二百五十九、Java——采集Kafka数据,解析成一条条数据,写入另一Kafka中(一般JSON)
一、目的
由于部分数据类型频率为1s,从而数据规模特别大,因此完整的JSON放在Hive中解析起来,尤其是在单机环境下,效率特别慢,无法满足业务需求。
而Flume的拦截器并不能很好的转换数据,因为只能采用Java方式,从Kafka的主题A中采集数据,并解析字段,然后写入到放在Kafka主题B中
二 、原始数据格式
JSON格式比较正常,对象中包含数组
{
"deviceNo": "39",
"sourceDeviceType": null,
"sn": null,
"model": null,
"createTime": "2024-09-03 14:10:00",
"data": {
"cycle": 300,
"evaluationList": [{
"laneNo": 1,
"laneType": null,
"volume": 3,
"queueLenMax": 11.43,
"sampleNum": 0,
"stopAvg": 0.54,
"delayAvg": 0.0,
"passRate": 0.0,
"travelDist": 140.0,
"travelTimeAvg": 0.0
},
{
"laneNo": 2,
"laneType": null,
"volume": 7,
"queueLenMax": 23.18,
"sampleNum": 0,
"stopAvg": 0.47,
"delayAvg": 10.57,
"passRate": 0.0,
"travelDist": 140.0,
"travelTimeAvg": 0.0
},
{
"laneNo": 3,
"laneType": null,
"volume": 9,
"queueLenMax": 11.54,
"sampleNum": 0,
"stopAvg": 0.18,
"delayAvg": 9.67,
"passRate": 0.0,
"travelDist": 140.0,
"travelTimeAvg": 0.0
},
{
"laneNo": 4,
"laneType": null,
"volume": 6,
"queueLenMax": 11.36,
"sampleNum": 0,
"stopAvg": 0.27,
"delayAvg": 6.83,
"passRate": 0.0,
"travelDist": 140.0,
"travelTimeAvg": 0.0
}]
}
}
三、Java代码
package com.kgc;import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaKafkaEvaluation {// 添加 Kafka Producer 配置private static Properties producerProps() {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.70:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.ACKS_CONFIG, "-1");props.put(ProducerConfig.RETRIES_CONFIG, "3");props.put(ProducerConfig.BATCH_SIZE_CONFIG, "16384");props.put(ProducerConfig.LINGER_MS_CONFIG, "1");props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432");return props;}public static void main(String[] args) {Properties prop = new Properties();prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.70:9092");prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 每一个消费,都要定义不同的Group_IDprop.put(ConsumerConfig.GROUP_ID_CONFIG, "evaluation_group");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);consumer.subscribe(Collections.singleton("topic_internal_data_evaluation"));ObjectMapper mapper = new ObjectMapper();// 初始化 Kafka ProducerKafkaProducer<String, String> producer = new KafkaProducer<>(producerProps());while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {try {JsonNode rootNode = mapper.readTree(record.value());System.out.println("原始数据"+rootNode);String device_no = rootNode.get("deviceNo").asText();String source_device_type = rootNode.get("sourceDeviceType").asText();String sn = rootNode.get("sn").asText();String model = rootNode.get("model").asText();String create_time = rootNode.get("createTime").asText();String cycle = rootNode.get("data").get("cycle").asText();JsonNode evaluationList = rootNode.get("data").get("evaluationList");for (JsonNode evaluationItem : evaluationList) {String lane_no = evaluationItem.get("laneNo").asText();String lane_type = evaluationItem.get("laneType").asText();String volume = evaluationItem.get("volume").asText();String queue_len_max = evaluationItem.get("queueLenMax").asText();String sample_num = evaluationItem.get("sampleNum").asText();String stop_avg = evaluationItem.get("stopAvg").asText();String delay_avg = evaluationItem.get("delayAvg").asText();String pass_rate = evaluationItem.get("passRate").asText();String travel_dist = evaluationItem.get("travelDist").asText();String travel_time_avg = evaluationItem.get("travelTimeAvg").asText();String outputLine = String.format("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s",device_no, source_device_type, sn, model, create_time, cycle,lane_no, lane_type,volume,queue_len_max,sample_num,stop_avg,delay_avg,pass_rate,travel_dist,travel_time_avg);// 发送数据到 KafkaProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic_db_data_evaluation", record.key(), outputLine);producer.send(producerRecord, (RecordMetadata metadata, Exception e) -> {if (e != null) {e.printStackTrace();} else {System.out.println("The offset of the record we just sent is: " + metadata.offset());}});}} catch (Exception e) {e.printStackTrace();}}consumer.commitAsync();}}}
1、服务器IP都是 192.168.0.70
2、消费Kafka主题(数据源):topic_internal_data_evaluation
3、生产Kafka主题(目标源):topic_db_data_evaluation
4、注意:字段顺序与ODS层表结构字段顺序一致!!!
四、开启Kafka主题topic_db_data_evaluation消费者
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.0.70:9092 --topic topic_db_data_evaluation --from-beginning
五、运行测试
1、启动项目

2、消费者输出数据

然后再用Flume采集写入HDFS就行了,不过ODS层表结构需要转变
六、ODS层新表结构
create external table if not exists hurys_dc_ods.ods_evaluation(device_no string COMMENT '设备编号',source_device_type string COMMENT '设备类型',sn string COMMENT '设备序列号 ',model string COMMENT '设备型号',create_time timestamp COMMENT '创建时间',cycle int COMMENT '评价数据周期',lane_no int COMMENT '车道编号',lane_type int COMMENT '车道类型 0:渠化1:来向2:出口3:去向4:左弯待转区5:直行待行区6:右转专用道99:未定义车道',volume int COMMENT '车道内过停止线流量(辆)',queue_len_max float COMMENT '车道内最大排队长度(m)',sample_num int COMMENT '评价数据计算样本量',stop_avg float COMMENT '车道内平均停车次数(次)',delay_avg float COMMENT '车道内平均延误时间(s)',pass_rate float COMMENT '车道内一次通过率',travel_dist float COMMENT '车道内检测行程距离(m)',travel_time_avg float COMMENT '车道内平均行程时间' ) comment '评价数据外部表——静态分区' partitioned by (day string) row format delimited fields terminated by ',' stored as SequenceFile ;
七、Flume采集配置文件

八、运行Flume任务,检查HDFS文件、以及ODS表数据
--刷新表分区 msck repair table ods_evaluation; --查看表分区 show partitions hurys_dc_ods.ods_evaluation; --查看表数据 select * from hurys_dc_ods.ods_evaluation where day='2024-09-03';
搞定,这样就不需要在Hive中解析JSON数据了!!!
相关文章:
二百五十九、Java——采集Kafka数据,解析成一条条数据,写入另一Kafka中(一般JSON)
一、目的 由于部分数据类型频率为1s,从而数据规模特别大,因此完整的JSON放在Hive中解析起来,尤其是在单机环境下,效率特别慢,无法满足业务需求。 而Flume的拦截器并不能很好的转换数据,因为只能采用Java方…...

Qt项目使用Inno Setup打包(关于打包中文乱码的解决)
关于打包好的文件乱码解决方法 打包好的文件中文乱码,就是编码格式出现了问题,更改一下中文脚本编码格式,在官网Inno Setup Translations下载好中文脚本 点击下载,然后另存为 得到ChineseSimplified.isl.txt文件后&#…...

HTML和HTML5有什么区别
HTML(超文本标记语言)是构建网页的基础,而HTML5是HTML的最新版本。虽然HTML和HTML5在许多方面相似,但HTML5引入了许多新的特性和改进,使得网页开发更加高效和功能丰富。 一、HTML概述 HTML,即超文本标记语…...

Collections
Collections 是 Java 中的一个实用工具类,提供了一系列静态方法来操作集合。以下是其详细介绍: 前置知识 在 Java 中,可变参数(Varargs)允许方法接受可变数量的参数。使用可变参数时,可以传递任意数量的参…...

fastreport打印trichedit分页问题的解决
用fastreport来打印richedit里面的内容。刚开始放一个frxrichview组件到报表上,然后在 var str: TMemoryStream; begin begin str: TMemoryStream.Create; CurrRichRecord.richedit.Lines.SaveToStream(str); str.Position: 0; tfrxRichview(fr…...

【MeterSphere】vnc连接不上selenium-chrome容器
目录 一、现象 二、查看配置文件 docker-compose-seleniarm.yml 三、处理 3.1 删除上图当中的三行 3.2 msctl reload 3.3 重新连接 前言:使用vnc连不上ms的selenium-chrome容器,看不到里面运行情况,以前其实可以,后来不行…...

mysql explain分析
目录 思维导图 id select_type SIMPLE PRIMARY SUBQUERY DEPENDENT SUBQUREY UNCACHEABLE SUBQUREY: UNION UNION RESULT DERIVED MATERIALIZED table partitions type ALL index range ref eq_ref const system possible_keys keys key_l…...

[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization
引言 为了理解CoSENT的loss,今天来读一下Circle Loss: A Unified Perspective of Pair Similarity Optimization。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 这篇论文从对深度特征学习的成对相似度优化角度出发,旨在最大化同类之间…...

Windows .NET8 实现 远程一键部署,几秒完成发布,提高效率 - CICD
1. 前言 场景 (工作环境 一键部署 到 远端服务器 [阿里云]) CICD 基本步骤回顾 https://blog.csdn.net/CsethCRM/article/details/141604638 2. 环境准备 服务器端IP:106.15.74.25(阿里云服务器) 客户端࿱…...

echarts 水平柱图 科技风
var category [{ name: "管控", value: 2500 }, { name: "集中式", value: 8000 }, { name: "纳管", value: 3000 }, { name: "纳管", value: 3000 }, { name: "纳管", value: 3000 } ]; // 类别 var total 10000; // 数据…...

标准IO与系统IO
概念区别 标准IO:(libc提供) fopen fread fwrite 系统IO:(linux系统提供) open read write 操作效率 因为内存与磁盘的执行效率不同 系统IO: 把数据从内存直接写到磁盘上 标准IOÿ…...

【conda】Conda 环境迁移指南:如何更改 envs_dirs 和 pkgs_dirs 以及跨盘迁移
目录 迁移概述一、conda 配置文件1.1 安装 Conda 后的默认目录设置1.2 查看当前 .condarc 配置 二、更改 Conda 的 envs_dirs 和 pkgs_dirs 设置2.1 使用 conda config 命令Windows 和 Linux 系统 2.2 手动编辑 .condarc 文件Windows 系统Linux 系统 2.3 验证设置 三、迁移 Con…...

脏页写入磁盘的过程详解
脏页写入磁盘的过程 一、引言 在数据库系统中,脏页是指那些被修改过但还未写入磁盘的数据页。为了保证数据的一致性和持久性,数据库系统需要在适当的时候将脏页写入磁盘。了解脏页写入磁盘的过程对于理解数据库的内部工作机制和优化性能至关重要。 二、触发脏页写入的条件…...

数据结构——单链表实现和注释浅解
关于单链表的基础部分增删查改的实现和一点理解,写在注释里~ SList.h #pragma once #include<stdio.h> #include<stdlib.h> #include<assert.h>//定义节点的结构 //数据 指向下一个节点的指针 typedef int SLTDataType;typedef struct SListNo…...

滑动窗口系列(同向双指针)/9.7
新的解题思路 一、三数之和的多种可能 给定一个整数数组 arr ,以及一个整数 target 作为目标值,返回满足 i < j < k 且 arr[i] arr[j] arr[k] target 的元组 i, j, k 的数量。 由于结果会非常大,请返回 109 7 的模。 输入&…...

C# 窗体中Control以及Invalidate,Update,Refresh三种重绘方法的区别
在 C# 中,Control 类是 Windows Forms 应用程序中所有控件的基类。它提供了控件的基本功能和属性,这些功能和属性被所有继承自 Control 类的子类所共享。这意味着 Control 类是构建 Windows Forms 应用程序中用户界面元素的基础。 以下是 Control 类的一…...

缓存类型以及读写策略
缓存(Cache)是一种高效的数据存储技术,旨在提高数据访问速度。 它将频繁访问或最近使用的数据临时存储在更快速但较小的存储介质(如内存)中,以减少从较慢的存储设备(如硬盘或远程服务器&#x…...
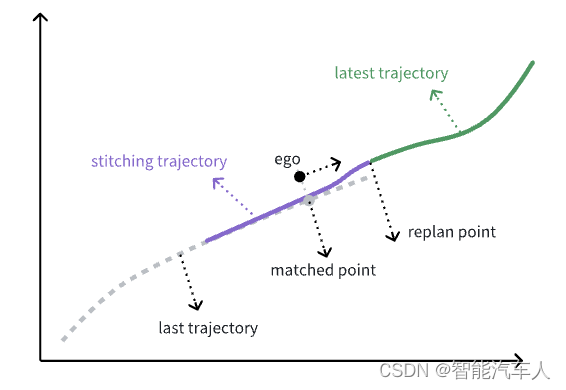
自动驾驶---Motion Planning之轨迹拼接
1 背景 笔者在之前的专栏中已经详细讲解了自动驾驶Planning模块的内容:包括行车的Behavior Planning和Motion Planning,以及低速记忆泊车的Planning。 本篇博客主要聊一聊Motion Planning中轨迹拼接的相关内容。从网络上各大品牌的车主拍摄的智驾视频来看…...

没资料的屏幕怎么点亮?思路分享
这次尝试调通一个没资料的屏幕,型号是HYT13264,这个是淘宝上面的老王2.9元屏,成色很好但是长期库存没有资料和代码能点亮,仅仅只有一个引脚定义。这里我使用Arduino Nano作为控制器尝试点亮这个模块。 首先,已知别人找…...
通信工程学习:什么是FEC前向纠错
FEC:前向纠错 FEC(Forward Error Correction,前向纠错)是一种增加数据通信可信度的技术,广泛应用于计算机网络、无线通信、卫星通信等多种数据传输场景中。其基本原理和特点可以归纳如下: 一、FEC前向纠错…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...