构建LangChain应用程序的示例代码:62、如何使用Oracle AI向量搜索和Langchain构建端到端的RAG(检索增强生成)pipeline
Oracle AI 向量搜索与文档处理
Oracle AI向量搜索专为人工智能(AI)工作负载设计,允许您基于语义而非关键词来查询数据。
Oracle AI向量搜索的最大优势之一是可以在单一系统中结合对非结构化数据的语义搜索和对业务数据的关系搜索。
这不仅功能强大,而且显著更有效,因为您不需要添加专门的向量数据库,从而消除了多个系统之间数据碎片化的痛点。
此外,您的向量可以受益于Oracle数据库所有最强大的功能,如以下这些:
- 分区支持
- Real Application Clusters可扩展性
- Exadata智能扫描
- 跨地理分布数据库的分片处理
- 事务
- 并行SQL
- 灾难恢复
- 安全性
- Oracle机器学习
- Oracle图数据库
- Oracle空间和图形
- Oracle区块链
- JSON
本指南演示了如何使用Oracle AI向量搜索与Langchain来服务端到端的RAG pipeline。本指南通过示例展示了:
- 使用OracleDocLoader从各种来源加载文档
- 使用OracleSummary在数据库内/外对它们进行摘要
- 使用OracleEmbeddings在数据库内/外为它们生成嵌入
- 使用OracleTextSplitter的高级Oracle功能根据不同需求对它们进行分块
- 在向量存储中存储和索引它们,并在OracleVS中为查询查询它们
如果您刚开始使用Oracle数据库,可以考虑探索免费的Oracle 23 AI,它为设置您的数据库环境提供了很好的介绍。在使用数据库时,通常建议避免默认使用系统用户;相反,您可以创建自己的用户以增强安全性和自定义性。有关用户创建的详细步骤,请参阅我们的端到端指南,它还展示了如何在Oracle中设置用户。此外,了解用户权限对于有效管理数据库安全至关重要。您可以在官方Oracle指南中了解更多关于管理用户账户和安全性的信息。
先决条件
请安装Oracle Python客户端驱动程序以使用Langchain和Oracle AI向量搜索。
# pip install oracledb
# 安装Oracle Python客户端驱动程序
创建演示用户
首先,创建一个具有所有必需权限的演示用户。
import sys
import oracledb# 请更新您的用户名、密码、主机名和服务名
# 请确保此用户具有执行以下所有操作的足够权限
username = ""
password = ""
dsn = ""try:conn = oracledb.connect(user=username, password=password, dsn=dsn)print("连接成功!")cursor = conn.cursor()cursor.execute("""begin-- 删除用户beginexecute immediate 'drop user testuser cascade';exceptionwhen others thendbms_output.put_line('设置用户时出错。');end;execute immediate 'create user testuser identified by testuser';execute immediate 'grant connect, unlimited tablespace, create credential, create procedure, create any index to testuser';execute immediate 'create or replace directory DEMO_PY_DIR as ''/scratch/hroy/view_storage/hroy_devstorage/demo/orachain''';execute immediate 'grant read, write on directory DEMO_PY_DIR to public';execute immediate 'grant create mining model to testuser';-- 网络访问beginDBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(host => '*',ace => xs$ace_type(privilege_list => xs$name_list('connect'),principal_name => 'testuser',principal_type => xs_acl.ptype_db));end;end;""")print("用户设置完成!")cursor.close()conn.close()
except Exception as e:print("用户设置失败!")cursor.close()conn.close()sys.exit(1)
使用Oracle AI处理文档
考虑以下场景:用户拥有存储在Oracle数据库或文件系统中的文档,并打算将这些数据与由Langchain支持的Oracle AI向量搜索一起使用。
为了准备文档进行分析,需要一个全面的预处理工作流程。首先,必须检索文档,根据需要进行摘要,并按需分块。随后的步骤涉及为这些块生成嵌入并将它们集成到Oracle AI向量存储中。然后,用户可以对这些数据进行语义搜索。
Oracle AI向量搜索Langchain库包含一套文档处理工具,可以促进文档加载、分块、摘要生成和嵌入创建。
在接下来的部分中,我们将详细说明如何使用Oracle AI Langchain API有效地实现这些过程中的每一个。
连接到演示用户
以下示例代码将展示如何连接到Oracle数据库。默认情况下,python-oracledb 以"瘦"模式运行,直接连接到Oracle数据库。这种模式不需要Oracle客户端库。然而,当python-oracledb使用它们时,一些额外的功能是可用的。当使用Oracle客户端库时,python-oracledb被称为处于"厚"模式。两种模式都有全面的功能,支持Python数据库API v2.0规范。参见以下指南,其中讨论了每种模式支持的功能。如果您无法使用瘦模式,可能需要切换到厚模式。
import sys
import oracledb# 请更新您的用户名、密码、主机名和服务名
username = ""
password = ""
dsn = ""try:conn = oracledb.connect(user=username, password=password, dsn=dsn)print("连接成功!")
except Exception as e:print("连接失败!")sys.exit(1)
填充演示表
创建一个演示表并插入一些示例文档。
try:cursor = conn.cursor()drop_table_sql = """drop table demo_tab"""cursor.execute(drop_table_sql)# 删除已存在的demo_tab表create_table_sql = """create table demo_tab (id number, data clob)"""cursor.execute(create_table_sql)# 创建新的demo_tab表,包含id和data两列insert_row_sql = """insert into demo_tab values (:1, :2)"""rows_to_insert = [(1,"如果前面任何问题的答案是肯定的,那么数据库将停止搜索并从指定的表空间分配空间;否则,将从数据库默认共享临时表空间分配空间。",),(2,"当数据库打开时,表空间可以是在线(可访问)或离线(不可访问)。\n表空间通常在线,以便用户可以访问其数据。SYSTEM表空间和临时表空间不能离线。",),(3,"数据库存储LOB的方式与其他数据类型不同。创建LOB列隐式创建LOB段和LOB索引。包含LOB段和LOB索引(它们总是存储在一起)的表空间可能与包含表的表空间不同。\n有时,数据库可以将少量LOB数据存储在表本身中,而不是在单独的LOB段中。",),]cursor.executemany(insert_row_sql, rows_to_insert)# 向demo_tab表中插入示例数据conn.commit()print("表创建并填充完成。")cursor.close()
except Exception as e:print("表创建失败。")cursor.close()conn.close()sys.exit(1)
随着演示用户和填充的示例表的包含,剩余的配置涉及设置嵌入和摘要功能。用户有多个提供者选项,包括本地数据库解决方案和第三方服务,如Ocigenai、Hugging Face和OpenAI。如果用户选择第三方提供者,他们需要建立包含必要认证详细信息的凭据。相反,如果选择数据库作为嵌入的提供者,则需要将ONNX模型上传到Oracle数据库。使用数据库选项时,摘要功能不需要额外设置。
加载ONNX模型
Oracle支持各种嵌入提供者,使用户能够在专有数据库解决方案和第三方服务(如OCIGENAI和HuggingFace)之间进行选择。这个选择决定了生成和管理嵌入的方法。
重要提示:如果用户选择数据库选项,他们必须将ONNX模型上传到Oracle数据库。相反,如果选择第三方提供者进行嵌入生成,则不需要将ONNX模型上传到Oracle数据库。
直接在Oracle中使用ONNX模型的一个显著优势是它通过消除向外部方传输数据的需求来提供增强的安全性和性能。此外,这种方法避免了通常与网络或REST API调用相关的延迟。
以下是将ONNX模型上传到Oracle数据库的示例代码:
from langchain_community.embeddings.oracleai import OracleEmbeddings# 请更新您的相关信息
# 确保系统中有onnx文件
onnx_dir = "DEMO_PY_DIR"
onnx_file = "tinybert.onnx"
model_name = "demo_model"try:OracleEmbeddings.load_onnx_model(conn, onnx_dir, onnx_file, model_name)print("ONNX模型加载完成。")
except Exception as e:print("ONNX模型加载失败!")sys.exit(1)
创建凭据
当选择第三方提供者生成嵌入时,用户需要建立凭据以安全地访问提供者的端点。
重要提示: 当选择"database"提供者生成嵌入时不需要凭据。但是,如果用户决定使用第三方提供者,他们必须创建特定于所选提供者的凭据。
以下是一个说明性示例:
try:cursor = conn.cursor()cursor.execute("""declarejo json_object_t;begin-- HuggingFacedbms_vector_chain.drop_credential(credential_name => 'HF_CRED');jo := json_object_t();jo.put('access_token', '<access_token>');dbms_vector_chain.create_credential(credential_name => 'HF_CRED',params => json(jo.to_string));-- OCIGENAIdbms_vector_chain.drop_credential(credential_name => 'OCI_CRED');jo := json_object_t();jo.put('user_ocid','<user_ocid>');jo.put('tenancy_ocid','<tenancy_ocid>');jo.put('compartment_ocid','<compartment_ocid>');jo.put('private_key','<private_key>');jo.put('fingerprint','<fingerprint>');dbms_vector_chain.create_credential(credential_name => 'OCI_CRED',params => json(jo.to_string));end;""")cursor.close()print("凭据创建完成。")
except Exception as ex:cursor.close()raise
加载文档
用户可以通过适当配置加载器参数,灵活地从Oracle数据库、文件系统或两者加载文档。有关这些参数的详细信息,请参阅Oracle AI向量搜索指南。
使用OracleDocLoader的一个显著优势是其处理超过150种不同文件格式的能力,消除了对不同文档类型使用多个加载器的需求。有关支持的格式的完整列表,请参阅Oracle Text支持的文档格式。
以下是展示如何使用OracleDocLoader的示例代码片段
from langchain_community.document_loaders.oracleai import OracleDocLoader
from langchain_core.documents import Document# 从Oracle数据库表加载
# 确保您有具有此规格的表
loader_params = {}
loader_params = {"owner": "testuser","tablename": "demo_tab","colname": "data",
}""" 加载文档 """
loader = OracleDocLoader(conn=conn, params=loader_params)
docs = loader.load()""" 验证 """
print(f"加载的文档数量: {len(docs)}")
# print(f"Document-0: {docs[0].page_content}") # 内容
生成摘要
现在用户已经加载了文档,他们可能希望为每个文档生成摘要。Oracle AI向量搜索Langchain库提供了一套用于文档摘要的API。它支持多个摘要提供者,如数据库、OCIGENAI、HuggingFace等,允许用户选择最适合他们需求的提供者。要利用这些功能,用户必须按照指定配置摘要参数。有关这些参数的详细信息,请参阅Oracle AI向量搜索指南。
注意: 如果用户想使用除Oracle内置和默认提供者"database"之外的第三方摘要生成提供者,可能需要设置代理。如果您没有代理,请在实例化OracleSummary时删除代理参数。
# 在实例化摘要和嵌入对象时使用的代理
proxy = ""
以下示例代码将展示如何生成摘要:
from langchain_community.utilities.oracleai import OracleSummary
from langchain_core.documents import Document# 使用 'database' 提供者
summary_params = {"provider": "database","glevel": "S","numParagraphs": 1,"language": "english",
}# 获取摘要实例
# 如果不需要,请移除代理
summ = OracleSummary(conn=conn, params=summary_params, proxy=proxy)list_summary = []
for doc in docs:summary = summ.get_summary(doc.page_content)list_summary.append(summary)""" 验证 """
print(f"摘要数量: {len(list_summary)}")
# print(f"Summary-0: {list_summary[0]}") #内容
分割文档
文档的大小可能从小到非常大不等。用户通常倾向于将他们的文档分割成更小的部分以便于生成嵌入。这个分割过程有广泛的自定义选项。有关这些参数的详细信息,请参阅Oracle AI向量搜索指南。
以下是说明如何实现这一点的示例代码:
from langchain_community.document_loaders.oracleai import OracleTextSplitter
from langchain_core.documents import Document# 使用默认参数进行分割
splitter_params = {"normalize": "all"}""" 获取分割器实例 """
splitter = OracleTextSplitter(conn=conn, params=splitter_params)list_chunks = []
for doc in docs:chunks = splitter.split_text(doc.page_content)list_chunks.extend(chunks)""" 验证 """
print(f"块的数量: {len(list_chunks)}")
# print(f"Chunk-0: {list_chunks[0]}") # 内容
生成嵌入
现在文档已按要求分块,用户可能希望为这些块生成嵌入。Oracle AI向量搜索提供了多种生成嵌入的方法,使用本地托管的ONNX模型或第三方API。有关配置这些替代方案的全面说明,请参阅Oracle AI向量搜索指南。
注意: 目前,OracleEmbeddings通过单独调用REST端点来单独处理每个嵌入生成请求,而不进行批处理。这种方法可能导致超过某些提供者设置的每分钟最大请求配额。然而,我们正在积极工作,通过实现请求批处理来增强这个过程,这将允许将多个嵌入请求组合成更少的API调用,从而优化我们对提供者资源的使用并遵守他们的请求限制。预计这个更新很快就会推出,消除当前的限制。
注意: 用户可能需要配置代理以使用第三方嵌入生成提供者,不包括使用ONNX模型的’database’提供者。
# 在实例化摘要和嵌入对象时使用的代理
proxy = ""
以下示例代码将展示如何生成嵌入:
from langchain_community.embeddings.oracleai import OracleEmbeddings
from langchain_core.documents import Document# 使用加载到Oracle数据库的ONNX模型
embedder_params = {"provider": "database", "model": "demo_model"}# 获取嵌入实例
# 如果不需要,请移除代理
embedder = OracleEmbeddings(conn=conn, params=embedder_params, proxy=proxy)embeddings = []
for doc in docs:chunks = splitter.split_text(doc.page_content)for chunk in chunks:embed = embedder.embed_query(chunk)embeddings.append(embed)""" 验证 """
print(f"嵌入数量: {len(embeddings)}")
# print(f"Embedding-0: {embeddings[0]}") # 内容
创建Oracle AI向量存储
现在您已经了解如何单独使用Oracle AI Langchain库API来处理文档,让我们展示如何与Oracle AI向量存储集成以促进语义搜索。
首先,让我们导入所有依赖项。
import sysimport oracledb
from langchain_community.document_loaders.oracleai import (OracleDocLoader,OracleTextSplitter,
)
from langchain_community.embeddings.oracleai import OracleEmbeddings
from langchain_community.utilities.oracleai import OracleSummary
from langchain_community.vectorstores import oraclevs
from langchain_community.vectorstores.oraclevs import OracleVS
from langchain_community.vectorstores.utils import DistanceStrategy
from langchain_core.documents import Document
接下来,让我们将所有文档处理阶段组合在一起。以下是示例代码:
"""
在这个示例中,我们将对摘要和嵌入使用'database'提供者。
因此,我们不需要执行以下操作:- 为第三方提供者设置代理- 为第三方提供者创建凭据如果您选择使用第三方提供者,
请按照代理和凭据的必要步骤操作。
"""# oracle连接
# 请更新您的用户名、密码、主机名和服务名
username = ""
password = ""
dsn = ""try:conn = oracledb.connect(user=username, password=password, dsn=dsn)print("连接成功!")
except Exception as e:print("连接失败!")sys.exit(1)# 加载onnx模型
# 请用您的相关信息更新
onnx_dir = "DEMO_PY_DIR"
onnx_file = "tinybert.onnx"
model_name = "demo_model"
try:OracleEmbeddings.load_onnx_model(conn, onnx_dir, onnx_file, model_name)print("ONNX模型加载完成。")
except Exception as e:print("ONNX模型加载失败!")sys.exit(1)# 参数
# 请用相关信息更新必要的字段
loader_params = {"owner": "testuser","tablename": "demo_tab","colname": "data",
}
summary_params = {"provider": "database","glevel": "S","numParagraphs": 1,"language": "english",
}
splitter_params = {"normalize": "all"}
embedder_params = {"provider": "database", "model": "demo_model"}# 实例化加载器、摘要、分割器和嵌入器
loader = OracleDocLoader(conn=conn, params=loader_params)
summary = OracleSummary(conn=conn, params=summary_params)
splitter = OracleTextSplitter(conn=conn, params=splitter_params)
embedder = OracleEmbeddings(conn=conn, params=embedder_params)# 处理文档
chunks_with_mdata = []
for id, doc in enumerate(docs, start=1):summ = summary.get_summary(doc.page_content)chunks = splitter.split_text(doc.page_content)for ic, chunk in enumerate(chunks, start=1):chunk_metadata = doc.metadata.copy()chunk_metadata["id"] = chunk_metadata["_oid"] + "$" + str(id) + "$" + str(ic)chunk_metadata["document_id"] = str(id)chunk_metadata["document_summary"] = str(summ[0])chunks_with_mdata.append(Document(page_content=str(chunk), metadata=chunk_metadata))""" 验证 """
print(f"带有元数据的总块数: {len(chunks_with_mdata)}")
此时,我们已经处理了文档并生成了带有元数据的块。接下来,我们将使用这些块创建Oracle AI向量存储。
以下是如何实现的示例代码:
# 创建Oracle AI向量存储
vectorstore = OracleVS.from_documents(chunks_with_mdata,embedder,client=conn,table_name="oravs",distance_strategy=DistanceStrategy.DOT_PRODUCT,
)""" 验证 """
print(f"向量存储表: {vectorstore.table_name}")
提供的示例演示了使用DOT_PRODUCT距离策略创建向量存储。用户可以灵活地使用Oracle AI向量存储的各种距离策略,详情请参阅我们的全面指南。
现在嵌入已存储在向量存储中,建议建立一个索引以增强查询执行期间的语义搜索性能。
注意 如果遇到"内存不足"错误,建议在数据库配置中增加 vector_memory_size
以下是创建索引的示例代码片段:
oraclevs.create_index(conn, vectorstore, params={"idx_name": "hnsw_oravs", "idx_type": "HNSW"}
)print("索引创建完成。")
这个例子演示了在’oravs’表中的嵌入上创建默认HNSW索引。用户可以根据他们的特定需求调整各种参数。有关这些参数的详细信息,请参阅Oracle AI向量搜索指南。
此外,可以创建各种类型的向量索引以满足不同的需求。更多详情可以在我们的全面指南中找到。
执行语义搜索
一切就绪!
我们已经成功处理了文档并将它们存储在向量存储中,然后创建了索引以增强查询性能。我们现在准备进行语义搜索。
以下是这个过程的示例代码:
query = "What is Oracle AI Vector Store?"
filter = {"document_id": ["1"]}# Similarity search without a filter
print(vectorstore.similarity_search(query, 1))# Similarity search with a filter
print(vectorstore.similarity_search(query, 1, filter=filter))# Similarity search with relevance score
print(vectorstore.similarity_search_with_score(query, 1))# Similarity search with relevance score with filter
print(vectorstore.similarity_search_with_score(query, 1, filter=filter))# Max marginal relevance search
print(vectorstore.max_marginal_relevance_search(query, 1, fetch_k=20, lambda_mult=0.5))# Max marginal relevance search with filter
print(vectorstore.max_marginal_relevance_search(query, 1, fetch_k=20, lambda_mult=0.5, filter=filter)
)
总结
本文档详细介绍了如何使用Oracle AI向量搜索和Langchain构建端到端的RAG(检索增强生成)pipeline。主要内容包括:
- 环境设置和用户创建
- 文档处理流程:加载、摘要生成、分块和嵌入生成
- Oracle AI向量存储的创建和索引建立
- 语义搜索的实现和示例
本指南突出了Oracle AI向量搜索的强大功能,包括与关系型数据的结合、广泛的文档格式支持、灵活的嵌入和摘要生成选项,以及优化的搜索性能。
相关文章:
pipeline)
构建LangChain应用程序的示例代码:62、如何使用Oracle AI向量搜索和Langchain构建端到端的RAG(检索增强生成)pipeline
Oracle AI 向量搜索与文档处理 Oracle AI向量搜索专为人工智能(AI)工作负载设计,允许您基于语义而非关键词来查询数据。 Oracle AI向量搜索的最大优势之一是可以在单一系统中结合对非结构化数据的语义搜索和对业务数据的关系搜索。 这不仅功能强大,而且…...

ffmpeg转换MP4为gif命令
这里记录一下使用 ffmpeg去转化 gif 的一些快捷命令 # 直接转换 ffmpeg -i 222.mp4 -r 12 222.gif# 调色板优化处理 ffmpeg -i 222.mp4 -r 12 -vf "split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" 222.gif第二条命令的解释如下: split[s0][s1]&am…...

kotlin Flow 学习指南 (三)最终篇
目录 前言Flow生命周期StateFlow 替代LiveDataSharedFlow其他常见应用场景处理复杂、耗时逻辑存在依赖关系的接口请求组合多个接口的数据 Flow使用注意事项总结 前言 前面两篇文章,介绍了Flow是什么,如何使用,以及相关的操作符进阶ÿ…...

Memcached负载均衡:揭秘高效缓存分发策略
标题:Memcached负载均衡:揭秘高效缓存分发策略 在分布式缓存系统中,Memcached通过负载均衡技术来提高缓存效率和系统吞吐量。负载均衡确保了缓存请求能够均匀地分配到多个缓存节点上,从而防止任何一个节点过载。本文将深入探讨Me…...
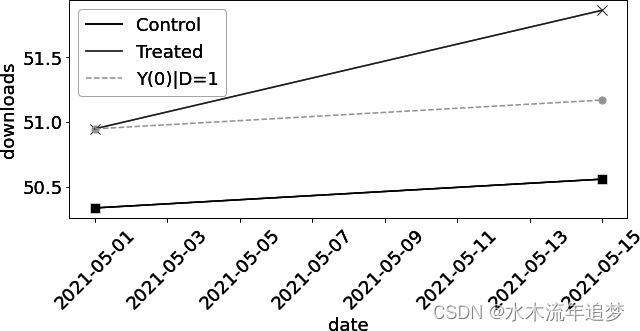
【Python实战因果推断】31_双重差分2
目录 Canonical Difference-in-Differences Diff-in-Diff with Outcome Growth Canonical Difference-in-Differences 差分法的基本思想是,通过使用受治疗单位的基线,但应用对照单位的结果(增长)演变,来估算缺失的潜…...

ArcGIS中使用线快速构造成面的方法
准备工作:一个需要转化为面的封闭线;一个处于可编辑状态的面要素文件。 1.选中一个围合封闭成的线 2.点击高级编辑工具中的构造面小工具 3.弹出对话框,直接点确定即可 4.效果如下图: 特别注意:记得要把面图层编辑功能…...

Spring AOP的几种实现方式
1.通过注解实现 1.1导入依赖 <dependency><groupId>org.springframework</groupId><artifactId>spring-aop</artifactId><version>5.1.6.RELEASE</version></dependency> 1.2定义注解 import java.lang.annotation.*;Targ…...

字节码编程bytebuddy之实现抽象类并并添加自定义注解
写在前面 本文看下使用bytebuddy如何实现抽象类,并在子类中添加自定义注解。 1:代码 1.1:准备基础代码 类和方法注解 package com.dahuyou.bytebuddy.cc.mine;import java.lang.annotation.ElementType; import java.lang.annotation.Re…...
LLM-阿里云 DashVector + ModelScope 多模态向量化实时文本搜图实战总结
文章目录 前言步骤图片数据Embedding入库文本检索 完整代码 前言 本文使用阿里云的向量检索服务(DashVector),结合 ONE-PEACE多模态模型,构建实时的“文本搜图片”的多模态检索能力。整体流程如下: 多模态数据Embedd…...

CentOS7安装部署git和gitlab
安装Git 在Linux系统中是需要编译源码的,首先下载所需要的依赖: yum install -y curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker方法一 下载: wget https://mirrors.edge.kernel.org/pub/s…...

《昇思25天学习打卡营第16天|基于MindNLP+MusicGen生成自己的个性化音乐》
MindNLP 原理 MindNLP 是一个自然语言处理(NLP)框架,用于处理和分析文本数据。 文本预处理:包括去除噪声、分词、词性标注、命名实体识别等步骤,使文本数据格式化并准备好进行进一步分析。 特征提取:将文…...

算法学习day10(贪心算法)
贪心算法:由局部最优->全局最优 贪心算法一般分为如下四步: 将问题分解为若干个子问题找出适合的贪心策略求解每一个子问题的最优解将局部最优解堆叠成全局最优解 一、摆动序列(理解难) 连续数字之间的差有正负的交替&…...
卡尔曼滤波Kalman Filter零基础入门到实践(上部)
参考视频:入门(秒懂滤波概要)_哔哩哔哩_bilibili 一、入门 1.引入 假设超声波距离传感器每1ms给单片机发数据。 理论数据为黑点, 测量数据曲线为红线,引入滤波后的数据为紫线 引入滤波的作用是过滤数据中的噪声&a…...
力扣-dfs
何为深度优先搜索算法? 深度优先搜索算法,即DFS。就是找一个点,往下搜索,搜索到尽头再折回,走下一个路口。 695.岛屿的最大面积 695. 岛屿的最大面积 题目 给你一个大小为 m x n 的二进制矩阵 grid 。 岛屿 是由一些相…...

keepalived高可用集群
一、keepalived: 1.keepalive是lvs集群中的高可用架构,只是针对调度器的高可用,基于vrrp来实现调度器的主和备,也就是高可用的HA架构;设置一台主调度器和一台备调度器,在主调度器正常工作的时候࿰…...

文献翻译与阅读《Integration Approaches for Heterogeneous Big Data: A Survey》
CYBERNETICS AND INFORMATION TECHNOLOGIES’24 论文原文下载地址:原文下载 目录 1 引言 2 大数据概述 3 大数据的异构性 4 讨论整合方法 4.1 大数据仓库(BDW) 4.2 大数据联盟(BDF) 5 DW 和 DF 方法的比较、分…...

应用最优化方法及MATLAB实现——第3章代码实现
一、概述 在阅读最优方法及MATLAB实现后,想着将书中提供的代码自己手敲一遍,来提高自己对书中内容理解程度,巩固一下。 这部分内容主要针对第3章的内容,将其所有代码实现均手敲一遍,中间部分代码自己根据其公式有些许的…...

django的增删改查,排序,分组等常用的ORM操作
Django 的 ORM(对象关系映射)提供了一种方便的方式来与数据库进行交互。 1. Django模型 在 myapp/models.py 中定义一个示例模型:python from django.db import modelsclass Person(models.Model):name models.CharField(max_length100)age…...

Leetcode Java学习记录——树、二叉树、二叉搜索树
文章目录 树的定义树的遍历中序遍历代码 二叉搜索树 常见二维数据结构:树/图 树和图的区别就在于有没有环。 树的定义 public class TreeNode{public int val;public TreeNode left,right;public TreeNode(int val){this.val val;this.left null;this.right nu…...

华为HCIP Datacom H12-821 卷30
1.单选题 以下关于OSPF协议报文说法错误的是? A、OSPF报文采用UDP报文封装并且端口号是89 B、OSPF所有报文的头部格式相同 C、OSPF协议使用五种报文完成路由信息的传递 D、OSPF所有报文头部都携带了Router-ID字段 正确答案:A 解析: OSPF用IP报文直接封装协议报文,…...

在ubuntu上为hermes agent配置taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Hermes Agent 配置 Taotoken 作为自定义模型供应商 基础教程类,面向使用 Hermes Agent 框架构建 AI 应…...

3步高效启用Windows Insider预览计划:免登录离线方案终极指南
3步高效启用Windows Insider预览计划:免登录离线方案终极指南 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: https://g…...

告别抢票焦虑:大麦网双端自动抢票系统深度解析与实战指南
告别抢票焦虑:大麦网双端自动抢票系统深度解析与实战指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾在心仪演出的开票瞬间…...

5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计
5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在为设计项目寻找一款既简洁有力又能免费商用的字体吗?Bebas Neue这款由日本设计…...

深度解析 | SRE 核心机制:如何通过“错误预算”平衡速度与稳定性?
在网站可靠性工程 (SRE) 的世界中,在创新的速度与系统的稳定性之间找到完美的平衡是一项持续的挑战。虽然开发团队致力于快速发布新功能,但运维团队和 SRE 的目标则是保持系统平稳运行且不中断。这种利益冲突常常导致团队之间的摩擦。而这正是错误预算 (…...

企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本 对于现代企业而言,构建一个高效、智能的内训系统是提升员…...

终极Python SECS/GEM协议实现:5分钟构建半导体设备通信系统
终极Python SECS/GEM协议实现:5分钟构建半导体设备通信系统 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem secsgem是一个专为半导体制造行业设计的Python SECS/GEM协议实现库&#…...

通过模型广场快速选型并获取对应API调用示例代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过模型广场快速选型并获取对应API调用示例代码 当你需要将大模型能力集成到自己的应用时,面对众多厂商和模型&#x…...

初创团队如何通过Taotoken模型广场选型并控制AI成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken模型广场选型并控制AI成本 对于资源有限的初创团队而言,将大模型能力集成到产品中是加速创新…...
)
NotebookLM实验结果可信吗?(P值阈值设定与多重检验校正全拆解)
更多请点击: https://codechina.net 第一章:NotebookLM实验结果可信吗?(P值阈值设定与多重检验校正全拆解) NotebookLM 作为基于文档的AI实验助手,其内置的“实验模式”常用于自动比对不同提示策略或模型配…...