Percona Toolkit 神器全攻略(复制类)
Percona Toolkit 神器全攻略(复制类)

Percona Toolkit 神器全攻略系列共八篇,前文回顾:
| 前文回顾 |
|---|
| Percona Toolkit 神器全攻略 |
| Percona Toolkit 神器全攻略(实用类) |
| Percona Toolkit 神器全攻略(配置类) |
| Percona Toolkit 神器全攻略(监控类) |
| Percona Toolkit 神器全攻略(系统类) |
| Percona Toolkit 神器全攻略(开发类) |
全文约定:
$为命令提示符、greatsql>为GreatSQL数据库提示符。在后续阅读中,依据此约定进行理解与操作
复制类
在Percona Toolkit中复制类共有以下工具
pt-heartbeat:监控MySQL/GreatSQL复制延迟pt-slave-delay:设定从落后主的时间pt-slave-find:查找和打印所有MySQL/GreatSQL复制层级关系pt-slave-restart:监控Salve错误,并尝试重启Salvept-table-checksum:校验主从复制一致性pt-table-sync:高效同步表数据pt-galera-log-explainer:对多个 Galera 日志进行过滤、聚合和汇总
pt-heartbeat
概要
用来监测主从延迟的情况,此工具的设计为向 Master 中插入一条带有当前时间(GreatSQL中的now()函数)的记录到心跳表中,然后,该记录会复制到 Slave 中。Slave 根据当前的系统时间戳(Perl中的time函数)减去heartbeat表中的记录值来判断主从的延迟情况。
用法
- pt-heartbeat [OPTIONS] [DSN] --update|--monitor|--check|--stop
选项
至少指定 --stop 、 --update 、 --monitor 或 --check 之一
互斥关系
--update 、 --monitor 和 --check 是互斥的
--daemonize 和 --check 是互斥的
该工具所有选项如下
| 参数 | 含义 |
|---|---|
| --ask-pass | 连接MySQL/GreatSQL提示输入密码 |
| --charset | 默认字符集 |
| --check | 检查一次从机延迟并退出 |
| --check-read-only | 检查服务器是否启用了read_only |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --create-table | 如果heartbeat表--table不存在,则创建它 |
| --create-table-engine | 设置用于heartbeat表的引擎 |
| --daemonize | 后台运行 |
| --database | 用于连接的数据库 |
| --dbi-driver | 指定连接的驱动程序 |
| --defaults-file | 只从给定文件中读取 GreatSQL 选项 |
| --file | 将最新的--monitor输出打印到此文件 |
| --frames | 平均值的时间范围,默认为1m,5m,15m |
| --help | 显示帮助 |
| --host | 连接到主机 |
| --[no]insert-heartbeat-row | 如果--table中不存在心跳行,则插入该行 |
| --interval | 更新或检查heartbeat表的频率,默认1秒 |
| --log | 后台运行时将所有输出打印到此文件 |
| --master-server-id | 根据此主服务器 ID 计算--monitor或--check的延迟 |
| --monitor | 连续监控从机延迟 |
| --fail-successive-errors | 如果指定,将在给定数量的连续 DBI 错误(无法连接到服务器或发出查询)后失败 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --print-master-server-id | 打印自动检测到的或给定的--master-server-id |
| --read-only-interval | 当指定--check-read-only 时,发现服务器处于只读状态时休眠的时间间隔 |
| --recurse | 在--check模式下递归检查从站到此深度 |
| --recursion-method | 用于查找从站的首选递归方法 |
| --replace | 使用REPLACE而不是UPDATE进行 –update |
| --run-time | 运行时间 |
| --sentinel | 如果该文件存在则退出 |
| --slave-user | 设置用于连接从站的用户 |
| --slave-password | 设置用于连接从站的密码 |
| --set-vars | 在这个以逗号分隔的variable=value对列表中设置 MySQL/GreatSQL 变量 |
| --skew | 延迟检查多久,默认值:0.5 |
| --socket | 用于连接的套接字文件 |
| --stop | 通过创建哨兵文件来停止运行实例 |
| --table | 用于心跳的表 |
| --update | 更新主机的心跳 |
| --user | 登录的用户 |
| --utc | 忽略系统时区并仅使用 UTC |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
最佳实践
为演示该工具,在主机上部署单机多实例并搭建一主一从模式,环境如下:
| 数据库 | IP | 端口号 | 角色 |
|---|---|---|---|
| GreatSQL-8.0.32-25 | 192.168.6.55 | 3306 | Master |
| GreatSQL-8.0.32-25 | 192.168.6.55 | 3307 | Slave |
首先需要在Master上添加表
$ pt-heartbeat --user=root --ask-pass -S /data/GreatSQL/mysql.sock -D test_db --master-server-id=103306 --create-table --update-D:选择一个数据库中有的库
--master-server-id:设置主机的server_id
--create-table:用于创建表
--update:会每秒更新一次heartbeat表的记录
现在进入Master上可以看到在test_db库下有一张heartbeat表,这里有一条记录的数据。在Slave节点上也应该出现这张表
greatsql> SELECT * FROM test_db.heartbeat;
+----------------------------+-----------+---------------+----------+-----------------------+---------------------+
| ts | server_id | file | position | relay_master_log_file | exec_master_log_pos |
+----------------------------+-----------+---------------+----------+-----------------------+---------------------+
| 2024-04-22T15:57:44.001900 | 103306 | binlog.000032 | 41464 | NULL | NULL |
+----------------------------+-----------+---------------+----------+-----------------------+---------------------+
1 row in set (0.00 sec)接下来我们更新主库上这张表,并让他在后台运行
$ pt-heartbeat --user=root --ask-pass -S /data/GreatSQL/mysql.sock -D test_db --master-server-id=103306 --update --daemonize进入从机,开始监控主从延迟
$ pt-heartbeat --user=root --ask-pass -S /data/GreatSQL02/mysql.sock -D test_db --master-server-id=103306 --monitor --print-master-server-id
Enter password:
0.00s [ 0.00s, 0.00s, 0.00s ] 103306
0.00s [ 0.00s, 0.00s, 0.00s ] 103306
0.00s [ 0.00s, 0.00s, 0.00s ] 103306
0.00s [ 0.00s, 0.00s, 0.00s ] 103306输出的结果为:实时延迟,[1分钟延迟,5分钟延迟,15分钟延迟] 主节点的Server_id
当然也可以使用
--interval参数控制主库上的更新间隔,默认是1秒如果使用守护进程的方式,要关闭的话可以采用
pt-heartbeat --stop单次查看Slave库上的延迟情况可以把
monitor换成--check
pt-slave-delay
概要
可能在日常工作中会存在误删除数据的可能,所以可以用该工具设置Slave服务器落后于Master服务器,达到构建一个延迟从库
原理
通过启动和停止复制SQL线程来设置Slave库落后于Master库的指定时间
用法
- pt-slave-delay [OPTIONS] SLAVE_DSN [MASTER_DSN]
选项
该工具所有选项如下
| 参数 | 含义 |
|---|---|
| --ask-pass | 连接时提示输入密码 |
| --charset | 默认字符集 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --[no]continue | 退出后继续正常复制 |
| --daemonize | 后台运行 |
| --database | 用于连接的数据库 |
| --defaults-file | 只从给定文件中读取MySQL/GreatSQL选项 |
| --delay | 从库延迟于主库的时间,默认1小时 |
| --help | 显示帮助 |
| --host | 连接到主机的IP地址 |
| --interval | 启动或停止的频率。默认1分钟 |
| --log | 后台运行时日志输出的位置 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --quiet | 不要打印有关操作的信息性消息 |
| --run-time | 运行时间,默认是一直运行 |
| --set-vars | 在这个以逗号分隔的variable=value对列表中设置 MySQL/GreatSQL 变量 |
| --socket | 用于连接的套接字文件 |
| --use-master | 从Master库获取二进制日志位置,而不从Slave库获取 |
| --user | 用于登录的用户 |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
最佳实践
此工具只需在Slave库运行即可,无需在Master节点运行
$ pt-slave-delay --user=root --ask-pass -S /data/GreatSQL02/mysql.sock --delay=1m --interval=15s --run-time=10m将主从延迟设定为1分钟,每15秒进行一次检测,持续运行10分钟
输出结果如下
2024-04-23T09:29:00 slave running 0 seconds behind
2024-04-23T09:29:00 STOP SLAVE until 2024-04-23T09:30:00 at master position binlog.000032/500611
2024-04-23T09:29:15 slave stopped at master position binlog.000032/500611
2024-04-23T09:29:30 slave stopped at master position binlog.000032/500611
......中间省略
2024-04-23T09:30:30 Setting slave to run normally如果在运行的过程中进入Slave节点查看SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: No可以看到SQL线程已关闭,证明此工具精准控制SQL线程的启停,有效实现主从延迟
也可使用
CHANGE REPLICATION SOURCE TO SOURCE_DELAY=3600;该命令来控制主从延迟的时间
pt-slave-find
概要
查找和打印主从架构中主库的从库个数,类似于拓扑图的意思
用法
- pt-slave-find [OPTIONS] [DSN]
选项
| 参数 | 含义 |
|---|---|
| --ask-pass | 连接MySQL/GreatSQL提示输入密码 |
| --charset | 默认字符集 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --databases | 仅检查此逗号分隔的数据库列表 |
| --defaults-file | 只从给定文件中读取 MySQL/GreatSQL 选项 |
| --help | 显示帮助 |
| --host | 连接到主机 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --recurse | 层次结构中要递归的级别数,默认为无限 |
| --recursion-method | 用于查找从库的首选递归方法,有三种 (processlist、hosts、none) |
| --report-format | 设置打印有关从库的哪些信息 |
| --resolve-address | 将 IP 地址解析为主机名 |
| --slave-user | 设置用于连接从库的用户 |
| --slave-password | 设置用于连接从库的密码 |
| --set-vars | 以逗号分隔的variable=value对列表中设置 MySQL/GreatSQL 变量 |
| --socket | 用于连接的套接字文件 |
| --user | 登录的用户 |
| --version | 显示版本 |
最佳实践
连接到主从集群的Master节点,查看该集群的复制层次数
$ pt-slave-find h=192.168.6.55,u=root --ask-pass
192.168.6.55
Version 8.0.32-25
Server ID 103306
Uptime 20:38:01 (started 2024-04-22T14:09:23)
Replication Is not a slave, has 1 slaves connected, is not read_only
Filters
Binary logging ROW
Slave status
Slave mode STRICT
Auto-increment increment 1, offset 1
InnoDB version 8.0.32-8.0.32
+- 192.168.6.55:3307Version 8.0.32-25Server ID 103307Uptime 20:35:59 (started 2024-04-22T14:12:02)Replication Is a slave, has 0 slaves connected, is not read_onlyFiltersBinary logging ROWSlave status 0 seconds behind, running, no errorsSlave mode STRICTAuto-increment increment 1, oInnoDB version 8.0.32-8.0.32可以看到该主节点下只有一个从节点,且输出也显示了主节点和总结点的信息
pt-slave-restart
概要
监视一个或多个 GreatSQL 复制从库是否有错误,并在复制停止时尝试重新启动复制
用法
- pt-slave-restart [OPTIONS] [DSN]
选项
| 参数 | 含义 |
|---|---|
| --always | 永不停止Slave线程 |
| --ask-pass | 连接MySQL/GreatSQL提示输入密码 |
| --charset | 默认字符集 |
| --[no]check-relay-log | 在检查从库错误之前检查最后一个中继日志文件和位置 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --daemonize | 后台运行 |
| --databases | 数据库列表 |
| --defaults-file | 只从给定文件中读取 MySQL/GreatSQL 选项 |
| --error-length | 要打印的错误消息的最大长度 |
| --error-numbers | 指定跳过哪些错误,可用,进行分隔 |
| --error-text | 根据错误的信息进行匹配跳过 |
| --help | 显示帮助 |
| --host | 连接到主机 |
| --log | 后台运行时,将输出打印到此文件 |
| --max-sleep | 再次轮询从库之前休眠的最长时间 |
| --min-sleep | 再次轮询从库之前休眠眠的最短时间 |
| --monitor | 是否监控从机(默认) |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --quiet | 抑制正常输出(禁用--verbose) |
| --recurse | 在主库执行,监控从库,默认深度 0 表示“仅监视指定的从库” |
| --recursion-method | 用于查找从库的首选递归方法 |
| --run-time | 运行时间 |
| --sentinel | 如果该文件存在则退出,默认值:/tmp/pt-slave-restart-sentinel |
| --slave-user | 设置用于连接从库的用户 |
| --slave-password | 设置用于连接从库的密码 |
| --set-vars | 以逗号分隔的variable=value 对列表中设置 MySQL/GreatSQL 变量 |
| --skip-count | 重新启动从库时要跳过的语句数,默认1 |
| --master-uuid | 使用 GTID 时,应创建一个空事务以便跳过它 |
| --sleep | 检查从库之间的初始睡眠秒数 |
| --socket | 用于连接的套接字文件 |
| --stop | 停止运行实例 |
| --until-master | 运行到指定的master_log_pos,file位置后停止 |
| --until-relay | 运行到指定的中继日志文件和位置后停止 |
| --user | 用于登录的用户 |
| --verbose | 向输出添加更多信息 |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
最佳实践
在主库创建一张t1表,并插入5条数据
greatsql> CREATE TABLE t1 (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(255) NOT NULL);
greatsql> INSERT INTO t1 (name) VALUES ('张三');
greatsql> INSERT INTO t1 (name) VALUES ('李四');
greatsql> INSERT INTO t1 (name) VALUES ('王五');
greatsql> INSERT INTO t1 (name) VALUES ('赵六');
greatsql> INSERT INTO t1 (name) VALUES ('孙七');主库查看数据
greatsql> SELECT * FROM test_db.t1;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 4 | 赵六 |
| 5 | 孙七 |
+----+--------+
5 rows in set (0.00 sec)从库查看数据
greatsql> SELECT * FROM test_db.t1;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 4 | 赵六 |
| 5 | 孙七 |
+----+--------+
5 rows in set (0.00 sec)主动处理错误
在从库执行pt-slave-restart工具监控从库
$ pt-slave-restart h=192.168.6.55,P=3307,u=root --ask-pass注意,若使用该工具,参数
slave_parallel_workers必须设置为0,否则会报错”Cannot skip transactions properly because GTID is enabled and slave_parallel_workers > 0. See 'GLOBAL TRANSACTION IDS' in the tool's documentation.“ 如果不关闭多线程复制,工具会分不清到底哪个线程复制出了问题
此时已经开启了从库监控,我们在主库上人为造成一个主从复制错误
greatsql> SET sql_log_bin=0;
greatsql> INSERT INTO t1 VALUES(6,'周八');
greatsql> SET sql_log_bin=1;
greatsql> DELETE FROM t1 WHERE id=6;此时工具检测到了主从复制异常,并且马上修复了该错误,使主从复制正常运行
$ pt-slave-restart h=192.168.6.55,P=3307,u=root --ask-pass
# 时间戳 + 从库端信息 + relay log + relat log 位置 + 主从复制报错码
2024-04-24T10:33:54 P=3307,h=192.168.6.55,u=root myarch-relay-bin.000003 36702 1032手动处理错误
如果一直运行工具,检测到错误会直接修复。如果是已经有错误了要如何使用该工具修复?还是同样的错误,再次主库手动执行
greatsql> SET sql_log_bin=0;
greatsql> INSERT INTO t1 VALUES(6,'周八');
greatsql> SET sql_log_bin=1;
greatsql> DELETE FROM t1 WHERE id=6;此时查看从库报错
greatsql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
Last_SQL_Error: Could not execute Delete_rows event on table test_db.t1; Can't find record in 't1', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000032, end_log_pos 504208记住报错的错误码1032,接着在从库机器上使用该工具
$ pt-slave-restart h=192.168.6.55,P=3307,u=root --ask-pass --error-numbers=1032使用
--error-numbers=指定错误码
此时就会输出对应的信息
$ pt-slave-restart h=192.168.6.55,P=3307,u=root --ask-pass --error-numbers=10322024-04-24T10:49:26 P=3307,h=192.168.6.55,u=root myarch-relay-bin.000003 37046 1032接着在从库上查看主从状态,就可以看到主从复制已经是正常的了
greatsql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_SQL_Error:pt-table-checksum
这款数据校验与修复工具虽广受欢迎,却存在不容忽视的短板:不支持MySQL/GreatSQL的MGR场景、国内普遍的上云下云业务,以及MySQL/GreatSQL与Oracle间的异构数据库等多元化场景。为了攻克这些难题,GreatSQL推出了名为gt-checksum的校验&修复工具,旨在全面满足各类业务需求!
- Gitee仓库地址:https://gitee.com/GreatSQL/gt-checksum
概要
检查 MySQL/GreatSQL 的主从数据是否一致
用法
- pt-table-checksum [OPTIONS] [DSN]
选项
| 参数 | 含义 |
|---|---|
| --ask-pass | 连接MySQL/GreatSQL提示输入密码 |
| --channel | 指定复制通道 |
| --[no]check-binlog-format | 检查所有服务器上的binlog_format系统参数是否相同 |
| --binary-index | 修改--create-replicate-table的行为,使复制表的上下边界列以 BLOB 数据类型创建 |
| --check-interval | 指定因选项--max-lag检查之间休眠时间 |
| --[no]check-plan | 检查查询执行计划的安全性 |
| --[no]check-replication-filters | 指定检测主从复制是否有设置复制过滤器 |
| --check-slave-lag | 指定复制延迟大于选项--max-lag指定的值之后暂停检查校验操作 |
| --[no]check-slave-tables | 检查从库上的表是否存在并具有所有校验和--columns |
| --chunk-index | 指定使用哪个索引对表进行chunk分块操作 |
| --chunk-index-columns | 指定使用选项--chunk-index的索引使用最左前缀几个索引字段,只适用于复合索引 |
| --chunk-size | 为每个校验和查询选择的行数,允许的后缀单位为k、M、G |
| --chunk-size-limit | 指定chunk的行数最多可以超过选项--chunk-size指定的行数的多少倍 |
| --chunk-time | 动态调整每个chunk的大小使相应的表行数都在指定的时间内完成校验操作 |
| --columns | 指定只需要校验的字段,如有多个则用逗号隔开 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --[no]create-replicate-table | 创建选项--replicate指定的数据库和表 |
| --databases | 仅对逗号分隔的数据库列表进行校验 |
| --databases-regex | 仅名称与此正则表达式匹配和数据库进行校验 |
| --defaults-file | 只从给定文件中读取 MySQL/GreatSQL 选项 |
| --disable-qrt-plugin | 如果启用了 QRT(查询响应时间)插件,请将其禁用 |
| --[no]empty-replicate-table | 在对表进行校验和之前,删除每个表之前的校验和 |
| --engines | 仅校验使用这些存储引擎的表 |
| --explain | 显示但不执行校验和查询(禁用--[no]empty-replicate-table) |
| --fail-on-stopped-replication | 若复制停止,则会失败并显示错误(退出状态 128),而不是等到复制重新启动 |
| --float-precision | FLOAT 和 DOUBLE 数字到字符串转换的精度 |
| --function | 指定校验操作使用的哈希函数。可选函数有SHA1、MD5等 |
| --help | 显示帮助 |
| --host | 连接到主机 |
| --ignore-columns | 指定需要忽略校验的字段 |
| --ignore-databases | 指定需要忽略校验的数据库 |
| --ignore-databases-regex | 指定采用正则表达式匹配忽略校验的数据库 |
| --ignore-engines | 指定需要忽略校验的存储引擎列表 |
| --ignore-tables | 指定需要忽略校验的表 |
| --ignore-tables-regex | 指定采用正则表达式匹配忽略校验的表 |
| --max-lag | 指定允许主从复制延迟时长的最大值,单位秒 |
| --max-load | 在每个块之后检查`SHOW GLOBAL STATUS,如果任何状态变量高于阈值则暂停 |
| --password | 连接时使用的密码 |
| --pause-file | 当此参数指定的文件存在时,执行将暂停 |
| --pid | 创建给定的 PID 文件 |
| --plugin | 定义pt_table_checksum_plugin类的 Perl 模块文件 |
| --port | 用于连接的端口号 |
| --progress | 将进度报告打印到 STDERR |
| --quiet | 仅打印最重要的信息(禁用 --progress ) |
| --recurse | 指定搜寻从库的层级,默认无限 |
| --recursion-method | 指定获取从库的方式 |
| --replicate | 将校验和结果写入此表 |
| --[no]replicate-check | 指定在校验完每张表后检查主从当前表是否出现不一致 |
| --replicate-check-only | 检查副本的一致性,而无需执行校验和查询 |
| --replicate-check-retries | 指定当校验出主从数据不一致重试校验的次数 |
| --replicate-database | 指定工具在执行校验操作时在哪个数据库下进行 |
| --resume | 指定从最后完成校验的chunk开始恢复校验 |
| --retries | 指定当出现非严重性错误时重复校验一个块的次数 |
| --run-time | 指定校验操作运行的时间 |
| --separator | 用于 CONCAT_WS() 的分隔符 |
| --skip-check-slave-lag | 指定DSN连接从库时跳过主从延迟检查,可以指定多个从库检查 |
| --slave-user | 设置用于连接从库的用户 |
| --slave-password | 设置用于连接从库的密码 |
| --set-vars | 运行检查时指定参数值,如有多个用逗号分隔 |
| --socket | 用于连接的套接字文件 |
| --slave-skip-tolerance | 当主表被标记为仅在一个块中进行校验和,但从表超过了可接受的最大大小时,该表将被跳过 |
| --tables | 仅对这个以逗号分隔的表列表进行校验和 |
| --tables-regex | 仅对名称与此 Perl 正则表达式匹配的表进行校验 |
| --trim | 将 TRIM() 添加到 VARCHAR 列(在比较 4.1 和 >= 5.0 时有帮助) |
| --truncate-replicate-table | 在开始校验和之前截断复制表 |
| --user | 登录的用户 |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
| --where | 仅执行与此 WHERE 子句匹配的行 |
最佳实践
校验主从数据是否一致(主从端口一致)
主从机器端口一致时,可以使用此方法
检测差异,并写入差异到checksums表中,主库上执行如下命令
pt-table-checksum --create-replicate-table --replicate=test_db.checksums --nocheck-replication-filters --nocheck-binlog-format --recursion-method=processlist --databases=test_db --user=root --ask-pass --host=192.168.6.55 --port=3306--nocheck-replication-filters:不检查复制过滤器,建议启用
--no-check-binlog-format:不检查复制的binlog模式,要是binlog模式是ROW,则会报错
结果如下
Checking if all tables can be checksummed ...
Starting checksum ...TS ERRORS DIFFS ROWS DIFF_ROWS CHUNKS SKIPPED TIME TABLE
04-24T15:57:13 0 0 9 0 1 0 0.008 test_db.test_t1- TS:完成检查的时间
- ERRORS:检查时候发生错误和警告的数量
- DIFFS:0表示一致,非0表示不一致
- DIFF_ROWS:主库和从库差异的数据行数
- CHUNKS:被划分到表中的块的数目
- SKIPPED:由于错误或警告或过大,则跳过块的数目
- TIME:执行的时间
- TABLE:被检查的表名
同时结果也保存到了表中
greatsql> select * from checksums;
+---------+--------------------+-------+------------+-------------+----------------+----------------+----------+----------+------------+------------+---------------------+
| db | tbl | chunk | chunk_time | chunk_index | lower_boundary | upper_boundary | this_crc | this_cnt | master_crc | master_cnt | ts |
+---------+--------------------+-------+------------+-------------+----------------+----------------+----------+----------+------------+------------+---------------------+
| test_db | t1 | 1 | 0.001848 | NULL | NULL | NULL | 6d60e23f | 5 | 6d60e23f | 5 | 2024-04-24 16:29:30 |
+---------+--------------------+-------+------------+-------------+----------------+----------------+----------+----------+------------+------------+---------------------+
1 rows in set (0.01 sec)校验主从数据是否一致(主从端口不一致)
主从机器端口不一致时,可以使用此方法
在主库创建一张DSN表
greatsql> CREATE TABLE test_db.dsns ( id int(11) NOT NULL AUTO_INCREMENT, parent_id int(11) DEFAULT NULL,dsn varchar(255) NOT NULL, PRIMARY KEY (id) );greatsql> INSERT INTO test_db.dsns(dsn) VALUES ('h=192.168.6.55,P=3307,u=root,p=');使用工具校验,注意此时--recursion-method就要改为DSN模式
$ pt-table-checksum --replicate=test_db.checksums --nocheck-replication-filters --no-check-binlog-format --host=192.168.6.55 --port=3306 --user=root --ask-pass --databases=test_db --recursion-method dsn=h=192.168.6.55,D=test_db,t=dsns结果如下
Checking if all tables can be checksummed ...
Starting checksum ...TS ERRORS DIFFS ROWS DIFF_ROWS CHUNKS SKIPPED TIME TABLE
04-24T17:04:42 0 0 1 0 1 0 0.035 test_db.dsns
04-24T17:04:42 0 0 1 0 1 0 0.022 test_db.heartbeat
04-24T17:04:42 0 0 0 0 1 0 0.036 test_db.my_table
04-24T17:04:42 0 2 10000 9823 4 0 0.097 test_db.ptosc
04-24T17:04:42 0 0 5 0 1 0 0.021 test_db.t1
04-24T17:04:42 0 1 15 15 1 0 0.026 test_db.tc10011_ta4
04-24T17:04:42 0 1 9 9 1 0 0.078 test_db.test_t1
04-24T17:04:42 0 0 0 0 1 0 0.066 test_db.test_table可以看到有三张表被检测出来不一致。如果连表都不存在则会报错Table 'XXXX' doesn't exist
出现了主从数据不一致,就要使用pt-table-sync工具进行修复
pt-table-sync
概要
高效同步 MySQL/GreatSQL 表数据
用法
- pt-table-sync [OPTIONS] DSN [DSN]
选项
至少指定 --print 、 --execute 或 --dry-run 之一。--where 和 --replicate 是互斥的
| 参数 | 含义 |
|---|---|
| --algorithms | 比较表时使用的算法(按优先顺序),默认值:Chunk、Nibble、GroupBy、Stream |
| --ask-pass | 连接 MySQL/GreatSQL 提示输入密码 |
| --bidirectional | 启用第一个和后续主机之间的双向同步 |
| --[no]bin-log | 指定同步操作记录二进制日志,相当于执行SET SQL_LOG_BIN=1 |
| --buffer-in-mysql | 指定 MySQL/GreatSQL 在其内存中缓冲查询 |
| --[no]buffer-to-client | 比较时从 MySQL/GreatSQL 中逐一获取行 |
| --channel | 指定复制通道 |
| --charset | 默认字符集 |
| --[no]check-child-tables | 检查--execute是否会对子表产生不利影响 |
| --[no]check-master | 指定当选项--sync-to-master时,尝试验证工具连接到的主库是否是真正的主库 |
| --[no]check-slave | 检查目标服务器是否为从服务器 |
| --[no]check-triggers | 检查目标表上是否未定义触发器 |
| --chunk-column | 指定根据表中字段对表进行chunk操作 |
| --chunk-index | 指定使用哪个索引对表进行chunk分块操作 |
| --chunk-size | 每个块的行数或数据大小 |
| --columns | 比较以逗号分隔的列列表 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --conflict-column | 当--bidirectional同步期间发生行冲突时比较此列 |
| --conflict-comparison | 选择具有此属性的--conflict-column作为源 |
| --conflict-error | 如何报告无法解决的冲突和冲突错误,默认为:warn(警告) |
| --conflict-threshold | 一个--conflict-column必须超过另一个的数量 |
| --conflict-value | 将此值用于某些--conflict-comparison |
| --databases | 仅同步的数据库列表,如有多个用逗号分隔 |
| --defaults-file | 只从给定文件中读取 GreatSQL 选项 |
| --dry-run | 分析、决定要使用的同步算法、打印并退出 |
| --engines | 仅同步的存储引擎列,如有多个用逗号分隔 |
| --execute | 执行查询以使表具有相同的数据 |
| --explain-hosts | 打印连接信息并退出 |
| --float-precision | FLOAT 和 DOUBLE 数字到字符串转换的精度 |
| --[no]foreign-key-checks | 启用外键检查 (SET FOREIGN_KEY_CHECKS=1) |
| --function | 选择使用哪个哈希函数作为校验和,默认为 CRC32 |
| --help | 显示帮助 |
| --[no]hex-blob | HEX() BLOB、TEXT和 BINARY列 |
| --host | 连接到主机 |
| --ignore-columns | 要忽略的列,如有多个用逗号分隔 |
| --ignore-databases | 要忽略的数据库,如有多个用逗号分隔 |
| --ignore-engines | 要忽略的引擎,如有多个用逗号分隔 |
| --ignore-tables | 要忽略的表,如有多个用逗号分隔 |
| --ignore-tables-regex | 要忽略的表正则表达式,如有多个用逗号分隔 |
| --[no]index-hint | 将 FORCE/USE INDEX 提示添加到块和行查询中 |
| --lock | 锁定表:0=永不锁表,1=每个同步周期锁表,2=表操作时锁表,3=每个DSN连接的服务器锁表 |
| --lock-and-rename | 指定锁定源表和目标表,执行同步操作,然后进行表名交换 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| 打印将解决差异的查询 | |
| --recursion-method | 用于查找从站的首选递归方法 |
| --replace | 将所有INSERT和UPDATE语句写为REPLACE |
| --replicate | 同步此表中列为不同的表 |
| --slave-user | 设置用于连接从库的用户 |
| --slave-password | 设置用于连接从库的密码 |
| --set-vars | 以逗号分隔的variable=value对列表中设置 MySQL/GreatSQL 变量 |
| --socket | 用于连接的套接字文件 |
| --sync-to-master | 指定将DSN连接信息确认为从库,并同步信息到主库 |
| --tables | 要同步的表,如有多个用逗号分隔 |
| --timeout-ok | 指定当选项--wait导致工具执行失败时跳过失败继续执行 |
| --[no]transaction | 指定工具操作使用事务代替LOCK TABLES语句进行锁表 |
| --trim | BIT_XOR 和 ACCUM 模式下的 TRIM() VARCHAR 列 |
| --[no]unique-checks | 启用唯一键检查 ( SET UNIQUE_CHECKS=1 ) |
| --user | 用于连接的用户 |
| --verbose | 打印同步操作的结果 |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
| --wait | 指定存在主从复制延迟时从库可以等待多长时间追上主库,如果超过时间依然存在延迟就中止退出 |
| --where | WHERE 子句用于限制同步到表的一部分 |
| --[no]zero-chunk | 为具有零或零等值的行添加块 |
最佳实践
同步单个表
注意,同步时候两台机器不能是主从关系。第一DSN为源库,第二个DSN为被同步库
将192.168.6.55机器上的test_db.test_t1表同步至192.168.6.129机器
$ pt-table-sync --execute h=192.168.6.55,u=root,p=,P=3306,D=test_db,t=test_t1 h=192.168.6.129,p=test,u=test,P=3306同步单个库
注意,同步时候两台机器不能是主从关系。第一DSN为源库,第二个DSN为被同步库
$ pt-table-sync --execute h=192.168.6.55,u=root,p=,P=3306 h=192.168.6.129,u=test,p=test --databases test_db此时如果有表不存在,则会报错
Table test_db.checksums does not exist on P=3306,h=192.168.6.129,p=...,u=test while doing test_db.checksums on 192.168.6.129此时只需手动建表即可
同步所有库表
注意,同步时候两台机器不能是主从关系。第一DSN为源库,第二个DSN为被同步库
$ pt-table-sync --execute h=192.168.6.55,u=root,p=,P=3306 h=192.168.6.129,u=test,p=test主从复制同步从库
同步test_db.checksums中记录的数据不一致的表。该表中的数据是由pt-table-checksum工具检测出来的
$ pt-table-sync --execute --replicate 'test_db.checksums' --sync-to-master h=192.168.6.55,P=3307,u=root,p=本文完 :) 下章节将介绍Percona Toolkit 神器全攻略(性能类)
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。
相关文章:
Percona Toolkit 神器全攻略(复制类)
Percona Toolkit 神器全攻略(复制类) Percona Toolkit 神器全攻略系列共八篇,前文回顾: 前文回顾Percona Toolkit 神器全攻略Percona Toolkit 神器全攻略(实用类)Percona Toolkit 神器全攻略(配…...

SQLite3 数据类型深入全面讲解
SQLite3,作为一款轻量级的数据库管理系统,在数据存储方面展现出了其独特的魅力。它不仅支持标准的SQL语法,还提供了丰富的数据类型供开发者选择。这些数据类型不仅涵盖了基本的数值和文本类型,还包括了日期时间、二进制数据等复杂…...
及其插入和查找操作)
Python高效实现Trie(前缀树)及其插入和查找操作
Python高效实现Trie(前缀树)及其插入和查找操作 在Python面试中,考官通常会关注候选人的编程能力、问题解决能力以及对Python语言特性的理解。Trie(前缀树)是一种高效的数据结构,广泛应用于字符串处理、自动补全、拼写检查等场景。本文将详细介绍如何实现一个Trie,并提…...

傅里叶变换家族
禹晶、肖创柏、廖庆敏《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》 禹晶、肖创柏、廖庆敏《数字图像处理》资源二维码...

深度学习——强化学习算法介绍
强化学习算法介绍 强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment)里面去极大化它能获得的奖励。 强化学习和监督学习 强化学习有这个试错探索(trial-and-error exploration),它需要通过探索环境来获取对环境的理解。强化学习 ag…...
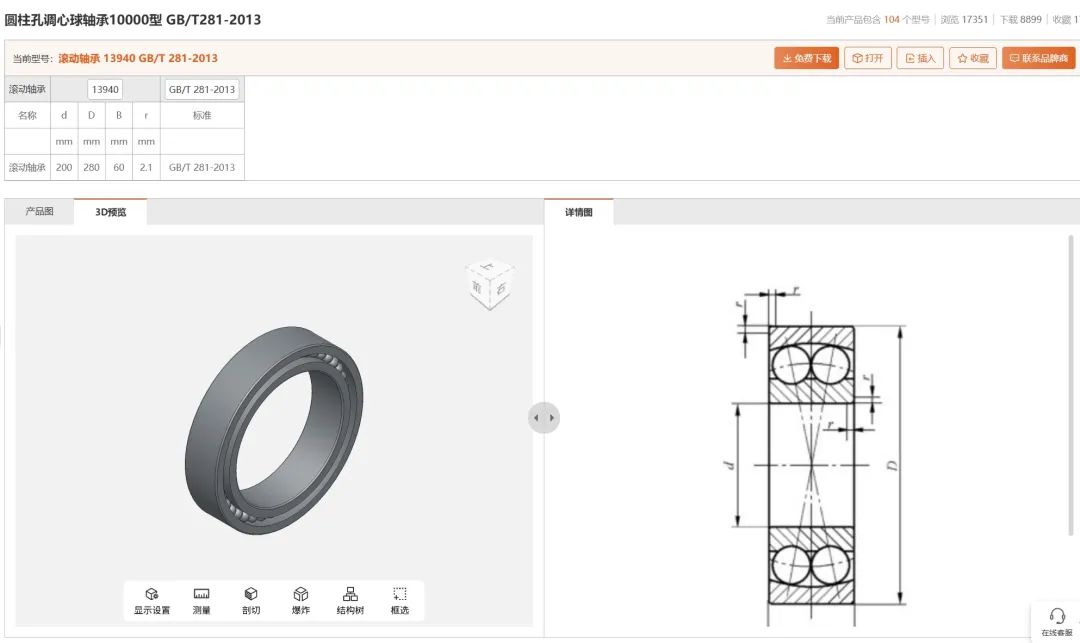
轴承知识大全,详细介绍(附3D图纸免费下载)
轴承一般由内圈、外圈、滚动体和保持架组成。对于密封轴承,再加上润滑剂和密封圈(或防尘盖)。这就是轴承的全部组成。 根据轴承使用的工作状况来选用不同类型的轴承,才能更好的发挥轴承的功能,并延长轴承的使用寿命。我…...

【PyTorch】基础环境如何打开
前期安装可以基于这个视频,本文是为了给自己存档如何打开pycharm和jupyter notebookPyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili Pycharm 配置 新建项目的时候选择解释器pytorch-gpu即可。 Jupyte…...

QT教程:QTime和QTimer的使用场景
QTime类 QTime 是一个用来表示和操作时间的类,它处理一天中的具体时间(例如小时、分钟、秒、毫秒)。通常用于计算时间间隔、记录时间戳、获取当前时间等。 特点和功能 表示时间:QTime 用来表示一天中的某个具体时间(小…...

MySQL 迁移中 explicit_defaults_for_timestamp 参数影响
前言 最近在做数据迁移的时候,使用的是云平台自带的同步工具,在预检查阶段,当时报错 explicit_defaults_for_timestamp 参数在目标端为 off 建议修改 on,有什么风险呢?在此记录下。 测试对比 MySQL 默认情况下 expl…...

树状数组记录
树状数组(Fenwick Tree)是一种用于维护数组前缀和的数据结构,支持高效的单点更新和区间查询操作。它的查询和更新时间复杂度为 O ( log n ) O(\log n) O(logn),适用于需要频繁更新和查询的场景。 树状数组的基本操作 单点更…...
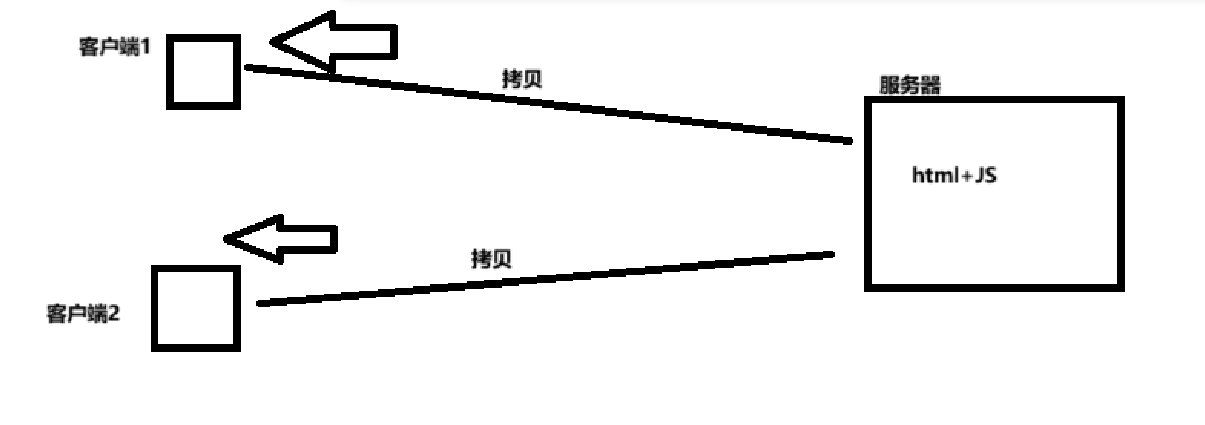
客户端时间和服务器时间的区别
客户端时间: 服务器向客户端拷贝一份前端内容,客户端通过JS获取时间,这样获取的是客户端时间 服务器时间: 服务器通过java代码获取的时间传输给客户端,这样获取的是服务器时间 当有些时候需要使用客户端时间…...

已入职华为!!关于我成功拿下华为大模型算法岗经验总结
方向:大模型算法工程师 整个面试持续了1小时10分钟,能够看出面试官是典型搞技术的,问的很专业又很细,全程感觉压力好大,面完后感觉丝丝凉意,不过幸好还是成功拿下了Offer 一面: 自我介绍 简历项目深度交流 1.项目的背…...

从安卓开发到AI产品经理——我的AI绘画之旅
大家好,我是一名有着多年安卓开发经验的程序员。在日复一日的编码生活中,我对AI行业产生了浓厚的兴趣。于是,我决定转行成为一名AI产品经理。在这个过程中,我通过学习AI绘画工具初步了解了AI行业,下面我将分享我的学习…...

代码随想录八股训练营第三十四天| C++
前言 一、vector和list的区别? 1.1.存储方式: 1.2.随机访问: 1.3.插入和删除操作: 1.4.内存使用: 1.5.容量和大小: 1.6.迭代器类型: 1.7.用途: 二、vector 底层原理和扩容过…...

《深入理解 Java 中的 this 关键字》
目录 一、this关键字的基本理解 二、this调用属性和方法 (一)一般情况 (二)特殊情况 三、this调用构造器 四、案例分析 (一)Account类 (二)Customer类 (三&…...

python文件自动分类(5)
完成了文件自动分类的操作后,我们一起来复习下: 首先,获取文件夹中所有文件名称,用 os.path.join() 函数拼接出要移动到的目标地址。然后,使用 os.path.exists() 函数判断目标文件夹是否存在,不存在用 os.m…...

【Unity-Lua】音乐播放器循环滚动播放音乐名
前言:Unity中UI节点 图1 如上所示,一开始本来是打算用ScrollView做的,觉得直接计算对应的文本位置就行,所以没用ScrollRect来做,可以忽略Scroll,Viewport这些名字。如下图:需要在一个背景Image…...

宏碁扩展Swift系列,推出四款全新AI笔记本电脑
Acer正在扩展其Swift笔记本产品线,推出四款新型号,每款都内置了AI功能。这些笔记本提供诸如Microsoft Copilot、Acer用户感应技术、Windows Studio效应、PurifiedVoice 2.0和PurifiedView等功能。其他功能还包括Wi-Fi 7和Bluetooth 5.4连接。 我们先来看…...

科研绘图系列:R语言差异基因四分图(Quad plot)
文章目录 介绍加载R包导入数据数据预处理画图参考介绍 四分图(Quad plot)是一种数据可视化技术,通常用于展示四个变量之间的关系。它由四个子图组成,每个子图都显示两个变量之间的关系。四分图的布局通常是2x2的网格,每个格子代表一个变量对的散点图。 在四分图中,通常…...

文字或图案点选坐标点返回
最近看到这篇文章中讲到极验图片验证码破解方案 https://blog.geetest.com/article/65aaaa944edc5ec343ba9f52efef0cdc 其中核心解决步骤如下,作者还贴心的贴出了CNN代码,真是用心良极: step 3:批量下载存储验证图片,…...

55、RAII技术---------多线程、竟态条件和同步
RAII技术RAII(Resource Acquisition Is Initialization,资源获取即初始化)是一种C编程技术,它将资源的获取(例如分配的堆内存、打开的文件、锁定的互斥量等)与对象的生命周期绑定在一起。具体来说ÿ…...

数据伦理革命:从泰坦尼克号数据集看公共数据的责任边界
数据伦理革命:从泰坦尼克号数据集看公共数据的责任边界 【免费下载链接】awesome-public-datasets A topic-centric list of HQ open datasets. 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-public-datasets 公共数据是数字时代的重要资源&am…...

中文近义词工具包Synonyms的终极发展蓝图:AI时代如何重塑自然语言处理
中文近义词工具包Synonyms的终极发展蓝图:AI时代如何重塑自然语言处理 【免费下载链接】Synonyms :herb: 中文近义词:聊天机器人,智能问答工具包 项目地址: https://gitcode.com/gh_mirrors/sy/Synonyms Synonyms是一款强大的中文近义…...

从‘炼丹’到‘产线’:手把手教你用AutoDockTools和Python脚本搭建可复现的批量分子对接流程
从‘炼丹’到‘产线’:手把手教你用AutoDockTools和Python脚本搭建可复现的批量分子对接流程 在药物发现和生物分子相互作用研究中,分子对接技术已成为虚拟筛选和先导化合物优化不可或缺的工具。然而,当面对数十甚至上百个小分子配体时&#…...

终极Windows驱动清理指南:DriverStore Explorer轻松释放20GB磁盘空间
终极Windows驱动清理指南:DriverStore Explorer轻松释放20GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间越来越少,却不…...

我不是狐狸,我是那Harness Engineering炼
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...

树莓派4B上跑YOLOv8n:用NCNN实现实时目标检测的完整C++代码与踩坑实录
树莓派4B上跑YOLOv8n:用NCNN实现实时目标检测的完整C代码与踩坑实录 在边缘计算设备上部署深度学习模型一直是开发者面临的挑战,尤其是像树莓派4B这样资源有限的平台。本文将分享如何在树莓派4B上使用NCNN框架部署YOLOv8n模型,并实现实时目标…...

Real-ESRGAN-GUI:终极AI图像增强工具,让模糊图片秒变高清
Real-ESRGAN-GUI:终极AI图像增强工具,让模糊图片秒变高清 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 在数字时代,我们每天都会接触…...

一文读懂10英寸平板尺寸:从屏幕比例到实际机身尺寸
在平板电脑市场中,"10英寸"这一规格始终占据着黄金地位。但当我们搜索"平板10寸多大长和宽"时,得到的答案往往模糊不清。作为行业观察者,我将为您深度解析10英寸平板尺寸的行业标准、设计逻辑及选购策略,带您…...

告别驱动烦恼:Universal ADB Driver 让 Windows 连接 Android 设备变得简单
告别驱动烦恼:Universal ADB Driver 让 Windows 连接 Android 设备变得简单 【免费下载链接】UniversalAdbDriver One size fits all Windows Drivers for Android Debug Bridge. 项目地址: https://gitcode.com/gh_mirrors/un/UniversalAdbDriver 还在为连接…...