Linux 性能调优之CPU上下文切换
写在前面
- 博文内容为 Linux 性能指标 CPU 上下文切换认知
- 内容涉及:
- 上下文认知,发生上下文切换的场景有哪些
- 上下文指标信息查看,内核上下文切换事件跟踪,系统上下文切换统计
- 上下文异常场景分析,CPU亲和性配置优化上下文
- 理解不足小伙伴帮忙指正 😃,生活加油
99%的焦虑都来自于虚度时间和没有好好做事,所以唯一的解决办法就是行动起来,认真做完事情,战胜焦虑,战胜那些心里空荡荡的时刻,而不是选择逃避。不要站在原地想象困难,行动永远是改变现状的最佳方式
上下文认知
什么是CPU上下文切换?
通俗的话讲,给定的CPU在某个时间点仅可以运行一个进程,为了制造出单处理器同时运行多个任务的假象(实际受限系统调度器:调度策略 + 调度优先级), 每个进程完成他们的任务一般都需要停止和启动很多次。 Linux内核就要不断地在不同的进程间切换。这种不同进程间的切换称为上下文切换
上下文切换时, CPU要保存旧进程的所有上下文信息,并取出新进程的所有上下文信息。上下文中包含了 Linux 跟踪新进程的大量信息,其中包括: 进程正在执行的指令,分配给进程的内存,进程打开的文件等
所以实际上上下文切换涉及大量信息的移动,上下文切换的开销可以是相当大的
上下文切换可以是内核调度的结果。简单来讲,为了保证公平地给每个进程分配处理器时间,内核会周期性地中断正在运行的进程,在适当的情况下,内核调度器会决定开始另一个进程,而不是让当前进程继续执行。
每次这种周期性中断或定时发生时,系统都可能进行上下文切换。每秒定时中断的次数与架构和内核版本有关。
一个检查中断频率的简单方法是用 /proc/interrupts 文件,它可以确定已知时长内发生的中断次数。
通过这个命令,可以观察到5秒钟内定时器中断次数的变化
┌──[root@vms81.liruilongs.github.io]-[~]
└─$cat /proc/interrupts | grep time; sleep 5 ;cat /proc/interrupts | grep time0: 337 0 IO-APIC-edge timerLOC: 9896498 9871317 Local timer interrupts0: 337 0 IO-APIC-edge timerLOC: 9901529 9876213 Local timer interrupts
┌──[root@vms81.liruilongs.github.io]-[~]
└─$
LOC 即为本地定时器中断
上面定时器的启动频率为 (9896498-9901529)/5 =1000,即每秒要中断 1000次,同时也可以理解为内核在 sleep 进程执行中,每秒发生 1000 次 CPU 定时中断
如果
上下文切换明显多于定时器中断,那么这些切换极有可能是由I/O请求或其他长时间运行的系统调用(如休眠)造成的。当应用请求的操作不能立即完成时,内核启动该操作,保存请求进程,并尝试切换到另一个已就绪进程。这能让处理器尽量保持忙状态。
#上下文切换数量
cs=$(vmstat 1 1 | awk 'NR==3{print $12}')
实际中调度策略不同,定时器中断的意义也不一样:
实时调度策略 :如FIFO(先进先出)和时间片轮转(RR),这些策略依赖于定时中断来确保实时进程的及时执行,但同时也需要考虑非实时进程的调度以避免饥饿
普通调度策略 :如CFS,定时中断用于动态调整时间片,以实现公平性和效率的平衡
什么是上下文
当多个进程进行切换时,内核会包含前一个和后一个进程的相关信息。每次一个进程让出CPU时,内核都会存储进程当前的操作状态,当以后该进程再次被调度回CPU时,可以从相同的位置恢复操作。
这些操作状态数据又被称为上下文,包含CPU的寄存器数据以及程序的计数器数据。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
给进程切换CPU时间片,就是所谓的上下文切换。CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务
保存下来的上下文,会存储在系统内核中,并在任务重新被分配到时间片时再次被加载,这样看起来系统实际中同时运行多个任务,具体和对应的CPU 调度策略有关系,不同调度策略分配时间片策略不同。
只有进程会发生上下文切换么?
实际上不仅进程会发生CPU上下文切换,线程,协程和中断也会发生CPU上下文切换。CPU上下文切换包括:
进程上下文切换线程上下文切换协程上下文切换中断上下文切换
进程上下文切换涉及到虚拟内存、栈、全局变量等用户空间资源,以及内核堆栈、寄存器等内核空间的状态。这种切换发生在进程调度时,例如:
CPU时间片用完、系统资源不足、进程通过 sleep 函数主动挂起、高优先级进程抢占时间片、硬件中断时CPU上的进程被挂起转而执行内核中的中断服务
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。

内核空间(Ring 0)具有最高权限,可以直接访问所有资源;用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
进程既可以在用户空间运行,又可以在内核空间中运行。
进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容.
这里可以通过 bcc 或者 perf 工具来跟踪系统调用
采集数据
┌──[root@liruilongs.github.io]-[~]
└─$perf record -g $(which cat) test.log
Holler
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.012 MB perf.data (2 samples) ]
┌──[root@liruilongs.github.io]-[~]
└─$
输出数据
┌──[root@liruilongs.github.io]-[~]
└─$perf script > perf_script.txt
┌──[root@liruilongs.github.io]-[~]
└─$cat perf_script.txt
cat 3070 403.637613: 250000 cpu-clock:pppH: ffffffffa2afb616 vma_interval_tree_remove+0x156 ([kernel.kallsyms])ffffffffa2b12068 unlink_file_vma+0x48 ([kernel.kallsyms])ffffffffa2b05da1 free_pgtables+0x71 ([kernel.kallsyms])ffffffffa2b1176a unmap_region+0x10a ([kernel.kallsyms])ffffffffa2b13bcd __do_munmap+0x20d ([kernel.kallsyms])ffffffffa2b156f6 mmap_region+0x2f6 ([kernel.kallsyms])ffffffffa2b15de0 do_mmap+0x380 ([kernel.kallsyms])ffffffffa2ae69b8 vm_mmap_pgoff+0xd8 ([kernel.kallsyms])ffffffffa2b131b8 ksys_mmap_pgoff+0x58 ([kernel.kallsyms])ffffffffa284b2a3 __x64_sys_mmap+0x33 ([kernel.kallsyms])ffffffffa2805089 x64_sys_call+0x3b9 ([kernel.kallsyms])ffffffffa35c2f36 do_syscall_64+0x56 ([kernel.kallsyms])ffffffffa36000df entry_SYSCALL_64_after_hwframe+0x67 ([kernel.kallsyms])7ff93a740cb7 mmap64+0x17 (/usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2)7ff93a724601 _dl_map_object+0x1f1 (/usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2)cat 3070 403.637863: 250000 cpu-clock:pppH: ffffffffa28a5a6f do_user_addr_fault+0x2ff ([kernel.kallsyms])ffffffffa35c6ed7 exc_page_fault+0x77 ([kernel.kallsyms])ffffffffa3600bb7 asm_exc_page_fault+0x27 ([kernel.kallsyms])ffffffffa2eb6130 copy_user_generic_unrolled+0xa0 ([kernel.kallsyms])ffffffffa2ac3705 filemap_read+0x165 ([kernel.kallsyms])ffffffffa2ac3a62 generic_file_read_iter+0xe2 ([kernel.kallsyms])ffffffffa2c6ecfb ext4_file_read_iter+0x5b ([kernel.kallsyms])ffffffffa2b9b65a new_sync_read+0x10a ([kernel.kallsyms])ffffffffa2b9bff3 vfs_read+0x103 ([kernel.kallsyms])ffffffffa2b9eac7 ksys_read+0x67 ([kernel.kallsyms])ffffffffa2b9eb69 __x64_sys_read+0x19 ([kernel.kallsyms])ffffffffa2806a8a x64_sys_call+0x1dba ([kernel.kallsyms])ffffffffa35c2f36 do_syscall_64+0x56 ([kernel.kallsyms])ffffffffa36000df entry_SYSCALL_64_after_hwframe+0x67 ([kernel.kallsyms])7ff93a5f37e2 read+0x12 (/usr/lib/x86_64-linux-gnu/libc.so.6)┌──[root@liruilongs.github.io]-[~]
└─$也可以使用 strace 命令
┌──[root@liruilongs.github.io]-[~]
└─$strace cat test.log
execve("/usr/bin/cat", ["cat", "test.log"], 0x7ffcc8683ce8 /* 35 vars */) = 0
brk(NULL) = 0x55f45d320000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fffbabbec00) = -1 EINVAL (无效的参数)
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f05f1400000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (没有那个文件或目录)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=62779, ...}, AT_EMPTY_PATH) = 0
mmap(NULL, 62779, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f05f13f0000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\237\2\0\0\0\0\0"..., 832) = 832
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
pread64(3, "\4\0\0\0 \0\0\0\5\0\0\0GNU\0\2\0\0\300\4\0\0\0\3\0\0\0\0\0\0\0"..., 48, 848) = 48
pread64(3, "\4\0\0\0\24\0\0\0\3\0\0\0GNU\0I\17\357\204\3$\f\221\2039x\324\224\323\236S"..., 68, 896) = 68
newfstatat(3, "", {st_mode=S_IFREG|0755, st_size=2220400, ...}, AT_EMPTY_PATH) = 0
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
mmap(NULL, 2264656, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f05f11c7000
mprotect(0x7f05f11ef000, 2023424, PROT_NONE) = 0
mmap(0x7f05f11ef000, 1658880, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x28000) = 0x7f05f11ef000
mmap(0x7f05f1384000, 360448, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1bd000) = 0x7f05f1384000
mmap(0x7f05f13dd000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x215000) = 0x7f05f13dd000
mmap(0x7f05f13e3000, 52816, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f05f13e3000
close(3) = 0
mmap(NULL, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f05f11c4000
arch_prctl(ARCH_SET_FS, 0x7f05f11c4740) = 0
set_tid_address(0x7f05f11c4a10) = 3659
set_robust_list(0x7f05f11c4a20, 24) = 0
rseq(0x7f05f11c50e0, 0x20, 0, 0x53053053) = 0
mprotect(0x7f05f13dd000, 16384, PROT_READ) = 0
mprotect(0x55f45d2aa000, 4096, PROT_READ) = 0
mprotect(0x7f05f143a000, 8192, PROT_READ) = 0
prlimit64(0, RLIMIT_STACK, NULL, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
munmap(0x7f05f13f0000, 62779) = 0
getrandom("\xc0\x67\xb1\x59\x59\xe4\xa9\xdc", 8, GRND_NONBLOCK) = 8
brk(NULL) = 0x55f45d320000
brk(0x55f45d341000) = 0x55f45d341000
openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=6213280, ...}, AT_EMPTY_PATH) = 0
mmap(NULL, 6213280, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f05f0bd7000
close(3) = 0
newfstatat(1, "", {st_mode=S_IFCHR|0600, st_rdev=makedev(0x88, 0), ...}, AT_EMPTY_PATH) = 0
openat(AT_FDCWD, "test.log", O_RDONLY) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=7, ...}, AT_EMPTY_PATH) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
mmap(NULL, 139264, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f05f0bb5000
read(3, "Holler\n", 131072) = 7
write(1, "Holler\n", 7Holler
) = 7
read(3, "", 131072) = 0
munmap(0x7f05f0bb5000, 139264) = 0
close(3) = 0
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
┌──[root@liruilongs.github.io]-[~]
└─$在内核函数调用的过程有没有发生 CPU 上下文的切换呢?
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的
进程上下文切换,是指从一个进程切换到另一个进程运行。而系统调用过程中一直是同一个进程在运行。
系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
进程上下文切换跟系统调用又有什么区别呢?
进程是由内核来管理调度的,进程的切换只能发生的内核态,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
进程的上下文切换就比系统调用时多了一步:
在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也是导致平均负载升高的一个重要因素,尤其是这 CPU 处于饱和状态的时候。
Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。
当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
什么时候会切换进程上下文?
进程切换时需要切换上下文,默认调度策略情况下,Linux 为每个 CPU 维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
进程在什么时候才会被调度到 CPU 上运行呢?
实际上调度策略不同,优先级不同,调度结果也不同,大多数情况下:
-
当某个进程的分配的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
-
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
-
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
-
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
-
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
进程本质上是由线程构成,当一个进程为单线程时,可以理解线程就是进程。
线程上下文切换
线程与进程最大的区别在于:
- 线程是
调度的基本单位(所谓内核中的任务调度,实际上的调度对象是线程,) - 进程则是
资源拥有的基本单位(即系统资源的申请,给线程提供了虚拟内存、全局变量等资源)
对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的
虚拟内存和全局变量等资源。这些资源在上下文切换时是不涉及的。 - 线程也有自己的私有数据,比如
栈和寄存器等,这些在上下文切换时也是需要保存的。
线程的上下文切换实际上就可以分为两种情况:
- 前后两个线程属于不同的进程,切换过程和进程切换时一样的
- 前后两个线程属于同一个进程,
虚拟内存和全局变量共享,只需要切换线程的私有数据。
所以理论上从上下文切换的角度考虑,多线程的资源消耗小与多进程。
既然线程可以共享进程的数据,重而在上下文切换节省切换时数据的保存和刷新,那么是否存在可以共享线程的数据,重而节省更多的时间,这就是协程。
协程的上下文切换
协程是一种用户态的轻量级线程,完全由用户程序控制,协程创建和销毁的开销非常小(共享进程的内存空间和资源,不需要操作系统分配独立的栈空间和寄存器状态),因为它们不需要内核介入。
协程间的上下文切换完全在用户态进行,开销非常小。实际上如果为单线程的协程上下文切换,如果协程不执行系统调用,是不会涉及到CPU上下文切换的。当协程执行系统调用时,会涉及到从用户态切换到内核态
实际的协程上下文切换分为:
- 多个线程的不同协程上下文切换
- 多个进程的不同协程上下文切换
协程的上下文切换开销远小于线程,因为:
- 线程切换涉及到更多的状态信息,如所有
寄存器、线程堆栈等, - 协程切换主要是保存和恢复少量的状态信息,如
程序计数器和少量寄存器。
中断上下文切换
处理器还周期性地从硬件设备接收中断。当设备有事件需要内核处理时,它通常就会触发这些中断。
比如,如果磁盘控制器刚刚完成从驱动器取数据块的操作,并准备好提供给内核,那么磁盘控制器就会触发一个中断。对内核收到的每个中断,如果已经有相应的已注册的中断处理程序,就运行该程序,否则将忽略这个中断。
中断处理程序在系统中具有很高的运行优先级,并且通常执行速度也很快,查看/proc/interrupts文件可以显示出哪些CPU上触发了哪些中断。
┌──[root@vms81.liruilongs.github.io]-[~]
└─$cat /proc/interruptsCPU0 CPU10: 337 0 IO-APIC-edge timer1: 10 0 IO-APIC-edge i80428: 1 0 IO-APIC-edge rtc09: 0 0 IO-APIC-fasteoi acpi12: 16 0 IO-APIC-edge i804214: 0 0 IO-APIC-edge ata_piix15: 0 0 IO-APIC-edge ata_piix17: 57939 0 IO-APIC-fasteoi ioc018: 14 9800 IO-APIC-fasteoi ens3224: 0 0 PCI-MSI-edge PCIe PME, pciehp25: 0 0 PCI-MSI-edge PCIe PME, pciehp26: 0 0 PCI-MSI-edge PCIe PME, pciehp27: 0 0 PCI-MSI-edge PCIe PME, pciehp
.......................THR: 0 0 Threshold APIC interruptsDFR: 0 0 Deferred Error APIC interruptsMCE: 0 0 Machine check exceptionsMCP: 37 37 Machine check pollsERR: 0MIS: 0PIN: 0 0 Posted-interrupt notification eventPIW: 0 0 Posted-interrupt wakeup event
┌──[root@vms81.liruilongs.github.io]-[~]
└─$
快速查看中断的次数:
#发生中断数量irq=$(vmstat 1 1 | awk 'NR==3{print $11}')
中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。
中断上下文切换,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
可以这么理解,中断上下文切换发生的时候CPU并没有离开内核态,所以不需要用户态的东西,只是需要部分内核态数据。所以中断上下文切换相比进程上下文切换消耗更少的资源
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
即便是保存少量的内核态数据,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。
上下文指标信息查看
内核上下文切换事件跟踪
通过确定上下文切换的位置,可以分析哪些进程或线程导致了频繁的上下文切换,从而优化系统性能。
确定内核中发生上下文切换的位置,可以使用 sched:sched_switch 内核跟踪点
sched:sched_switch 是 BPF(Berkeley Packet Filter)工具集中用于跟踪内核上下文切换事件的跟踪点
# ./stackcount -P t:sched:sched_switch__schedulescheduleworker_threadkthreadret_from_forkkworker/0:2 [25482]1__schedulescheduleschedule_hrtimeout_range_clockschedule_hrtimeout_rangeep_pollSyS_epoll_waitentry_SYSCALL_64_fastpathepoll_waitLsun/nio/ch/SelectorImpl;::lockAndDoSelectLsun/nio/ch/SelectorImpl;::selectLio/netty/channel/nio/NioEventLoop;::selectLio/netty/channel/nio/NioEventLoop;::runInterpreterInterpretercall_stubJavaCalls::call_helper(JavaValue*, methodHandle*, JavaCallArguments*, Thread*)JavaCalls::call_virtual(JavaValue*, KlassHandle, Symbol*, Symbol*, JavaCallArguments*, Thread*)JavaCalls::call_virtual(JavaValue*, Handle, KlassHandle, Symbol*, Symbol*, Thread*)thread_entry(JavaThread*, Thread*)JavaThread::thread_main_inner()JavaThread::run()java_start(Thread*)start_threadjava [4996]1... (omitted for brevity)__schedulescheduleschedule_preempt_disabledcpu_startup_entryxen_play_deadarch_cpu_idle_deadcpu_startup_entrycpu_bringup_and_idleswapper/1 [0]289
从这些栈跟踪中,我们可以得出以下结论:
- 有一个
工作线程(kworker)和一个Java进程导致了上下文切换。 - 有一个
CPU大部分时间都是空闲的(swapper/1 [0])。
运行命令(进程)的上下文切换次数统计
┌──[root@liruilongs.github.io]-[~]
└─$yum -y install perf
........
使用了 Linux 的 perf stat命令来收集关于 sleep 2 命令执行期间的性能计数器统计信息
┌──[root@liruilongs.github.io]-[~]
└─$perf stat sleep 2Performance counter stats for 'sleep 2':12.04 msec task-clock # 0.006 CPUs utilized1 context-switches # 0.083 K/sec1 cpu-migrations # 0.083 K/sec74 page-faults # 0.006 M/sec3,328,860 cycles # 0.276 GHz0 instructions # 0.00 insn per cycle289,196 branches # 24.020 M/sec12,686 branch-misses # 4.39% of all branches2.034208658 seconds time elapsed0.000000000 seconds user0.032226000 seconds sys┌──[root@liruilongs.github.io]-[~]
└─$统计信息的解释:
task-clock:任务时钟,表示命令执行的总时间(以毫秒为单位)。context-switches:上下文切换次数,表示在命令执行期间发生的进程上下文切换次数。cpu-migrations:CPU 迁移次数,表示在命令执行期间发生的进程在不同 CPU 之间的迁移次数。page-faults:缺页错误次数,表示在命令执行期间发生的内存页面错误次数(可以简单理解为类似缓存穿透)。cycles:CPU 周期数,表示命令执行期间的 CPU 周期数。instructions:指令数,表示命令执行期间执行的指令数。branches:分支数(分支预测的次数),表示命令执行期间执行的分支指令数。branch-misses:分支未命中数,表示命令执行期间发生的分支预测错误次数。
汇总数据:
seconds time elapsed: 命令的总执行时间seconds user:用户空间时间seconds user:系统空间时间
sleep 2 命令主要在内核态执行,用户态执行时间几乎为 0。任务执行期间发生了 1 次上下文切换和 1 次 CPU 迁移。任务执行期间发生了 74 次页面错误。
由于 sleep 命令本身不执行很多指令,因此指令数为 0,分支缺失率为 4.39%。
使用了 Linux 的 perf 命令来收集关于 dd if=/dev/zero of=/dev/null bs=2048 count=100000 命令执行期间的性能计数器统计信息。
┌──[root@liruilongs.github.io]-[~]
└─$dd if=/dev/zero of=/dev/null bs=2048 count=100000
记录了100000+0 的读入
记录了100000+0 的写出
204800000字节(205 MB,195 MiB)已复制,0.0863494 s,2.4 GB/s
┌──[root@liruilongs.github.io]-[~]
└─$perf stat !!
perf stat dd if=/dev/zero of=/dev/null bs=2048 count=100000
记录了100000+0 的读入
记录了100000+0 的写出
204800000字节(205 MB,195 MiB)已复制,0.0960513 s,2.1 GB/sPerformance counter stats for 'dd if=/dev/zero of=/dev/null bs=2048 count=100000':96.63 msec task-clock # 0.993 CPUs utilized 3 context-switches # 31.046 /sec 1 cpu-migrations # 10.349 /sec 86 page-faults # 889.991 /sec <not supported> cycles <not supported> instructions <not supported> branches <not supported> branch-misses 0.097339885 seconds time elapsed0.052670000 seconds user0.044566000 seconds sys┌──[root@liruilongs.github.io]-[~]
└─$
系统级上下文切换统计
vmstat 是一个用于报告虚拟内存统计信息的工具,也可以用来监控系统的整体性能和健康状况
┌──[root@liruilongs.github.io]-[~]
└─$vmstat -S m 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st1 0 0 32658 9 3600 0 0 7 1 31 53 0 0 100 0 00 0 0 32658 9 3600 0 0 0 0 440 794 0 0 100 0 00 0 0 32658 9 3600 0 0 0 0 425 774 0 0 100 0 0
┌──[root@liruilongs.github.io]-[~]
└─$
procs 列显示了进程和线程的相关统计信息。
- r 表示正在运行的进程或线程数。
- b 表示处于阻塞状态的进程或线程数。
system 列显示了系统调用和上下文切换的相关统计信息。
- in 表示
每秒的中断数。 - cs 表示
每秒的上下文切换数。
cpu 列显示了 CPU 的使用情况统计信息。
- us 表示用户空间进程的 CPU 使用率。
- sy 表示系统空间进程的 CPU 使用率。
- id 表示 CPU 空闲时间的百分比。
- wa 表示等待 I/O 操作的 CPU 时间的百分比。
- st 表示被虚拟化软件(如果有)偷取的 CPU 时间的百分比。
pcp dstat 是 Performance Co-Pilot 的一个工具,它结合了dstat和pmval命令的功能,提供了实时系统性能监控的功能。
┌──[root@liruilongs.github.io]-[~]
└─$ pcp dstat
You did not select any stats, using -cdngy by default.
----total-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw0 0 97 0 0| 0 0 | 126 637 | 0 0 |1036 11110 0 95 2 0| 0 0 | 66 302 | 0 0 |1135 12560 0 96 0 0|4094B 0 | 66 318 | 0 0 |1368 15540 0 98 0 0| 0 0 | 186 318 | 0 0 | 940 10130 0 96 0 0| 0 0 | 126 310 | 0 0 |1180 13021 0 96 1 0|4098B 0 | 66 310 | 0 0 |1114 11861 0 97 0 0| 0 0 | 186 326 | 0 0 |1225 13460 0 98 0 0| 0 0 | 126 318 | 0 0 |1070 11500 0 97 0 0| 0 0 | 66 310 | 0 0 |1005 10931 0 91 1 0|4099B 0 | 186 310 | 0 0 |2564 32551 0 93 0 0| 92k 56k| 126 326 | 0 0 |1807 2085
.......
┌──[root@liruilongs.github.io]-[~]
└─$
- CPU 使用情况(
usr:用户态 CPU 使用率,sys:内核态 CPU 使用率,idl:空闲 CPU 使用率,wai:等待 I/O 的 CPU 使用率,stl:偷取的 CPU 使用率) - 磁盘读写统计(
read:读取的字节数,writ:写入的字节数) - 网络接收和发送统计(
recv:接收的字节数,send:发送的字节数) - 分页统计(
in:页面读取数,out:页面写入数) - 系统调用和上下文切换统计(
int:系统调用次数,csw:上下文切换次数
pcp dstat 命令默认选项是 -cdngy ,等同于 --cpu,-disk,--net,--page,--sys,可以同时查看多组数据
也可以查看指定的指标信息,查看 CPU 和进程信息,每个 2 秒获取一次数据,获取 8 组数据
[root@workstation ~]# pkill sha1sum
[1]+ Terminated sha1sum /dev/zero
[root@workstation ~]# pcp dstat --time --cpu --proc 2 8
----system---- ----total-usage---- ---procs---time |usr sys idl wai stl|run blk new
17-09 05:03:50| | 0 0
17-09 05:03:52| 0 0 100 0 0| 0 0 0
17-09 05:03:54| 1 0 100 0 0| 0 0 0
17-09 05:03:56| 0 0 100 0 0| 0 0 0
17-09 05:03:58| 0 0 100 0 0| 0 0 0
17-09 05:04:00| 0 0 100 0 0| 0 0 0
17-09 05:04:02| 0 0 100 0 0| 0 0 0
17-09 05:04:04| 0 0 100 0 0| 0 0 0
指标说明:
- 时间戳(time):显示采样时的日期和时间。
- CPU 使用情况(usr:用户态 CPU 使用率,sys:内核态 CPU 使用率,idl:空闲 CPU 使用率,wai:等待 I/O 的 CPU 使用率,stl:偷取的 CPU 使用率)。
- 进程统计信息(run:运行中的进程数,blk:被阻塞的进程数,new:新进程数)。
也可以使用短命令的方式:-c:显示 CPU 使用情况。
自愿非自愿上下文切换查看
上下文切换可以分为:
voluntary(自愿)involuntary(非自愿)
查询单个进程:
通过查看/proc/{PID}/status文件,我们可以看到某个进程的自愿和非自愿上下文切换的次数。
┌──[root@vms99.liruilongs.github.io]-[~]
└─$cat /proc/$$/status | grep "voluntary"
voluntary_ctxt_switches: 272
nonvoluntary_ctxt_switches: 1
┌──[root@vms99.liruilongs.github.io]-[~]
└─$
voluntary_ctxt_switches: 272:表示当前进程自愿上下文切换的次数为 272 次。自愿上下文切换通常是由进程主动让出 CPU 时间片引起的,例如进程等待 I/O 操作完成或调用 sched_yield() 函数。
nonvoluntary_ctxt_switches: 1:表示当前进程非自愿上下文切换的次数为 1 次。非自愿上下文切换通常是由操作系统调度器强制进行的,例如当进程的时间片用完或高优先级进程抢占 CPU 时。
查询所有进程:
┌──[root@liruilongs.github.io]-[~]
└─$pidstat -w 5
Linux 5.15.0-112-generic (liruilongs.github.io) 2024年09月04日 _x86_64_ (4 CPU)08时08分02秒 UID PID cswch/s nvcswch/s Command
08时08分07秒 0 14 13.77 0.00 rcu_sched
08时08分07秒 0 15 0.20 0.00 migration/0
08时08分07秒 0 21 0.20 0.00 migration/1
08时08分07秒 0 27 0.20 0.00 migration/2
08时08分07秒 0 33 0.20 0.00 migration/3
08时08分07秒 0 43 2.00 0.00 kcompactd0
08时08分07秒 0 56 4.19 0.00 kworker/2:1-events
08时08分07秒 0 111 2.99 0.00 kworker/u8:2-writeback
08时08分07秒 0 120 0.40 0.00 kworker/3:1H-kblockd
08时08分07秒 0 133 5.99 0.00 kworker/1:2-events
08时08分07秒 0 191 0.60 0.00 kworker/1:1H-kblockd
这个工具需要注意,旧版本可能没有上下文相关的指标
cswch:表示每秒自愿上下文切换(voluntary context switches)的次数,nvcswch:表示每秒非自愿上下文切换(non voluntary context switches)的次数
pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标
实战
上下文频繁切换导致的CPU饱和分析
Sysbench是一个开源的、模块化的、跨平台的多线程性能测试工具,主要用于评估计算机系统在不同负载条件下的性能。
┌──[root@liruilongs.github.io]-[~]
└─$apt install sysbench -y
当前的 CPU 指标信息
┌──[root@liruilongs.github.io]-[~]
└─$vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st0 0 0 5195216 60404 1353744 0 0 140 43 620 4679 2 2 97 0 00 0 0 5195216 60404 1353744 0 0 0 0 439 762 1 0 98 0 00 0 0 5195216 60404 1353744 0 0 0 32 491 818 1 0 99 0 00 0 0 5195216 60412 1353736 0 0 0 16 425 683 1 0 99 0 00 0 0 5195216 60412 1353744 0 0 0 0 414 700 1 0 99 0 0
┌──[root@liruilongs.github.io]-[~]
└─$
模拟系统多线程饱和调度
┌──[root@liruilongs.github.io]-[~]
└─$sysbench --threads=10 --max-time=300 threads run
WARNING: --max-time is deprecated, use --time instead
sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)Running the test with following options:
Number of threads: 10
Initializing random number generator from current timeInitializing worker threads...Threads started!^C
┌──[root@liruilongs.github.io]-[~]
└─$
通过 vmstat 来打印CPU 相关指标信息
┌──[root@liruilongs.github.io]-[~]
└─$vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st9 0 0 5196448 60212 1353692 0 0 148 45 282 3355 1 1 98 0 05 0 0 5196448 60212 1353732 0 0 0 0 77739 1342743 32 53 16 0 09 0 0 5196448 60212 1353732 0 0 0 0 79785 1383450 28 56 16 0 07 0 0 5196448 60212 1353732 0 0 0 0 79945 1411280 27 57 16 0 07 0 0 5196224 60220 1353724 0 0 0 20 81862 1377316 29 55 16 0 0
┌──[root@liruilongs.github.io]-[~]
└─$可以看到 中断数(in)和上下文切换数(cs)大幅度增大,用户态和内核态 CPU 使用率同时增大,主要为内核态(sy),CPU 呈现饱和状态,空闲率(id)为 16%
同时系统就绪队列增加,有进程在等待CPU时间,但数量不是特别高,如果上面的指标长时间保持,可能需要排查是什么问题导致。
可以通过 pistat 来定位进程或在线程。通过 /proc/interrupts 分析中断类型
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interruptsCPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
每秒多少上下文切换才算正常?
当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,可能会出现性能问题。实际情况中,可能还需要根据 自愿切换和非自愿切换来分情况讨论:
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
配置CPU亲和性优化上下文
CPU 配置亲和性,限制特定进程仅在特定的CPU或内核上运行(也称为CPU绑定或CPU亲和性),可以减少上下文切换
当进程被限制在特定的CPU上运行时,操作系统会减少将其从一个CPU迁移到另一个CPU的可能性,从而减少了上下文切换的开销。上下文切换涉及保存和恢复进程的CPU状态,是一个相对昂贵的操作。
缓存局部性:如果进程频繁访问内存中的某些区域,将其绑定到某个CPU可以确保这些区域的数据和指令更可能驻留在该CPU的缓存中,从而提高了缓存命中率,降低了访问延迟。
taskset
taskset 是一个在 Linux 系统中用于设置或检索进程 CPU 亲和性(affinity)的命令行工具。通过 taskset,你可以控制进程应该在哪些 CPU 核心或哪些 CPU 集合上运行。这对于性能调优和故障隔离特别有用。
更改已运行进程的 CPU 亲和性
┌──[root@liruilongs.github.io]-[~]
└─$taskset -pc 0 3960506
pid 3960506's current affinity list: 0,1
pid 3960506's new affinity list: 0
┌──[root@liruilongs.github.io]-[~]
└─$
通过 /prod/{PID}/status 查看 CPU 亲和性
┌──[root@liruilongs.github.io]-[~]
└─$egrep Cpu /proc/3960506/status
Cpus_allowed: 1
Cpus_allowed_list: 0
通过 systemd 的 service unit 文件配置
systemd 提供了简单的方法可用实现 CPU 资源的亲和性限制。通过在服务的 unit 文件中[Service]块中,添加CPUAffinity=""即可。
[Service]
CPUAffinity=1-3
CPUAffinity=0-3:允许进程在 CPU 核心 0、1、2 和 3 上运行。CPUAffinity=0,2,3:允许进程在 CPU 核心 0、2 和 3 上运行,但不允许在核心 1 上运行
如果一个 unit 文件中有多行 CPUAffinity= 指令,systemd 确实会合并这些设置,但合并的方式是逻辑 OR,而不是逻辑 AND。这意味着只要在任何一行 CPUAffinity= 中列出的 CPU 核心,进程都有权限运行。
也可以使用 命令行的方式
┌──[root@liruilongs.github.io]-[~]
└─$systemctl set-property <service name> CPUAffinity=<value>
使用 cgroup 的 cpuset 进行 CPU 亲和性限制
这里需要注意 cgroup 版本不同,对应的限制方式也不同,在 v2 版本中不直接支持 cpuset 控制器。cpuset 控制器是 cgroup v1 中的一个功能,它允许管理员为 cgroup 中的进程分配特定的 CPU 核心和内存节点,在 cgroup v2 中,cpuset 功能被整合到了统一的资源管理中,并且不再提供单独的 cpuset 控制器。
Cgroup V1
创建一个 cgroup
┌──[root@vms99.liruilongs.github.io]-[~]
└─$mkdir -p /sys/fs/cgroup/cpuset/cpuset0
配置 cpuset,这里配置 CPU 允许在 0,1 对应的 CPU 上运行
┌──[root@vms99.liruilongs.github.io]-[~]
└─$echo 0-1 > /sys/fs/cgroup/cpuset/cpuset0/cpuset.cpus
┌──[root@vms99.liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cpuset/cpuset0/cpuset.cpus
0-1
将进程添加到 cgroup, 这里是 tasks 文件,和 Cgroup v2 版本不同
┌──[root@vms99.liruilongs.github.io]-[~]
└─$echo 40604 > /sys/fs/cgroup/cpuset/cpuset0/tasks
┌──[root@vms99.liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cpuset/cpuset0/tasks
40604
验证配置
┌──[root@vms99.liruilongs.github.io]-[~]
└─$cat /proc/40604/status | grep Cpu
Cpus_allowed: 00000000,00000000,00000000,00000003
Cpus_allowed_list: 0-1
┌──[root@vms99.liruilongs.github.io]-[~]
└─$printf "%032x\n" $((2**0+2**1))
00000000000000000000000000000003
Cgroup V2
cgroup v2 中控制应用程序的 CPU 亲和性,需要启用特定的 CPU 控制器,并创建一个专用的控制组。建议在 /sys/fs/cgroup/ 根控制组群中至少创建两级子控制组
验证 /sys/fs/cgroup/cgroup.controllers 文件中是否提供了 cpu 和 cpuset 控制器:
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misc
为 /sys/fs/cgroup/ 根控制组的直接子组启用了 cpu 和 cpuset 控制器。子组 是可以指定进程的 Cgroup 层级,并根据标准对每个进程应用控制检查的地方,用户可以在任意级别读取 cgroup.subtree_control 文件的内容,以了解子组中哪些控制器可用于启用。默认情况下,根控制组中的 /sys/fs/cgroup/cgroup.subtree_control 文件包含 memory 和 pids 控制器。
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cgroup.subtree_control
memory pids
┌──[root@liruilongs.github.io]-[~]
└─$echo "+cpu" >> /sys/fs/cgroup/cgroup.subtree_control
┌──[root@liruilongs.github.io]-[~]
└─$echo "+cpuset" >> /sys/fs/cgroup/cgroup.subtree_control
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/cgroup.subtree_control
cpuset cpu memory pids
┌──[root@liruilongs.github.io]-[~]
└─$
创建 /sys/fs/cgroup/Example/ 目录,/sys/fs/cgroup/Example/ 目录定义了一个子组。此外,上一步为这个子组启用了 cpu 和 cpuset 控制器。
┌──[root@liruilongs.github.io]-[~]
└─$mkdir /sys/fs/cgroup/Example/
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/Example/cgroup.controllers
cpuset cpu memory pids
创建 /sys/fs/cgroup/Example/ 目录时,一些 cgroups-v2 接口文件以及 cpu 和 cpuset 特定于控制器的文件也会在目录中自动创建。/sys/fs/cgroup/Example/目录还包含 memory 和 pids 控制器的特定于控制器的文件
┌──[root@liruilongs.github.io]-[~]
└─$ls /sys/fs/cgroup/Example/
cgroup.controllers cpuset.cpus.exclusive memory.oom.group
cgroup.events cpuset.cpus.exclusive.effective memory.peak
cgroup.freeze cpuset.cpus.partition memory.reclaim
cgroup.kill cpuset.mems memory.stat
cgroup.max.depth cpuset.mems.effective memory.swap.current
cgroup.max.descendants cpu.stat memory.swap.events
cgroup.procs cpu.weight memory.swap.high
cgroup.stat cpu.weight.nice memory.swap.max
cgroup.subtree_control memory.current memory.swap.peak
cgroup.threads memory.events memory.zswap.current
cgroup.type memory.events.local memory.zswap.max
cpu.idle memory.high pids.current
cpu.max memory.low pids.events
cpu.max.burst memory.max pids.max
cpuset.cpus memory.min pids.peak
cpuset.cpus.effective memory.numa_stat
┌──[root@liruilongs.github.io]-[~]
└─$
启用 /sys/fs/cgroup/Example/ 中与 CPU 相关的控制器,以获取仅与 CPU 相关的控制器:
──[root@liruilongs.github.io]-[~]
└─$echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control
┌──[root@liruilongs.github.io]-[~]
└─$echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_control
创建 /sys/fs/cgroup/Example/tasks/ 目录,/sys/fs/cgroup/Example/tasks/ 目录定义了一个子组,以及只与 cpu 和 cpuset 控制器相关的文件。
┌──[root@liruilongs.github.io]-[~]
└─$mkdir /sys/fs/cgroup/Example/tasks/
┌──[root@liruilongs.github.io]-[~]
└─$cat /sys/fs/cgroup/Example/tasks/cgroup.controllers
cpuset cpu
┌──[root@liruilongs.github.io]-[~]
└─$
配置 CPU 亲和性
┌──[root@liruilongs.github.io]-[~]
└─$echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpus
┌──[root@liruilongs.github.io]-[~]
└─$
通过 httpd 的服务测试
┌──[root@liruilongs.github.io]-[~]
└─$systemctl enable --now httpd
┌──[root@liruilongs.github.io]-[~]
└─$pgrep httpd
879
1096
1098
1105
1106
11313
┌──[root@liruilongs.github.io]-[~]
└─$cat /proc/1105/status | grep Cpu
Cpus_allowed: 3
Cpus_allowed_list: 0-1
将服务的 PID 添加到 Example/tasks 子组中:
┌──[root@liruilongs.github.io]-[~]
└─$echo "1105" > /sys/fs/cgroup/Example/tasks/cgroup.procs
验证配置
┌──[root@liruilongs.github.io]-[~]
└─$cat /proc/1105/status | grep Cpu
Cpus_allowed: 2
Cpus_allowed_list: 1
┌──[root@liruilongs.github.io]-[~]
└─$
┌──[root@vms99.liruilongs.github.io]-[~]
└─$printf "%032x\n" $((2**1))
00000000000000000000000000000002
关于 CPU 上下文就可小伙伴们分享到这里 ^_^
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 😃
《BPF Performance Tools》读书笔记
《Linux性能优化》中文版
极客时间 《Linux 性能优化实战》 课程笔记
© 2018-2024 liruilonger@gmail.com, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
相关文章:
Linux 性能调优之CPU上下文切换
写在前面 博文内容为 Linux 性能指标 CPU 上下文切换认知内容涉及: 上下文认知,发生上下文切换的场景有哪些上下文指标信息查看,内核上下文切换事件跟踪,系统上下文切换统计上下文异常场景分析,CPU亲和性配置优化上下文…...

【无标题】符文价值的退化页
我们利用现有的符文体系建立了一个健全的符文扩展空间,可假若符文让我们感到十分困惑,我们不介意毁灭它们,让一切回到没有字迹的蛮荒纪。 如此,眼睛也失去了作用。我们的成GUO也会给后来者提供又是一DUI 令人眼花缭乱的无用符咒。…...

DFS 算法:洛谷B3625迷宫寻路
我的个人主页 {\large \mathsf{{\color{Red} 我的个人主页} } } 我的个人主页 往 {\color{Red} {\Huge 往} } 往 期 {\color{Green} {\Huge 期} } 期 文 {\color{Blue} {\Huge 文} } 文 章 {\color{Orange} {\Huge 章}} 章 DFS 算法:记忆化搜索DFS 算法…...

结构开发笔记(七):solidworks软件(六):装配摄像头、摄像头座以及螺丝,完成摄像头结构示意图
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/141931518 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

Android 15 新特性快速解读指南
核心要点 16K 页面大小支持目前作为开发人员选项提供,并非强制要求。 引入多项提升开发体验、多语言支持、多媒体功能、交互体验和隐私安全的更新。 重点关注前台服务限制、Window Insets 行为变化、AndroidManifest 文件限制等适配要求。 开发体验 ApplicationS…...
】机器人工具箱Link类函数参数说明)
【机器人工具箱Robotics Toolbox开发笔记(十九)】机器人工具箱Link类函数参数说明
机器人工具箱中的Link对象保存于机器人连杆相关的所有信息,如运动学参数、刚体惯性参数、电机和传动参数等。 与Link对象有关参数如表1所示。 表1 Link对象参数 参 数 意 义 参 数 意 义 A 连杆变换矩阵 islimit 测试关节是否超过软限制 RP RP关节类型 isrevo…...

排查SQL Server中的内存不足及其他疑难问题
文章目录 引言I DMV 资源信号灯资源信号灯 DMV sys.dm_exec_query_resource_semaphores( 确定查询执行内存的等待)查询性能计数器什么是内存授予?II DBCC MEMORYSTATUS 查询内存对象III DBCC 命令释放多个 SQL Server 内存缓存 - 临时度量值IV 等待资源池 %ls (%ld)中的内存…...
输送线相机拍照信号触发(博途PLC高速计数器中断立即输出应用)
博途PLC相关中断应用请参考下面文章链接: T法测速功能块 T法测速功能块(博途PLC上升沿中断应用)-CSDN博客文章浏览阅读165次。本文介绍了博途PLC中T法测速的原理和应用,包括如何开启上升沿中断、配置中断以及T法测速功能块的使用。重点讲述了在中断事件发生后执行的功能块处…...
)
【数学分析笔记】第3章第1节 函数极限(6)
3. 函数极限与连续函数 3.1 函数极限 【例3.1.12】 f ( x ) a n x n a n − 1 x n − 1 ⋯ a k x k b m x m b m − 1 x m − 1 ⋯ b j x j , b m , b j ≠ 0 , a n , a k ≠ 0 f(x) \frac{a_{n} x^{n}a_{n-1} x^{n-1}\cdotsa_{k} x^{k}}{b_{m} x^{m}b_{m-1} x^{m-1}\…...

程序员如何写笔记?
word。没错,我也看了网上一大堆软件,还有git管理等等。个人认为如果笔记只是记录个人的经验积累,一个word就够了,那些notepad,laTex个人觉得不够简练。word。 1.word可以插入任何文件附件(目前最大的word 200MB也没出现…...

Linux网络——Socket编程函数
一.网络命令 1.ping ping命令用来检测网络是否连通,具体用法为: ping 任意网址 结果如下: 当出现上述字段时,证明网络是连通的,这里值得注意的是,ping命令执行之后会不断进行网络检测,不会停…...
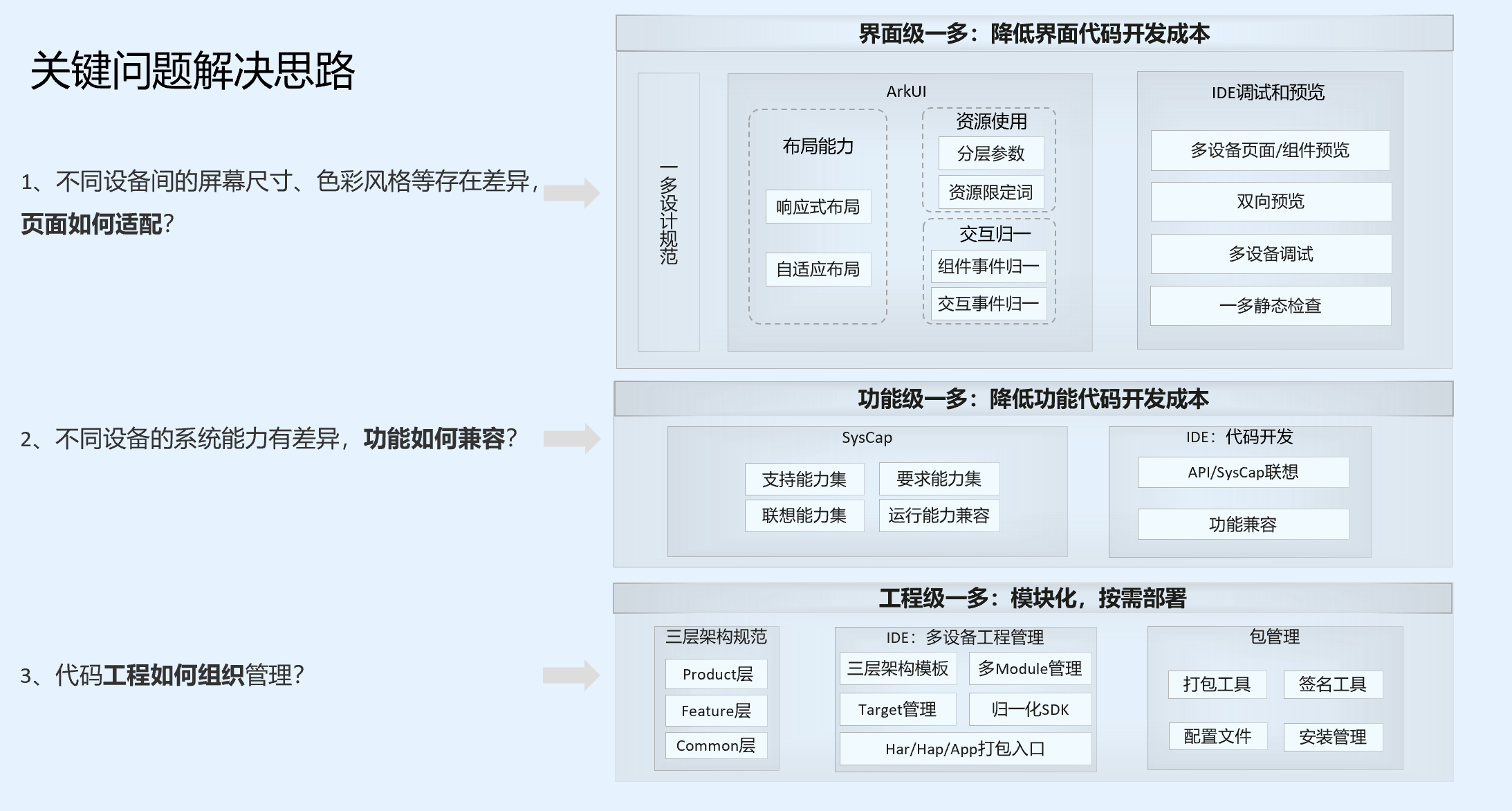
HarmonyOS 是如何实现一次开发多端部署 -- HarmonyOS自学1
一次开发多端部署遇到的几个关键问题 为了实现“一多”的目标,需要解决如下三个基础问题: 问题1:页面如何适配 不同设备间的屏幕尺寸、色彩风格等存在差异,页面如何适配。 问题2:功能如何兼容 不同设备的系统能力…...

嵌入式硬件-ARM处理器架构,CPU,SOC片上系统处理器
多进程空间内部分布图:注意:创建线程实际使用堆区空间,栈区独立 ARM处理器架构: 基于ARM920T架构的CPU:以下为哈佛结构 ALU:算数运算器 R0~R12:寄存器 PC:程序计数器,默认为0,做自加运算&#x…...

《JavaEE进阶》----12.<SpringIOCDI【扫描路径+DI详解+经典面试题+总结】>
本篇博客主要讲解 扫描路径 DI详解:三种注入方式及优缺点 经典面试题 总结 五、环境扫描路径 虽然我们没有告诉Spring扫描路径是什么,但是有一些注解已经告诉Spring扫描路径是什么了 如启动类注解SpringBootApplication。 里面有一个注解是componentS…...

Selenium 自动化测试:常用函数与实例代码
引言 Selenium 是一个强大的自动化测试工具,广泛用于网页应用的自动化测试。它支持多种编程语言,包括 Python。本文将介绍 Selenium 的常用函数,并提供参数解释和代码示例。 Selenium 简介 Selenium 是一个用于自动化 Web 应用测试的工具&…...
——爬取天气预报)
python网络爬虫(五)——爬取天气预报
1.注册高德天气key 点击高德天气,然后按照开发者文档完成key注册;作为爬虫练习项目之一。从高德地图json数据接口获取天气,可以获取某省的所有城市天气,高德地图的这个接口还能获取县城的天气。其天气查询API服务地址为https://re…...

四.海量数据实时分析-Doris数据导入导出
数据导入 1.概述 Apache Doris 提供多种数据导入方案,可以针对不同的数据源进行选择不同的数据导入方式。 数据源导入方式对象存储(s3),HDFS使用 Broker 导入数据本地文件Stream Load, MySQL LoadKafka订阅 Kafka 数据Mysql、PostgreSQL&a…...

一. 从Hive开始
1. 怎么理解Hive Hive不能理解成一个传统意义上的数据库,应该理解成一个解决方案。 是Hadoop在hdfs和mapreduce之后才出现的一个结构化数据处理的解决方案。 Hdfs解决了大数据的存储问题,mapreduce解决了数据的计算问题。 一切似乎很美好。 但是使用成本…...
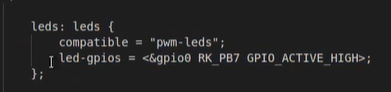
Linux下的PWM驱动
PWM PWM简介⭕ **PWM(Pulse Width Modulation,脉冲宽度调制)**是一种利用微处理器的数字输出对模拟电路进行控制的技术。通过改变脉冲的占空比,可以控制模拟电路的输出电压或电流。PWM技术广泛应用于电机控制、灯光调节、音频信号…...

日语输入法平假名和片假名切换
在学日语输入法的时候,我们在使用罗马音输入的时候,在进行平假名和片假名切换: 1、使用电脑在打字,日语输入法切换的时候使用 Shift Alt 如果日语输入法显示为 A 需要切换为 あ的话可以按Caps Lock键 。(相当于中文…...
)
【小白快速上手】 OpenClaw 安装部署全流程(含安装包)
OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js&#…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...

机器学习预测关税冲击下的股市波动:随机森林、SVR、kNN与线性回归实战对比
1. 项目概述与核心问题拆解做量化研究的朋友们,尤其是关注宏观事件对市场冲击的,应该都对“黑天鹅”事件不陌生。政策变动,特别是像关税这种直接影响国际贸易成本和公司利润的宏观变量,往往会在短期内引发市场剧烈波动。传统的做法…...

5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南
5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/…...

如何在Windows上轻松查看和转换iPhone HEIF图片:HEIF实用工具指南
如何在Windows上轻松查看和转换iPhone HEIF图片:HEIF实用工具指南 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility HEIF Utility是一款专为Windows用户…...

如何精准识别高校院所与企业之间的潜在合作机会?
核心要点 传统“相亲角”式校企对接效率低下,根源在于科研供给与市场需求间的信息断层,必须转向以数据驱动、模型研判为核心的精准识别机制,才能将模糊的产学研线索转化为可落地的合作机会。精准识别合作机会的关键在于分拆为“供给侧”与“需…...

3个实用技巧:零门槛批量下载抖音无水印视频
3个实用技巧:零门槛批量下载抖音无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批…...

Gazebo Sim物理引擎对比:Bullet、ODE与DART性能优化指南
Gazebo Sim物理引擎对比:Bullet、ODE与DART性能优化指南 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim作为开源机器人仿真的终极工具,…...

Unity WebGL项目内存爆了别慌!用Profiler揪出2048大贴图,5分钟搞定优化
Unity WebGL内存优化实战:用Profiler精准定位2048大贴图当Unity WebGL项目在浏览器中运行时突然弹出"Out Of Memory"错误,不少开发者会感到手足无措。这种内存溢出问题往往源于未被注意到的资源"巨无霸"——比如一张20482048的高清贴…...

2026年降AI后语义失真攻略:过度改写论点跑偏4.8元修复语义同时达标完整方案
2026年降AI后语义失真攻略:过度改写论点跑偏4.8元修复语义同时达标完整方案 从AI率71%到5.9%,我用了一个晚上。降AI后语义失真修复完整经历。 核心工具:嘎嘎降AI(www.aigcleaner.com),4.8元,达…...