从手动测试菜鸟,到自动化测试老司机,实现自动化落地
虽然许多伙伴是一个测试老人了,但是基本上所有的测试经验都停留在手工测试方面,对于自动化测试方面的实战经验少之又少。

其实,究其原因:一方面是,自动化方面不求上进,觉得会手工测试就可以了,自动化就能躲就躲吧;另一方面是,觉得自动化是个慢慢积累的过程,不是那么容易学会的,既然不是那么学会的,那是不是......,就先不学了。(我估计大部分人都中枪了,哈哈)然后,就一拖再拖,能拖就拖,殊不知,自动化已经逐步成为测试领域必备的生存技能了。
所以,为了顺应测试行业发展的潮流,我就开始了从测试“原始人”到测试“现代人”的转变。(顺便说一下,想快速成长,有两个方面的因素也很重要,一方面想学习,是内因,感兴趣的事情,一般效率都会高很多;另一方面项目迫切需要,是外因,正所谓有压力才有动力)
考虑到python语言相对于大部分语言的语法简单,容易上手的特点,再加之python在自动化测试方面的广泛应用,我选择了python语言进行学习。
01 菜鸟是怎样炼成的
这一部分主要讲讲从一无所知到正式入门,Python从零开始学习的步骤.
1、基本语法的学习——打铁还需自身硬
首先,找一个适合零基础的学习网站,粗略过一遍python基本语法,推荐
https://www.sharetechnote.com/
https://www.runoob.com/python/python-tutorial.html
Str、List、dict、set、loop、if等等,这些都是最最基本的语法知识。
需要注意的是,学习教程中的练习实例,一定要一步一步跟着敲下来,这样学习效果最佳。
等到基本语法学的差不多了,就可以直接进入实战阶段了。
需要特别指出的是,没有必要在语法方面反复看,看过一遍基础就可以了,看再多遍也只是纸上谈兵,重要的还是通过实战来巩固前面学习到的知识,也更加深对语法的使用技巧的理解。
2、项目实战——上阵练兵
有了一些语法基础之后,接下来要结合项目,实现一些自动化功能。或者,如果没有合适的项目进行练习,给自己定一个目标作为项目,限定时间,实现一定的功能需求
我学习python的时候,由于项目中有一个几乎是日常需要做的事情,比较适合进行自动化,提高工作效率。
具体需求是这样的。从客户返回的产品日志log中提取关键信息,然后以固定的模板填写excel表格,回传给客户。再详细一点呢,就是从txt多个文件和excel文件中,提取某些数据的值,填写到表格中,便于做问题定位和分析,其中涉及到平均值,最大值,同时涉及到几种固定的类别(就不更具体了,免得读者对号入座,联想到自己身边的同事~~)
接下来我就来说说,我是如何完成这个项目的。

第 1 则
-THE FIRST-
程序初版面世:
通过日夜奋战,到处求医问药,搞定功能
第一步
最开始,从待处理的txt文件出发,先实现一些特点比较明显的,看起来比较简单的数据处理,比如搜索含有特定的关键字的所有行,然后,取这些行中某一特定位置的值,然后计算这些值的平均值。
大体思路是:
1、 遍历txt文件中所有的行
2、然后通过关键字搜索
3、 搜索到的行,通过一定的字符进行分割,然后存为list
4、按照list下标取值,然后把所有的值加起来求和,再除以个数
虽然我知道这个方法不是最聪明最快的,但是我知道它是我当前的水平能做到的一种方法,至少能实现功能,满足项目需求。
这个阶段学习到的方法是:
open()打开文件
readlines()读取行
find()找到关键字,后来发现find只能找到一次,并且返回值是所在的位置,不方便,随后改为使用if X in Y来实现了 re.split。
这个阶段,用到的基础知识点是list,for循环,str
第二步
随后,另一个需求随之而来,我上面计算出来的值,得想个办法存下来,等自动化执行完之后,好去统计,然后填表。
因此,我想了一个办法:把重要数据print出来,然后把执行的log保存下来(从网上找的方法),然后人工进行查看和填表。
这个阶段学习到的方法是:
class类
write写文件
第三步
后来发现,这种方法的工作效率貌似有点低,明明是很高大上的自动化,怎么成了半自动化了?
所以,我想到的是,把计算出来的数据,保存成表格,然后去表格里查看,就不用从茫茫执行记录里边去找了。
这个阶段学习到的方法是:
读EXCEL的模块xlrd
写EXCEL的模块xlwt
第四步
最初生成的表格,基本上是几个类似的数据就生成一个EXCEL,其他类似的再生成一个EXCEL。所以,如果一旦填写的数据有上百个(这个项目就是这种情况),那差不多也要10几个甚至20多个表格。
因此,我的想法是,能不能把这些生成的数据统统生成到一个表格里,然后再去这个表格里去找我需要的数据。
有了这个想法之后,我的想法就不止停留在了这个层面了。而是,既然我打算自动生成数据到统一的一个表格里边,然后去取数据,再填到我的结果表格里边,那不如一步到位,通过程序直接把计算出来的结果,填到我创建的结果模板表格里边,实现计算---填表全自动化。
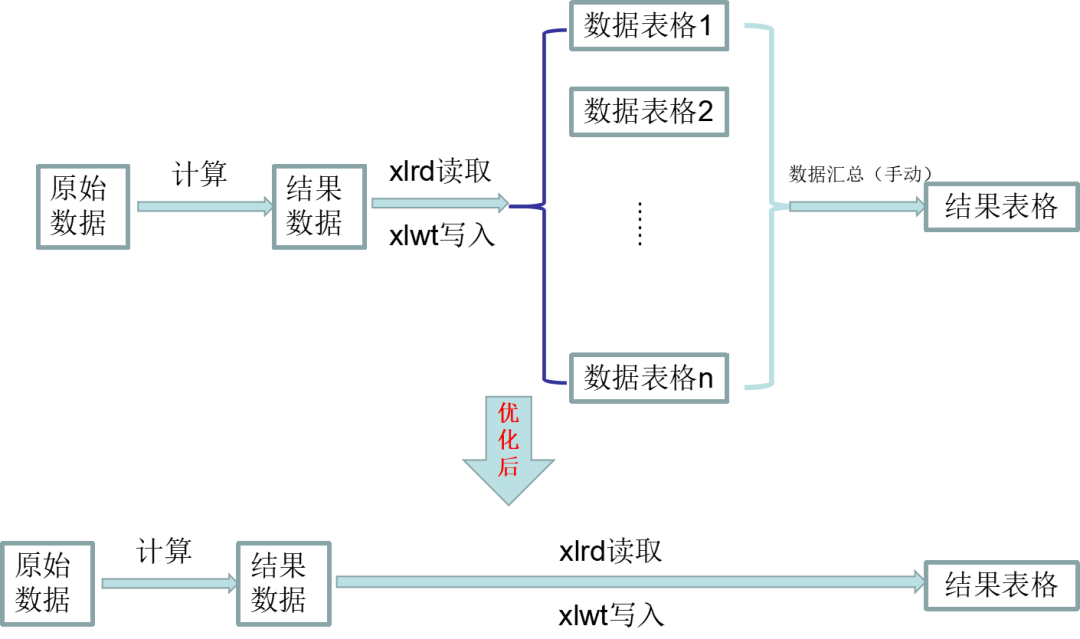
这个阶段用到的主要方法是仍然是读EXCEL的模块xlrd和写EXCEL的模块xlwt,不过,改变了一下这两种方法的用途,原来只用于把txt提取的数据存下来备用,现在直接用于写入最终的结果表格中。
第五步
需要特别指出的是,经过上面几个过程之后,所有的txt部分的需求才终于实现了,但是EXCEL数据读取、计算还没有进行。所以,接下来的主要目标,就是实现EXCEL表格的数据统计。
我首先想到的方法是,获取Excel的单元格的值,然后进行计算。有了之前txt数据的类似的经验,只要解决了如何获取单元格的值,就能实现此功能。
这个阶段,我学习到的方法是cell().value,取单元格的值。
第 2 则
-THE SECOND-
程序优化改版:
通过试用和代码审查,优化代码
至此,需要实现的需求都一步一步的通过探索实现了。
但是,由于时间紧迫,第一版代码以自己最容易hold住的方式实现功能,没有特别去思考是否最优方案,所以,此时的代码只能用“水”来形容。
所以,接下来我做的是:
一方面:推广试用
让同事们试用我的代码,发现一些明显的问题,事实证明,实践是检验真理的唯一标准。试用过程中,发现的问题见python学习和工具试用过程中遇到的问题部分
另一方面:代码检视
1)算法优化
在让团队成员试用工具的同时,重新审视自己的代码,寻找优化点。首先是算法方面的优化。
①提取代码逻辑完全相同的复制粘贴的代码,使用for循环进行结构简化。示意图如下:

②对于代码逻辑类似的,可酌情通过自定义函数库,来进行调用,这样可以使代码更加简洁,逻辑更加清晰。
例如,查找文件夹下的文件;通过一定的关键字搜索txt文件的所有行,然后把找到的行切割,然后取出需要的列,形成列表,最后形成dataframe,便于计算平均值等
③寻找内置库或者第三方库中是否有更简便的方法,替代代码中一坨代码实现的功能
例如,计算平均值用mean()替代求和后再除以数量
![]()
③用dataframe的groupby和value_counts()方法来输出一坨数据中,
![]()
可以说,代码优化的过程,更是一个各方面飞速进步的过程。
2)效率及易用性优化
除了上面的代码结构和调用的模块方法的优化,审视代码过程中,还识别出了一些执行效率和易用性方面的需求:
① 控制循环中某一分支执行次数,获取到一次数据之后,就停止循环。

②将log打印信息以一定的颜色输出,方便提示用户一些重要的文件存储信息。
![]()
3)可靠性优化
除了效率和易用性方面,在这个项目过程中,也识别出了可靠性方面的需求。例如,存放txt文件名的list,优化之前是通过动态获取目标路径下的所有txt,然后通过list下标来取,这种方法最大的问题是,如果目标路径下有多余的txt,则用下标可能取的不对
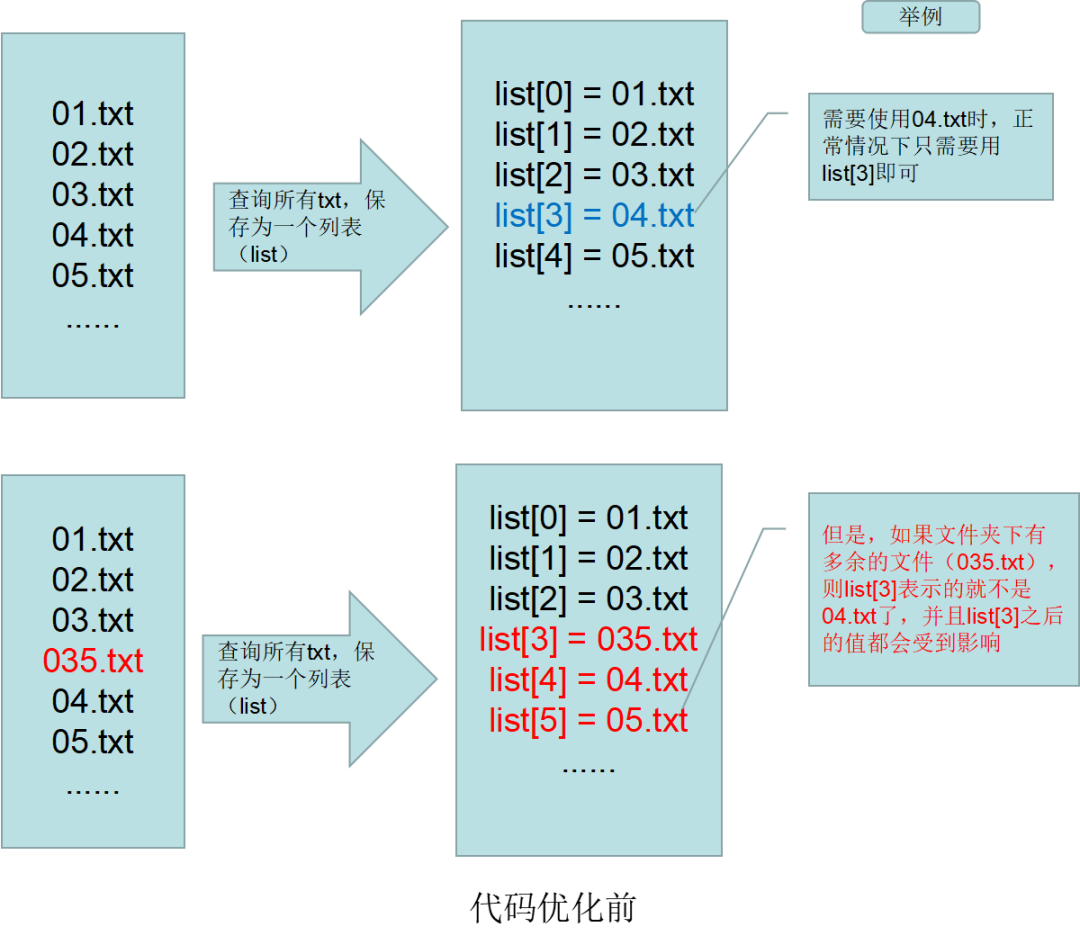
优化后,将待处理的文件,通过文件名进行关键字搜索,如果搜索到,则统一放到新建的文件夹下,并重命名为固定的文件名,这样做可以保证后面调用文件列表的时候,一定是我需要的,不会取错 。
02 python学习和工具试用过程中遇到的问题
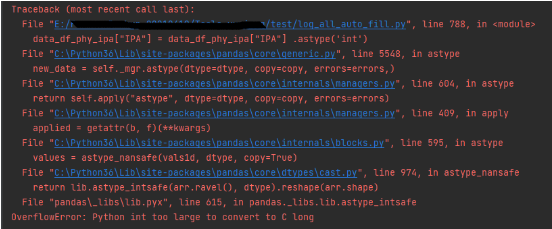
1、int越界
File "pandas\_libs\lib.pyx", line 615, in pandas._libs.lib.astype_intsafe
OverflowError: Python int too large to convert to C long
大体意思就是:溢出错误,Python int太大,无法转换为C long
python的int是没有上限的,但是C有,如果传入参数大于C语言的int上限就会出错。
解决方案:
把data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('int')
改为data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('int64')
或data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('float')
遇到此类问题,其他参考方案是:
修改算法,不用这个c写的函数。
升级python版本,有的时候这个错误是python2的,将python升级为3。
2、重命名文件或文件夹时,提示已存在,异常结束执行
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件
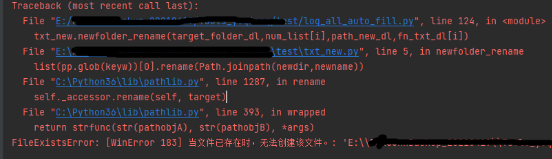
解决方案:
对目标文件夹或文件做判空处理
if not Path.exists(Path.joinpath(newdir,newname))
3、使用round方法时,提示错误
AttributeError: 'float' object has no attribute 'round'

错误提示:AttributeError: ‘float’ object has no attribute ‘round’
方案一:
该错误是由于numpy库版本较低导致的,需要更新numpy库至最新版本
pip install --upgrade numpy更新时需要保证pip版本比较新,否则会提示pip版本更新较低更新失败
python3 -m pip install --upgrade pip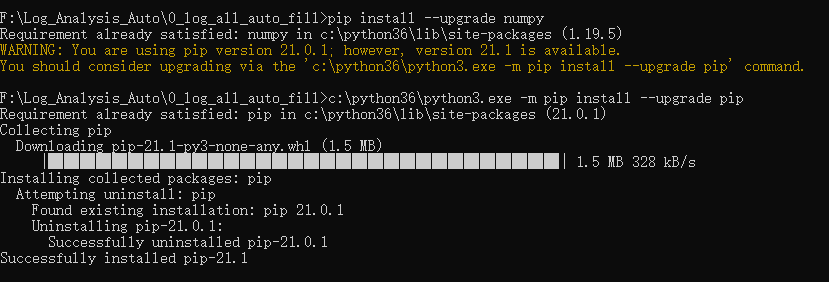
F:\Log_Analysis_Auto\0_log_all_auto_fill>pip install --upgrade numpy
Requirement already satisfied: numpy in c:\python36\lib\site-packages (1.19.5)
WARNING: You are using pip version 21.0.1; however, version 21.1 is available.
You should consider upgrading via the 'c:\python36\python3.exe -m pip install --upgrade pip' command.
F:\Log_Analysis_Auto\0_log_all_auto_fill>c:\python36\python3.exe -m pip install --upgrade pip
Requirement already satisfied: pip in c:\python36\lib\site-packages (21.0.1)
Collecting pip
Downloading pip-21.1-py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 328 kB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 21.0.1
Uninstalling pip-21.0.1:
Successfully uninstalled pip-21.0.1
Successfully installed pip-21.1
方案二:
如果方案一解决不了问题,请
如下这种格式的代码
rb_s2 = df[df['Cell']=='SCC2'].RB.mean().round(2)
修改为:
rb_s2 = round(df[df['Cell']=='SCC2'].RB.mean(),2)
4、提示含有gbk或者utf-8解码错误的报错
原因:
这种情况是因为txt文件没有存为utf-8 无bom格式
解决方案:
Ultra edit打开txt文件,然后另存为格式选择“UTF-8-无BOM”
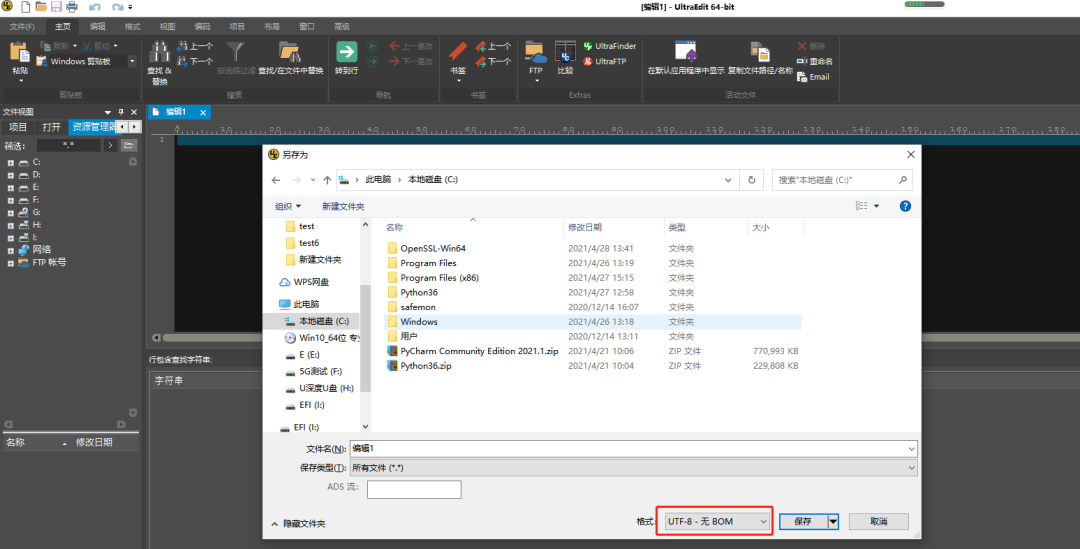
5、提示无权限Permission denied:
PermissionError: [Errno 13] Permission denied:
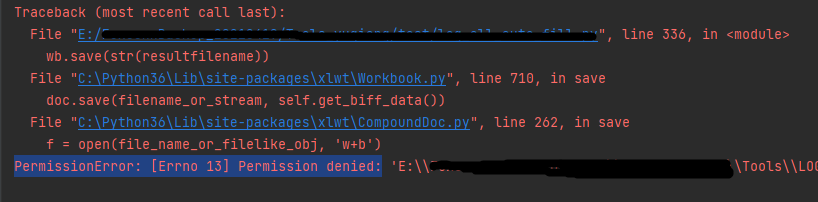
原因:
程序执行完成之前,需要读写的文件不能打开,否则会读写冲突,执行终止
解决方案:
程序执行过程中,不要打开文件
6、invalid literal for int() with base 10
报错:ValueError: invalid literal for int() with base 10
原因:
原因为参数有误,int()函数可以把数字字符串转化成int类型的数字,但是不能传入非数字的字符串
解决方案:
非数字字符串改成数字字符串
03 python学习总结
1、处理数据pandas库的dataframe比较强大
数据被DataFrame了之后,就像是操作EXCEL表格中的数据一样,只要你敢想,它就敢做。就我目前用到的DataFrame功能,我总结如下:
统计均值
统计最大值
统计哪个值最多
整列删除
筛选数据
整列合并
DataFrame的功能远远不止这些,感兴趣的小伙伴可以自行学习
2、对于读写EXCEL的方法,有如下的总结:
openpyxl可以处理xlsx文件和XLSM文件,可以写入单页sheet超过65535行,可以同时读写Excel;xlrd、xlwt只能处理xls,最大可以写65535行的表格。
不过,如果EXCEL表格的数据量不是很大时,还是建议使用xlrd、xlwt套装。
04 后记
最后,一些Python学习心得分享给大家,希望对大家有所帮助。
自动化脚本写作,重在实战
潜力是逼出来,有压力才有动力
写代码之前最好先构思好代码逻辑,躺石头过河的笨方法只适合初学者,并且后期维护成本较高,返工的概率也高一些
Python编码选模块很重要,选对模块事半功倍
希望本文能够帮助那些“原始人”快速“进化”为“现代人”,或者对那些已经成为“现代人”有一些启发。
我下一步的计划是,学习和实践Python+Selenium的自动化框架,我将在后续的文章中把我的学习心得分享给大家,敬请关注。

相关文章:
从手动测试菜鸟,到自动化测试老司机,实现自动化落地
虽然许多伙伴是一个测试老人了,但是基本上所有的测试经验都停留在手工测试方面,对于自动化测试方面的实战经验少之又少。 其实,究其原因:一方面是,自动化方面不求上进,觉得会手工测试就可以了,自…...

docker zookeeper集群启动报错:Cannot open channel to * at election address /ip:3888
下面几点需要注意的: 1、确认在每个$zookeeper_home/data/myid中有对应数字 2、是否关闭防火墙:systemctl stop firewalld,systemctl disable firewalld 3、zoo.cfg中的server需要写成以下形式的: 假如有两台机器,1…...

【Linux探索学习】第一弹——Linux的基本指令(上)——开启Linux学习第一篇
前言: 在进入Linux学习之前,我们首先要先做好以下两点:1、已经基本掌握C语言或C,2、已经配置好了Linux的环境,做完以上两点后我们就开始Linux的学习,今天我们首先要学习的就是Linux中最基础的操作ÿ…...

3.Vue2结合element-ui实现国际化多语言i18n
1.安装vue-i18n npm install vue-i18n8.2.1说明:Vue2使用vue-i18n是8.x,Vue3使用的版本是9.x以上,使用错了会导致报错 2.创建多语言文件 在src/下创建src/lang/langs/zh.js和src/lang/langs/en.js两个文件,里面内容如下&#x…...

整数二分算法和浮点数二分算法
整数二分算法和浮点数二分算法 二分 现实中运用到二分的就是猜数字的游戏 假如有A同学说B同学所说数的大小,B同学要在1~100中间猜中数字65,当B同学每次说的数都是范围的一半时这就算是一个二分查找的过程 二分查找的前提是这个数字序列要有单调性 基…...

智能回收箱的功能和使用步骤介绍
智能回收箱是现代城市环保与资源循环利用领域的一项创新技术,它通过集成各种智能化功能,提高了垃圾回收的效率和准确性,促进了垃圾分类与减量。随着全球对环境保护意识的增强和智慧城市概念的推广,智能回收箱的发展前景非常广阔&a…...

Remix在SPA模式下,出现ErrorBoundary错误页加载Ant Design组件报错,不能加载样式的问题
Remix是一个既能做服务端渲染,又能做单页应用的框架,如果想做单页应用,又想学服务端渲染,使用Remix可以降低学习成本。最近,在学习Remix的过程中,遇到了在SPA模式下与Ant Design整合的问题。 我用Remix官网…...

ADB ROOT开启流程
开启adb root 选项后,执行如下代码: packages/apps/Settings/src/com/android/settings/development/AdbRootPreferenceController.java mADBRootService new ADBRootService(); Override public boolean onPreferenceChange(Preference preference…...

传输层协议 —— TCP协议(上篇)
目录 1.认识TCP 2.TCP协议段格式 3.可靠性保证的机制 确认应答机制 超时重传机制 连接管理机制 三次握手 四次挥手 1.认识TCP 在网络通信模型中,传输层有两个经典的协议,分别是UDP协议和TCP协议。其中TCP协议全称为传输控制协议(Tra…...

YOLOv8改进,YOLOv8的Neck替换成AFPN(CVPR 2023)
摘要 多尺度特征在物体检测任务中对编码具有尺度变化的物体非常重要。多尺度特征提取的常见策略是采用经典的自上而下和自下而上的特征金字塔网络。然而,这些方法存在特征信息丢失或退化的问题,影响了非相邻层次的融合效果。一种渐进式特征金字塔网络(AFPN),以支持非相邻…...

学习大数据DAY59 全量抽取和增量抽取实战
目录 需求流程: 需求分析与规范 作业 作业2 需求流程: 全量抽取 增量抽取 - DataX Kettle Sqoop ... 场景: 业务部门同事或者甲方的工作人员给我们的部门经理和你提出了新的需 求 流程: 联系 > 开会讨论 > 确认需求 > 落地 需求文档( 具体…...

YOLOv8——测量高速公路上汽车的速度
引言 在人工神经网络和计算机视觉领域,目标识别和跟踪是非常重要的技术,它们可以应用于无数的项目中,其中许多可能不是很明显,比如使用这些算法来测量距离或对象的速度。 测量汽车速度基本步骤如下: 视频采集&#x…...

在线相亲交友系统:寻找另一半的新方式
在这个快节奏的时代里,越来越多的单身男女发现,传统意义上的相亲方式已经难以满足他们的需求。与此同时,互联网技术的迅猛发展为人们提供了新的社交渠道——在线相亲交友系统作者h17711347205。本文将探讨在线相亲交友系统如何成为一种寻找另…...

MySQL 中存储过程参数的设置与使用
《MySQL 中存储过程参数的设置与使用》 在 MySQL 数据库中,存储过程是一组预先编译好的 SQL 语句集合,可以接受参数并返回结果。使用存储过程可以提高数据库的性能和可维护性,同时也可以减少网络流量和代码重复。那么,如何在 MyS…...

2k1000LA 调试HDMI
问题: 客户需要使用HDMI 接口,1080p 的分辨率。 ---------------------------------------------------------------------------------------------------------------- 这里需要看看 龙芯派的 demo 版 的 硬件上的连接。 硬件上: 官方的demo 板 , dvo1 应该是 HDMI的…...

24年蓝桥杯及攻防世界赛题-MISC-1
2 What-is-this AZADI TOWER 3 Avatar 题目 一个恐怖份子上传了这张照片到社交网络。里面藏了什么信息?隐藏内容即flag 解题 ┌──(holyeyes㉿kali2023)-[~/Misc/tool-misc/outguess] └─$ outguess -r 035bfaa85410429495786d8ea6ecd296.jpg flag1.txt Reading 035bf…...

前端项目代码开发规范及工具配置
在项目开发中,良好的代码编写规范是项目组成的重要元素。本文将详细介绍在项目开发中如何集成相应的代码规范插件及使用方法。 项目规范及工具 集成 EditorConfig集成 Prettier1. 安装 Prettier2. 创建 Prettier 配置文件3. 配置 .prettierrc4. 使用 Prettier 集成 …...
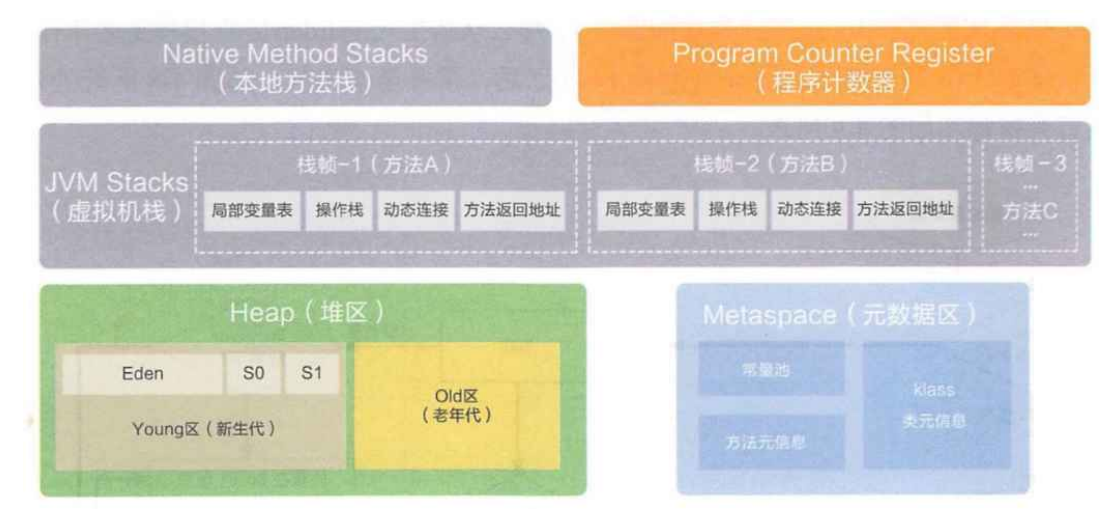
【JVM】JVM执行流程和内存区域划分
文章目录 是什么JVM 执行流程内存区域划分堆栈程序计数器元数据区经典笔试题 是什么 Java 虚拟机 JDK,Java 开发工具包JRE,Java 运行时环境JVM,Java 虚拟机 JVM 就是 Java 虚拟机,解释执行 Java 字节码 JVM 执行流程 编程语言…...
Python | 读取.dat 文件
写在前面 使用matlab可以输出为 .dat 或者 .mat 形式的文件,之前介绍过读取 .mat 后缀文件,今天正好把 .dat 的读取也记录一下。 读取方法 这里可以使用pandas库将其作为一个dataframe的形式读取进python,数据内容格式如下,根据…...

信息技术的变革与未来发展的思考
信息技术的变革与未来发展的思考 在21世纪,信息技术(IT)正在以前所未有的速度推动社会、经济、文化的深刻变革。无论是人工智能、大数据,还是云计算、物联网,信息技术的发展已经渗透到了各个行业,彻底改变…...

高速SerDes技术解析:从差分传输到时钟恢复的硬件设计实战
1. 从并行到串行:高速通信的基石SerDes在数字电路的世界里,数据最初大多以并行的形式存在,比如我们熟悉的32位或64位数据总线。但当我们需要把数据从一个芯片发送到另一个芯片,或者从一块电路板传到另一块,尤其是在高速…...

思科CCNA认证备考:从题库到实战,这11个章节的易错点你踩过几个?
思科CCNA认证通关指南:11大核心章节的深度避坑策略 从题库到实战的认知跃迁 当您翻开CCNA的备考资料时,是否曾感到困惑——即使熟记题库答案,在实际操作和模拟考试中仍频频出错?这种现象在认证考生中极为普遍。问题的根源往往不在…...
)
ElevenLabs语音克隆效果翻倍秘技(实测SSML+声纹嵌入+噪声抑制三重优化)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆效果翻倍秘技(实测SSML声纹嵌入噪声抑制三重优化) ElevenLabs 的语音克隆能力虽强,但原始 API 调用常因语调扁平、背景干扰与韵律失真导致真实感不…...
)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战) 在Java开发中,生成随机字符串的需求无处不在——从用户邀请码、临时密码到订单编号,我们经常需要快速生成一串既随机又可读的字…...
)
TVA智能体范式的工业视觉革命(10)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

MySQL 跑得稳不稳,Prometheus 得能抓到这个数据才能说清楚
前言 数据库出问题的时候,最怕的不是故障本身,而是故障发生了却没人知道,等用户反馈过来才去翻日志,慢了不止一拍。 MySQL 本身有一些状态变量能反映运行状况——连接数、QPS、缓冲池命中率、慢查询数量——但这些数据要么存着没…...

VScode:将VScode界面的显示语言改为简体中文
这是 VS Code 设置语言的标准方式,直接强制指定界面语言: 在 VS Code 界面按下快捷键 Ctrl Shift P(Windows/Linux),Mac 用户用 Cmd Shift P,打开「命令面板」 在弹出的输入框里,输入 Confi…...

为什么92%的康复科博士生还没用NotebookLM做系统评价?——2024年最新工具链适配白皮书首发
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在康复医学研究中的范式革命 传统康复医学研究长期受限于多源异构数据整合困难、临床证据转化周期长、跨学科知识对齐成本高等瓶颈。NotebookLM 以“以文献为中心”的可溯源推理架构…...

基于OpenCV与MediaPipe的手势与头部姿态控制鼠标实现
1. 项目概述:解放双手的鼠标控制新范式最近在GitHub上看到一个挺有意思的项目,叫ShafwanAbd/handsfree-mouse。顾名思义,这是一个“免提鼠标”项目,核心目标是通过摄像头捕捉你的手势或头部动作,来替代传统的物理鼠标&…...

MATLAB浮动许可利用率低:软件许可浪费,提高周转率
说实话,MATLAB浮动许可利用率低这个问题,我真的被老板问爆了。咱们实验室有50个许可,但系统显示平均不到20%在用,剩下的40%天天躺在服务器上吃灰。这事儿让我悟了:软件许可不是你买了就赚了,它要像现金流一…...