用于表示一个可并行执行的任务。compute方法定义了任务的执行逻辑。当一个SortTask实例被创建并提交给ForkJoinPool时,它会根据子任务的大小决定是继续分割任务还是直接执行。如果任务足够小,它将直接进行排序;如果任务足够大,它将被分割成更小的子任务,并在多个线程上并行执行。
这种方法特别适用于多核处理器,因为它能有效利用所有可用的CPU核心。但是,对于较小的数据集,由于启动额外线程的开销,传统的单线程排序可能会更快。因此,在实际应用中,你可能还需要调整任务分割的阈值,以找到最适合特定硬件配置的平衡点。
优化后的非递归版本的快速排序算法通常使用显式栈来模拟递归调用的行为,从而避免了递归调用带来的栈溢出风险以及函数调用的开销。下面是一个使用显式栈的非递归快速排序算法的Java实现:
import java.util.ArrayDeque;
import java.util.Deque;public class NonRecursiveQuickSort {public static void quickSort(int[] arr) {Deque<Integer> stack = new ArrayDeque<>();stack.push(0);stack.push(arr.length - 1);while (!stack.isEmpty()) {int high = stack.pop();int low = stack.pop();int pivotIndex = partition(arr, low, high);if (pivotIndex - 1 > low) {stack.push(low);stack.push(pivotIndex - 1);}if (pivotIndex + 1 < high) {stack.push(pivotIndex + 1);stack.push(high);}}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {int[] arr = {10, 7, 8, 9, 1, 5};quickSort(arr);System.out.println("Sorted array:");for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
在这个实现中,我们使用了一个双向队列ArrayDeque作为栈,用于存储待处理的子数组的边界。quickSort函数初始化栈,然后在一个循环中不断弹出栈顶的高边界和低边界,进行分区操作,并根据分区结果更新栈的内容,直到栈为空为止。
这种非递归的方法可以有效地减少内存栈的使用,避免了在递归深度过深时可能出现的栈溢出问题,同时也能保持快速排序的高效性能。在实际应用中,你可以根据具体需求调整分区策略、基准值的选择方法等,以进一步优化排序过程。
相关文章:

数据结构第20节 快速排序以及优化
快速排序是一种非常高效的排序算法,由英国计算机科学家托尼霍尔(Tony Hoare)在1960年代发明。它使用分治法(Divide and Conquer)策略来把一个序列分为较小的部分,然后递归地排序这些部分。 快速排序的基本…...
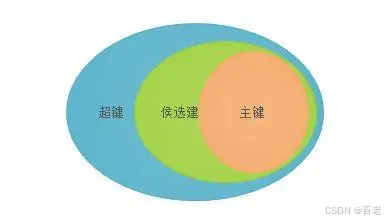
3分钟理解超键、候选键、主键
1.超键 在关系模式中,能唯一标识实体实例的任何属性集 学生(学号,姓名,性别,专业编号,年龄) 通过学号可以找到一个学生的姓名、性别、专业号、年龄,但是通过姓名不一定能找到这些…...

Centos忘记密码,重置root密码
Centos忘记密码,重置root密码 操作环境:Centos7.6 1、选择包含rescue的选项,按e进入编辑模式 首先,我们需要重启系统,进入开机引导菜单界面。在这里,我们可以看到系统的内核版本和启动参数等信息。我们需…...

Android初学者书籍推荐
书单 1.《Android应用开发项目式教程》,机械工业出版社,2024年出版2.《第一行代码Android》第二版3.《第一行代码Android》第三版4.《疯狂Android讲义》第四版5.《Android移动应用基础教程(Android Studio 第2版)》 从学安卓到用安…...

安卓文件上传照片单张及多张照片上传实现
一、首先导入对应库 //网络请求库 implementation com.squareup.okhttp3:okhttp:3.9.0//Gson解析 implementation com.google.code.gson:gson:2.10.1 二、然后就是们实现上传方法 UploaderTool.java import android.util.Log;import com.google.gson.Gson;import java.io.File…...
 bug)
小白学webgl合集-import.meta.url 和 new URL() bug
为什么使用 import.meta.url 和 new URL() 动态路径解析: 在 ESM(ECMAScript Modules)环境中,import.meta.url 提供了当前模块的完整 URL。结合 new URL(),你可以基于这个 URL 动态解析其他资源的路径。这样可以确保路…...

pico+unity3d开启彩色透视
1、点击游戏对象、点击XR、点击添加XR Origin,并把自带的摄像对象删除 2、添加脚本 using System.Collections; using System.Collections.Generic; using UnityEngine; using Unity.XR.PXR;//引入xr对象 public class toushi : MonoBehaviour {// Start is called…...

python常用命令
文章目录 1. 安装模块 1. 安装模块 pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple (切换数据源)...

使用定时器消除抖动
问题:定时器中断和按键中断属于什么操作模式,轮询吗? 具体怎么实现 定时器中断 (判断) 时间参数 按键中断(修改) 中断 向量表.s文件 DCD SysTick_Handler …...

IOS热门面试题一
GCD(Grand Central Dispatch)是什么?如何在iOS中使用它? GCD(Grand Central Dispatch)是什么? GCD(Grand Central Dispatch)是苹果公司开发的一套多线程编程的API&…...
pipeline)
构建LangChain应用程序的示例代码:62、如何使用Oracle AI向量搜索和Langchain构建端到端的RAG(检索增强生成)pipeline
Oracle AI 向量搜索与文档处理 Oracle AI向量搜索专为人工智能(AI)工作负载设计,允许您基于语义而非关键词来查询数据。 Oracle AI向量搜索的最大优势之一是可以在单一系统中结合对非结构化数据的语义搜索和对业务数据的关系搜索。 这不仅功能强大,而且…...

ffmpeg转换MP4为gif命令
这里记录一下使用 ffmpeg去转化 gif 的一些快捷命令 # 直接转换 ffmpeg -i 222.mp4 -r 12 222.gif# 调色板优化处理 ffmpeg -i 222.mp4 -r 12 -vf "split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" 222.gif第二条命令的解释如下: split[s0][s1]&am…...

kotlin Flow 学习指南 (三)最终篇
目录 前言Flow生命周期StateFlow 替代LiveDataSharedFlow其他常见应用场景处理复杂、耗时逻辑存在依赖关系的接口请求组合多个接口的数据 Flow使用注意事项总结 前言 前面两篇文章,介绍了Flow是什么,如何使用,以及相关的操作符进阶ÿ…...

Memcached负载均衡:揭秘高效缓存分发策略
标题:Memcached负载均衡:揭秘高效缓存分发策略 在分布式缓存系统中,Memcached通过负载均衡技术来提高缓存效率和系统吞吐量。负载均衡确保了缓存请求能够均匀地分配到多个缓存节点上,从而防止任何一个节点过载。本文将深入探讨Me…...
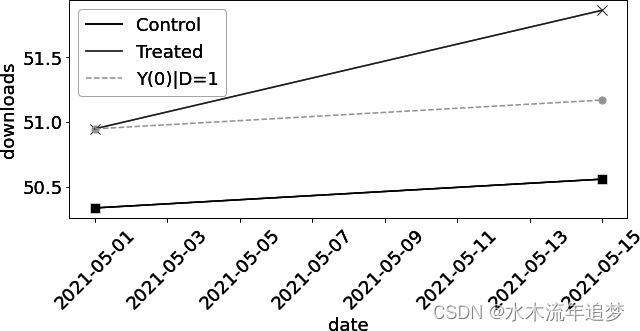
【Python实战因果推断】31_双重差分2
目录 Canonical Difference-in-Differences Diff-in-Diff with Outcome Growth Canonical Difference-in-Differences 差分法的基本思想是,通过使用受治疗单位的基线,但应用对照单位的结果(增长)演变,来估算缺失的潜…...

ArcGIS中使用线快速构造成面的方法
准备工作:一个需要转化为面的封闭线;一个处于可编辑状态的面要素文件。 1.选中一个围合封闭成的线 2.点击高级编辑工具中的构造面小工具 3.弹出对话框,直接点确定即可 4.效果如下图: 特别注意:记得要把面图层编辑功能…...

Spring AOP的几种实现方式
1.通过注解实现 1.1导入依赖 <dependency><groupId>org.springframework</groupId><artifactId>spring-aop</artifactId><version>5.1.6.RELEASE</version></dependency> 1.2定义注解 import java.lang.annotation.*;Targ…...

字节码编程bytebuddy之实现抽象类并并添加自定义注解
写在前面 本文看下使用bytebuddy如何实现抽象类,并在子类中添加自定义注解。 1:代码 1.1:准备基础代码 类和方法注解 package com.dahuyou.bytebuddy.cc.mine;import java.lang.annotation.ElementType; import java.lang.annotation.Re…...
LLM-阿里云 DashVector + ModelScope 多模态向量化实时文本搜图实战总结
文章目录 前言步骤图片数据Embedding入库文本检索 完整代码 前言 本文使用阿里云的向量检索服务(DashVector),结合 ONE-PEACE多模态模型,构建实时的“文本搜图片”的多模态检索能力。整体流程如下: 多模态数据Embedd…...

CentOS7安装部署git和gitlab
安装Git 在Linux系统中是需要编译源码的,首先下载所需要的依赖: yum install -y curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker方法一 下载: wget https://mirrors.edge.kernel.org/pub/s…...

终极3D转2D视频转换器:让VR内容在普通设备上“活“起来
终极3D转2D视频转换器:让VR内容在普通设备上"活"起来 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.…...

Beam Search超参数调优指南:从原理到实践,如何为你的NLP任务选择最佳beam width?
Beam Search超参数调优实战:如何在生成质量与推理效率间找到平衡点 当GPT-3生成那段令人惊艳的诗歌时,背后其实经历了几百次候选序列的评估与筛选——这正是beam search算法的魔力所在。作为自然语言生成任务中最核心的解码策略之一,beam wid…...

掌握SRA Tools:3步轻松处理高通量测序数据的高效工具
掌握SRA Tools:3步轻松处理高通量测序数据的高效工具 【免费下载链接】sra-tools SRA Tools 项目地址: https://gitcode.com/gh_mirrors/sr/sra-tools SRA Tools是处理NCBI Sequence Read Archive数据的核心工具集,让你可以轻松地下载、转换和分析…...
)
胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比=1.03:0.97:1.12)
更多请点击: https://codechina.net 第一章:胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比1.03:0.97:1.12) 胶片颗粒是银盐晶体在显影过程中形成的物理性随机簇状结构,…...

第P5周:Pytorch实现运动鞋识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人体悟:今天学习了动态学习率有种豁然开朗的感觉,在引入该部分之后模型的学习速度和学习质量都得到了较大提升!...

Runtime不是跑kernel的——它是昇腾CANN里的执行层
前言 昇腾NPU上的算子是怎么跑起来的?有人说"runtime就是负责跑kernel的",有人说"runtime管内存分配",还有人说"runtime就是CUDA runtime的对应物"。这些答案都有对的地方,但都没说到根子上。 Ru…...

3Dmigoto:如何让破败的立体游戏重获新生?
3Dmigoto:如何让破败的立体游戏重获新生? 【免费下载链接】3Dmigoto DX11 modding wrapper to enable fixing broken stereoscopic effects. Warning: 3Dmigoto[.]com is a phishing site, not us. 项目地址: https://gitcode.com/gh_mirrors/3d/3Dmig…...

Proxmox-Arm64:ARM架构企业级虚拟化的技术突破与实现
Proxmox-Arm64:ARM架构企业级虚拟化的技术突破与实现 【免费下载链接】Proxmox-Arm64 Proxmox VE & PBS unofficial arm64 version 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmox-Arm64 随着ARM64架构在服务器、边缘计算和嵌入式领域的快速普及&…...

Vue Antd Admin架构完全指南:从设计哲学到最佳实践
Vue Antd Admin架构完全指南:从设计哲学到最佳实践 【免费下载链接】vue-antd-admin 🐜 Ant Design Pros implementation with Vue 项目地址: https://gitcode.com/gh_mirrors/vu/vue-antd-admin Vue Antd Admin是一款基于Vue.js和Ant Design Pro…...

Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案
Mac NTFS读写终极指南:Free NTFS for Mac完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management fo…...