Python 中考虑 concurrent.futures 实现真正的并行计算
Python 中考虑 concurrent.futures 实现真正的并行计算
思考,如何将代码所要执行的计算任务划分成多个独立的部分并在各自的核心上面平行地运行。
Python 的全局解释器锁(global interpreter lock,GIL)导致没办法用线程来实现真正的并行,所以先把这种方案排除掉。另一种常见的方案,是把那些对性能要求比较高的(performance-critical)代码用 C 语言重写成扩展模块。然而,用 C 语言重写 Python 代码,代价是比较高的。所以,还是要能够在 Python 语言自身的范围内,解决这种复杂的并行计算问题。
Python 内置的 multiprocessing 模块提供了多进程机制,这种机制很容易通过内置的 concurrent.futures 模块来使用。这种方案可以启动许多条子进程(child process),这些进程是独立于主解释器的,它们有各自的解释器与相应的全局解释器锁,因此这些子进程可以平行地运行在 CPU 的各个核心上面。每条子进程都能够充分利用它所在的这个核心来执行运算。这些子进程都有指向主进程的链接,用来接收所要执行的计算任务并返回结果。
例如,现在要用 Python 来执行某种计算量很大的工作,而且想把 CPU 里的各个核心充分利用起来。用下面这个计算最大公约数的函数,来模拟刚才讲的那种工作。
# my_module.py
def gcd(pair):a, b = pairlow = min(a, b)for i in range(low, 0, -1):if a % i == 0 and b % i == 0:return iassert False, 'Not reachable'
如果把有待求解最大公约数的那些元组按照先后顺序交给这个函数去执行,那么程序花费的总时间就会随着元组的数量呈正比例上升,因为根本就没有做平行计算。
# run_serial.py
import timenumbers = [(1963309, 2265973), (2030677, 3814172),(1551645, 2229620), (2039045, 2020802),(1823712, 1924928), (2293129, 1020491),(1281238, 2273782), (3823812, 4237281),(3812741, 4729139), (1292391, 2123811),
]def main():start = time.time()results = list(map(gcd, numbers))end = time.time()delta = end - startprint(f'Took {delta:.3f} seconds')main()# >>>
# Took 0.863 seconds
直接把这种代码分给多条 Python 线程去执行,是不会让程序提速的,因为它们全都受制于同一个 Python 全局解释器锁(GIL),无法真正平行地运行在各自的 CPU 核心上面。现在就来演示这一点。使用 concurrent.futures 模块里面的 ThreadPoolExecutor 类,并允许它最多可以启用四条工作线程(根据机器核心数设置)。
# run_threads.py
from concurrent.futures import ThreadPoolExecutor
import timenumbers = [(1963309, 2265973), (2030677, 3814172),(1551645, 2229620), (2039045, 2020802),(1823712, 1924928), (2293129, 1020491),(1281238, 2273782), (3823812, 4237281),(3812741, 4729139), (1292391, 2123811),
]def main():start = time.time()pool = ThreadPoolExecutor(max_workers=4)results = list(pool.map(gcd, numbers))end = time.time()delta = end - startprint(f'Took {delta:.3f} seconds')main()# >>>
# Took 0.846 seconds
由于要启动线程池并和它通信,这种写法比单线程版本还慢。但是请注意,只需要变动一行代码就能让程序出现奇效,也就是把 ThreadPoolExecutor 改成 concurrent.futures 模块里的 ProcessPoolExecutor。这样一改,程序立刻就快了起来。
# run_parallel.py
from concurrent.futures import ProcessPoolExecutor
import timenumbers = [(1963309, 2265973), (2030677, 3814172),(1551645, 2229620), (2039045, 2020802),(1823712, 1924928), (2293129, 1020491),(1281238, 2273782), (3823812, 4237281),(3812741, 4729139), (1292391, 2123811),
]def main():start = time.time()pool = ProcessPoolExecutor(max_workers=4) # The one changeresults = list(pool.map(gcd, numbers))end = time.time()delta = end - startprint(f'Took {delta:.3f} seconds')if __name__ == '__main__':main()# >>>
# Took 0.464 seconds
程序变得比原来快多了。这是为什么呢?因为 ProcessPool-Executor 类会执行下面这一系列的步骤(当然,这实际上是由 multiprocessing 模块里的底层机制所推动的)。
- 1)从包含输入数据的NUMBERS列表里把每个元素取出来,以便交给 map。
- 2)用 pickle 模块对每个元素做序列化处理,把它转成二进制形式。
- 3)将序列化之后的数据,从主解释器所在的进程经由本地 socket 复制到子解释器所在的进程。
- 4)在子进程里面,用 pickle 模块对数据做反序列化处理,把它还原成 Python 对象。
- 5)引入包含 gcd 函数的那个 Python 模块。
- 6)把刚才还原出来的那个对象交给 gcd 函数去处理,此时,其他子进程也可以把它们各自的那份数据交给它们各自的 gcd 函数执行。
- 7)对执行结果做序列化处理,把它转化成二进制形式。
- 8)将二进制数据通过 socket 复制到上级进程。
- 9)在上级进程里面对二进制数据做反序列化处理,把它还原成 Python 对象。
- 10)把每条子进程所给出的结果都还原好,最后合并到一个 list 里面返回。
从开发者这边来看,这个过程似乎很简单,但实际上,multiprocessing 模块与 Proce-ssPoolExecutor 类要做大量的工作才能实现出这样的并行效果。同样的效果,假如改用其他语言来做,那基本上只需要用一把锁或一项原子操作就能很好地协调多个线程,从而实现并行。但这在 Python 里面不行,所以才考虑通过 ProcessPoolExecutor 来实现。然而这样做的开销很大,因为它必须在上级进程与子进程之间做全套的序列化与反序列化处理。
这个方案对那种孤立的而且数据利用度较高的任务来说,比较合适。所谓孤立(isolated),这里指每一部分任务都不需要跟程序里的其他部分共用状态信息。所谓数据利用度较高(high-leverage),这里指任务所使用的原始材料以及最终所给出的结果数据量都很小,因此上级进程与子进程之间只需要互传很少的信息就行,然而在把原始材料加工成最终产品的过程中,却需要做大量运算。
如果你面对的计算任务不具备刚才那两项特征,那么使用 ProcessPoolExecutor 所引发的开销可能就会盖过因为并行而带来的好处。在这种情况下,可以考虑直接使用 multiprocessing 所提供的一些其他高级功能,例如共享内存(shared memory)、跨进程的锁(cross-process lock)、队列(queue)以及代理(proxy)等。但是,这些功能都相当复杂,即便两个 Python 线程之间所要共享的进程只有一条,也是要花很大工夫才能在内存空间里面将这些工具安排到位。假如需要共享的进程有很多条,而且还涉及 socket,那么这种代码理解起来会更加困难。
总之,不要刚一上来,就立刻使用跟 multiprocessing 这个内置模块有关的机制,而是可以先试着用 ThreadPoolExecutor 来运行这种孤立且数据利用度较高的任务。把这套方案实现出来之后,再考虑向 ProcessPoolExecutor 方案迁移。如果 ProcessPoolExecutor 方案也无法满足要求,而且其他办法也全都试遍了,那么最后可以考虑直接使用 multiprocessing 模块里的高级功能来编写代码。
相关文章:

Python 中考虑 concurrent.futures 实现真正的并行计算
Python 中考虑 concurrent.futures 实现真正的并行计算 思考,如何将代码所要执行的计算任务划分成多个独立的部分并在各自的核心上面平行地运行。 Python 的全局解释器锁(global interpreter lock,GIL)导致没办法用线程来实现真…...

【C++多线程编程】 线程安全与对象生命周期管理
目录 类的线程安全 实现线程安全 构造函数在多线程中的安全性 析构函数多线程环境的安全 智能指针实现多线程安全 shared_ptr 非完全线程安全 shared_ptr可能导致对象生命周期延长 const引用可以减少传递shared_ptr开销 shared_ptr 智能指针块模块的优点 析构所在线程…...

【系统架构设计师-2024年-上半年】综合知识-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16~17题】【第18~19题】【第20~21题】【第22题】【第23题】…...

MATLAB 中的对数计算
在 MATLAB 中,计算对数是进行数学分析和科学计算的常见需求。对数运算在数据分析、信号处理和控制系统中都有广泛应用。本篇博客将详细介绍如何在 MATLAB 中进行对数计算,包括自然对数、常用对数以及任意底数的对数。 1. 自然对数(以 e 为底…...

详解 HTTPS 与 TLS证书链校验
一文详解 HTTPS 与 TLS证书链校验_证书链怎么验证-CSDN博客 深入浅出 SSL/CA 证书及其相关证书文件(pem、crt、cer、key、csr) https://zhuanlan.zhihu.com/p/702745054...

新手做短视频素材在哪里找?做短视频素材工具教程网站有哪些?
本文将为你提供一系列新手友好的视频制作资源,包括素材网站和编辑工具,帮助你快速成为短视频领域的新星。让我们从国内知名的蛙学网开始介绍。 蛙学网:新手的视频素材天堂 对于短视频新手而言,蛙学网绝对是一个宝库。该网站提供了…...

【html】编辑器、基础、属性、标题、段落、格式化、 连接、头部、CSS、图像
目录 2.HTML编辑器 3.HTML基础 3.1 HTML标题 3.2 段落 4.HTML元素 4.1 元素语法 4.2 嵌套元素 4.3 HTML空元素 4.4 HTML提示,使用小写标签 5.HTML属性 5.1 属性实例 5.2 HTML 属性常用引用属性值 5.3 使用小写属性 5.4 HTML属性参考手册 6.HTML标题 6.1 HTML水…...

算法【洪水填充】
洪水填充是一种很简单的技巧,设置路径信息进行剪枝和统计,类似感染的过程。路径信息不撤销,来保证每一片的感染过程可以得到区分。看似是暴力递归过程,其实时间复杂度非常好,遍历次数和样本数量的规模一致。 下面通过…...

PostgreSQL的repmgr工具介绍
PostgreSQL的repmgr工具介绍 repmgr(Replication Manager)是一个专为 PostgreSQL 设计的开源工具,用于管理和监控 PostgreSQL 的流复制及实现高可用性。它提供了一组工具和实用程序,简化了 PostgreSQL 复制集群的配置、维护和故障…...
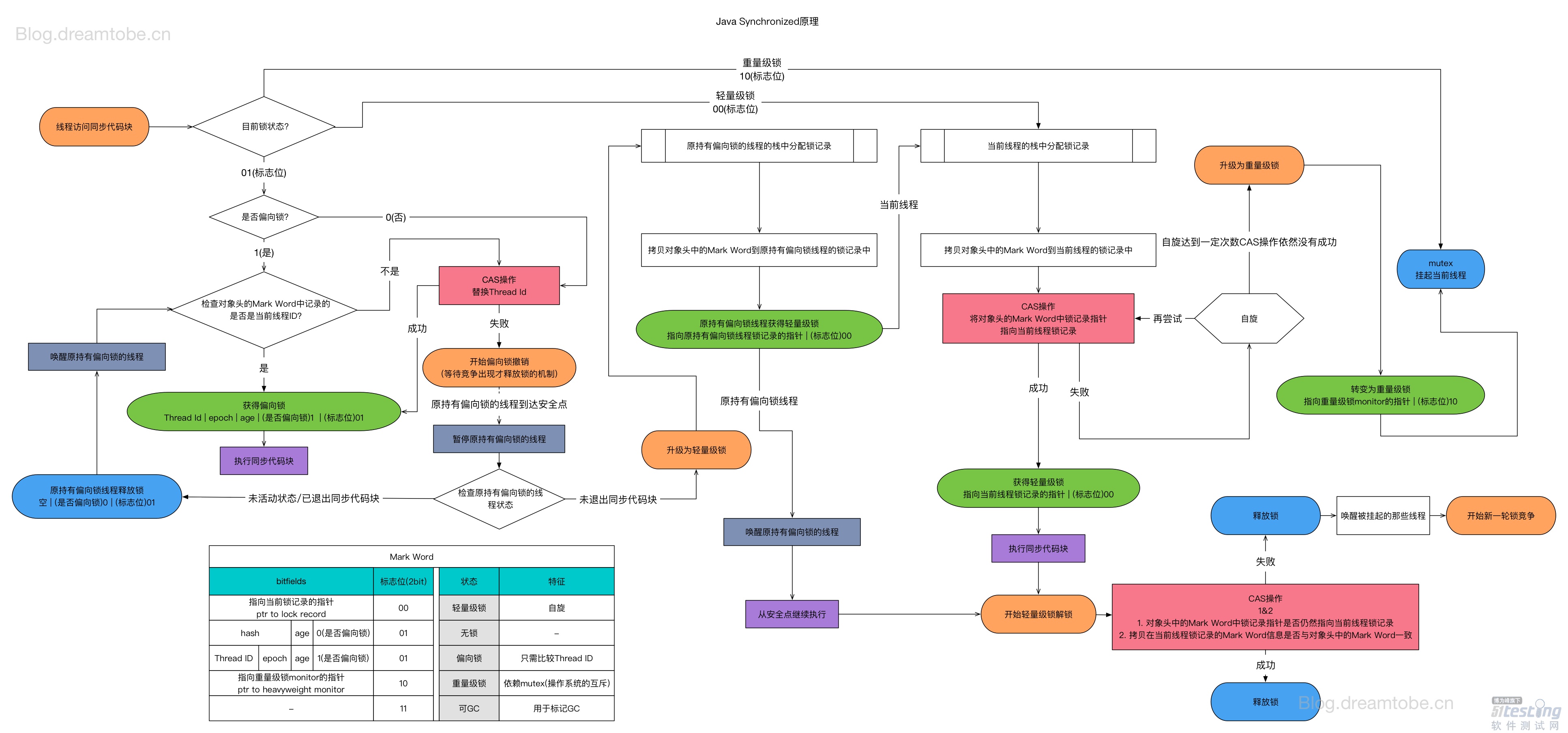
面试官:synchronized的锁升级过程是怎样的?
大家好,我是大明哥,一个专注「死磕 Java」系列创作的硬核程序员。 回答 在 JDK 1.6之前,synchronized 是一个重量级、效率比较低下的锁,但是在JDK 1.6后,JVM 为了提高锁的获取与释放效,,对 synchronized 进…...

Linux中的时间
1、date命令 参数作用参数作用参数作用%Y年xxxx%m月xx%d日xx%H小时(00~23)%M分钟(00~59)%S秒(00~59)%I小时(00~12)%t跳格[Tab键]%j今…...

用Boot写mybatis的增删改查
一、总览 项目结构: 图一 1、JavaBean文件 2、数据库操作 3、Java测试 4、SpringBoot启动类 5、SpringBoot数据库配置 二、配置数据库 在项目资源包中新建名为application.yml的文件,如图一。 建好文件我们就要开始写…...

电脑主机内存
在计算机的组成结构当中内存是非常重要的一部分,它用来存储程序和数据。对于计算机来说有了内存才能保证计算机的正常工作。 内部存储器就是我们所说的内存条,一般是用来即时存储数据。不做数据的长期保留。 外部存储器就是我们常说的固态或者硬盘。固态…...
文件操作与隐写
一、文件类型的识别 1、文件头完好情况: (1)file命令 使用file命令识别:识别出file.doc为jpg类型 (2)winhex 通过winhex工具查看文件头类型,根据文件头部内容去判断文件的类型 eg:JPG类型 &a…...

SQLException: No Suitable Driver Found - 完美解决方法详解
🚨 SQLException: No Suitable Driver Found - 完美解决方法详解 🚨 **🚨 SQLException: No Suitable Driver Found - 完美解决方法详解 🚨****摘要 📝****引言 🎯****正文 📚****1. 问题概述 ❗…...
pycharm破解教程
下载pycharm https://www.jetbrains.com/pycharm/download/other.html 破解网站 https://hardbin.com/ipfs/bafybeih65no5dklpqfe346wyeiak6wzemv5d7z2ya7nssdgwdz4xrmdu6i/ 点击下载破解程序 安装pycharm 自己选择安装路径 安装完成后运行破解程序 等到Done图标出现 选择Ac…...
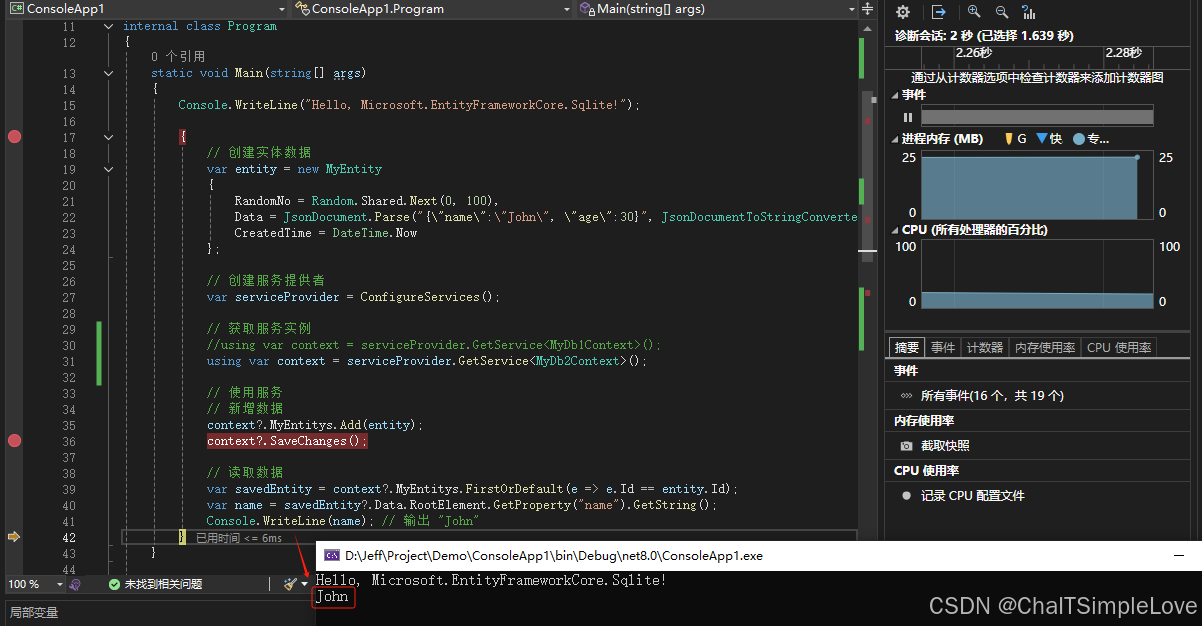
如何使用 ef core 的 code first(fluent api)模式实现自定义类型转换器?
如何使用 ef core 的 code first 模式实现自定义类型转换器 前言 1. 项目结构2. 实现步骤2.1 定义转换器2.1.1 DateTime 转换器2.1.2 JsonDocument 转换器 2.2 创建实体类并配置数据结构类型2.3 定义 Utility 工具类2.4 配置 DbContext2.4.1 使用 EF Core 配置 DbContext 的两种…...

MapSet之相关概念
系列文章: 1. 先导片--Map&Set之二叉搜索树 2. Map&Set之相关概念 目录 1.搜索 1.1 概念和场景 1.2 模型 2.Map的使用 2.1 关于Map的说明 2.2 关于Map.Entry的说明 2.3 Map的常用方法说明 3.Set的说明 3.1关于Set说明 3.2 常见方法说明 1.搜…...

【大数据】浅谈Pyecharts:数据可视化的强大工具
文章目录 一、引言二、Pyecharts是什么三、Pyecharts的发展历程四、如何使用Pyecharts1. 安装Pyecharts2. 创建图表(1)导入Pyecharts模块:(2)创建图表实例:(3)添加数据:&…...
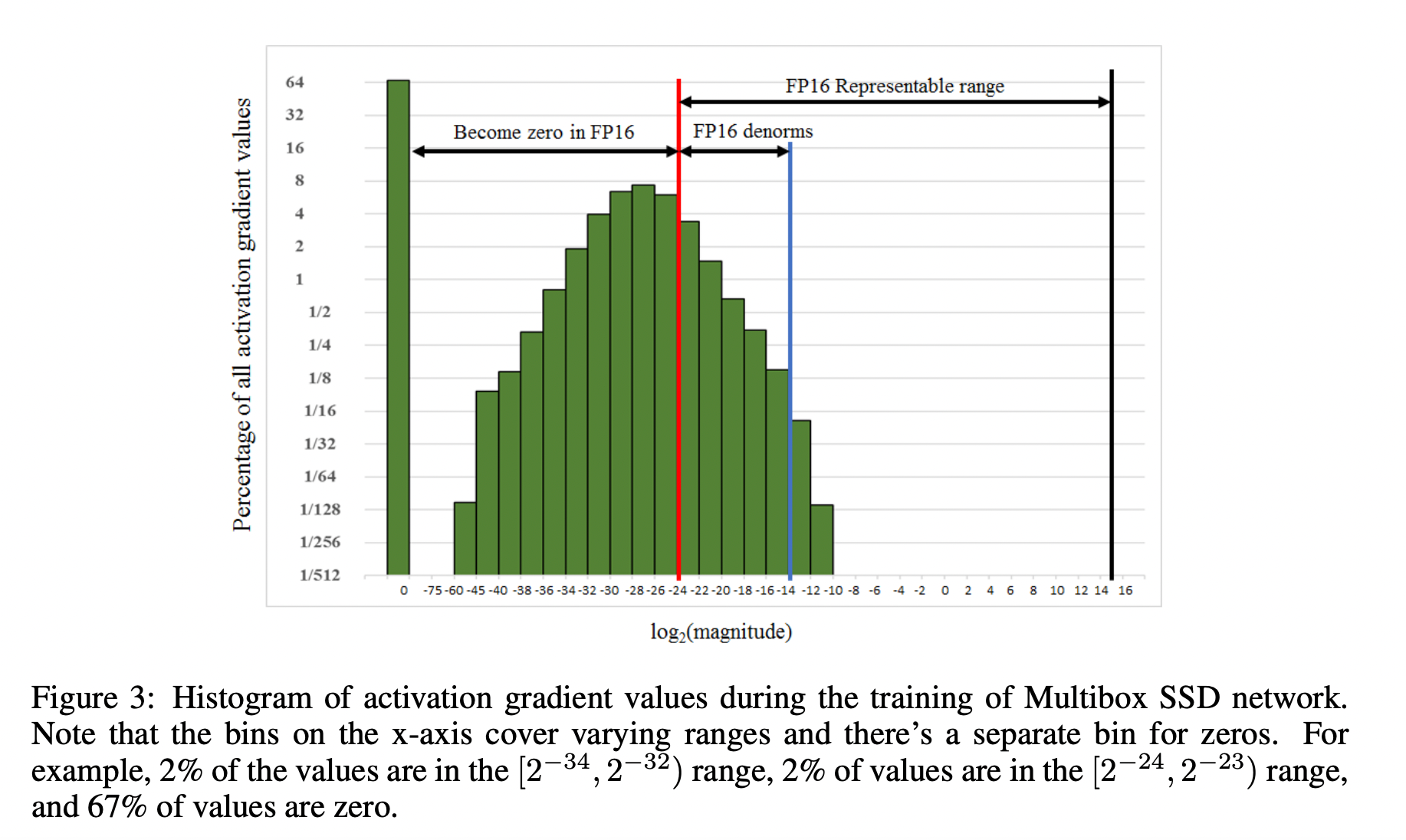
[深度学习][LLM]:浮点数怎么表示,什么是混合精度训练?
混合精度训练 混合精度训练1. 浮点表示法:[IEEE](https://zh.wikipedia.org/wiki/电气电子工程师协会)二进制浮点数算术标准(IEEE 754)1.1 浮点数剖析1.2 举例说明例子 1:例子 2: 1.3 浮点数比较1.4 浮点数的舍入 2. 混合精度训练2.1 为什么需…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...