Hive企业级调优[6]——HQL语法优化之任务并行度
目录
HQL语法优化之任务并行度
优化说明
Map端并行度
Reduce端并行度
优化案例
HQL语法优化之任务并行度
优化说明
对于分布式计算任务来说,设置一个合理的并行度至关重要。Hive的计算任务依赖于MapReduce框架来完成,因此并行度的调整需要从Map端和Reduce端两方面考虑。
Map端并行度
Map端的并行度指的是Map任务的数量,这通常是由输入文件的切片数决定的。在大多数情况下,Map端的并行度无需手动调整。但在以下特殊情况下,可以考虑调整Map端并行度:
-
查询的表中存在大量小文件 按照Hadoop默认的切片策略,每个小文件会被分配给一个独立的map task进行处理。如果查询的表包含大量的小文件,则会导致启动大量的map task,造成计算资源的浪费。为了解决这个问题,可以使用Hive提供的CombineHiveInputFormat,将多个小文件合并成一个切片,从而减少map task的数量。相关参数如下:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -
Map端有复杂的查询逻辑 如果SQL语句中包含了复杂的查询逻辑,如正则替换、JSON解析等,那么Map端的计算可能会相对较慢。在这种情况下,如果计算资源充足,可以考虑增加Map端的并行度,使每个map task处理的数据量减少,以加快计算速度。相关参数如下:
-- 一个切片的最大值 set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce端并行度
Reduce端的并行度是指Reduce任务的数量。与Map端相比,Reduce端的并行度更为关键。Reduce端的并行度可以由用户指定,也可以由Hive根据输入文件的大小自动估算。Reduce端并行度的相关参数如下:
set mapreduce.job.reduces;(指定Reduce端并行度,默认值为-1,表示用户未指定)set hive.exec.reducers.max;(Reduce端并行度最大值)set hive.exec.reducers.bytes.per.reducer;(单个Reduce Task计算的数据量,用于估算Reduce并行度)
Reduce端并行度的确定逻辑如下:
如果指定了参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为该指定值。否则,Hive将自行估算Reduce并行度,估算逻辑如下:
假设Job输入的文件大小为totalInputBytes, 参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer, 参数hive.exec.reducers.max的值为maxReducers,
则Reduce端的并行度为:
Reduce并行度=min(⌈totalInputBytesbytesPerReducer⌉,maxReducers)Reduce并行度=min(⌈bytesPerReducertotalInputBytes⌉,maxReducers)
由于Hive自行估算Reduce并行度时,是基于整个MR Job输入文件大小的,因此在某些情况下,其估计的并行度可能并不准确。此时,用户需要根据实际情况来指定Reduce并行度。
优化案例
示例SQL语句
hive (default)> select province_id, count(*) from order_detail group by province_id;优化前 上述SQL语句在不指定Reduce并行度时,Hive自行估算并行度的逻辑如下:
假设totalInputBytes = 1136009934, bytesPerReducer = 256000000, maxReducers = 1009,
经计算,Reduce并行度为:
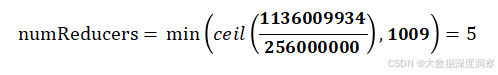
优化思路 上述SQL语句在默认情况下,会进行map-side聚合,即Reduce端接收到的数据已经是Map端聚合后的结果。观察任务执行过程会发现,每个Map端输出的数据只有34条记录,共有5个map task。
这意味着Reduce端实际上只会接收170(34 * 5)条记录。因此理论上Reduce端并行度设置为1就足够了。在这种情况下,用户可以通过以下参数自行设置Reduce端并行度为1:
-- 指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces=1;相关文章:
Hive企业级调优[6]——HQL语法优化之任务并行度
目录 HQL语法优化之任务并行度 优化说明 Map端并行度 Reduce端并行度 优化案例 HQL语法优化之任务并行度 优化说明 对于分布式计算任务来说,设置一个合理的并行度至关重要。Hive的计算任务依赖于MapReduce框架来完成,因此并行度的调整需要从Map端和…...

Excel 冻结多行多列
背景 版本:office 2021 专业版 无法像下图内某些版本一样,识别选中框选的多行多列。 如下选中后毫无反应,点击【视图】->【冻结窗口】->【冻结窗格】后自动设置为冻结第一列。 操作 如下,要把前两排冻结起来。 选择 C1&a…...

基于微信小程序的智慧物业管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码 精品专栏:Java精选实战项目…...

【论文笔记】BEVNeXt: Reviving Dense BEV Frameworks for 3D Object Detection
原文链接:https://arxiv.org/pdf/2312.01696 简介:最近,在摄像头3D目标检测任务中,基于查询的Transformer解码器正在超越传统密集BEV方法。但密集BEV框架有着更好的深度估计和目标定位能力,能全面精确地描绘3D场景。本…...

基于open-gpu-kernel-modules的p2p vram映射bar1提高通信效率
背景 bar1 Base Address Register 1 用于内存映射的寄存器,定义了设备的内存映射区域,BAR1专门分配给gpu的一部分内存区域,允许cpu通过pcie总线直接访问显存VRAM中的数据。但bar1的大小是有限的,在常规的4090上,bar1只…...

java之斗地主部分功能的实现
今天我们要实现斗地主中发牌和洗牌这两个功能,该如何去实现呢? 1.创建牌类:52张牌每一张牌包含两个属性:牌的大小和牌的花色。 故我们优先创建一个牌的类(Card):包含大小和花色。 public class Card { //单张牌的大小及类型/…...
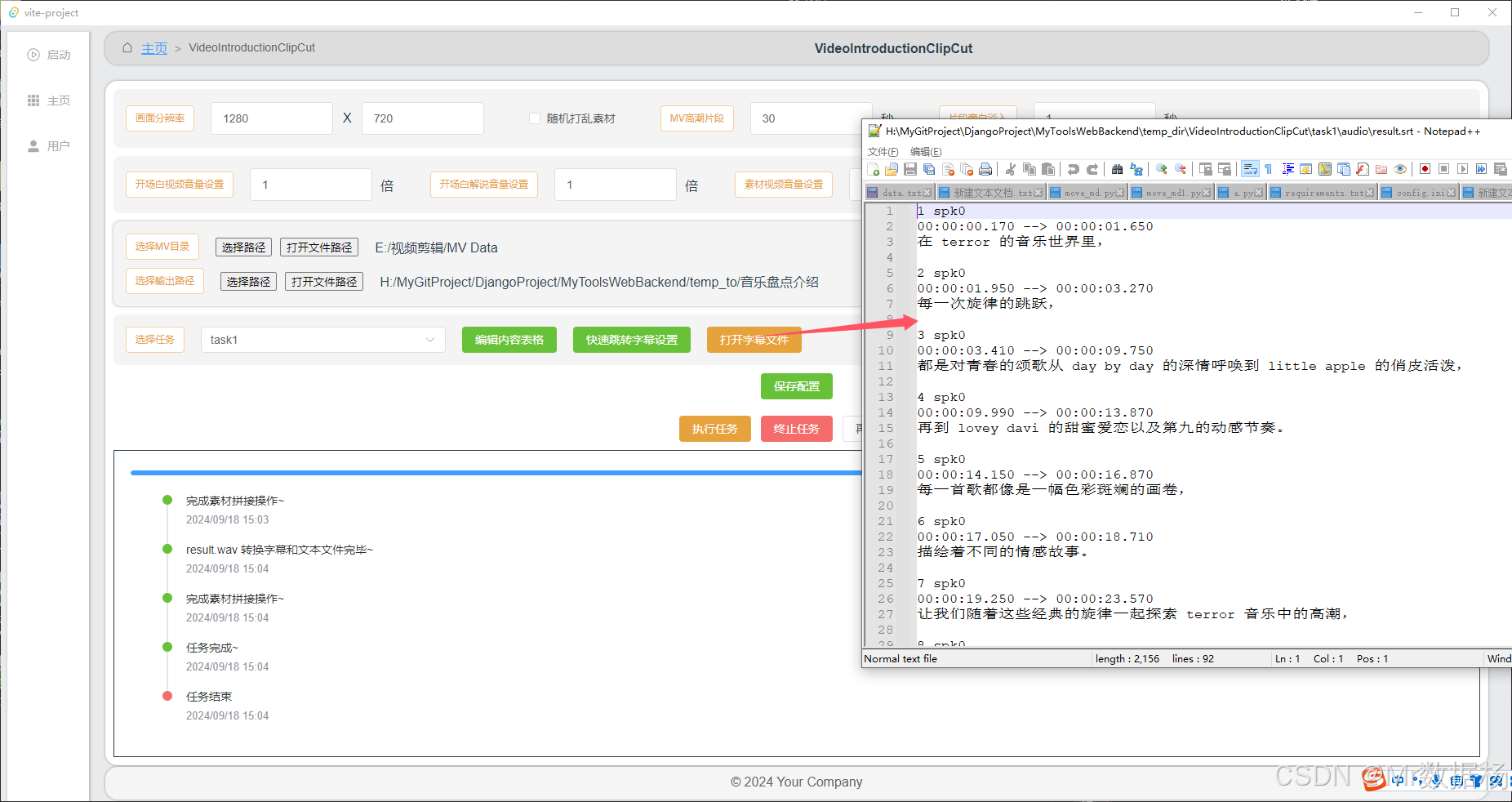
我的AI工具箱Tauri版-VideoIntroductionClipCut视频介绍混剪
本教程基于自研的AI工具箱Tauri版进行VideoIntroductionClipCut视频介绍混剪。 本项目为自研的AI工具箱Tauri版中的视频剪辑模块,专注于自动生成视频介绍片段。该模块名为 VideoIntroductionClipCut,用户可以通过该工具快速进行视频的混剪和介绍内容的生…...

【鸿蒙OH-v5.0源码分析之 Linux Kernel 部分】011 - 第一个用户空间进程 init 进程 第一阶段初始化过程 源码分析
【鸿蒙OH-v5.0源码分析之 Linux Kernel 部分】011 - 第一个用户空间进程 init 进程 第一阶段初始化过程 源码分析 系列文章汇总:《鸿蒙OH-v5.0源码分析之 Uboot+Kernel 部分】000 - 文章链接汇总》 本文链接:《【鸿蒙OH-v5.0源码分析之 Linux Kernel 部分】011 - 第一个用户空…...

MyBatis 源码解析:Mapper 文件加载与解析
引言 在 MyBatis 中,Mapper 文件扮演了至关重要的角色,它通过 SQL 映射文件来定义数据库查询操作和 Java 对象之间的映射关系。Mapper 文件通常是以 XML 格式存储的,包含了 SQL 语句以及与 Java 对象的对应关系。在本篇文章中,我…...

(11)(2.1.2) DShot ESCs(二)
文章目录 前言 3 配置伺服功能 4 检查RC横幅 5 参数说明 前言 DShot 是一种数字 ESC 协议,它允许快速、高分辨率的数字通信,可以改善飞行器控制,这在多旋翼和 quadplane 应用中特别有用。 3 配置伺服功能 如上所述,如果使用…...

yolov5/8/9模型在COCO分割数据集上的应用【代码+数据集+python环境+GUI系统】
yolov5/8/9模型在COCO分割数据集上的应用【代码数据集python环境GUI系统】 yolov5/8/9模型在COCO分割数据集上的应用【代码数据集python环境GUI系统】 1.COCO数据集介绍 COCO数据集,全称为Microsoft Common Objects in Context,是微软于2014年出资标注的…...

技术周总结 09.16~09.22 周日(架构 C# 数据库)
文章目录 一、09.16 周一1.1)问题01: 软件质量属性中"质量属性场景"、"质量属性环境分析"、"质量属性效用树"、"质量属性需求用例分析"分别是什么?1.2)问题02: 软件质量属性中…...

【java实现json转化为CSV文件】
文章目录 JSON文件中的数据格式测试文件转换的接口 JSON文件中的数据格式 单条数据展开后如下: {"text": "《邪少兵王》是冰火未央写的网络小说连载于旗峰天下","spo_list":[{"predicate": "作者", "objec…...

MySQL索引知识个人笔记总结(持续整理)
本篇笔记是个人整理的索引知识总结,刚开始有点乱,后续会一直边学边整理边总结 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。就好比索引就是数据的目录 索引结构 Btree索引,Hash索引,Full-text索引,R-tree(空…...

ReKep——李飞飞团队提出的让机器人具备空间智能:基于视觉语言模型GPT-4o和关系关键点约束
前言 由于工厂、车厂的任务需求场景非常明确,加之自今年年初以来,我司在机器人这个方向的持续大力度投入(包括南京、长沙两地机器人开发团队的先后组建),使得近期我司七月接到了不少来自车厂/工厂的订单,比如其中的三个例子&…...

[Java并发编程] synchronized(含与ReentrantLock的区别)
文章目录 1. synchronized与ReentrantLock的区别2. synchronized的作用3. synchronized的使用3.1 修饰实例方法,作用于当前实例,进入同步代码前需要先获取实例的锁3.2 修饰静态方法,作用于类的Class对象,进入修饰的静态方法前需要…...

spring-boot-maven-plugin插件打包和java -jar命令执行原理
文章目录 1. Maven生命周期2. jar包结构2.1 不可执jar包结构2.2 可执行jar包结构 3. spring-boot-maven-plugin插件打包4. 执行jar原理 1. Maven生命周期 Maven的生命周期有三种: clean:清除项目构建数据,较为简单,不深入探讨&a…...

Python办公自动化教程(001):PDF内容提取
1、Pdfplumber介绍 pdfplumber的github地址: https://github.com/jsvine/pdfplumber/【介绍】:pdfplumber 是一个用于处理 PDF 文件的 Python 第三方库,它提供了一种方便的方式来提取 PDF 文件中的文本、表格和其他信息。【功能】ÿ…...
HarmonyOS鸿蒙开发实战(5.0)自定义全局弹窗实践
鸿蒙HarmonyOS开发实战往期文章必看: HarmonyOS NEXT应用开发性能实践总结 最新版!“非常详细的” 鸿蒙HarmonyOS Next应用开发学习路线!(从零基础入门到精通) 非常详细的” 鸿蒙HarmonyOS Next应用开发学习路线&am…...

【AI学习】了解OpenAI o1背后的self-play RL:开启新的智能道路
在ChatGPT刚刚出来的时候,沐神关于ChatGPT有一段视频,只有几分钟,却是讲得极其透彻的一段。大概意思就是,过去的AI智能水平,比如五年前,大概相当于人类5秒钟思考的程度,包括自动驾驶,…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...