Kylin的工作原理及使用分享
前言
在当今信息爆炸的时代,企业和研究机构每天都在生成和收集大量的数据。这些数据中蕴藏着巨大的商业价值和研究潜力,但要从中提取出有用的信息却并非易事。传统的数据处理和分析技术在面对如此庞大的数据量时,往往难以提供快速和有效的响应。而Apache Kylin作为一款开源的分布式分析引擎,正是为了解决这一问题而设计的。
Apache Kylin的出现为大数据分析开辟了一条新的道路。通过其创新的预计算多维立方体(Cube)技术,Kylin能够在大数据环境中实现亚秒级的查询响应。这一特性使得Kylin在处理海量数据时,能够提供高效、快速的分析能力,为企业的决策提供及时的数据支持。
本文将详细介绍Kylin的工作原理,分析其在大数据处理中的优势,并结合实际案例分享如何在生产环境中有效利用Kylin进行数据分析。希望通过这篇文章,读者能够对Kylin有一个全面的了解,并能够在实际应用中灵活运用这一强大的工具。无论您是数据分析师、架构师,还是对大数据技术感兴趣的开发者,本文都将为您提供有价值的参考和指导。
一、Kylin简介
Apache Kylin是由eBay公司于2014年开源的一款分布式分析引擎,专为超大规模数据集的OLAP(Online Analytical Processing,在线分析处理)需求而生。它旨在通过预计算技术,提供对海量数据的亚秒级查询能力,使得大规模数据分析变得更加高效和便捷。
1.1 Kylin的核心特性
-
高性能查询:Kylin通过预计算的方式将数据立方体存储在HBase中,极大地缩短了查询时的响应时间。其设计目标是在处理TB级甚至PB级数据时,依然能保持秒级的查询响应。
-
大规模数据处理:Kylin能够处理海量数据集,支持数百亿行数据的分析处理。它利用Hadoop生态系统的优势,提供了水平扩展的能力,使得数据处理和存储不受限于单一节点的资源。
-
多维分析能力:Kylin支持复杂的多维OLAP分析,用户可以自由定义维度和度量,满足多样化的业务分析需求。通过Cube的设计,用户可以实现灵活的数据切片和聚合操作。
-
易于集成:Kylin支持标准的SQL查询接口,并能无缝地集成到现有的数据分析工具和BI平台中,如Tableau、Power BI等。此外,Kylin支持多种数据源,包括Hive、Kafka等,使得数据导入和处理更加灵活。
1.2 Kylin的架构概览
Kylin的架构设计充分考虑了大数据处理的复杂性和效率问题。其整体架构主要包括以下几个模块:
-
数据源:Kylin可以从多种数据源导入数据,主要包括Hadoop生态系统中的Hive和Kafka等。通过与这些数据源的集成,Kylin能够灵活地获取和处理数据。
-
Cube构建引擎:在数据导入后,Kylin通过其构建引擎将数据预计算成多维立方体。这个过程包括数据清洗、转换、聚合等步骤,最终将结果存储在HBase中。
-
查询引擎:Kylin的查询引擎负责将用户提交的SQL查询翻译为对预计算结果的检索操作。通过优化的查询路径,Kylin能够在极短的时间内返回查询结果。
-
用户接口:Kylin提供了一个友好的Web界面,用户可以在上面进行Cube的设计、构建任务的管理以及SQL查询的执行。此外,Kylin还支持通过JDBC和ODBC连接进行查询,方便与其他工具的集成。
1.3 Kylin的应用场景
Kylin在多个领域都有广泛的应用,特别是在需要快速分析海量数据的场景中。例如:
-
电子商务平台:实时分析用户行为和交易数据,优化产品推荐和库存管理。
-
金融服务:进行风险分析和实时监控,帮助金融机构迅速响应市场变化。
-
电信行业:分析通话记录和网络使用情况,提升客户服务和网络质量。
二、Kylin的工作原理
Kylin之所以能够提供高效的查询性能,关键在于其独特的预计算技术和架构设计。通过预先计算和存储多维数据立方体(Cube),Kylin可以在查询时快速检索和返回结果。下面,我们将详细探讨Kylin的工作原理,包括数据预计算和查询加速的过程。
2.1 数据预计算
数据预计算是Kylin实现快速查询响应的核心。这个过程主要包括以下步骤:
2.1.1 Cube设计
-
定义维度和度量:在使用Kylin之前,用户需要根据业务需求定义Cube的维度(Dimensions)和度量(Measures)。维度是数据的切片和聚合方式,例如时间、地区、产品等;度量则是需要聚合的数值数据,例如销售额、访问次数等。
-
建立维度模型:用户可以在Kylin的Web界面上直观地设计维度模型。合理的维度设计是确保查询性能和Cube存储效率的关键。
2.1.2 ETL过程
- 数据导入:Kylin通过ETL(Extract, Transform, Load)过程,将数据从Hive、Kafka等数据源导入系统。在这一阶段,数据会被清洗和转换,以符合Cube构建的要求。
2.1.3 Cube构建
-
MapReduce任务:Kylin利用Hadoop的MapReduce框架进行Cube的构建。这个过程将数据按照用户定义的维度和度量进行聚合计算,生成多维Cube。
-
存储在HBase中:构建完成的Cube会被存储在HBase中。HBase的高性能和可扩展性使得它非常适合存储大规模的预计算数据。
2.2 查询加速
Kylin的查询加速主要依托于其预计算的Cube。在查询阶段,Kylin的工作流程如下:
2.2.1 SQL解析
- SQL翻译:Kylin支持标准的SQL查询。用户提交的SQL查询首先会被解析器翻译成Cube上的操作。Kylin会识别出查询所需的维度和度量,从而定位到相应的预计算结果。
2.2.2 快速检索
- Cube检索:查询引擎直接从HBase中检索预先计算好的Cube数据,而不需要对原始数据集进行全面的扫描和计算。这样,查询响应时间大大缩短。
2.2.3 返回结果
- 结果返回:经过优化的查询引擎在极短时间内返回查询结果,通常能够实现亚秒级的响应。这使得Kylin特别适合用于需要实时分析和快速决策的场景。
2.3 支持多种数据源
Kylin能够灵活地集成多种数据源:
-
Hive:通过Hive,Kylin能够从Hadoop集群中直接获取海量数据。
-
Kafka:对于实时数据流,Kylin可以通过Kafka进行实时数据的导入和处理。
这种灵活性使得Kylin能够适应不同的数据环境和需求,成为大数据分析解决方案中的一块重要拼图。
三、Kylin的使用
在了解了Kylin的工作原理后,接下来我们将探讨如何在实际项目中有效地使用Kylin进行数据分析。本文将从环境准备、Cube设计与构建、查询分析以及性能优化等方面详细介绍Kylin的使用方法。
3.1 环境准备
在开始使用Kylin之前,必须先搭建和配置好所需的环境,包括Hadoop、Hive和HBase等组件。以下是环境准备的基本步骤:
3.1.1 安装Hadoop生态系统
-
Hadoop集群:确保已经搭建好Hadoop集群,包括HDFS和YARN。这是Kylin运行的基础环境。
-
Hive:安装Hive,用于数据存储和初始化,Kylin会从中提取数据。
-
HBase:安装并配置HBase,Kylin会将预计算的Cube数据存储在HBase中。
3.1.2 安装Kylin
-
下载Kylin:从Apache Kylin的官方网站下载最新版本的Kylin。
-
配置Kylin:解压安装包并配置
kylin.properties文件,包括Hadoop集群的路径、HBase的配置等。 -
启动Kylin:通过命令行启动Kylin服务,确保它能够正常运行,并可以通过Web界面访问。
3.2 Cube设计与构建
Cube的设计与构建是Kylin使用中的核心部分,直接影响到查询性能和存储效率。
3.2.1 Cube设计
-
确定业务需求:在设计Cube之前,首先要明确业务需求,确定需要分析的维度和度量。例如,销售分析可能需要的维度包括时间、地区、产品类别,而度量可能包括销售金额和数量。
-
设计维度模型:在Kylin的Web界面上,创建新的Cube项目,定义所需的维度和度量。合理的维度设计不仅能提高查询性能,还能节省存储空间。
3.2.2 Cube构建
-
数据准备:确保数据已经准备好并存储在Hive中。Kylin将从Hive中读取数据用于Cube的构建。
-
启动构建任务:在Kylin的Web界面上,选择要构建的Cube,并启动构建任务。Kylin会自动生成MapReduce任务,通过Hadoop集群进行数据预计算。
-
监控构建进度:在Kylin的Web界面或日志中监控构建任务的进度,确保其顺利完成。
3.3 查询分析
Cube构建完成后,用户可以通过Kylin提供的SQL接口进行查询分析。
3.3.1 执行查询
-
SQL查询:使用Kylin提供的查询界面或通过JDBC/ODBC连接工具,输入SQL语句进行查询。Kylin支持标准SQL语法,用户无需学习新的查询语言。
-
查看查询结果:Kylin会在后台进行优化查询,并快速返回结果。用户可以在界面上查看结果或导出数据进行进一步分析。
3.4 性能优化
为了充分发挥Kylin的查询性能,用户可以采取以下几种优化策略:
3.4.1 Cube优化
- 简化维度和度量:在设计Cube时,尽量减少不必要的维度和度量,以降低Cube的复杂度和存储需求。
3.4.2 增量构建
- 增量更新:对于不断变化的数据集,可以设置增量构建策略,减少全量重构Cube的开销,从而提高效率。
3.4.3 系统调优
-
HBase参数调整:根据实际查询情况,调整HBase的缓存和索引参数,以提升数据检索性能。
-
资源分配优化:合理分配Hadoop集群的计算资源,确保Kylin的构建任务和查询任务能够高效执行。
四、使用案例分享
在实际项目中,Apache Kylin的高效性和灵活性使其成为大数据分析的重要工具。下面,我将分享一个具体的使用案例,展示Kylin如何在现实场景中应用。
4.1 案例背景
某大型电商平台需要对海量的用户行为数据进行实时分析,以优化其产品推荐系统和库存管理策略。传统的分析方法在面对TB级数据时,查询响应时间过长,无法满足业务实时性要求。
4.2 解决方案
通过引入Apache Kylin,团队能够设计并构建适合其业务需求的Cube,实现快速的数据查询和分析。
4.2.1 Cube设计
-
维度选择:选定用户ID、产品ID、时间、地区作为主要维度,以便分析不同用户群体在不同时间和地区的购买行为。
-
度量选择:选择了购买金额、购买数量作为主要度量,用于衡量销售业绩。
4.2.2 Cube构建与优化
-
数据导入与预处理:从Hive中导入用户行为日志数据,进行清洗和转换,确保数据质量。
-
构建Cube:通过Kylin Web界面配置和启动Cube构建任务。利用增量构建机制,每日更新数据,避免全量重构,节省了大量计算资源。
-
性能优化:通过调整HBase的缓存和索引配置,提高了查询性能。减少了不必要的维度组合,从而降低了Cube的存储需求。
4.3 查询与分析
-
实时查询:通过Kylin的SQL接口,业务分析人员能够实时查询用户的购买行为数据,获得关键的销售趋势信息。
-
结果应用:分析结果用于调整产品推荐算法,提高了用户满意度,并优化了库存管理,减少了缺货和过剩库存的情况。
4.4 成果与收益
通过应用Kylin,电商平台实现了对海量用户数据的实时分析,查询响应时间从数分钟缩短至秒级。这使得业务决策能够更加敏捷,直接推动了销售额的提升和运营效率的提高。
五、总结
Apache Kylin凭借其卓越的性能和灵活的扩展性,已经成为大数据分析领域的重要工具。通过预计算技术,Kylin有效地解决了海量数据分析中的性能瓶颈,提供了亚秒级的查询响应能力。在本文中,我们详细探讨了Kylin的工作原理、使用方法和实际案例,帮助大家更好地理解和应用这一技术。
无论是在电商、金融,还是在电信等行业,Kylin都展示了其强大的分析能力和广泛的应用价值。希望通过本文的分享,读者能够在自己的项目中灵活运用Kylin,推动业务的发展和创新。如果您在使用过程中遇到任何问题或有新的想法,欢迎在评论区与我交流,我们可以共同探讨,互相学习。
作者: FLK_9090
CSDN博客: https://blog.csdn.net/FLK_9090
Gitee: https://gitee.com/fantasy_5
相关文章:

Kylin的工作原理及使用分享
前言 在当今信息爆炸的时代,企业和研究机构每天都在生成和收集大量的数据。这些数据中蕴藏着巨大的商业价值和研究潜力,但要从中提取出有用的信息却并非易事。传统的数据处理和分析技术在面对如此庞大的数据量时,往往难以提供快速和有效的响…...

python 使用seleniumwire获取响应数据
seleniumwire 是一个在 Selenium WebDriver 基础上扩展的库,它允许你在使用 Selenium 进行网页自动化测试或爬虫时捕获和修改 HTTP 请求和响应。这对于需要分析网页数据或进行更复杂的网络交互的自动化任务特别有用。 以下是如何使用 seleniumwire 来获取响应数据的…...
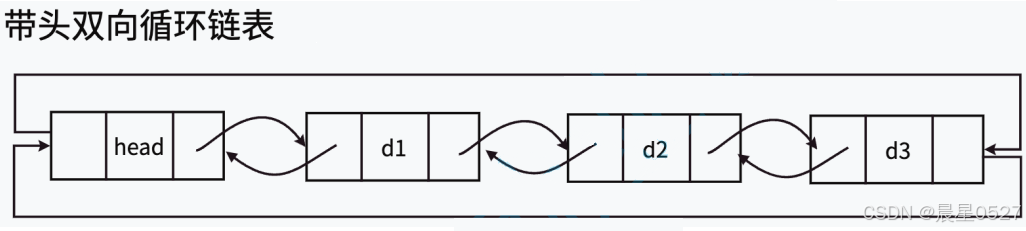
用C语言实现双向链表
目录 一.双向链表的结构 二. 双向链表的实现 1. 在List.h中结构体的定义和各函数的声明 1.1 结构体(节点)的定义 1.2 各函数的声明 2. 在List.c中各函数的实现 2.1 初始化 LTInit 2.2 尾插 LTPushBack 2.3 打印 LTPrint 2.4 头插 LTPushFron…...

Github 2024-08-10 Rust开源项目日报Top10
根据Github Trendings的统计,今日(2024-08-10统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Rust项目10Python项目1Turbo:下一代前端开发工具链 创建周期:977 天开发语言:Rust协议类型:MIT LicenseStar数量:25308 个Fork数量:1713 …...

深入解析 ESLint 配置:从零到精通
深入解析 ESLint 配置:从零到精通 ESLint 是一个强大的代码检查工具,主要用于识别 JavaScript 和其他支持的语言中的常见编程错误,并强制执行一致的编码风格。自2013年6月由Nicholas C. Zakas创建以来,ESLint 已成为前端开发中不…...

BTC连续拉涨,击碎空头幻想
原创 | 刘教链 隔夜BTC继续拉涨,急破6万刀,“过了黄洋界,险处不须看”,一度逼近63k,目前暂于61-62k区间休整。从8月5日极限插针下探49k,仅仅3天多时间,就连续拉涨到了61k,总涨幅接近…...

【Spring】Sping笔记01
参考学习:b站浪飞yes ---------------------------------------------------- # 一、Spring 引入 **事务实现** java public class EmployeeServiceImpl implements IEmployeeService { public void save(Employee employee){ // 打开资源 /…...

Gridcontrol纵向/横向合并单元格
指定列值相同,纵向合并: this.gridView1.OptionsView.AllowCellMerge true;//启用合并列 // 启用指定合并列事件 this.gridView1.CellMerge new DevExpress.XtraGrid.Views.Grid.CellMergeEventHandler(gridView1_CellMerge);#region 合并指定的列 pri…...

从周杰伦的《青花瓷》三次更名看方文山的国学情怀与工匠精神
《青花瓷》三次更名,方文山的国学情怀与工匠精神 在华语乐坛上,周杰伦与方文山的合作堪称黄金组合,他们的作品不仅引领了流行音乐的潮流,更让传统文化焕发出新的生机。在这其中,《青花瓷》无疑是他们合作的经典之一&a…...
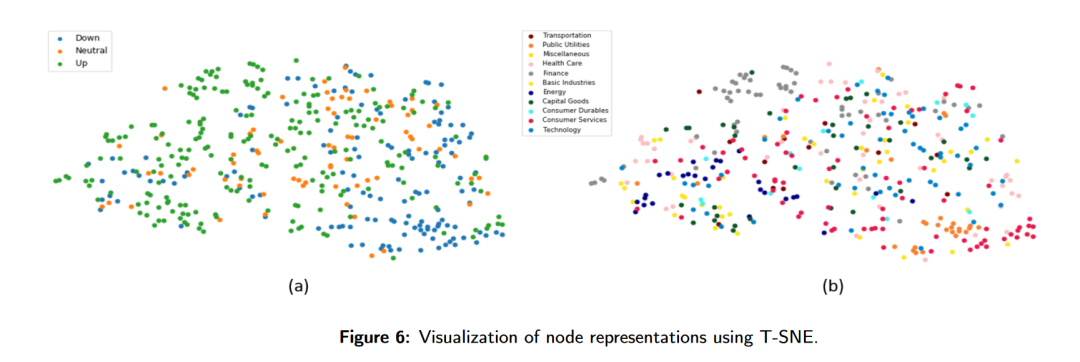
HATS:分层图注意力神经网络用于股票预测
HATS:分层图注意力神经网络用于股票预测 原创 QuantML QuantML 2024年08月09日 19:08 上海 Content 本文提出了一种名为HATS(Hierarchical Graph Attention Network)的分层图注意力网络,用于预测股市动向。HATS通过选择性地聚合…...

【日常记录-MySQL】MySQL设置root用户密码
Author:赵志乾 Date:2024-08-09 Declaration:All Right Reserved!!! 1. 简介 MySQL8.0.30安装后启动,发现root用户尚未设置密码。以下是两种设置root用户密码的方式。 2. 示例 2.1 mysqladmin…...
)
高级Web安全技术(第二篇)
我们继续第二篇,继续深入了解web的安全 一、概述 在Web应用的开发与部署中,安全问题不仅是技术挑战,更是对系统整体架构的考验。本篇文章将继续深入探讨高级Web安全技术,重点关注API安全的最佳实践、OAuth的安全实施以及安全编码…...

前端实现文件下载常用几种方式
项目中前端下载一般分为两种情况: 后端直接提供一个文件地址,通过浏览器打开就可以下载。需要发送请求,后端返回二进制流数据,前端解析流数据,生成URL实现下载。 前端对应的实质是a标签和Blob文件下载,这…...
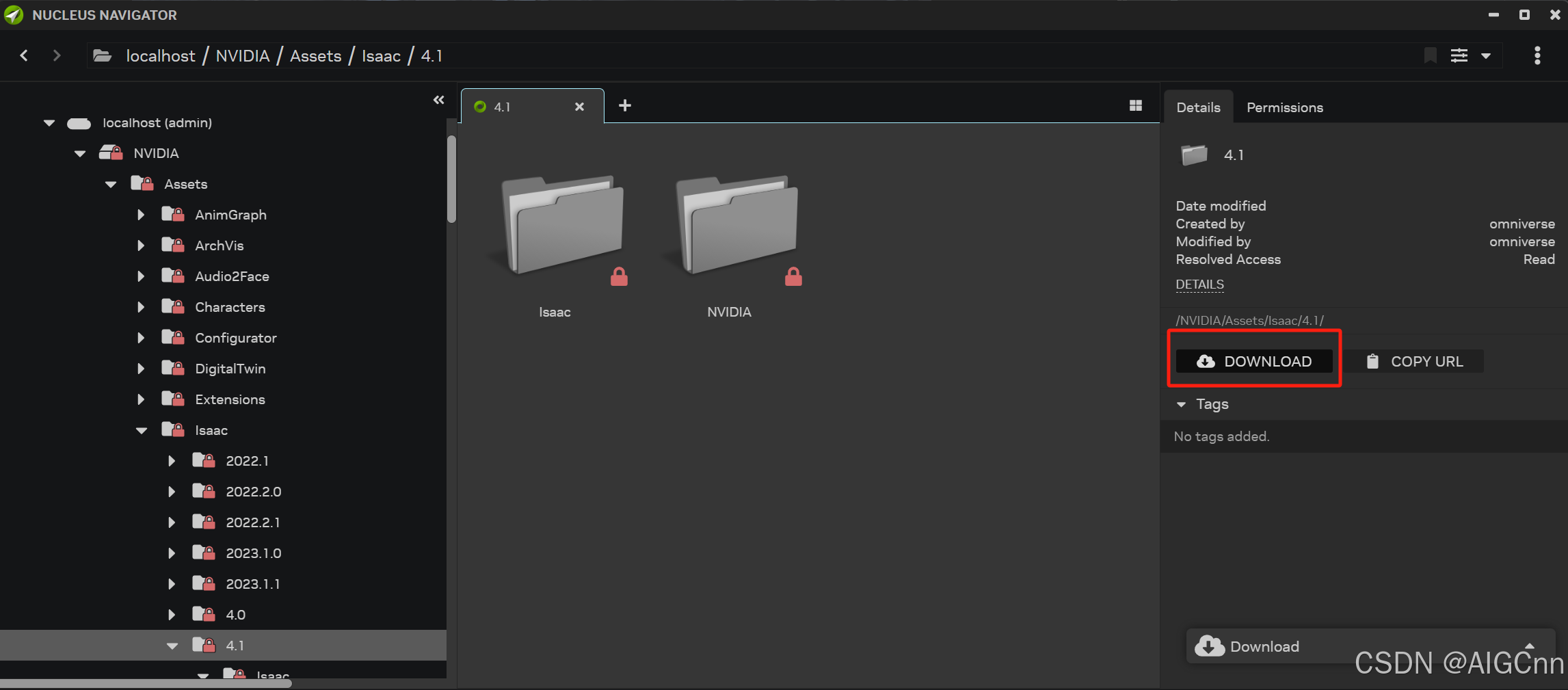
Isaac Lab 安装 (ubuntu22.04环境)
Windows下的安装见这篇博客: Isaac Lab 安装与初体验 (windows环境)-CSDN博客 ubuntu22.04下的安装与windows下十分类似,还是参考官方的,Installation using Isaac Sim Binaries Installation using Isaac Sim Bina…...

todoList清单(HTML+CSS+JavaScript)
🌏个人博客主页: 前言: 前段时间学习了JavaScript,然后写了一个todoList小项目,现在和大家分享一下我的清单以及如何实现的,希望对大家有所帮助 🔥🔥🔥文章专题ÿ…...

LVS集群实现四层负载均衡详解(以nat,dr模式为例)
目录 一、LVS集群的介绍 1、LVS 相关术语: 2、lvs四层负载均衡工作原理 3、相关名词概念 4、lvs集群的类型 二、lvs的nat模式 1、介绍: 2、数据逻辑: 3、nat实验部署 环境搭建: 1、lvs中要去打开内核路由功能,…...

七夕表白网页效果实现与解析
七夕是中国传统的情人节,是一个充满浪漫与爱的节日。在这个特别的日子里,用代码来表达心意也是一种独特且有趣的方式。本篇文章将带你一步步实现一个简单但充满心意的七夕表白网页。通过使用HTML、CSS和少量的JavaScript,我们将创建一个包含跳…...
课程11-自然语言处理之NLP的语言模型-seq2seq模型,seq+注意力与代码详解)
人工智能算法工程师(高级)课程11-自然语言处理之NLP的语言模型-seq2seq模型,seq+注意力与代码详解
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师(高级)课程11-自然语言处理之NLP的语言模型-seq2seq模型,seq+注意力,word2vec与代码详解。本课程面向高级人工智能算法工程师,深入讲解自然语言处理(NLP)中的关键语言模型技术,包括seq2seq模型及其增强版加入注意力…...

从PyTorch官方的一篇教程说开去(6.2 - 张量 tensor 矩阵运算等)
您的进步和反馈是我写作最大的动力,小伙伴来个三连呗!共勉~ 话不多说,书接上文,需要温习的小伙伴请移步 - 从PyTorch官方的一篇教程说开去(6.1 - 张量 tensor 基本操作)-CSDN博客 借图镇楼 - 1 - 矩阵乘…...

【网络层】直连路由、静态路由、动态路由
文章目录 路由表直连路由直连路由 技术背景直连路由 实战训练 静态路由静态路由 技术背景静态路由 概述静态路由 配置命令静态路由 实战训练 动态路由动态路由 技术背景路由协议概述路由协议分类 路由表 路由表的形成,路由的来源: 路由来源备注直连路由…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...