LeetCode从入门到超凡(二)递归与分治算法

引言
大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年9月学习赛的LeetCode学习总结文档;在算法设计中,递归和分治算法是两种非常重要的思想和方法。它们不仅在解决复杂问题时表现出色,而且在许多经典算法中都有广泛的应用😉。因此理解这两种算法的原理和思路,对算法学习很有意义!💕💕😊
介绍
- 递归(Recursion):是一种通过重复将原问题分解为同类的子问题来解决问题的方法。在编程中,
递归通常通过在函数内部调用函数自身来实现。递归算法的核心思想是将复杂问题分解为更小的子问题,直到子问题足够简单,可以直接求解。
递归算法在许多场景中都非常有用,例如树的遍历、图的搜索、以及一些数学问题的求解(如阶乘、斐波那契数列等)。
- 分治算法(Divide and Conquer):是一种
将复杂问题分解为多个相同或相似的子问题,直到子问题可以直接求解,再将子问题的解合并为原问题的解的方法。分治算法的核心思想是将问题分解为更小的子问题,递归地解决这些子问题,然后将子问题的解合并以得到原问题的解。分治算法在许多经典算法中都有应用,例如归并排序、快速排序、二分查找等。
🙂接下来,作者将和各位分别详细探讨递归算法和分治算法的基本原理和实现步骤。
一. 递归算法
1.简介
递归(Recursion) 是一种通过重复将原问题分解为同类的子问题来解决问题的方法。在编程中,递归通常通过在函数内部调用函数自身来实现。递归算法的核心思想是将复杂问题分解为更小的子问题,直到子问题足够简单,可以直接求解。递归算法在许多场景中都非常有用,例如树的遍历、图的搜索、以及一些数学问题的求解(如阶乘、斐波那契数列等)。
举例说明:阶乘计算的递归实现
让我们从一个经典的例子开始——阶乘计算。阶乘的数学定义如下:
fact ( n ) = { 1 n = 0 n × fact ( n − 1 ) n > 0 \text{fact}(n) = \begin{cases} 1 & \text{n = 0} \\ n \times \text{fact}(n - 1) & \text{n > 0} \end{cases} fact(n)={1n×fact(n−1)n = 0n > 0
根据这个定义,我们可以使用递归来实现阶乘函数。代码如下:
def fact(n):if n == 0:return 1return n * fact(n - 1)
以 ( n = 6 ) 为例,上述代码中阶乘函数 fact ( 6 ) \text{fact}(6) fact(6) 的计算过程如下:
fact(6)
= 6 * fact(5)
= 6 * (5 * fact(4))
= 6 * (5 * (4 * fact(3)))
= 6 * (5 * (4 * (3 * fact(2))))
= 6 * (5 * (4 * (3 * (2 * fact(1)))))
= 6 * (5 * (4 * (3 * (2 * (1 * fact(0))))))
= 6 * (5 * (4 * (3 * (2 * (1 * 1)))))
= 6 * (5 * (4 * (3 * (2 * 1))))
= 6 * (5 * (4 * (3 * 2)))
= 6 * (5 * (4 * 6))
= 6 * (5 * 24)
= 6 * 120
= 720
这个过程就像是一个不断缩小的俄罗斯套娃,最终找到最小的那个。
2 递归的基本思想
① 递推过程:将问题分解为子问题
递归的递推过程是指将原问题分解为更小的子问题。在这个过程中,函数会不断调用自身,直到达到某个终止条件。例如,在阶乘计算中,我们将 fact ( n ) \text{fact}(n) fact(n)分解为 n × fact ( n − 1 ) n \times \text{fact}(n - 1) n×fact(n−1) 。
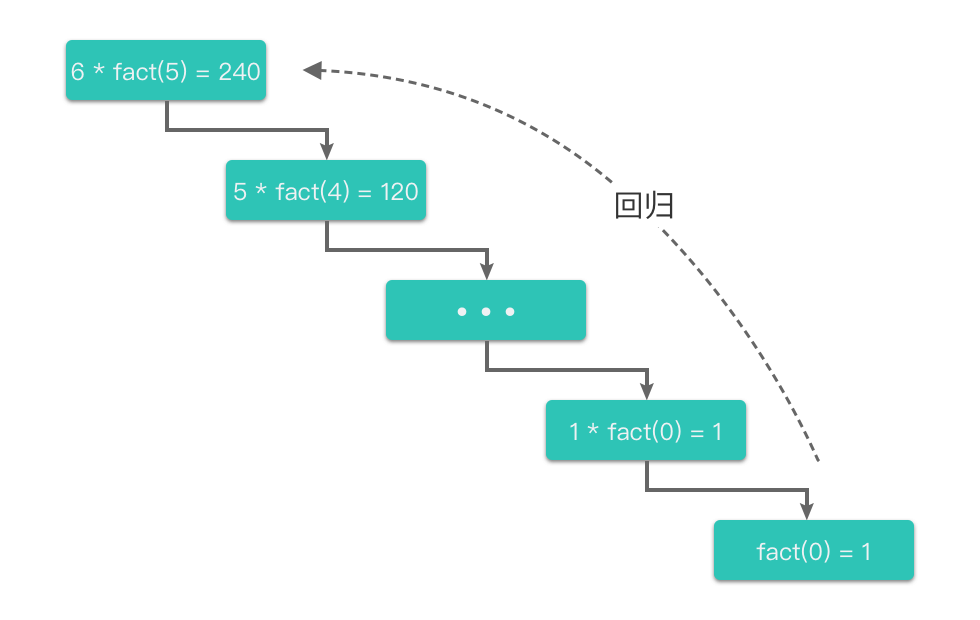
② 回归过程:从子问题的解回归到原问题的解
回归过程是指从最小的子问题的解开始,逐步返回到原问题的解。在阶乘计算中,当 ( n = 0 ) 时,递归终止,开始回归过程,逐层返回结果,直到返回原问题的解。
③ 图示说明递推和回归过程
为了更直观地理解递推和回归过程,我们可以通过图示来说明。假设我们要计算 fact ( 5 ) \text{fact}(5) fact(5),递推和回归过程如下图所示:
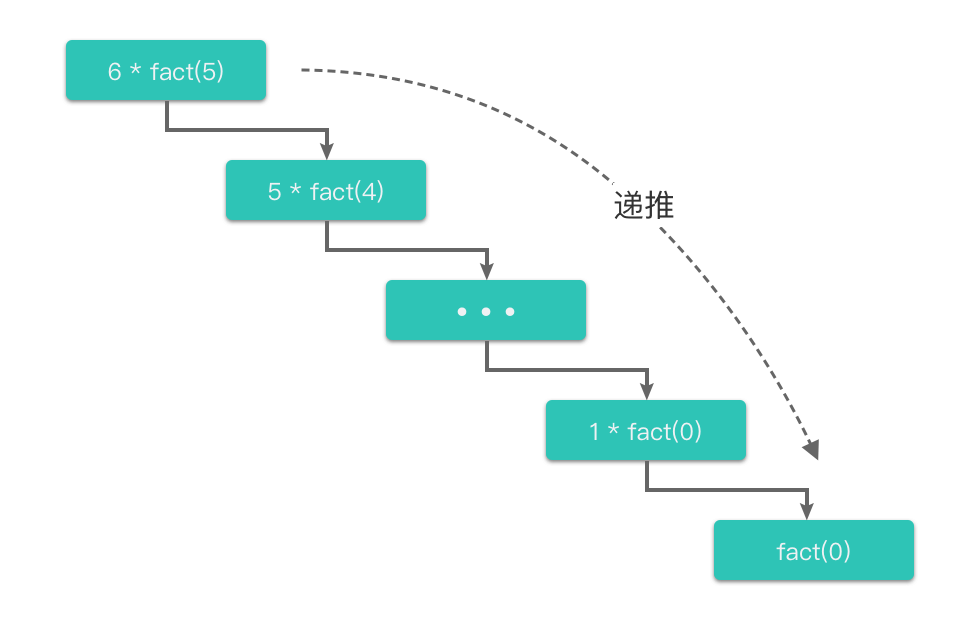
递归就像是一个不断重复的自我召唤过程,就像你在镜子前放了一面镜子,镜子里又有一个镜子,无限循环下去。在编程中,递归就是函数调用自身,直到问题变得足够简单,可以直接解决。
其基本思想就是:把规模大的问题不断分解为子问题来解决。
3. 递归与数学归纳法
递归与数学归纳法的相似性
递归和数学归纳法在思想上非常相似。数学归纳法是一种证明方法,通常用于证明某个命题对所有自然数成立。数学归纳法的证明步骤如下:
- 基例:证明当 n = b 时,命题成立。
- 归纳步骤:假设当 n = k 时命题成立,证明当 ( n = k + 1 ) 时命题也成立。
递归的实现过程也可以分为两个部分:
- 递归终止条件:相当于数学归纳法中的基例。
- 递推过程:相当于数学归纳法中的归纳步骤。
数学归纳法的证明步骤与递归的对应关系
- 递归终止条件:数学归纳法第一步中的 ( n = b ),可以直接得出结果。
- 递推过程:数学归纳法第二步中的假设部分(假设 ( n = k ) 时命题成立),也就是假设我们当前已经知道了 ( n = k ) 时的计算结果。
- 回归过程:数学归纳法第二步中的推论部分(根据 ( n = k ) 推论出 ( n = k + 1 )),也就是根据下一层的结果,计算出上一层的结果。
4 递归三步走
① 写出递推公式:找到将原问题分解为子问题的规律
写出递推公式的关键在于找到将原问题分解为子问题的规律,并将其抽象成递推公式。例如,在阶乘计算中,递推公式为 fact ( n ) = n × fact ( n − 1 ) \text{fact}(n) = n \times \text{fact}(n - 1) fact(n)=n×fact(n−1)。
② 明确终止条件:确定递归的结束条件
递归的终止条件也叫做递归出口。如果没有递归的终止条件,函数就会无限地递归下去,程序就会失控崩溃。通常情况下,递归的终止条件是问题的边界值。例如,在阶乘计算中,终止条件是 ( n = 0 )。
③ 将递推公式和终止条件翻译成代码
在写出递推公式和明确终止条件之后,我们就可以将其翻译成代码了。这一步也可以分为三步来做:
- 定义递归函数:明确函数意义、传入参数、返回结果等。
- 书写递归主体:提取重复的逻辑,缩小问题规模。
- 明确递归终止条件:给出递归终止条件,以及递归终止时的处理方法。
def fact(n):if n == 0:return 1return n * fact(n - 1)
5 注意事项
① 避免栈溢出:限制递归深度或转换为非递归算法
在程序执行中,递归是利用堆栈来实现的。每一次递推都需要一个栈空间来保存调用记录,每当进入一次函数调用,栈空间就会加一层栈帧。每一次回归,栈空间就会减一层栈帧。由于系统中的栈空间大小不是无限的,所以,如果递归调用的次数过多,会导致栈空间溢出。
为了避免栈溢出,我们可以在代码中限制递归调用的最大深度来解决问题。当递归调用超过一定深度时(比如 100)之后,不再进行递归,而是直接返回报错。当然,这种做法并不能完全避免栈溢出,也无法完全解决问题,因为系统允许的最大递归深度跟当前剩余的栈空间有关,事先无法计算。
如果使用递归算法实在无法解决问题,我们可以考虑将递归算法变为非递归算法(即递推算法)来解决栈溢出的问题。
② 避免重复运算:使用缓存(哈希表、集合或数组)保存已求解的子问题结果
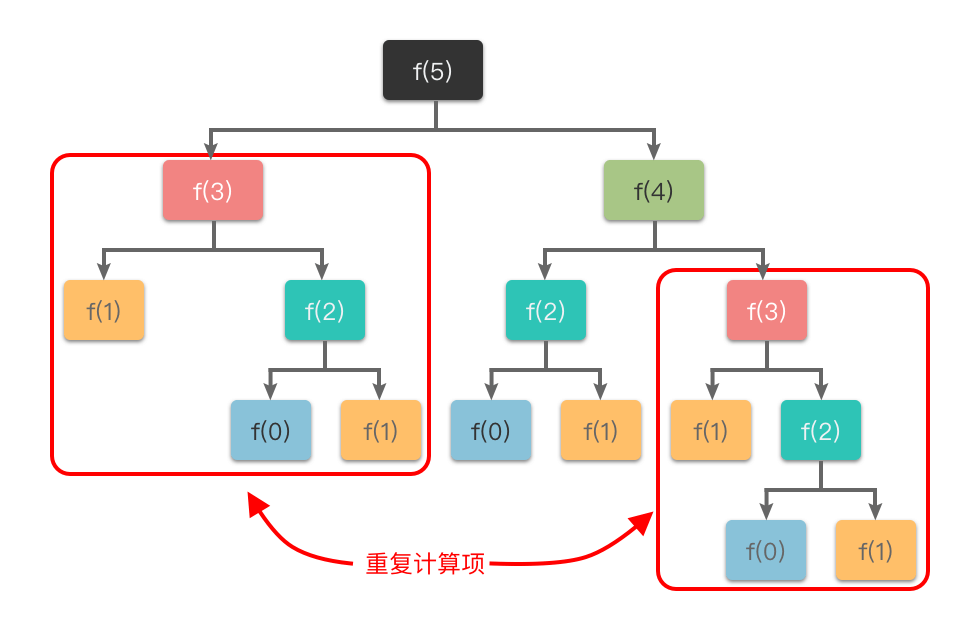
在使用递归算法时,还可能会出现重复运算的问题。例如,在计算斐波那契数列时,递归过程中会多次计算相同的子问题,导致效率低下。为了避免重复计算,我们可以使用一个缓存(哈希表、集合或数组)来保存已经求解过的子问题的结果。当递归调用到某个子问题时,先查看缓存中是否已经计算过结果,如果已经计算,则直接从缓存中取值返回,而无需继续递推,如此以来便避免了重复计算问题。

6.递归的应用
① 斐波那契数列:递归实现及其复杂度分析
斐波那契数列的定义如下:
f ( n ) = { 0 n = 0 1 n = 1 f ( n − 1 ) + f ( n − 2 ) n > 1 f(n) = \begin{cases} 0 & n = 0 \\ 1 & n = 1 \\ f(n - 1) + f(n - 2) & n > 1 \end{cases} f(n)=⎩ ⎨ ⎧01f(n−1)+f(n−2)n=0n=1n>1
我们可以使用递归来实现斐波那契数列的计算:
def fib(n):if n == 0:return 0if n == 1:return 1return fib(n - 1) + fib(n - 2)
然而,这种递归实现的效率非常低,时间复杂度为 $ O(2^n) $,因为递归过程中会多次计算相同的子问题。为了避免重复计算,我们可以使用缓存来优化算法:
cache = {}
def fib(n):if n in cache:return cache[n]if n == 0:return 0if n == 1:return 1cache[n] = fib(n - 1) + fib(n - 2)return cache[n]
通过使用缓存,我们可以将时间复杂度降低到 ( O(n) )。
② 二叉树的最大深度:递归实现及其复杂度分析
二叉树的最大深度是指从根节点到最远叶子节点的最长路径上的节点数。我们可以使用递归来计算二叉树的最大深度:
def maxDepth(root):if not root:return 0return max(maxDepth(root.left), maxDepth(root.right)) + 1
这个递归算法的时间复杂度为 ( O(n) ),其中 ( n ) 是二叉树的节点数。空间复杂度为 ( O(h) ),其中 ( h ) 是二叉树的高度。
二. 分治算法
1.简介
分治算法(Divide and Conquer)是一种经典的算法设计策略,其核心思想是**将一个复杂的问题分解为多个相同或相似的子问题,直到这些子问题变得足够简单,可以直接求解。然后,将这些子问题的解合并起来,形成原问题的解。**
分治算法的步骤通常包括以下三个部分:
- 分解(Divide):将原问题分解为若干个规模较小的子问题,这些子问题通常是原问题的简化版本。
- 解决(Conquer):递归地解决这些子问题。如果子问题的规模足够小,可以直接求解。
- 合并(Combine):将子问题的解合并为原问题的解。
① 与递归的联系
递归是一种编程技巧,通过函数调用自身来解决问题。分治算法通常使用递归来实现,因为递归能够自然地表达问题的分解和合并过程。
具体来说,递归函数在执行过程中会不断地调用自身,直到达到某个基准条件(即子问题可以直接求解的条件),然后逐层返回结果,最终合并成原问题的解。
然而,分治算法并不局限于递归实现。在某些情况下,也可以使用迭代(循环)来实现分治策略。迭代实现通常需要手动管理问题的分解和合并过程,因此在复杂度上可能不如递归实现直观。
② 应用场景
分治算法广泛应用于各种领域,特别是在处理大规模数据或复杂问题时,其优势尤为明显。以下是一些常见的应用场景:
- 排序算法:如归并排序(Merge Sort)和快速排序(Quick Sort)。
- 搜索算法:如二分查找(Binary Search)。
- 矩阵运算:如矩阵乘法(Strassen算法)。
- 图算法:如最近公共祖先(LCA)问题。
- 几何问题:如最近点对问题。
③ 优缺点
优点:
- 高效性:通过将问题分解为多个子问题,分治算法通常能够显著降低问题的复杂度。
- 模块化:分治算法将问题分解为多个独立的子问题,便于模块化设计和实现。
- 可扩展性:分治算法适用于处理大规模问题,能够有效地利用多核处理器和分布式计算资源。
缺点:
- 递归开销:递归实现的分治算法可能会带来较大的函数调用开销,尤其是在问题规模较大时。
- 空间复杂度:递归实现通常需要额外的栈空间来存储中间结果,可能导致空间复杂度较高。
- 合并复杂度:在某些情况下,合并子问题的解可能比解决子问题本身更为复杂,导致整体效率下降。
2.适用条件
分治算法是一种强大的问题解决策略,但其适用性受到一些特定条件的限制。理解这些条件有助于我们在面对具体问题时,判断是否适合采用分治策略。这里作者整理了一下分治算法的应用条件:
② 可分解(Divisibility)
条件:问题可以分解为若干个规模较小的相同子问题。
解释:
分治算法的核心思想是将复杂问题分解为多个相同或相似的子问题。这意味着问题的结构必须允许我们将其划分为多个独立的子问题,且这些子问题的结构与原问题相同或相似。例如,在归并排序中,我们将一个数组分解为两个子数组,每个子数组的排序问题与原数组的排序问题结构相同。
思考:
- 可分解性是分治算法的基础。如果一个问题无法被自然地分解为多个子问题,或者分解后的子问题与原问题结构差异较大,那么分治算法可能不适用。
- 例如,某些非线性问题或依赖于全局信息的问题,可能不适合使用分治策略。
- 在实际应用中,我们需要分析问题的结构,判断其是否具有可分解性。
② 子问题可独立求解(Independence)
条件:子问题之间不包含公共的子子问题。
解释:
分治算法要求子问题之间是独立的,即每个子问题的求解不依赖于其他子问题的结果。如果子问题之间存在依赖关系,那么分治算法可能会变得复杂,甚至无法有效应用。例如,在快速排序中,每个子数组的排序是独立的,不依赖于其他子数组的排序结果。
思考:
- 子问题的独立性保证了我们可以并行地解决这些子问题,从而提高算法的效率。
- 如果子问题之间存在依赖关系,可能需要引入额外的数据结构或算法来处理这些依赖,这会增加问题的复杂度。
- 在实际应用中,我们需要分析子问题之间的关系,确保其独立性。
3. 具有分解的终止条件(Termination Condition)
条件:当问题的规模足够小时,能够用较简单的方法解决。
解释:
分治算法通过递归地分解问题,直到问题的规模足够小,可以直接求解。这个“足够小”的规模通常称为终止条件或基准条件。终止条件保证了递归过程能够终止,并且能够返回有效的结果。例如,在归并排序中,当子数组的长度为1时,可以直接返回该数组作为排序结果。
思考:
- 终止条件是分治算法的重要组成部分。如果问题无法被分解到足够小的规模,或者在终止条件下无法直接求解,那么分治算法可能无法正常工作。
- 例如,某些问题可能在分解到一定规模后,仍然需要复杂的计算才能求解,这会限制分治算法的应用。
- 在实际应用中,我们需要确定合适的终止条件,确保问题能够被有效分解和求解。
4. 可合并(Combinability)
条件:子问题的解可以合并为原问题的解,且合并操作的复杂度不能太高。
解释:
分治算法的最后一步是将子问题的解合并为原问题的解。合并操作的复杂度直接影响整体算法的效率。如果合并操作的复杂度过高,可能会抵消分解和求解子问题带来的效率提升。例如,在归并排序中,合并两个已排序的子数组的操作是线性的,复杂度较低。
思考:
- 合并操作的复杂度是分治算法的关键因素之一。在某些情况下,合并操作可能比求解子问题本身更为复杂,导致整体效率下降。
- 例如,某些问题的合并操作可能涉及复杂的计算或数据结构操作,这会增加算法的复杂度。
- 在实际应用中,我们需要仔细考虑合并操作的复杂度,确保其不会成为瓶颈。
3.应用案例:使用分治算法实现归并排序
① 代码
代码如下:
def merge_sort(arr):# 基本情况:如果数组长度小于等于1,直接返回数组if len(arr) <= 1:return arr# 分解:将数组分为两个子数组mid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]# 递归调用,分别对左右两个子数组进行排序left_half = merge_sort(left_half)right_half = merge_sort(right_half)# 合并:将两个有序的子数组合并为一个有序数组return merge(left_half, right_half)def merge(left, right):# 定义一个空列表,用于存储合并后的有序数组merged_arr = []i = j = 0# 比较左右两个子数组的元素,按顺序合并到merged_arr中while i < len(left) and j < len(right):if left[i] < right[j]:merged_arr.append(left[i])i += 1else:merged_arr.append(right[j])j += 1# 将剩余的元素添加到merged_arr中merged_arr.extend(left[i:])merged_arr.extend(right[j:])return merged_arr# 测试代码
arr = [38, 27, 43, 3, 9, 82, 10]
sorted_arr = merge_sort(arr)
print("排序后的数组:", sorted_arr)
② 思路
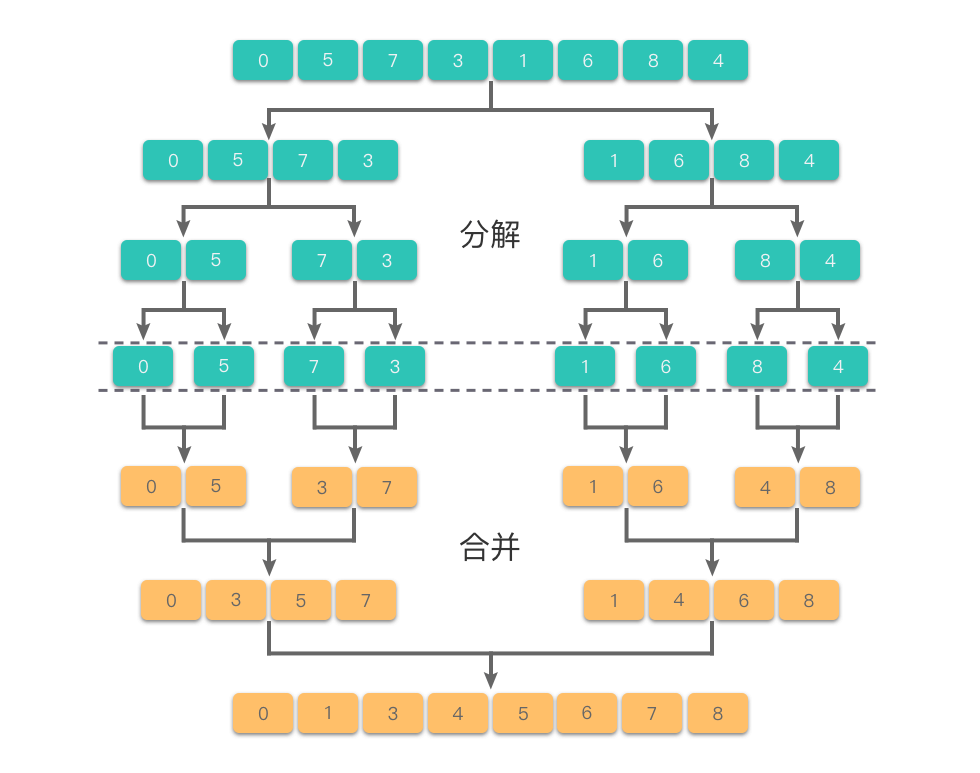
- 函数定义
def merge_sort(arr):
函数定义:merge_sort(arr) 是一个递归函数,用于对数组 arr 进行归并排序。
- 基本情况
if len(arr) <= 1:return arr
基本情况:当数组长度小于等于1时,直接返回数组。这是递归的终止条件,确保递归过程能够终止。
- 分解
mid = len(arr) // 2
left_half = arr[:mid]
right_half = arr[mid:]
分解:将数组 arr 分为两个子数组 left_half 和 right_half。mid 是数组的中间位置,left_half 包含前半部分元素,right_half 包含后半部分元素。
- 递归调用
left_half = merge_sort(left_half)
right_half = merge_sort(right_half)
递归调用:递归调用 merge_sort 函数,分别对左右两个子数组进行排序。
- 合并
return merge(left_half, right_half)
合并:调用 merge 函数,将两个有序的子数组合并为一个有序数组,并返回合并后的结果。
- 合并函数
def merge(left, right):merged_arr = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:merged_arr.append(left[i])i += 1else:merged_arr.append(right[j])j += 1merged_arr.extend(left[i:])merged_arr.extend(right[j:])return merged_arr
合并函数:merge(left, right) 函数用于将两个有序的子数组 left 和 right 合并为一个有序数组。
- **初始化**:定义一个空列表 `merged_arr`,用于存储合并后的有序数组。
- **比较与合并**:使用两个指针 `i` 和 `j`,分别指向 `left` 和 `right` 的当前元素。比较两个指针指向的元素,将较小的元素添加到 `merged_arr` 中,并将对应指针后移。
- **剩余元素**:将 `left` 和 `right` 中剩余的元素添加到 `merged_arr` 中。
- **返回结果**:返回合并后的有序数组 `merged_arr`。
- 测试代码
arr = [38, 27, 43, 3, 9, 82, 10]
sorted_arr = merge_sort(arr)
print("排序后的数组:", sorted_arr)
测试代码:定义一个测试数组 arr,调用 merge_sort 函数对其进行排序,并输出排序后的结果。
③ 思维导图

三、总结
这里我们发现递归和分治算法思路很相似,我们再次声明一下其区别与联系,帮助读者更好的理解;
- 递归是一种编程技巧,通过函数调用自身来简化问题的求解过程。
- 分治算法是一种算法设计策略,通过将复杂问题分解为多个简单的子问题,并递归地解决这些子问题,最终合并得到原问题的解。
- 递归是实现分治算法的一种常用方法,但递归的应用范围更广,不仅仅局限于分治算法。
- 分治算法是一种特定的算法设计策略,适用于那些可以被分解为多个相同或相似子问题的问题。
相关链接
- 项目地址:LeetCode-CookBook
- 相关文档:专栏地址
- 作者主页:GISer Liu-CSDN博客

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.
相关文章:
LeetCode从入门到超凡(二)递归与分治算法
引言 大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年9月学习赛的LeetCode学习总结文档;在算法设计中,递归和分治算法是两种非常重要的思想和方法。它们不仅在解决复杂问题时表…...

superset 解决在 mac 电脑上发送 slack 通知的问题
参考文档: https://superset.apache.org/docs/configuration/alerts-reports/ 核心配置: FROM apache/superset:3.1.0USER rootRUN apt-get update && \apt-get install --no-install-recommends -y firefox-esrENV GECKODRIVER_VERSION0.29.0 RUN wget -q https://g…...

SQL_UNION
在 SQL 中使用 UNION 操作符时,被联合的两个或多个 SELECT 语句的列数必须相同,并且相应的列数据类型也需要兼容。这是因为 UNION 操作符会将结果组合成单个结果集,每个 SELECT 语句的结果行将按顺序放置在结果集中。 例如,如果你…...
高等代数笔记(2)————(弱/强)数学归纳法
数学归纳法的引入情景其实很简单,就是多米诺骨牌。 推倒所有多米诺骨牌的关键就是推倒第一块,以及确保第一块倒下后会带动第二块,第二块带动第三块,以此类推,也就是可以递推。由此我们可以归纳出所有的多米诺骨牌都可…...

模拟自然的本质:与IBM量子计算研究的问答
量子计算可能是计算领域的下一个重大突破,但它的一般概念仍然处于炒作和猜测的现状?它能破解所有已知的加密算法吗?它能设计出治愈所有疾病的新分子吗?它能很好地模拟过去和未来,以至于尼克奥弗曼能和他死去的儿子说话…...

Robot Operating System——带有时间戳和坐标系信息的多边形信息
大纲 应用场景1. 机器人导航场景描述具体应用 2. 环境建模场景描述具体应用 3. 路径规划场景描述具体应用 4. 无人机飞行控制场景描述具体应用 5. 机械臂运动控制场景描述具体应用 6. 自动驾驶车辆控制场景描述具体应用 定义字段解释 案例 geometry_msgs::msg::PolygonStamped …...

内网穿透(当使用支付宝沙箱的时候需要内网穿透进行回调)
内网穿透 一、为什么要使用内网穿透: 内网穿透也称内网映射,简单来说就是让外网可以访问你的内网:把自己的内网(主机)当做服务器,让外网访问 二、安装路由侠 路由侠-局域网变公网 (luyouxia.com) 安装成功如下: 三…...

Contact Form 7最新5.9.8版错误修复方案
最近有多位用户反应Contact Form 7最新5.9.8版的管理页面有错误如下图所示 具体错误文件的路径为wp-content\plugins\contact-form-7\admin\includes\welcome-panel.php on line 153 找到welcome-panel.php这个文件编辑它,将如下图选中的部分删除 删除以后…...

【第十一章:Sentosa_DSML社区版-机器学习之分类】
目录 11.1 逻辑回归分类 11.2 决策树分类 11.3 梯度提升决策树分类 11.4 XGBoost分类 11.5 随机森林分类 11.6 朴素贝叶斯分类 11.7 支持向量机分类 11.8 多层感知机分类 11.9 LightGBM分类 11.10 因子分解机分类 11.11 AdaBoost分类 11.12 KNN分类 【第十一章&…...

kafka3.8的基本操作
Kafka基础理论与常用命令详解(超详细)_kafka常用命令和解释-CSDN博客 [rootk1 bin]# netstat -tunlp|grep 90 tcp6 0 0 :::9092 :::* LISTEN 14512/java [rootk1 bin]# ./kafka-topics.s…...

如何检测并阻止机器人活动
恶意机器人流量逐年增加,占 2023 年所有互联网流量的近三分之一。恶意机器人会访问敏感数据、实施欺诈、窃取专有信息并降低网站性能。新技术使欺诈者能够更快地发动攻击并造成更大的破坏。机器人的无差别和大规模攻击对所有行业各种规模的企业都构成风险。 但您的…...

《linux系统》基础操作
二、综合应用题(共50分) 随着云计算技术、容器化技术和移动技术的不断发展,Unux服务器已经成为全球市场的主导者,因此具备常用服务器的配置与管理能力很有必要。公司因工作需要,需要建立相应部门的目录,搭建samba服务器和FTP服务器,要求将销售部的资料存放在samba服务器…...

EMT-LTR--学习任务间关系的多目标多任务优化
EMT-LTR–学习任务间关系的多目标多任务优化 title: Learning Task Relationships in Evolutionary Multitasking for Multiobjective Continuous Optimization author: Zefeng Chen, Yuren Zhou, Xiaoyu He, and Jun Zhang. journal: IEE…...

MySQL record 08 part
数据库连接池: Java DataBase Connectivity(Java语言连接数据库) 答: 使用连接池能解决此问题, 连接池,自动分配连接对象,并对闲置的连接进行回收。 常用的数据库连接池: 建立数…...
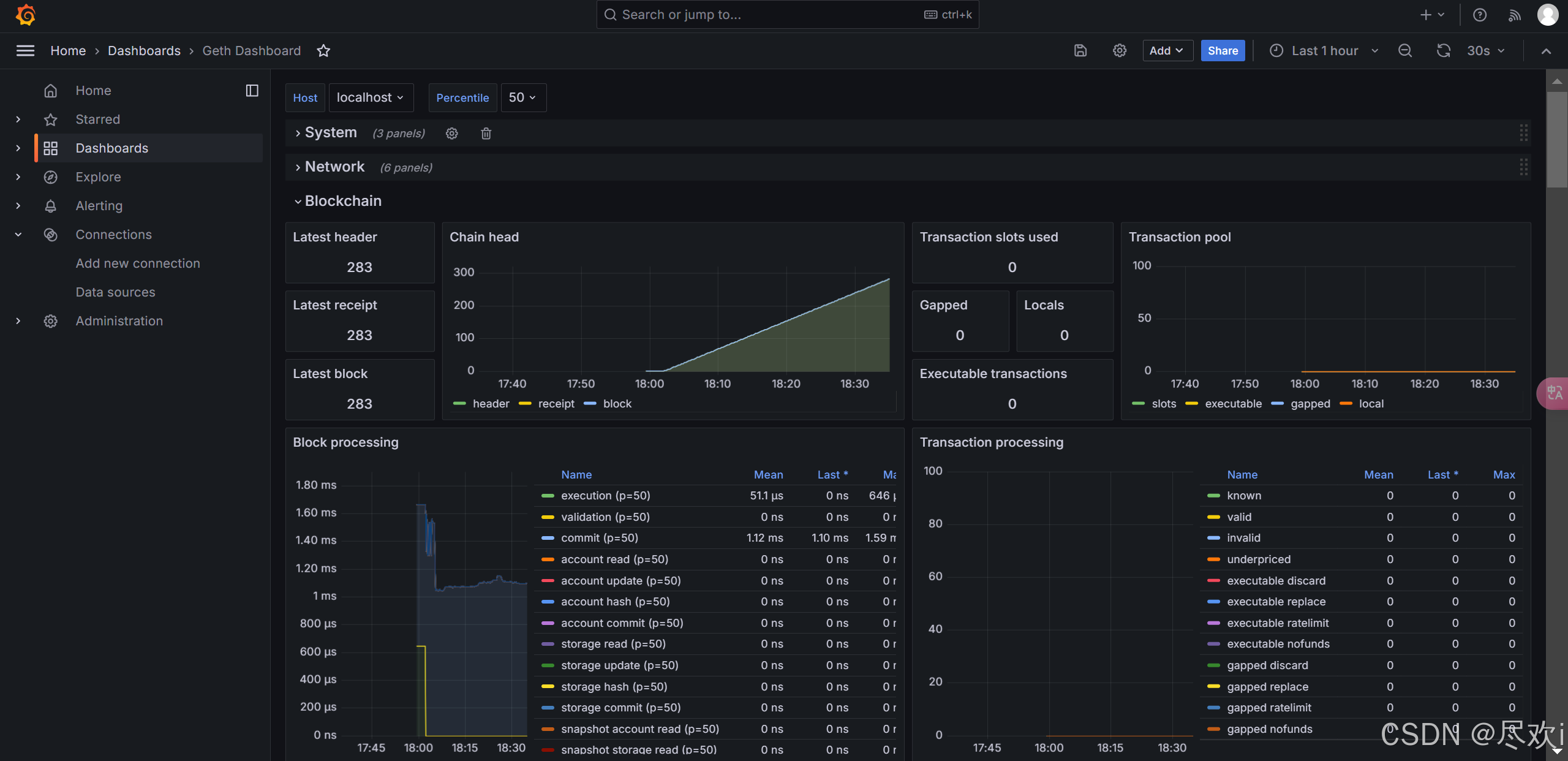
打造以太坊数据监控利器:InfluxDB与Grafana构建Geth可视化分析平台
前言 以太坊客户端收集大量数据,这些数据可以按时间顺序数据库的形式读取。为了简化监控,这些数据可以输入到数据可视化软件中。在此页面上,将配置 Geth 客户端以将数据推送到 InfluxDB 数据库,并使用 Grafana 来可视化数据。 一…...

对onlyoffice进行定制化开发
基于onlyoffice8.0源码,进行二次开发,可实现包括但不限于以下的功能 1、内容控件的插入 2、内容空间的批量替换 3、插入文本 4、插入图片 5、添加,去除水印 6、修改同时在线人数限制 7、内容域的删除 8、页面UI的定制化 9、新增插件开发 10、…...

使用llama.cpp 在推理MiniCPM-1.2B模型
llama.cpp 是一个开源项目,它允许用户在C中实现与LLaMA(Large Language Model Meta AI)模型的交互。LLaMA模型是由Meta Platforms开发的一种大型语言模型,虽然llama.cpp本身并不包含LLaMA模型的训练代码或模型权重,但它…...

分布式环境中,接口超时重试带来的的幂等问题如何解决?
目录标题 幂等不能解决接口超时吗?幂等的重要性什么是幂等?为什么需要幂等?接口超时了,到底如何处理? 如何设计幂等?幂等设计的基本流程实现幂等的8种方案1.selectinsert主键/唯一索引冲突(常用)2.直接insert 主键…...

设计一个推荐系统:使用协同过滤算法
设计一个推荐系统:使用协同过滤算法 在当今数据驱动的时代,推荐系统已经成为了许多在线平台(如电商、社交媒体和流媒体服务)不可或缺的一部分。推荐系统通过分析用户的行为和偏好,向用户推荐可能感兴趣的内容或产品。本文将详细介绍如何设计一个基于协同过滤算法的推荐系…...
Linux 基本指令(二)
目录 1. more指令 2. less指令(重要) 3. head指令 4. tail指令 5. date指令 (1)可以通过选项来指定格式: 编辑 (2)在设定时间方面 (3)时间戳 6. cal指令 7. find指令 8. grep指令 9. alias指令 10. zip指令与unzip指令 (1). zip指令 (2). unzip指令…...

从原理到实践:深入解析调频连续波雷达的核心技术与应用
1. 调频连续波雷达的基本原理 我第一次接触调频连续波(FMCW)雷达是在2015年做智能停车项目时。当时为了检测车位占用情况,试过超声波、红外等多种传感器,最后发现毫米波雷达才是最佳选择。FMCW雷达与传统脉冲雷达最大的区别在于它持续发射频率变化的电磁…...

数据分析篇---U型关系与与阈值效应
在数据科学、经济学和医学研究中,“U型关系”和“阈值效应”是两种非常经典且重要的非线性模式。它们描述的是变量之间并非简单的“越多越好”的直线关系,而是存在转折点。可以把线性关系想象成匀速开车,而U型和阈值效应则像是开车时遇到的上…...

Spire性能优化技巧:如何高效使用Rational和SafeLong提升Scala数值计算效率
Spire性能优化技巧:如何高效使用Rational和SafeLong提升Scala数值计算效率 【免费下载链接】spire Powerful new number types and numeric abstractions for Scala. 项目地址: https://gitcode.com/gh_mirrors/spi/spire Spire作为Scala的强大数值库&#x…...

CANN/asc-devkit LogSoftMax Tiling接口文档
LogSoftMax Tiling 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitc…...

今天开始学爬虫1
1.1:import urllib错误 module urllib has no attribute request应该import urllib.requestimport urllib.requesturlhttp://www.baidu.com/ responseurllib.request.urlopen(url) contentresponse.read().decode(utf-8) print(content)2.1#返回字节 contentrespons…...
)
Langchain的学习(一)
目录 一,实操 编码 Runnable Runnable 是什么 核心方法(所有 Runnable 都有) 最关键能力:用 | 组合(LCEL) 常用内置 Runnable 总结 二,聊天模型-核心能力 定义模型 init_chat_model 本地部署 调用工具 定义工具-Tool version1 schema: version2(基于…...

[题材选股] 商业航天、人形机器人双主线高位震荡,低位氟化工、光伏迎补涨机会!股票量化分析工具QTYX-V3.4.8
前言我们的股票量化系统QTYX在实战中不断迭代升级!!!分享QTYX系统目的是提供给大家一个搭建量化系统的模版,帮助大家搭建属于自己的系统。因此我们提供源码,可以根据自己的风格二次开发。关于QTYX的使用攻略可以查看链接:QTYX使用攻略QTYX一直…...

3分钟掌握视频下载:VideoDownloadHelper免费插件完全指南
3分钟掌握视频下载:VideoDownloadHelper免费插件完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾经遇到过这样的…...

座机号码认证支持哪些机型?固话企业认证覆盖华为/小米/OPPO/vivo等手机
很多做业务的朋友都有这种体会:好不容易联系到一个精准意向客户,电话拨过去,还没等开口,对方直接挂断。更有甚者,手机屏幕上赫然跳出“疑似推销”四个大字。现在的职场沟通,信任成本高得离谱。如果你还指望…...

C++11多线程与线程管理
一、线程基础 1.1 thread默认构造函数 std::thread::thread() _NOEXCEPT {_Thr_set_null(_Thr); }默认构造函数创建一个空线程对象,不关联任何执行线程。 1.2 thread带参数构造函数 explicit thread(Fn &&, Args &&...);可变参数模板,可…...