MongoDB基础
优质博客 IT-BLOG-CN
一、简介
MongoDB是一个强大的分布式文件存储的NoSQL数据库,天然支持高可用、分布式和灵活设计。由C++编写,运行稳定,性能高。为WEB应用提供可扩展的高性能数据存储解决方案。主要解决关系型数据库数据量大,并发高导致查询效率低下的问题,通过使用内存代替磁盘提高查询性能。
MongoDB特点:
【1】模块自由:可以把不同结构的文档存在在同一个数据库里;
【2】面向集合的存储:适合存储JSON风格文件的形式;
【3】完整的索引支持:对任何属性都可以加索引;
【4】复制和高可用性:支持服务器之间的数据复制,支持主-从模式及服务器之间的相互复制。从而提供冗余备份及自动故障转移;
【5】自动分片:支持云级别的伸缩性,自动分片功能支持水平的数据库集群,可动态添加额外的机器;
【6】丰富的查询:支持丰富的查询表达方式,查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组;
【7】快速更新查询:查询优化器会分析查询表示式,并生成一个高效的查询计划;
【8】高效的传统存储方式:支持二进制数据及大型对象(如图片);
二、基本操作
MongoDB将数据存储在一个文件,数据结构由键值key:value对组成,类似于JSON对象,字段值包含其他文档、数组、文档数组。
| SQL术语 | MongoDB术语 | 说明 |
|---|---|---|
| DataBase | DataBase | 数据库 |
| Table | Collection | 数据库表/集合:存储多个文档,结构不固定{'name':'zzx','gender':'男'}{'class':'一班','count':'10'} |
| Row | Document | 数据记录行/文档就是一个对象,由键值对构成,是JSON扩展的BSON格式{'name':'zzx','gender':'男'} |
| Column | Field | 数据字段/域 |
| Index | Index | 索引 |
| Table Joins | 表连接,MongoDB不支持 | |
| Primary Key | Primary Key | 主键,MongoDB自动将_id设置为主键 |
集合操作
// 创建
db.createCollection(name, options)
// 查看集合
show collections
// 删除
db.集合名称.drop()
name要创建的集合名称,options是一个文档,用于制定集合的配置,选项参数是可选的:参数capped:默认为false表示不设置上限;参数size:当capped值为true时,需要指定此参数,表示设置上限的大小,会覆盖之前的值,单位为字节。
db.createCollection("stu")
db.createCollection("stu", { capped: true, size: 20})
数据类型
| 类型 | 说明 |
|---|---|
| Object ID | 文档ID,每个文档都有一个属性,为_id保证一个文档的唯一性,可以自己设置,如果没有设置自动提供一个特别的_id,类型为objectID:12字节的十六进制数,前4个字节时时间戳,接下来3个字节是机器ID,接下来2个字节服务进程ID最后三位是增量值 |
| String | 字符串UTF-8 |
| Boolean | 布尔 |
| Integer | 整形 |
| Double | 布尔 |
| Arrays | 数组或列表 |
| Object | 嵌入式的文档,MongoDB是不能维护关系的,可以通过嵌入文档的形式来维护这个关系 |
| Null | 空值 |
| Timestamp | 时间戳 |
| Date | 日期UNIX时间格式 |
文档操作
// 插入
db.集合名称.insert(document)//案例1
db.stu.insert({name:'zzx',gender:1}) //自动生成_id
//案例2
s1={_id:'43444433',name:'zzx'}
s1.gender=0
db.stu.insert(s1)// 修改
db.集合名称.update(<query>, // 查询条件,类似sql中的where部分<update>, // 类似sql中的 set部分{$multi:<boolean>} // 默认false值改第一条记录,true表示修改满足的所有数据
)//案例
db.stu.update({name:'zzx'},{name:'fj'}) // 整个文档的结构都会发生变化
db.stu.update({name:'zzx'},{$set:{name:'fj'}}) // 只会修改 name的属性// 保存:如果数据存在进行修改,不存在进行插入
db.集合名称.save(document)// 删除
db.集合名称.remove(<query>,{justOne:<boolean> //默认false会删除多条}
)
查询操作
// 查询
db.集合名称.find(条件文档)
// 查询一条数据
db.集合名称.findOne(条件文档)//案例 and和or一起使用。运算法符:$lt小于 $lte小于等于 $gt大于 $gte大于等于 $ne不等于 使用//或者$regex编写正则表达式
db.stu.find({$or:[{age: {$gte: 18}}, {gender: 1}], name: 'zzx'})
db.stu.find({name:{$regex:'^黄'}})
db.stu.find({name:/^黄/})// ** 自定义查询:使用 $where后面写一个函数
db.stu.find({$where:function(){return this.age > 20}})// limit()用于读取指定数量的文档
db.集合名称.find().limit(NUMBER) //NUMBER表示文档的条数
// skip()用于跳过指定数量的文件,配合limit实现分页功能,与limit同时使用的时候不分先后顺序。
db.集合名称.find().skip(NUMBER)//投影:查询的结构集只选择必要的字段
db.集合名称.find({},{字段名称:1,...}) // 对需要显示的字段设置为1,id默认会返回,如果不想返回可以设置为0// 排序 sort()
db.集合名称.find().sort({字段:1,...}) // 1升序,-1降序
// 统计 count()
db.集合名称.find().count({条件}) //find可以省略
db.stu.count({age:{$gt:20},gender:1})// 去重distinct()
db.集合名称.distinct({去重字段,{条件}})
聚合
主要用于计算数据,类似sql中的sum()、avg()。
常用的管道:$group将集合中的文档分组,可用于统计结果;$match过滤数据,只输出符合条件的文档;$project修改输入文档的结构,如重命名、增加、删除字段、创建计算结果;$sort将输入文档排序后输出;$limit限制聚合管道返回的文档数;$skip跳过指定数量的文档,返回剩余文档;$unwind将数组类型的字段进行拆分;
常用的表达式:$sum计算综合,$sum:1同count表示计数;$avg计算平均值;$min获取最小值;$max获取最大值;$push在结果文档中插入值到下一个数组中;$first根据资源文件的排序获取第一个文档数据;$last根据资源文档的排序获取最后一个文档数据。
db.集合名称.aggregate([{管道:{表达式}}]) //管道在Linux中一般用于将当前命令的输出结果作为下一个命令的输入,在MongoDB中是同样的作用
分组$group
// 统计男女的总人数 _id表示组分的依据,使用某个字段的格式为'$字段',如果需要得到整个文档可以使用 '$$ROOT' 替换 '$age'
db.stu.aggregate([{$group:{_id:'$gender',counter:{$push:'$age'}}}
])
// 输入
{"_id":男,"counter":[12,45]}
{"_id":女,"counter":[22,15]}
过滤数据$match
db.stu.aggregate([{$match:{age:{$gt:20}}},{$group:{_id:'$gender',counter:{$sum:1}}}
])
投影$project:只显示某个字段
db.stu.aggregate([{$group:{_id:'$gender',counter:{$sum:1}}},{$project:{_id:0,counter:1}}
])
排序$sort
db.stu.aggregate([{$group:{_id:'$gender',counter:{$sum:1}}},{$sort:{counter:-1}}
])
$limit 和 $skip
db.stu.aggregate([{$group:{_id:'$gender',counter:{$sum:1}}},{$sort:{counter:-1}},{$skip:1},{$limit:1}
])
$unwind 将数组类型的字段进行拆分,如果不是数组是一个属性,就单独输出该属性
db.集合名称.aggregate([{$unwind:'$字段名称'}])db.stu.insert({name:'zzx',size:['S','Z','L']})
db.stu.aggregate([$unwind:'$size'
])// 处理是空数组,无字段,null的情况使用上述 $unwind数据会丢失,可以使用下面表达式,防止数据丢失
db.stu.aggregate([{$unwind:{path:'$字段名称',preserverNullAndEmptyArrays:<boolean> //防止数据丢失}}
])
三、索引
MongoDB通过索引提升查询速度
// 使用explain()命令分析查询性能
db.stu.find({name:'zzx100000'}).explain('executionStats')
// 分析结果如下:
"executionStats": {"executionSuccess": true,"nReturned": 1,"executionTimeMillis": 96,"totalKeysExamined": 0,"totalDocsExamined": 100000,
}
建立索引: 1表示升序,-1表示降序
db.集合.ensureIndex({属性:1})
db.stu.ensureIndex({name:1})// 对索引属性查询
db.stu.find({name:'zzx100000'}).explain('executionStats')
// 分析结果如下:
"executionStats": {"executionSuccess": true,"nReturned": 1,"executionTimeMillis": 1,"totalKeysExamined": 0,"totalDocsExamined": 100000,
}// 唯一索引
db.stu.ensureIndex({'name':1},{'unique':true})
// 联合索引
db.stu.ensureIndex({name:1,age1})
// 查看索引
db.stu.getIndexes()
// 删除所以
db.stu.dropIndexes('索引名称')
四、安全
为了更安全的访问MongoDB,需要创建用户。采用角色、用户、数据库的安全管理方式。常用的角色如下:root只在admin数据库中可用,超级账号,超级权限。Read用户只读权限,readWrite用户读写权限。
// 创建超级管理员
use admin // admin是数据库
db.createUser({user:'admin',pwd:'123',roles:[{role:'root',db:'admin'}]
})
启用安全认证:修改配置文件
sudo vi /etc/mongod.conf
启用身份认证:keys and values之间一定要有空格,否则解析错误。修改完配置文件后,必须重启服务。
security:authorization: enable
数据库连接
mongo -u admin -p 123 --authenticationDatabase admin
五、备份与恢复
复制提供数据冗余备份,并在多个服务器上存储数据副本,提高数据的可用性,并保证数据的安全性,允许从硬件故障和服务中断中恢复数据。常见的搭配是一主多从。主节点记录所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证数据的一致性。
优点:
【1】数据备份;
【2】数据灾难恢复(自动故障转移,自动恢复);
【3】读写分离;
【4】高数据可用;
【5】无宕机维护;
【6】副本集对应用程序是透明的;
设置复制节点:
mongod --bind_ip 192.168.113.122 --port 27017 --dbpath ./mongdb/file1 --replSet rs0 // rs0副本集,master和slave的副本集相同
mongod --bind_ip 192.168.154.132 --port 27017 --dbpath ./mongdb/file1 --replSet rs0
通过客户端连接MongoDB master,并在master上面进行初始化,同时添加其他副本集(也就是备份的服务器信息)。如果在从服务器上进行读操作,需要设置rs.slaveOk()。
mongo --host 192.168.113.122 --port 27017 // 主服务器rs.initiate() //rs是mongodb提供的副本集管理对象rs.add('192.168.154.132:27017') // 从服务器rs.salveOk()
手动备份:
mongodump -h dbhost -d dbname -o dbdirectory
恢复:
mongorestore -h dbhost -d dbname --dir dbdirectory
相关文章:

MongoDB基础
优质博客 IT-BLOG-CN 一、简介 MongoDB是一个强大的分布式文件存储的NoSQL数据库,天然支持高可用、分布式和灵活设计。由C编写,运行稳定,性能高。为WEB应用提供可扩展的高性能数据存储解决方案。主要解决关系型数据库数据量大,并…...

【Linux】Linux基本指令(下)
前言: 紧接上期【Linux】基本指令(上)的学习,今天我们继续学习基本指令操作,深入探讨指令的基本知识。 目录 (一)常用指令 👉more指令 👉less指令(重要&…...
基于uniapp+u-view开发小程序【技术点整理】
一、上传图片 1.实现效果: 2.具体代码: <template><view><view class"imgbox"><view>职业证书</view><!-- 上传图片 --><u-upload :fileList"fileList1" afterRead"afterRead"…...
)
投稿指南【NO.7】目标检测论文写作模板(初稿)
中文标题(名词性短语,少于20字,尽量不使用外文缩写词)张晓敏1,作者1,2***,作者2**,作者2*(通信作者右上标*)1中国科学院上海光学精密机械研究所空间激光传输与探测技术重…...
【绘图】比Matplotlib更强大:ProPlot
✅作者简介:在读博士,伪程序媛,人工智能领域学习者,深耕机器学习,交叉学科实践者,周更前沿文章解读,提供科研小工具,分享科研经验,欢迎交流!📌个人…...

经典七大比较排序算法 ·上
经典七大比较排序算法 上1 选择排序1.1 算法思想1.2 代码实现1.3 选择排序特性2 冒泡排序2.1 算法思想2.2 代码实现2.3 冒泡排序特性3 堆排序3.1 堆排序特性:4 快速排序4.1 算法思想4.2 代码实现4.3 快速排序特性5 归并排序5.1 算法思想5.2 代码实现5.3 归并排序特性…...

【网络安全工程师】从零基础到进阶,看这一篇就够了
学前感言 1.这是一条需要坚持的道路,如果你只有三分钟的热情那么可以放弃往下看了。 2.多练多想,不要离开了教程什么都不会,最好看完教程自己独立完成技术方面的开发。 3.有问题多google,baidu…我们往往都遇不到好心的大神,谁…...
素描-基础
# 如何练习排线第一次摸板子需要来回的排线,两点然后画一条线贯穿两点画直的去练 练线的定位叫做穿针引线法或者两点一线法 练完竖线练横线 按照这样去练顺畅 直线曲线的画法 直线可以按住shift键 练习勾线稿 把线稿打开降低透明度去勾线尽量一笔的去练不要压…...
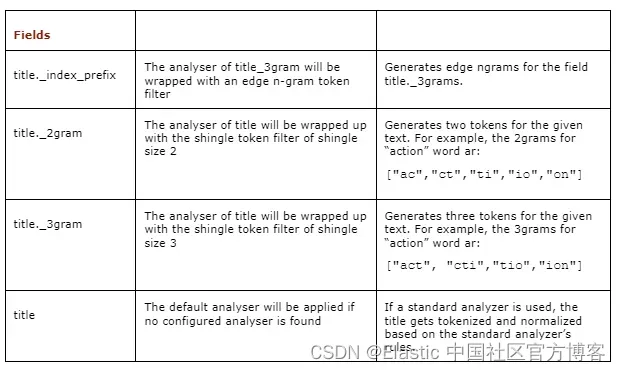
Elasticsearch:高级数据类型介绍
在我之前的文章 “Elasticsearch:一些有趣的数据类型”,我已经介绍了一下很有趣的数据类型。在今天的文章中,我再进一步介绍一下高级的数据类型,虽然这里的数据类型可能和之前的一些数据类型有所重复。即便如此,我希望…...

Golang每日一练(leetDay0012)
目录 34. 查找元素首末位置 Find-first-and-last-position-of-element-in-sorted-array 🌟🌟 35. 搜索插入位置 Search Insert Position 🌟 36. 有效的数独 Valid Sudoku 🌟🌟 🌟 每日一练刷题专栏 …...

Web前端:6种基本的前端编程语言
如果你想在前端web开发方面开始职业生涯,学习JavaScript是必须的。它是最受欢迎的编程语言,它功能广泛,功能强大。但JavaScript并不是你唯一需要知道的语言。HTML和CSS对于前端开发至关重要。他们将帮助你开发用户友好的网站和应用程序。什么…...
九【springboot】
Springboot一 Spring Boot是什么二 SpringBoot的特点1.独立运行的spring项目三 配置开发环境四 配置开发环境五 创建 Spring Boot 项目1.在 IntelliJ IDEA 欢迎页面左侧选择 Project ,然后在右侧选择 New Project,如下图2.在新建工程界面左侧,…...

《程序员成长历程的四个阶段》
阶段一:不知道自己不知道(Unconscious incompetence) 大学期间,我和老师做过一些小项目,自认为自己很牛,当时还去过一些公司面试做兼职,但是就是不知道为什么没有回复。那个时期的我,压根不知道自己不知道&…...

【SpringBoot】Spring data JPA的多数据源实现
一、主流的多数据源支持方式 将数据源对象作为参数,传递到调用方法内部,这种方式增加额外的编码。将Repository操作接口分包存放,Spring扫描不同的包,自动注入不同的数据源。这种方式实现简单,也是一种“约定大于配置…...

uni-app基础知识介绍
uni-app的基础知识介绍 1、在第一次将代码运行在微信开发者工具的时候,应该进行如下的配置: (1)将微信开发者工具路径进行配置; [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lbyk5Jw2-16790251840…...
Word2010(详细布局解释)
目录一、界面介绍二、选项卡1、文件选项卡(保存、打开、新建、打印、保存并发送、选项)2、开始选项卡(剪贴板、字体、段落、样式、编辑)3、插入选项卡(页、表格、插图、链接、页眉页脚、文本、符号)4、页面…...
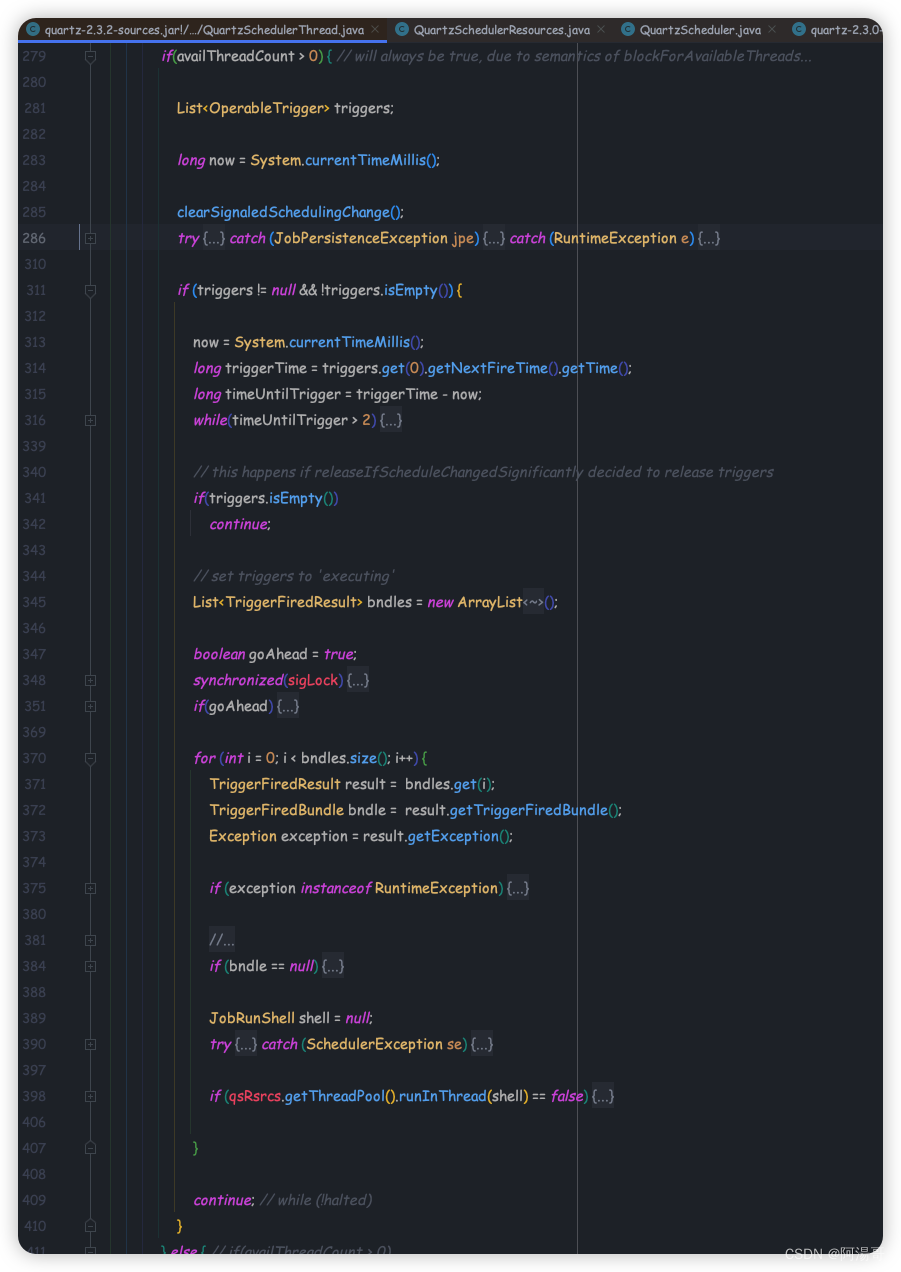
Spring如何实现Quartz的自动配置
Spring如何实现Quartz的自动配置1. 开启Quartz自动配置2. Quartz自动配置的实现过程2.1 核心类图2.2 核心方法3. 任务调度执行3.1 大致流程3.2 调整线程池的大小如果想在应用中使用Quartz任务调度功能,可以通过Spring Boot实现Quartz的自动配置。以下介绍如何开启Qu…...

计算机组成原理——作业四
一. 单选题(共11题,33分) 1. (单选题, 3分)四片74181 ALU和一片74182 CLA器件相配合,具有如下进位传递功能:________。 A. 行波进位B. 组内先行进位,组间行波进位C. 组内先行进位,组间先行进位D. 组内行波进位,组间先行进位 我的答案: C 3…...
)
2023前端面试题(经典面试题)
经典面试题Vue2.0 和 Vue3.0 有什么区别?vue中计算属性和watch以及methods的区别?单页面应用和多页面应用区别及优缺点?说说 Vue 中 CSS scoped 的原理?谈谈对Vue中双向绑定的理解?为什么vue2和vue3语法不可以混用&…...

【Linux内网穿透】使用SFTP工具快速实现内网穿透
文章目录内网穿透简介1. 查看地址2.局域网测试连接3.创建tcp隧道3.1. 安装cpolar4.远程访问5.固定TCP地址内网穿透简介 是一种通过公网将内网服务暴露出来的技术,可以使得内网服务可以被外网访问。以下是内网穿透的一些应用: 远程控制:通过内…...

航拍小目标检测入门必看:YOLOv8 VisDrone实战第一阶段,基线mAP从32%提升至58%
本文是YOLOv8 VisDrone航拍目标检测全系列实战的第一阶段,基于我3年智慧城市、无人机安防项目的一线落地经验,针对VisDrone航拍场景最核心的「小目标密集、尺度变化大、类别分布不均、遮挡严重」四大痛点,完整拆解从0到1搭建基线模型的全流程。 本文全程配套VisDrone数据集…...

内存检测从入门到精通:Memtest86+实战指南
内存检测从入门到精通:Memtest86实战指南 【免费下载链接】memtest86plus memtest86plus: 一个独立的内存测试工具,用于x86和x86-64架构的计算机,提供比BIOS内存测试更全面的检查。 项目地址: https://gitcode.com/gh_mirrors/me/memtest86…...

Qwen2-VL-2B-Instruct助力Java开发:智能代码注释与文档生成实战
Qwen2-VL-2B-Instruct助力Java开发:智能代码注释与文档生成实战 写Java代码最烦什么?对我来说,除了调试那些神出鬼没的Bug,就是写注释和文档了。明明代码逻辑自己一清二楚,但要把它转化成清晰、规范的文档,…...

PvZ Toolkit 技术指南:从游戏修改到体验重塑
PvZ Toolkit 技术指南:从游戏修改到体验重塑 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 价值定位:为什么选择 PvZ Toolkit? 当你在《植物大战僵尸》无尽模式…...
)
MySQL误删数据别慌!手把手教你用binlog2sql从ROW格式日志恢复(附常见报错解决方案)
MySQL数据恢复实战:从误删到完美还原的完整指南 凌晨三点,当大多数人都沉浸在梦乡时,数据库管理员小李却被一阵急促的电话铃声惊醒。生产环境的核心用户表被误操作清空,数百万条用户数据瞬间消失。这种场景对于任何DBA来说都是噩梦…...
)
告别模拟信号烦恼:手把手教你用51单片机驱动DAC0832输出正弦波(附Proteus仿真)
51单片机实战:用DAC0832打造完美正弦波发生器 在电子设计领域,能够精确生成模拟信号是一项基础却至关重要的技能。想象一下,当你亲手搭建的电路在示波器上显示出光滑的正弦波形时,那种成就感是无与伦比的。本文将带你从零开始&…...

从演唱会踩踏到交通拥堵:我们如何用无人机双光人群计数,为城市装上‘智慧之眼’?
无人机双光人群计数:城市安全管理的智能升级之路 当夜幕降临,体育场外数万观众正陆续离场,安保指挥中心的大屏上闪烁着红黄相间的热力图——这不是科幻电影的场景,而是某省会城市在明星演唱会后的真实一幕。通过部署在关键节点的1…...

uni-app微信小程序版本更新策略:冷启动与热启动的优化实践
1. 理解uni-app微信小程序的启动机制 开发过微信小程序的同行应该都遇到过这样的困扰:明明已经发布了新版本,但部分用户反馈看到的还是旧版内容。这种情况在uni-app开发的微信小程序中尤为常见,因为uni-app的编译机制和微信原生小程序存在一些…...

计算机毕业设计springboot鲜花在线商城 基于SpringBoot的园艺花卉网络销售系统 基于Java Web的线上花店订购管理平台
计算机毕业设计springboot鲜花在线商城911yt9 (配套有源码 程序 mysql数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联xi 可分享近年来,互联网技术的迅猛发展和智能终端设备的全面普及,为传统零售行业带来…...

告别ODX文件!用AUTOSAR AP的SOVD协议,5分钟搞懂服务化诊断怎么玩
告别ODX文件!用AUTOSAR AP的SOVD协议,5分钟搞懂服务化诊断怎么玩 如果你是一名嵌入式软件工程师或诊断工程师,一定对传统UDS诊断中繁琐的ODX文件配置深恶痛绝。每次ECU升级都要重新生成和分发ODX文件,版本管理混乱,工具…...