初识linux之管道
一、进程间通信的概念
大家都知道,进程是具有独立性的,因为一个程序运行起来生成进程时,也会生成它的进程结构体,即PCB,然后然后通过进程结构体中的结构体指针找到它的虚拟地址空间,然后再通过它的页表映射到物理地址空间上。既然进程具有独立性,那就意味着,如果想完成进程间通信,就一定伴随着较大的代价。
概念
一般来讲,进程间通信主要用于四个方面。
(1)数据传输:一个进程需要将自己的数据发送给另一个进程
(2)资源共享:多个进程共享同样的资源。即在内存中有一块空间,这块空间上的数据被多个进程共同使用。
(3)通知事件:一个进程需要另一个或另一组进程发送消息,通知它们发生了某个事件(如子进程终止时要通知父进程,让父进程回收它的退出信息)。
(4)进程控制:有些进程希望完全控制另一些进程的执行(如调试时就是让debug进程控制我们写的程序运行起来生成的进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态的改变。
进程间通信出现的原因
进程间通信虽然需要付出较大代价,但是在某些时候是必须要使用到进程间通信的。现在大家写的程序一般都是单进程的,例如在大家平时写代码时,几乎不会用到fork()去创建子进程完成某种需求。但是,在未来,我们写的程序很多都是需要多进程协同的。例如在linux中输入“cat file | grep 'hello'”命令,该命令会读取file文件中的数据,然后根据“hello”关键字进行筛选。这里面的“|”其实是一个“管道”,用于连接两个进程。
进程间通信的方案经过多年的发展,已经有了对应的标准。现在比较知名的标准就是“POSIX”和“System V”。
这两套标准中,“POSIX”可以让通信过程跨主机。而“System V”聚焦与本地通信。但是,在现在物联网快速发展的时代,很多时候都是需要跨主机通信的,而“System V”只能用于单主机本地通信的特点就导致这套标准的使用越来越少,主流都是使用“POSIX”标准。但是这并不代表“System V”没人使用,只是使用的地方很少而已。
“System V”无法跨主机通信是因为在linux下一切皆文件,而文件系统管理文件时主要依靠的就是文件描述符。但是“System V”出现的太早了,这就导致“System V”的内部接口虽然和文件有关,但是在使用时和文件描述符没有关系,导致“System V”在跨主机通信时与其他主机很难兼容,导致难以使用。而现在的主流标准的接口都是与文件描述符密切相关的,使其在跨主机时也能够很好的使用。
二、管道
管道是基于文件系统形成的。与上面的“POSIX”和“System V”标准没有关系。在这里,首先来了解管道。
管道分为匿名管道和命名管道两种
管道的概念
管道是linux中最古老的的进程间通信方式,把从一个进程链接到另一个进程的数据流称为“管道”。
管道的执行方式
如果现在运行一个程序,那么该程序就会生成一个task_struct,即进程结构体。然后我们再打开一个文件,该文件也会在内存中生成它的文件对象struct_file。如果这个进程要找到对应打开的文件,就要通过在它们之间的文件描述表struct files_strcut中保存的文件描述符来找到对应的文件位置。而在在这个文件描述符表中有一个“struct file *fd array[]”数组,这个数组里面就存储了文件描述符。
在系统运行时,文件描述表中默认有标准输出流、标准输入流和标准错误流占据了0,1,2三个位置。假设进程打开的文件在下标为3的位置,那么进程要访问打开的文件,就是到文件描述符表中的下标3的位置拿到文件对象的地址,然后到对应的位置上去找到文件:

如果此时当前进程生成了一个子进程,那么该子进程就会拷贝一份父进程的pcb,继承父进程的数据,其中就包括文件描述符表。但是并不会拷贝一份文件对象。子进程的文件描述符表是拷贝的父进程的,因此子进程也可以通过自己的文件描述符表找到同一个文件对象。此时,子进程和父进程就可以同时访问同一个文件对象了。
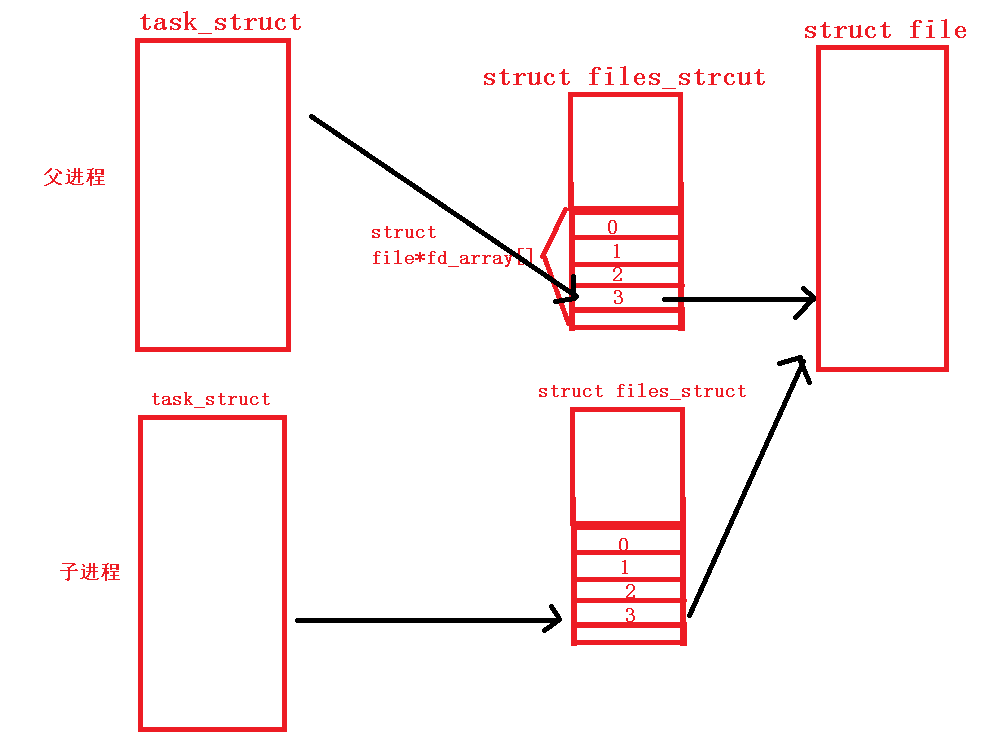
通过上面的父子进程打开同一个文件的例子,就可以推导出进程间通信的原理了。说白了,进程间通信就是不同的进程之间有一个共享内存空间,不同的进程都可以向这个共享空间中读写数据。
这个共享空间是由操作系统通过直接或间接的方向通信双方的进程提供。因为进程具有独立性,如果这个共享空间由某个进程提供,就会导致这块空间被进程私有,其他进程无法访问。
因此,进程间通信的本质就是“让不同的进程看到同一份公共资源”。而在实际说的各种不同的通信方式,其实就是指这块由操作系统提供的公共资源来源于哪一个模块。如果这份资源来源于文件系统,就叫做管道通信;如果来源于“System V”提供,就叫做“System V”通信,如果是一大块内存,就叫做共享内存。当然,通信方式不止这几个,但是其本质都是一样的,即让不同的进程看到同一份公共资源。
匿名管道
3.1匿名管道的概念
再说回上面的父子进程例子。在这个例子中,父子进程可以同时看到同一个文件对象,此时就满足了通信的让不同进程看到同一份共享资源”必要条件。同时我们知道,一个文件对象中必然包含两个东西,即文件的操作方法和内核缓冲区。操作方法这里不重要,重要的是内核缓冲区。在父子进程看到同一个文件对象的情况下, 父进程向内核缓冲区中发送数据,子进程再从内核缓冲区中读取数据。
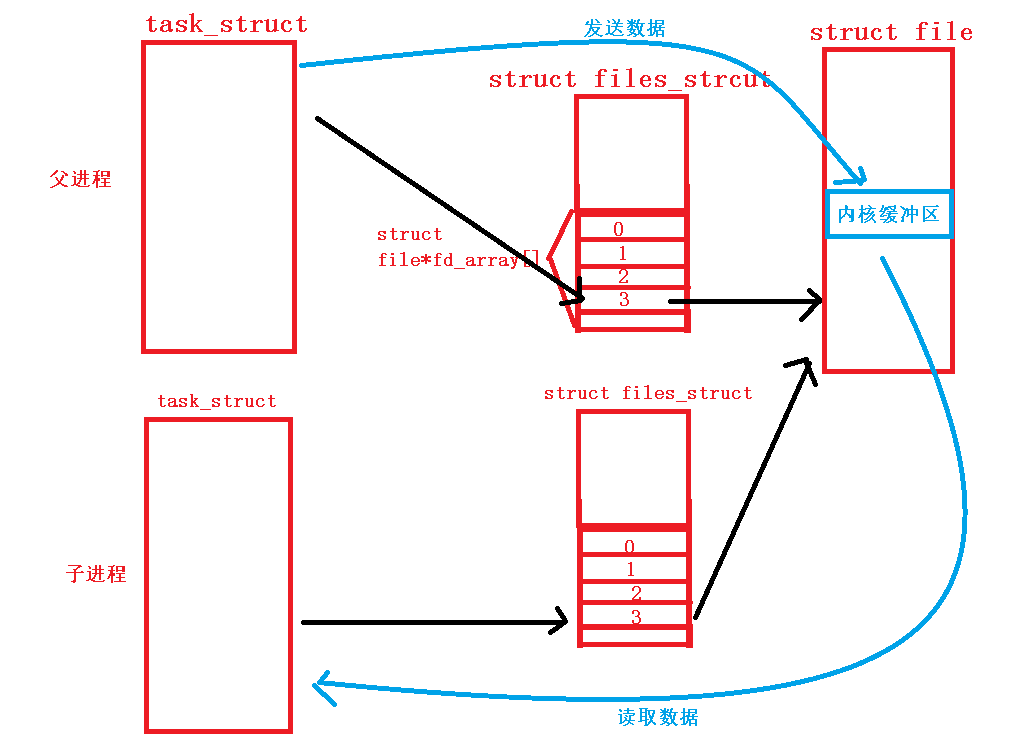
一个进程从文件中读数据,一个进程从文件中读数据,这个过程就完成了一次进程间通信。而这种使用文件的方式来完成父子的进程间通信的方法,就叫做“管道”。而这个由文件系统所提供的文件就叫做“管道文件”,是一个内存级文件。
内存级文件与普通文件不同。普通文件存在于磁盘上,当打开一个文件时,需要从磁盘中读取该文件的数据,并在内存创建它的文件对象。而内存级文件在磁盘上并不存在,它是由操作系统创建的,操作系统会自动帮该文件生成对应的文件对象和申请内核缓冲区,在内存级文件中的数据无需传输到磁盘上,而是直接在内存中。
管道文件是用于进程间通信的,它上面的数据需要从一个进程发送到另一个进程上去,属于内存向内存传输数据。如果还是采用普通文件的方式,进程发送的数据先发送到磁盘的文件中,然后另一个进程再从文件上将数据从磁盘读取到内存中,很明显,这样效率太慢了。因此,管道文件是一个内存级文件,它并不存在与磁盘,而是存在于内存中,直接为通信进程双方提供内存间的数据传输。
那么如何让两个进程看到同一个管道文件呢?很简单,父进程先打开一个管道文件,此时该管道文件的文件描述符就会被存到父进程的文件描述符表中。然后生成一个子进程,该子进程会继承父进程的pcb,包括文件描述符表。此时,父子进程就可以通过自己的文件描述表找到同一个管道文件了。
我们要找到一个文件都是通过文件名来找到的。就好比你要找人,都是通过他的名字来找到他的。那么这个管道文件叫什么名字呢?实际上,管道文件没有名字,我们把这种使用没有名字的管道文件的通信方式,叫做“匿名管道”。父子进程都是通过文件描述符表中存的地址找到管道文件的。就好比你有一个同学,你不知道他的名字,但是你知道他的家庭住址,你可以通过家庭住址找到他。
3.2从文件描述符上理解管道
管道文件要用于不同进程间传输数据,就说明它需要能够同时以读写方式打开。因为如果父进程仅仅以读或写的方式打开,那么子进程继承后也只能以读或写方式打开,就无法满足传输数据的需要。
因此,管道文件在创建后,一般都是以读写方式打开的,然后再用不同的文件描述符标定读写方式,再将文件描述符写到父进程的文件描述符表中:

当父进程的文件描述表中有管道文件的文件描述表后,子进程继承下来后也会有管道文件的文件描述符:

但是要注意,如果此时父子进程对管道文件的读端和写端都同时打开,就可能导致传输不明确。父子进程不知道这份数据是由谁读或由谁写的。因此,在管道中,一般都只允许单向通信。即父进程读子进程写或子进程读父进程写。当确定好数据传输方向后,就需要将父子进程中对应的另一端关闭。假如此时是父进程写,子进程读,那么父进程中的读端和子进程中的写端都需要关闭。当然,并不是必须关闭,但是为了防止意外使用到另一端,因此还是建议关闭。

如果想双向通信,就需要再建立另一个管道,利用第二个管道进行反向通信。
同时,上面一直都在说,子进程可以看到管道文件的原因是继承了父进程的文件描述表。同时这个匿名管道的管道文件是没有名字的,因此如果一个进程没有继承到另一个进程的文件描述符表,就无法用管道通信。换句话说,“匿名管道只能用于父子进程通信”。
3.3匿名管道通信
当我们创建管道文件,让父子进程可以看到这个管道文件并关闭对应的读写端使得父子进程可以单向通信后,其实这时候还没有开始进程通信。因为此时仅仅是完成了“让不同进程看到同一份共享资源”这件事,而实际通信还没有开始,只是做好了通信的准备。而实际的通信,是需要在对应的情景下实现的。
3.3.1创建管道文件
上面说过,管道文件是一个内存级文件,是由操作系统创建的,因此无法通过直接创建文件的方式形成,而是需要使用“pipe()”函数:
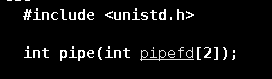
这个函数用于创建一个管道文件,它的参数是一个输出型参数。用于接收管道文件的文件描述符。上文也说过了,一个管道需要同时以读写方式打开,所以会返回两个文件描述符,一个表示读端,一个表示写端。pipefd[2]就是用于接收文件描述符的。
再来看看这个函数的返回值:

可以看到,该函数成功返回0,失败则返回-1。
了解了返回值后,还有一个问题。就是它的参数是一个输出型参数,会返回两个文件描述符。那么这两个文件描述符谁是读端谁是写端呢?查看它的函数说明:

从函数说明中可以看到上面的描述。翻译过来就是输出的数组的0下标上存储的是读端,1下标处是写端。有了以上的了解,就可以实现进程间通信的第一步:创建管道文件了:
3.3.2创建子进程
要创建一个子进程很简单,直接调用fork()函数即可。该函数会创建一个子进程,并将子进程的进程pid返回给父进程,然后将0返回给子进程。在子进程结束后,需要调用waitpid()函数进行等待,回收子进程的退出信息和资源

第一个参数是要等待的进程的pid,第二个参数是保存进程的退出信息,如果没有获取进程退出信息的需求,设置为nullptr即可。第三个参数是提供了另一些选项来控制pid的行为,如果没有需求,填为0即可。在成功时返回要等待的进程的pid
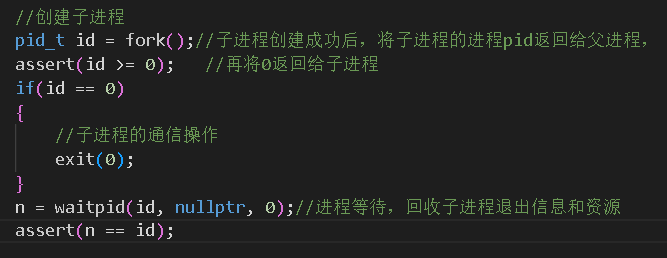
3.3.3父子进程通信
在这里,就让子进程写入,父进程读取来演示。
要让子进程写入,父进程读取,首先就要关闭子进程中的读端和父进程中的写端。为了方便实验,这里就让子进程每隔1s向管道文件中写入一个字符串,然后让父进程从管道文件中读取。

运行该程序:

此时就会出现如上信息。要知道,在上面的程序中,子进程是没有进行任何输出的,父进程也仅仅只是在从buffer中获取从管道上接受的数据。但是却打印了如上的内容,这也就说明此时父子进程是成功进行了通信的。

当父子进程进行通信时,其实就是如上图所示的方案。子进程用write()向共享资源中写入数据,然后父进程再通过read()函数从管道中获取数据。
管道的读写特征
因为这里还没有将命名管道,所以就以匿名管道为例。首先来看以下程序:

在这个程序里面进行了父子进程的进程间通信,子进程每隔1s向管道中写入数据。父进程则不间断地从管道中读取数据。
下面讲的所有特征,都是以上面的代码修改来演示的。
4.1读端进程无数据可读时会默认阻塞
如果管道中没有数据并且读端在读,默认会直接阻塞当前正在读的进程。
以上图原代码为例,运行上面的程序:
会得到以上结果。结果不重要,因为父子进程进行了进程间通信,结果在预料之中。但是,当父进程在读取数据时,它的读取速度和子进程写入的速度是一样的。换句话说就是,子进程写一句,父进程读一句。原因很简单,在上面的程序中,子进程写完后就会休眠1s。而在子进程休眠的过程中,父进程将管道内的数据读取完后就没有数据可读了。此时,管道内没有数据,读端却依然在读,操作系统就会将该进程放入对应文件的等待队列中进行等待,并将该进程的进程状态由“R”改为“S”。
将子进程的休眠时间改为10s,并将父进程的代码修改如下:

运行该程序:

运行程序后,每隔10s才会打印一次数据,而不是循环打印“正常读取”和“等待结束”两句话。这也就证明了当管道中没有数据时,读端的进程并不会循环运行,而是会被操作系统识别,然后被操作系统放入对应文件的等待队列,当文件中有数据时,操作系统就会将进程从等待队列中提取出来,将状态从S改为R,让其继续读取数据。
4.2写端满时阻塞
管道文件其实是一个固定大小的缓冲区,是会被写满的。如果写端向管道中写满了,此时再写就会发生阻塞,写端的进程就不会再继续写入,而是等待读端读取数据,当数据被读取走后再重新写入。
在子进程代码中删除sleep()并打印“cnt”记录,然后让父进程休眠1000s。然后运行该程序:

可以看到,当子进程的计数打印到834时就不再打印了。原因就是此时管道中已经被写满了,子进程阻塞,不再运行,等待读端读取数据后再写入。
这一机制的作用是为了保护数据。因为在某些情况下,写端写入数据的速度可能比读端快,此时可能导致管道被写满了但读端还没有读取数据。如果此时不停下继续写,就可能导致已经写入的数据被覆盖,进而出现数据丢失的情况。
注意,读端读取数据时,并不是按照写端写入数据的格式来读取的。例如写端一行行的写入数据,但是读端并不会一行一行的读取数据,而是一次性读取读端所规定的字节数。修改子进程代码,让子进程不间断写入数据,然后让父进程每隔2s读取数据。运行程序:

如上图所示,程序中对读端的限制是一次读取1023个数据,因此, 当要读取数据时,就是一次性读取1023个字符,而不是根据写端一行行的写入来读取。
4.3写端关闭,管道数据读取完后读端会读取的字符个数为0
如果写端在写数据的过程中,将写端关闭了,此时管道中就不会再新增数据。如果写端仅仅只是写的慢点,读端可以继续等待。但是如果读端已经关闭,就没有等待写入的必要了。此时就可以结束读取了。在子进程代码中加上break,并在父进程中加上s = 0的判断条件:


运行程序:

当管道内没有数据时且写端关闭后,读端就会结束读取。当然,这里程序还没有结束时因为子进程在休眠100s,父进程需要等待子进程结束回收子进程资源。这个特性很好理解。
4.4读端关闭,写端也会自动关闭
管道是单向通信,如果读端被关闭,就说明此时没有进程再需要读取数据。既然已经没有进程要读取数据,那么此时就算写端继续写入数据也没有意义。因此,当读端关闭后,操作系统会检测到这一行为,然后操作系统就会给写端发送信号,终止写端。
修改代码,让子进程每隔1s写入一次数据,让父进程在读取一次后就退出并关闭读端:
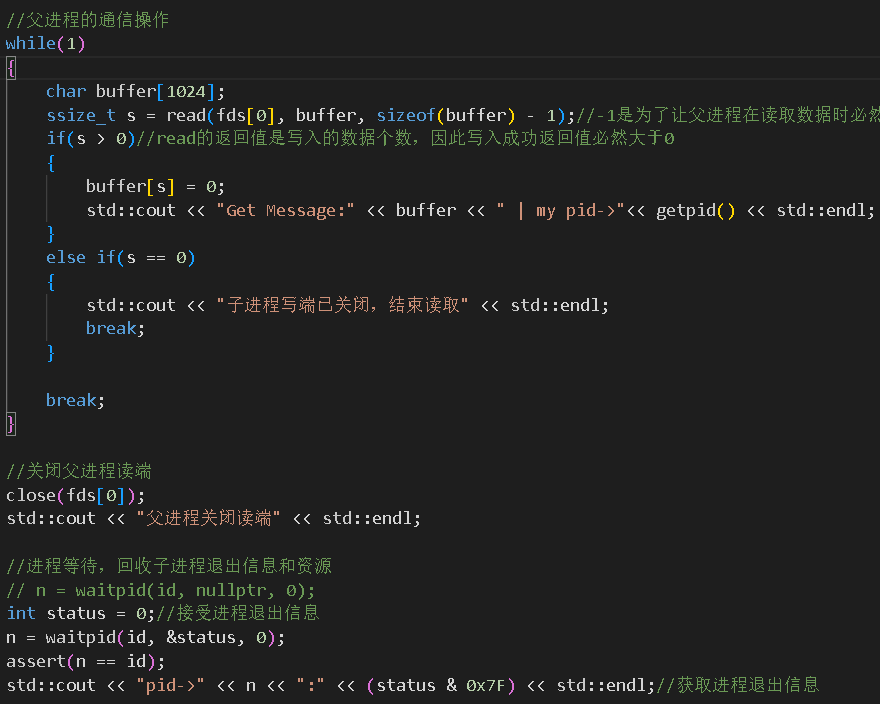
运行程序:

运行起来后可以看到,虽然子进程在一直写数据,但是父进程在读取一次数据后就退出了。且退出信号为13。
输入“kill -l”命令查看信号:

13号信号的名字是SIGPIPE。这就是说当写端未关闭,读端关闭时,操作系统就会将13号进程发给运行写端的进程,终止写入。
管道的特征
(1)管道的生命周期随进程。管道是基于文件的,如果执行读端和写端的进程都关闭了,那么管道也会被自动关闭然后释放
(2)管道可以用与具有血缘关系的进程之间的进行通信。例如子进程的子进程也是可以与它的父进程及它父进程的父进程进行通信的,子进程也可以和具有继承自同一个父进程的子进程通信。原因就是子进程继承父进程时会继承父进程的文件描述符表,里面就有管道文件的读写端位置。
(3)管道是面向字节流(网络)的。
(4)半双工——单向通信。半双工指的是一个时刻只允许一个进程向另一个进程发送消息。单向通信是半双工的特殊概念。
(5)互斥与同步机制(对共享资源进行保护的方案)。
使用管道实现用一个进程控制另外的几个进程的代码实现
现在我们只了解了匿名管道,并且通过上面的代码实现也初步了解到了如何使用管道完成父子进程的通信。接下来,我们就使用匿名管道来实现用一个进程控制其他的几个进程完成不同的操作。当然,这里也只是个demo代码,仅仅只是用于演示可以通过管道用一个进程控制其他进程。
在这个程序中,我们要让父进程创建4个子进程,每个子进程中都有一个对应的管道文件,父进程作为写端,子进程作为读端。当父进程没有向子进程的管道中写入数据时,子进程处于阻塞状态,等待数据写入。父进程会向任一子进程随机传入一个4字节的操作码。例如向2号子进程传输1操作码,2号进程就要对应的去找1操作码对应的操作。
以下就是整个程序的示意图:

在实现这个程序之前,先来梳理一下实现思路。
(1)要让父进程控制子进程,那么就要创建一个CreateSubProcess()函数,用于生成管道文件和创建子进程;
(2)父进程要控制子进程,那么就需要拿到子进程的进程pid和与子进程相对应的管道文件的写端描述符。因此创建一个SubEp类,里面用于存储子进程的pid和对应管道文件的写端描述符;
(3)既然子进程要执行任务,就要将任务准备好。为了便于演示,可以写几个打印函数来充当任务;
(4)任务创建好后,就要开始给子进程分配任务。为了便于分配,创建一个vector类,里面存储任务的函数指针,便于父进程直接使用类中的数据来分配任务;
(5)要给子进程分配任务很简单,将对应的任务的任务码通过管道发送给子进程即可,任务码可以用vector内的下标来标识;
(6)当父进程结束后,标识写端关闭,此时read()读到0,使子进程的循环结束退出,然后回收资源和退出信息即可。代码如下:
#include<iostream>
#include<unistd.h>
#include<cassert>
#include<stdlib.h>
#include<string>
#include<ctime>
#include<vector>
#include<sys/types.h>
#include<sys/wait.h>#define PROCESS_NUMS 5
//种随机数种子。因为rand()虽然可以生成随机数,但是需要依赖srand来初始化。必须要先将srand()的参数中放入随机数
//rand()函数才能返回随机数。否则rand()默认生成随机数1,且每次都是相同的
#define MakeSeed() srand((unsigned long)time(nullptr) ^ getpid() ^ rand() % 15643)子进程所需完成的任务//
typedef void(*func_t)();//对一个返回值为void,没有参数的函数指针重名名func_tvoid DownLoadTask()
{std::cout << getpid() << ":下载任务" << std::endl;sleep(1);
}
void IoTask()
{std::cout << getpid() << ":io任务" << std::endl;sleep(1);
}
void FlushTask()
{std::cout << getpid() << ":刷新任务" << std::endl;sleep(1);
}void LoadTaskFunc(std::vector<func_t>& FuncMap)//将子进程需要执行的方法的地址加载到vector中以供父进程使用
{FuncMap.push_back(DownLoadTask);FuncMap.push_back(IoTask);FuncMap.push_back(FlushTask);
}/父进程与子进程交互
class SubEp
{
public:SubEp(pid_t subId, int writeFd): _subId(subId), _writeFd(writeFd){char nameBuffer[1024];snprintf(nameBuffer, sizeof(nameBuffer), "process-%d[pid(%d)-fd(%d)]", _num++, _subId, _writeFd);_name = nameBuffer;}public://这里设置为public只是不想写对应的ger函数,有兴趣的可以自己写以下static int _num;//记录子进程个数std::string _name;//子进程名字pid_t _subId;//子进程pidint _writeFd;//保存该子进程对应的写端以提供给父进程使用
};
int SubEp::_num = 0;int recvTask(int fd)//从管道中读取任务码
{int code = 0;ssize_t s = read(fd, &code, sizeof(code));if(s == 4) return code;else if(s <= 0)return -1;else return -1;
}void SendTask(const SubEp& process, int taskNum)//将任务码发送到指定子进程的管道文件中
{std::cout << "task num:" << taskNum << " send to -> " << process._name << std::endl;//打印信息,以表示发送成功int n = write(process._writeFd, &taskNum, sizeof(taskNum));assert(n == sizeof(int));(void)n;
}//创建子进程,并将子进程的pid和写端文件描述符写入subs类中以供父进程使用
void CreateSubProcess(std::vector<SubEp>* subs, std::vector<func_t>& FuncMap)
{std::vector<int> deleteFd;//存储父进程的文件描述表中的子进程的写端描述符for(size_t i = 0; i < PROCESS_NUMS; ++i){int fds[2];int n = pipe(fds);//创建管道文件,创建成功返回0assert(n == 0);(void)n;//assert在release环境下不会生效,为了避免编译器认为变量n生成了但没有使用,于是在此随意使用一次pid_t id = fork();//创建子进程assert(id >= 0);if(id == 0)//id == 0,则表示子进程{for(int i = 0; i < deleteFd.size(); ++i)//将子进程中存储的上一个子进程的写端关闭{close(deleteFd[i]);}//关闭子进程的写端close(fds[1]);//子进程执行对应的操作while(1){//(1)子进程从管道获取任务码,如果没有发送,子进程阻塞int commandCode = recvTask(fds[0]);//从管道中读取任务码//(2)完成任务if(commandCode >= 0 && commandCode < FuncMap.size())FuncMap[commandCode]();elsebreak;// std::cout << "sub recv code error" << std::endl;}exit(0);}//父进程才可以走到这里close(fds[0]); //关闭父进程的读端。写在这里是因为每个子进程都会有单独的管道与父进程通信,在循环这里//关闭父进程的读端,可以直接将父进程中对应每个子进程的管道的读端全部关闭 SubEp sub(id, fds[1]);//在这里构建sub对象可以防止子进程继承,因为该对象只是提供给父进程使用subs->push_back(sub);deleteFd.push_back(fds[1]);}
}//随机给子进程派发任务
void LoadBlanceContrl(const std::vector<SubEp>& subs, const std::vector<func_t>& FuncMap, int count = 0)
{size_t processNums = subs.size();size_t taskNums = FuncMap.size();//父进程执行控制子进程的操作size_t cnt = subs.size();//子进程的数量bool forever = (count == 0 ? true : false);while(1)//不间断循环选择子进程并派发任务{//(1)选择一个子进程int proIdx = rand() % processNums; //(2)选择给子进程派发的任务int taskIdx = rand() % taskNums;//(3)将任务派发给子进程SendTask(subs[proIdx], taskIdx);//将任务码发给指定子进程的管道文件中sleep(1);//每隔1s发送一次任务if(!forever){--count;if(count == 0)break;}}for(int i = 0; i < subs.size(); ++i)//当父进程写端停止派发任务后,关闭子进程的所有读端{close(subs[i]._writeFd);}
}void WaitPrcoess(std::vector<SubEp>& subs)//回收子进程资源和退出信息
{int processNum = subs.size();for(int i = 0; i < processNum; ++i){waitpid(subs[i]._subId, nullptr, 0);std::cout << "wait sub process success..." << subs[i]._subId << std::endl;}
}int main()
{MakeSeed();//生成随机数种子//加载方法表std::vector<func_t> FuncMap;LoadTaskFunc(FuncMap);//创建子进程并维护好父子进程通信管道std::vector<SubEp> subs;CreateSubProcess(&subs, FuncMap); int taskCnt = 5;//表示运行几次任务,若要一直运行,传入0或不传LoadBlanceContrl(subs, FuncMap, taskCnt);//随机给子进程派发任务//回收子进程信息WaitPrcoess(subs);return 0;
}
在这里面有一个地方要注意:
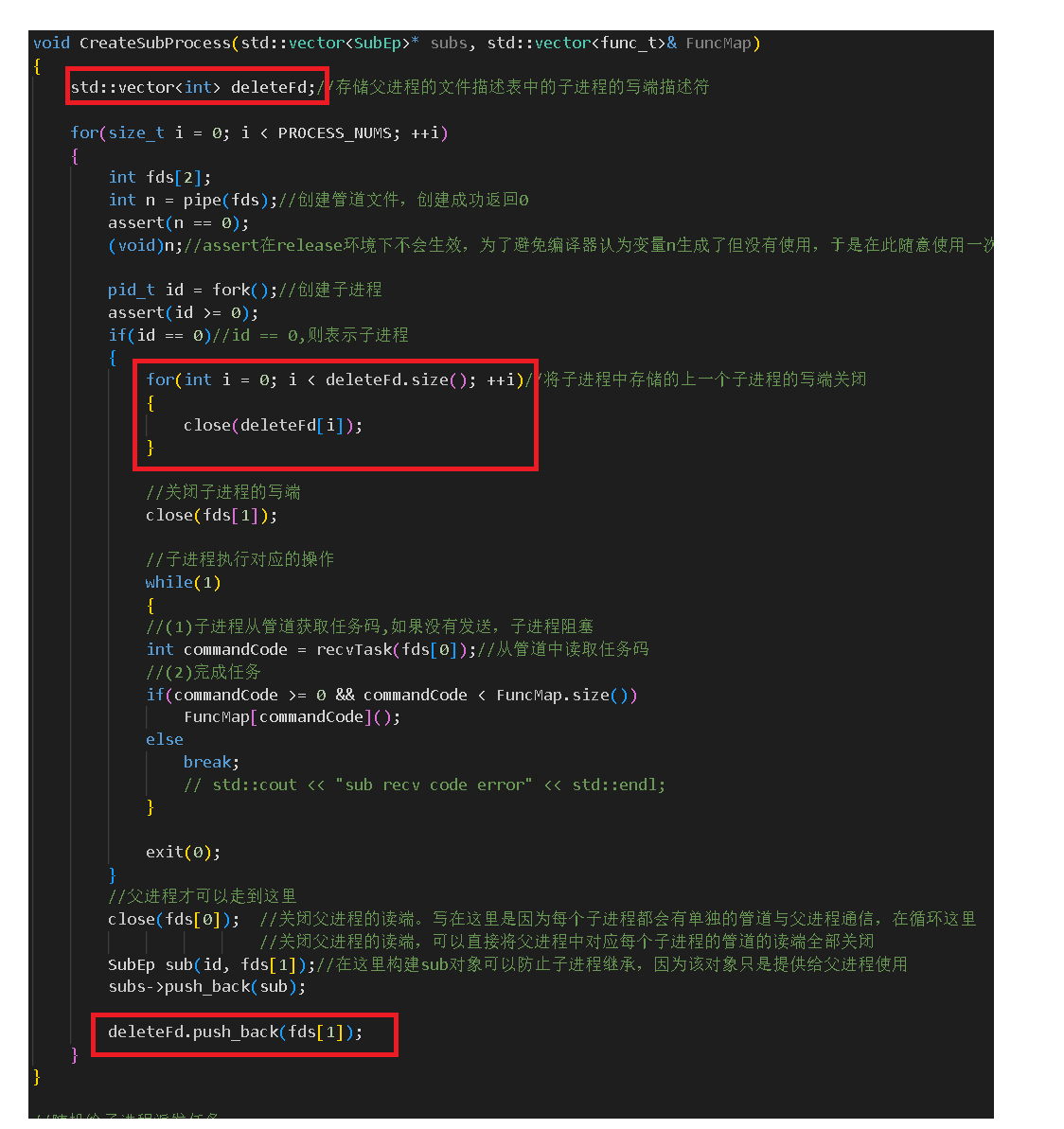
可以看到,在代码实现时,这里是用了一个deleteFd类来存储所有管道文件的写端,并在创建子进程后关闭掉它们。原因是子进程的文件描述表是继承自父进程的。父进程虽然关闭了文件描述符表中的读端,但是文件描述符表中保存的写端还没有被关闭。这就会导致第一个子进程的管道文件的写端描述符会被第二个子进程继承,第三个子进程会继承第二个和第一个子进程对应的管道文件的写端,以此类推,如下图:
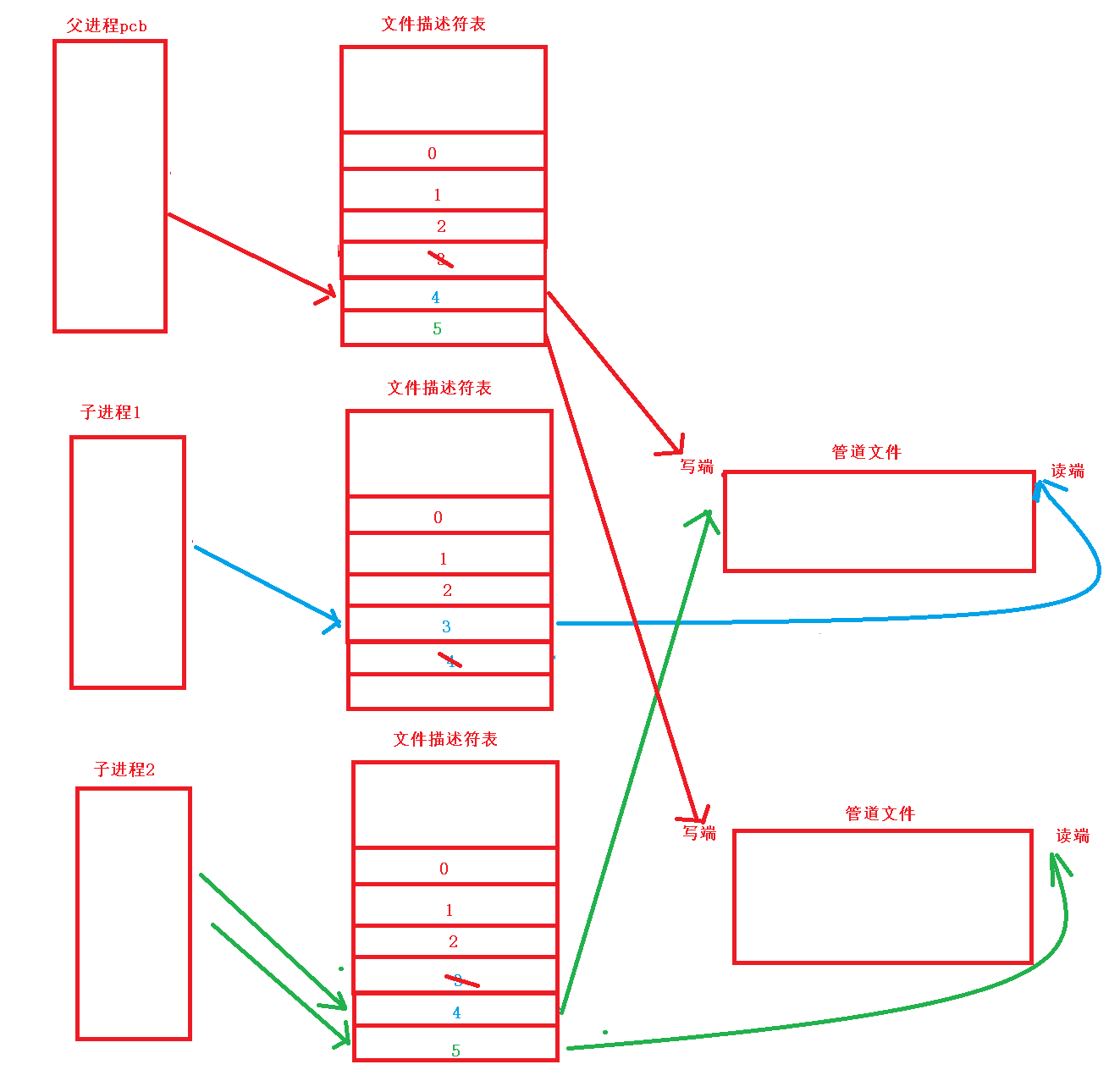
这就会导致每个子进程对应的管道文件除了父进程可以通过写端描述符与其通信外,其他子进程也可以通信。这就可能导致在意外情况下子进程向其他子进程写数据。为了防止这种状况,就最好是在创建子进程后将其存储的其他子进程的写端关闭。
命名管道
匿名管道的使用是有限制的,只能在父子进程中使用。换句话说就是,匿名管道无法在两个毫不相关的进程间进行通信。因此,当需要在两个无关的管道间通信时,就可以使用“命名管道”。
首先要知道,不同进程是可以打开同一份文件的。因为当一个文件打开后,内存就会创建它的文件对象,进程可以根据文件描述符表来找到文件对象。如果又有一个进程打开了同一份文件,那么该进程的文件描述符表中就也会有文件对象的地址。此时两个进程指向同一份文件对象,任何一个进程对文件进行修改,另一个进程都可以看见。命名管道其实就是用的这个原理,即让不同的进程打开指定名称的同一份文件。
命名管道使用的管道文件既然有名字,那么它就一定存在于磁盘中。但是该文件打开后,进程传输的数据并不会通过文件对象写入到磁盘的文件中,而是在内存中传输。
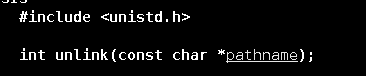
要创建一个命名管道文件,就需要使用mkfifo()函数。该函数在创建成功时返回0,创建失败则返回-1。两个参数分别是要创建的管道文件的文件名和文件权限。

如果想要删除一个管道文件,则使用unlink()函数即可。该函数会删除指定的文件。删除成功返回0,删除失败返回-1.
7.1使用命名管道实现不同进程通信
在这里,就写一个简单的demo代码实现两个毫无关联的进程间的通信。上文中说了,要让两个进程实现通信,就必须要让它们看到同一份公共资源。匿名管道是依靠父子关系的继承来实现的,而命名管道则是依靠打开同一份管道文件来实现。
在这份代码里面,用server作为读端,client作为写端。然后让这两个程序通过管道文件"name_pipe"来实现通信。
函数文件:
#pragma once
#include<iostream>
#include<string>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<errno.h>
#include<cstring>
#include<cassert>
#include<stdio.h>
#include<unistd.h>#define NAME_FILE "name_pipe"bool CreateFifo(const std::string& path)//创建命名管道文件
{int n = mkfifo(path.c_str(), 0666);if(n == 0)return true;else{std::cout << "errno" << errno << "err string:" << strerror(errno) << std::endl;return false;}
}bool RemoveFifo(const std::string& path)//删除管道文件
{int n = unlink(path.c_str());assert(n == 0);(void)n;
}server.cpp文件:
#include"comm.cpp"int main()
{int n = CreateFifo(NAME_FILE);//创建管道文件assert(n);(void)n;int rfd = open(NAME_FILE, O_RDONLY);//以只读方式打开if(rfd < 0)exit(1);char buffer[1024];//设置缓冲区while(1){ssize_t s = read(rfd, buffer, sizeof(buffer));if(s > 0)//正常读取{buffer[s] = 0;std::cout << "client ->server:" << buffer << std::endl;}else if(s == 0)//写端关闭,读端没有数据可读,退出{std::cout << "client quit, me too!" << std::endl;break;}else//读取发生错误,退出{std::cout << "err string:" << strerror(errno) << std::endl;break;}}close(rfd);//关闭管道文件RemoveFifo(NAME_FILE);//删除管道文件return 0;
}client.cpp文件:
#include"comm.cpp"int main()
{int wfd = open(NAME_FILE, O_WRONLY);//以只写方式打开if(wfd < 0)exit(1);char buffer[1024];while(1){std::cout << "Please Say:";fgets(buffer, sizeof(buffer) - 1, stdin);//从标准输入流获取数据到缓冲区bufferif(strlen(buffer) > 0)buffer[strlen(buffer) - 1] = 0;//因为fgets中获取数据时,会多输入一个\n,此处将多的换行设置为0ssize_t n = write(wfd, buffer, strlen(buffer));//将缓冲区内的数据写入到管道文件中assert(n == strlen(buffer));(void) n;}close(wfd);//关闭管道文件return 0;
}注意,在从标准输入读取数据时,要记得将缓冲区内的最后一个字符置为0,。因为从标准输入中读取的数据会有\n。
写好代码后,就分别运行client程序和server程序:

此时在client程序中输入的内容,就会被reserve程序接收并打印。实现了两个毫不相关的进程之间的通信。
在运行这两个程序时,要先运行作为读端的程序。如果先运行写端的程序,操作系统会检测到管道文件中没有程序在读取管道文件的内容,操作系统就会传13号信号给写端程序,将其关闭。而先运行读端程序,读端从管道中没有数据可读时,会进入阻塞状态,等待数据写入到管道,不会停止运行。

上图中就是先运行了写端程序,导致程序自己退出。
相关文章:
初识linux之管道
一、进程间通信的概念大家都知道,进程是具有独立性的,因为一个程序运行起来生成进程时,也会生成它的进程结构体,即PCB,然后然后通过进程结构体中的结构体指针找到它的虚拟地址空间,然后再通过它的页表映射到…...

C++成神之路 | 第一课【步入C++的世界】
目录 一、认识C++ 1.1、关于 C++ 1.2、C++的前世今生 1.2.1、C+...
【面试题】大厂面试官:你做过什么有亮点的项目吗?
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库前言大厂面试中除了问常见的算法网络基础,和一些八股文手写体之外,经常出现的一个问题就是,你做过什么项目…...
Springboot Long类型数据太长返回给前端,精度丢失问题 复现、解决
前言 惯例,收到兄弟求救,关于long类型丢失精度的问题: 存在一个初学者不会,就会有第二个初学者不会,所以我出手。 正文 不多说,开搞。 如题, 后端返回的数据 给到 前端, Long类型数…...
Anaconda虚拟环境的创建方法(命令创建)
虚拟环境介绍: 虚拟环境是一为某个项目创建的专属于它的python包,因此做python项目时,一般一个项目用一个虚拟环境。在实际开发中,如果项目A需要某个包的1.0版本,项目B需要此包的2.0版本。如果没有安装虚拟环境&#…...

数据结构——树与二叉树
作者:几冬雪来 时间:2023年3月22日 内容:数据结构树与二叉树的讲解(介绍) 目录 前言: 1.树的概念: 2.树与非树: 3.树的定义: 4.树的应用: 二叉树&…...
vue后台管理系统
后面可参考下:vue系列(三)——手把手教你搭建一个vue3管理后台基础模板 以下代码项目gitee地址 文章目录1. 初始化前端项目初始化项目添加加载效果配置 vite.config.js2. 使用路由安装路由配置路由配置别名和跳转安装pathvite.config.jsjsco…...

spring boot 集成 postgis jar
要将 PostGIS 集成到 Spring Boot 应用程序中,需要按照以下步骤进行操作:1. 将 PostGIS JDBC 驱动程序添加到项目依赖项中。可以在 Maven 或 Gradle 中添加以下依赖项:Maven:```xml <dependency><groupId>org.postgresql</groupId><artifactId>pos…...
【Java进阶篇】——反射机制
一、反射的概念 1.1 反射出现的背景 Java程序中,所有对象都有两种类型:编译时类型和运行时类型,而很多时候对象的编译时类型和运行时类型不一致 Object obj new String("hello")、obj.getClass(); 如果某些变量或形参的声明类型…...

Oracle中含有recover 状态的数据文件环境中,做异机恢复
背景: 我们在一些恢复测试案例中,会经常遇到一些奇怪的问题,其中有的是源端数据文件不规范而导致恢复过程出错,比较常见的错误有: 数据文件名称重复(如:/oradata1/user01.dbf 和 /oradata2/us…...
图像识别模型
一、数据准备 首先要做一些数据准备方面的工作:一是把数据集切分为训练集和验证集, 二是转换为tfrecord 格式。在data_prepare/文件夹中提供了会用到的数据集和代码。首先要将自己的数据集切分为训练集和验证集,训练集用于训练模型…...
[零刻]EQ12 N100 迷你主机:从开箱到安装ESXi+虚拟机
开箱先上图:配置详情:EQ12采用了Intel最新推出的N100系列的处理,超低的功耗,以及出色的CPU性能用来做软路由或者是All in one 相当不错,CPU带有主动散热风扇,在长期运行下散热完全不用担心,性价…...

MongoDB基础
优质博客 IT-BLOG-CN 一、简介 MongoDB是一个强大的分布式文件存储的NoSQL数据库,天然支持高可用、分布式和灵活设计。由C编写,运行稳定,性能高。为WEB应用提供可扩展的高性能数据存储解决方案。主要解决关系型数据库数据量大,并…...

【Linux】Linux基本指令(下)
前言: 紧接上期【Linux】基本指令(上)的学习,今天我们继续学习基本指令操作,深入探讨指令的基本知识。 目录 (一)常用指令 👉more指令 👉less指令(重要&…...
基于uniapp+u-view开发小程序【技术点整理】
一、上传图片 1.实现效果: 2.具体代码: <template><view><view class"imgbox"><view>职业证书</view><!-- 上传图片 --><u-upload :fileList"fileList1" afterRead"afterRead"…...
)
投稿指南【NO.7】目标检测论文写作模板(初稿)
中文标题(名词性短语,少于20字,尽量不使用外文缩写词)张晓敏1,作者1,2***,作者2**,作者2*(通信作者右上标*)1中国科学院上海光学精密机械研究所空间激光传输与探测技术重…...
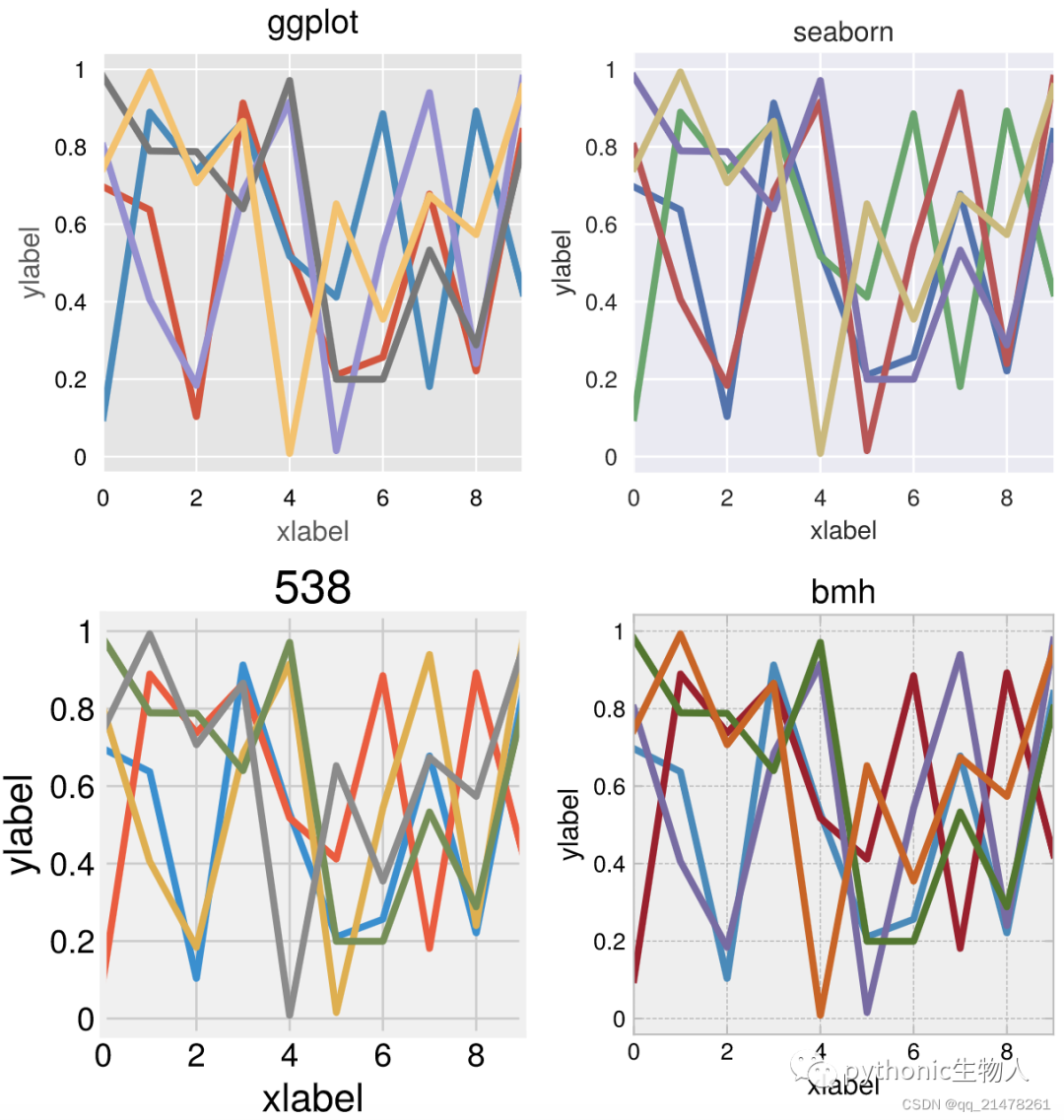
【绘图】比Matplotlib更强大:ProPlot
✅作者简介:在读博士,伪程序媛,人工智能领域学习者,深耕机器学习,交叉学科实践者,周更前沿文章解读,提供科研小工具,分享科研经验,欢迎交流!📌个人…...

经典七大比较排序算法 ·上
经典七大比较排序算法 上1 选择排序1.1 算法思想1.2 代码实现1.3 选择排序特性2 冒泡排序2.1 算法思想2.2 代码实现2.3 冒泡排序特性3 堆排序3.1 堆排序特性:4 快速排序4.1 算法思想4.2 代码实现4.3 快速排序特性5 归并排序5.1 算法思想5.2 代码实现5.3 归并排序特性…...

【网络安全工程师】从零基础到进阶,看这一篇就够了
学前感言 1.这是一条需要坚持的道路,如果你只有三分钟的热情那么可以放弃往下看了。 2.多练多想,不要离开了教程什么都不会,最好看完教程自己独立完成技术方面的开发。 3.有问题多google,baidu…我们往往都遇不到好心的大神,谁…...
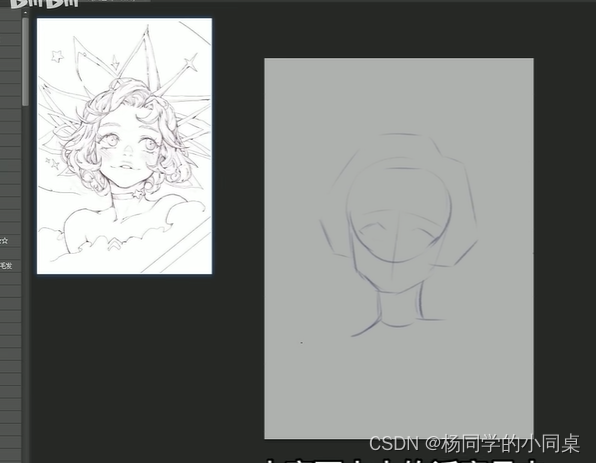
素描-基础
# 如何练习排线第一次摸板子需要来回的排线,两点然后画一条线贯穿两点画直的去练 练线的定位叫做穿针引线法或者两点一线法 练完竖线练横线 按照这样去练顺畅 直线曲线的画法 直线可以按住shift键 练习勾线稿 把线稿打开降低透明度去勾线尽量一笔的去练不要压…...

PvZ Toolkit 技术指南:从游戏修改到体验重塑
PvZ Toolkit 技术指南:从游戏修改到体验重塑 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 价值定位:为什么选择 PvZ Toolkit? 当你在《植物大战僵尸》无尽模式…...

提升输入效率:Qwerty Learner开源键盘训练工具的肌肉记忆训练方案
提升输入效率:Qwerty Learner开源键盘训练工具的肌肉记忆训练方案 【免费下载链接】qwerty-learner 项目地址: https://gitcode.com/GitHub_Trending/qw/qwerty-learner Qwerty Learner是一款开源键盘训练工具,通过将单词记忆与英语肌肉记忆训练…...
)
FOC算法中SIMULINK常用模块解析:从坐标变换到SVPWM(实践指南)
1. FOC算法与SIMULINK模块概述 第一次接触FOC(磁场定向控制)算法时,我被那些复杂的坐标变换搞得晕头转向。直到在SIMULINK里亲手搭建了完整的控制环路,才真正理解每个模块的作用。FOC算法的核心思想,简单来说就是把三相…...

Qwen3-ASR-1.7B部署案例:高校科研组构建本地化学术讲座语音知识库
Qwen3-ASR-1.7B部署案例:高校科研组构建本地化学术讲座语音知识库 1. 项目背景与价值 高校科研团队经常举办各类学术讲座和研讨会,这些宝贵的学术内容通常以音频形式记录。传统的人工转录方式耗时耗力,且对于专业术语密集的学术内容&#x…...

突破硬件限制的跨显卡AI增强方案:OptiScaler游戏画质优化全解析
突破硬件限制的跨显卡AI增强方案:OptiScaler游戏画质优化全解析 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler OptiSc…...
)
RK3568开发板烧录避坑指南:Maskrom和Loader模式切换失败?手把手教你排查(附串口调试技巧)
RK3568开发板烧录模式切换全攻略:从原理到实战排查 刚拿到RK3568开发板的开发者们,往往会在第一个环节就遭遇"拦路虎"——开发板死活进不了Maskrom或Loader模式。看着官方文档里简单的按键操作说明,实际操作时却像在玩一场没有规则…...
)
从‘玩具项目’到‘线上产品’:我的Vue3项目在阿里云ECS上线的完整踩坑记录(含Nginx配置)
从本地开发到云端部署:Vue3项目实战全流程解析 第一次将自己的Vue项目部署到线上时,我盯着浏览器里那个404错误页面整整发呆了十分钟。作为一个刚完成基础学习的开发者,我原以为按照教程一步步操作就能顺利上线,但现实却给了我当头…...

你的电动车续航打折了?可能是AMT换挡逻辑没调好!聊聊经济性换挡那些事儿
你的电动车续航打折了?可能是AMT换挡逻辑没调好!聊聊经济性换挡那些事儿 最近在车主群里经常看到这样的抱怨:"明明官方标称续航500公里,怎么我开起来连400都跑不到?"作为一位开了三年电动车的"老司机&q…...

如何高效获取六大网盘直链下载地址:开源工具的实用指南
如何高效获取六大网盘直链下载地址:开源工具的实用指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 在当今数字时代,网盘已成为我们日常工作和学习中不可或缺的工具…...

Gurobi Python接口避坑指南:从安装、建模到求解电影排片问题的实战记录
Gurobi Python实战避坑手册:电影排片优化全流程解析 第一次接触Gurobi时,我被它号称的"商业求解器性能标杆"吸引,却在安装环节就被Anaconda环境冲突绊住了脚步。作为从开源求解器转战商业工具的用户,我完整记录了从零开…...