【自用】Python爬虫学习(三):图片下载、使用代理、防盗链视频下载、多线程与多进程
Python爬虫学习(三)
- 使用BeautifulSoup解析网页并下载图片
- 模拟用户登录处理
- 使用代理
- 视频下载,防盗链的处理
- 多线程与多进程
使用BeautifulSoup解析网页并下载图片
目的:对某网站的某个专栏页面的图片进行下载得到高清图。
思路:从主页获取每张图片对应的子页面的链接地址,在子页面找到对应的高清图片下载地址然后下载。查找使用BeautifulSoup,直接从主页拿到的图片下载链接为缩略图,这里想要下载的是高清的图片。
import time
import requests
from bs4 import BeautifulSoupdomain = "https://www.umei.cc/"
# url = "https://www.umei.cc/bizhitupian/weimeibizhi/" # 唯美壁纸专栏
url = "https://www.umei.cc/bizhitupian/fengjingbizhi/" # 风景壁纸专栏
# 浏览器的标头身份标识信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0"
}resp = requests.get(url, headers=headers)
print("服务器响应状态码:", resp.status_code)
resp.encoding = 'utf-8' # 处理乱码# 把主页源代码交给BeautifulSoup
main_page = BeautifulSoup(resp.text, "html.parser")
# 获取图片子页源码链接
alist = (main_page.find("div", class_="item_list infinite_scroll").find_all("a", class_="img_album_btn"))# print(alist)
img_num = 0
for a in alist:href = a.get('href') # 直接通过get就可以拿到属性的值child_url = domain + href.strip('/')# print(child_url) # 子页面网址# 拿到子页面的源代码child_page_resp = requests.get(child_url, headers=headers)child_page_resp.encoding = 'utf-8'# 从子页面中获取图片的下载路径child_page = BeautifulSoup(child_page_resp.text, "html.parser")div_list = child_page.find('div', class_='big-pic')image_src = div_list.find('img').get('src') # 用get拿到标签的对应属性image_name_src = div_list.find('img').get('alt')[:-1] + '.jpg'# print(image_src) # 打印图片下载地址,http://kr.shanghai-jiuxin.com/file/bizhi/20220927/5wn4old1jef.jpg# print(image_name_src) # 红色,爱心,心,玫瑰,叉子,刀.jpg# 下载图片img_resp = requests.get(image_src)# 获取url中最后一个/以后的内容作为图片名称# img_name_url = image_src.split('/')[-1] #5wn4old1jef.jpgwith open("data_file/img/" + image_name_src, mode='wb') as f:f.write(img_resp.content) # img_resp.content #这里得到的是字节数据img_num = img_num + 1print(f"Download successfully!\t{img_num}:'{image_name_src}'")# 只下载前6景图片if img_num == 6:img_resp.close()child_page_resp.close()breaktime.sleep(3) # 每下载一张图片休息3s
print("Over!!!")
resp.close()
模拟用户登录处理
- 方法1:使用会话session对象,使用session.get()、session.post()进行请求
session = requests.session()
resp = session.post()
# resp = session.get()
- 方法2:使用requests.get(),在headers中设置参数,直接从浏览器中复制对应的Cookie
resp = requests.get(url=url, headers={"Cookie": "一长串内容"})
# !!!注:代码不能正常运行,仅做示例!!!
# 登录->得到cookie,带着cookie 去请求服务器
# 使用session进行请求->session你可以认为是一连串的请求。在这个过程中的cookie不会丢失
import requests# 登录账户与密码信息(仅做示例)
data = {"loginName": "15100001234","password": "1234abcd"
}# 会话
session = requests.session()# 1.登录
url = "https://passport.17k.com/ck/user/login"
resp = session.post(url, data=data)
# print(resp.json())
print(resp.cookies)# 2.拿书架上的数据
# 刚才的那个session中是有cookie的
url2 = 'https://user.17k.com/ck/author/shelf?page=1&appkey=2406394919'
resp1 = session.get(url=url2) # 第一种方法
print(resp1.json())resp2 = requests.get(url=url2, headers={# 第二种方法,使用requests.get(),在headers中设置参数,直接从浏览器中复制对应的Cookie"Cookie": "GUID=abcdfa-adg-ag;c_channel=0;c_csc=web;UM_distinctid=177=1614336271"# 实际的Cookie很长一串,这里仅做示范瞎写的
})
print(resp2.text)
使用代理
请求时传入一个proxies参数
resp = requests.get(url, proxies=proxies)
# 代码不能正常运行,仅做示例,想要正常运行需要寻找可用的代理IP节点
import requests# 218.60.8.83:3129 找一个可用的代理IP
proxies = {"https": "https://218.60.8.83:3129"# "http": ""#具体使用哪种看具体的网站
}url = "https://www.baidu.com"resp = requests.get(url, proxies=proxies)
print("服务器响应状态码:", resp.status_code)
resp.encoding = 'utf-8' # 处理乱码
print(resp.text)
视频下载,防盗链的处理
根据某视频文章页面的网页链接下载文章对应的视频
思路:
- 拿到contId
- 拿到videoStatus返回的json.-> srcURL
- 对srcURL内容进行修正
- 下载视频
防盗链,添加一个参数
"referer": url
import requestsurl = "https://www.pearvideo.com/video_1795368"
# url = "https://www.pearvideo.com/video_1689388"contId = url.split("_")[1] # 1795368
# print(contId)videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.7991879511806432"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0",# 防盗链,溯源,当前本次请求的上一级是谁"referer": url
}resp = requests.get(videoStatusUrl, headers=headers)
# print(resp.text)dict = resp.json()
srcUrl = dict['videoInfo']['videos']['srcUrl'] # 返回的虚假的地址
# print(srcUrl)
systemTime = dict['systemTime']relSrcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # 寻找规律进行替换得到的真实的地址
print(relSrcUrl)# srcUrl: "https://video.pearvideo.com/mp4/short/20240802/1723116619381-16034050-hd.mp4" 返回的虚假的地址
# relUrl: "https://video.pearvideo.com/mp4/short/20240802/cont-1795368-16034050-hd.mp4" 实际真实的地址
# https://video.pearvideo.com/mp4/short/20240802/cont-1795368-16034050-hd.mp4# 根据真实下载地址下载视频
with open(f"{contId}.mp4", mode='wb') as f:f.write(requests.get(relSrcUrl).content)print("Over!!!")
resp.close()多线程与多进程
# 线程,进程
# 进程是资源单位,每一个进程至少要有一个线程
# 线程是执行单位# 启动每一个程序默认都会有一个主线程
def func():for i in range(100):print("func", i)if __name__ == '__main__':# print("hello wolrd")func()for i in range(100):print("main", i)多线程的第一种写法
# 多线程
from threading import Thread # 线程类# 多线程的第一种写法
def func():for i in range(100):print("func", i)if __name__ == '__main__':t = Thread(target=func) # 创建线程并给线程安排任务t.start() # 多线程状态为可以开始工作状态,具体的执行时间由CPU决定for i in range(100):print("main", i)多线程的第二种写法
# 多线程
from threading import Thread # 线程类# 多线程的第二种写法
class MyThread(Thread):def run(self):for i in range(100): # 固定的 -->当线程被执行的时候,被执行的就是run()print("子线程", i)if __name__ == '__main__':t = MyThread() # 创建线程并给线程安排任务# t.run() # 注意,这种写法会被当成方法的调用.-->成为单线程t.start() # 开启线程for i in range(100):print("主线程", i)
多线程的传参
from threading import Thread # 线程类# 多线程的传参
def func(name):for i in range(100):print(name, i)if __name__ == '__main__': # 传递参数必须是元组,逗号不能省,不能写成args=("周杰伦")t1 = Thread(target=func, args=("周杰伦",))t1.start()t2 = Thread(target=func, args=("王力宏",))t2.start()
多进程
from multiprocessing import Process # 进程类def funcc():for i in range(100):print("子进程", i)if __name__ == '__main__':p = Process(target=funcc)p.start()for i in range(100):print("主进程", i)
相关文章:
:图片下载、使用代理、防盗链视频下载、多线程与多进程)
【自用】Python爬虫学习(三):图片下载、使用代理、防盗链视频下载、多线程与多进程
Python爬虫学习(三) 使用BeautifulSoup解析网页并下载图片模拟用户登录处理使用代理视频下载,防盗链的处理多线程与多进程 使用BeautifulSoup解析网页并下载图片 目的:对某网站的某个专栏页面的图片进行下载得到高清图。 思路&am…...

#Datawhale AI夏令营第4期#AIGC方向Task3
在之前的任务中,我们已经对baseline进行了精读,并生成了,我们自己的八图故事。 在Task3中,我们的主要任务有两个:part1:工具初探一ComfyUI应用场景探索;Part2:Lora微调。 微调是一…...
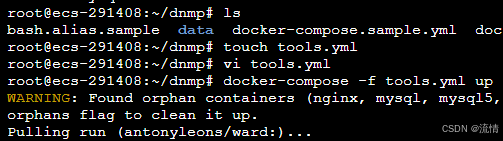
【docker综合篇】关于我用docker搭建了6个应用服务的事
最近一直在捣鼓docker,利用测试服务器,本着犯错就重来(重装系统)的大无畏精神,不断尝试,总结经验,然后在网上搜寻一些关于docker有关的服务镜像,并搭建起来。看着一个个服务在我的服务器跑起来,…...
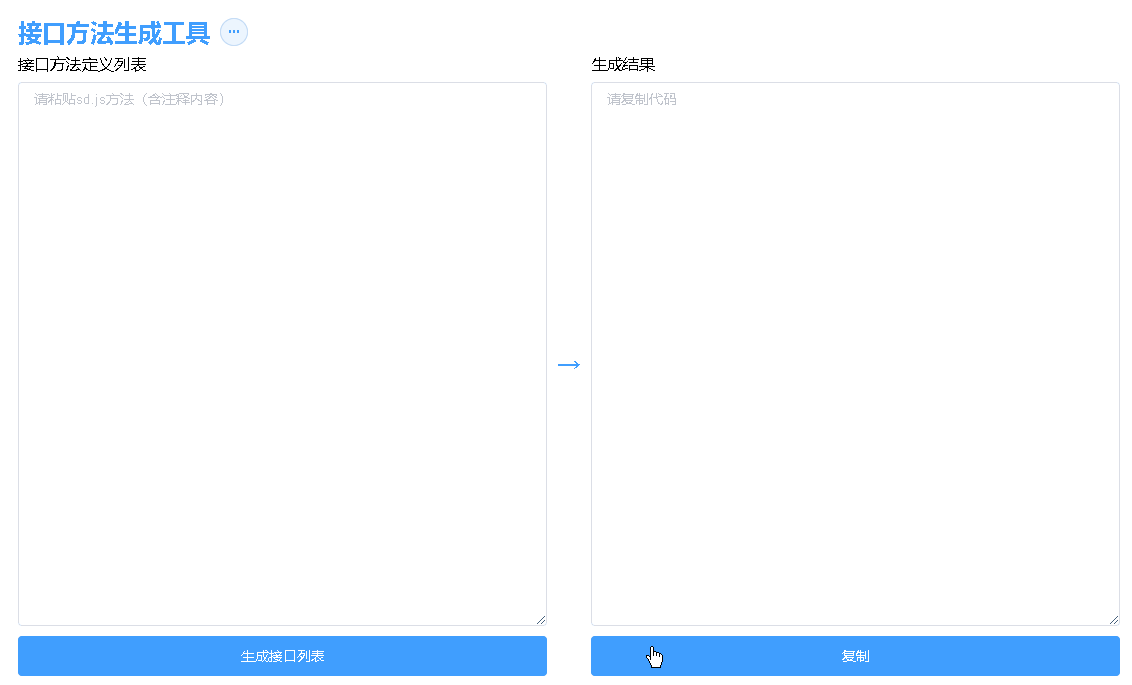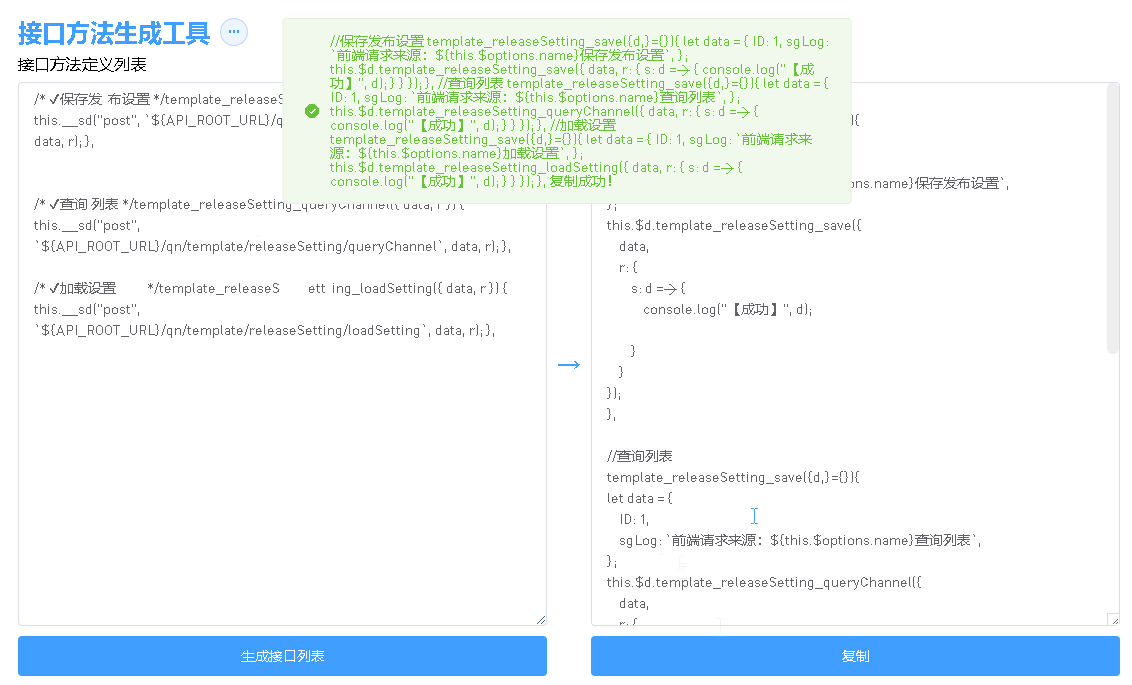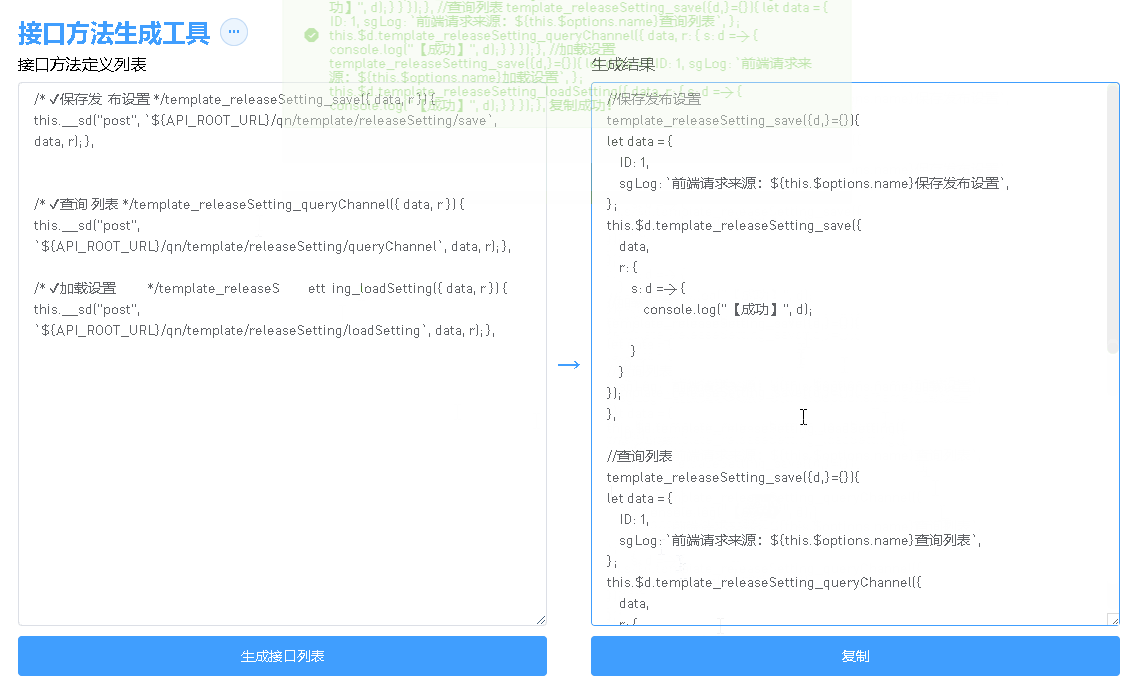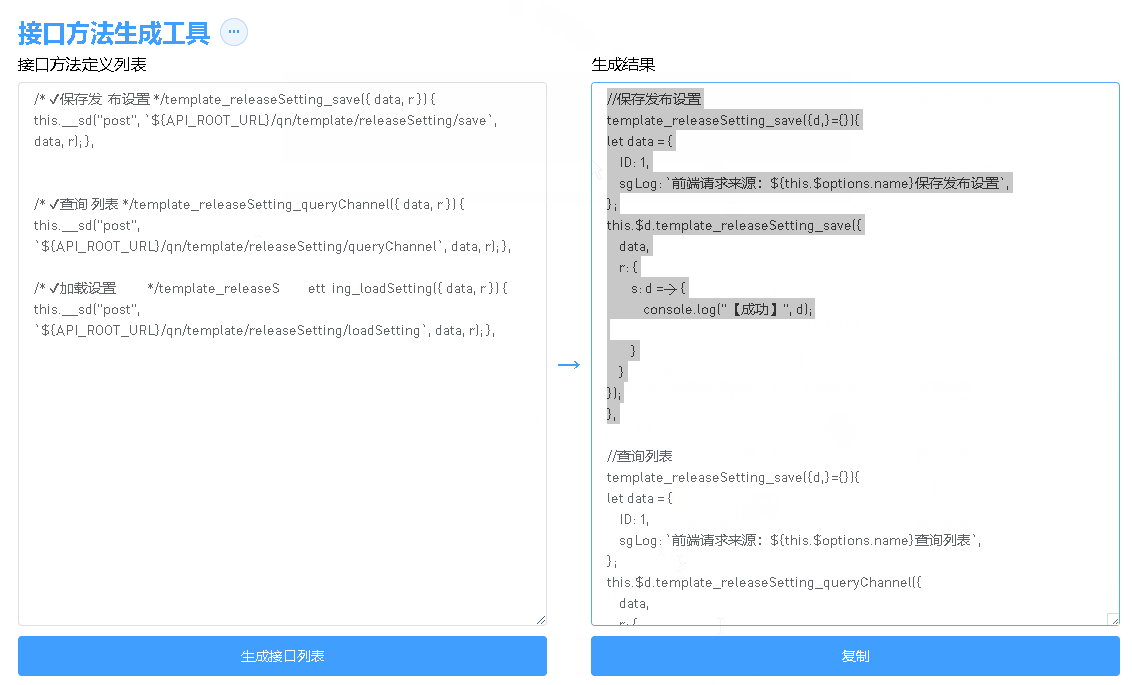
【sgCreateAPIFunction】自定义小工具:敏捷开发→自动化生成API接口方法代码片段脚本(接口方法代码生成工具)
sgCreateAPIFunction源码 <template><!-- 前往https://blog.csdn.net/qq_37860634/article/details/141159084 查看使用说明 --><div :class"$options.name"><div class"sg-head">接口方法生成工具<el-dropdown:show-timeou…...
)
Vue2图片懒加载(vue-lazyload)
参考文档:vue-lazyload 安装插件 npm install vue-lazyload # or yarn add vue-lazyload # or pnpm add vue-lazyload使用 使用方式 一: 所有懒加载图片的占位图使用同一张默认图片 引入并注册 // main.js import VueLazyload from vue-lazyload Vue…...
Jenkins-拉取代码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Jenkins环境配置(一)配置Maven环境(1)Maven下载(2)将Maven上传服务器(3&…...
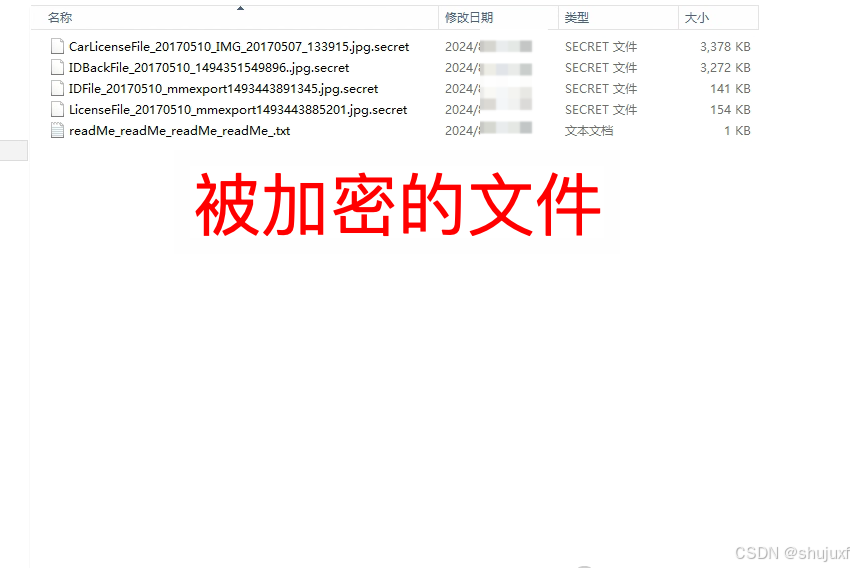
深度解析:.secret勒索病毒如何加密你的数据并勒索赎金
引言: 在当今这个数字化、信息化的时代,网络安全已成为一个不容忽视的重要议题。随着互联网的普及和技术的飞速发展,我们的生活、工作乃至整个社会的运转都越来越依赖于各种计算机系统和网络。然而,这种高度依赖也为我们带来了前…...

测试岗位应该学什么
以下是测试岗位需要学习的一些关键内容: 1. 测试理论和方法 - 了解不同类型的测试,如功能测试、性能测试、压力测试、安全测试、兼容性测试等。 - 掌握测试策略和测试计划的制定。 2. 编程语言 - 至少熟悉一种编程语言,如 Python、Java…...

【RISC-V设计-12】- RISC-V处理器设计K0A之验证环境
【RISC-V设计-12】- RISC-V处理器设计K0A之验证环境 文章目录 【RISC-V设计-12】- RISC-V处理器设计K0A之验证环境1.简介2.验证顶层3.顶层代码4.模型结构4.1 地址映射4.2 特殊功能寄存器 5.模型代码6.运行脚本7.总结 1.简介 在前几篇文章中,分别介绍了各个模块的设…...
react-redux的使用
关于react-redux 首先:react-redux和redux并不是一个东西,redux是一个独立的东西,react-redux是react官方根据市场偏好redux推出的react插件库。 了解react-redux的原理图: 安装:npm i react-redux redux的ui组件和…...

大模型在chat bi 场景下的优化思路
文章目录 背景提示词模版表结构注释示例数据给出示例答案语法验证外挂知识库 背景 大模型的出现使chat bi 成为一种可能,自然语句的交互,极大的提高了数据分析的效率,也极大的降低了用户使用的门槛。下面主要列出几点提高自然语句转成SQL的技…...
Qt登录窗口
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget),btn(new QPushButton("取消", this)),login_btn(new QPushButton("登录", this)) { ui->setupUi(this);thi…...

Zookeeper的在Ubuntu20.04上的集群部署
安装资源 官方安装包下载地址:https://zookeeper.apache.org/releases.html 懒得找版本的可以移步下载zookeeper3.84稳定版本: https://download.csdn.net/download/qq_43439214/89646735 安装方法 创建安装路径&&解压安装包 # 创建路径 m…...
Qt+OpenCV配置和测试
一、前言 OpenCV作为比较大众化的跨平台计算机视觉开源库,可以运行在多种操作系统上,通过与Qt的结合,能够轻松的是实现一些图像处理和识别的任务,本文在Windows操作系统的基础上具体讲解Qt和OpenCV的配置和环境搭建方法ÿ…...

Ruby GUI宝典:探索顶级图形界面库
标题:Ruby GUI宝典:探索顶级图形界面库 Ruby,这门以优雅和简洁著称的语言,不仅在服务器端编程中大放异彩,其在图形用户界面(GUI)开发上同样拥有不可忽视的地位。本文将带领大家深入了解Ruby的G…...

探索Jinja2的神秘力量:Python模板引擎的魔法之旅
文章目录 探索Jinja2的神秘力量:Python模板引擎的魔法之旅1. 背景:为何选择Jinja2?2. 什么是Jinja2?3. 安装Jinja2:一键启程4. 基础用法:Jinja2的五大法宝5. 实战演练:Jinja2在场景中的应用6. 常…...
Vue3小兔仙电商项目实战
Vue3小兔仙电商项目实战 项目技术栈 create-vuePiniaElementPlusVue3-SetupVue-RouterVueUse 项目规模 项目亮点: 基于业务逻辑的组件拆分思想 长页面吸顶交互实现SKU电商组件封装图片懒加载指令封装通用逻辑函数封装面板插槽组件等业务通用组件封装路由缓存问题…...
)
MATLAB基础应用精讲-【数模应用】肯德尔协调系数(附MATLAB、R语言和python代码实现)
目录 前言 几个高频面试题目 肯德尔协调系数低原因? 知识储备 相关性分析对比 1 相关分析 2 Cochrans Q 检验 3 Kappa一致性检验 4 Kendall协调系数 5 组内相关系数 算法原理 数学模型 SPSSPRO:Kendall一致性检验 1、作用 2、输入输出描述 3、案例示例 4、案…...

计算函数(c语言)
1.描述 //小乐乐学会了自定义函数,BoBo老师给他出了个问题,根据以下公式计算m的值。 // //其中 max3函数为计算三个数的最大值,如: max3(1, 2, 3) 返回结果为3。 //输入描述: //一行,输入三个整数ÿ…...

Linux 7 x86平台上安装达梦8数据库
1、环境描述 2、安装前准备 2.1 操作系统信息调研 Linux平台需要通过命令查看操作系统版本、位数、磁盘空间、内存等信息。 CPU信息 [rootray1 ~]# cat /proc/cpuinfo | grep -E "physical id|core id|cpu cores|siblings|cpu MHz|model name|cache size"|tail -n…...

3种完整破解方案深度解析:Beyond Compare 5授权密钥生成技术实现指南
3种完整破解方案深度解析:Beyond Compare 5授权密钥生成技术实现指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen BCompare_Keygen是一个基于Python 3开发的Beyond Compare 5.x版…...

手势传感器技术:原理、实现与应用解析
1. 手势传感器技术解析:从原理到实现手势传感器本质上是一种基于光学原理的交互设备,其核心技术在于利用红外光的发射与接收来捕捉用户手势动作。与传统的电容式触摸技术不同,手势传感器通过主动发射红外光并测量反射信号的变化,实…...

私域团队如何用企业微信 API 提升客户维护效率?
一、 场景描述:为什么你的团队每天都在“瞎忙”? 很多私域团队看似忙碌,实则效率低下。典型的现象包括: • 重复回答:每天 70% 的时间在复制粘贴相同的话术(如:发货时间、优惠券怎么领ÿ…...

基于MCP协议构建安全可控的AI智能体数据接入层
1. 项目概述:一个为智能体打造的“安全印章”与“情报中枢”最近在折腾AI智能体(Agent)的开发与集成,发现一个挺有意思的现象:大家把模型能力、工具调用这些“上层建筑”都玩得很溜,但一涉及到让智能体安全…...

电子束光刻掩模误差建模与校正技术解析
1. 电子束光刻中的掩模误差来源解析在半导体制造领域,电子束光刻技术因其高分辨率特性而被广泛应用于掩模制作。然而,这一工艺过程中产生的掩模误差会直接影响最终芯片的图形精度和良率。理解这些误差的物理成因是进行有效校正的前提。1.1 电子散射效应的…...

Swagger Skills:让OpenAPI文档活起来,实现自动化契约测试与场景编排
1. 项目概述:一个为Swagger API文档注入“技能”的利器如果你是一名后端开发者,或者经常需要与API打交道,那么Swagger(现在更常被称为OpenAPI)对你来说一定不陌生。它通过一个标准的YAML或JSON文件,清晰地描…...
)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集) 刚入坑深度学习的开发者,最头疼的莫过于环境配置。明明按照教程一步步安装了PyTorch或TensorFlow,却在代码运行时看到CUDA不可用…...

信息几何物理学:范式构建、本体坐标与世毫九理论科学谱系定位
信息几何物理学:范式构建、本体坐标与世毫九理论科学谱系定位 Information-Geometric Physics: Paradigm Construction, Ontological Coordinates and Scientific Pedigree Positioning of Shihao-9 Theory 作者:方见华 单位:世毫九实验室 摘要 当代人工智能与认知科学正…...

Python 爬虫进阶技巧:请求头 UA 随机伪装绕过基础检测
前言 当下绝大多数网站均部署了基础反爬检测机制,服务器会优先校验客户端请求身份标识,未携带合法浏览器标识、使用默认程序请求载体的爬虫请求,极易被直接拦截、封禁 IP、返回空数据或跳转拦截页面。爬虫默认发起请求时会自带程序原生 UA 标识,服务器可通过该标识直接识别…...

Awesome-AITools:AI开发者必备的开源工具聚合地图
1. 项目概述:一份AI工具的“藏宝图”如果你是一名AI开发者、研究者,或者只是一个对AI工具充满好奇的探索者,那么你肯定经历过这样的时刻:面对网络上浩如烟海的AI工具,从聊天机器人、代码助手到图像生成、模型训练平台&…...