mysql explain分析
目录
思维导图
id
select_type
SIMPLE
PRIMARY
SUBQUERY
DEPENDENT SUBQUREY
UNCACHEABLE SUBQUREY:
UNION
UNION RESULT
DERIVED
MATERIALIZED
table
partitions
type
ALL
index
range
ref
eq_ref
const
system
possible_keys
keys
key_len
ref
rows
filtered
Extra
思维导图


| 序号 | 列名 | 列名注释 |
| 1 | 字段 | 含义 |
| 2 | id | 操作标识符,从 1 开始递增。 |
| 3 | select_type | 查询类型,例如 SIMPLE、PRIMARY、SUBQUERY 等等。 |
| 4 | table | 操作的表名。 |
| 5 | partitions | 操作的分区。 |
| 6 | type | 操作的连接类型,例如 const、eq_ref、ref、range、index、ALL 等等。 |
| 7 | possible_keys | 操作可能使用的索引。 |
| 8 | key | 操作实际使用的索引。 |
| 9 | key_len | 操作使用的索引的长度。 |
| 10 | ref | 操作使用的索引的参考。 |
| 11 | rows | 操作返回的行数的估计值。 |
| 12 | filtered | 操作返回的行的过滤率。 |
| Extra | 操作的额外信息,例如 Using where、Using index 等等。 |
id
表示查询中执行select子句或操作表的顺序,
id相同:执行顺序由上至下。
id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行。
id为NULL:最后执行。
id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好。
select_type
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
SIMPLE
简单查询。查询中不包含子查询或者UNION。

PRIMARY
主查询。查询中若包含子查询,则最外层查询被标记为PRIMARY。
SUBQUERY
子查询。在SELECT或WHERE列表中包含了子查询。
SQL示例:
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content= 'a');

DEPENDENT SUBQUREY
如果包含了子查询,并且查询语句不能被优化器转换为连接查询,并
且子查询是 相关子查询(子查询基于外部数据列) ,则子查询就是DEPENDENT SUBQUREY。
SQL示例:
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content = t3.content);

UNCACHEABLE SUBQUREY:
表示这个subquery的查询要受到外部系统变量的影响
UNION
对于包含UNION或者UNION ALL的查询语句,除了最左边的查询是PRIMARY,其余的查
询都是UNION。
UNION RESULT
UNION会对查询结果进行查询去重,MYSQL会使用临时表来完成UNION查询
的去重工作,针对这个临时表的查询就是"UNION RESULT"。
EXPLAIN SELECT * FROM t3 WHERE id = 1 UNION SELECT * FROM t2 WHERE id = 1;

DERIVED
在包含 派生表(子查询在from子句中) 的查询中,MySQL会递归执行这些子查询,把结果放在临时表里。
EXPLAIN SELECT * FROM ( SELECT content, COUNT(*) AS c FROM t1 GROUP BY content ) AS derived_t1 WHERE c > 1;
这里的 就是在id为2的查询中产生的派生表。

补充:MySQL在处理带有派生表的语句时,优先尝试把派生表和外层查询进行合并,如果不行,再把派
生表物化掉(执行子查询,并把结果放入临时表),然后执行查询。下面的例子就是就是将派生表和外层查
询进行合并的例子:
EXPLAIN SELECT*FROM(SELECT*FROMt1WHEREcontent='t1_832')ASderived_t1;

MATERIALIZED
优化器对于包含子查询的语句,如果选择将子查询物化后再与外层查询连接查询,
该子查询的类型就是MATERIALIZED。如下的例子中,查询优化器先将子查询转换成物化表,然后
将t1和物化表进行连接查询。
EXPLAIN SELECT*FROM t1 WHERE content IN(SELECT content FROM t2);

table
单表:显示这一行的数据是关于哪张表的
EXPLAIN SELECT * FROM t1;

多表关联:t1为驱动表,t2为被驱动表。
注意:内连接时,MySQL性能优化器会自动判断哪个表是驱动表,哪个表示被驱动表,和书写的顺序无
关
EXPLAIN SELECT * FROM t1 INNER JOIN t2;

partitions
代表分区表中的命中情况,非分区表,该项为NULL
type
此列表示关联类型或访问类型。也就是MySQL决定如何查找表中的行。依次从最优到最差分别为:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery> index_subquery > range > index > all
比较重要的system > const > eq_ref > ref > range > index > all。
SQL 性能优化的目标:至少要达到里巴巴开发手册要求 至少要达到range级别,要求是ref级别,最好是const级别
ALL
全表扫描。Full Table Scan,将遍历全表以找到匹配的行。
index
扫描全部索引获取到结果。
覆盖索引:如果能通过读取索引就可以得到想要的数据,那就不需要读取用户记录,或者不用再做回表
操作了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
range
通常出现在范围查询中,比如in、between、大于、小于等。使用索引来检索给定范围的行。这种范围扫描索引扫描比全表扫描要好,
因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
ref
不使用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引和某个值比较,会找到多个符合条件的行。
eq_ref
主键或者不允许NULL值的唯一键索引被连接使用,最多只会返回一条符合条件的记录。简单的select查询不会出现这种type。
const
根据主键或者唯一二级索引列与常数进行匹配时
system
MyISAM引擎中,当表中只有一条记录时。
possible_keys
possible_keys表示执行查询时可能用到的索引,一个或多个。查询涉及到的字段上若存在索
引,则该索引将被列出,但不一定被查询实际使用。
keys
表示实际使用的索引。如果为NULL,则没有使用索引。
key_len
表示索引使用的字节数,根据这个值可以判断索引的使用情况,检查是否充分利用了索引,针对联合索引值
越大越好。
ref
显示与key中的索引进行比较的列或常量。
rows
MySQL认为它执行查询时必须检查的行数。值越小越好。
filtered
最后查询出来的数据占所有服务器端检查行数(rows)的百分比。值越大越好。
Extra
包含不适合在其他列中显示但十分重要的额外信息。通过这些额外信息来理解MySQL到底将如何执行当前
的查询语句。MySQL提供的额外信息有好几十个,这里只挑介绍比较重要的介绍。
Impossible WHERE:where子句的值总是false
Using where:使用了where,但在where上有字段没有创建索引
Using temporary:使了用临时表保存中间结果
Using filesort:在对查询结果中的记录进行排序时,是可以使用索引的
Using index:使用了覆盖索引,表示直接访问索引就足够获取到所需要的数据,不需要通过索引
回表
Using index condition:叫作Index Condition Push down Optimization(索引下推优化)
如果没有使用索引下推(ICP):那么MySQL在存储引擎层找到满足content1>'z'条件的第一
条二级索引记录。主键值进行回表,返回完整的记录给server层,server层再判断其他的搜索
条件是否成立。如果成立则保留该记录,否则跳过该记录,然后向存储引擎层要下一条记录。
如果使用了索引下推(ICP):那么MySQL在存储引擎层找到满足content1>'z'条件的第
一条二级索引记录。不着急执行回表,而是在这条记录上先判断一下所有关于idx_content1
索引中包含的条件是否成立,也就是content1>'z'ANDcontent1LIKE'%a'是否成
立。如果这些条件不成立,则直接跳过该二级索引记录,去找下一条二级索引记录;如果这些
条件成立,则执行回表操作,返回完整的记录给server层。
相关文章:
mysql explain分析
目录 思维导图 id select_type SIMPLE PRIMARY SUBQUERY DEPENDENT SUBQUREY UNCACHEABLE SUBQUREY: UNION UNION RESULT DERIVED MATERIALIZED table partitions type ALL index range ref eq_ref const system possible_keys keys key_l…...

[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization
引言 为了理解CoSENT的loss,今天来读一下Circle Loss: A Unified Perspective of Pair Similarity Optimization。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 这篇论文从对深度特征学习的成对相似度优化角度出发,旨在最大化同类之间…...

Windows .NET8 实现 远程一键部署,几秒完成发布,提高效率 - CICD
1. 前言 场景 (工作环境 一键部署 到 远端服务器 [阿里云]) CICD 基本步骤回顾 https://blog.csdn.net/CsethCRM/article/details/141604638 2. 环境准备 服务器端IP:106.15.74.25(阿里云服务器) 客户端࿱…...

echarts 水平柱图 科技风
var category [{ name: "管控", value: 2500 }, { name: "集中式", value: 8000 }, { name: "纳管", value: 3000 }, { name: "纳管", value: 3000 }, { name: "纳管", value: 3000 } ]; // 类别 var total 10000; // 数据…...

标准IO与系统IO
概念区别 标准IO:(libc提供) fopen fread fwrite 系统IO:(linux系统提供) open read write 操作效率 因为内存与磁盘的执行效率不同 系统IO: 把数据从内存直接写到磁盘上 标准IOÿ…...

【conda】Conda 环境迁移指南:如何更改 envs_dirs 和 pkgs_dirs 以及跨盘迁移
目录 迁移概述一、conda 配置文件1.1 安装 Conda 后的默认目录设置1.2 查看当前 .condarc 配置 二、更改 Conda 的 envs_dirs 和 pkgs_dirs 设置2.1 使用 conda config 命令Windows 和 Linux 系统 2.2 手动编辑 .condarc 文件Windows 系统Linux 系统 2.3 验证设置 三、迁移 Con…...

脏页写入磁盘的过程详解
脏页写入磁盘的过程 一、引言 在数据库系统中,脏页是指那些被修改过但还未写入磁盘的数据页。为了保证数据的一致性和持久性,数据库系统需要在适当的时候将脏页写入磁盘。了解脏页写入磁盘的过程对于理解数据库的内部工作机制和优化性能至关重要。 二、触发脏页写入的条件…...

数据结构——单链表实现和注释浅解
关于单链表的基础部分增删查改的实现和一点理解,写在注释里~ SList.h #pragma once #include<stdio.h> #include<stdlib.h> #include<assert.h>//定义节点的结构 //数据 指向下一个节点的指针 typedef int SLTDataType;typedef struct SListNo…...

滑动窗口系列(同向双指针)/9.7
新的解题思路 一、三数之和的多种可能 给定一个整数数组 arr ,以及一个整数 target 作为目标值,返回满足 i < j < k 且 arr[i] arr[j] arr[k] target 的元组 i, j, k 的数量。 由于结果会非常大,请返回 109 7 的模。 输入&…...

C# 窗体中Control以及Invalidate,Update,Refresh三种重绘方法的区别
在 C# 中,Control 类是 Windows Forms 应用程序中所有控件的基类。它提供了控件的基本功能和属性,这些功能和属性被所有继承自 Control 类的子类所共享。这意味着 Control 类是构建 Windows Forms 应用程序中用户界面元素的基础。 以下是 Control 类的一…...

缓存类型以及读写策略
缓存(Cache)是一种高效的数据存储技术,旨在提高数据访问速度。 它将频繁访问或最近使用的数据临时存储在更快速但较小的存储介质(如内存)中,以减少从较慢的存储设备(如硬盘或远程服务器&#x…...
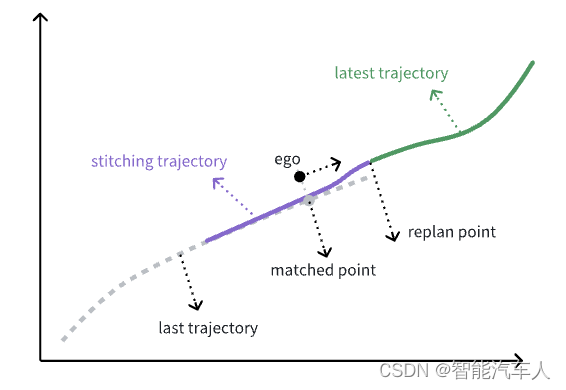
自动驾驶---Motion Planning之轨迹拼接
1 背景 笔者在之前的专栏中已经详细讲解了自动驾驶Planning模块的内容:包括行车的Behavior Planning和Motion Planning,以及低速记忆泊车的Planning。 本篇博客主要聊一聊Motion Planning中轨迹拼接的相关内容。从网络上各大品牌的车主拍摄的智驾视频来看…...

没资料的屏幕怎么点亮?思路分享
这次尝试调通一个没资料的屏幕,型号是HYT13264,这个是淘宝上面的老王2.9元屏,成色很好但是长期库存没有资料和代码能点亮,仅仅只有一个引脚定义。这里我使用Arduino Nano作为控制器尝试点亮这个模块。 首先,已知别人找…...
通信工程学习:什么是FEC前向纠错
FEC:前向纠错 FEC(Forward Error Correction,前向纠错)是一种增加数据通信可信度的技术,广泛应用于计算机网络、无线通信、卫星通信等多种数据传输场景中。其基本原理和特点可以归纳如下: 一、FEC前向纠错…...
】机器人工具箱SerialLink I类函数参数说明)
【机器人工具箱Robotics Toolbox开发笔记(二十)】机器人工具箱SerialLink I类函数参数说明
机器人工具箱中的SerialLink表示串联机器人型机器人的具体类。该类使用D-H参数描述,每个关节一组。SerialLink I类包含的参数如表1所示。 表1 SerialLink I类参数 参 数 意 义 参 数 意 义 plot 显示机器人的图形表示 jacobn 工具坐标系中的雅可比矩阵 plot3D 显示机…...
单调栈的实现
这是C算法基础-数据结构专栏的第二十四篇文章,专栏详情请见此处。 引入 单调栈就是满足单调性的栈结构,它最经典的应用就是给定一个序列,找出每个数左边离它最近的比它大/小的数。 下面我们就来讲单调栈的实现。 定义 单调栈就是满足单调性…...

ffmpeg的安装和使用教程
在Linux上安装和使用FFmpeg可以方便地完成音视频的编码、解码、转码等操作。以下是详细的安装和使用教程。 安装FFmpeg FFmpeg的安装方法会因为不同的Linux发行版有所不同。下面是几种常见的安装方法: Ubuntu/Debian 打开终端,更新包列表并安装FFmpe…...
从计组中从重温C中浮点数表示及C程序翻译过程
目录 移码编辑 传统浮点表示格式 浮点数的存储(ieee 754)->修炼内功 例子: 编辑 浮点数取的过程 C程序翻译过程 移码 传统浮点表示格式 浮点数的存储(ieee 754)->修炼内功 根据国际标准IEEE࿰…...
详细版)
MySQL常用函数(总结)详细版
1. 字符串函数 CONCAT(str1, str2, ...):将多个字符串连接成一个字符串。 SELECT CONCAT(Hello, , World); LENGTH(str):返回字符串的长度(字节数)。 SELECT LENGTH(Hello); SUBSTRING(str, pos, len):从字符串 …...

学习记录——day41 C++ 类的静态成员 static
静态成员,是类中不依赖于类对象而独立存在的成员变量,但仍然属于类,是成员的一种 静态成员的空间分配发生在出现编译阶段,不占用类的空间 静态成员分为,静态成员变量和静态成员函数 静态成员变量 1、相关概念 1&…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...