Python 如何进行Web抓取(BeautifulSoup, Scrapy)
Web抓取(Web Scraping)是一种从网站提取数据的技术。Python有许多用于Web抓取的库,其中最常用的是BeautifulSoup和Scrapy。
BeautifulSoup
BeautifulSoup是一个用于解析HTML和XML文档的Python库,适合处理简单的Web抓取任务。它将复杂的HTML文档转换成一个可遍历的解析树,可以方便地找到需要的元素。
安装BeautifulSoup
要使用BeautifulSoup,首先需要安装它以及请求库requests:
pip install beautifulsoup4
pip install requests
导入BeautifulSoup
from bs4 import BeautifulSoup
import requests
获取网页内容
首先需要获取网页的HTML内容,可以使用requests库:
url = 'http://example.com'
response = requests.get(url)
html_content = response.content
解析HTML
使用BeautifulSoup解析HTML内容:
soup = BeautifulSoup(html_content, 'html.parser')
查找元素
BeautifulSoup提供了多种查找元素的方法,如find、find_all、select等。
# 查找第一个<p>标签
p_tag = soup.find('p')
print(p_tag.text)# 查找所有<a>标签
a_tags = soup.find_all('a')
for tag in a_tags:print(tag.get('href'))# 使用CSS选择器
header = soup.select_one('h1')
print(header.text)
处理属性
可以方便地获取标签的属性:
img_tag = soup.find('img')
print(img_tag['src'])
示例:抓取一个博客的标题和链接
以下是一个简单的示例,展示如何抓取一个博客页面的所有文章标题和链接:
url = 'http://example-blog.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')articles = soup.find_all('article')
for article in articles:title = article.find('h2').textlink = article.find('a')['href']print(f'Title: {title}, Link: {link}')
Scrapy
Scrapy是一个功能强大的Web抓取和Web爬虫框架,适用于复杂的抓取任务。它具有高性能、可扩展性强、支持异步处理等特点。
安装Scrapy
使用pip安装Scrapy:
pip install scrapy
创建Scrapy项目
首先需要创建一个Scrapy项目:
scrapy startproject myproject
cd myproject
创建爬虫
在Scrapy项目中,可以创建一个新的爬虫:
scrapy genspider myspider example.com
这将在spiders目录下生成一个名为myspider.py的文件。
编写爬虫
打开myspider.py,可以看到一个基本的爬虫模板。我们将修改这个模板来实现抓取任务。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):# 解析响应for article in response.css('article'):title = article.css('h2::text').get()link = article.css('a::attr(href)').get()yield {'title': title,'link': link}
运行爬虫
在命令行中运行爬虫:
scrapy crawl myspider -o output.json
这将抓取example.com并将结果保存到output.json文件中。
Scrapy中的重要概念
- Item:定义抓取的数据结构。
- Spider:定义如何抓取网站的爬虫。
- Pipeline:定义数据处理和存储的流程。
- Middleware:处理请求和响应的中间件。
定义Item
可以在items.py中定义Item:
import scrapyclass MyprojectItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()
然后在爬虫中使用Item:
from myproject.items import MyprojectItemclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):for article in response.css('article'):item = MyprojectItem()item['title'] = article.css('h2::text').get()item['link'] = article.css('a::attr(href)').get()yield item
使用Pipeline处理数据
在pipelines.py中定义Pipeline:
class MyprojectPipeline:def process_item(self, item, spider):# 处理itemreturn item
在settings.py中启用Pipeline:
ITEM_PIPELINES = {'myproject.pipelines.MyprojectPipeline': 300,
}
示例:抓取一个电商网站的商品信息
以下是一个完整的示例,展示如何使用Scrapy抓取一个电商网站的商品信息。
首先定义Item:
# items.py
import scrapyclass ProductItem(scrapy.Item):name = scrapy.Field()price = scrapy.Field()availability = scrapy.Field()
然后编写爬虫:
# spiders/products_spider.py
import scrapy
from myproject.items import ProductItemclass ProductsSpider(scrapy.Spider):name = 'products'start_urls = ['http://example-ecommerce.com/products']def parse(self, response):for product in response.css('div.product'):item = ProductItem()item['name'] = product.css('h3.product-name::text').get()item['price'] = product.css('span.product-price::text').get()item['availability'] = product.css('span.availability::text').get()yield item# 处理分页next_page = response.css('a.next-page::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)
最后启用Pipeline并运行爬虫:
# pipelines.py
class ProductPipeline:def process_item(self, item, spider):# 处理商品信息return item# settings.py
ITEM_PIPELINES = {'myproject.pipelines.ProductPipeline': 300,
}# 运行爬虫
scrapy crawl products -o products.json
BeautifulSoup和Scrapy各有优缺点,BeautifulSoup适合处理简单的抓取任务,使用方便,代码简洁;而Scrapy则更适合处理复杂的抓取任务,具有强大的功能和高效的性能。在实际项目中,可以根据具体需求选择合适的工具,甚至结合使用这两个库,以充分发挥各自的优势。

相关文章:
Python 如何进行Web抓取(BeautifulSoup, Scrapy)
Web抓取(Web Scraping)是一种从网站提取数据的技术。Python有许多用于Web抓取的库,其中最常用的是BeautifulSoup和Scrapy。 BeautifulSoup BeautifulSoup是一个用于解析HTML和XML文档的Python库,适合处理简单的Web抓取任务。它将…...

白骑士的PyCharm教学进阶篇 2.5 数据库连接与管理
系列目录 上一篇:白骑士的PyCharm教学进阶篇 2.4 Django开发支持 在Web开发中,数据库是必不可少的部分。PyCharm不仅是一款功能强大的IDE,还提供了丰富的数据库连接和管理工具,使开发者可以更方便地浏览和操作数据库。本篇将详细…...

(五)activiti-modeler 编辑器初步优化
最终效果: 1..首先去掉顶部的logo,没什么用,还占用空间。 修改modeler.html文件,添加样式: <style type"text/css"> #main-header{display: none; } #main{padding: 0px; } </style> 2.左边组…...
C++类和对象3)
(学习总结12)C++类和对象3
C类和对象3 一、初始化列表二、类型转换三、static成员四、友元五、内部类六、匿名对象 以下代码环境在 VS2022。 一、初始化列表 之前我们实现构造函数时,初始化成员变量主要使用函数体内赋值,构造函数初始化还有⼀种方式,就是初始化列表&a…...

docxtpl,一个强大的 Python 库!
更多资料获取 📚 个人网站:ipengtao.com 大家好,今天为大家分享一个强大的 Python 库 - docxtpl。 项目地址:https://docxtpl.readthedocs.io/en/latest/ 在日常工作中,自动生成和处理 Word 文档是一个常见需求。doc…...

捷途山海T2:超长续航,节能环保的驾驶新星
在当今的汽车市场中,消费者的购车选择日趋多样化,不再仅限于传统的燃油车。随着环保理念的深入人心以及人们对用车成本的日益关注,像捷途山海T2这样配备高效混动系统的车型逐渐受到大众的青睐。 捷途山海T2,以其杰出的节能性、强劲…...

[Day 45] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的可擴展性挑戰 概述 區塊鏈技術在過去幾年中取得了顯著的進展,其去中心化、透明和安全的特性使其在金融、供應鏈管理、醫療等領域得到了廣泛應用。然而,區塊鏈技術的一個重大挑戰是其可擴展性。可擴展性是指系統能夠有效處理日益增長的數據和用…...

白骑士的PyCharm教学实战项目篇 4.3 自动化测试与持续集成
系列目录 上一篇: 在现代软件开发过程中,自动化测试与持续集成(CI)是确保代码质量和快速交付的关键环节。PyCharm作为一款强大的集成开发环境(IDE),为自动化测试和持续集成提供了全面的支持。本…...
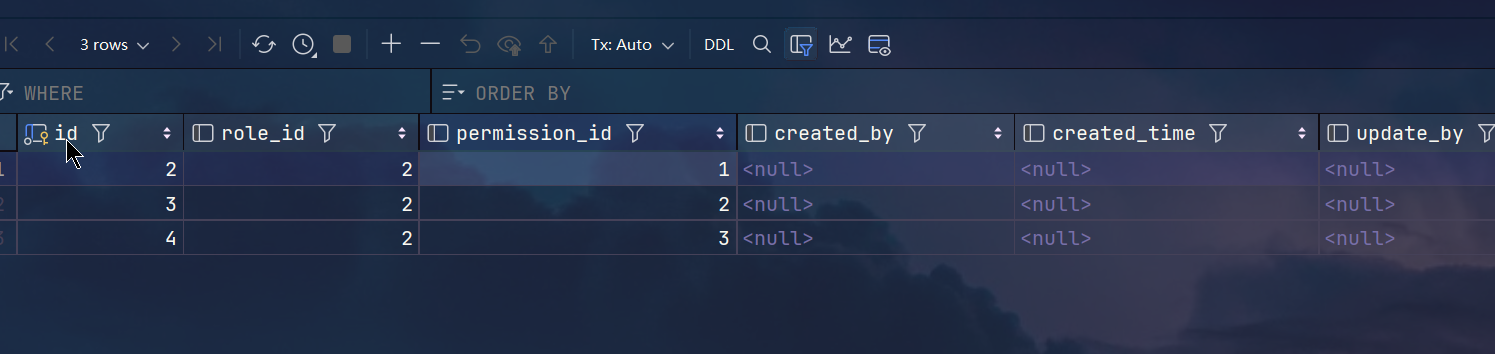
权限模块开发+权限与角色关联(完整CRUD)
文章目录 🌞 Sun Frame:SpringBoot 的轻量级开发框架(个人开源项目推荐)🌟 亮点功能📦 spring cloud模块概览常用工具 🔗 更多信息1.easycode生成代码1.配置2.AuthPermissionDao.java剪切到mapp…...

llama神经网络的结构,llama-3-8b.layers=32 llama-3-70b.layers=80; 2000汉字举例说明
目录 llama-3-8b.layers=32 llama-3-70b.layers=80 llama神经网络的结构 Llama神经网络结构示例 示例中的输入输出大小 实际举例说明2000个汉字文本数据集 初始化词嵌入矩阵 1. 输入层 2. 嵌入层 3. 卷积层 4. 全连接层 llama-3-8b.layers=32 llama-3-70b.laye…...

单细胞数据怎么表现genes mRNA表达的热图?
愿武艺晴小朋友一定得每天都开心 #热图 library("ComplexHeatmap") exp <- AverageExpression(subset(fasting_memory, Celltype %in% c("Pre-B")), layer = "data", #即CPM值 features …...

Java聚合快递对接云洋系统小程序源码
🚀【物流新纪元】聚合快递如何无缝对接云洋系统,效率飙升秘籍大公开!✨ 🔍 开篇揭秘:聚合快递的魅力所在 Hey小伙伴们,你是否还在为多家快递公司账号管理繁琐、订单处理效率低下而头疼?&#…...
修改数据表)
MySQL——数据表的基本操作(三)修改数据表
有时候,希望对表中的某些信息进行修改,这时就需要修改数据表。所谓修改数据表指的是修改数据库中已经存在的数据表结构,比如,修改表名、修改字段名、修改字段的数据类型等。在 MySQL中,修改数据表的操作都是使用 ALTER…...

医学图像分割的基准:TransUnet(用于医学图像分割的Transformer编码器)器官分割
1、 TransUnet 介绍 TransUnet是一种用于医学图像分割的深度学习模型。它是基于Transformer模型的图像分割方法,由AI研究公司Hugging Face在2021年提出。 医学图像分割是一项重要的任务,旨在将医学图像中的不同结构和区域分离出来,以便医生可…...

java-swing编写学生成绩查询管理系统
本文是本人大二上实训项目-学生成绩查询管理系统,采用本项目使用Java、MySQL技术。界面框架由Java Swing搭建,用JDBC实现Java与MySQL的连接。 本项目适合初学java和mysql的同学,来做一些小项目来提升自己,因为兴趣所以想要做去尝…...

volatile浅解
volatile修饰的变量有两个特点 线程中修改了自己工作内存中的副本后,立即将其刷新到主内存工作内存中每次读取共享变量时,都会去主内存中重新读取,然后拷贝到工作内存 内存 -> CPU Cache -> CPU 如果没有volatile那么就会继续读取缓存…...

世媒讯带您了解什么是媒体邀约
什么是媒体邀约?其实媒体邀约是一种公关策略,旨在通过邀请媒体记者和编辑参加特定的活动、发布会或其他重要事件,以确保这些活动能够得到广泛的报道和关注。通过这种方式,企业和组织希望能够传达重要信息,提高品牌知名…...

[Kimi 笔记]“面向搜索引擎”
"面向搜索引擎"(Search Engine-Oriented,SEO-Oriented 或 SEO-Friendly)通常指的是在设计和开发网站时,采取一系列措施来优化网站内容和结构,以便提高网站在搜索引擎结果页面(SERP)中…...

如何在亚马逊云科技AWS上利用LoRA高效微调AI大模型减少预测偏差
简介: 小李哥将继续每天介绍一个基于亚马逊云科技AWS云计算平台的全球前沿AI技术解决方案,帮助大家快速了解国际上最热门的云计算平台亚马逊云科技AWS AI最佳实践,并应用到自己的日常工作里。 在机器学习和人工智能领域,生成偏差…...

订单定时状态处理业务(SpringTask)
文章目录 概要整体架构流程技术细节小结 概要 订单定时状态处理通常涉及到对订单状态进行定期检查,并根据订单的状态自动执行某些操作,比如关闭未支付的订单、自动确认收货等. 需求分析以及接口设计 需求分析 用户下单后可能存在的情况: …...

Linux时钟子系统:CCF框架与驱动开发实践
1. Linux时钟子系统概述在嵌入式Linux系统中,时钟管理是驱动开发的基础环节之一。时钟子系统负责为整个系统提供精确的时序控制,从CPU主频到外设工作时钟,都需要通过时钟子系统进行管理和配置。Linux内核通过CCF(Common Clock Fra…...

:5天打造跨平台Galgame播放器《Galplayer》——从脚本解析到电影式体验)
【游戏引擎之路】极速狂飙(一):5天打造跨平台Galgame播放器《Galplayer》——从脚本解析到电影式体验
1. 极速开发背后的技术选型 开发《Galplayer》最疯狂的地方在于,我只用了5天就完成了从零到可运行版本的开发。这听起来像天方夜谭,但合理的工具链选择让这一切成为可能。我选择了WPFPythonUnity这个"三件套"组合,每个工具都发挥了…...

TouchGal终极指南:打造纯净Galgame社区的完整解决方案
TouchGal终极指南:打造纯净Galgame社区的完整解决方案 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next TouchGal是一个专为…...

TFLint Docker终极指南:在容器中轻松运行Terraform代码检查
TFLint Docker终极指南:在容器中轻松运行Terraform代码检查 【免费下载链接】tflint A Pluggable Terraform Linter 项目地址: https://gitcode.com/gh_mirrors/tf/tflint TFLint是一个可插拔的Terraform代码检查工具,帮助开发者发现Terraform配置…...

# 大数据开发面试题库
大数据开发岗面试必备:SQL 高频题、Spark 性能调优、数仓建模实战、项目经验梳理,覆盖初中级到高级岗位 📌 前言 为什么面试总被问倒? 为什么项目经验说不清楚? 为什么调优问题总是泛泛而谈? 根本原因&am…...

如何查看浏览器中当前存储的 Cookie?
如何查看浏览器中的 Cookie?为什么有些 Cookie 看不到?1. 引言:快递单号与隐私信封2. Cookie 是什么?(小白必备)3. 核心问题:为什么有些 Cookie“看不到”?4. 如何查看 Cookie&#…...
)
深度解析 Claude Code v2.1.88 源码:技术栈与底层实现全揭秘(基于流出架构资料)
深度解析 Claude Code v2.1.88 源码:技术栈与底层实现全揭秘(基于流出架构资料) 摘要:2026年3月31日,Claude Code v2.1.88 相关技术资料(含TypeScript工程架构、核心模块实现逻辑,合计51.2万行代码量级)公开流出,包含其核心架构、工具系统、安全机制等全部实现细节。…...
的5个常见错误及优化方案)
避坑指南:Doris明细模型(Duplicate Key Model)的5个常见错误及优化方案
避坑指南:Doris明细模型(Duplicate Key Model)的5个常见错误及优化方案 在实时数据分析领域,Apache Doris凭借其卓越的性能和易用性赢得了众多企业的青睐。作为Doris中最基础也最常用的数据模型,明细模型(Duplicate Key Model&…...

Keil MDK-ARM工程改名后编译报错?可能是这3个隐藏配置没改对
Keil MDK-ARM工程改名后编译报错?可能是这3个隐藏配置没改对 当你按照标准流程修改Keil工程名后,发现编译依然报错,这往往意味着某些隐藏配置仍在引用旧工程名。作为嵌入式开发者,我们需要像侦探一样排查这些"数字指纹"…...