核函数支持向量机(Kernel SVM)
核函数支持向量机(Kernel SVM)是一种非常强大的分类器,能够在非线性数据集上实现良好的分类效果。以下是关于核函数支持向量机的详细数学模型理论知识推导、实施步骤与参数解读,以及两个多维数据实例(一个未优化模型,一个优化后的模型)的完整分析。
一、数学模型理论推导
1.1 线性支持向量机
支持向量机的目标是找到一个超平面,以最大化两类数据点之间的间隔。对于线性可分的数据,支持向量机的目标可以用以下优化问题来表示:

1.2 非线性支持向量机


二、实施步骤与参数解读
2.1 选择核函数
常用的核函数有:

2.2 参数选择
- C:控制分类错误与间隔的权衡。值越大,分类错误越少,但间隔越小,容易过拟合。
:控制RBF核的宽度。值越大,高斯分布越窄,模型复杂度越高,容易过拟合。
三、多维数据实例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report# 生成数据
X, y = make_classification(n_samples=300, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 未优化的核函数SVM模型
model = SVC(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train, y_train)# 预测与结果分析
y_pred = model.predict(X_test)
print("未优化模型分类报告:")
print(classification_report(y_test, y_pred))# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='coolwarm', s=30, edgecolors='k')
plt.title("未优化的核函数SVM分类结果", fontname='KaiTi')
plt.show()
# 优化后的核函数SVM模型
model_optimized = SVC(kernel='rbf', C=10.0, gamma=0.1)
model_optimized.fit(X_train, y_train)# 预测与结果分析
y_pred_optimized = model_optimized.predict(X_test)
print("优化后模型分类报告:")
print(classification_report(y_test, y_pred_optimized))# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='coolwarm', s=30, edgecolors='k')
plt.title("优化后的核函数SVM分类结果", fontname='KaiTi')
plt.show()



四、结果与结果解释
4.1 未优化模型
- 分类报告显示了精度、召回率和F1分数等指标。
- 可视化图展示了未优化模型的分类边界和测试集数据点。
4.2 优化后的模型
- 优化后模型的分类报告通常会显示更高的精度、召回率和F1分数,表明模型性能提升。
- 优化后的可视化图展示了改进后的分类边界,更好地分隔了数据点。
相关文章:
核函数支持向量机(Kernel SVM)
核函数支持向量机(Kernel SVM)是一种非常强大的分类器,能够在非线性数据集上实现良好的分类效果。以下是关于核函数支持向量机的详细数学模型理论知识推导、实施步骤与参数解读,以及两个多维数据实例(一个未优化模型&a…...

二分查找(折半查找)
这次不排序了,对排好序的数组做个查找吧 介绍 二分查找排序英文名为BinarySort,是一种效率较高的查找方法要求线性表必须采用顺序存储结构 基本思路 通过不断地将搜索范围缩小一半来找到目标元素: 1、假定数组为arr,需要查找的…...
)
arcgis紧凑型切片缓存(解决大范围切片,文件数量大的问题)
ArcGIS 切片缓存的紧凑型存储格式是一种优化的存储方式,用于提高切片缓存的存储效率和访问速度。紧凑型存储格式将多个切片文件合并为一个单一的 .bundle 文件,从而减少文件系统的开销和切片的加载时间。这类格式已经应用很久了,我记得2013我…...
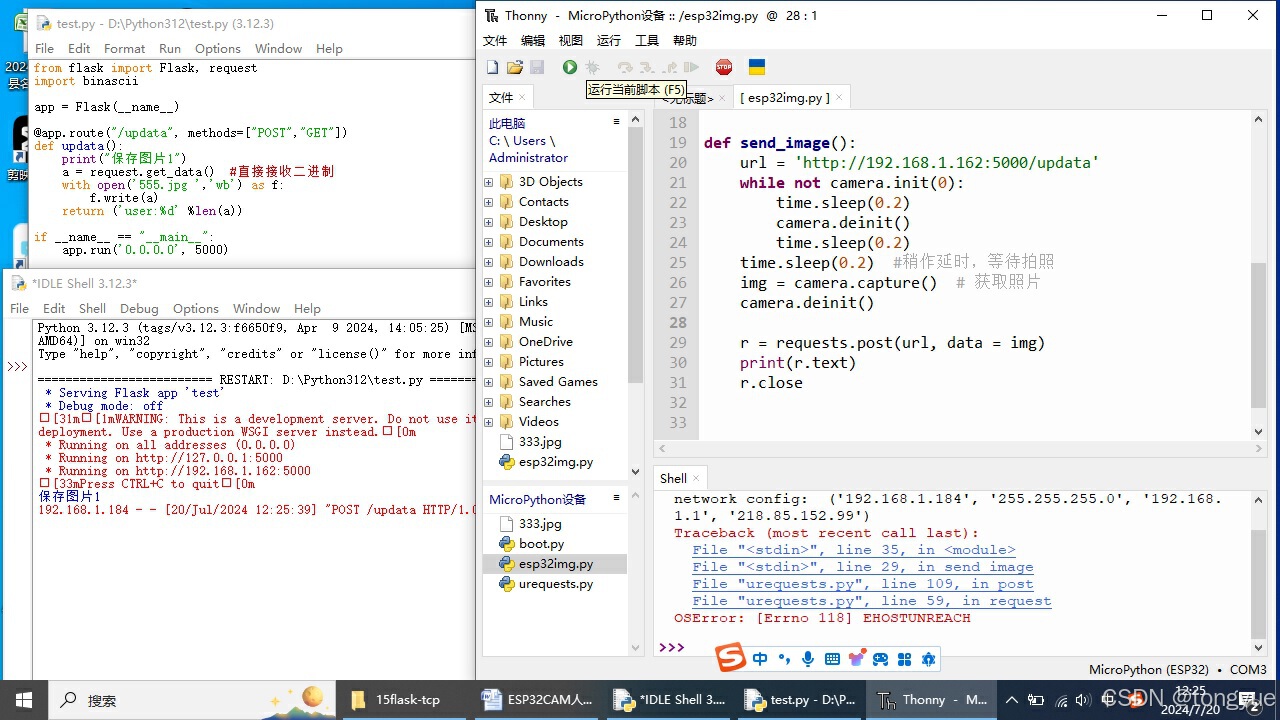
ESP32CAM人工智能教学15
ESP32CAM人工智能教学15 Flask服务器TCP连接 小智利用Flask在计算机中创建一个虚拟的网页服务器服务器,让ESP32Cam通过WiFi连接,把摄像头拍摄到的图片发送到电脑中,并在电脑中保存成图片文件。 Flask是用Python编写的网页服务程序WebServer。…...

Pandas 33个冷知识 0721
Pandas 33个冷知识 从Excel读取数据: 使用 pd.read_excel(file.xlsx) 来读取Excel文件。 写入Excel: 使用 df.to_excel(file.xlsx, indexFalse) 将DataFrame写入Excel文件。 创建日期索引: 使用 df.set_index(pd.to_datetime(df[date])) 创建日期索引。 向后填充缺失值: 使用…...

C++ map和set的使用
目录 0.前言 1.关联式容器 2.键值对 3.树形结构的关联式容器 3.1树形结构的特点 3.2树形结构在关联式容器中的应用 4.set 4.1概念与性质 4.2使用 5.multiset 5.1概念与性质 5.2使用 6.map 6.1概念与性质 6.2使用 7.multimap 7.1概念与性质 7.2使用 8.小结 &a…...

yarn的安装和配置以及更新总结,npm的对照使用差异
1. Yarn简介 Yarn 是一个由 Facebook 开发的现代 JavaScript 包管理器,旨在提供更快、更安全、更可靠的包管理体验。 1.1 什么是Yarn Yarn 是一个快速、可靠和安全的 JavaScript 包管理器,它通过并行化操作和智能缓存机制,显著提升了依赖安…...

【Git命令】git rebase之合并提交记录
使用场景 在本地提交了两个commit,但是发现根本没有没必要分为两次,需要想办法把两次提交合并成一个提交;这个时候可以使用如下命令启动交互式变基会话: git rebase -i HEAD~N这里 N 是你想要重新调整的最近的提交数。 如下在本地…...

为什么品牌需要做 IP 形象?
品牌做IP形象的原因有多方面,这些原因共同构成了IP形象在品牌建设中的重要性和价值,主要原因有以下几个方面: 增强品牌识别度与记忆点: IP形象作为品牌的视觉符号,具有独特性和辨识性,能够在消费者心中留…...

Kubernetes 1.24 版弃用 Dockershim 后如何迁移到 containerd 和 CRI-O
在本系列的上一篇文章中,我们讨论了什么是 CRI 和 OCI,Docker、containerd、CRI-O 之间的区别以及它们的架构等。最近,我们得知 Docker 即将从 kubernetes 中弃用!(查看 kubernetes 官方的这篇文章)那么让我…...
 】)
70. 爬楼梯【 力扣(LeetCode) 】
一、题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 二、测试用例 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶…...

R语言优雅的把数据基线表(表一)导出到word
基线表(Baseline Table)是医学研究中常用的一种数据表格,用于在研究开始时呈现参与者的初始特征和状态。这些特征通常包括人口统计学数据、健康状况和疾病史、临床指标、实验室检测、生活方式、社会经济等。 本人在既往文章《scitb包1.6版本发…...

XMl基本操作
引言 使⽤Mybatis的注解⽅式,主要是来完成⼀些简单的增删改查功能. 如果需要实现复杂的SQL功能,建议使⽤XML来配置映射语句,也就是将SQL语句写在XML配置⽂件中. 之前,我们学习了,用注解的方式来实现MyBatis 接下来我们…...

Linux——Shell脚本和Nginx反向代理服务器
1. Linux中的shell脚本【了解】 1.1 什么是shell Shell是一个用C语言编写的程序,它是用户使用Linux的桥梁 Shell 既是一种命令语言,有是一种程序设计语言 Shell是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问…...

pyspark使用 graphframes创建和查询图的方法
1、安装graphframes的步骤 1.1 查看 spark 和 scala版本 在终端输入: spark-shell --version 查看spark 和scala版本 1.2 在maven库中下载对应版本的graphframes https://mvnrepository.com/artifact/graphframes/graphframes 我这里需要的是spark 2.4 scala 2.…...

【web】-flask-简单的计算题(不简单)
打开页面是这样的 初步思路,打开F12,查看头,都发现了这个表达式的base64加密字符串。编写脚本提交答案,发现不对; 无奈点开source发现源代码,是flask,初始化表达式,获取提交的表达式࿰…...

Apache Sqoop
Apache Sqoop是一个开源工具,用于在Apache Hadoop和关系型数据库(如MySQL、Oracle、PostgreSQL等)之间进行数据的批量传输。其主要功能包括: 1. 数据导入:从关系型数据库(如MySQL、Oracle等)中将…...

【Python】TensorFlow介绍与实战
TensorFlow介绍与使用 1. 前言 在人工智能领域的快速发展中,深度学习框架的选择至关重要。TensorFlow 以其灵活性和强大的社区支持,成为了许多研究者和开发者的首选。本文将进一步扩展对 TensorFlow 的介绍,包括其优势、应用场景以及在最新…...

第100+16步 ChatGPT学习:R实现Xgboost分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现Xgboost分类 (…...

【操作系统】定时器(Timer)的实现
这里写目录标题 定时器一、定时器是什么二、标准库中的定时器三、实现定时器 定时器 一、定时器是什么 定时器也是软件开发中的⼀个重要组件.类似于⼀个"闹钟".达到⼀个设定的时间之后,就执行某个指定 好的代码. 定时器是⼀种实际开发中⾮常常用的组件. ⽐如⽹络通…...

2025年项目管理工具TOP10:Gitee引领技术驱动新浪潮
1.Gitee(码云):代码与管理的双核引擎 作为中国最大的代码托管平台,Gitee在2025年全面升级项目管理模块,成为技术团队的首选工具。其核心优势在于: 开发与协作无缝衔接:代码提交直接关联任务看板…...

Zotero插件市场TOP1新势力:Perplexity Connector v2.3正式发布,支持LLM上下文感知文献溯源,仅限前500名开发者早鸟激活
更多请点击: https://intelliparadigm.com 第一章:Perplexity Zotero整合方案全景概览 Perplexity 作为新一代 AI 驱动的研究型搜索引擎,其核心优势在于实时引用溯源与上下文感知问答;Zotero 则是学术工作者广泛采用的开源文献管…...

基于大语言模型的自动化股票研报生成系统设计与实现
1. 项目概述:当ChatGPT遇上股票研报最近几年,AI在金融领域的应用已经从简单的数据查询,进化到了能够进行复杂分析和生成专业报告的程度。我关注到一个挺有意思的项目,叫ddobokki/chatgpt_stock_report。光看这个名字,你…...

免费好用的去水印工具推荐:哪个效果最好?免费去水印工具对比 2026 实测
免费好用的去水印工具推荐:哪个效果最好?免费去水印工具对比 2026 实测 去水印这件事,真的是越来越高频了。自媒体剪素材、收藏喜欢的短视频、整理图片资料……一旦碰到带水印的内容,找个顺手的工具就成了刚需。网上工具多&#x…...

从好奇号火星着陆看复杂系统工程:天空起重机方案与工程管理启示
1. 项目概述:从“不可能”到“火星新地标”的工程壮举2012年8月6日,当“好奇号”火星车在盖尔陨石坑成功着陆,传回第一张火星地表照片时,整个喷气推进实验室(JPL)控制中心沸腾了。这不仅仅是一次成功的行星…...

Kubernetes配置管理神器Monokle:可视化IDE提升YAML开发效率
1. 项目概述:一个被低估的Kubernetes配置管理神器如果你和我一样,每天都在和成堆的YAML文件、复杂的Kubernetes资源关系以及让人头疼的配置漂移问题打交道,那你一定理解那种在终端、IDE和Dashboard之间反复横跳的疲惫感。几年前,当…...

Codepack:标准化开发配置与自动化工具链的工程实践
1. 项目概述:一个为开发者准备的“代码行囊” 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 JasonLovesDoggo/codepack 。乍一看名字,你可能会觉得这又是一个普通的代码库或者工具集。但点进去仔细研究后,我发现…...

Roast:颠覆AI助手模式,打造苏格拉底式思维拷问引擎
1. 项目概述:当AI开始“拷问”你如果你用过市面上那些主流的AI助手,不管是ChatGPT、Claude还是DeepSeek,你大概率有过这样的体验:你抛出一个想法,它总能给你一堆“哇,这个想法太棒了!”、“很有…...

Articuler.Ai 技术深度解析:海量人脉匹配、数字足迹解析与高转化冷触达引擎
摘要Articuler.Ai 是一款面向商业人脉精准匹配与高效触达的 AI 引擎,核心定位为 “商业关系搜索引擎 智能触达工作台”,彻底重构传统关键词搜索失效背景下的 B2B 人脉连接逻辑。本文从9.8 亿级公开档案数据底座、语义匹配引擎架构、Playbook 深度解析技…...

从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束
从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束 在ZYNQ7000系列开发中,EMIO引脚的正确分配与约束是实现PS与PL协同工作的关键环节。许多工程师在初次接触ZYNQ架构时,往往会被MIO、EMIO和AXI_GPIO的关系所困扰ÿ…...