B-树(不是B减树)原理剖析(1)
目录
B树的主要特性:
B树的操作:
B树的优点:
为什么要发明出B-树?
B树的概念和原理剖析
原理图讲解(部分讲解在图中)
初始化结点:
处理数据数量计算(了解)
底层代码实现(加深理解)
前些日子我们学了AVl树,红黑树感受到了搜索树在底层和实际应用的广泛和其规则的复杂性,今天我们继续学习一下原理也是搜索树的B-树。
B树是一种自平衡的树数据结构,常用于实现数据库和文件系统的索引。它的设计目的是保持数据有序,并允许高效的插入、删除和搜索操作。B树的特点是它的节点可以包含多个子节点,而不是像二叉树那样每个节点只有两个子节点。这样可以减少树的高度,从而减少查找和更新操作的时间复杂度。
B树的主要特性:
-
有序性:B树中的所有节点按升序排列,这使得查找非常高效。每个节点包含一个键值的有序列表,以及指向其子节点的指针。
-
多子节点:与二叉树不同,B树中的每个节点可以有多个子节点。节点中的键值和子节点之间有一定的关系:子节点中的值总是介于父节点键值之间。
-
平衡性:B树是平衡树,它通过在插入和删除时重新分布节点的键值,确保树的所有叶节点都位于同一层级上。因此,查找的时间复杂度始终为 O(log n),其中 n 是树中的键值总数。
-
分支因子:B树的分支因子(通常称为阶数,order)决定了每个节点可以有多少个子节点。一个阶数为 mmm 的 B 树,意味着每个节点最多可以有 m−1m-1m−1 个键和 mmm 个子节点。
-
高效磁盘访问:由于每个节点可以存储多个键和指针,B树减少了对磁盘的访问次数。因此,B树在数据库管理系统和文件系统中广泛应用,特别适用于处理大量需要存储在外存(如硬盘)上的数据。
B树的操作:
-
查找:查找操作从根节点开始,逐层深入,通过比较键值找到目标元素。每次查找时,最多需要访问树的高度层数,这使得查找效率较高。
-
插入:插入时,首先通过查找找到应插入的位置,然后将新键值插入到合适的节点中。如果节点已满,节点会被拆分,部分键值上移到父节点中。
-
删除:删除操作更为复杂,如果直接删除某节点会导致树失衡,因此可能需要将相邻节点的键值重新分配,或者将节点合并以保持树的平衡性。
B树的优点:
- 高效的插入、删除、查找操作,特别是在处理大量数据时。
- 保证树的高度始终较低,从而减少操作的复杂度。
- 适用于外存系统的索引结构,因为它减少了对磁盘的访问次数。
常见的改进版本包括 B+(B加)树,它在叶节点中包含所有的数据,并使用顺序链表链接叶节点,从而提高了范围查询的效率。
为什么要发明出B-树?
其实B-树最初被发明出来是为了解决磁盘上读取数据普遍较慢的问题。B-树即使用于内查找也适用于外查找。

这里有人就有意见了呀,为什么别的数据结构不行,偏偏要选择B-呢?

首先,由于磁盘数据过多,假设需要查找磁盘里10亿个值,我们可以看到以上图不同的数据结构的时间复杂度可以看出,最优的就是哈希和平衡二叉树的那两个,AVl树比红黑树相对选择条件更严格,所以选择AVl树,那也需要logn次,也就是说10亿个数据就是30次可以查完,虽然已经很短了,但是磁盘的访问速度太慢了,30次还是显得太多了。
那使用哈希表行不行呢,虽然时间复杂度为o1,但是由于会产生负面的哈希冲突问题,所以比较难以处理多个数据重复映射到同一个位置,比较麻烦!!!
由于磁盘一般不存在空间不足的问题,所以即便使用位图和布隆过滤器也是没有用的。
下面有更清晰的解释可供参考:

所以最大的问题就是磁盘自己本身访问数据太慢了,需要将次数降至个位数才行,于是由于之前的搜索二叉树都是二叉的(一个根最多只有2个孩子节点),所以这里要想提高速率只能降低树的高度,增加根节点的孩子个数(变成多叉)。
就这样B树就诞生了!!!
B树的概念和原理剖析
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树 (后面有一个B的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一 棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
1. 根节点至少有两个孩子//为了增加叉数而设置的
2. 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
3. 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
4. 所有的叶子节点都在同一层
5. 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划 分 6. 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键 字,且Ki。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的 关键字均小于Ki+1。 n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。

解析开始:我们可以看到这个B树的规则还是比较复杂的。先理清楚几个概念
关键字:就是每一层的节点个数(相当于根)
孩子:就是每个关键字所引出的节点(相当于根的子节点)
从2,和3规则可以看出B树是多叉搜索树,如果阶数m为10,那关键字最少为4,最多为9,孩子最少为5,最多为10,并且可以看出,每层的关键字的个数总比其孩子节点少1,说明有一个孩子必定同时是两个相邻的关键字的孩子。
第5条规则体现了其仍为搜索树,需要按从大到小排列关键字才可以在后面分裂后通过取中位数的方式取到新的关键字(根)
说到分裂,由于规则3,每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m,所以每行的关键字个数最多为阶数-1,当插入的关键字的个数等于阶数m时,就需要进行分裂,分裂具体是怎么样的后面会体现。
原理图讲解(部分讲解在图中)

由于我们这边设的阶数为m = 3,但是我们必须给每行的关键字m个空间,因为如果只给2个(对于m ==3来说,每行关键字最多为2)就无法判断是否关键字等于m,是否需要分裂,因为第3个数无法插入了,多开一个空间方便判断,磁盘很大的不差那一个空间!
刚开始插入时,由于还没有明显的头结点,需要通过不断插入关键字来完成第一次分裂产生,这也比较符合先利用已经开辟好的空间的逻辑


当第一次分裂完成后会产生一个新的单个头节点,之后我们在插入节点的时候必须从叶子节点开始插入,这样才不会剖坏之前已经插入的节点的位置,因为B树仍然是搜索树。从上图也证明了一个结点可能会成为两个根的孩子的理论,所以B树中根节点的个数不是其孩子的两倍,因为根据图可以看出有些孩子被重复利用了,且根节点是通过子节点分裂产生的。
分裂引起的根的移动,需要连同着其孩子节点一起移动。种种异样表明B树的设计完全是为了插入数据的方便,不是为了保持平衡而设计的,所以和其他的搜索树不太一样。
这里关键是画图出来,一下展示我画的图:

初始化结点:
根据规则6和演示图解就可以很轻松的得出,每个结点的构造。

由于每个结点是有可能形成多叉的,且一个结点可能会成为两个根的孩子,所以一个结点会先有一个存放关键字的数组,然后为了访问其孩子,还需要一个存有指向此根的全部孩子的指针数组(这里不是单纯的左右指针那么简单了,因为孩子有点多),另外根据上图还需要一个变量n统计关键字的个数(就是当层的结点数),由于我们之前的搜索树都还有一个指向其父亲结点的指针,所以这里也可以考虑加入。
struct BTreeNode
{
//K _keys[M - 1];
//BTreeNode<K, M>* _subs[M];
// 为了方便插入以后再分裂,多给一个空间
K _keys[M];//关键字(本行节点)
BTreeNode<K, M>* _subs[M+1];//子节点(快速连串访问,体现树结构)
BTreeNode<K, M>* _parent;//父亲节点,体现原本三叉链的本质结构
size_t _n; // 记录实际存储多个关键字
};
处理数据数量计算(了解)
实际情况运用B树时,阶层通常会很大(B树阶层越大处理的节点数(关键字)就越多数据量就越大),所以我们以下定义形成一个1023阶层的4层的B树。
根据规则,那么每个分支的关键字数最多就为m - 1 = 1023,其孩子为m等于1024,根据下图的逐层推算可以得出每行的关键字和孩子节点的个数。可以看出B树成功的通过压缩了高度同时存储了更多的数据

底层代码实现(加深理解)
欲知后事如何,请听下文分解!!!持续关注博主以解锁B树更多秘密!!!
相关文章:
B-树(不是B减树)原理剖析(1)
目录 B树的主要特性: B树的操作: B树的优点: 为什么要发明出B-树? B树的概念和原理剖析 原理图讲解(部分讲解在图中) 初始化结点: 处理数据数量计算(了解) 底层代码实现(加深理解) 前些日子我们学了AVl树&…...

【shell脚本8】Shell脚本学习--其他
目录 编辑 Shell输入输出重定向 重定向深入讲解 Here Document Shell输入输出重定向 Unix 命令默认从标准输入设备(stdin)获取输入,将结果输出到标准输出设备(stdout)显示。一般情况下,标准输入设备就是键盘,标准输出设备就是终端&…...

《深度学习》ResNet残差网络、BN批处理层 结构、原理详解
目录 一、关于ResNet 1、什么是ResNet 2、传统卷积神经网络存在的问题 1)梯度消失和梯度爆炸问题 2)训练困难 3)特征表示能力受限 4)模型复杂度和计算负担 3、如何解决 1)解决梯度问题 BN层重要步骤: 2…...
)
javadoc:jdk 9通过javadoc API读取java源码中的注释信息(comment)
几年前写过一博客:《java:通过javadoc API读取java源码中的注释信息(comment)》,简单介绍了通过javadoc API读取源码注释的流程。 那时还是用JDK 1.8。但是在JDK9环境下JDK 1.8的那一套API就不能用了。JDK 9提供了一套新的javadoc API实现注释代码的读取…...

nordic使用FDS保存数据需要注意的地方
FDS使用常见问题 大家在使用FDS模块时,经常碰到的问题有如下几种: FDS不支持掉电保护,所以在Flash操作过程中出现了掉电,FDS行为将未知OTA的时候,新固件的FDS page数目一定要等于老固件的FDS page数,否则将出现不可知行为fds_record_write或者fds_record_update后,强烈…...
环境搭建与使用)
docker-compose集群(单机多节点)环境搭建与使用
此方案已经经过生产环境验证,可放心大胆使用如果喜欢,欢迎点赞👍收藏❤️评论噢~ 略去 Docker 和 Docker Compose 安装部分,如果有需要的同学,可以评论,创建 docker-compose.yml 文件并配置 Nacos 集群和 M…...

从静态多态、动态多态到虚函数表、虚函数指针
多态(Polymorphism)是面向对象编程中的一个重要概念,它允许不同类的对象对同一消息做出不同的响应。多态性使得可以使用统一的接口来操作不同类的对象,从而提高了代码的灵活性和可扩展性。 一、多态的表现形式 1. 静态多态&…...

用 Pygame 实现一个乒乓球游戏
用 Pygame 实现一个乒乓球游戏 伸手需要一瞬间,牵手却要很多年,无论你遇见谁,他都是你生命该出现的人,绝非偶然。若无相欠,怎会相见。 引言 在这篇文章中,我将带领大家使用 Pygame 库开发一个简单的乒乓球…...

基于大数据可视化的化妆品推荐及数据分析系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码 精品专栏:Java精选实战项目…...

Java项目实战II基于Java+Spring Boot+MySQL的汽车销售网站(文档+源码+数据库)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 在数字化时…...

数学基础 -- 微积分最优化之一个最简单的例子
微积分中的一个最简单的最优化例子 问题描述 假设你有一条长度为 10 米的栅栏,你需要围成一个矩形的鸡舍,使得围成的面积最大。求这个矩形的长和宽应是多少,以使得面积最大。 步骤 设定变量: 设矩形的长为 x x x 米࿰…...

kubernetes K8S 结合 Istio 实现流量治理
目录 1.Istio介绍? 1.1 Istio是什么? 1.2 Istio流量管理 1.2.1 熔断 1.2.2 超时 1.2.3 重试 2.Istio架构 3.istio组件详解 3.1 Pilot 3.2 Envoy 3.3 Citadel 3.4 Galley 3.5 Ingressgateway 3.5 egressgateway 扩展、k8s1.23及1.23以下版…...
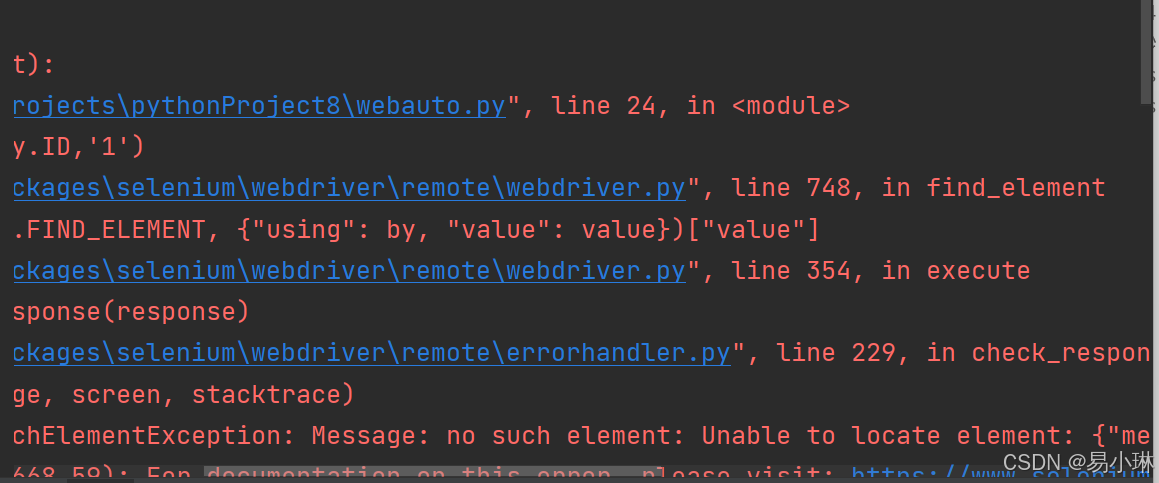
Selenium with Python学习笔记整理(网课+网站持续更新)
本篇是根据学习网站和网课结合自己做的学习笔记,后续会一边学习一边补齐和整理笔记 非常推荐白月黑羽的学习网站: 白月黑羽 (byhy.net) https://selenium-python.readthedocs.io/getting-started.html#simple-usage WEB UI自动化环境配置 (推荐靠谱…...

1.随机事件与概率
第一章 随机时间与概率 1. 随机事件及其运算 1.1 随机现象 确定性现象:只有一个结果的现象 确定性现象:结果不止一个,且哪一个结果出现,人们事先并不知道 1.2 样本空间 样本空间:随机现象的一切可能基本…...

Redis结合Caffeine实现二级缓存:提高应用程序性能
本文将详细介绍如何使用CacheFrontend和Caffeine来实现二级缓存。 1. 简介 CacheFrontend: 是一种用于缓存的前端组件或服务。通俗的讲:该接口可以实现本地缓存与redis自动同步,如果本地缓存(JVM级)有数据,则直接从本…...

【LLM】Ollama:本地大模型 WebAPI 调用
Ollama 快速部署 安装 Docker:从 Docker 官网 下载并安装。 部署 Ollama: 使用以下命令进行部署: docker run -d -p 11434:11434 --name ollama --restart always ollama/ollama:latest进入容器并下载 qwen2.5:0.5b 模型: 进入 O…...
Excel监听以及常用工具类)
SpringBoot集成阿里easyexcel(二)Excel监听以及常用工具类
EasyExcel中非常重要的AnalysisEventListener类使用,继承该类并重写invoke、doAfterAllAnalysed,必要时重写onException方法。 Listener 中方法的执行顺序 首先先执行 invokeHeadMap() 读取表头,每一行都读完后,执行 invoke()方法…...

使用ELK Stack进行日志管理和分析:从入门到精通
在现代IT运维中,日志管理和分析是确保系统稳定性和性能的关键环节。ELK Stack(Elasticsearch, Logstash, Kibana)是一个强大的开源工具集,广泛用于日志收集、存储、分析和可视化。本文将详细介绍如何使用ELK Stack进行日志管理和分…...

前端框架对比与选择
🤖 作者简介:水煮白菜王 ,一位资深前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧✍。 感谢支持💕💕💕 目…...
Springboot jPA+thymeleaf实现增删改查
项目结构 pom文件 配置相关依赖: 2.thymeleaf有点类似于jstlel th:href"{url}表示这是一个链接 th:each"user : ${users}"相当于foreach,对user进行循环遍历 th:if进行if条件判断 {变量} 与 ${变量}的区别: 4.配置好application.ym…...

从BERT到GPT-4:大语言模型的技术演进与应用实践
1. 从单向到双向:大语言模型如何重塑AI的认知边界如果你在2018年之前问我,一个AI模型能不能同时理解一句话里每个词的前后文关系,我会告诉你这很难。那时的主流模型,比如OpenAI的GPT初代,就像一个只能从左到右阅读的读…...

【uniapp】告别静态focus:动态控制input聚焦的实战与思考
1. 为什么静态focus在uniapp中会失效 很多刚开始接触uniapp的开发者都会遇到一个奇怪的现象:明明在input组件上设置了focus"true",但页面加载后输入框却没有自动聚焦。这个问题困扰了不少人,我也是在踩过这个坑之后才明白其中的原理…...

蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析
蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析 在蓝桥杯单片机竞赛中,AT24C02 EEPROM模块是必考内容之一。许多选手已经掌握了基本字符型数据的读写操作,但当面对整型数据时,往往会遇到各种问题。本文将深…...

HoRain云--Skills 工作原理
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

终极指南:在Windows上使用APK Installer轻松安装Android应用
终极指南:在Windows上使用APK Installer轻松安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行Android应用吗&…...

ZYNQ AXI DMA Scatter/Gather模式实战:从PL到PS的高效数据流构建与FreeRTOS任务调度
1. 理解AXI DMA Scatter/Gather模式的核心价值 在ZYNQ平台上构建高效数据流系统时,AXI DMA的Scatter/Gather模式(简称SG模式)绝对是硬件加速的利器。我第一次接触这个功能时,发现它完美解决了传统DMA传输中的两大痛点:…...
)
Linux蓝牙SPP连接保姆级教程:从手机App到开发板双向通信实战(Android/iOS)
Linux蓝牙SPP连接实战:手机与开发板双向通信全指南 当智能家居控制面板需要无线接收手机指令,或是工业传感器数据要通过移动设备实时查看时,蓝牙串口协议(SPP)便成为最便捷的桥梁。不同于常见的蓝牙音频传输,SPP提供了稳定的数据通…...

SSD1306 OLED屏幕驱动全攻略:从Arduino到CircuitPython实战
1. 项目概述如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定遇到过一个问题:怎么把程序运行的状态、传感器的数据或者一些简单的交互界面直观地展示出来?用串口监视器看数据流当然可以,但不够“酷”,也不够便…...

nRF52832蓝牙协议栈烧写实战:J-Flash与SoftDevice分区指南
1. nRF52832蓝牙开发入门:为什么需要烧写SoftDevice? 第一次接触nRF52832蓝牙开发的朋友可能会疑惑:为什么明明芯片支持蓝牙功能,却还要额外烧写一个叫SoftDevice的东西?这个问题要从Nordic芯片的架构设计说起。简单来…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...