图像识别模型
一、数据准备
首先要做一些数据准备方面的工作:一是把数据集切分为训练集和验证集, 二是转换为tfrecord 格式。在data_prepare/文件夹中提供了会用到的数据集和代码。首先要将自己的数据集切分为训练集和验证集,训练集用于训练模型, 验证集用来验证模型的准确率。这篇文章已经提供了一个实验用的卫星图片分类数据集,这个数据集一共6个类别, 见下表所示
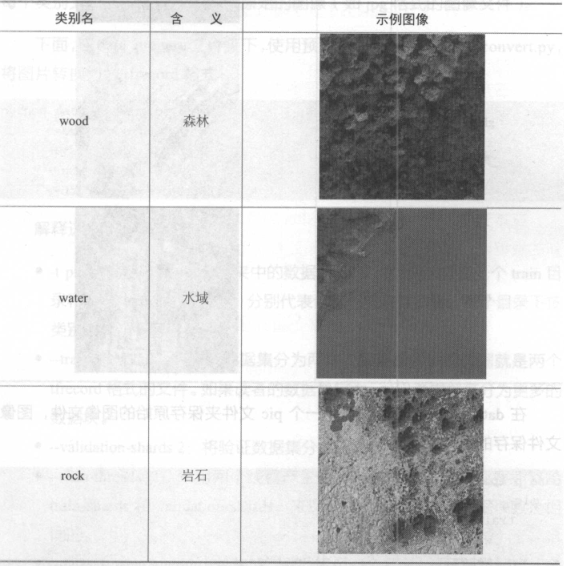
在data_prepare目录中,有一个pic文件夹保存原始的图像文件,这里面有train 和validation 两个子目录,分别表示训练使用的图片和验证使用的图片。在每个目录中,分别以类别名为文件夹名保存所有图像。在每个类别文件夹下,存放的就是原始的图像(如jpg 格式的图像文件)。下面在data_prepare 文件夹下,使用预先编制好的脚本data_convert .py,使用以下命令将图片转换为为tfrecord格式。
python data_convert.py
data_convert.py代码中的一些参数解释为:
# -t pic/: 表示转换pic文件夹中的数据。pic文件夹中必须有一个train目录和一个validation目录,分别代表训练和验证数据集。 #–train-shards 2:将训练数据集分成两块,即最后的训练数据就是两个tfrecord格式的文件。如果自己的数据集较大,可以考虑将其分为更多的数据块。 #–validation-shards 2: 将验证数据集分为两块。 #–num-threads 2:采用两个线程产生数据。注意线程数必须要能整除train-shaeds和validation-shards,来保证每个线程处理的数据块是相同的。 #–dataset-name satellite: 给生成的数据集起一个名字。这里将数据集起名叫“satellite”,最后生成的头文件就是staellite_trian和satellite_validation。
运行上述命令后,就可以在pic文件夹中找到5个新生成的文件,分别是两个训练数据和两个验证数据,还有一个文本文件label.txt ,其表示图片的内部标签(数字)到真实类别(字符串)之间的映射顺序。如图片在tfrecord 中的标签为0 ,那么就对应label.txt 第一行的类别,在tfrecord的标签为1,就对应label.txt 中第二行的类别,依此类推。
二、使用TensorFlow Slim微调模型
1、介绍TensorFlow Slim源码
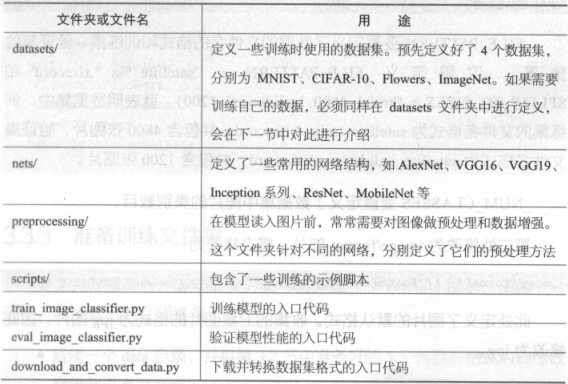
TensorFlow Slim 是Google 公司公布的一个图像分类工具包,它不仅定义了一些方便的接口,还提供了很多ImageNet数据集上常用的网络结构和预训练模型。截至2017 年7 月, Slim 提供包括VGG16 、VGG19 、InceptionVl ~ V4, ResNet 50 、ResNet 101, MobileNet 在内大多数常用模型的结构以及预训练模型,更多的模型还会被持续添加进来。如果需要使用Slim 微调模型,首先要下载Slim的源代码。Slim的源代码保存在tensorflow/models 项目中models/research/slim at master · tensorflow/models · GitHub。提供的代码里面已经包含了这份代码,在chapter3/slim目录下。下面简单介绍下Slim的代码结构,如下表所示:
2、定义新的datasets文件
在slim/datasets 中, 定义了所有可以使用的数据库,为了可以使用在前面中创建的tfrecord数据进行训练,必须要在datasets中定义新的数据库。首先,在datasets/目录下新建一个文件satellite.py,并将flowers.py 文件中的内容复制到satellite.py 中。接下来,需要修改以下几处内容:第一处是_FILE_PATTERN 、SPLITS_TO SIZES 、_NUM_CLASSES , 将其进行以下修改:
_FILE_PATTERN = 'satellite_%s_*.tfrecord'
SPLITS_TO_SIZES = { 'train' : 4800 , 'validation' : 1200 }
_NUM_CLASSES = 6
第二处修改image/format部分,将之修改为:
'image/format' tf.FixedLenFeature( (), tf. string, default_value = 'jpg' ),
此处定义了图片的默认格式。收集的卫星图片的格式为jpg图片,因此修改为jpg 。修改完satellite.py后,还需要在同目录的dataset_factory.py文件中注册satellite数据库。注册后dataset_factory. py 中对应代码为:
from datasets import cifar10
from datasets import flowers
from datasets import imagenet
from datasets import mnist
from datasets import satellite # 自行添加datasets_map = {'cifar10' : cifar10,'flowers' : flowers,'imagenet' : imagenet,'mnist' : mnist,'satellite' :satellite, # 自行添加
}
3、准备训练文件夹
定义完数据集后,在slim文件夹下再新建一个satellite目录,在这个目录中,完成最后的几项准备工作:
新建一个data目录,并将前面准备好的5 个转换好格式的训练数据(4个tfrecords文件和1个txt文件)复制进去。
新建一个空的train_dir 目录,用来保存训练过程中的日志和模型。
新建一个pretrained目录,在slim的GitHub页面找到Inception_V3 模型的下载地址,下载并解压后,会得到一个inception_v3 .ckpt 文件,将该文件复制到pretrained 目录下。
最后形成的目录如下所示:

4、开始训练
在slim 文件夹下,运行以下命令就可以开始训练了:
python train_image_classifier.py
train_image_classifier.py中部分参数解释如下:
# –trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits:首先来解释trainable_scope的作用,因为它非常重要。trainable_scopes规定了在模型中微调变量的范围。这里的设定表示只对InceptionV3/Logits,InceptionV3/AuxLogits 两个变量进行微调,其它的变量都不动。InceptionV3/Logits,InceptionV3/AuxLogits就相当于在VGG模型中的fc8,他们是Inception V3的“末端层”。如果不设定trainable_scopes,就会对模型中所有的参数进行训练。 # –train_dir=satellite/train_dir:表明会在satellite/train_dir目录下保存日志和checkpoint。 # –dataset_name=satellite、–dataset_split_name=train:指定训练的数据集。在3.2节中定义的新的dataset就是在这里发挥用处的。 # –dataset_dir=satellite/data: 指定训练数据集保存的位置。 # –model_ name=inception_v3 :使用的模型名称。 # –checkpoint_path=satellite/pretrained/inception_v3.ckpt:预训练模型的保存位置。 # –checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits : 在恢复预训练模型时,不恢复这两层。正如之前所说,这两层是InceptionV3模型的末端层,对应着ImageNet 数据集的1000 类,和当前的数据集不符, 因此不要去恢复它。 # –max_number_of_steps 100000 :最大的执行步数。 # –batch_size =32 :每步使用的batch 数量。 # –learning_rate=0.001 : 学习率。 # –learning_rate_decay_type=fixed:学习率是否自动下降,此处使用固定的学习率。 # –save_interval_secs=300 :每隔300s ,程序会把当前模型保存到train_dir中。此处就是目录satellite/train_dir 。 # –save_summaries_secs=2 :每隔2s,就会将日志写入到train_dir 中。可以用TensorBoard 查看该日志。此处为了方便观察,设定的时间间隔较多,实际训练时,为了性能考虑,可以设定较长的时间间隔。 # –log_every_n_steps=10: 每隔10 步,就会在屏幕上打出训练信息。 # –optimizer=rmsprop: 表示选定的优化器。 # –weight_decay=0.00004 :选定的weight_decay值。即模型中所有参数的二次正则化超参数。
但是经过笔者自己实验,发现在书上给出的下载地址下载的inception_v3.ckpt,会报出如下错误:DataLossError (see above for traceback): Unable to open table file satellite/pretrained/inception_v3.ckpt: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need touse a different restore operator?。如下图所示:

解决办法:文件错误,笔者选择从CSDN重新下载inception_v3.ckpt。这才能够训练起来。如下图所示是成功训练起来的截图

以上参数是只训练末端层InceptionV3/Logits, InceptionV3/AuxLogits, 还可以去掉–trainable_ scopes 参数。原先的–trainable_scopes= InceptionV3 /Logits ,InceptionV3/AuxLogits 表示只对末端层InceptionV3/Logits 和InceptionV3/AuxLogits 进行训练,去掉后就可以训练模型中的所有参数了。
5、训练程序行为
当train_image_classifier.py程序启动后,如果训练文件夹(即satellite/train_dir)里没有已经保存的模型,就会加载checkpoint_path中的预训练模型,紧接着,程序会把初始模型保存到train_dir中,命名为model.ckpt-0,0表示第0步。这之后,每隔5min(参数--save_interval_secs=300指定了每隔300s保存一次,即5min)。程序还会把当前模型保存到同样的文件夹中,命名格式和第一次保存的格式一样。因为模型比较大,程序只会保留最新的5个模型。
此外,如果中断了程序并再次运行,程序会首先检查train_dir中有无已经保存的模型,如果有,就不会去加载checkpoint_path中的预训练模型,而是直接加载train_dir中已经训练好的模型,并以此为起点进行训练。Slim之所以这样设计,是为了在微调网络的时候,可以方便地按阶段手动调整学习率等参数。
6、验证模型准确率
使用eval_image_classifier.py程序验证模型在验证数据集上的准确率,执行以下指令:
python eval_image_classifier.py
eval_image_classifier.py中部分参数解释如下
# –checkpoint_path=satellite/train_ dir: 这个参数既可以接收一个目录的路径,也可以接收一个文件的路径。如果接收的是一个目录的路径, # 如这里的satellite/train_dir,就会在这个目录中寻找最新保存的模型文件,执行验证。也可以指定一个模型验证,以第300步为例, # 如果要对它执行验证,传递的参数应该为satellite/train_ dir/model.ckpt-300 。 # –eval_dir=satellite/eval_dir :执行结果的曰志就保存在eval_dir 中,同样可以通过TensorBoard 查看。 # –dataset_name=satellite 、–dataset_split_name=validation 指定需要执行的数据集。注意此处是使用验证集( validation )执行验证。 # –dataset_dir=satellite/data :数据集保存的位置。 # –model_ name「nception_ v3 :使用的模型。
执行后,出现如下结果:
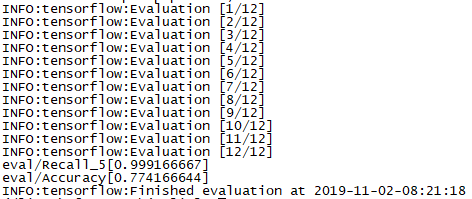
Accuracy表示模型的分类准确率,而Recall_5 表示Top 5 的准确率,即在输出的各类别概率中,正确的类别只要落在前5 个就算对。由于此处的类别数比较少,因此可以不执行Top 5 的准确率,换而执行Top 2 或者Top 3的准确率,只要在eval_image_classifier.py 中修改下面的部分就可以了:
# Define the metrics:
names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({'Accuracy' : slim.metrics.streaming_accuracy(predictions, labels),'Recall_5' : slim.metrics.streaming_recall_at_k(logits, labels, 5 ),
})
7、导出模型
训练完模型后,常见的应用场景是:部署训练好的模型并对单张图片进行识别。此处提供了freeze_graph.py用于导出识别的模型,classify_image_inception_v3.py是使用inception_v3模型对单张图片进行识别的脚本。导出模型:TensorFlow Slim提供了导出网络结构的脚本export_inference_graph.py 。 首先在 slim 文件夹下运行指令:
python export_inference_graph.py
这个命令会在 satellite 文件夹中生成一个 inception_v3_inf_graph.pb 文件 。
注意: inception_v3 _inf _graph.pb 文件中只保存了Inception V3 的网络结构,并不包含训练得到的模型参数,需要将checkpoint 中的模型参数保存进来。方法是使用freeze_graph. py 脚本(在chapter_3 文件夹下运行):在 项目根目录 执行如下命令(需将10085改成train_dir中保存的实际的模型训练步数)
python freeze_graph.py
freeze_graph.py中部分参数解释如下
#–input_graph slim/satellite/inception_v3_inf_graph.pb。表示使用的网络结构文件,即之前已经导出的inception_v3 _inf_gr aph.pb 。 #–input_checkpoint slim/satallite/train_dir/model.ckpt-10085。具体将哪一个checkpoint 的参数载入到网络结构中。 # 这里使用的是训练文件夹train _d让中的第10085步模型文件。我们需要根据训练文件夹下checkpoint的实际步数,将10085修改成对应的数值。 #input_binary true。导入的inception_v3_inf_graph.pb实际是一个protobuf文件。而protobuf 文件有两种保存格式,一种是文本形式,一种是二进制形式。 # inception_v3_inf_graph.pb 是二进制形式,所以对应的参数是–input_binary true 。初学的话对此可以不用深究,若有兴趣的话可以参考资料。 #--output_node_names 在导出的模型中指定一个输出结点,InceptionV3/Predictions/Reshape_1是Inception_V3最后的输出层 #–output_graph slim/satellite/frozen_graph.pb。最后导出的模型保存为slim/satellite/frozen_graph.pb 文件
最后导出的模型文件如下:

三、预测图片
如何使用导出的frozen_graph.pb文件对单张图片进行预测?此处使用一个编写的文件classify_image_inception_v3.py 脚本来完成这件事 。先来看这个脚本的使用方法:
python classify_image_inception_v3.py
classify_image_inception_v3.py中部分参数解释如下
# 一model_path 很好理解,就是之前导出的模型frozen_graph. pb 。 # –label_path 指定了一个label文件, label文件中按顺序存储了各个类别的名称,这样脚本就可以把类别的id号转换为实际的类别名。 # –image _file 是需要测试的单张图片。
脚本的运行结果应该类似于:
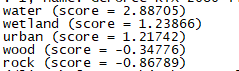
这就表示模型预测图片对应的最可能的类别是water,接着是wetland 、urban 、wood 等。score 是各个类别对应的Logit 。
四、TensorBoard 可视化与超参数选择
在训练时,可以使用TensorBoard 对训练过程进行可视化,这也有助于设定训练模型的方式及超参数。在slim文件夹下使用下列命令可以打开TensorBoard (其实就是指定训练文件夹):
tensorboard - - logdir satellite / train_dir
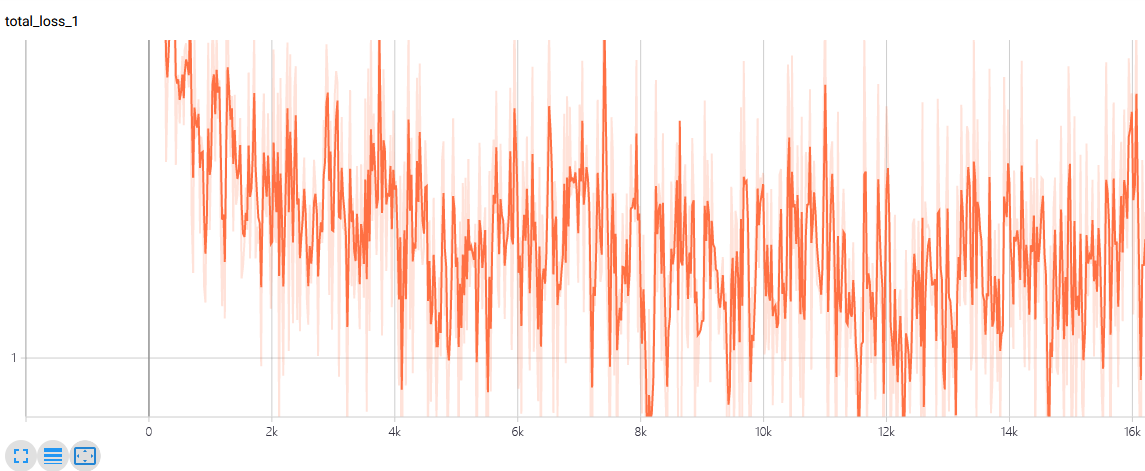
在TensorBoard中,可以看到损失的变化如上图 所示。观察损失曲线有助于调整参数。当损失曲线比较平缓,收敛较慢时,可以考虑增大学习率,以加快收敛速度;如果损失曲线波动较大,无法收敛,就可能是因为学习率过大,此时就可以尝试适当减小学习率。
另外,在上面的学习中,在笔者自己进行试验的过程中,一些小的错误就没有粘贴出来了,读者自行搜索即可得到解决方法。这篇博文主要来自《21个项目玩转深度学习》这本书里面的第三章,内容有删减,还有本书的一些代码的实验结果,经过笔者自己修改,已经能够完全成功运行。随书附赠的代码库链接为:GitHub - hzy46/Deep-Learning-21-Examples: 《21个项目玩转深度学习———基于TensorFlow的实践详解》配套代码。
相关文章:
图像识别模型
一、数据准备 首先要做一些数据准备方面的工作:一是把数据集切分为训练集和验证集, 二是转换为tfrecord 格式。在data_prepare/文件夹中提供了会用到的数据集和代码。首先要将自己的数据集切分为训练集和验证集,训练集用于训练模型…...
[零刻]EQ12 N100 迷你主机:从开箱到安装ESXi+虚拟机
开箱先上图:配置详情:EQ12采用了Intel最新推出的N100系列的处理,超低的功耗,以及出色的CPU性能用来做软路由或者是All in one 相当不错,CPU带有主动散热风扇,在长期运行下散热完全不用担心,性价…...

MongoDB基础
优质博客 IT-BLOG-CN 一、简介 MongoDB是一个强大的分布式文件存储的NoSQL数据库,天然支持高可用、分布式和灵活设计。由C编写,运行稳定,性能高。为WEB应用提供可扩展的高性能数据存储解决方案。主要解决关系型数据库数据量大,并…...

【Linux】Linux基本指令(下)
前言: 紧接上期【Linux】基本指令(上)的学习,今天我们继续学习基本指令操作,深入探讨指令的基本知识。 目录 (一)常用指令 👉more指令 👉less指令(重要&…...
基于uniapp+u-view开发小程序【技术点整理】
一、上传图片 1.实现效果: 2.具体代码: <template><view><view class"imgbox"><view>职业证书</view><!-- 上传图片 --><u-upload :fileList"fileList1" afterRead"afterRead"…...
)
投稿指南【NO.7】目标检测论文写作模板(初稿)
中文标题(名词性短语,少于20字,尽量不使用外文缩写词)张晓敏1,作者1,2***,作者2**,作者2*(通信作者右上标*)1中国科学院上海光学精密机械研究所空间激光传输与探测技术重…...
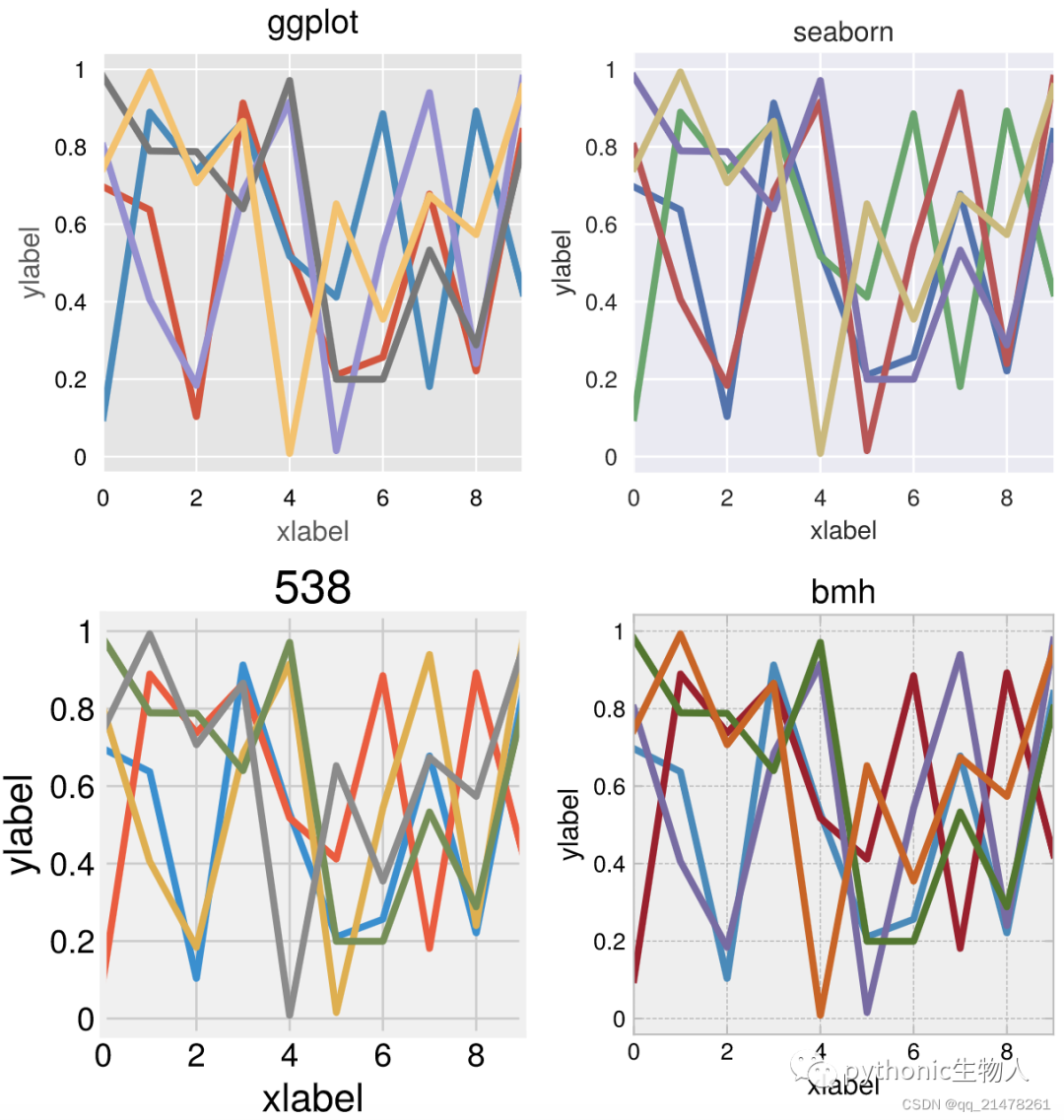
【绘图】比Matplotlib更强大:ProPlot
✅作者简介:在读博士,伪程序媛,人工智能领域学习者,深耕机器学习,交叉学科实践者,周更前沿文章解读,提供科研小工具,分享科研经验,欢迎交流!📌个人…...

经典七大比较排序算法 ·上
经典七大比较排序算法 上1 选择排序1.1 算法思想1.2 代码实现1.3 选择排序特性2 冒泡排序2.1 算法思想2.2 代码实现2.3 冒泡排序特性3 堆排序3.1 堆排序特性:4 快速排序4.1 算法思想4.2 代码实现4.3 快速排序特性5 归并排序5.1 算法思想5.2 代码实现5.3 归并排序特性…...

【网络安全工程师】从零基础到进阶,看这一篇就够了
学前感言 1.这是一条需要坚持的道路,如果你只有三分钟的热情那么可以放弃往下看了。 2.多练多想,不要离开了教程什么都不会,最好看完教程自己独立完成技术方面的开发。 3.有问题多google,baidu…我们往往都遇不到好心的大神,谁…...
素描-基础
# 如何练习排线第一次摸板子需要来回的排线,两点然后画一条线贯穿两点画直的去练 练线的定位叫做穿针引线法或者两点一线法 练完竖线练横线 按照这样去练顺畅 直线曲线的画法 直线可以按住shift键 练习勾线稿 把线稿打开降低透明度去勾线尽量一笔的去练不要压…...
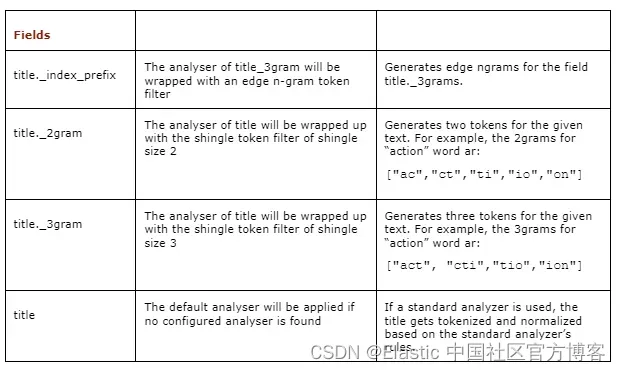
Elasticsearch:高级数据类型介绍
在我之前的文章 “Elasticsearch:一些有趣的数据类型”,我已经介绍了一下很有趣的数据类型。在今天的文章中,我再进一步介绍一下高级的数据类型,虽然这里的数据类型可能和之前的一些数据类型有所重复。即便如此,我希望…...

Golang每日一练(leetDay0012)
目录 34. 查找元素首末位置 Find-first-and-last-position-of-element-in-sorted-array 🌟🌟 35. 搜索插入位置 Search Insert Position 🌟 36. 有效的数独 Valid Sudoku 🌟🌟 🌟 每日一练刷题专栏 …...

Web前端:6种基本的前端编程语言
如果你想在前端web开发方面开始职业生涯,学习JavaScript是必须的。它是最受欢迎的编程语言,它功能广泛,功能强大。但JavaScript并不是你唯一需要知道的语言。HTML和CSS对于前端开发至关重要。他们将帮助你开发用户友好的网站和应用程序。什么…...
九【springboot】
Springboot一 Spring Boot是什么二 SpringBoot的特点1.独立运行的spring项目三 配置开发环境四 配置开发环境五 创建 Spring Boot 项目1.在 IntelliJ IDEA 欢迎页面左侧选择 Project ,然后在右侧选择 New Project,如下图2.在新建工程界面左侧,…...

《程序员成长历程的四个阶段》
阶段一:不知道自己不知道(Unconscious incompetence) 大学期间,我和老师做过一些小项目,自认为自己很牛,当时还去过一些公司面试做兼职,但是就是不知道为什么没有回复。那个时期的我,压根不知道自己不知道&…...

【SpringBoot】Spring data JPA的多数据源实现
一、主流的多数据源支持方式 将数据源对象作为参数,传递到调用方法内部,这种方式增加额外的编码。将Repository操作接口分包存放,Spring扫描不同的包,自动注入不同的数据源。这种方式实现简单,也是一种“约定大于配置…...

uni-app基础知识介绍
uni-app的基础知识介绍 1、在第一次将代码运行在微信开发者工具的时候,应该进行如下的配置: (1)将微信开发者工具路径进行配置; [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lbyk5Jw2-16790251840…...
Word2010(详细布局解释)
目录一、界面介绍二、选项卡1、文件选项卡(保存、打开、新建、打印、保存并发送、选项)2、开始选项卡(剪贴板、字体、段落、样式、编辑)3、插入选项卡(页、表格、插图、链接、页眉页脚、文本、符号)4、页面…...
Spring如何实现Quartz的自动配置
Spring如何实现Quartz的自动配置1. 开启Quartz自动配置2. Quartz自动配置的实现过程2.1 核心类图2.2 核心方法3. 任务调度执行3.1 大致流程3.2 调整线程池的大小如果想在应用中使用Quartz任务调度功能,可以通过Spring Boot实现Quartz的自动配置。以下介绍如何开启Qu…...

计算机组成原理——作业四
一. 单选题(共11题,33分) 1. (单选题, 3分)四片74181 ALU和一片74182 CLA器件相配合,具有如下进位传递功能:________。 A. 行波进位B. 组内先行进位,组间行波进位C. 组内先行进位,组间先行进位D. 组内行波进位,组间先行进位 我的答案: C 3…...

原创:光刻机中下游质量约束框架:从底层落地破局芯片制造困局
光刻机中下游质量约束框架:从底层落地破局芯片制造困局 作者:华夏之光永存 摘要 当下国内芯片产业陷入一个普遍误区:将攻克EUV光刻机整机视为破局“卡脖子”的唯一核心,大量资源集中投入上游光刻机研发,却严重忽视中下…...

Marp CLI元数据管理:如何优化SEO和社交媒体分享
Marp CLI元数据管理:如何优化SEO和社交媒体分享 【免费下载链接】marp-cli A CLI interface for Marp and Marpit based converters 项目地址: https://gitcode.com/gh_mirrors/ma/marp-cli Marp CLI是一款强大的命令行工具,让你仅用纯Markdown就…...

CTF逆向实战:从RC4到Base64,手把手拆解CTFshow赛题
1. RC4加密实战:从文件分析到密钥破解 第一次接触CTF逆向题时,看到RC4加密可能会觉得无从下手。但实际拆解后你会发现,这类题目往往藏着明显的突破口。就拿CTFshow这道re2赛题来说,整个解题过程就像在玩解谜游戏。 用IDA打开题目…...

从零开始!DeepSeek-R1-Distill-Qwen-1.5B完整部署流程详解
从零开始!DeepSeek-R1-Distill-Qwen-1.5B完整部署流程详解 1. 模型简介与核心优势 1.1 什么是DeepSeek-R1-Distill-Qwen-1.5B? DeepSeek-R1-Distill-Qwen-1.5B是一款经过知识蒸馏优化的轻量级语言模型,由DeepSeek团队基于Qwen-1.5B架构开发…...
数码管显示)
51单片机学习(五)数码管显示
如有大佬发现我文章里的错误,希望多多指出,或者有缺少的也欢迎告诉我,我会尽快补充上去的,感谢各位的支持,要互三的d我哦!一.数码管数码管显示屏和U4 74HC245U574H138译码器一位数码管引脚定义一个数码管由…...

Layerdivider:零基础上手图像分层工具的完整指南
Layerdivider:零基础上手图像分层工具的完整指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 为什么自动分层总是不尽如人意?设…...
)
保姆级教程:用CST 2023的RLC求解器搞定空心电感仿真(附网格优化技巧)
从零到精通的CST空心电感仿真实战指南:RLC求解器与网格优化全解析 在电磁兼容设计和高频电路开发中,空心电感作为无磁芯干扰的理想元件,其精确建模一直是工程师的痛点。传统手工计算难以应对复杂的高频效应,而商业仿真软件的门槛…...

【AI知识点】交叉注意力机制:连接不同世界的“信息桥梁”
1. 从"信息桥梁"理解交叉注意力机制 想象你正在同时阅读一本英文书和它的中文翻译版。当你遇到一个不太理解的英文句子时,会自然地在中文版本中寻找对应的段落来帮助理解——这个过程就像交叉注意力机制在神经网络中的工作方式。它就像是架设在两个不同世…...
LumiPixel开箱即用教程:快速上手这个专为人像设计的AI创作平台
LumiPixel开箱即用教程:快速上手这个专为人像设计的AI创作平台 1. 认识LumiPixel:纯净人像创作平台 LumiPixel: Canvas Quest是一款专注于人像创作的AI视觉平台,它将先进的Z-Image扩散模型与复古像素艺术美学完美结合。这个平台特别适合需要…...

Wan2.1视频生成小白必看:避开这些坑,让你的视频生成一次成功
Wan2.1视频生成小白必看:避开这些坑,让你的视频生成一次成功 1. 为什么你的视频生成总是失败? 很多新手第一次使用Wan2.1视频生成模型时,都会遇到各种问题:生成的视频模糊不清、内容与描述不符、甚至直接失败。这通常…...