【半监督学习】3、PseCo | FPN 错位对齐的高效半监督目标检测器
文章目录
- 一、背景
- 二、方法
- 2.1 基础框架结构
- 2.2 带噪声的伪边界框学习
- 2.3 多视图尺度不变性学习
- 三、实验
论文:PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection
代码:https://github.com/ligang-cs/PseCo
出处:ECCV 2022 | 南京科技大学 商汤
一、背景
现阶段图像分类、目标检测等任务的效果都取得了很大的进展,这很大程度上依赖于大量标注好的数据。
但是大量的数据标注非常耗时且昂贵,尤其是目标检测任务,需要很严格精细的标注。
所以,使用未标注的数据来提升模型效果的半监督学习就被提出来,可以同时使用标注数据和未标注数据来进行模型训练。
半监督图像分类(Semi-Supervised for Image Classification,SSIC),对未标记数据的学习可以分为两类:
- 伪标记 [7,18]
- 一致性训练 [24,22]
还有一些方法如 FixMatch [19],FlexMatch [28] 试图将这两种技术结合到一个框架中来提升效果
半监督目标检测( Semi-Supervised Object DetectionS,SOD)中,一些工作借鉴了 SSIC 的关键技术(如伪标记、一致性训练),并将其直接应用于SSOD,但效果不尽如意。原因主要有两点:
- 一方面,与图像分类相比,目标检测的伪标签更加复杂,既包含类别信息,又包含位置信息。
- 另一方面,目标检测需要捕获比图像分类更强的尺度不变能力,因为它需要仔细处理具有丰富尺度的目标
本文的贡献:
- 提出了一个 SSOD 框架(PSEudo labeling and COnsistency training,PseCo),将目标检测属性集成到 SSOD 中,使得伪标签和一致性训练能更好的用于目标检测任务
二、方法
PseCo 的整体架构如图 2 所示,在未标记的数据中,PseCo 由以下两部分构成:
- 带噪声的伪框学习(Noisy Pseudo box Learning,NPL)
- 多视图尺度不变学习(Multi-view Scale-invariant Learning,MSL)

2.1 基础框架结构
本文使用 Faster RCNN 作为基础检测框架
使用 Teacher-student 训练模式,教师模型是通过对学生模型进行指数移动平均(Exponential Moving Average,EMA)得到的,教师网络和学生网络的结构完全相同。学生网络使用梯度更新来训练,教师网络根据学生网络来更新且无需参与训练。
整体过程如下:
- 使用定义好的采样率来从标注数据和未标注数据中采用,得到一个 batch 的数据输入网络进行训练
- 对标注数据:送入学生网络进行学习,并得到监督学习 loss,Ll=Lclsl+LreglL_l=L^l_{cls} + L^l_{reg}Ll=Lclsl+Lregl
- 对未标注数据:
- 进行弱数据增强后送入教师网络进行学习,生成伪标签
- 进行强数据增强后送入学生网络进行学习,学习伪标签
- 根据学生网络和教师网络的预测结果,得到半监督学习 loss:Lu=LclsuL_u = L^u_{cls}Lu=Lclsu
- 然后计算总体的 loss: L=Ll+LuL = L_l + L_uL=Ll+Lu,用于指导梯度更新来更新学生网络的权重
- 最后,使用指数移动平均来更新教师网络权重
每次训练根据抽取比例进行随机抽取标注数据和未标注数据:
-
对标注数据:
- student model 按正常模式训练,用 gt box 来监督其训练,Ll=Lclsl+LreglL^l = L_{cls}^l+L_{reg}^lLl=Lclsl+Lregl
-
对未标注数据:
弱数据增强后送入教师模型生成伪标签,强数据增强后送入学生网络学习伪标签,且由于作者认为分类和回归没有强联系,即分类好不一定回归好,则对未标注数据舍弃了回归 loss,只使用分类 focal loss: Lu=LclsuL^u = L^u_{cls}Lu=Lclsu
-
首先,使用弱数据增强(水平翻转、随机调整大小等),然后输入教师模型进行伪标签生成(也就是让教师模型输出预测结果,毕竟教师模型是比较大的,能力较强,对学生网络有很大的指导作用的)。此外,考虑到在使用了 NMS 后的伪标签(检测框)也会很密集,故此又设置了一个分数阈值 τ\tauτ,只保留分数高于阈值的框作为伪标签
-
之后,对输入训练数据进行强增强(如切割、旋转、亮度抖动等),生成学生模型的训练样本,对学习模型进行训练
-
最后,由于好的分类和好的定位没有强关联,所以作者不对未标记数据进行位置回归,而且实验也能证明对未标记的数据进行位置回归的话也会导致训练不稳定,所以作者对无标签数据没有使用回归 loss,只使用了分类 Focal loss
-
前景和背景的数量不平衡问题:
- 前景-背景不平衡在目标检测中普遍存在,在半监督情况下更加严重
- 上面提到的过滤 NMS 保留下来的伪标签的得分阈值 τ\tauτ 虽然可以提高伪标签的精度,但也会导致伪标签数量减少,使得模型容易学习优势类别,导致偏倚的预测
如何解决前景和背景的数量不平衡问题:
-
对未标记的数据,分类 loss 使用类似于 Unbiased Teacher[14] 中的方法,将 CE loss 替换成 Focal loss,且 αt\alpha_tαt 和 γ\gammaγ 和原始论文中一样
-
标记数据和未标记数据的总体 loss 为 L=Ll+βLuL = L^l+\beta L^uL=Ll+βLu,其中 β\betaβ 被用于控制未标记数据的权重
2.2 带噪声的伪边界框学习
Noisy Pseudo Box Learning
在 SSOD 中,伪标签包含类别和位置两种信息
伪标签的类别得分只能表示其类别的置信度,无法保证框位置的质量,如果伪标签的框位置不精确的话就会拉低模型的效果,所以本文使用下面两种方法来减少位置对 label assign 和回归任务的损害:
- Prediction-guided Label Assignment
- Positive-proposal Consistency Voting
1、Prediction-guided Label Assignment
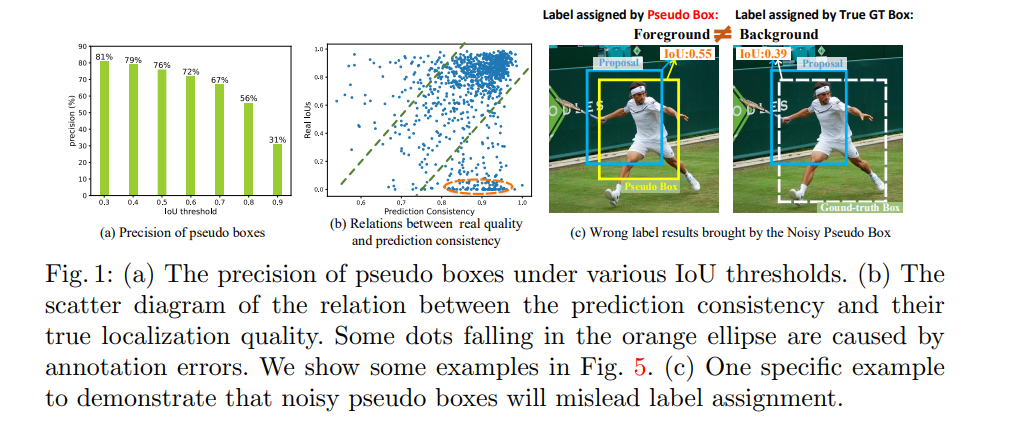
Faster RCNN 中的 label assignment 是基于 IoU 的方法,将和 gt 的 IoU 大于阈值(0.7)的 box 置位正样本。
在半监督学习中,gt 就是生成的伪标签。
该做法的前提是假设 gt 的框位置非常的准确,所以方法不适合于未标记的数据,可能会导致一些低质量的 proposal 被分配为正样本。
一个示例如图 1c 所示,一个和真实 gt 的 IoU 为 0.39 的 proposal 被分配为正样本了。
为了解决这个问题,作者提出了 PLA(Prediction-guided Label Assignment):
- 将教师模型的预测作为辅助信息,且降低对 IoU 的依赖
- 在 Teacher-Student 训练模式下,不仅仅教师网络预测结果 NMS 之后的框可以做伪标签,NMS 之前的框也可以做伪标签,用于指导学生模型的训练。
- 作者将教师网络生成的 RPN 和学生网络共享,那么教师网络在这些 proposal 上的预测结果就可以很方便的迁移到学生网络
- 为了更好的衡量 proposal 的质量 q,同时使用教师网络的分类得分和定位预测来作为衡量方法,即 q=sα×u1−αq = s^{\alpha} \times u^{1-\alpha}q=sα×u1−α,s 是 RPN 输出的前景得分,u 是 RPN 预测的 proposal 和 gt 的 IoU。α\alphaα 控制 s 和 u 对结果的贡献程度。
如何在未标记数据上使用呢:
- 首先,使用传统的基于 IoU 的方法为每个 gt 生成一系列候选框,且 IoU 阈值设置为比较低的值(0.4)来保证包含更多的候选框
- 对于这些候选框,按质量 q 进行降序排序,将 top-N 的框看做正样本,其余为负样本,N 是基于 OTA 方法中的 dynamic k 估计得到的
PLA 的优势:
- 减轻了对 IoU 的强烈依赖,减轻了定位较差的框带来的负面影响
- 标签分配策略将更多的教师知识整合到了学生模型的训练中,实现了更好的知识蒸馏

2、Positive-proposal Consistency Voting
由于分类得分不能很好的表示定位的质量,所以作者还提测了一个方法来衡量定位质量——PCV
基于 CNN 的模板检测器一般都是会将多个 proposal 分配给一个 gt(或 pseudo box),这些 proposal 回归结果的一致性能反映其对应的这个伪边界框的质量。
则第 j 个伪边界框的回归一致性 σi\sigma_iσi 表示为:
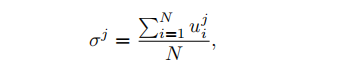
- 其中,u 是预测框和伪边界框的 IoU
- N 是分配给第 j 个伪边界框的正 proposal 的数量
得到了 σi\sigma_iσi 后,使用 instance-wise 的回归:

- reg 是回归的输出
- reg^ 是 gt
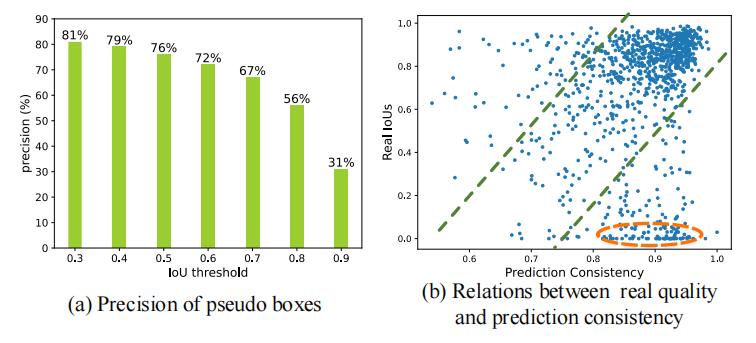
如图 1b 所示,其中描述了伪边界框的预测一致性和其真实 IoU 之间的关系散点图,可以看出:
- 一致性和 IoU 正相关
- 橘色圆中的是标注错误引起的
如图 5,展示了伪边界框也可以准确的指导模型预测

2.3 多视图尺度不变性学习
不同于图像分类,目标检测中的目标尺度变化较大,故难以在每个尺度上都表现较好。
所以,从未标记数据中学习尺度不变的表示对 SSOD 相当重要。
在一致性训练中,强数据增强为提高模型性能起到了很重要的作用。
通过在输入图像中注入强扰动,能使模型对各种变化都保持鲁棒性。
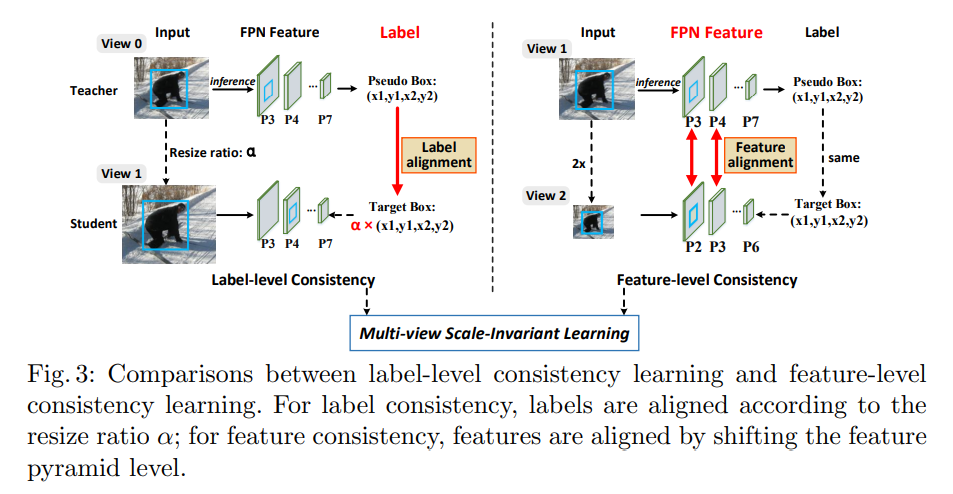
标签级一致性:
从尺度不变性角度来看,将常见的数据增强(如随机调整大小)看做标签级一致性,因为其能根据输入图像尺度的变化来调整标签的大小。
特征级一致性:
由于检测网络通常有丰富的特征金字塔设计,因此特征级的一致性也很容易在配对输入之间实现。
所以,本文中提测了多视图尺度不变学习,将标签级和特征级的一致性组合到一个框架中,特征一致性通过对齐两个内容相同但尺度不同的图像之间的金字塔特征来实现的。
过程:
- 两个视图(两个图像)分别为 V1V_1V1 和 V2V_2V2,用于训练 MSL 中的学生网络
- 教师模型的输入图像为 V0V_0V0
- V1V_1V1 和 V2V_2V2 会被结合起来分别学习标签级和特征级的一致性
- V1V_1V1 是使用随机缩放得到的,也就是将 V0V_0V0 和伪边界框进行随机的缩放,缩放尺度在 [0.8, 1.3]。
- V2V_2V2 是将 V1V_1V1 下采样 2 倍得到的
- V1V_1V1 和 V2V_2V2 构成一组图像对儿
- V1V_1V1 的 FPN 的 P3-P7 层可以刚好和 V2V_2V2的 P2-P6 层大小对应,如图 3 所示
三、实验
1、数据集
使用 MS COCO,包括两个训练集:
- train2017,包含 118k 标注数据
- unlabeled2017,包含 123k 未标注数据
Partially Labeled Data:
- 随机选择 train2017 中的 1%,2%,5%,10% 作为标注数据,其他的作为未标注数据
- 在每个采样率下,对比了 5 种不同倍的均值和方法
Fully Labeled Data:
- 使用 train2017 作为带标签的训练数据,unlabeled2017 作为无标签的训练数据
2、实验细节
使用 Faster RCNN with FPN 作为检测框架,backbone 为 Res50
伪标签分类阈值为 0.5
伪标签 loss 权重 β=4.0\beta=4.0β=4.0
Partially Labeled Data:
- 在 8 GPU 上训练 180k iters
- 初始学习率为 0.01,在 120k、160k iters 分别降低 10 倍
- 每个 GPU 的每个 batch 有 5 张图,无标签:有标签=4:1
Fully Labeled Data:
- 在 8 GPU 上训练 720k iters
- 每个 GPU 每个 batch 为 8 张图,有标签:无标签=1:1
- 初始学习率为 0.01,在 480k、680k iters 分别降低 10 倍
3、和 SOTA 的对比(COCO val2017)
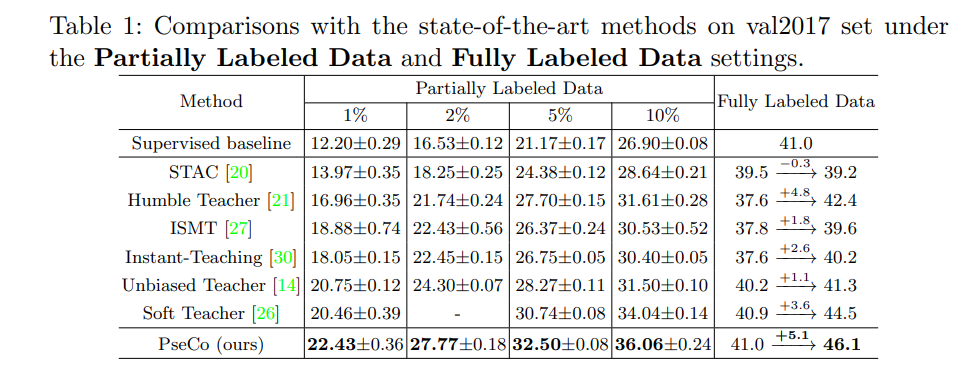
Partially Labeled Data:
- 当有标注的数据比较少时(1% 或 2% 采样率),本文方法超越 Unbiased Teacher 分别为 1.7% 和 3.5%
- 当有标注的数据增多时(5% 或 10% 采样率),本文方法比最强的 Soft Teacher 分别高 1.8% 和 2.0%
- 本文方法和 Soft Teacher 的收敛速度如图 4 所示,可见本文方法收敛速度更快
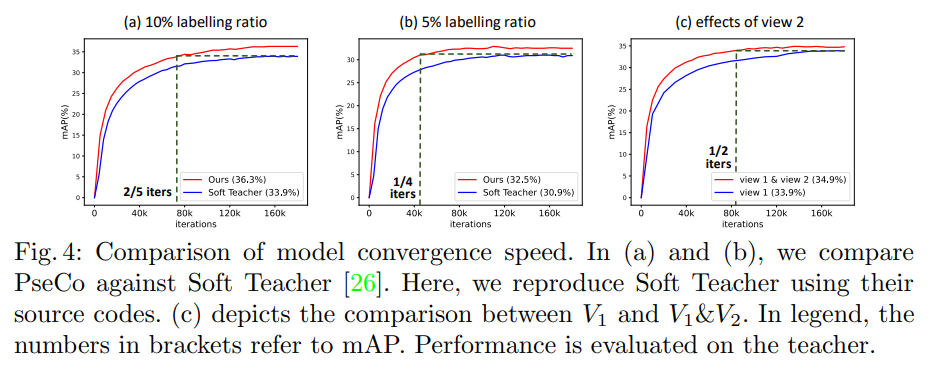
Fully Labeled Data:
- 本文方法获得了 46.1 mAP,是 SOTA 的效果
- 定性的可视化如图 5 所示

4、消融实验
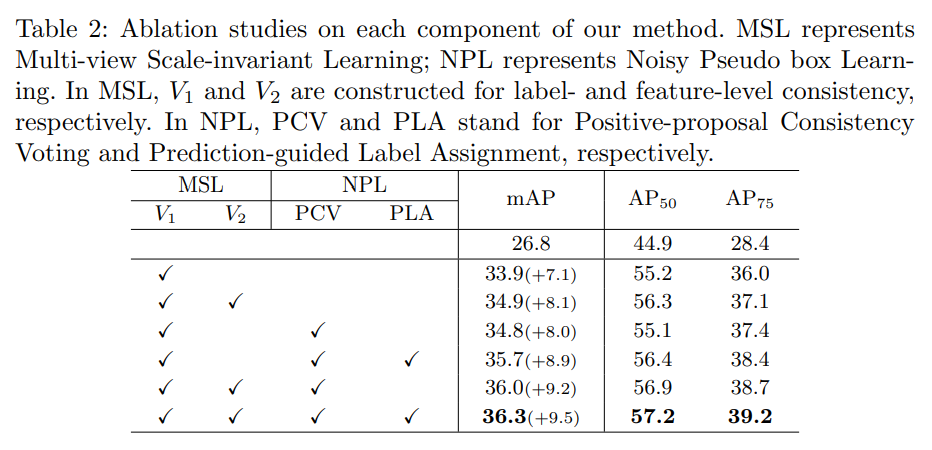
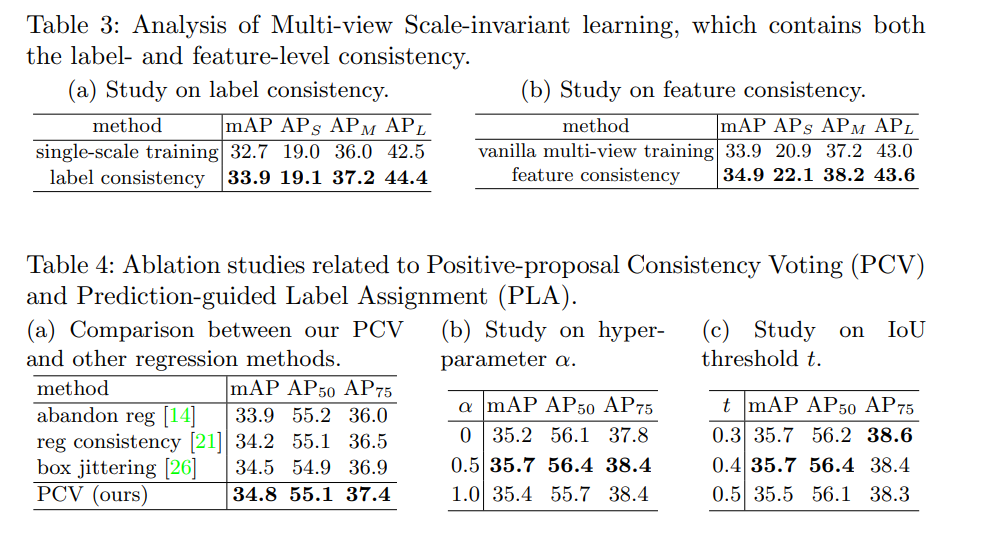

相关文章:
【半监督学习】3、PseCo | FPN 错位对齐的高效半监督目标检测器
文章目录一、背景二、方法2.1 基础框架结构2.2 带噪声的伪边界框学习2.3 多视图尺度不变性学习三、实验论文:PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection 代码:https://github.com/ligang-cs/PseCo 出处&a…...
Tomcat+Servlet初识
文章目录Tomcat什么是TomcatTomcat的安装启动tomcat静态页面的访问动态页面的访问一个Servlet程序的部署流程Tomcat 什么是Tomcat Tomcat是一个HTTP服务器,在开发或调试Servlet代码时应用广泛;使用Tomcat,实际就是将用户浏览器输入的http请…...
ChatGPT-4 终于来了(文末附免费体验地址)
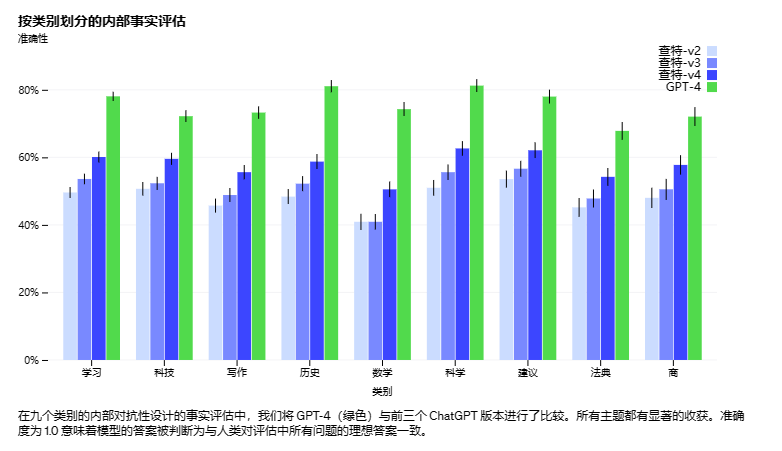
大家好,我是小钱学长。 ChatGPT4.0 重磅来袭,今天一打开plus页面出现的就是这个GPT-4的体验界面!现在就带大家一起看看GPT4.0。 进入之后是这样的 看到最下面有一行话,目前应该是4个小时限制100条消息。 GPT-4有什么优势&…...

【C++学习】类和对象(中)一招带你彻底了解六大默认成员函数
前言:在之前,我们对类和对象的上篇进行了讲解,今天我们我将给大家带来的是类和对象中篇的学习,继续深入探讨【C】中类和对象的相关知识!!! 目录 1. 类的6个默认成员函数 2. 构造函数 2.1概念介…...

面试——Java基础
说一说你对Java访问权限的了解 在修饰成员变量/成员方法时,该成员的四种访问权限的含义如下: private:该成员可以被该类内部成员访问; default:该成员可以被该类内部成员访问,也可以被同一包下其他的类访…...

JavaWeb——Request(请求)和Response(响应)介绍
在写servlet时需要实现5个方法,在一个service方法里面有两个参数request和response。 浏览器向服务器发送请求会发送HTTP的请求数据——字符串,这些字符串会被Tomcat所解析,然后这些请求数据会被放到一个对象(request)里面保存。 相应的Tom…...
JMeter压测文件上传接口和中文乱码
一、压测文件上传接口 新建测试计划,然后添加需要的元件。 1、添加HTTP信息头管理器 可以在测试计划中添加,也可以在线程组里面添加。 我的接口使用到 token信息。这里在测试计划中添加。 2、添加线程组 上图解释:会在 2秒钟之内启动起来 5…...
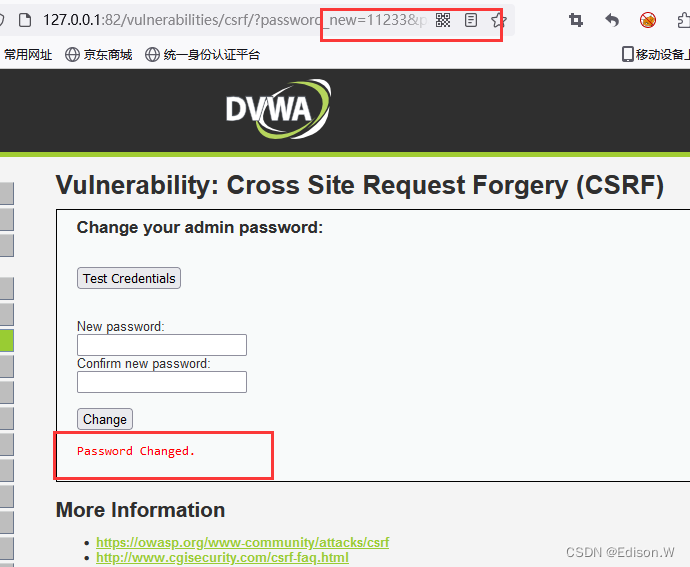
CSRF漏洞复现
目录标题原理如何实现和xss区别危害CSRF实战(pikachu)dvwa靶场CSRF(Cross Site Request Forgery)。跨站请求伪造原理 攻击者会伪造一个请求(一般是一个链接),然后让用户去点击,然后…...

Google Colab导入GitHub python项目进行运行
本文介绍包含 ipynb后缀文件的github项目,导入到GitHub上进行运行的方法。 导入项目 Colab是需要梯子的。 访问网址:https://colab.research.google.com 输入github网之后回车,下面的内容是从github上自动获取的。 选择项目要打开的ipynb文…...

Qss样式表语法
QSS样式表语法 更多精彩内容👉个人内容分类汇总 👈👉QSS样式学习 👈文章目录QSS样式表语法[toc]概述一、样式规则二、选择器类型三、子控件四、伪状态五、样式表冲突解决六、级联七、继承八、命名空间中的控件概述 Qt样式表的概念…...

「Python 基础」异步 I/O 编程
I/O 密集型应用程序大大提升系统多任务处理能力; 异步 I/O 模型 一个消息循环,主线程在消息循环中不断重复 读取消息-处理消息; # 获取线程池 loop get_event_loop() while True:# 接收事件消息event loop.get_event()# 处理事件消息pro…...

通配符的匹配很全面, 但无法找到元素 ‘tx:advice‘ 的声明
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! 通配符的匹配很全面, 但无法找到元素 ‘tx:advice’ 的声明 错误原因: xmlns和xsi:schemaLocation未书写约束或者书写错误 正确书写 <beans xmlns:tx&q…...

响应式编程详解,带你熟悉Reactor响应式编程
文章目录一、什么是响应式编程1、Java的流和响应式流2、Java中响应式的使用3、Reactor中响应式流的基本接口4、Reactor中响应式接口的基本使用二、初始Reactor1、Flux和Mono的基本介绍2、引入Reactor依赖3、响应式类型的创建4、响应式类型的组合(1)使用m…...
踩坑篇之WebSocket实现类中无法使用@Autowired注入对象
大家好,我是小简,今天我又大意了,在WebSocket这个类上踩坑了。 接下来我讲讲我踩坑的经历吧! package cn.donglifeng.shop.socket.endpoin;import cn.donglifeng.shop.common.context.SpringBeanContext; import cn.donglifeng.s…...
QT CTK插件框架 (一 下载编译)
CTK 为支持生物医学图像计算的公共开发包,其全称为 Common Toolkit。为医学成像提供一组统一的基本功能;促进代码和数据的交互及结合;避免重复开发;在工具包(医学成像)范围内不断扩展到新任务,而…...

【Java版oj】day10 井字棋、密码强度等级
目录 一、井字棋 (1)原题再现 (2)问题分析 (3)完整代码 二、密码强度等级 (1)原题再现 (2)问题分析 (3)完整代码 一、井字棋 &a…...
JavaScript的事件传播机制
你在学习和编写JavaScript时可能听说过事件冒泡(event bubbling)。它会发生在多个元素存在嵌套关系,并且这些元素都注册了同一事件(例如click)的监听器时。 但是事件冒泡只是事件机制的一部分。它经常与事件捕获(event capturing)和事件传播…...

队列的定义及基本操作实现(链式)
个人主页:【😊个人主页】 系列专栏:【❤️数据结构与算法】 学习名言:天子重英豪,文章教儿曹。万般皆下品,惟有读书高 系列文章目录 第一章 ❤️ 学前知识 第二章 ❤️ 单向链表 第三章 ❤️ 递归 文章目录…...
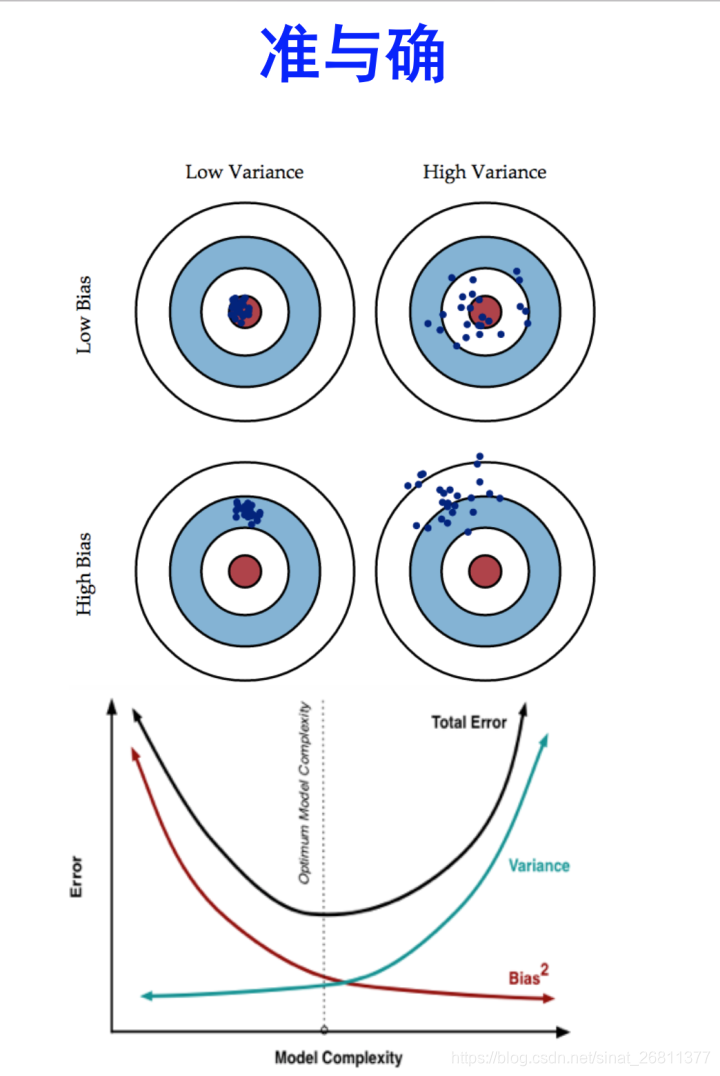
集成方法!
目录 关注降低variance,选择bias较小的基学习器 Bagging Stacking Random Forest 关注降低bias,选择variance较小的基学习器 Adaboost Boosting 关注降低variance,选择bias较小的基学习器 Bagging 给定m个样本的数据集,利用有放回的随机采样法,得…...

20年程序员生涯,读了200多本技术书,挑了几本精华好书分享给大家
不知不觉已经又走过了20个年头了,今年已经44了,虽然我已经退休在家,但一直都保持着读书的习惯,我每年平均要读10本技术书籍,保持不让自己的技术落伍。 这些年读的技术书不下200本,很多好书我都会保存在家&a…...

蝾螈机器人多自由度控制与强化学习实践
1. 蝾螈机器人全身控制的技术挑战蝾螈作为自然界典型的两栖动物,其运动模式具有独特的生物力学特性。传统机器人控制方法在面对这种多自由度系统时面临诸多挑战。我曾在实验室参与过类似的多关节机器人控制项目,深刻体会到协调十几个关节运动的复杂性。1…...

如何高效调试硬件设备:SSCom串口调试助手让你的Linux/Mac开发更简单
如何高效调试硬件设备:SSCom串口调试助手让你的Linux/Mac开发更简单 【免费下载链接】sscom Linux/Mac版本 串口调试助手 项目地址: https://gitcode.com/gh_mirrors/ss/sscom 你是否曾经在调试嵌入式设备时,因为找不到合适的串口工具而烦恼&…...
)
机械工程师的Gazebo捷径:用SolidWorks建模,5步搞定你的仿真世界(.world文件生成)
机械工程师的Gazebo捷径:用SolidWorks建模,5步搞定你的仿真世界 作为一名机械工程师,你可能已经习惯了SolidWorks精确的建模环境,但当需要将设计转移到机器人仿真平台Gazebo时,却常常感到束手无策。本文将为你揭示一条…...

拆解一个经典课程设计:双工对讲机电路中,扬声器如何兼作话筒?电桥与运放是关键
双工对讲机设计精要:扬声器如何实现声电双向转换的奥秘 在模拟电路设计中,双工对讲机一直是一个令人着迷的经典案例。它巧妙地利用扬声器同时作为话筒和喇叭,实现了双向通话且互不干扰的功能。这种设计不仅节省了元件成本,更体现了…...

[具身智能-636]:什么是语音识别?语音识别的技术过程?语音于语音特征提取?什么环节实现时域到频域的转化?
一、什么是语音识别语音识别 ASR:把人说话的语音声波(时域音频),自动转换成文字的技术。本质:时域语音信号 → 机器可懂的语音特征 → 文本。不关心声音多好听,只关心说了什么内容。二、语音识别完整技术流…...

QMCDecoder:3步解锁音乐版权壁垒,重获音频自由掌控权
QMCDecoder:3步解锁音乐版权壁垒,重获音频自由掌控权 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经遇到过这样的困扰:从QQ音…...

告别复杂配置!5分钟在Vue/React项目中集成讯飞语音听写WebSocket API
5分钟实现Vue/React与讯飞语音听写的优雅集成方案 在智能语音交互逐渐成为标配的今天,前端开发者经常面临将语音识别能力快速集成到现代Web应用中的需求。讯飞语音听写WebSocket API凭借其流式传输、低延迟的特性,成为众多项目的首选方案。但官方示例往往…...

如何用douyin-downloader一键批量下载抖音视频:免费高效完整指南
如何用douyin-downloader一键批量下载抖音视频:免费高效完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

别再乱用交叉验证了!用Python+Scikit-learn实战嵌套交叉验证,避免模型评估的‘信息泄漏’陷阱
嵌套交叉验证实战指南:如何用Python规避模型评估中的信息泄漏陷阱 在机器学习项目中,我们常常会遇到这样的困惑:为什么验证集上的表现总是优于测试集?这种看似"超常发挥"的现象背后,往往隐藏着一个容易被忽视…...

Applera1n终极指南:iOS 15-16激活锁强力绕过工具深度解析
Applera1n终极指南:iOS 15-16激活锁强力绕过工具深度解析 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 面对iPhone激活锁的困境,你是否曾感到束手无策?当二手交易…...