基于chatGPT设计卷积神经网络
1. 简介
本文主要介绍基于chatGPT,设计一个针对骁龙855芯片设计的友好型神经网络。
提问->跑通总共花了5min左右,最终得到的网络在Cifar100数据集上与ResNet18的精度对比如下。
| 模型 | flops | params | train acc1/5 | test acc1/5 |
|---|---|---|---|---|
| ResNet18(timm) | 1.82 | 11.18 | ~98%/100% | 63.11%/86.11% |
| CNN-GPT | 1.51 | 6.66 | ~98%/100% | 68.44%/89.14% |
此外,GPT生成的模型训练速度更快,ResNet18才训练170个epoch,CNN-GPT已经完整地训练完了,具体的模型结构在文末,欢迎尝试使用~
个人认为比较有意思的一点是,GPT生成的模型并没有在stem block中就进行降采样,而是卷了一会之后才开始,这个与之前在文本任务中的经验结果类似,特征图越大,会避免信息损失。
基于chatGPT生成模型结构的方式或许在某些情况下可以解决我们的问题,但是基础的神经网络知识还是需要的,否则它给出的答案有些小bug,我们也不知道怎么修改。
模型训练结果与超参设置强相关,在这里仅设置默认的训练策略作为对比,根据训练结果看出,两个模型均过拟合严重。而且,不管是ResNet18或者CNN-GPT,均与Cifar100数据集的SOTA精度相差很远,此处需要注意。
2. 具体步骤
Step1 骁龙855芯片上可以正常运行的算子
基于上述问题,chatGPT给出的回答如下所示。
以下是在骁龙855芯片上比较友好的神经网络算子:1. Conv2d
2. Depthwise Conv2d
3. Maxpool2d
4. Avgpool2d
5. BatchNorm2d
6. ReLU
7. Flatten
8. Linear
整体看起来还算比较靠谱。
Step2 构建一个模型大小在10M左右的模型
针对上面的问题,chatGPT首先给出了思路。
如果想设计一个在骁龙855芯片上运行速度很快,模型大小在10M以内的模型,可以考虑使用以下方法来进行优化:1. 使用深度可分离卷积代替标准卷积,以获得更快的速度和更小的模型尺寸。
2. 使用深度方向的滤波器来替换全连接层,以减少参数数量并减少内存使用。
3. 对于每个卷积层,使用Batch Norm层来加速收敛。
4. 使用ReLU代替传统的Sigmoid或Tanh激活函数,因为ReLU的计算效率更高。
然后给出了一个模型示例。
以下是一个可以作为参考的模型:Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
BatchNorm2d(32)
ReLU()DepthwiseConv2d(32, kernel_size=3, stride=1, padding=1)
BatchNorm2d(32)
ReLU()Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
BatchNorm2d(64)
ReLU()DepthwiseConv2d(64, kernel_size=3, stride=1, padding=1)
BatchNorm2d(64)
ReLU()Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
BatchNorm2d(128)
ReLU()DepthwiseConv2d(128, kernel_size=3, stride=1, padding=1)
BatchNorm2d(128)
ReLU()Conv2d(128, 256, kernel_size=3, stride=2, padding=1)
BatchNorm2d(256)
ReLU()DepthwiseConv2d(256, kernel_size=3, stride=1, padding=1)
BatchNorm2d(256)
ReLU()Conv2d(256, 512, kernel_size=3, stride=2, padding=1)
BatchNorm2d(512)
ReLU()DepthwiseConv2d(512, kernel_size=3, stride=1, padding=1)
BatchNorm2d(512)
ReLU()Conv2d(512, 1024, kernel_size=3, stride=2, padding=1)
BatchNorm2d(1024)
ReLU()Avgpool2d(kernel_size=4)
Flatten()
Linear(1024, 10)
上面生成的模型有几个小问题。
- DepthwiseConv2d没有被定义
- DepthwiseConv2d的参数列表中没有out channel的参数,需要手动补充。
Step3 生成一个DepthwiseConv2d结构
chatGPT回答如下
以下是一个非常简单的torch的DepthwiseConv2d实现:
import torch.nn as nnclass DepthwiseConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=None):super(DepthwiseConv2d, self).__init__()if groups is None:groups = in_channelsself.depthwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups=groups)self.pointwise_conv = nn.Conv2d(out_channels, out_channels, 1, 1, 0, 1, groups=1)def forward(self, x):x = self.depthwise_conv(x)x = self.pointwise_conv(x)return x
加入到模型结构定义文件中,同时修改类别数,就可以进行模型训练了。
设置训练超参数
为保证对比的公平性,下面是训练过程中的一些超参数,
parser.add_argument("--epoch", type=int, default=240)parser.add_argument("--batch_size", type=int, default=64)parser.add_argument("--lr", type=float, default=0.05)parser.add_argument("--lr_decay_rate", type=float, default=0.1)parser.add_argument("--lr_decay_stages", type=str, default="150,180,210")parser.add_argument("--wd", type=float, default=0.0005)
3. 完整的模型结构
完整的模型结构如下,也欢迎大家在自己的数据集上尝试。
import torch
import torch.nn as nnclass DepthwiseConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=None):super(DepthwiseConv2d, self).__init__()if groups is None:groups = in_channelsself.depthwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups=groups)self.pointwise_conv = nn.Conv2d(out_channels, out_channels, 1, 1, 0, 1, groups=1)def forward(self, x):x = self.depthwise_conv(x)x = self.pointwise_conv(x)return xclass CNNGPT(nn.Module):def __init__(self) -> None:super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(32),nn.ReLU(),DepthwiseConv2d(32, 32, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(64),nn.ReLU(),DepthwiseConv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(128),nn.ReLU(),DepthwiseConv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(256),nn.ReLU(),DepthwiseConv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(512),nn.ReLU(),DepthwiseConv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 1024, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(1024),nn.AdaptiveAvgPool2d(1),nn.Flatten(),nn.Linear(1024, 100),)def forward(self, x):y = self.model(x)return ydef get_flops_params(model):from thop import profilemodel.eval()flops, params = profile(model,inputs=[torch.randn([1, 3, 224, 224]),],)print(f"flops: {flops/1000**3} G, params: {params/1000**2} M")return flops, paramsif __name__ == "__main__":model = CNNGPT()get_flops_params(model)相关文章:

基于chatGPT设计卷积神经网络
1. 简介 本文主要介绍基于chatGPT,设计一个针对骁龙855芯片设计的友好型神经网络。 提问->跑通总共花了5min左右,最终得到的网络在Cifar100数据集上与ResNet18的精度对比如下。 模型flopsparamstrain acc1/5test acc1/5ResNet18(timm)1.8211.18~98…...

java.sql.Date和java.util.Date的区别
参考答案 java.sql.Date 是 java.util.Date 的子类java.util.Date 是 JDK 中的日期类,精确到时、分、秒、毫秒java.sql.Date 与数据库 Date 相对应的一个类型,只有日期部分,时分秒都会设置为 0,如:2019-10-23 00:00:0…...
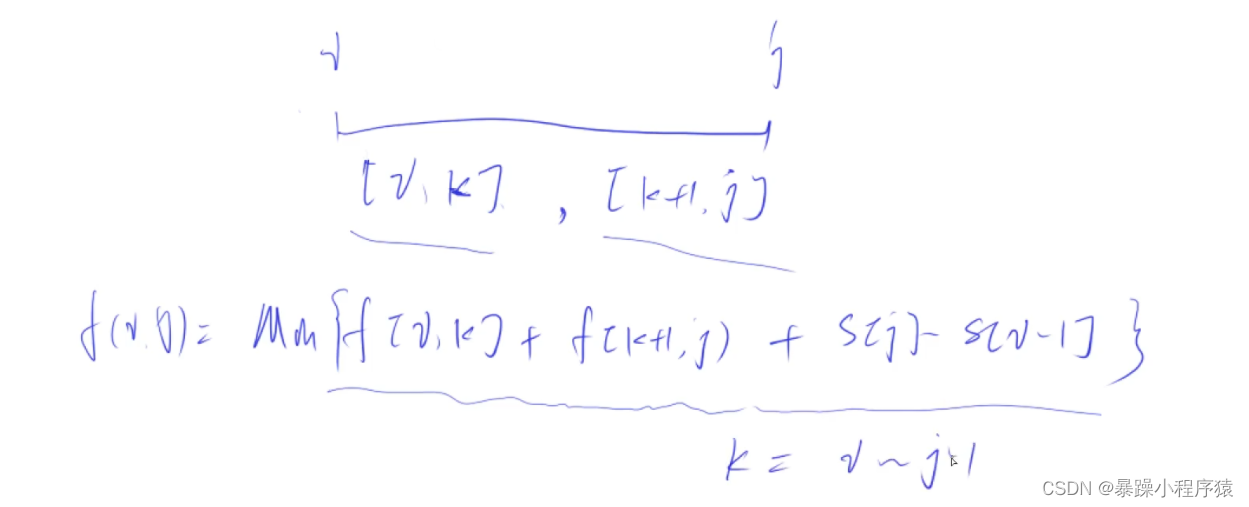
动态规划---线性dp和区间dp
动态规划(三) 目录动态规划(三)一:线性DP1.数字三角形1.1数字三角形题目1.2代码思路1.3代码实现(正序and倒序)2.最长上升子序列2.1最长上升子序列题目2.2代码思路2.3代码实现3.最长公共子序列3.1最长公共子序列题目3.2代码思路3.3代码实现4.石子合并4.1题目如下4.2代…...

常见的2D与3D碰撞检测算法
分离轴分离轴定理(Separating Axis Theorem)是用于解决2D或3D物体碰撞检测问题的一种方法。其基本思想是,如果两个物体未发生碰撞,那么可以找到一条分离轴(即一条直线或平面),两个物体在该轴上的…...

STM32 10个工程篇:1.IAP远程升级(二)
一直提醒自己要更新CSDN博客,但是确实这段时间到了一个项目的关键节点,杂七杂八的事情突然就一涌而至。STM32、FPGA下位机代码和对应Labview的IAP升级助手、波形设置助手上位机代码笔者已经调试通过,因为不想去水博客、凑数量,复制…...
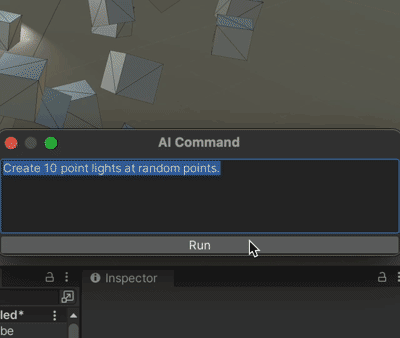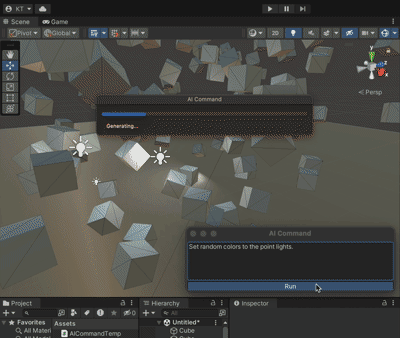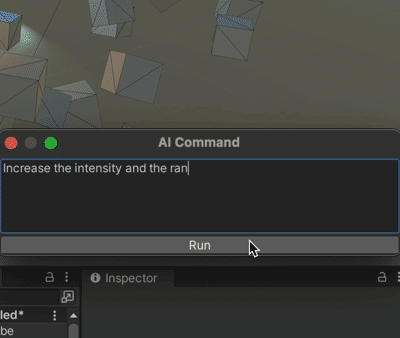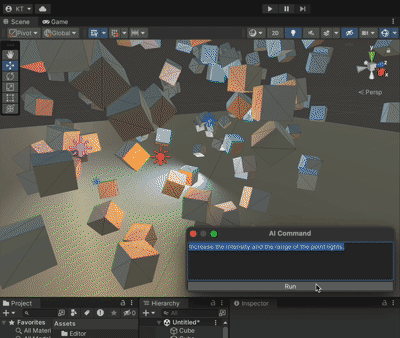
Unity+ChatGpt的联动 AICommand
果然爱是会消失的,对吗 chatGpt没出现之前起码还看人家的文章,现在都是随便你。 本着师夷长技以制夷的思路,既然打不过,那么我就加入 github地址:https://github.com/keijiro/AICommand 文档用chatGpt翻译如下&#…...
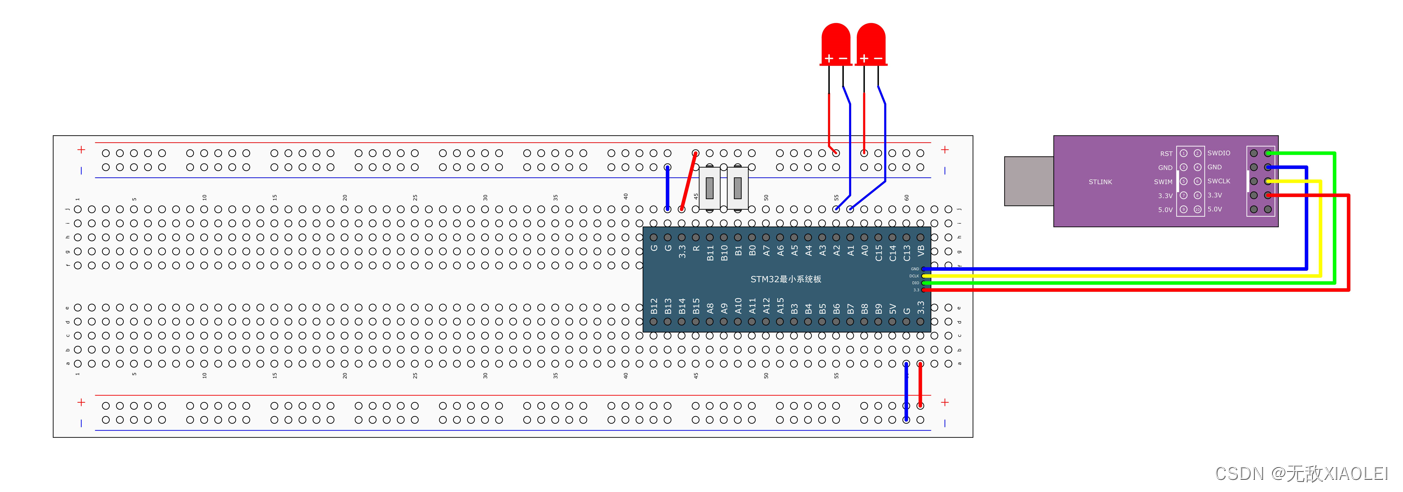
STM-32:按键控制LED灯 程序详解
目录一、基本原理二、接线图三、程序思路3.1库函数3.2程序代码注:一、基本原理 左边是STM322里电路每一个端口均可以配置的电路部分,右边部分是外接设备 电路图。 配置为 上拉输入模式的意思就是,VDD开关闭合,VSS开关断开。 浮空…...
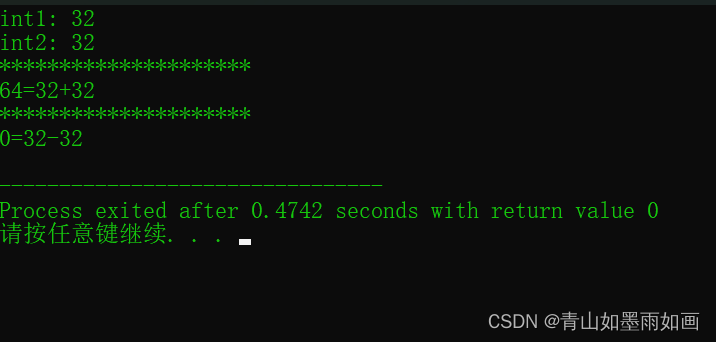
北邮22信通:(8)实验1 题目五:大整数加减法(搬运官方代码)
北邮22信通一枚~ 跟随课程进度每周更新数据结构与算法的代码和文章 持续关注作者 解锁更多邮苑信通专属代码~ 上一篇文章: 北邮22信通:(7)实验1 题目四:一元多项式(节省内存版)_青山如…...

Fiddler抓取https史上最强教程
有任何疑问建议观看下面视频 2023最新Fiddler抓包工具实战,2小时精通十年技术!!!对于想抓取HTTPS的测试初学者来说,常用的工具就是fiddler。 但是初学时,大家对于fiddler如何抓取HTTPS难免走歪路ÿ…...
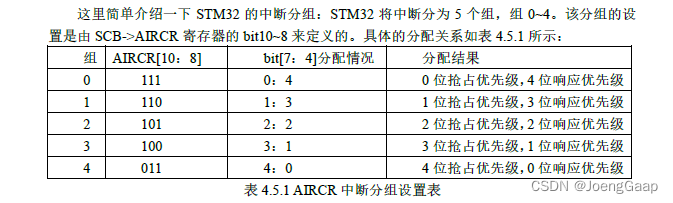
STM32开发基础知识入门
C语言基础 位操作 对基本类型变量可以在位级别进行操作。 1) 不改变其他位的值的状况下,对某几个位进行设值。 先对需要设置的位用&操作符进行清零操作,然后用|操作符设值。 2) 移位操作提高代码的可读性。 3) ~取反操作使用技巧 可用于对某…...

学习操作系统的必备教科书《操作系统:原理与实现》| 文末赠书4本
使用了6年的实时操作系统,是时候梳理一下它的知识点了 摘要: 本文简单介绍了博主学习操作系统的心路历程,同时还给大家总结了一下当下流行的几种实时操作系统,以及在工程中OSAL应该如何设计。希望对大家有所启发和帮助。 文章目录…...
)
大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学…...
【数据结构】详解二叉树与堆与堆排序的关系
🌇个人主页:平凡的小苏 📚学习格言:别人可以拷贝我的模式,但不能拷贝我不断往前的激情 🛸C语言专栏:https://blog.csdn.net/vhhhbb/category_12174730.html 🚀数据结构专栏ÿ…...
【Pandas】数据分析入门
文章目录前言一、Pandas简介1.1 什么是Pandas1.2 Pandas应用二、Series结构2.1 Series简介2.2 基本使用三、DataFrame结构3.1 DataFrame简介3.2 基本使用四、Pandas-CSV4.1 CSV简介4.2 读取CSV文件4.3 数据处理五、数据清洗5.1 数据清洗的方法5.2 清洗案例总结前言 大家好&…...
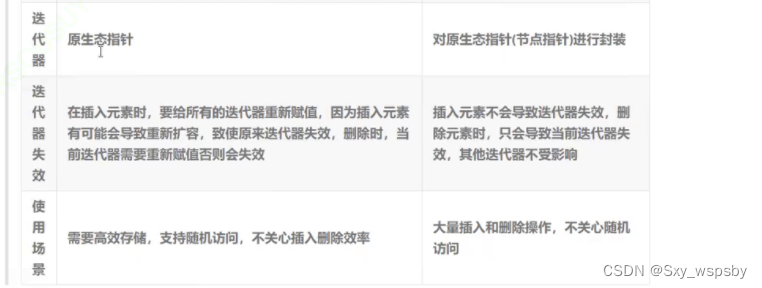
【c++】:list模拟实现“任意位置插入删除我最强ƪ(˘⌣˘)ʃ“
文章目录 前言一.list的基本功能的使用二.list的模拟实现总结前言 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中࿰…...

QT表格控件实例(Table Widget 、Table View)
欢迎小伙伴的点评✨✨,相互学习🚀🚀🚀 博主🧑🧑 本着开源的精神交流Qt开发的经验、将持续更新续章,为社区贡献博主自身的开源精神👩🚀 文章目录前言一、图示实例二、列…...

第二章Vue组件化编程
文章目录模块与组件、模块化与组件化模块组件模块化组件化Vue中的组件含义非单文件组件基本使用组件注意事项使用 kebab-case使用 PascalCase组件的嵌套模板templateVueComponent一个重要的内置功能单文件组件Vue脚手架使用Vue CLI脚手架先配置环境初始化脚手架分析脚手架结构实…...
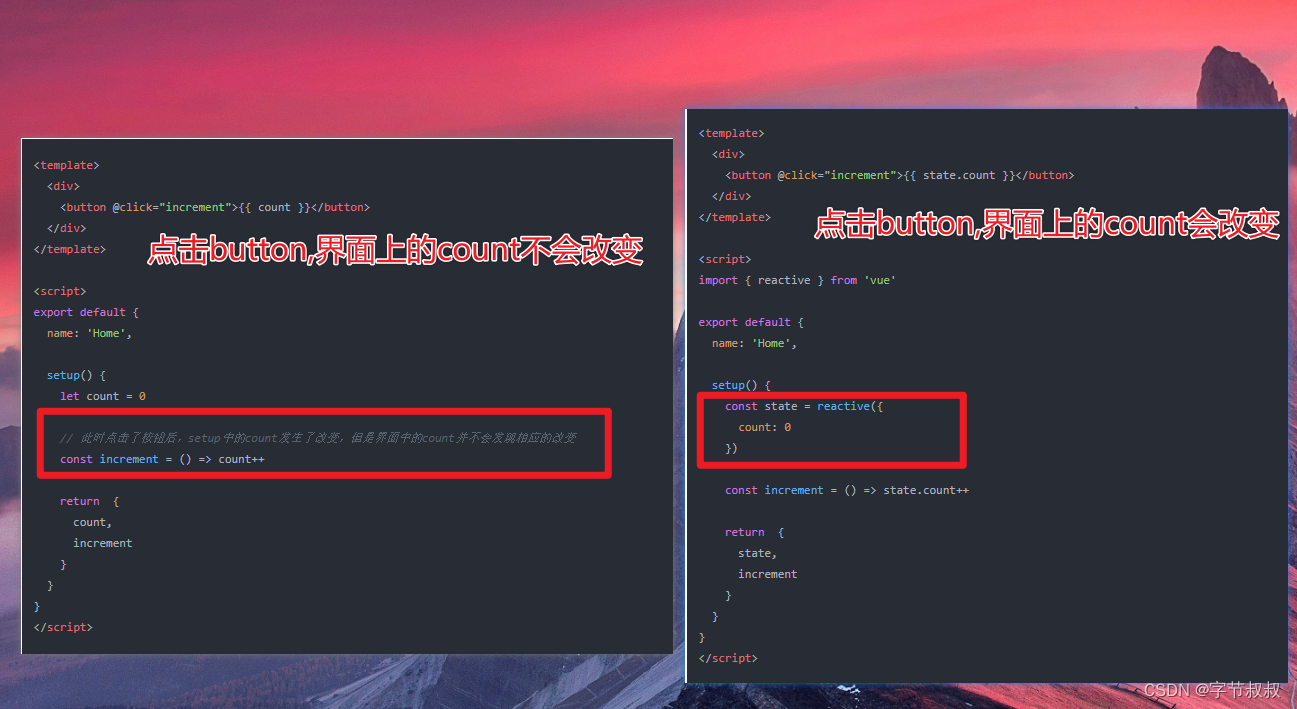
面试官:vue2和vue3的区别有哪些
目录 多根节点,fragment(碎片) Composition API reactive 函数是用来创建响应式对象 Ref toRef toRefs 去除了管道 v-model的prop 和 event 默认名称会更改 vue2写法 Vue 3写法 vue3组件需要使用v-model时的写法 其他语法 1. 创…...

【TopK问题】——用堆实现
文章目录一、TopK问题是什么二、解决方法三、时间复杂度一、TopK问题是什么 TopK问题就是从1000个数中找出前K个最大的数或者最小的数这样的类似问题。 不过并不要求这k个数字必须是有序的,如果题目有要求,则进行堆排序即可。 还有比如求出全国玩韩信…...

【Spring从成神到升仙系列 四】从源码分析 Spring 事务的来龙去脉
👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙…...

Google I/O 2026最魔幻的一幕:发新模型的同时,Google砍了自己的CLI
5月19号凌晨,我刚躺下准备刷会儿手机睡觉,结果被朋友圈刷屏了。 Google I/O 2026,总共两个小时的 keynote,愣是让我看到凌晨两点。不是因为我有多敬业,而是信息量实在太大——大到我觉得不记下来,明天就忘了…...

当“数字孪生”有了坐标、时序和一棵“会落叶的树”:NNU‑Campus‑Geo3DGS 数据集深度解读
地理编码的3D高斯,联结了数字重建与“真实地面”之间的两条坐标轴线假设你是一名城市规划师,面对一座城市的数字孪生模型——楼宇轮廓完整、道路走向清晰、绿化植被葱郁——但无论怎样旋转视角,这座模型都“悬浮”在地理基准面之上࿰…...

在OpenClaw项目中集成Taotoken实现Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中集成Taotoken实现Agent工作流 对于使用OpenClaw框架构建AI Agent的开发者而言,一个稳定、便捷的模型服…...

别再重复造轮子!用PADS自带转换器+立创EDA,5分钟搞定原理图符号同步
高效复用立创EDA资源:PADS原理图符号同步实战指南 在硬件设计领域,重复绘制原理图符号堪称工程师的"时间黑洞"。当你在立创EDA上发现完美的元器件模型时,为何还要在PADS中从零开始?本文将揭示一套被多数人忽视的PADS原生…...

从一颗2N5551看懂半导体散热:热阻Rja、Rjc到底怎么测?对我们选型有啥用?
从一颗2N5551看懂半导体散热:热阻Rja、Rjc到底怎么测?对我们选型有啥用? 拆开一颗塑料封装的2N5551三极管,你会看到指甲盖大小的黑色环氧树脂包裹着不到1平方毫米的硅晶片。这个微型结构在工作时产生的热量,可能让芯片…...

格式规范否?8款AI论文网站排名,毕业答辩稳了!
论文选题总在反复纠结,文献检索耗时又费力?写作过程中思路混乱,逻辑难以梳理?查重修改一遍又一遍,时间精力都被消耗殆尽? 别担心!AI论文工具正在成为高校学子的得力助手。本文将基于内容生成质量…...

Redis 集群脑裂深度剖析:成因、危害与防丢失策略
Redis 集群脑裂深度剖析:成因、危害与防丢失策略 1. 引言 在 Redis 高可用架构中,主从复制 哨兵(Sentinel)模式为我们提供了自动故障转移的能力。然而,在分布式系统中,网络并不可靠——脑裂(Sp…...

2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由
2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由 一、UWB:厘米级精度,困在硬件里的“昂贵精准” UWB(超宽带)凭借短脉冲、宽频谱特性,在理想视距环境下可实现5–10厘米定位精度࿰…...

OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 [特殊字符]
OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 🎨 【免费下载链接】openpose-editor Openpose Editor for AUTOMATIC1111s stable-diffusion-webui 项目地址: https://gitcode.com/gh_mirrors/op/openpose-editor 在AI绘画创作的世界里&…...

KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平
KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否曾经在对局后感到困惑,不知道自己的失误究竟在哪…...