小红书笔记评论采集全攻略:三种高效方法教你批量导出
摘要:
本文将深入探讨如何利用Python高效采集小红书平台上的笔记评论,通过三种实战策略,手把手教你实现批量数据导出。无论是市场分析、竞品监测还是用户反馈收集,这些技巧都将为你解锁新效率。
一、引言:小红书数据金矿与采集挑战
在社交电商领域,小红书凭借其独特的UGC内容模式,积累了海量高价值的用户笔记与评论数据。对于品牌方、市场研究者而言,这些数据如同待挖掘的金矿,蕴藏着用户偏好、市场趋势的宝贵信息。然而,面对小红书严格的反爬机制和动态加载的内容,如何高效且合规地采集这些数据成为了一大挑战。
二、三大高效采集策略
2.1 基础篇:requests + BeautifulSoup 简单入手
关键词:Python爬虫, 数据解析
import requests
from bs4 import BeautifulSoupdef fetch_comments(url):headers = {'User-Agent': 'Your User Agent'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')comments = soup.find_all('div', class_='comment-item') # 假设的类名for comment in comments:print(comment.text.strip())# 示例URL,实际操作中需要替换为具体笔记链接
fetch_comments('https://www.xiaohongshu.com/notes/xxxxxx')2.2 进阶篇:Selenium自动化应对动态加载
关键词:Selenium自动化, 动态加载
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdef scroll_to_bottom(driver):SCROLL_PAUSE_TIME = 2last_height = driver.execute_script("return document.body.scrollHeight")while True:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")WebDriverWait(driver, SCROLL_PAUSE_TIME).until(EC.presence_of_element_located((By.TAG_NAME, "body")))new_height = driver.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_heightdriver = webdriver.Chrome()
driver.get('https://www.xiaohongshu.com/notes/xxxxxx')
scroll_to_bottom(driver)comments = driver.find_elements_by_css_selector('.comment-item') # 假设的类名
for comment in comments:print(comment.text)
driver.quit()2.3 高手篇:Scrapy框架批量处理
关键词:Scrapy框架, 批量导出
首先安装Scrapy框架并创建项目:
pip install scrapy
scrapy startproject xhs_spider在items.py定义数据结构:
import scrapyclass XhsSpiderItem(scrapy.Item):comment_text = scrapy.Field()在spiders目录下创建爬虫文件,例如xhs_comments.py:
import scrapy
from xhs_spider.items import XhsSpiderItemclass XhsCommentsSpider(scrapy.Spider):name = 'xhs_comments'allowed_domains = ['xiaohongshu.com']start_urls = ['https://www.xiaohongshu.com/notes/xxxxxx']def parse(self, response):for comment in response.css('.comment-item'):item = XhsSpiderItem()item['comment_text'] = comment.css('p::text').get()yield item运行爬虫并导出数据至CSV:
scrapy crawl xhs_comments -o comments.csv三、注意事项
在实施上述策略时,务必遵守小红书的使用条款,尊重用户隐私,合法合规采集数据。此外,优化爬取频率,避免对服务器造成不必要的压力,保证数据采集活动的可持续性。
常见问题解答
-
问:如何处理反爬虫策略? 答:使用代理IP、设置合理的请求间隔时间,以及模拟更真实的浏览器行为,可以有效绕过部分反爬机制。
-
问:遇到动态加载的内容怎么办? 答:采用Selenium或类似工具进行页面滚动加载,等待数据加载完全后再进行数据抓取。
-
问:Scrapy框架如何处理登录认证? 答:可以通过中间件实现登录认证,或者在爬虫启动前先获取cookie,然后在请求头中携带cookie访问需要登录后才能查看的页面。
-
问:如何提高采集效率? 策略包括但不限于并发请求、优化数据解析逻辑、合理安排爬取时间等。
-
问:如何存储和管理采集到的数据? 推荐使用数据库如MySQL、MongoDB或云数据库服务存储数据,便于管理和后续分析。
引用与推荐
对于复杂的数据采集需求,推荐使用集蜂云平台,它提供了从数据采集、处理到存储的一站式解决方案,支持海量任务调度、三方应用集成、数据存储等功能,是企业和开发者高效、稳定采集数据的理想选择。
结语
掌握高效的小红书笔记评论采集技巧,能让你在信息海洋中迅速定位关键数据,为市场决策提供强有力的支持。实践上述方法,开启你的数据洞察之旅吧!
相关文章:
小红书笔记评论采集全攻略:三种高效方法教你批量导出
摘要: 本文将深入探讨如何利用Python高效采集小红书平台上的笔记评论,通过三种实战策略,手把手教你实现批量数据导出。无论是市场分析、竞品监测还是用户反馈收集,这些技巧都将为你解锁新效率。 一、引言:小红书数据…...
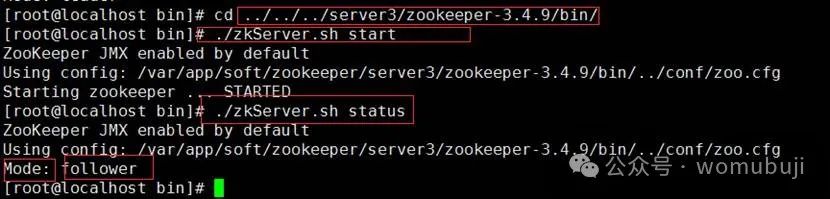
实战:ZooKeeper 操作命令和集群部署
ZooKeeper 操作命令 ZooKeeper的操作命令主要用于对ZooKeeper服务中的节点进行创建、查看、修改和删除等操作。以下是一些常用的ZooKeeper操作命令及其说明: 一、启动与连接 启动ZooKeeper服务器: ./zkServer.sh start这个命令用于启动ZooKeeper服务器…...

linux运维一天一个shell命令之 top详解
概念: top 命令是 Unix 和类 Unix 操作系统(如 Linux、macOS)中一个常用的系统监控工具,它提供了一个动态的实时视图,显示系统的整体性能信息,如 CPU 使用率、内存使用情况、进程列表等。 基本用法 root…...
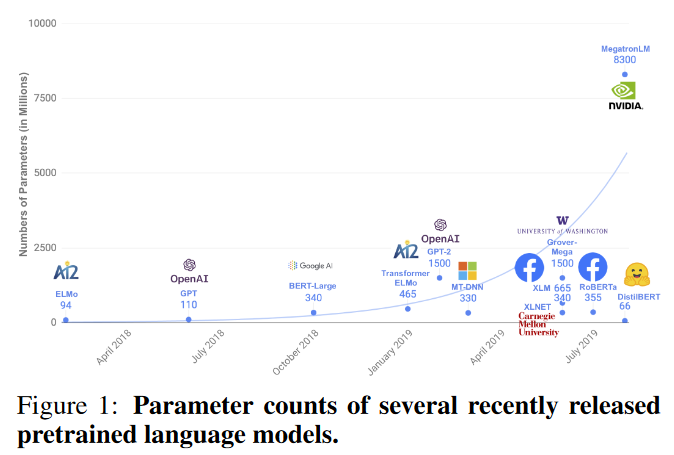
大模型微调:参数高效微调(PEFT)方法总结
PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。 以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下 LORA 论文题目:LORA:…...

Spark+实例解读
第一部分 Spark入门 学习教程:Spark 教程 | Spark 教程 Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(…...

WPF多语言国际化,中英文切换
通过切换资源文件的形式实现中英文一键切换 在项目中新建Language文件夹,添加资源字典(xaml文件),中文英文各一个。 在资源字典中写上想中英文切换的字符串,需要注意,必须指定key值,并且中英文…...
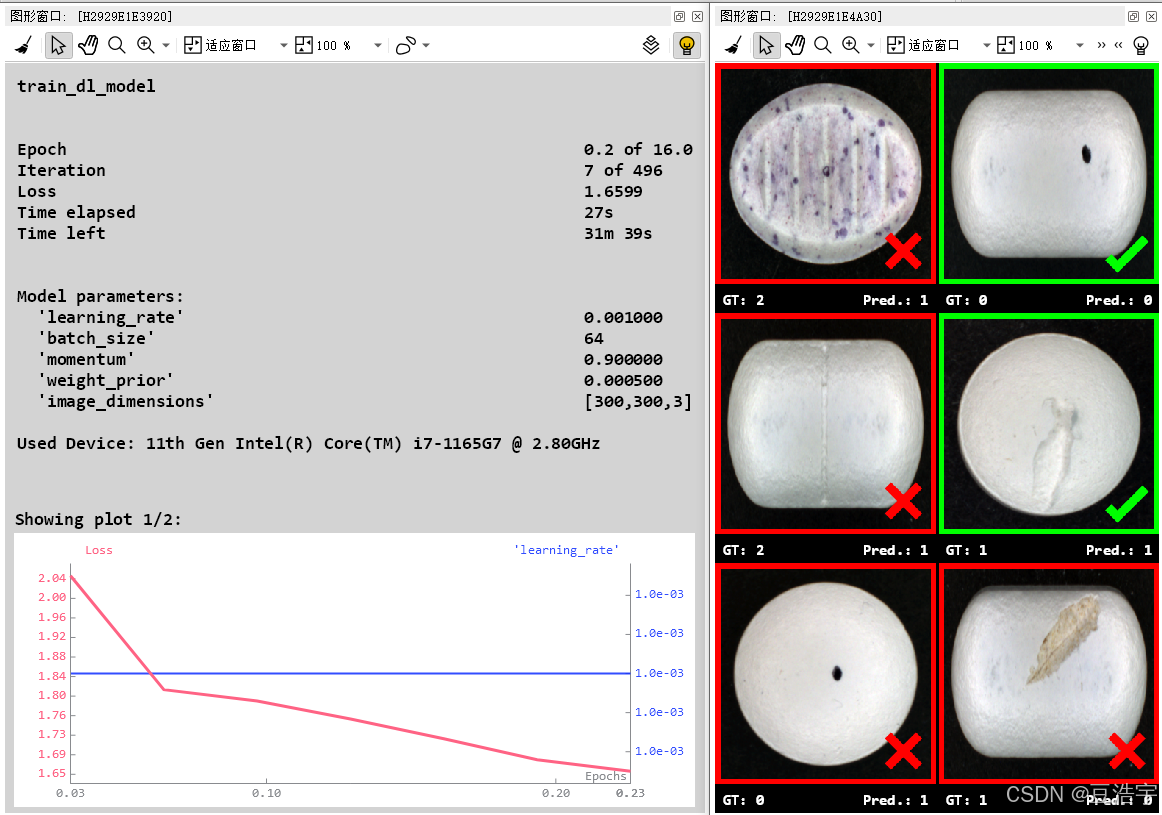
Halcon深度学习分类模型
1.Halcon20之后深度学习支持CPU训练模型,没有money买显卡的小伙伴有福了。但是缺点也很明显,就是训练速度超级慢,推理效果也没有GPU好,不过学习用足够。 2.分类模型是Halcon深度学习最简单的模型,可以用在物品分类&…...

洗地机哪种牌子好?洗地机排行榜前十名公布
洗地机市场上品牌琳琅满目,每个品牌都有其独特的魅力和优势。消费者在选择时,往往会根据自己的实际需求、预算以及对产品性能的期望来做出决策。因此,无论是哪个品牌的洗地机,只要能够满足用户的清洁需求,提供便捷的操…...

C++中的虚函数与多态机制如何工作?
在C中,虚函数和多态机制是实现面向对象编程的重要概念。 虚函数是在基类中声明的函数,可以在派生类中进行重写。当基类的指针或引用指向派生类的对象时,通过调用虚函数可以实现动态绑定,即在运行时确定要调用的函数。 多态是指通…...

《LeetCode热题100》---<哈希三道>
本篇博客讲解 LeetCode热题100道中的哈希篇中的三道题。分别是 1.第一道:两数之和(简单) 2.第二道:字母异位词分组(中等) 3.第三道:最长连续序列(中等) 第一道࿱…...
秒懂C++之string类(下)
目录 一.接口说明 1.1 erase 1.2 replace(最好别用) 1.3 find 1.4 substr 1.5 rfind 1.6 find_first_of 1.7 find_last_of 二.string类的模拟实现 2.1 构造 2.2 无参构造 2.3 析构 2.4.【】运算符 2.5 迭代器 2.6 打印 2.7 reserve扩容 …...
github简单地操作
1.调节字体大小 选择options 选择text 选择select 选择你需要的参数就可以了。 2.配置用户名和邮箱 桌面右键,选择git Bash Here git config --global user.name 用户名 git config --global user.email 邮箱名 3.用git实现代码管理的过程 下载别人的项目 git …...

模型改进-损失函数合集
模版 第一步在哪些地方做出修改: 228行 self.use_wiseiouTrue 230行 self.wiou_loss WiseIouLoss(ltypeMPDIoU, monotonousFalse, inner_iouTrue, focaler_iouFalse) 238行 wiou self.wiou_loss(pred_bboxes[fg_mask], target_bboxes[fg_mask], ret_iouFalse…...
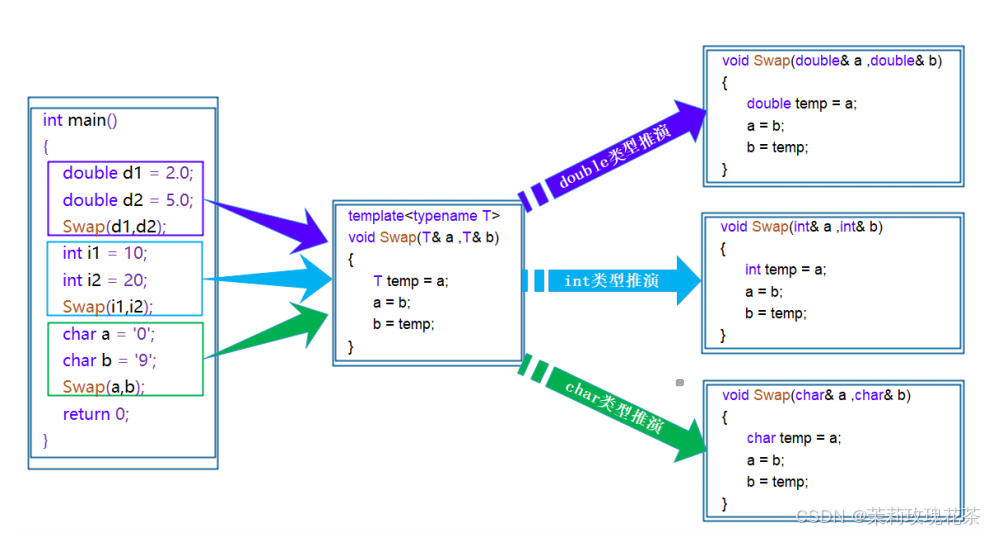
C++模板(初阶)
1.引入 在之前的笔记中有提到:函数重载(特别是交换函数(Swap)的实现) void Swap(int& left, int& right) {int temp left;left right;right temp; } void Swap(double& left, double& right) {do…...

下面关于Date类的描述错误的一项是?
下面关于Date类的描述错误的一项是? A. java.util.Date类下有三个子类:java.sql.Date、java.sql.Timestamp、java.sql.Time; B. 利用SimpleDateFormat类可以对java.util.Date类进行格式化显示; C. 直接输出Date类对象就可以取得日…...
【Python面试题收录】Python编程基础练习题①(数据类型+函数+文件操作)
本文所有代码打包在Gitee仓库中https://gitee.com/wx114/Python-Interview-Questions 一、数据类型 第一题(str) 请编写一个Python程序,完成以下任务: 去除字符串开头和结尾的空格。使用逗号(","&#…...
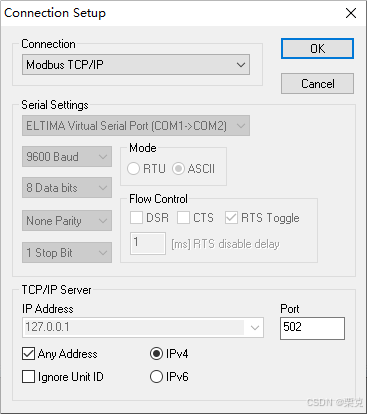
C# Nmodbus,EasyModbusTCP读写操作
Nmodbus读写 两个Button控件分别为 读取和写入 分别使用控件的点击方法 ①引用第三方《NModbus4》2.1.0版本 全局 public SerialPort port new SerialPort("COM2", 9600, Parity.None, 8, (StopBits)1); ModbusSerialMaster master; public Form1() port.Open();…...

spark常用参数调优
目录 1.set spark.grouping.sets.reference.hivetrue;2.set spark.locality.wait.rack0s3.set spark.locality.wait0s;4.set spark.executor.memoryOverhead 2G;5.set spark.sql.shuffle.partitions 1000;6.set spark.shuffle.file.buffer 256k7. set spark.reducer.maxSizeInF…...
C#/WinFrom TCP通信+ 网线插拔检测+客服端异常掉线检测
Winfor Tcp通信(服务端) 今天给大家讲一下C# 关于Tcp 通信部分,这一块的教程网上一大堆,不过关于掉网,异常断开连接的这部分到是到是没有多少说明,有方法 不过基本上最多的两种方式(1.设置一个超时时间,2.…...

一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80% Python爬虫 Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。 一、Python 爬虫…...

构建可复用技能库:从代码片段到自动化工作流的工程实践
1. 项目概述:从零构建一套可复用的“副爪”技能库在技术社区里,我们常常会看到一些零散的代码片段、脚本工具或者临时的解决方案,它们像散落的“爪子”一样,能解决特定问题,但不成体系,难以复用和传承。我自…...

Arm A64指令集SIMD与浮点寄存器架构解析
1. A64指令集的SIMD与浮点寄存器架构解析在Armv8-A架构中,A64指令集引入了强大的向量处理能力,通过32个128位宽的V寄存器(V0-V31)实现了高效的SIMD(单指令多数据)和浮点运算支持。这套寄存器文件的设计巧妙…...
)
从STM32到华大HC32F460:手把手移植USB HOST MSC + FatFs R0.13c(含源码对比与避坑指南)
从STM32到华大HC32F460:USB HOST MSC与FatFs移植实战全解析 1. 迁移背景与核心挑战 对于长期使用STM32的嵌入式开发者而言,切换到华大半导体HC32F460系列MCU既是一次技术升级,也面临实际移植的挑战。USB HOST MSC(Mass Storage Cl…...

Linux调试利器:用addr2line精准定位程序崩溃现场
1. 当程序崩溃时,我们该如何快速定位问题? 作为一名长期奋战在Linux开发一线的程序员,我最头疼的就是遇到程序突然崩溃的情况。那种看着终端输出"Segmentation fault (core dumped)"却无从下手的无力感,相信很多开发者都…...

从ADI收购LTC看电源管理趋势:软件定义电源与能量收集技术解析
1. 从一笔天价收购案,看电源管理技术的未来十年2016年,模拟芯片行业发生了一场地震级的并购:模拟巨头亚德诺半导体(Analog Devices Inc., ADI)以148亿美元的天价,收购了以高性能模拟芯片闻名的凌力尔特&…...

从玩具车到智能体:用STC89C52给小车装上‘眼睛’和‘触角’的传感器融合实战
从玩具车到智能体:STC89C52多传感器融合的决策系统设计 当一辆普通的玩具车被赋予环境感知能力,它便开始了向智能体的进化。在这个项目中,我们使用STC89C52单片机作为"大脑",通过超声波模块和漫反射光电传感器构建了一…...

别再傻傻分不清了!VB、VBS、VBA到底该用哪个?从Excel自动化到网页脚本的实战选择指南
VB、VBS与VBA实战指南:从Excel自动化到系统脚本的精准选择 每次打开Excel准备处理数据时,你是否纠结过该用VBA还是VBS?当需要批量重命名文件时,是否犹豫过VB和VBS哪个更高效?这三种看似相似的"VB系"语言&am…...

CANN/asc-devkit bfloat16转half API
__bfloat162half_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://git…...

不可错过的AI教材写作攻略,借助工具轻松达成低查重目标
教材编写中的挑战与AI工具的解决方案 在教材编写的过程中,确保原创性与合规性之间的平衡是一项关键任务。创作者在借鉴优秀教材的同时,又担心查重率可能会超标;而在尝试自主创作时,又容易面临逻辑不够严密或内容不准确的问题。更…...

从课堂到代码:三大数学可视化工具实战解析
1. 数学可视化工具的选择困境 第一次接触数学可视化工具时,我被各种选项搞得眼花缭乱。作为数学老师,我需要一个能让学生快速上手的工具;作为编程爱好者,我又希望它能支持更复杂的算法可视化。经过多年实践,我发现Desm…...