如何评估一个RAG(检索增强生成)系统-上篇
最近项目中需要评估业务部门搭建的RAG助手的效果好坏,看了一下目前业界一些评测的方法。目前分为两大类,基于传统的规则、机器学习的评测方法,基于大模型的评测方法。在这里做一些记录,上篇主要做评测方法的记录,下篇会详细分析下RAGas评测框架指标的一些实现
传统评测方法
基于字符规则
最常见的评测,是判断输出的字符是否包含、不包含或者正则满足一些规则。也可以给各个规则之间配置与或非的条件,这里的实现也比较简单,不过过多赘述
基于编程
相较于基于字符规则,允许适用方编写代码,给与了更大的灵活性,这里可以发挥的空间也更大。如果编程代码中也允许调用大模型接口,那可以实现很多种基于大语言模型的评测。
BLEU
https://blog.csdn.net/qq_36485259/article/details/136604753
BLEU(Bilingual Evaluation Understudy)是一种评估机器翻译质量的方法,特别是它如何接近人类翻译的程度。它通过计算机器翻译输出与一组参考翻译(通常是人类翻译)之间的重叠来工作。BLEU分数的范围通常是0到1,其中1表示完美的匹配,0表示没有重叠。
BLEU分数主要基于两个方面:n-gram精确度和短句惩罚。以下是BLEU度量的基本步骤:
- n-gram精确度:BLEU检查机器翻译输出中的n-gram(连续的n个词)与参考翻译中的n-gram有多少是匹配的。这里的n可以是1、2、3等,通常会计算多个n-gram长度的精确度,并对它们进行加权平均。
- 短句惩罚:为了避免机器翻译只输出很短的句子来提高n-gram精确度,BLEU引入了一个短句惩罚因子。如果机器翻译的句子比参考翻译短,那么它的BLEU分数会受到惩罚。
- 计算BLEU分数:对于每个n-gram长度,计算机器翻译输出与参考翻译之间的n-gram精确度,然后对这些精确度值应用短句惩罚,最后将它们结合起来得到一个综合的BLEU分数。
BERT
https://arxiv.org/abs/1904.09675
https://github.com/Tiiiger/bert_score
这篇论文介绍了BERTSCORE,这是一种新的文本生成自动评估指标,它利用了预训练的BERT模型的上下文嵌入。与传统依赖于表面形式相似性的度量方法(例如BLEU)不同,BERTSCORE使用上下文嵌入来计算令牌之间的相似性,这更好地捕捉了语义等价性。
BART
https://arxiv.org/abs/2106.11520
https://github.com/neulab/BARTScore
BARTSCORE是一种无监督的评估指标,它不需要人类提供标准答案或进行人工评判来训练。它的优势在于能够直接利用预训练的语言模型(如BART)来评估生成文本的质量,而不需要依赖于人类的标注数据。
具体来说,BARTSCORE通过以下方式工作:
- 模型训练:使用预训练的序列到序列(seq2seq)模型,如BART,该模型已经在大量文本数据上进行了训练,能够捕捉语言的复杂特征。
- 评估公式:BARTSCORE使用一个公式来计算生成文本的概率,该公式基于生成文本给定源文本或参考文本的条件下的对数概率之和。
- 无监督:由于BART模型已经在预训练阶段学习了丰富的语言表示,因此在评估新文本时不需要额外的人类标注数据。
- 多角度评估:通过改变输入和输出的方式,BARTSCORE能够从不同的角度(如信息量、流畅性、事实性等)对生成的文本进行评估。
基于大语言模型的评测
G-Eval
https://arxiv.org/abs/2303.16634?ref=blog.langchain.dev
https://github.com/nlpyang/geval
G-EVAL是一个用于评估自然语言生成(NLG)系统输出质量的框架,它利用大型语言模型(LLMs)和思维链(Chain-of-Thoughts,CoT)以及一种填表范式来评估。G-EVAL的核心思想是通过让大型语言模型根据给定的任务介绍和评估标准来自动生成详细的评估步骤(CoT),然后使用这些步骤来评估NLG输出。
效果
- SummaryEval
SummEval是一个用于评估文本摘要质量的基准测试。它提供了人类对每个摘要在四个方面上的评分:流畅性(fluency)、连贯性(coherence)、一致性(consistency)和相关性(relevance)。SummEval建立在CNN/DailyMail数据集上,后者是一个广泛用于文本摘要任务的数据集,包含了大量的新闻文章和相应的摘要。
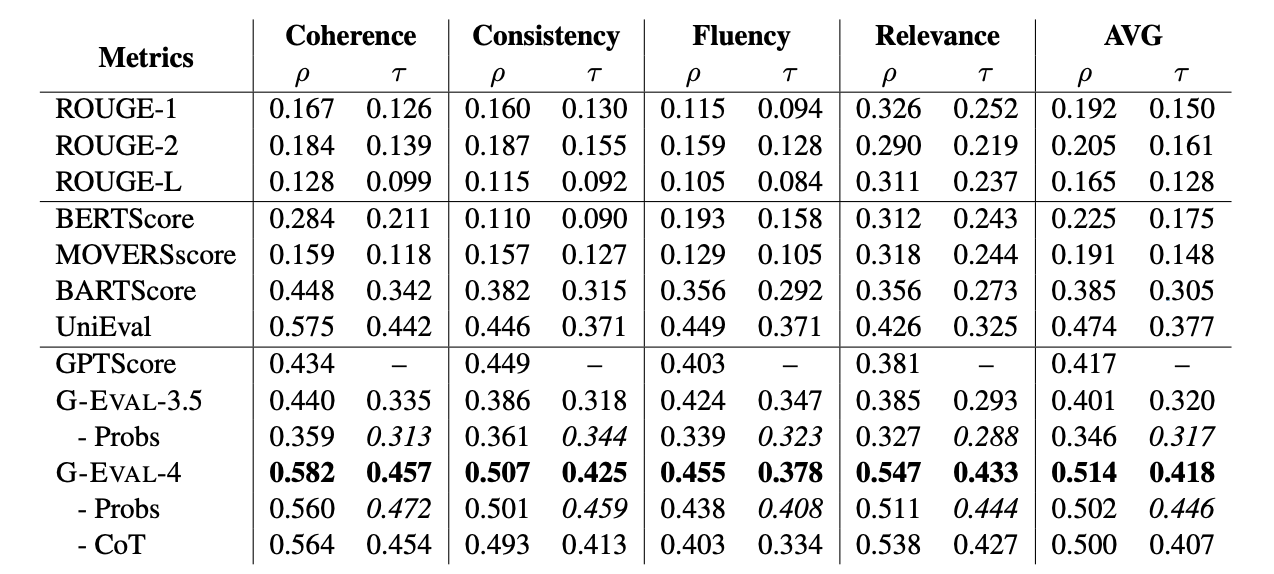
- Topical-Chat
Topical-Chat是一个用于元评估对话响应生成系统的测试平台,特别是那些使用知识的系统。它提供了人类对对话中每个回复在四个方面上的评分:自然性(naturalness)、连贯性(coherence)、引人入胜性(engagingness)和基于事实性(groundedness)。这个数据集用于评估对话系统生成的回复是否自然、相关,并且能否吸引用户继续对话。
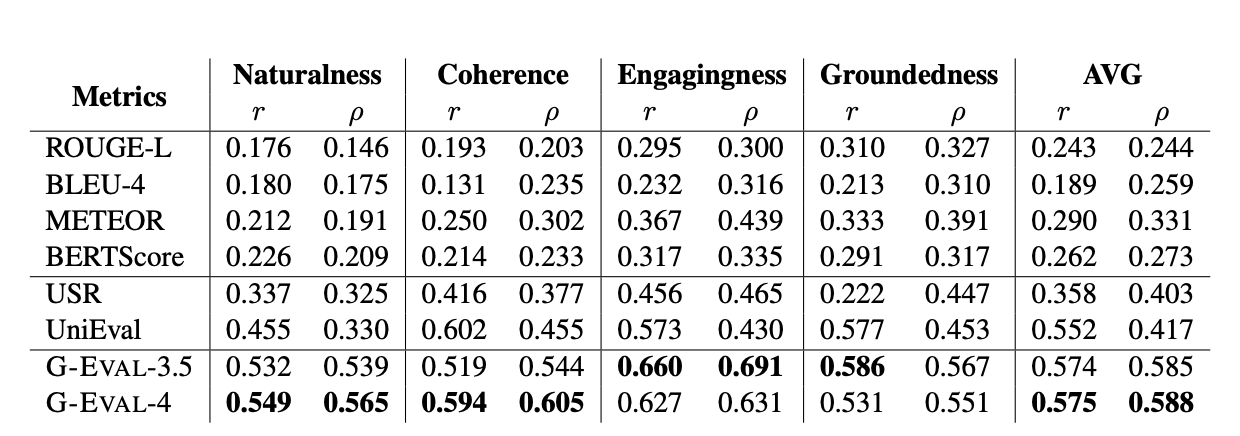
- QAGS
QAGS是一个用于评估摘要任务中事实一致性的基准测试。它旨在测量摘要在两个不同的摘要数据集上的事实一致性维度
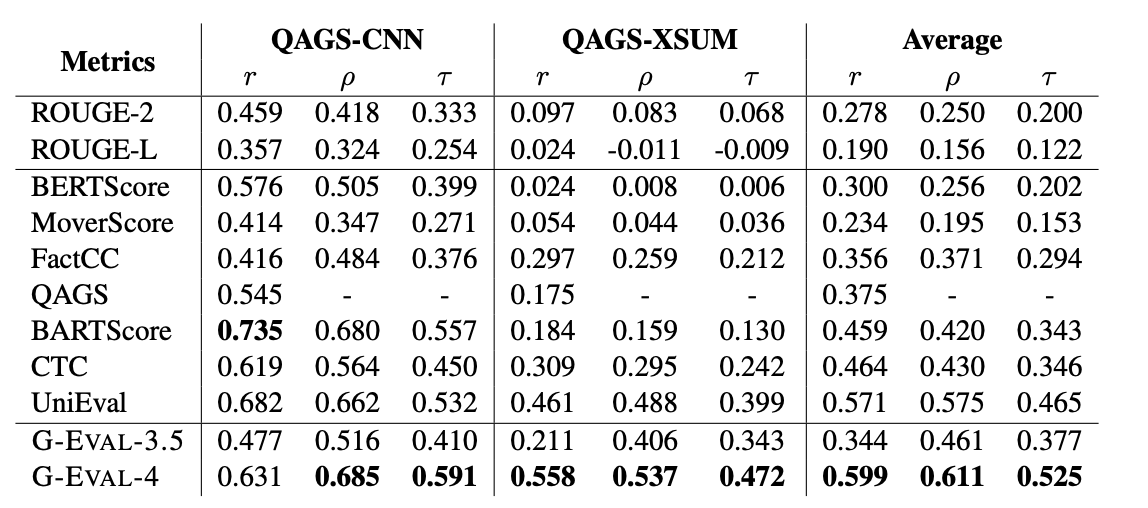
实现
Evaluate Coherence in the Summarization Task
评估文本摘要任务中连贯性(Coherence)
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.Evaluation Criteria:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.”Evaluation Steps:
1. Read the news article carefully and identify the main topic and key points.
2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order.
3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.Example:
Source Text:
{{Document}}
Summary:
{{Summary}}
Evaluation Form (scores ONLY):
- Coherence:Evaluate Engagingness in the Dialogue Generation Task
Evaluate Engagingness in the Dialogue Generation Task
评估对话生成任务中回复的参与度(Engagingness)
You will be given a conversation between two individuals. You will then be given one potential response for the next turn in the conversation. The response concerns an interesting fact, which will be provided as well.
Your task is to rate the responses on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.Evaluation Criteria:
Engagingness (1-3) Is the response dull/interesting?
- A score of 1 (dull) means that the response is generic and dull.
- A score of 2 (somewhat interesting) means the response is somewhat interesting and could engage you in the conversation (e.g., an opinion, thought)
- A score of 3 (interesting) means the response is very interesting or presents an interesting factEvaluation Steps:
1. Read the conversation, the corresponding fact and the response carefully.
2. Rate the response on a scale of 1-3 for engagingness, according to the criteria above.
3. Provide a brief explanation for your rating, referring to specific aspects of the response and the conversation.Example:
Conversation History:
{{Document}}
Corresponding Fact:
{{Fact}}
Response:
{{Response}}
Evaluation Form (scores ONLY):
- Engagingness:Evaluate Hallucinations
Human Evaluation of Text Summarization Systems:
Factual Consistency: Does the summary untruthful or misleading facts that are not supported by the source text? Source Text:
{{Document}}
Summary:
{{Summary}}
Does the summary contain factual inconsistency?
Answer:RAGAs
https://arxiv.org/pdf/2309.15217
https://github.com/explodinggradients/ragas
https://docs.ragas.io/en/latest/index.html
使用 RAGAs(Retrieval Augmented Generation Assessment)进行评测的步骤可以概括为以下几个主要环节:
- 定义质量维度:
-
- 忠实度(Faithfulness):确保生成的答案能够从给定的上下文中推断出来,避免幻觉。
- 答案相关性(Answer Relevance):生成的答案应直接且适当地回答所提出的问题。
- 上下文相关性(Context Relevance):检索的上下文应集中且只包含回答所需的信息。
- 使用语言模型(LLM)进行评估:
-
- 利用一个大型语言模型(如 GPT-3.5 或更新版本)来自动化评估过程。
- 依据数据分别评估每个维度的分数
- 计算分数并迭代优化
效果
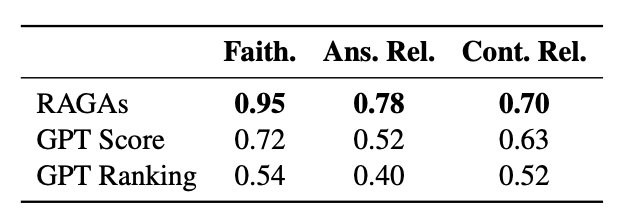
不同自动评测方法相较于人类评测的准确度
- 在忠实度(Faithfulness)上的预测与人类评估员的判断高度一致,准确率约为0.95。
- 在答案相关性(Answer Relevance)方面,RAGAs的一致性稍低,准确率约为0.78
- 在上下文相关性(Context Relevance)方面,RAGAs的准确率约为0.70,
实现
忠实度(Faithfulness)
- 忠实度评估的是生成答案是否能够从给定的上下文中推断出来。首先,使用 LLM 从生成的答案中提取一系列陈述。提取声明的 prompt 示例:
Given a question and answer, create one or more statements from each sentence in the given answer.
question: [question]
answer: [answer]- 然后,对于每个声明,使用 LLM 的验证函数来确定它是否可以从上下文中推断出来。验证声明的 prompt 示例:
Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explanation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
statement: [statement 1]
...
statement: [statement n]- 最终的忠实度得分(F)是支持的声明数量与总声明数量的比例,使用以下公式计算:
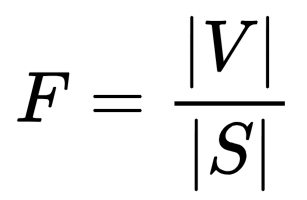
-
- F 代表忠实度得分。
- ∣V∣ 是模型验证后确认可以由上下文支持的声明的数量。
- ∣S∣ 是从答案中提取出的总声明数量。
答案相关性(Answer Relevance)
- 答案相关性评估的是生成答案是否直接且适当地回答了提出的问题。基于生成的答案,LLM 生成 n 个潜在的问题。生成潜在问题的 prompt 示例:
Generate a question for the given answer.
answer: [answer]- 使用文本嵌入模型计算原始问题与每个潜在问题之间的相似度。
- 答案相关性评分计算公式:
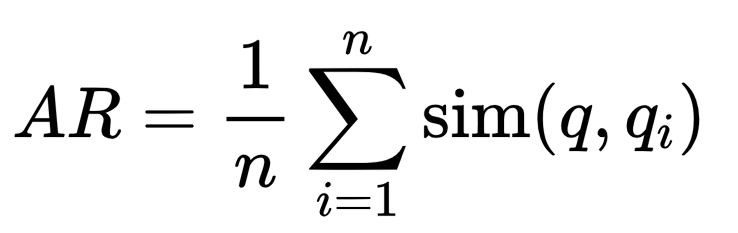
-
- AR 是答案相关性评分
-
是原始问题 q 与潜在问题 qi 之间的相似度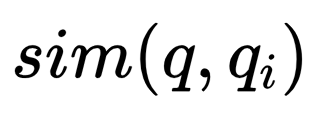
上下文相关性(Context Relevance)
- 上下文相关性评估的是检索的上下文是否只包含回答所需的信息,避免包含冗余信息。LLM 从给定的上下文中提取对回答问题至关重要的句子子集。提取相关句子的 prompt 示例:
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you’re not allowed to make any changes to sentences from given context.- 上下文相关性评分计算公式:
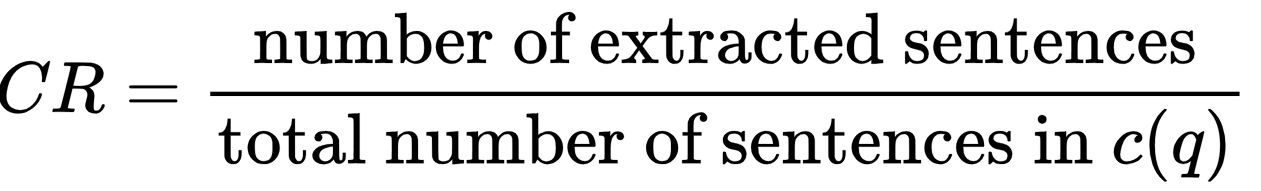
-
- 其中 CR 是上下文相关性评分
GPT Score
https://arxiv.org/pdf/2302.04166
相关文章:
如何评估一个RAG(检索增强生成)系统-上篇
最近项目中需要评估业务部门搭建的RAG助手的效果好坏,看了一下目前业界一些评测的方法。目前分为两大类,基于传统的规则、机器学习的评测方法,基于大模型的评测方法。在这里做一些记录,上篇主要做评测方法的记录,下篇会…...

rust解说
Rust 是一种开源的系统编程语言,由 Mozilla 研究院开发,旨在提供高性能、内存安全且并发性良好的编程体验。 Rust 于 2010 年由 Graydon Hoare 开始设计,并在 2015 年发布了第一个稳定版本。 Rust 的设计目标是解决 C 等传统系统编程语言在…...

Elasticsearch 开放 inference API 为 Hugging Face 添加了原生分块支持
作者:来自 Elastic Max Hniebergall 借助 Elasticsearch 开放推理 API,你可以使用 Hugging Face 的推理端点(Inference Endpoints)在 Elasticsearch 之外执行推理。这样你就可以使用 Hugging Face 的可扩展基础架构,包…...
Jenkins部署若依项目
一、配置环境 机器 jenkins机器 用途:自动化部署前端后端,前后端自动化构建需要配置发送SSH的秘钥和公钥,同时jenkins要有nodejs工具来进行前端打包,maven工具进行后端的打包。 gitlab机器 用途:远程代码仓库拉取和…...

ELK笔记
要搞成这样就需要钱来买服务器 开发人员一般不会给服务器权限,不能到服务器上直接看日志,所以通过ELK看日志。不让开发登录服务器。即使你查出来是开发的问题,费时间,而且影响了业务了,就是运维的问题 开发也不能登录…...

计算机网络 --- 计算机网络的分类
一、计算机网络分类 1.1 按分布范围分类 举例:广域网(WAN)、局域网(LAN) 举例:个域网(PAN) 1.2 按传输技术分类 广播式网络――当一台计算机发送数据分组时,广播范围…...

三维动画|创意无限,让品牌传播更精彩!
随着三维动画技术的不断成熟,三维动画宣传片能够很好地宣传品牌、推广产品,因而慢慢地受到不少企业的青睐,成为品牌最常用的一种宣传方式。 三维动画宣传片作为艺术感极高的宣传视频有强烈的节奏感,而且具有风趣、易懂等特点&…...

欧零导航系统正式版,功能强大,可直接运营
欧零导航系统正式版,带广告位/导航分类/可直接运营 本系统采用PHPMySQL技术开发 拥有独立的安装和后台系统 后台采用BootstripMDUI框架 前台使用响应式界面,自适应各种屏幕 代码免费下载:百度网盘...
了解变压器耦合电压开关 D类放大器
在本文中,我们将讨论另一种 D 类配置:变压器耦合电压切换 (TCVS) 放大器。TCVS 放大器的原理图如图 1 所示。 变压器耦合电压开关 D 类放大器的示意图。 图 1.变压器耦合电压开关 D 类放大器。 在本文中,我们将探索该放大器的工作原理&…...

openssh移植:精致的脚本版
前置文章: busybox移植:全能脚本版-CSDN博客 zlib交叉编译-CSDN博客 openssl移植:精致的脚本版-CSDN博客 源码下载 官网:http://www.openssh.com/ 下载了一个很新的版本 ftp://mirrors.sonic.net/pub/OpenBSD/OpenSSH/portable/openss…...

3C电子胶黏剂在手机制造方面有哪些关键的应用
3C电子胶黏剂在手机制造方面有哪些关键的应用 3C电子胶黏剂在手机制造中扮演着至关重要的角色,其应用广泛且细致,覆盖了手机内部组件的多个层面,确保了设备的可靠性和性能。以下是电子胶在手机制造中的关键应用: 手机主板用胶&…...
)
Oracle数据库中的动态SQL(Dynamic SQL)
Oracle数据库中的动态SQL是一种在运行时构建和执行SQL语句的技术。与传统的静态SQL(在编写程序时SQL语句就已经确定)不同,动态SQL允许开发者在程序执行过程中根据不同的条件或用户输入来构建SQL语句。这使得动态SQL在处理复杂查询、存储过程中…...

Python判断两张图片的相似度
在Python中,判断两张以numpy的ndarray格式存储的图片的相似度,通常可以通过多种方法来实现,包括但不限于直方图比较、像素差比较、结构相似性指数(SSIM)、特征匹配等。以下是一些常见方法的简要介绍和示例代码。 1. 像…...

MySQL高级功能-窗口函数
背景 最近遇到需求,需要对数据进行分组排序并获取每组数据的前三名。 一般涉及到分组,第一时间就是想到使用group by对数据进行分组,但这样分组,到最后其实只能获取到每组数据中的一条记录。 在需要获取每组里面的多条记录的时候…...

9.12总结
今天学了树状dp和tarjan 树状dp 树状dp,是一种在树形数据结构上应用的动态规划算法。动态规划(DP)通常用于解决最优化问题,通过将问题分解为相对简单的子问题来求解。在树形结构中,由于树具有递归和子结构的特性&…...

小众创新组合!LightGBM+BO-Transformer-LSTM多变量回归交通流量预测(Matlab)
小众创新组合!LightGBMBO-Transformer-LSTM多变量回归交通流量预测(Matlab) 目录 小众创新组合!LightGBMBO-Transformer-LSTM多变量回归交通流量预测(Matlab)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现LightGBMBO-Transformer-L…...

《CSS新世界》书评
《CSS新世界》是由张鑫旭所著,人民邮电出版社在2021年8月10日出版的一本专门讲解CSS3及其之后版本新特性的进阶读物。这本书是“CSS世界三部曲”中的最后一部,全书近600页,内容丰富,涵盖了CSS的全局知识、已有属性的增强、新布局方…...

python 实现euler modified变形欧拉法算法
euler modified变形欧拉法算法介绍 Euler Modified(改进)变形欧拉法算法,也被称为欧拉修改法或修正欧拉法(Euler Modified Method),是一种用于数值求解微分方程的改进方法。这种方法在传统欧拉法的基础上进…...

strcpy 函数及其缺点
目录 一、概念 二、strcpy 函数有什么缺点 1. 缺乏边界检查 2. 容易引发未定义行为 3. 不适合动态和未知长度的字符串操作 4. 替代方案的可用性 5. 效率问题 一、概念 strcpy 是 C 语言中的一个标准库函数,用于将源字符串复制到目标字符串中。它定义在 <…...

区块链-P2P(八)
前言 P2P网络(Peer-to-Peer Network)是一种点对点的网络结构,它没有中心化的服务器或者管理者,所有节点都是平等的。在P2P网络中,每个节点都可以既是客户端也是服务端,这种网络结构的优点是去中心化、可扩展…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

Wand-Enhancer:零成本解锁WeMod高级功能的完整指南
Wand-Enhancer:零成本解锁WeMod高级功能的完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫不决吗…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

基于PyPortal与CircuitPython的物联网游戏数据显示器开发实战
1. 项目概述 如果你和我一样,既是《英雄联盟》的忠实玩家,又对嵌入式硬件开发充满热情,那么把这两者结合起来,做一个能实时展示自己召唤师等级的“实体奖杯”,绝对是一件既酷又有成就感的事情。这个项目就是基于Adafr…...

基于Electron的ChatGPT桌面客户端开发:架构、功能与进阶实践
1. 项目概述:一个开源桌面客户端的诞生与价值如果你和我一样,在日常开发、写作或者处理一些需要深度思考的任务时,经常需要和ChatGPT这样的AI助手对话,那你一定对在浏览器里反复切换标签页、刷新页面、管理冗长的对话历史感到厌烦…...