四.海量数据实时分析-Doris数据导入导出
数据导入
1.概述
Apache Doris 提供多种数据导入方案,可以针对不同的数据源进行选择不同的数据导入方式。
| 数据源 | 导入方式 |
|---|---|
| 对象存储(s3),HDFS | 使用 Broker 导入数据 |
| 本地文件 | Stream Load, MySQL Load |
| Kafka | 订阅 Kafka 数据 |
| Mysql、PostgreSQL,Oracle,SQLServer | 通过外部表同步数据 |
| 通过 JDBC 导入 | 使用 JDBC 同步数据 |
| 导入 JSON 格式数据 | JSON 格式数据导入 |
| AutoMQ | AutoMQ Load |
按导入方式划分
| Broker Load | 通过 Broker 导入外部存储数据 |
|---|---|
| Stream Load | 流式导入数据 (本地文件及内存数据) |
| Routine Load | 导入 Kafka 数据 |
| Insert Into | 外部表通过 INSERT 方式导入数据 |
| S3 Load | S3 协议的对象存储数据导入 |
| MySQL Load | MySQL 客户端导入本地数据 |
支持的数据格式 : 不同的导入方式支持的数据格式略有不同。
| 导入方式 | 支持的格式 |
|---|---|
| Broker Load | parquet, orc, csv, gzip |
| Stream Load | csv, json, parquet, orc |
| Routine Load | csv, json |
| MySQL Load | csv |
Apache Doris 的每一个导入作业,不论是使用 Broker Load 进行批量导入,还是使用 INSERT 语句进行单条导入,都是一个完整的事务操作。导入事务可以保证一批次内的数据原子生效,不会出现部分数据写入的情况。
同时,一个导入作业都会有一个 Label,用于在一个数据库(Database)下唯一标识一个导入作业。Label 可以由用户指定,部分导入功能也会由系统自动生成。
Label 是用于保证对应的导入作业,仅能成功导入一次。一个被成功导入的 Label,再次使用时,会被拒绝并报错 Label already used。通过这个机制,可以在 Doris 侧做到 At-Most-Once 语义。如果结合上游系统的 At-Least-Once 语义,则可以实现导入数据的 Exactly-Once 语义。
导入方式分为同步和异步。对于同步导入方式,返回结果即表示导入成功还是失败。而对于异步导入方式,返回成功仅代表作业提交成功,不代表数据导入成功,需要使用对应的命令查看导入作业的运行状态。
2.Insert 导入
INSERT INTO 支持将 Doris 查询的结果导入到另一个表中。INSERT INTO 是一个同步导入方式,执行导入后返回导入结果。可以通过请求的返回判断导入是否成功。INSERT INTO 可以保证导入任务的原子性,要么全部导入成功,要么全部导入失败。
主要的 Insert Into 命令包含以下两种:
-
INSERT INTO tbl SELECT …
-
INSERT INTO tbl (col1, col2, …) VALUES (1, 2, …), (1,3, …)
这种导入方式并不适用于大量数据的场景,性能太差,只能测试的时候使用
第一步:创建表
CREATE TABLE testdb.test_table(user_id BIGINT NOT NULL COMMENT "用户 ID",name VARCHAR(20) COMMENT "用户姓名",age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
第二步:使用 INSERT INTO VALUES 向源表导入数据(不推荐在生产环境中使用)
INSERT INTO testdb.test_table (user_id, name, age)
VALUES (1, "Emily", 25),(2, "Benjamin", 35),(3, "Olivia", 28),(4, "Alexander", 60),(5, "Ava", 17);
INSERT INTO 是一种同步导入方式,导入结果会直接返回给用户。
Query OK, 5 rows affected (0.308 sec)
{'label':'label_3e52da787aab4222_9126d2fce8f6d1e5', 'status':'VISIBLE', 'txnId':'9081'}
也可以通过SELECT 来导入数据
INSERT INTO testdb.test_table2
SELECT * FROM testdb.test_table WHERE age < 30;
Query OK, 3 rows affected (0.544 sec)
{'label':'label_9c2bae970023407d_b2c5b78b368e78a7', 'status':'VISIBLE', 'txnId':'9084'}
查看手册:https://doris.incubator.apache.org/zh-CN/docs/data-operate/import/insert-into-manual#%E5%8F%82%E8%80%83%E6%89%8B%E5%86%8C
3.Stream Load
Stream Load 支持通过 HTTP 协议将本地文件或数据流导入到 Doris 中。Stream Load 是一个同步导入方式,执行导入后返回导入结果,可以通过请求的返回判断导入是否成功。一般来说,可以使用 Stream Load 导入 10GB 以下的文件,如果文件过大,建议将文件进行切分后使用 Stream Load 进行导入。Stream Load 可以保证一批导入任务的原子性,要么全部导入成功,要么全部导入失败。
Stream Load 支持导入 CSV、JSON、Parquet 与 ORC 格式的数据。在导入 CSV 文件时,需要明确区分空值(null)与空字符串:
-
空值(null)需要用 \N 表示,a,\N,b 数据表示中间列是一个空值(null)
-
空字符串直接将数据置空,a, ,b 数据表示中间列是一个空字符串
在使用 Stream Load 时,需要通过 HTTP 协议发起导入作业给 FE 节点,FE 会以轮询方式,重定向(redirect)请求给一个 BE 节点以达到负载均衡的效果。也可以直接发送 HTTP 请求作业给指定的 BE 节点。在 Stream Load 中,Doris 会选定一个节点做为 Coordinator 节点。Coordinator 节点负责接受数据并分发数据到其他节点上。

-
Client 向 FE 提交 Stream Load 导入作业请求
-
FE 会随机选择一台 BE 作为 Coordinator 节点,负责导入作业调度,然后返回给 Client 一个 HTTP 重定向
-
Client 连接 Coordinator BE 节点,提交导入请求
-
Coordinator BE 会分发数据给相应 BE 节点,导入完成后会返回导入结果给 Client
-
Client 也可以直接通过指定 BE 节点作为 Coordinator,直接分发导入作业
Stream Load 通过 HTTP 协议提交和传输。下例以 curl 工具为例,演示通过 Stream Load 提交导入作业。详细语法可以参见 STREAM LOAD
该方式中涉及HOST:PORT都是对应的HTTP协议端口。但须保证客户端所在机器网络能够联通FE,BE所在机器。
- BE的HTTP协议端口,默认为8040。
- FE的HTTP协议端口,默认为8030。
第一步:创建一个数据库和表
CREATE TABLE testdb.test_streamload(user_id BIGINT NOT NULL COMMENT "用户 ID",name VARCHAR(20) COMMENT "用户姓名",age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
第二步:创建一个load.txt文件,内容如下
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
第三步:执行下面命令
curl -u root:123456 -H "label:load_local_file_test" \
-H "column_separator:," -T load.txt \
http://192.168.220.253:8040/api/testdb/test_streamload/_stream_load
- -u root:123456 : 代表的是doris的账号密码
- label : 标签用来防止重复导入
- column_separator:, :代表的是数据的分隔符
- -T load.txt : 要导入的数据
- http://drois地址:BE端口/api/数据库/数据表/_stream_load
更多的导入参数看配置:https://doris.incubator.apache.org/zh-CN/docs/data-operate/import/stream-load-manual#%E5%AF%BC%E5%85%A5%E9%85%8D%E7%BD%AE%E5%8F%82%E6%95%B0
4.Broker Load
Stream Load 是一种推的方式,即导入的数据依靠客户端读取,并推送到 Doris。Broker Load 则是将导入请求发送给 Doris,有 Doris 主动拉取数据,所以如果数据存储在类似 HDFS 或者 对象存储中,则使用 Broker Load 是最方便的。这样,数据就不需要经过客户端,而有 Doris 直接读取导入。Broker Load 适合源数据存储在远程存储系统,比如 HDFS,并且数据量比较大的场景,比如几十G,上百G。
用户在提交导入任务后,FE 会生成对应的 Plan 并根据目前 BE 的个数和文件的大小,将 Plan 分给 多个 BE 执行,每个 BE 执行一部分导入数据。
BE 在执行的过程中会从 Broker 拉取数据,在对数据 transform 之后将数据导入系统。所有 BE 均完成导入,由 FE 最终决定导入是否成功。

从上图中可以看到,BE 会依赖 Broker 进程来读取相应远程存储系统的数据。之所以引入 Broker 进程,主要是用来针对不同的远程存储系统,用户可以按照 Broker 进程的标准开发其相应的 Broker 进程,Broker 进程可以使用 Java 程序开发,更好的兼容大数据生态中的各类存储系统。由于 broker 进程和 BE 进程的分离,也确保了两个进程的错误隔离,提升 BE 的稳定性。
注意:使用Broker 导入必须安装和启动 Broker ,以及安装和启动HDFS,高一点的Doris默认安装好了HDFS,我这个版本还需自己安装
5.安装HDFS
第一步:下载 hadoop , 下载地址https://downloads.apache.org/hadoop/common/ ,下载之后进行解压,我的解压目录为 /root/hadoop-3.2.4 解压命令如下
tar -zxf hadoop-3.2.4.tar.gz
第二步:创建数据存储目录
mkdir /root/hadoop-3.2.4/tmp
mkdir /root/hadoop-3.2.4/hdfs
mkdir /root/hadoop-3.2.4/hdfs/data
mkdir /root/hadoop-3.2.4/hdfs/name
第四步:配置环境变量 vi /etc/profile,加入一下内容 ,保存退出后,然后执行命令:source /etc/profile让其生效
export HADOOP_HOME=/root/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin
第四步:修改下面五个文件,位置在 /root/hadoop-3.2.4/etc/hadoop目录中
hadoop-3.2.4/etc/hadoop/hadoop-env.sh
hadoop-3.2.4/etc/hadoop/core-site.xml
hadoop-3.2.4/etc/hadoop/hdfs-site.xml
hadoop-3.2.4/etc/hadoop/mapred-site.xml
hadoop-3.2.4/etc/hadoop/yarn-site.xml
每个文件的内容分别如下 ,第一个: hadoop-env.sh ,加入Java的环境变量
# The java implementation to use.#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
修改 core-site.xml 配置文件,内容如下
<configuration><property><name>fs.defaultFS</name><value>hdfs://机器IP:9000</value>####注释 : HDFS的URI,文件系统://namenode标识:端口号
</property><property><name>hadoop.tmp.dir</name><value>/root/hadoop-3.2.4/tmp</value>###注释: namenode上本地的hadoop临时文件夹
</property>
</configuration>
修改配置文件 hdfs-site.xml 内容如下
<configuration> <property><name>dfs.replication</name><value>1</value><description>副本个数,配置默认是3,应小于datanode机器数量</description></property>
</configuration>修改配置文件 mapred-site.xml ,内容如下
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>修改配置文件 yarn-site.xml ,内容如下
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
最后进入到安装目录 cd /root/hadoop-3.2.4/ 然后执行下面命令启动HDFS
bin/hdfs namenode -format #对 HDFS这个分布式文件系统中的 DataNode 进行分块
sbin/hadoop-daemon.sh start namenode
sbin /hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
启动之后,创建一个文件 test.txt ; 执行测试命令: hadoop fs -put ./test.txt / ,浏览器访问9870端口可以查看文件列表,如下
6.通导入数据
第一步,创建一个数据文件,比如:load.text,内容如下
5,xxx,22
6,ooo,33
7,jjj,44这三个列对应了我Doris中的数据库和表 testdb.test_streamload ,然后执行命令把 load.txt 上传到HDFS中
hadoop fs -put ./load.txt /
第二步:执行命令,把HDFS上的load.txt 数据导入到Doris中,访问 http://ip:8030/ ,通过界面导入如下
LOAD LABEL testdb.lable_test_streamload //标签,用来判断重复的(DATA INFILE("hdfs://192.168.220.253:9000/load.txt") //HDFS上的数据文件INTO TABLE `test_streamload` //表名COLUMNS TERMINATED BY "," //数据分隔符 (user_id,name,age) //数据对应的列)with HDFS ("fs.defaultFS"="hdfs://192.168.220.253:9000", //hdfs默认地址"hdfs_user"="root" //hdfs用户名)PROPERTIES("timeout"="1200","max_filter_ratio"="0.1");
执行后效果如下:

然后通过:select * from test_streamload 即可查看导入的数据
数据的导出
数据导出(Export)是 Doris 提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据,以文本的格式,通过 Broker 进程导出到远端存储上,如 HDFS / 对象存储(支持 S3 协议)等。
访问:http://192.168.220.253:8030/ ,执行导出命令
EXPORT TABLE testdb.test_streamload //导出的数据库和表
PARTITION (test_streamload) //分区多个分区用逗号分开
TO "hdfs://192.168.220.253:9000/test_streamload" //HDFS地址,后面是表名
PROPERTIES
("label" = "mylabel", //标签"column_separator"=",", //分隔符"columns" = "user_id,username,age", //导出的字段名"exec_mem_limit"="2147483648", "timeout" = "3600"
)
WITH BROKER "fs_broker" // brocker的名字
("username" = "root","password"="123456"
);
- 查看分区命令:show PARTITIONS from 数据库.表;
- fs_broker :Brocker的名字可以在 doris控制台界面的 system中查看
- label:本次导出作业的标识。后续可以使用这个标识查看作业状态
- column_separator:列分隔符。默认为 \t。支持不可见字符,比如 ‘\x07’
- columns:要导出的列,使用英文状态逗号隔开,如果不填这个参数默认是导出表的所有列。
- exec_mem_limit:表示 Export 作业中,一个查询计划在单个 BE 上的内存使用限制。默认 2GB。单位字节。
- timeout:作业超时时间。默认 2 小时。单位秒。

执行成功后,可以通过HDFS控制台查看导出的文件

文章结束,如果对你有所帮助请收藏加好评哦
相关文章:
四.海量数据实时分析-Doris数据导入导出
数据导入 1.概述 Apache Doris 提供多种数据导入方案,可以针对不同的数据源进行选择不同的数据导入方式。 数据源导入方式对象存储(s3),HDFS使用 Broker 导入数据本地文件Stream Load, MySQL LoadKafka订阅 Kafka 数据Mysql、PostgreSQL&a…...

一. 从Hive开始
1. 怎么理解Hive Hive不能理解成一个传统意义上的数据库,应该理解成一个解决方案。 是Hadoop在hdfs和mapreduce之后才出现的一个结构化数据处理的解决方案。 Hdfs解决了大数据的存储问题,mapreduce解决了数据的计算问题。 一切似乎很美好。 但是使用成本…...
Linux下的PWM驱动
PWM PWM简介⭕ **PWM(Pulse Width Modulation,脉冲宽度调制)**是一种利用微处理器的数字输出对模拟电路进行控制的技术。通过改变脉冲的占空比,可以控制模拟电路的输出电压或电流。PWM技术广泛应用于电机控制、灯光调节、音频信号…...

日语输入法平假名和片假名切换
在学日语输入法的时候,我们在使用罗马音输入的时候,在进行平假名和片假名切换: 1、使用电脑在打字,日语输入法切换的时候使用 Shift Alt 如果日语输入法显示为 A 需要切换为 あ的话可以按Caps Lock键 。(相当于中文…...

Oracle向量搜索及其应用场景
Oracle 向量搜索(AI Vector Search)是一个集成到 Oracle 数据库中的功能,旨在优化人工智能(AI)工作负载。它允许用户存储和查询非结构化数据的语义内容,如文档、图像等,形式为向量。 向量数据类…...

【排序算法】六、快速排序补充:三指针+随机数法
「前言」文章内容是对快速排序算法的补充,之前的算法流程细节多难处理,这里补充三指针随机数法(递归),这个容易理解,在时间复杂度上也更优秀。 快排:三指针随机数法 原理跟之前的一致ÿ…...

PyTorch torch.cdist函数介绍及示例代码
1. torch.cdist 函数介绍 torch.cdist 是 PyTorch 中用于计算两组向量之间成对距离的函数。它可以计算两个张量(矩阵)中的每对向量之间的距离,支持多种距离度量方式,如欧氏距离(默认)或 p 范数距离。 函数原型 torch.cdist(x1, x2, p=2.0, compute_mode=use_mm_for_eu…...

CTK框架(四): 插件编写
目录 1.生成插件 1.1.环境说明 1.2.服务类,纯虚类,提供接口 1.3.实现插件类,实现纯虚函数 1.4.激活插件,加入ctk框架的生命周期中 1.5.添加资源文件 1.6..pro文件 2.使用此插件 3.总结 1.生成插件 1.1.环境说明 编译ct…...

深入理解C代码中的条件编译
引言 条件编译是 C 编程中的一个重要特性,它允许开发人员根据不同的条件选择性地编译源代码的不同部分。这一特性对于编写跨平台的程序、优化代码性能或控制编译时资源消耗等方面非常重要。本文将深入探讨条件编译的工作原理、使用场景、高级应用以及注意事项&…...

Ubuntu16.04操作系统-内核优化
1. 概述 本文所用优化是生产环境中经过长期验证的内核优化策略,针对的服务器与POD主要用于高CPU、高内存、高IO的业务场景。 备注: OS: ubuntu16.04, 内核: 4.15.0-147-generic 主要涵盖以下内容优化: ulimit优化加强tcp参数其他内存参数 …...

Qt/C++编写的Onvif调试助手调试神器工具/支持云台控制/预置位设置等/有手机版本
一、功能特点 广播搜索设备,支持IPC和NVR,依次返回。可选择不同的网卡IP进行对应网段设备的搜索。依次获取Onvif地址、Media地址、Profile文件、Rtsp地址。可对指定的Profile获取视频流Rtsp地址,比如主码流地址、子码流地址。可对每个设备设…...

【原创】java+swing+mysql密码管理器系统设计与实现
个人主页:程序员杨工 个人简介:从事软件开发多年,前后端均有涉猎,具有丰富的开发经验 博客内容:全栈开发,分享Java、Python、Php、小程序、前后端、数据库经验和实战 文末有本人名片,希望和大家…...

JavaEE-HTTPHTTPS
目录 HTTP协议 一、概念 二、http协议格式 http请求报文 http响应报文 URL格式 三、认识方法 四、认识报头 HTTP响应中的信息 HTTPS协议 对称加密 非对称加密 中间人攻击 解决中间人攻击 HTTP协议 一、概念 HTTP (全称为 "超⽂本传输协议") 是⼀种应⽤…...
iLogtail 开源两周年:社区使用调查报告
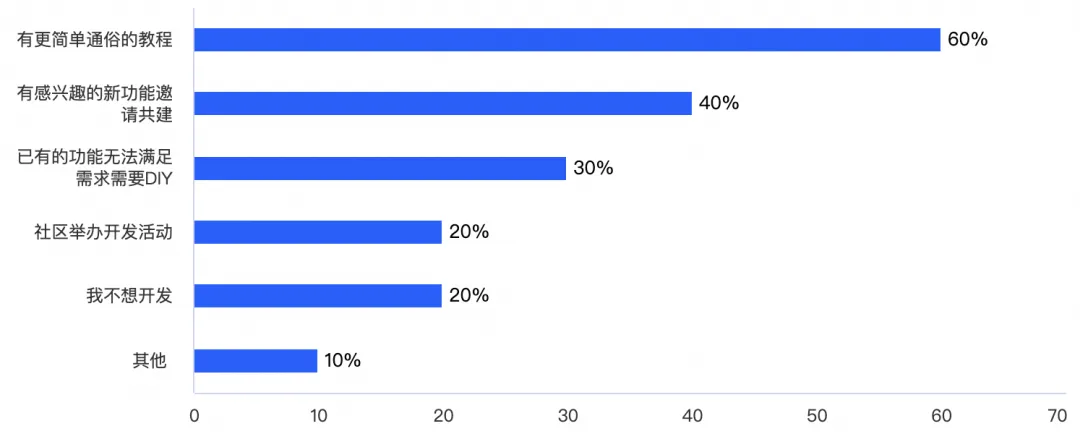
作者:玄飏 iLogtail 作为阿里云开源的可观测数据采集器,以其高效、灵活和可扩展的特性,在可观测采集、处理与分析领域受到了广泛的关注与应用。在 iLogtail 两周年之际,我们对 iLogtail 开源社区进行了一次使用调研,旨…...

Ubuntu 比较两个文件夹
比较两个文件夹下的大量文件是否一致,可以通过以下几种方式完成: 1. 使用 diff 命令 diff 命令不仅可以比较文件,还能递归比较文件夹。可以使用 -r 选项来递归比较两个目录下的文件: diff -r /path/to/dir1 /path/to/dir2 如…...

两数之和--力扣1
两数之和 题目思路C代码 题目 思路 根据题目要求,元素不能重复且不需要排序,我们这里使用哈希表unordered_map。注意题目说了只对应一种答案。 所以我们在循环中,使用目标值减去当前循环的nums[i],得到差值,如果我们…...
new()创建Vue实例)
vue原理分析(三)new()创建Vue实例
今天我们来分析Vue实例的创建 代码如下: Vue.config.productionTip falsenew Vue({render: h > h(App),}).$mount(#app) Vue.config.productionTip false 这个配置成false,是阻止启动生产消息 new Vue({render: h > h(App),}).$mount(#app)…...

Spring MVC: 构建Web应用的强大框架
Spring MVC: 构建现代Web应用的强大框架 1. MVC设计模式简介 MVC (Model-View-Controller) 是一种广泛使用的软件设计模式,它将应用程序的逻辑分为三个相互关联的组件: Model (模型): 负责管理数据、业务逻辑和规则。View (视图): 负责用户界面的展示,将数据呈现给用户。Con…...

网络学习-eNSP配置NAT
NAT实现内网和外网互通 #给路由器接口设置IP地址模拟实验环境 <Huawei>system-view Enter system view, return user view with CtrlZ. [Huawei]undo info-center enable Info: Information center is disabled. [Huawei]interface gigabitethernet 0/0/0 [Huawei-Gigabi…...

动态规划-最长回文子串
题目描述 给你一个字符串 s,找到 s 中最长的 回文子串。 对于该题使用中心扩展法在某些情况下可以比动态规划方法更优,尤其是在处理较长字符串时。这是因为中心扩展法具有更好的空间复杂度,并且在实际应用中可能具有更快的运行速度…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...

Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制
Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一款强大的分布式数据集版本控制工具,它比电子表格更强大,比数…...

事故数据四年连降,为何山西煤矿的命还是悬在一根绳上?
说实话,写到山西煤矿这四个字,我心里就咯噔一下。2026年5月22日19时29分,山西长治市沁源县山西通洲集团留神峪煤业有限公司井下发生瓦斯爆炸事故,截至到写稿,事故已造成90人遇难。看的心里堵得慌。我特意去翻了翻这些年…...
)
UnityWebRequest遇到SSL证书错误别慌!手把手教你用CertificateHandler绕过验证(附完整C#代码)
Unity开发中SSL证书验证问题的应急处理与深度解析当你在Unity项目中使用UnityWebRequest进行HTTPS通信时,突然遇到"Curl error 60"或"SSL CA certificate error"这类证书验证错误,确实会让人措手不及。特别是在开发关键阶段…...

基于树莓派与ADS1248的高精度多通道RTD温度采集系统设计与实践
1. 项目概述:低成本、高精度的多通道温度采集方案在工业自动化、环境监测或者实验室数据记录领域,多通道、高精度的温度测量一直是个既关键又有点“烧钱”的环节。传统的方案要么通道数有限,要么精度和成本难以兼得,尤其是在需要多…...

高端展馆数字交互设计,极简科技风多人同屏答题系统
随着城市文旅不断升级,高端展厅、城市规划馆、艺术展馆、文旅综合体逐步走向精细化、品质化、智能化。相较于普通大众展馆,高端场馆对空间美学、设备质感、交互体验、视觉呈现有着严苛标准。在数字化改造过程中,很多场馆容易踩入设计误区&…...

解决grunt-webfont常见问题:跨浏览器兼容与Firefox字体加载故障排除指南
解决grunt-webfont常见问题:跨浏览器兼容与Firefox字体加载故障排除指南 【免费下载链接】grunt-webfont SVG to webfont converter for Grunt 项目地址: https://gitcode.com/gh_mirrors/gr/grunt-webfont grunt-webfont 是一个强大的SVG转网页字体工具&…...

5分钟快速上手:E7Helper第七史诗智能挂机助手完整使用指南
5分钟快速上手:E7Helper第七史诗智能挂机助手完整使用指南 【免费下载链接】e7Helper 【Epic Seven Auto Bot】第七史诗多功能覆盖脚本(刷书签🍃,挂讨伐、后记、祭坛✌️,挂JJC等📛,多服务器支持Ǵ…...