Flash Attention是怎么做到又快又省显存的?

Flash Attention 并没有减少 Attention 的计算量,也不影响精度,但是却比标准的Attention运算快 2~4 倍的运行速度,减少了 5~20 倍的内存使用量。究竟是怎么实现的呢?
Attention 为什么慢?
此处的“快慢”是相对而言的。严格意义上来说,相比于传统的 RNN,Transformer中的Attention可以并行地处理序列所有位置的信息(RNN 只能串行处理),因此计算效率并不低,但是仍然有可以进一步改进的空间。
众所周知,科学计算通常分为计算密集型 (compute-bound) 和内存密集型 (memory-bound) 两类。其中,计算密集型运算的时间瓶颈主要在于算数计算,比如大型矩阵的相乘等,而内存密集型运算的时间瓶颈主要在于内存的读写时间,比如批归一化、层归一化等等。
- 时间复杂度:Attention 需要对矩阵 Q 和矩阵 K 的转置做乘法来得到注意力权重矩阵。不考虑 batch 维度,假设矩阵QK 的尺寸都为 ( n , d i m ) (n,dim) (n,dim),那么两个维度为 ( n , d i m ) (n,dim) (n,dim)的矩阵相乘的时间复杂度是序列长度n的平方级 O ( n 2 ) O(n^2) O(n2);在计算完注意力权重矩阵后,还需要对其进行softmax操作,这个算法需要分成三次迭代来执行 O ( n 3 ) O(n^3) O(n3)
- 空间复杂度:Attention的计算过程需要存储 S = Q K T S=QK^T S=QKT和 P = s o f t m a x ( S ) P=softmax(S) P=softmax(S)这两个尺寸均为 ( n , n ) (n,n) (n,n)的矩阵
为了对 Attention 的内存读取时间有更清晰的感知,这里简单介绍 GPU 的内存层级。
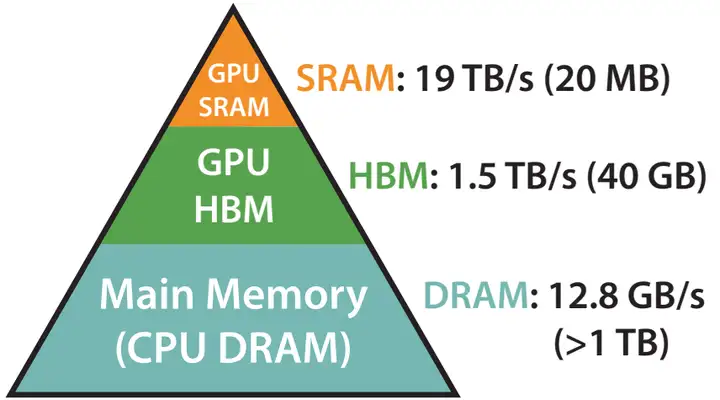
GPU 的内存可以分为 HBM 和 SRAM 两部分。例如,A100 GPU具有40-80 GB的高带宽内存(上图中的 HBM,即我们平时说的“显存”),带宽为 1.5TB/s,并且108个流式多核处理器都有 192 KB 的片上 SRAM,带宽约为 19 TB/s。片上 SRAM 比 HBM 快一个数量级,但容量要小很多个数量级。
在 GPU 运算之前,数据和模型先从 CPU 的内存(上图中的DRAM)移动到 GPU 的 HBM,然后再从 HBM 移动到 GPU 的 SRAM,CUDA kernel 在 SRAM 中对这些数据进行运算,运算完毕后将运算结果再从 SRAM 移动到 HBM。
所以提高Attention运算效率,需要从降低attention的时间和空间复杂度入手。
时间复杂度
在 S = Q K T S=QK^T S=QKT的计算过程中,理论上尝试的方法主要可以分为稀疏 (sparse) 估计和低秩 (low-rank) 估计。但是在实际应用中仍然存在一些缺陷:
- 性能比不上原始 attention。不论是稀疏估计、低秩估计还是其他,这些方法都采用了某种近似算法来估算注意力权重矩阵,难免会丢失信息。目前主流的还是原始的attention
- 无法减少内存读取的时间消耗。这些方法只能降低 attention 的计算复杂度,但是无法对 attention 运算过程中的空间复杂度等进行控制,无法减少内存读写带来的时间损耗
所以在时间复杂度方向的优化主要在softmax的计算过程中:
softmax ( x i ) = e x i ∑ k = 1 N e x k \operatorname{softmax}\left(x_{i} \right)=\frac{e^{x_{i}}}{\sum_{k=1}^{N} e^{x_{k}}} softmax(xi)=∑k=1Nexkexi
softmax 有个问题,那就是很容易溢出。比如float16的最大值为65504,所以只要 x ≥ 11 x\geq11 x≥11 的话softmax就溢出了。好在 exp 有这么一个性质,那就是 e x − y = e x e y e^{x-y} = \frac{e^x}{e^y} ex−y=eyex,根据这个性质,可以在分子分母上同时除以一个数,这样可以将 x x x的范围都缩放到范围内,保证计算 softmax 时的数值稳定性。这个算法可以分成三次迭代来执行:
- 遍历所有数,求 x 中的最大值m
for i ← 1 , N do m i = max ( m i , x i ) \begin{array}{l}\text { for } i \leftarrow 1, N \text { do } \\ \quad m_{i}=\max \left(m_{i}, x_{i}\right)\end{array} for i←1,N do mi=max(mi,xi)
2. 计算 softmax 分母,并根据m对其进行缩放
for i ← 1 , N do d i = d i − 1 + e x i − m N \begin{aligned} \text { for } i & \leftarrow 1, N \text { do } \\ d_{i} & =d_{i-1}+e^{x_{i}-m_{N}}\end{aligned} for idi←1,N do =di−1+exi−mN
3. 求对应位置的 softmax
for i ← 1 , N d o a i = e x i − m N d N \begin{aligned} \text { for } i & \leftarrow 1, N d o \\ a_{i} & =\frac{e^{x_{i}-m_{N}}}{d_{N}}\end{aligned} for iai←1,Ndo=dNexi−mN
分析以上步骤可以发现,如果是不做任何优化的话,至少要进行和 GPU 进行6次通信(3次写入,3次写出),如果对每一步的for循环进行一些并行切分的的话,还要加上 reduce_sum 和 reduce_max 之类的通信成本。所以2018年 Nvidia 提出了《Online normalizer calculation for softmax》,核心改进是去掉第二步 d i = d i − 1 + e x i − m N d_{i} =d_{i-1}+e^{x_{i}-m_{N}} di=di−1+exi−mN中对$m_N 的依赖,设 的依赖,设 的依赖,设d_{i}{\prime}=\sum_{j}{i} e^{x_{j}-m_{i}}$(这里的全局最大值变成了当前最大值),这个式子有如下的性质:
d i ′ = ∑ j i e x j − m i = ∑ j i − 1 e x j − m i + e x i − m i = ∑ j i − 1 e x j − m i − 1 + m i − 1 − m i + e x i − m i = ( ∑ j i − 1 e x j − m i − 1 ) e m i − 1 − m i + e x i − m i = d i − 1 ′ e m i − 1 − m i + e x i − m i \begin{aligned} d_{i}^{\prime} & =\sum_{j}^{i} e^{x_{j}-m_{i}} \\ & =\sum_{j}^{i-1} e^{x_{j}-m_{i}}+e^{x_{i}-m_{i}} \\ & =\sum_{j}^{i-1} e^{x_{j}-m_{i-1}+m_{i-1}-m_{i}}+e^{x_{i}-m_{i}} \\ & =\left(\sum_{j}^{i-1} e^{x_{j}-m_{i-1}}\right) e^{m_{i-1}-m_{i}}+e^{x_{i}-m_{i}} \\ & =d_{i-1}^{\prime} e^{m_{i-1}-m_{i}}+e^{x_{i}-m_{i}}\end{aligned} di′=j∑iexj−mi=j∑i−1exj−mi+exi−mi=j∑i−1exj−mi−1+mi−1−mi+exi−mi=(j∑i−1exj−mi−1)emi−1−mi+exi−mi=di−1′emi−1−mi+exi−mi
这个式子依赖于 d i − 1 ′ , m i , m i − 1 d_{i-1}^{\prime},m_i, m_{i-1} di−1′,mi,mi−1。那么就可以将softmax前两步合并到一起:
- 求 x 的最大值 m, 计算 softmax 的分母
for i ← 1 , N do m i = max ( m i , x i ) d i ′ = d i − 1 ′ e m i − 1 − m i + e x i − m i \begin{array}{l}\text { for } i \leftarrow 1, N \text { do } \\ \qquad m_{i}=\max \left(m_{i}, x_{i}\right) \\ \qquad d_{i}^{\prime}=d_{i-1}^{\prime} e^{m_{i-1}-m_{i}}+e^{x_{i}-m_{i}}\end{array} for i←1,N do mi=max(mi,xi)di′=di−1′emi−1−mi+exi−mi
2. 求对应位置的 softmax
for i ← 1 , N d o a i = e x i − m N d N \begin{aligned} \text { for } i & \leftarrow 1, N d o \\ a_{i} & =\frac{e^{x_{i}-m_{N}}}{d_{N}}\end{aligned} for iai←1,Ndo=dNexi−mN
以上的算法优化可以将3步合并变成2步,将softmax的时间复杂度降为 O ( n 2 ) O(n^2) O(n2)。
空间复杂度
在将3步合成2步的同时:
- 借助GPU的share memory来存储中间结果,将上面的两步只用一个 kernel 实现,这样就只需要与 global memory 通信两次(一次写入数据,一次读取结果)
- 还可以减少 Reduce_max 和 Reduce_sum 之类的通信成本
空间复杂度方面优化的基本思路是降低Attention对于显存的需求,减少HBM和SRAM之间的换入换出,充分利用 GPU 的并行优势,进而减少Attention运算的时间消耗。
总结
Flash Attention的动机是尽可能避免大尺寸的注意力权重矩阵在 HBM 和 SRAM 之间的换入换出。论文中具体方法包含两个部分:tiling 和 recomputation。
tiling 的基本思路:不直接对整个输入序列计算注意力,而是将其分为多个较小的块,逐个对这些块进行计算,增量式地进行 softmax 的规约。规约过程中只需要更新某些中间变量,不需要计算整个注意力权重矩阵,就是以上介绍的将三部合并成两步的过程。
recomputation 的基本思路:基于 tiling 技巧,在反向传播过程中不保留整个注意力权重矩阵,而是只保留前向过程中 tiling 的某些中间变量,然后在反向传播过程中重新计算注意力权重矩阵。recomputation 可以看作是一种基于 tiling 的特殊的 gradient checkpointing,想进一步了解 recomputation 的读者可以翻阅Flash Attention原文。
得益于上述技巧,Flash Attention 可以同时做到又快(运算速度快)又省(节省显存)。

相关文章:
Flash Attention是怎么做到又快又省显存的?
Flash Attention 并没有减少 Attention 的计算量,也不影响精度,但是却比标准的Attention运算快 2~4 倍的运行速度,减少了 5~20 倍的内存使用量。究竟是怎么实现的呢? Attention 为什么慢? 此处的“快慢”是相对而言的…...

CAN报文ID过滤
在CAN通信中,CAN_FILTERMODE_LIST和CAN_FILTERMODE_MASK是用于CAN过滤器配置的两种不同过滤模式。 1. CAN_FILTERMODE_LIST: - 当CAN过滤器使用CAN_FILTERMODE_LIST模式时,过滤器将匹配通过滤器的标识符列表中的任何一个标识符。换句话说…...

ELK-05-skywalking监控SpringCloud服务日志
文章目录 前言一、引入依赖二、增加日志配置文件三、打印日志四、skywalking网页查询链路五、日志收集5.1 修改logback-spring.xml5.2 重启SpringCloud服务并请求test接口5.3 查看skywalking网页的Log 总结 前言 基于上一章节,现在使用skywalkin监控SpringCloud服务…...

17年数据结构考研真题解析
第一题: 解析: 我们说递归要找出口,这道题的出口是sum<n,经过观察可以得知:sum123。。。k 设第k次循环跳出,则有sum123。。。k<n k<,很显然答案选B 第二题: 解析: 第一句&a…...

nginx 安装(Centos)
nginx 安装-适用于 Centos 7.x [rootiZhp35weqb4z7gvuh357fbZ ~]# lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 7.9.2009 (Core) Release: 7.9.2009 Codename: Core# 创建文件…...

异步编程利器:深入解析 Python 异步并发库 Gevent
在现代 Python 应用开发中,并发编程 是提高程序性能、处理多个任务的关键手段之一。虽然 Python 有原生的多线程、多进程模块,但这些模块存在一些限制,比如全局解释器锁(GIL)会影响多线程程序的执行效率。此外…...

Python pyusb 使用指南【windows+linux】
前言:USB(通用串行总线)作为一种高度通用性的硬件接口,在诸多领域均有应用。在C中可以直接使用libusb库即可完成USB设备信息查询、USB设备监听、与USB设备控制端点、数据(同步、批量、中断)端点进行指令、数据交互等功能。python中…...

Xcode报错:The request was denied by service delegate (SBMainWorkspace)
Xcode报错:The request was denied by service delegate (SBMainWorkspace) 造成的原因: (1)新的M2芯片的Mac电脑 (2) 此电脑首次安装启动Xcode的应用程序 (3)此电脑未安装Rosetta 解决方法: (1)打开终端…...
面试系列-携程暑期实习一面
Java 基础 1、Java 中有哪些常见的数据结构? 图片来源于:JavaGuide Java集合框架图 Java 中常见的数据结构包含了 List、Set、Map、Queue,在回答的时候,只要把经常使用的数据结构给说出来即可,不需要全部记住 如下&…...
你以为建站很复杂?Baklib 5分钟解决你的痛点
你以为建站很复杂?Baklib 5分钟解决你的痛点! 在这个“快节奏”的互联网时代,想要快速搭建一个网站是很多人的刚需。今天我要介绍的,就是如何利用Baklib的CMS/Wiki模板,五分钟内让你的网站“横空出世”。废话不多说&am…...

极狐GitLab 17.4 重点功能解读【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

LVS-DR实战案例,实现四层负载均衡
环境准备:三台虚拟机(NET模式或者桥接模式) 192.168.88.200 (web1)(安装nginx服务器作为测试) 192.168.88.201 (服务器)(用于部署lvs-dr) 192.168.88.202 (web2)…...

网游和3A类型游戏的CPU选择分析
目录 1. CPU性能基础 1.1 主频 1.2 三级缓存(L1、L2、L3缓存) 1.3 架构 1.4 单核与多核性能 2. 游戏类型分析 2.1 网游:以《永劫无间》为例 多核性能需求: 单核性能需求: CPU选择建议: 2.2 3A类…...

2024免费录屏软件的宝藏功能与实用技巧
在手机上操作很多时候为了记录方便都直接截图或者录屏,其实电脑也一样。现在面向电脑的录屏工具纷繁复杂,很容易让我们挑花了眼。今天这篇文章我将介绍几款免费的录屏软件为大家提供参考。 1.福昕录屏大师 链接达达:www.foxitsoftware.cn/R…...

linux---进程程序替换详解
提示:以下是本篇文章正文内容,下面案例可供参考 一、程序替换的原理 我们可以创建子进程通过程序替换,来执行不同的程序。程序替换不会重新创建子进程,我们通过程序替换函数,内核将磁盘中的可执行程序和数据加载到内存…...

笔试编程-百战成神——Day01
1.数字统计 题目来源:数字统计——牛客网 测试用例 算法原理 根据题目我们知道,首先要输出两个数字确定一个区间,寻找这个区间内数字中所有包含2的个数,比如12包含一个2,22包含两个2,以此类推,所以我们的…...

Qt+toml文件读写
Qttoml 使用 cpptoml 库示例Qt 项目中的代码示例 解释注意事项 在Qt中使用TOML(Tom’s Obvious, Minimal Language)格式的文件,可以通过第三方库来实现,例如 cpptoml。TOML是一种易于阅读和写入的配置文件格式,与JSON…...

浅谈C++之指针
一、基本介绍 在C中,指针是一种复杂的数据类型,它存储了另一个变量的内存地址。通过指针,程序可以直接访问和操作内存,这为编程提供了极大的灵活性和效率,但同时也增加了复杂性和潜在的错误风险。 二、指针的概念 指针…...

在虚幻引擎中实时显示帧率
引擎自带了显示帧率的功能 但是只能在编辑器中显示 , 在游戏发布后就没有了 , 所以我们要自己做一个 创建一个控件蓝图 创建画布和文本 , 修改文本 文本绑定函数 , 点击创建绑定 添加一个名为 FPS 的变量 格式化文本 用大括号把变量包起来 {FPS Int} FPS 然后转到事件图表…...

Apache Iceberg构建高性能数据湖
1. 概述 大数据时代的挑战 随着信息技术和互联网的迅猛发展,我们正处于一个数据爆炸的时代。企业和组织每天都在生成和收集海量的数据,这些数据来自于社交媒体、物联网设备、传感器、交易系统等各种来源。如何高效地存储、管理和分析这些庞大的数据集&…...

Flink窗口实战避坑指南:从AggregateFunction到ProcessWindowFunction,我踩过的那些坑
Flink窗口实战避坑指南:从AggregateFunction到ProcessWindowFunction的深度解析 第一次在真实项目中使用Flink窗口时,我像发现新大陆一样兴奋。直到凌晨三点被报警短信惊醒,才发现窗口计算的结果完全偏离预期——这让我意识到,窗口…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

nnU-Net v2实战:从零开始配置环境与训练自定义医学影像数据集
1. 环境配置:搭建nnU-Net v2的基础舞台 第一次接触nnU-Net时,我踩过的最大坑就是环境配置。当时为了赶项目进度,直接用了现有的Python 3.8环境,结果在安装时各种报错,浪费了大半天时间。后来才发现,nnU-Net…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

时空镜像立体成像楼宇全态透明智慧管控技术解析方案
时空镜像立体成像楼宇全态透明智慧管控技术解析方案一、方案概述当前传统楼宇管控普遍存在二维监控信息碎片化、空间感知能力薄弱、人员定位依赖外设、跨镜头轨迹断裂、身份核验存在漏洞、设备运维滞后、区域管控存在盲区等行业共性痛点,多数系统仅实现视频录像与基…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

Go语言SDK开发实战:为AI编程助手Cursor构建高效API客户端
1. 项目概述:一个为AI编程助手Cursor定制的Go语言SDK如果你和我一样,日常重度依赖Cursor这类AI编程助手来提升开发效率,同时又是个Go语言的忠实拥趸,那你肯定遇到过这样的场景:想用Go写个脚本,自动化处理一…...

Arm Neoverse-V2/V3缓存与内存参数优化指南
1. Arm Neoverse-V2/V3集群架构概述Arm Neoverse系列处理器作为数据中心和基础设施领域的重要计算引擎,其V2/V3代架构在缓存子系统和内存管理方面进行了显著优化。作为从业多年的系统架构师,我认为理解这些处理器的参数配置对性能调优至关重要。Neoverse…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...
做WiFi遥控小车,我踩过的那些坑)
保姆级避坑指南:用STM32F103C8T6+ESP8266(AT指令)做WiFi遥控小车,我踩过的那些坑
STM32F103C8T6ESP8266 WiFi遥控小车避坑实战手册 1. 硬件选型与连接:那些容易被忽视的细节 在开始任何代码编写之前,硬件连接的正确性往往决定了项目的成败。使用STM32F103C8T6(俗称"蓝莓板")与ESP8266模块组合时&#…...