k8s集群部署:环境准备
本教程基于centos9 arm架构展开。
1. 设置主机名
为每个节点设置主机别名,以便于集群中的角色识别:
# 设置主节点的主机名为 kmaster
sudo hostnamectl set-hostname kmaster --static# 设置工作节点1的主机名为 kworker1
sudo hostnamectl set-hostname kworker1 --static# 设置工作节点2的主机名为 kworker2
sudo hostnamectl set-hostname kworker2 --static
以上命令使用 hostnamectl 修改静态主机名,分别为 Kubernetes 主节点及两个工作节点设置合适的别名。执行 hostname 可以验证设置是否生效。
# 查看当前主机名
hostname
2. 配置静态 IP
为了确保集群各节点间的网络通信正常,需要为每台机器配置静态 IP 地址。
编辑网络接口配置文件(以 enp0s5 为例,实际接口名称请根据实际情况修改)
sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s5
修改配置如下:
BOOTPROTO="static" # 使用静态 IP
ONBOOT="yes" # 启用网络配置
IPADDR=10.211.55.9 # 静态 IP 地址
GATEWAY=10.211.55.1 # 默认网关
NETMASK=255.255.255.0 # 子网掩码
DNS1=114.114.114.114 # DNS 服务器
DNS2=8.8.8.8 # 备用 DNS
保存文件并重启网络服务:
sudo systemctl restart network
其中 BOOTPROTO 设置为 static,确保每次启动时使用静态 IP。DNS 配置至关重要,如果不正确,可能会影响下载速度和镜像拉取。
3. 配置 /etc/hosts 文件
为了让集群内的机器能够通过主机名互相访问,我们需要编辑 /etc/hosts 文件,添加主机名和 IP 地址的映射。
sudo vi /etc/hosts
添加以下内容:
10.211.55.56 kmaster # 主节点
10.211.55.57 kworker1 # 工作节点1
10.211.55.58 kworker2 # 工作节点2
4. 安装依赖环境
Kubernetes 集群运行时需要安装一些必要的依赖包,包括 conntrack、chrony 等用于网络连接、时钟同步的工具。
sudo yum install -y conntrack chrony ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git iproute lrzsz bash-completion tree unzip bind-utils gcc
注意:如果安装依赖包后导致 sshd 服务异常(如无法连接 SSH),请执行以下操作:
sudo yum clean all
sudo yum update
sudo yum reinstall openssh-server openssh-clients
5. 关闭 SELinux 和 Swap
Kubernetes 对安全机制和内存管理有一定的要求,因此需要关闭 SELinux 和 Swap 分区。
5.1 关闭 SELinux
SELinux(安全增强型 Linux)会限制某些服务和程序的访问权限,建议在 Kubernetes 环境中关闭。
# 临时关闭 SELinux
setenforce 0# 修改配置文件永久关闭 SELinux
sudo sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
5.2 关闭 Swap 分区
Kubernetes 要求禁用 Swap 分区,以确保稳定的内存分配。
# 关闭 Swap 并禁用开机启动
sudo swapoff -a && sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
6. 关闭防火墙
Kubernetes 需要在节点之间自由通信,因此建议关闭防火墙以避免不必要的网络阻塞。
# 停止并禁用防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld
7. 调整内核参数
为了优化系统性能并确保 Kubernetes 正常运行,需要调整一些内核参数。
7.1 创建内核配置文件
首先,创建一个新的内核参数配置文件 kubernetes.conf:
# 创建 kubernetes.conf 文件来配置系统内核参数
sudo cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1 # 启用 iptables 处理桥接流量的功能,确保 Kubernetes 网络能正常工作
net.bridge.bridge-nf-call-ip6tables=1 # 同样为 IPv6 启用 iptables 的桥接流量处理
net.ipv4.ip_forward=1 # 启用 IP 转发功能,允许节点转发数据包
vm.swappiness=0 # 设置系统不使用交换分区,保持物理内存的性能
vm.overcommit_memory=1 # 允许内存的过度分配,避免潜在的内存不足错误
vm.panic_on_oom=0 # 禁止内存溢出(OOM)时触发内核 panic,使得 OOM 事件不会导致系统崩溃
fs.inotify.max_user_instances=8192 # 提高每个用户可监控的 inotify 实例数,增强文件系统监控的能力
fs.inotify.max_user_watches=1048576 # 提高每个用户的 inotify 可监控的文件数,适用于需要监控大量文件的系统
fs.file-max=52706963 # 提高系统允许打开的文件句柄的最大数量,防止文件句柄耗尽
fs.nr_open=52706963 # 限制每个进程可以打开的文件数,提高系统性能
net.ipv6.conf.all.disable_ipv6=1 # 禁用 IPv6,除非集群中明确需要使用 IPv6,否则可以关闭以减少复杂性
net.netfilter.nf_conntrack_max=2310720 # 增加 conntrack 表的最大容量,确保系统能跟踪更多的网络连接
EOF
7.2 应用内核参数
将配置文件拷贝到 /etc/sysctl.d/ 目录下,并使其在开机时自动加载:
sudo cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sudo sysctl -p /etc/sysctl.d/kubernetes.conf
同时,为了确保在系统启动时加载相关模块,执行以下操作:
# 将模块配置文件写入
sudo echo "br_netfilter" | sudo tee /etc/modules-load.d/br_netfilter.conf
8. 安装并配置 Chrony
在分布式系统中,确保时间同步非常重要,否则可能会导致节点间通信问题。我们使用 chrony 来实现时钟同步。
8.1 安装 chrony
sudo yum install -y chrony
8.2 配置 chrony
编辑 chrony 配置文件以配置 NTP 服务器:
sudo vim /etc/chrony.conf
添加以下内容:
pool pool.ntp.org iburst # 使用 pool.ntp.org 作为时钟同步源
8.3 启动并验证 chrony 服务
sudo systemctl enable chronyd
sudo systemctl start chronyd# 验证 chrony 是否正常工作
sudo chronyc tracking
sudo chronyc sources
9. 调整系统时区和时间
将系统时区设置为中国上海,确保所有节点的时间保持一致。
# 设置时区为中国上海
sudo timedatectl set-timezone "Asia/Shanghai"
将当前时间写入硬件时钟,并重启依赖时间的服务:
# 写入 UTC 时间
sudo timedatectl set-local-rtc 0# 重启日志服务和计划任务服务
sudo systemctl restart rsyslog
sudo systemctl restart crond
10. 配置日志保存方式
为了方便排查问题和分析系统运行情况,我们可以将系统日志设置为持久化存储。
10.1 创建日志存储目录
sudo mkdir /var/log/journal
sudo mkdir /etc/systemd/journald.conf.d
10.2 创建日志配置文件
# 创建 systemd 日志配置文件,存储日志并设置相关策略
sudo cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
Storage=persistent # 持久化存储日志到磁盘,防止重启后日志丢失
Compress=yes # 启用日志压缩,节省磁盘空间
SyncIntervalSec=5m # 每5分钟将日志数据同步到磁盘,减少写入频率以提升性能
RateLimitInterval=30s # 设置日志速率限制时间为30秒,控制日志的频繁写入
RateLimitBurst=1000 # 限制日志爆发性写入的数量,防止日志泛滥占用过多资源
SystemMaxUse=10G # 设置日志的最大占用空间为10GB,超出部分将自动删除旧日志
SystemMaxFileSize=200M # 限制每个日志文件的最大大小为200MB,防止单个文件过大
MaxRetentionSec=2week # 日志保留时间为2周,超出时间的日志将自动删除
ForwardToSyslog=no # 不将日志转发到 syslog,避免重复记录以节省资源
EOF
10.3 重启日志服务
sudo systemctl restart systemd-journald
11. 调整文件句柄数(可选)
为防止大量并发连接时文件句柄耗尽,可以调整系统允许的最大打开文件数。
# 提高系统允许的文件句柄数,避免高并发时耗尽文件描述符
echo "* soft nofile 65536" | sudo tee -a /etc/security/limits.conf # 设置软限制,普通用户可以打开的文件数上限为 65536
echo "* hard nofile 65536" | sudo tee -a /etc/security/limits.conf # 设置硬限制,系统强制执行的文件数上限为 65536
以上是 Kubernetes 主机别名设置及服务器配置的详细步骤。通过这些配置,您可以为 Kubernetes 集群打下坚实的基础,确保集群内的各个节点能够顺畅通信并实现高效的资源管理。
专栏目录:
1、k8s集群部署:环境准备
2、k8s集群部署:容器运行时
3、k8s集群部署:安装 kubeadm
本文参考:http://www.weifos.com/Home/TechStack/1807017272963891200
相关文章:

k8s集群部署:环境准备
本教程基于centos9 arm架构展开。 1. 设置主机名 为每个节点设置主机别名,以便于集群中的角色识别: # 设置主节点的主机名为 kmaster sudo hostnamectl set-hostname kmaster --static# 设置工作节点1的主机名为 kworker1 sudo hostnamectl set-hostn…...

<C++> set、map模拟实现
目录 一、适配器红黑树 二、红黑树再设计 1. 重新设计 RBTree 的模板参数 2. 仿函数模板参数 3. 正向迭代器 构造 operator*() operator->() operator!() operator() operator--() 正向迭代器代码 4. 反向迭代器 构造 operator* operator-> operator operator-- operat…...

软考学习 数据结构 查找
1. 顺序查找(Sequential Search) 基本原理: 顺序查找是一种最简单、最直观的查找算法。它从数据集合的第一个元素开始,依次与目标元素进行比较,直到找到目标元素或遍历完所有元素为止。 适用条件: 适用…...

h264 视频流中添加目标检测的位置、类型信息到SEI帧
在 H.264 视频编码中,SEI(Supplemental Enhancement Information)消息用于传输额外的、非编码的数据,例如目标检测的信息。SEI 数据可以嵌入到 H.264 流中,以在解码过程中传递这些附加信息。 一、步骤 确定 SEI 类型&…...
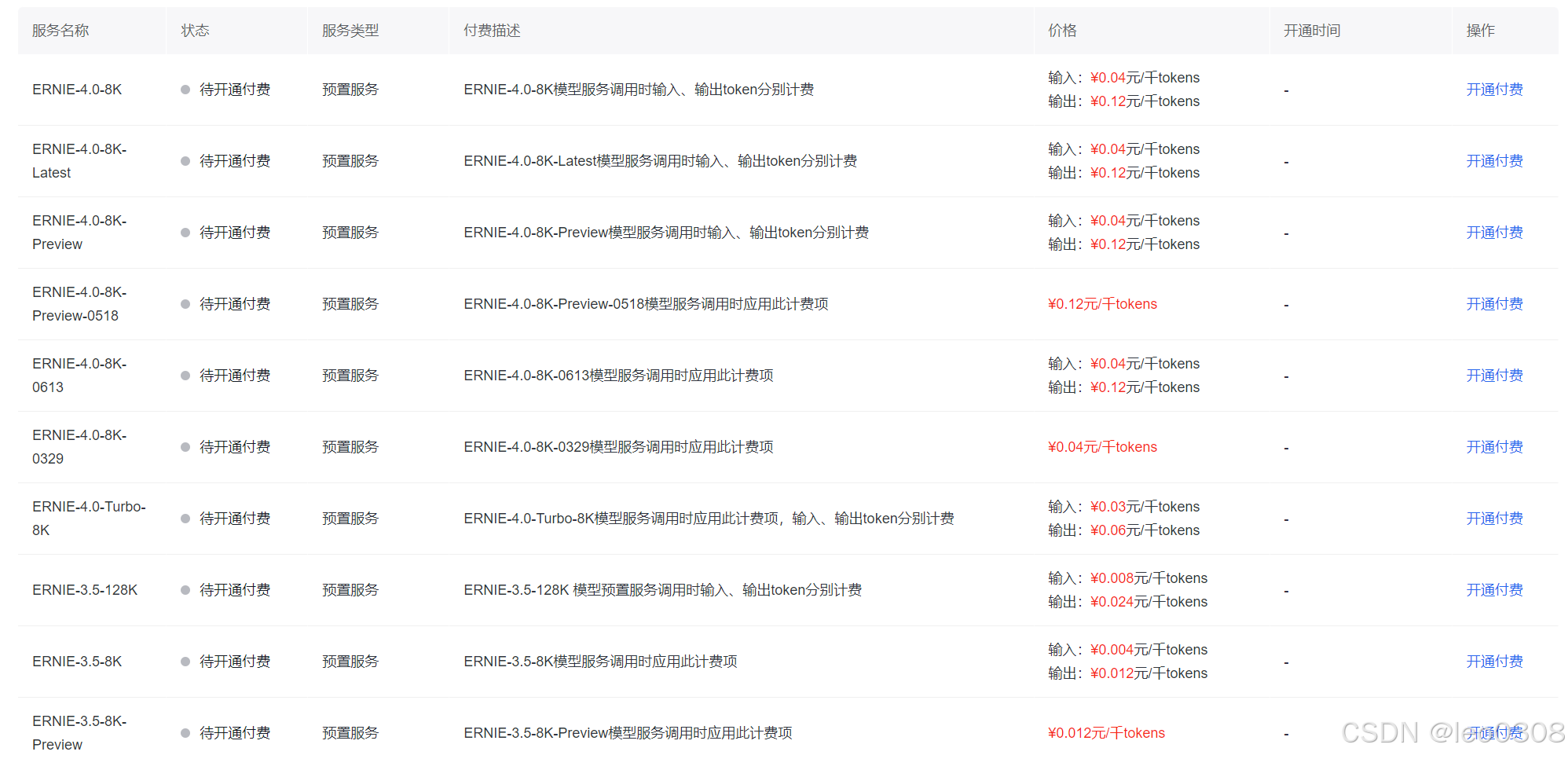
大模型api谁家更便宜
1 openai 可点此链接查询价格:https://openai.com/api/pricing/ 2 百度 可点此链接查询价格:https://console.bce.baidu.com/qianfan/chargemanage/list 需要注意,百度千帆平台上还提供其他家的模型调用服务, 如llama, yi-34b等…...
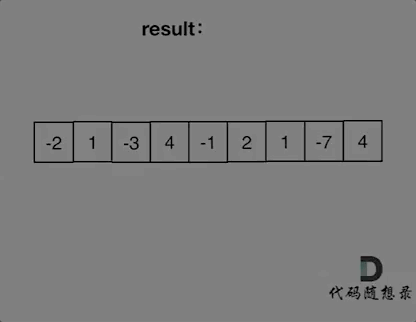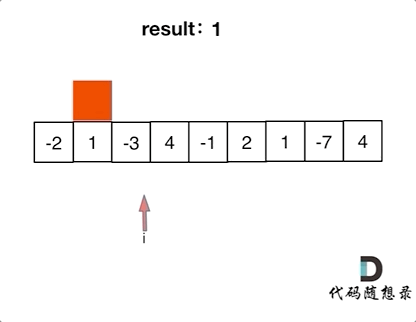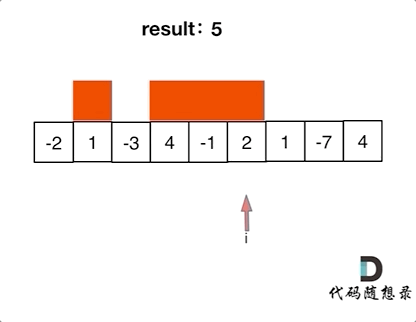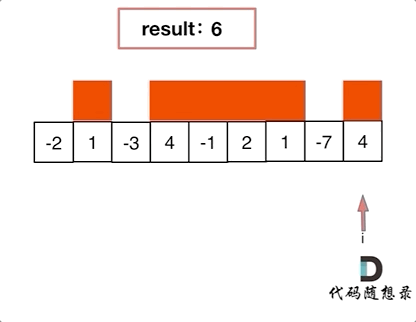
代码随想录算法训练营第二十三天| 455. 分发饼干、376. 摆动序列、53. 最大子序和
今日内容 贪心理论基础Leetcode. 455 分发饼干Leetcode. 376 摆动序列Leetcode. 53 最大子序和 贪心理论基础 贪心算法的本质就是选择每一阶段的最优,达到全局上的最优。 贪心算法和之前学到的所有方法相比,它没有固定的使用套路,也没有固…...
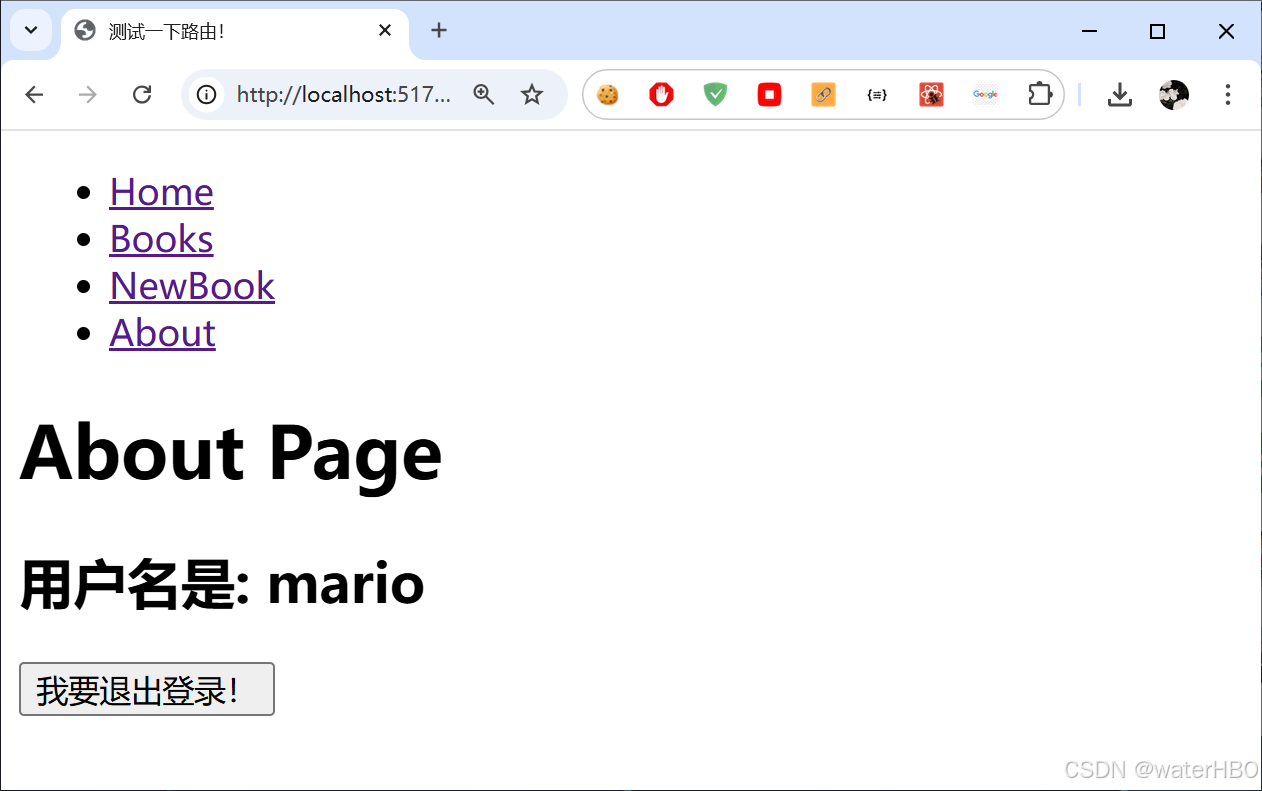
react js 路由 Router
完整的项目,我已经上传了 资料链接 起因, 目的: 路由, 这部分很难。 原因是, 多个组件,进行交互,复杂度比较高。 我看的视频教程 1. 初步使用 安装: npm install react-router-dom 修改 index.js/ 或是 main.js 把 App, 用 BrowserRouter 包裹起来 2. Navigate 点击…...
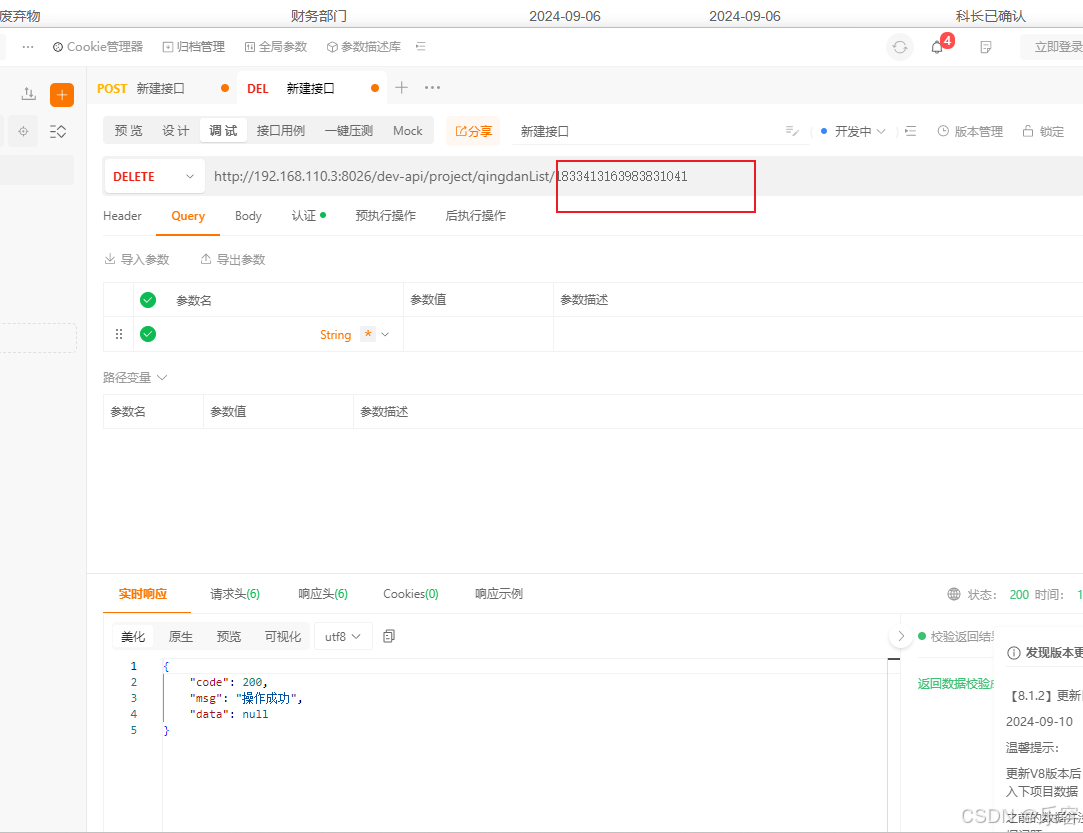
AplPost使用
请求get 方法 1,添加token 2,填写get 的参数 2,post方法 把对象的形式直接复制到row里面 3,delete方法 可以直接后面拼接参数...
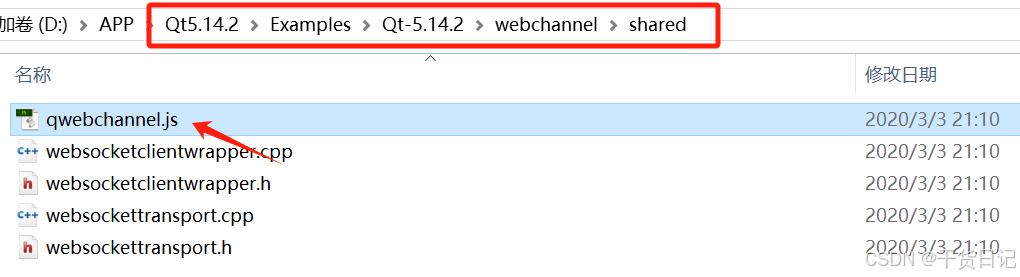
【Qt】Qt与Html网页进行数据交互
前言:此项目使用达梦数据库,以Qt制作服务器,Html制作网页客户端界面,可以通过任意浏览器访问。 1、Qt与网页进行数据交互 1.1、第一步:准备qwebchannel.js文件 直接在qt的安装路径里复制即可 1.2、第二步…...

教师节特辑:AI绘制的卡通人物,致敬最可爱的人
【编号:9】教师节到了,今天我要分享一组由AI绘制的教师节主题卡通人物插画,每一幅都充满了对老师的敬意和爱戴。让我们一起用这些可爱的卡通形象,向辛勤的园丁们致敬! 🎓【教师形象】 这…...

SprinBoot+Vue智慧农业专家远程指导系统的设计与实现
目录 1 项目介绍2 项目截图3 核心代码3.1 Controller3.2 Service3.3 Dao3.4 application.yml3.5 SpringbootApplication3.5 Vue 4 数据库表设计5 文档参考6 计算机毕设选题推荐7 源码获取 1 项目介绍 博主个人介绍:CSDN认证博客专家,CSDN平台Java领域优质…...

AI大模型行业专题报告:大模型发展迈入爆发期,开启AI新纪元
大规模语言模型(Large Language Models,LLM)泛指具有超大规模参数或者经过超大规模数据训练所得到的语言模型。与传统语言模型相比,大语言模型的构建过程涉及到更为复杂的训练方法,进而展现出了强大的自然语言理解能力…...
FLV 格式详解资料整理,关键帧格式解析写入库等等
FLV 是一种比较简单的视频封装格式。大致可以分为 FLV 文件头,Metadata元数据,然后一系列的音视频数据。 资料够多: FLV格式解析图 知乎用户 Linux服务器研究 画了一张格式解析图,比较全,但默认背景是白色ÿ…...

《深度学习》OpenCV 高阶 图像直方图、掩码图像 参数解析及案例实现
目录 一、图像直方图 1、什么是图像直方图 2、作用 1)分析图像的亮度分布 2)判断图像的对比度 3)检测图像的亮度和色彩偏移 4)图像增强和调整 5)阈值分割 3、举例 二、直方图用法 1、函数用法 2、参数解析…...

coredump-N: stack 消耗完之后,用户自定义信号处理有些问题 sigaltstack
https://mzhan017.blog.csdn.net/article/details/129401531 在上面一篇是关于stack耗尽的一个小程序例子。 https://www.man7.org/linux/man-pages/man2/sigaltstack.2.html 这里提到一个问题,就是如果栈被用光了,这个时候SIGSEGV的用户自定义的handler处理可能就没有空间进…...

数据库有关c语言
数据库的概念 SQL(Structured Query Language)是一种专门用来与数据库进行交互的编程语言,它允许用户查询、更新和管理关系型数据库中的数据。关系型数据库是基于表(Table)的数据库,其中表由行(…...
【网页播放器】播放自己喜欢的音乐
// 错误处理 window.onerror function(message, source, lineno, colno, error) {console.error("An error occurred:", message, "at", source, ":", lineno);return true; };// 检查 particlesJS 是否已定义 if (typeof particlesJS ! undefi…...
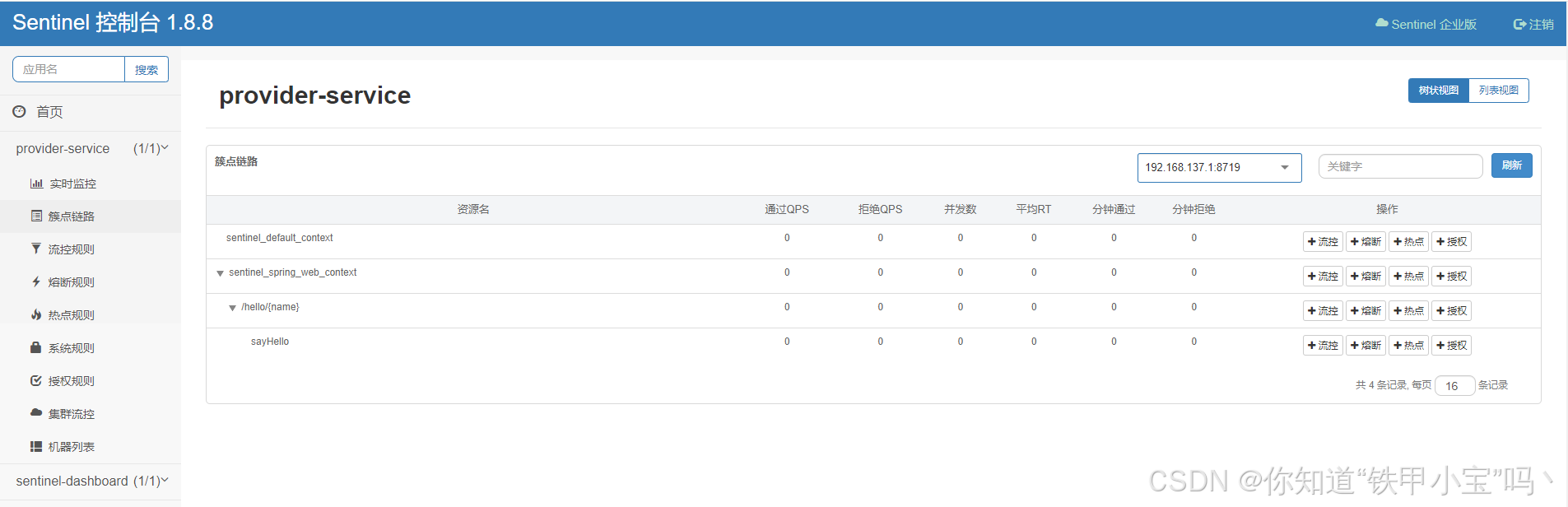
【第27章】Spring Cloud之适配Sentinel
文章目录 前言一、准备1. 引入依赖2. 配置控制台信息 二、定义资源1. Controller2. Service3. ServiceImpl 三、访问控制台1. 发起请求2. 访问控制台 总结 前言 Spring Cloud Alibaba 默认为 Sentinel 整合了 Servlet、RestTemplate、FeignClient 和 Spring WebFlux。Sentinel…...
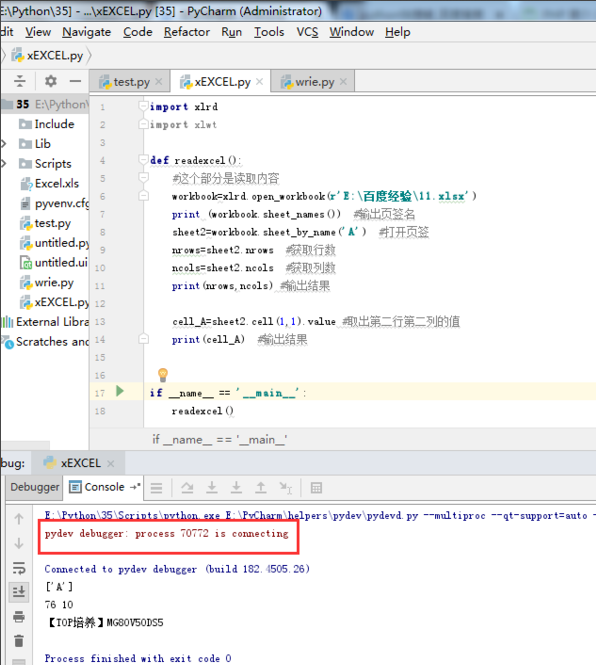
怎么debug python
1、打开pycharm,新建一个python程序,命名为excel.py。 2、编写代码。 3、点击菜单栏中的“Run”,在下拉菜单中选择“debug excel.py”或者“Debug...”,这两个功能是一样的,都是调试功能。 4、调试快捷键:C…...
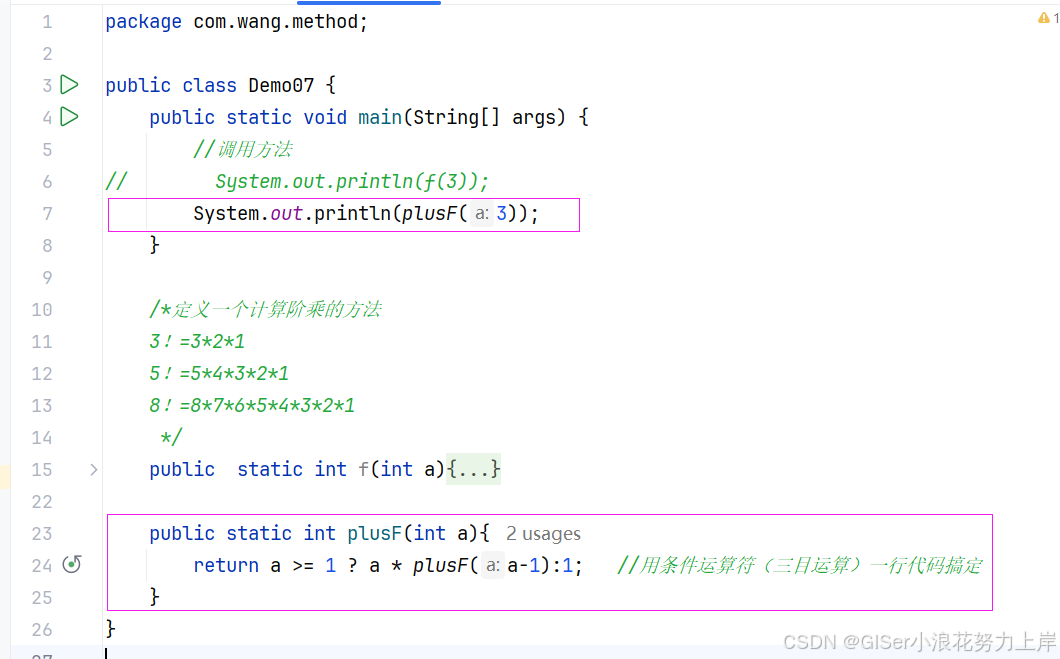
Java 递归
目录 1.A方法调用B方法,很容易理解! 2.递归:A方法调用A方法,就是自己调用自己! 3. 递归的优点: 4. 递归结构包括两个部分: 5. 递归的三个阶段 6. 递归的缺点&#…...

如何用TradingAgents-CN打造你的AI投资顾问:5步构建智能交易系统
如何用TradingAgents-CN打造你的AI投资顾问:5步构建智能交易系统 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 作为一名有着十年投…...

Rufus高效启动盘制作实战攻略:30分钟从入门到精通
Rufus高效启动盘制作实战攻略:30分钟从入门到精通 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 系统重装难题如何高效解决? 当你的电脑遭遇系统崩溃、病毒入侵或需要全…...

CameraFileCopy:重新定义无网络文件传输的安卓应用
CameraFileCopy:重新定义无网络文件传输的安卓应用 【免费下载链接】cfc Demo/test android app for libcimbar. Copy files over the cell phone camera! 项目地址: https://gitcode.com/gh_mirrors/cfc/cfc 在移动设备普及的今天,我们依然经常面…...

ib_insync与pandas集成:金融数据分析的完整解决方案
ib_insync与pandas集成:金融数据分析的完整解决方案 【免费下载链接】ib_insync Python sync/async framework for Interactive Brokers API 项目地址: https://gitcode.com/gh_mirrors/ib/ib_insync 想要在Python中高效处理Interactive Brokers的金融数据吗…...

VLN性能提升秘籍:详解JanusVLN的‘记忆宫殿’如何解决长期导航的内存爆炸问题
VLN性能优化实战:JanusVLN混合记忆机制解析与工程落地指南 1. 视觉语言导航的工程挑战与性能瓶颈 在智能家居助手、仓储机器人等实际应用场景中,视觉语言导航(VLN)系统经常面临三大核心性能挑战。首先是内存占用失控——传统方法需…...

wpa_supplicant与eloop机制:如何用C语言实现高效事件驱动框架
wpa_supplicant与eloop机制:如何用C语言实现高效事件驱动框架 在当今高并发的网络编程领域,事件驱动模型因其高效的资源利用率和出色的响应能力,已成为构建高性能系统的首选架构。wpa_supplicant作为Linux平台下广泛使用的无线认证客户端&am…...
—— 数码管动态扫描原理与实现)
51单片机(九)—— 数码管动态扫描原理与实现
1. 数码管动态扫描原理揭秘 第一次接触多位数码管显示时,我盯着电路板百思不得其解:明明只有8个数据引脚,怎么能同时控制8位数码管显示不同内容?直到理解了动态扫描原理,才恍然大悟这背后的精妙设计。动态扫描本质上是…...

TwinCAT3 PLC安装避坑指南:从EtherCAT驱动到系统配置的完整流程
TwinCAT3 PLC实战安装指南:从零搭建工业控制系统的关键步骤 第一次接触TwinCAT3的工程师往往会被其强大的功能和复杂的配置流程所震撼。作为工业自动化领域的瑞士军刀,TwinCAT3将PLC、运动控制和实时通信集成在一个平台上,但这也意味着安装过…...

从零到一:UniApp前端网页托管与自定义域名配置实战指南
1. 从零开始:UniApp前端网页托管全流程解析 第一次接触UniApp前端网页托管时,我也被各种专业术语搞得晕头转向。经过几个项目的实战,我发现这套流程其实就像租房子:你得先有个门牌号(域名),再找…...
)
别再到处找安装包了!Win10下Apache 2.4保姆级安装与配置(附网盘资源)
Win10下Apache 2.4终极安装指南:从零避坑到高效部署 第一次在Windows上配置Apache服务器时,我盯着命令行里反复出现的"Syntax error"提示整整两小时——直到发现是因为配置文件里少了个引号。这种看似简单的环境搭建,往往藏着无数…...