第06章_索引的数据结构
第06章_索引的数据结构
🏠个人主页:shark-Gao
🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉
🎉目前状况:23届毕业生,目前在某公司实习👏👏
❤️欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,我亲爱的大佬😘
🖥️个人小站 :个人博客,欢迎大家访问
配套视频参考:MySQL数据库天花板–康师傅http://www.atguigu.com/)
1. 为什么使用索引
索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教科书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。MySQL中也是一样的道理,进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据,如果不符合则需要全表扫描,即需要一条一条地查找记录,直到找到与条件符合的记录。
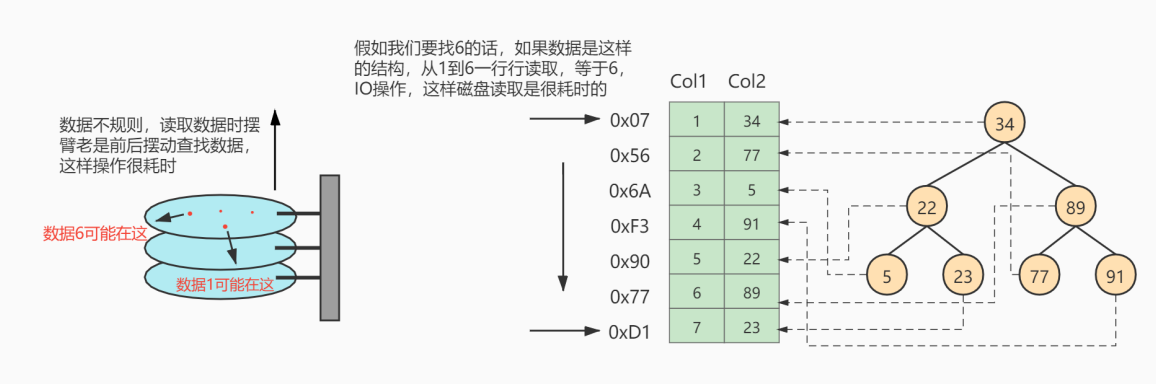
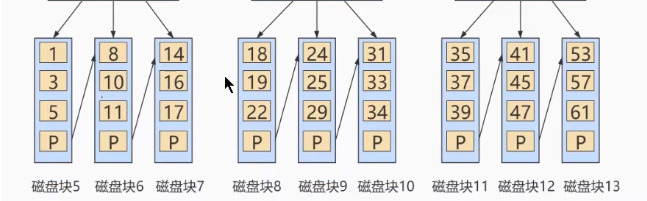
如上图所示,数据库没有索引的情况下,数据分布在硬盘不同的位置上面,读取数据时,摆臂需要前后摆动查询数据,这样操作非常消耗时间。如果数据顺序摆放,那么也需要从1到6行按顺序读取,这样就相当于进行了6次IO操作,依旧非常耗时。如果我们不借助任何索引结构帮助我们快速定位数据的话,我们查找 Col 2 = 89 这条记录,就要逐行去查找、去比较。从Col 2 = 34 开始,进行比较,发现不是,继续下一行。我们当前的表只有不到10行数据,但如果表很大的话,有上千万条数据,就意味着要做很多很多次硬盘I/0才能找到。现在要查找 Col 2 = 89 这条记录。CPU必须先去磁盘查找这条记录,找到之后加载到内存,再对数据进行处理。这个过程最耗时间就是磁盘I/O(涉及到磁盘的旋转时间(速度较快),磁头的寻道时间(速度慢、费时))
假如给数据使用 二叉树 这样的数据结构进行存储,如下图所示
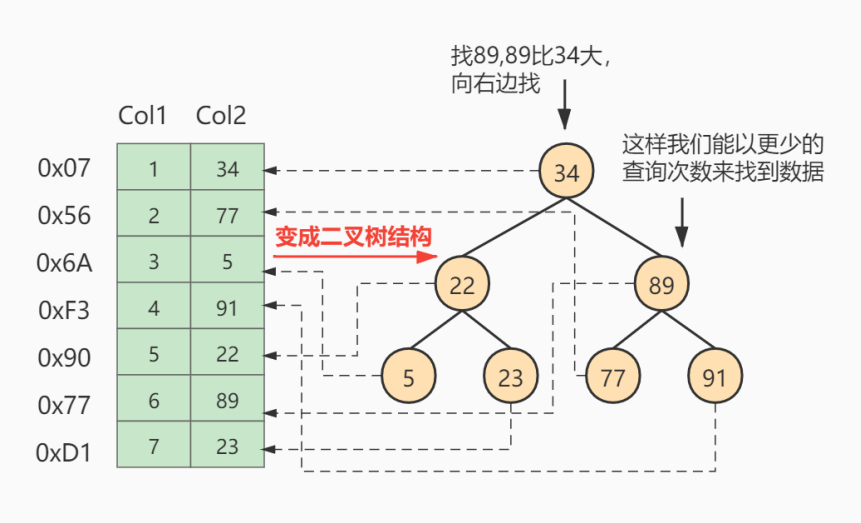
对字段 Col 2 添加了索引,就相当于在硬盘上为 Col 2 维护了一个索引的数据结构,即这个 二叉搜索树。二叉搜索树的每个结点存储的是 (K, V) 结构,key 是 Col 2,value 是该 key 所在行的文件指针(地址)。比如:该二叉搜索树的根节点就是:(34, 0x07)。现在对 Col 2 添加了索引,这时再去查找 Col 2 = 89 这条记录的时候会先去查找该二叉搜索树(二叉树的遍历查找)。读 34 到内存,89 > 34; 继续右侧数据,读 89 到内存,89==89;找到数据返回。找到之后就根据当前结点的 value 快速定位到要查找的记录对应的地址。我们可以发现,只需要 查找两次 就可以定位到记录的地址,查询速度就提高了。
这就是我们为什么要建索引,目的就是为了 减少磁盘I/O的次数,加快查询速率。
2. 索引及其优缺点
2.1 索引概述
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。你可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。 这些数据结构以某种方式指向数据, 这样就可以在这些数据结构的基础上实现 高级查找算法 。
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎不一定支持所有索引类型。同时,存储引擎可以定义每个表的 最大索引数和 最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。有些存储引擎支持更多的索引数和更大的索引长度。
2.2 优点
(1)类似大学图书馆建书目索引,提高数据检索的效率,降低 数据库的IO成本 ,这也是创建索引最主 要的原因。
(2)通过创建唯一索引,可以保证数据库表中每一行 数据的唯一性 。
(3)在实现数据的 参考完整性方面,可以 加速表和表之间的连接 。换句话说,对于有依赖关系的子表和父表联合查询时, 可以提高查询速度。
(4)在使用分组和排序子句进行数据查询时,可以显著 减少查询中分组和排序的时间 ,降低了CPU的消耗。
2.3 缺点
增加索引也有许多不利的方面,主要表现在如下几个方面:
(1)创建索引和维护索引要 耗费时间 ,并 且随着数据量的增加,所耗费的时间也会增加。
(2)索引需要占 磁盘空间 ,除了数据表占数据空间之 外,每一个索引还要占一定的物理空间, 存储在磁盘上 ,如果有大量的索引,索引文件就可能比数据文 件更快达到最大文件尺寸。
(3)虽然索引大大提高了查询速度,同时却会 降低更新表的速度 。当对表 中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。 因此,选择使用索引时,需要综合考虑索引的优点和缺点。
因此,选择使用索引时,需要综合考虑索引的优点和缺点。
提示:
索引可以提高查询的速度,但是会影响插入记录的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
3. InnoDB中索引的推演
3.1 索引之前的查找
先来看一个精确匹配的例子:
SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
1. 在一个页中的查找
假设目前表中的记录比较少,所有的记录都可以被存放到一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况:
-
以主键为搜索条件
可以在页目录中使用
二分法快速定位到对应的槽,然后再遍历该槽对用分组中的记录即可快速找到指定记录。 -
以其他列作为搜索条件
因为在数据页中并没有对非主键列简历所谓的页目录,所以我们无法通过二分法快速定位相应的槽。这种情况下只能从
最小记录开始依次遍历单链表中的每条记录, 然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。
2. 在很多页中查找
在很多页中查找记录的活动可以分为两个步骤:
- 定位到记录所在的页。
- 从所在的页内中查找相应的记录。
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能 从第一个页沿着双向链表 一直往下找,在每一个页中根据我们上面的查找方式去查 找指定的记录。因为要遍历所有的数据页,所以这种方式显然是 超级耗时 的。如果一个表有一亿条记录呢?此时 索引 应运而生。
3.2 设计索引
建一个表:
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
这个新建的 index_demo 表中有2个INT类型的列,1个CHAR(1)类型的列,而且我们规定了c1列为主键, 这个表使用 Compact 行格式来实际存储记录的。这里我们简化了index_demo表的行格式示意图:
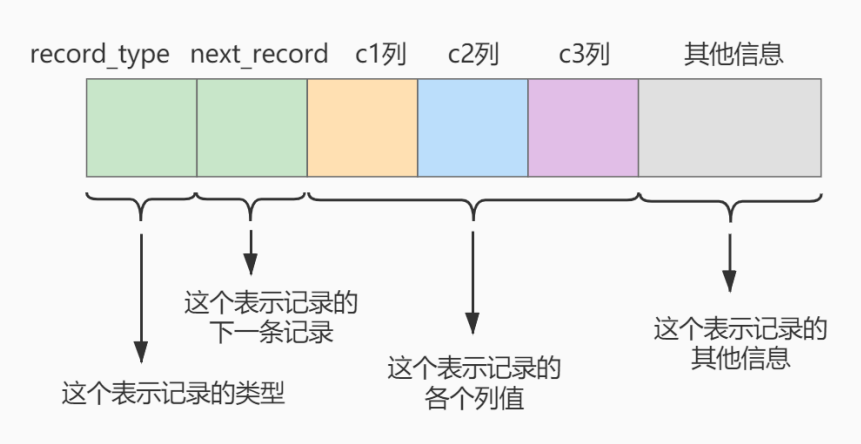
我们只在示意图里展示记录的这几个部分:
- record_type :记录头信息的一项属性,表示记录的类型, 0 表示普通记录、 2 表示最小记 录、 3 表示最大记录、 1 暂时还没用过,下面讲。
- mysql> CREATE TABLE index_demo( -> c1 INT, -> c2 INT, -> c3 CHAR(1), -> PRIMARY KEY(c1) -> ) ROW_FORMAT = Compact; next_record :记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量,我们用 箭头来表明下一条记录是谁。
- 各个列的值 :这里只记录在 index_demo 表中的三个列,分别是 c1 、 c2 和 c3 。
- 其他信息 :除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。
将记录格式示意图的其他信息项暂时去掉并把它竖起来的效果就是这样:

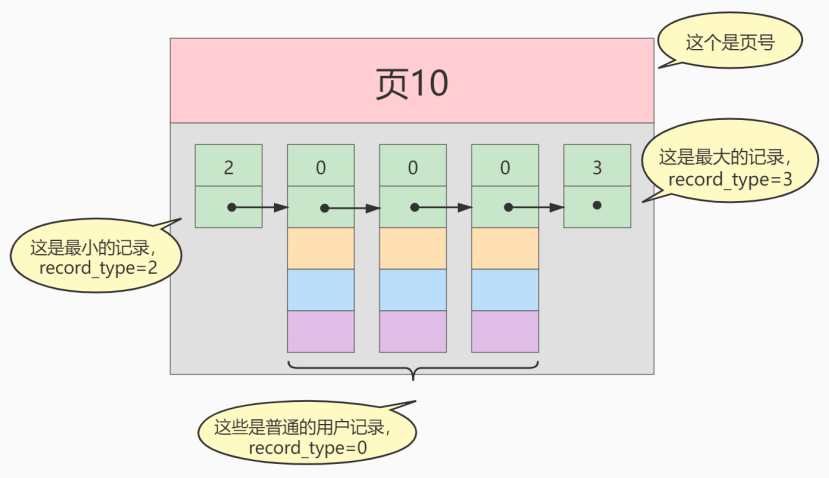
把一些记录放到页里的示意图就是:
1. 一个简单的索引设计方案
我们在根据某个搜索条件查找一些记录时为什么要遍历所有的数据页呢?因为各个页中的记录并没有规律,我们并不知道我们的搜索条件匹配哪些页中的记录,所以不得不依次遍历所有的数据页。所以如果我们 想快速的定位到需要查找的记录在哪些数据页 中该咋办?我们可以为快速定位记录所在的数据页而建立一个目录 ,建这个目录必须完成下边这些事:
-
下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。
假设:每个数据结构最多能存放3条记录(实际上一个数据页非常大,可以存放下好多记录)。
INSERT INTO index_demo VALUES(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');
那么这些记录以及按照主键值的大小串联成一个单向链表了,如图所示:
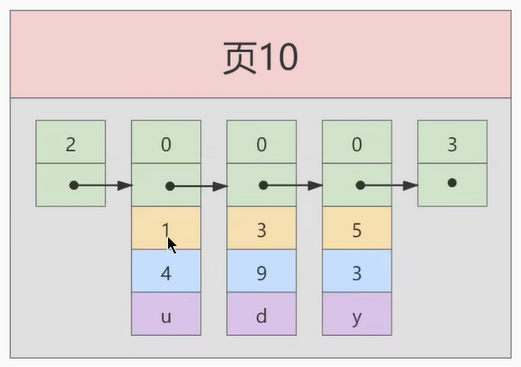
从图中可以看出来, index_demo 表中的3条记录都被插入到了编号为10的数据页中了。此时我们再来插入一条记录
INSERT INTO index_demo VALUES(4, 4, 'a');
因为 页10 最多只能放3条记录,所以我们不得不再分配一个新页:
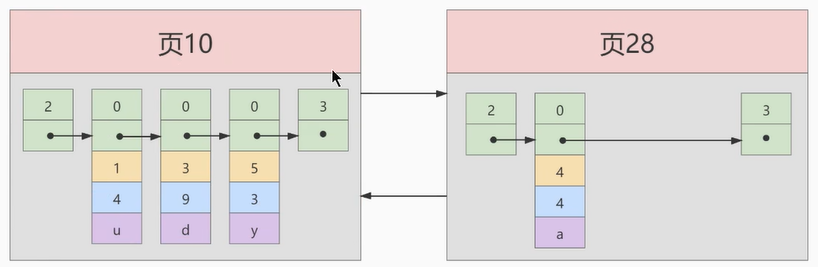
注意:新分配的 数据页编号可能并不是连续的。它们只是通过维护者上一个页和下一个页的编号而建立了 链表 关系。另外,页10中用户记录最大的主键值是5,而页28中有一条记录的主键值是4,因为5>4,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以在插入主键值为4的记录的时候需要伴随着一次 记录移动,也就是把主键值为5的记录移动到页28中,然后再把主键值为4的记录插入到页10中,这个过程的示意图如下:
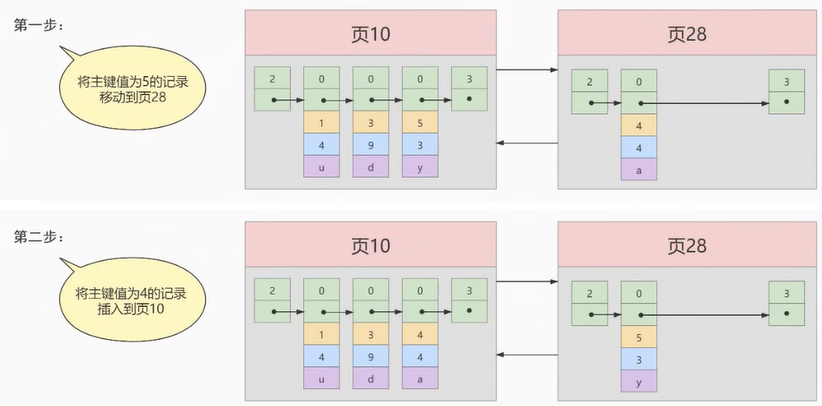
这个过程表明了在对页中的记录进行增删改查操作的过程中,我们必须通过一些诸如 记录移动 的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程称为 页分裂。
- 给所有的页建立一个目录项。
由于数据页的 编号可能是不连续 的,所以在向 index_demo 表中插入许多条记录后,可能是这样的效果:

我们需要给它们做个 目录,每个页对应一个目录项,每个目录项包括下边两个部分:
1)页的用户记录中最小的主键值,我们用 key 来表示。
2)页号,我们用 page_on 表示。
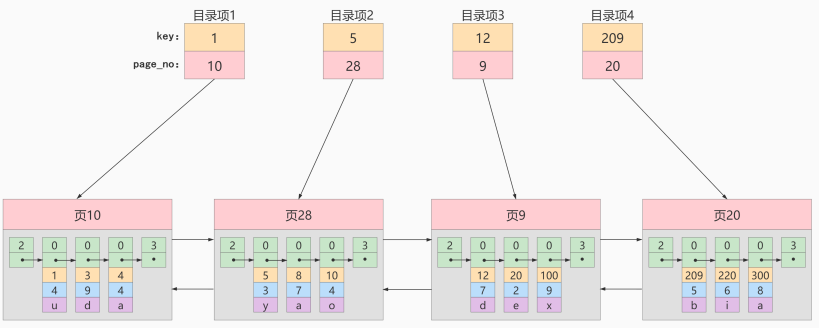
以 页28 为例,它对应 目录项2 ,这个目录项中包含着该页的页号 28 以及该页中用户记录的最小主 键值 5 。我们只需要把几个目录项在物理存储器上连续存储(比如:数组),就可以实现根据主键 值快速查找某条记录的功能了。比如:查找主键值为 20 的记录,具体查找过程分两步:
- 先从目录项中根据 二分法 快速确定出主键值为 20 的记录在 目录项3 中(因为 12 < 20 < 209 ),它对应的页是 页9 。
- 再根据前边说的在页中查找记录的方式去 页9 中定位具体的记录。
至此,针对数据页做的简易目录就搞定了。这个目录有一个别名,称为 索引 。
2. InnoDB中的索引方案
① 迭代1次:目录项纪录的页
InnoDB怎么区分一条记录是普通的 用户记录 还是 目录项记录 呢?使用记录头信息里的 record_type 属性,它的各自取值代表的意思如下:
- 0:普通的用户记录
- 1:目录项记录
- 2:最小记录
- 3:最大记录
我们把前边使用到的目录项放到数据页中的样子就是这样:
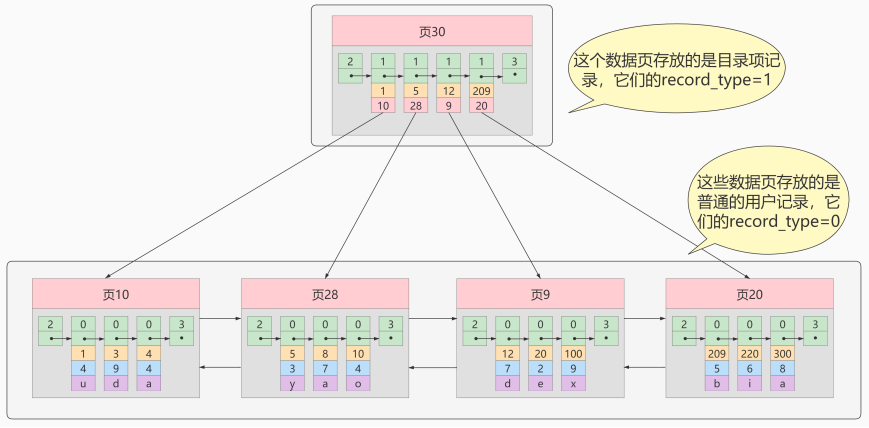
从图中可以看出来,我们新分配了一个编号为30的页来专门存储目录项记录。这里再次强调 目录项记录 和普通的 用户记录 的不同点:
- 目录项记录 的 record_type 值是1,而 普通用户记录 的 record_type 值是0。
- 目录项记录只有 主键值和页的编号 两个列,而普通的用户记录的列是用户自己定义的,可能包含 很多列 ,另外还有InnoDB自己添加的隐藏列。
- 了解:记录头信息里还有一个叫 min_rec_mask 的属性,只有在存储 目录项记录 的页中的主键值最小的 目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0 。
相同点:两者用的是一样的数据页,都会为主键值生成 Page Directory (页目录),从而在按照主键值进行查找时可以使用 二分法 来加快查询速度。
现在以查找主键为 20 的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
- 先到存储 目录项记录 的页,也就是页30中通过 二分法 快速定位到对应目录项,因为 12 < 20 < 209 ,所以定位到对应的记录所在的页就是页9。
- 再到存储用户记录的页9中根据 二分法 快速定位到主键值为 20 的用户记录。
② 迭代2次:多个目录项纪录的页
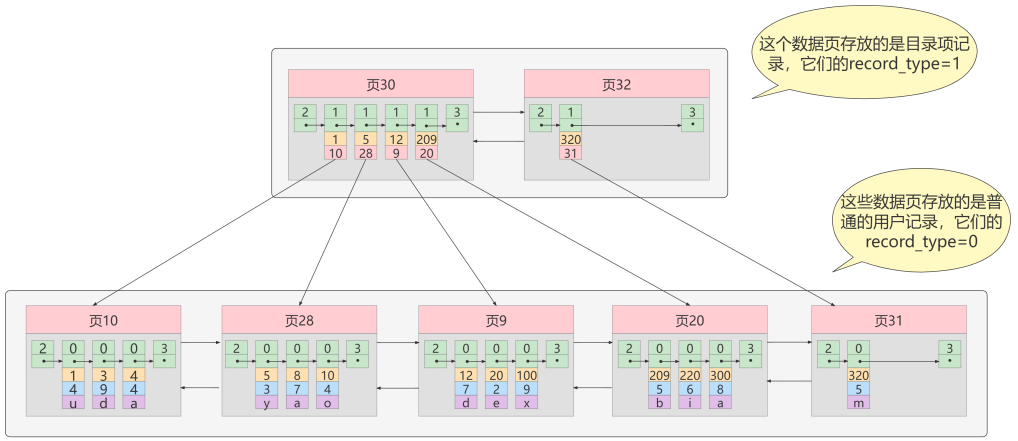
从图中可以看出,我们插入了一条主键值为320的用户记录之后需要两个新的数据页:
- 为存储该用户记录而新生成了 页31 。
- 因为原先存储目录项记录的 页30的容量已满 (我们前边假设只能存储4条目录项记录),所以不得 不需要一个新的 页32 来存放 页31 对应的目录项。
现在因为存储目录项记录的页不止一个,所以如果我们想根据主键值查找一条用户记录大致需要3个步骤,以查找主键值为 20 的记录为例:
- 确定 目录项记录页 我们现在的存储目录项记录的页有两个,即 页30 和 页32 ,又因为页30表示的目录项的主键值的 范围是 [1, 320) ,页32表示的目录项的主键值不小于 320 ,所以主键值为 20 的记录对应的目 录项记录在 页30 中。
- 通过目录项记录页 确定用户记录真实所在的页 。 在一个存储 目录项记录 的页中通过主键值定位一条目录项记录的方式说过了。
- 在真实存储用户记录的页中定位到具体的记录。
③ 迭代3次:目录项记录页的目录页
如果我们表中的数据非常多则会产生很多存储目录项记录的页,那我们怎么根据主键值快速定位一个存储目录项记录的页呢?那就为这些存储目录项记录的页再生成一个更高级的目录,就像是一个多级目录一样,大目录里嵌套小目录,小目录里才是实际的数据,所以现在各个页的示意图就是这样子:
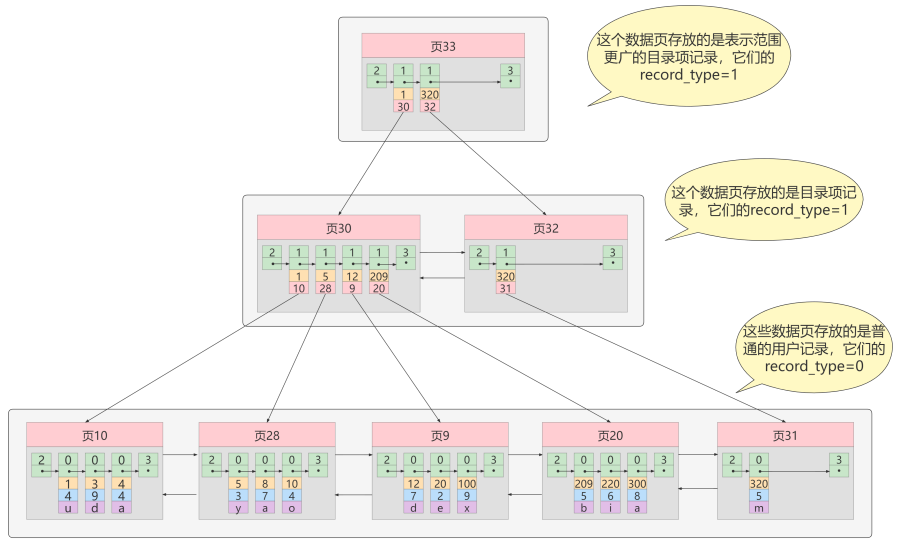
如图,我们生成了一个存储更高级目录项的 页33 ,这个页中的两条记录分别代表页30和页32,如果用 户记录的主键值在 [1, 320) 之间,则到页30中查找更详细的目录项记录,如果主键值 不小于320 的 话,就到页32中查找更详细的目录项记录。
我们可以用下边这个图来描述它:
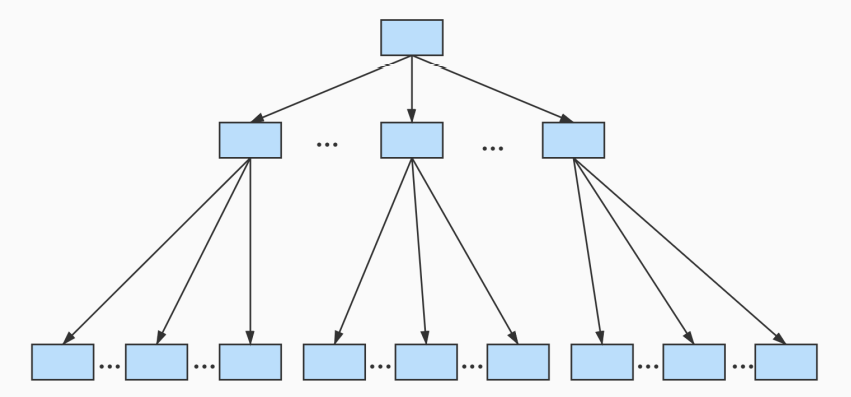
这个数据结构,它的名称是 B+树 。
④ B+Tree
一个B+树的节点其实可以分成好多层,规定最下边的那层,也就是存放我们用户记录的那层为第 0 层, 之后依次往上加。之前我们做了一个非常极端的假设:存放用户记录的页 最多存放3条记录 ,存放目录项 记录的页 最多存放4条记录 。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录 的叶子节点代表的数据页可以存放 100条用户记录 ,所有存放目录项记录的内节点代表的数据页可以存 放 1000条目录项记录 ,那么:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放 100 条记录。
- 如果B+树有2层,最多能存放 1000×100=10,0000 条记录。
- 如果B+树有3层,最多能存放 1000×1000×100=1,0000,0000 条记录。
- 如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000 条记录。相当多的记录!
你的表里能存放 100000000000 条记录吗?所以一般情况下,我们用到的 B+树都不会超过4层 ,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的 Page Directory (页目录),所以在页面内也可以通过 二分法 实现快速 定位记录。
3.3 常见索引概念
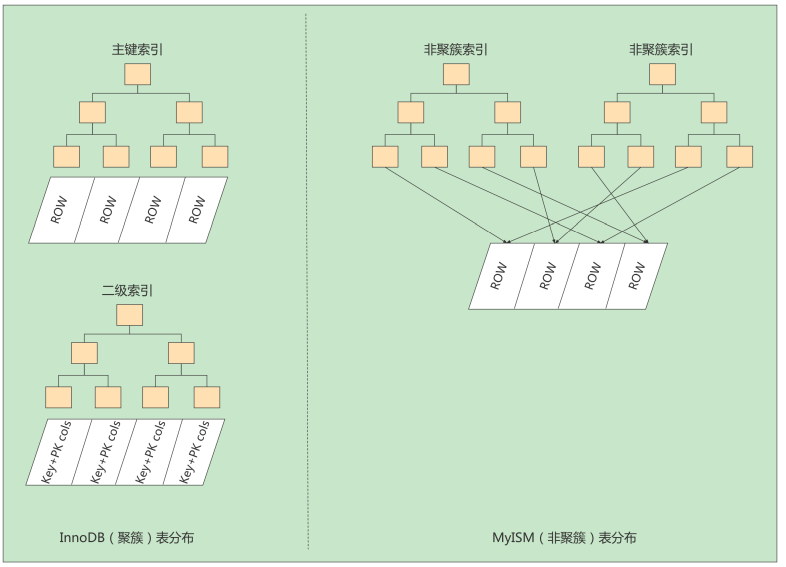
索引按照物理实现方式,索引可以分为 2 种:聚簇(聚集)和非聚簇(非聚集)索引。我们也把非聚集 索引称为二级索引或者辅助索引。
1. 聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的用户记录都存储在了叶子结点),也就是所谓的 索引即数据,数据即索引。
术语"聚簇"表示当前数据行和相邻的键值聚簇的存储在一起
特点:
-
使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。- 各个存放
用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。 - 存放
目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
-
B+树的 叶子节点 存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX 语句去创建, InnDB 存储引擎会 自动 的为我们创建聚簇索引。
优点:
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快- 聚簇索引对于主键的
排序查找和范围查找速度非常快 - 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多 个数据块中提取数据,所以
节省了大量的io操作。
缺点:
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
2. 二级索引(辅助索引、非聚簇索引)
如果我们想以别的列作为搜索条件该怎么办?肯定不能是从头到尾沿着链表依次遍历记录一遍。
答案:我们可以多建几颗B+树,不同的B+树中的数据采用不同的排列规则。比方说我们用c2列的大小作为数据页、页中记录的排序规则,再建一课B+树,效果如下图所示:
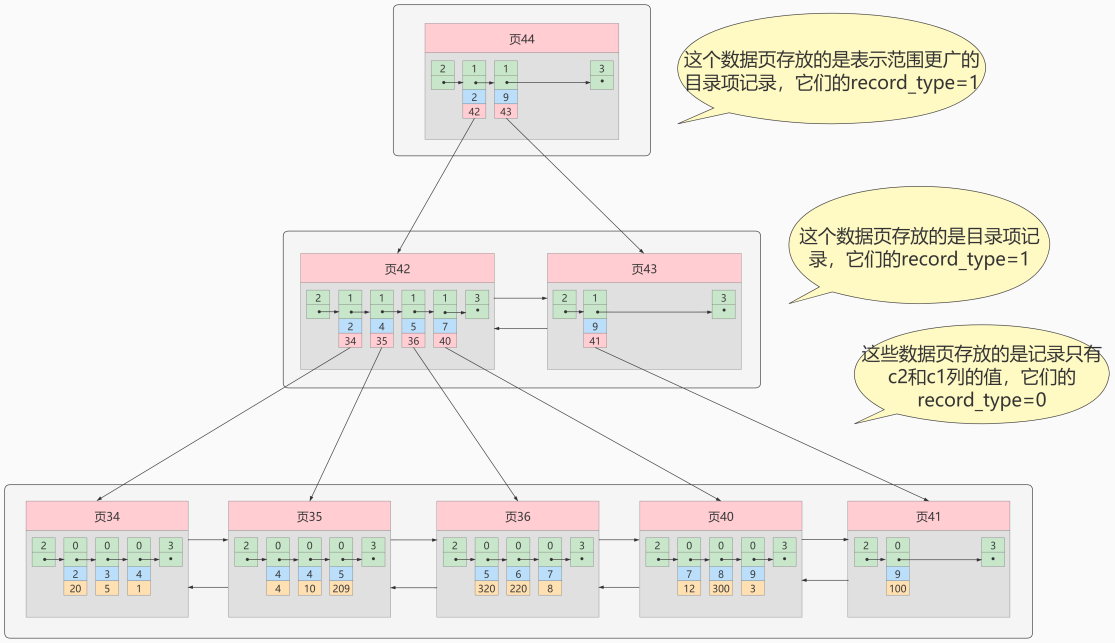
这个B+树与上边介绍的聚簇索引有几处不同:

**概念:回表 **
我们根据这个以c2列大小排序的B+树只能确定我们要查找记录的主键值,所以如果我们想根 据c2列的值查找到完整的用户记录的话,仍然需要到 聚簇索引 中再查一遍,这个过程称为 回表 。也就 是根据c2列的值查询一条完整的用户记录需要使用到 2 棵B+树!
问题:为什么我们还需要一次 回表 操作呢?直接把完整的用户记录放到叶子节点不OK吗?
回答:
如果把完整的用户记录放到叶子结点是可以不用回表。但是太占地方了,相当于每建立一课B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。
因为这种按照非主键列建立的B+树需要一次回表操作才可以定位到完整的用户记录,所以这种B+树也被称为二级索引,或者辅助索引。由于使用的是c2列的大小作为B+树的排序规则,所以我们也称这个B+树为c2列简历的索引。
非聚簇索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个非聚簇索引。
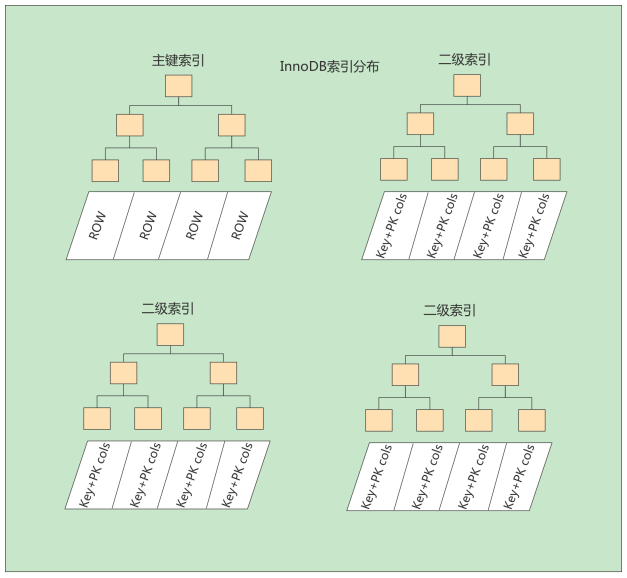
小结:聚簇索引与非聚簇索引的原理不同,在使用上也有一些区别:
- 聚簇索引的
叶子节点存储的就是我们的数据记录, 非聚簇索引的叶子节点存储的是数据位置。非聚簇索引不会影响数据表的物理存储顺序。 - 一个表
只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引,也就是多个索引目录提供数据检索。 - 使用聚簇索引的时候,数据的
查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚簇索引低。
3.联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按 照 c2和c3列 的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照c2列进行排序。
- 在记录的c2列相同的情况下,采用c3列进行排序
为c2和c3建立的索引的示意图如下:
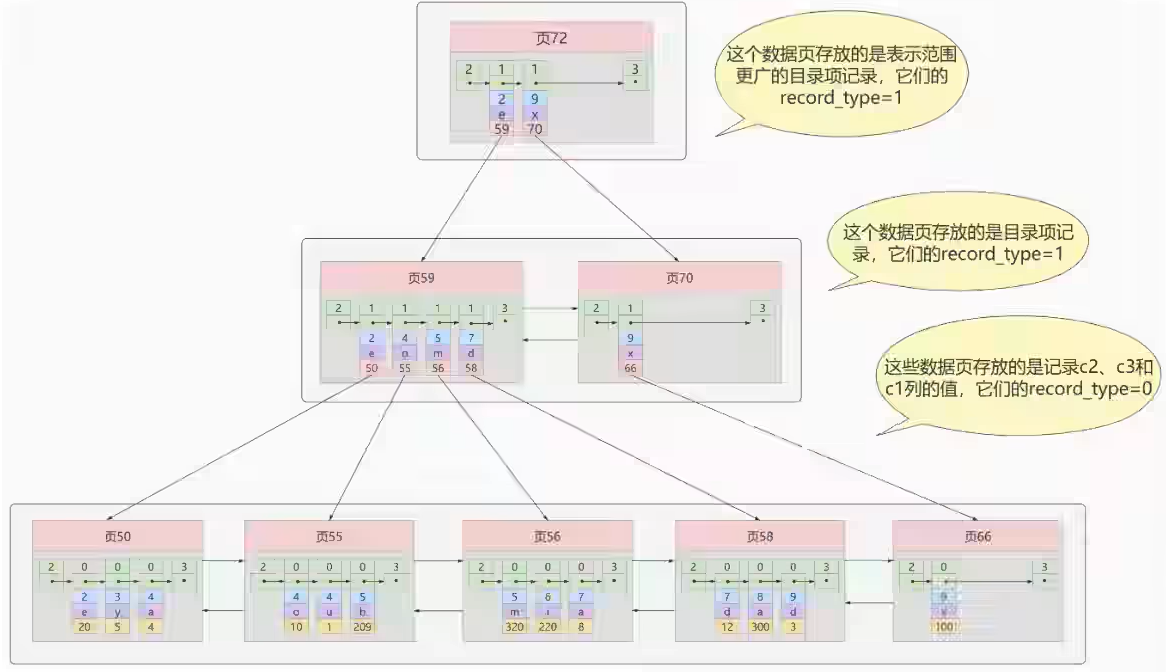
如图所示,我们需要注意以下几点:
- 每条目录项都有c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序
- B+树叶子节点处的用户记录由c2、c3和主键c1列组成
注意一点,以c2和c3列的大小为排序规则建立的B+树称为 联合索引 ,本质上也是一个二级索引。它的意 思与分别为c2和c3列分别建立索引的表述是不同的,不同点如下:
- 建立 联合索引 只会建立如上图一样的1棵B+树。
- 为c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。
3.4 InnoDB的B+树索引的注意事项
1. 根页面位置万年不动
实际上B+树的形成过程是这样的:
- 每当为某个表创建一个B+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个
根结点页面。最开始表中没有数据的时候,每个B+树索引对应的根结点中即没有用户记录,也没有目录项记录。 - 随后向表中插入用户记录时,先把用户记录存储到这个
根节点中。 - 当根节点中的可用
空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。
这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建议一个索引,那么它的根节点的页号便会被记录到某个地方。然后凡是 InnoDB 存储引擎需要用到这个索引的时候,都会从哪个固定的地方取出根节点的页号,从而来访问这个索引。
2. 内节点中目录项记录的唯一性
我们知道B+树索引的内节点中目录项记录的内容是 索引列 + 页号 的搭配,但是这个搭配对于二级索引来说有点不严谨。还拿 index_demo 表为例,假设这个表中的数据是这样的:
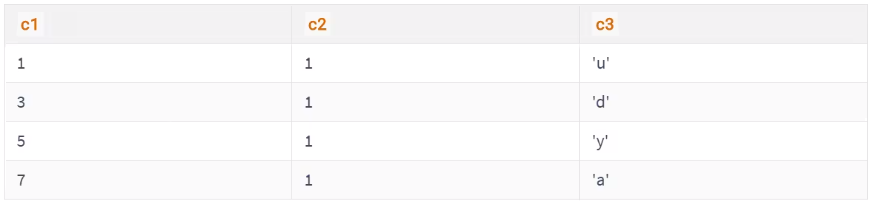
如果二级索引中目录项记录的内容只是 索引列 + 页号 的搭配的话,那么为 c2 列简历索引后的B+树应该长这样:
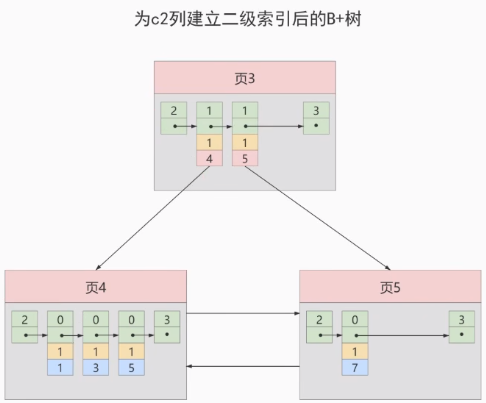
如果我们想新插入一行记录,其中 c1 、c2 、c3 的值分别是: 9、1、c, 那么在修改这个为 c2 列建立的二级索引对应的 B+ 树时便碰到了个大问题:由于 页3 中存储的目录项记录是由 c2列 + 页号 的值构成的,页3 中的两条目录项记录对应的 c2 列的值都是1,而我们 新插入的这条记录 的 c2 列的值也是 1,那我们这条新插入的记录到底应该放在 页4 中,还是应该放在 页5 中?答案:对不起,懵了
为了让新插入记录找到自己在那个页面,我们需要保证在B+树的同一层页节点的目录项记录除页号这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
也就是我们把主键值也添加到二级索引内节点中的目录项记录,这样就能保住 B+ 树每一层节点中各条目录项记录除页号这个字段外是唯一的,所以我们为c2建立二级索引后的示意图实际上应该是这样子的:
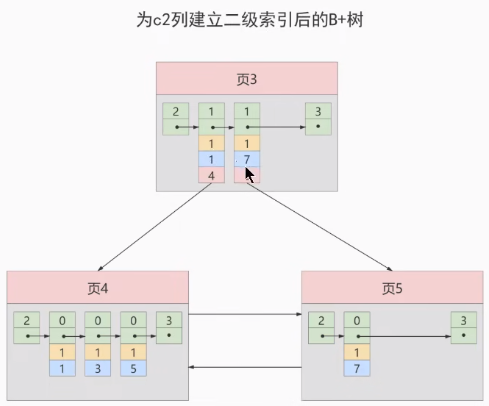
这样我们再插入记录(9, 1, 'c') 时,由于 页3 中存储的目录项记录是由 c2列 + 主键 + 页号 的值构成的,可以先把新纪录的 c2 列的值和 页3 中各目录项记录的 c2 列的值作比较,如果 c2 列的值相同的话,可以接着比较主键值,因为B+树同一层中不同目录项记录的 c2列 + 主键的值肯定是不一样的,所以最后肯定能定位唯一的一条目录项记录,在本例中最后确定新纪录应该被插入到 页5 中。
3. 一个页面最少存储 2 条记录
一个B+树只需要很少的层级就可以轻松存储数亿条记录,查询速度相当不错!这是因为B+树本质上就是一个大的多层级目录,每经过一个目录时都会过滤掉许多无效的子目录,直到最后访问到存储真实数据的目录。那如果一个大的目录中只存放一个子目录是个啥效果呢?那就是目录层级非常非常多,而且最后的那个存放真实数据的目录中只存放一条数据。所以 InnoDB 的一个数据页至少可以存放两条记录。
4. MyISAM中的索引方案
B树索引使用存储引擎如表所示:
| 索引 / 存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| B-Tree索引 | 支持 | 支持 | 支持 |
即使多个存储引擎支持同一种类型的索引,但是他们的实现原理也是不同的。Innodb和MyISAM默认的索 引是Btree索引;而Memory默认的索引是Hash索引。
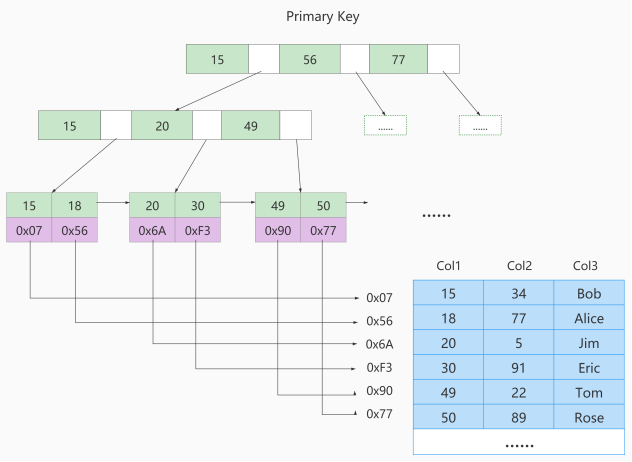
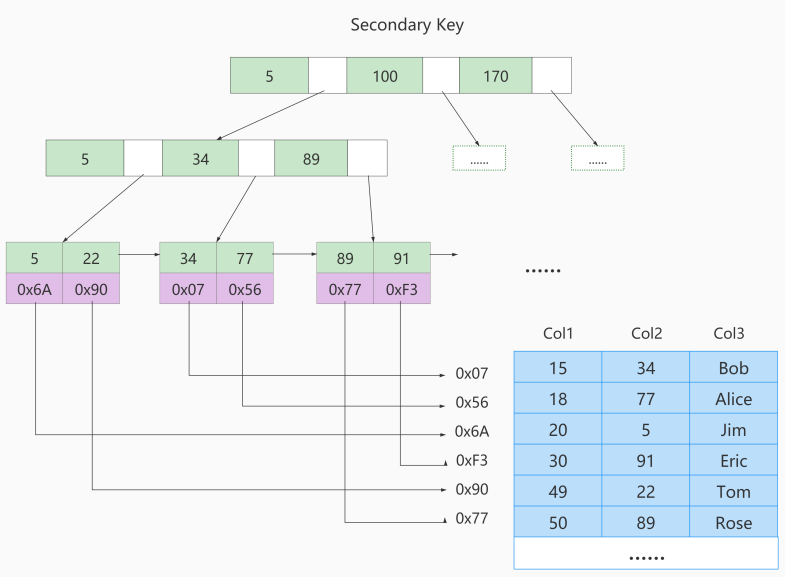
MyISAM引擎使用 B+Tree 作为索引结构,叶子节点的data域存放的是 数据记录的地址 。
4.1 MyISAM索引的原理



4.2 MyISAM 与 InnoDB对比
MyISAM的索引方式都是“非聚簇”的,与InnoDB包含1个聚簇索引是不同的。小结两种引擎中索引的区别:
① 在InnoDB存储引擎中,我们只需要根据主键值对 聚簇索引 进行一次查找就能找到对应的记录,而在 MyISAM 中却需要进行一次 回表 操作,意味着MyISAM中建立的索引相当于全部都是 二级索引 。
② InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是 分离的 ,索引文件仅保存数 据记录的地址。
③ InnoDB的非聚簇索引data域存储相应记录 主键的值 ,而MyISAM索引记录的是 地址 。换句话说, InnoDB的所有非聚簇索引都引用主键作为data域。
④ MyISAM的回表操作是十分 快速 的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通 过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。
⑤ InnoDB要求表 必须有主键 ( MyISAM可以没有 )。如果没有显式指定,则MySQL系统会自动选择一个 可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐 含字段作为主键,这个字段长度为6个字节,类型为长整型。
小结:

5. 索引的代价
索引是个好东西,可不能乱建,它在空间和时间上都会有消耗:
-
空间上的代价
每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会 占用 16KB 的存储空间,一棵很大的B+树由许多数据页组成,那就是很大的一片存储空间。
-
时间上的代价
每次对表中的数据进行 增、删、改 操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每 层节点都是按照索引列的值 从小到大的顺序排序 而组成了 双向链表 。不论是叶子节点中的记录,还 是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序 而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需 要额外的时间进行一些 记录移位 , 页面分裂 、 页面回收 等操作来维护好节点和记录的排序。如果 我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,会给性能拖后腿。
一个表上索引建的越多,就会占用越多的存储空间,在增删改记录的时候性能就越差。为了能建立又好又少的索引,我们得学学这些索引在哪些条件下起作用的。
6. MySQL数据结构选择的合理性

6.1 全表查询
这里都懒得说了。
6.2 Hash查询

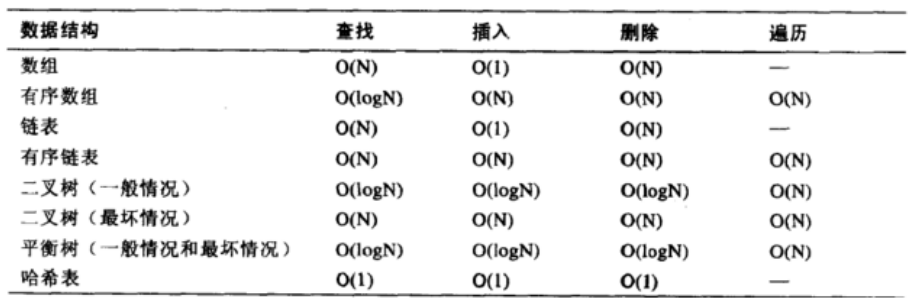
加快查找速度的数据结构,常见的有两类:
(1) 树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是 O(log2N);
(2)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是 O(1); (key, value)

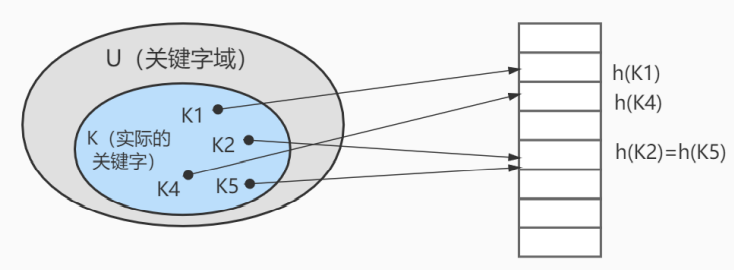
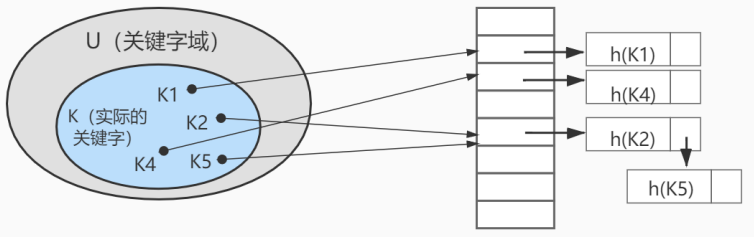
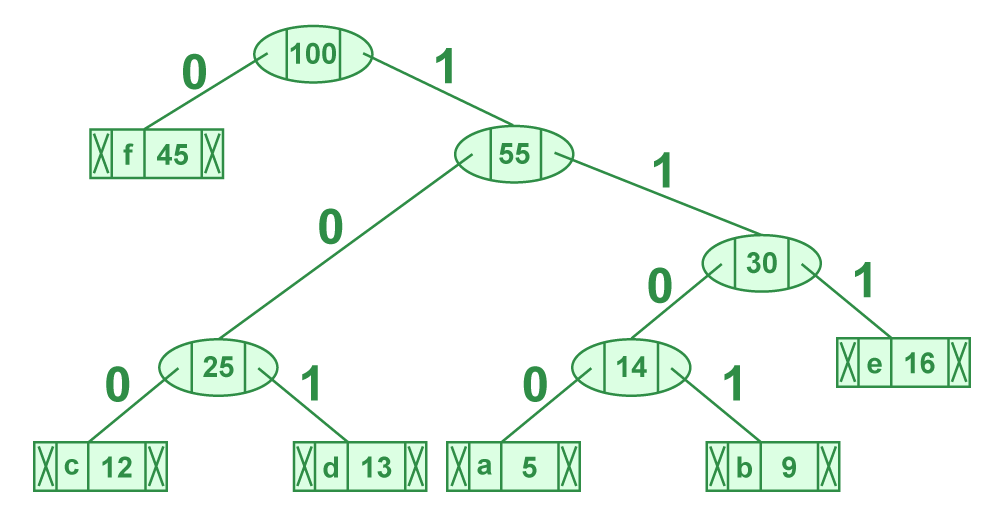
上图中哈希函数h有可能将两个不同的关键字映射到相同的位置,这叫做 碰撞 ,在数据库中一般采用 链 接法 来解决。在链接法中,将散列到同一槽位的元素放在一个链表中,如下图所示:
实验:体会数组和hash表的查找方面的效率区别
// 算法复杂度为 O(n)
@Test
public void test1(){int[] arr = new int[100000];for(int i = 0;i < arr.length;i++){arr[i] = i + 1;}long start = System.currentTimeMillis();for(int j = 1; j<=100000;j++){int temp = j;for(int i = 0;i < arr.length;i++){if(temp == arr[i]){break;}}}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 823
}
// 算法复杂度为 O(1)
@Test
public void test2(){HashSet<Integer> set = new HashSet<>(100000);for(int i = 0;i < 100000;i++){set.add(i + 1);}long start = System.currentTimeMillis();for(int j = 1; j<=100000;j++) {int temp = j;boolean contains = set.contains(temp);}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 5
}
Hash结构效率高,那为什么索引结构要设计成树型呢?

Hash索引适用存储引擎如表所示:
| 索引 / 存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| HASH索引 | 不支持 | 不支持 | 支持 |
Hash索引的适用性:

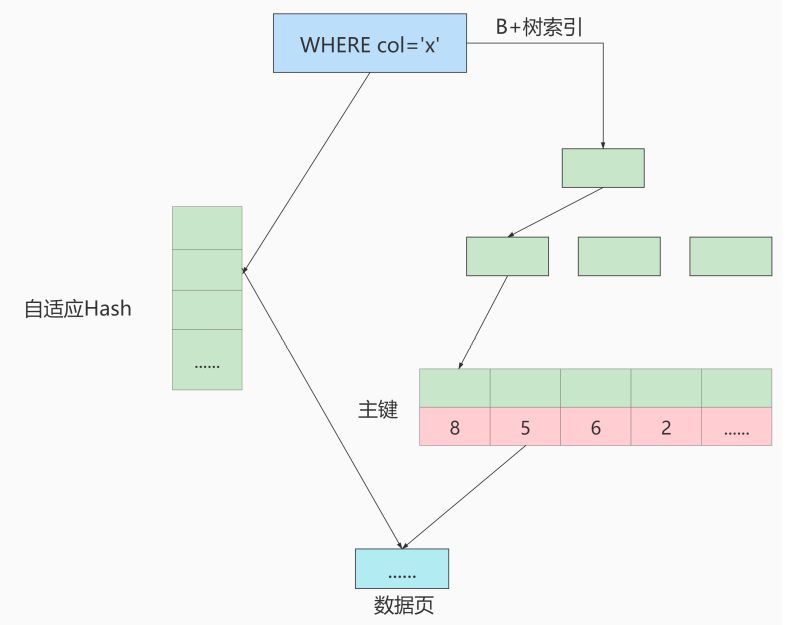
采用自适应 Hash 索引目的是方便根据 SQL 的查询条件加速定位到叶子节点,特别是当 B+ 树比较深的时 候,通过自适应 Hash 索引可以明显提高数据的检索效率。
我们可以通过 innodb_adaptive_hash_index 变量来查看是否开启了自适应 Hash,比如:
mysql> show variables like '%adaptive_hash_index';
6.3 二叉搜索树
如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。
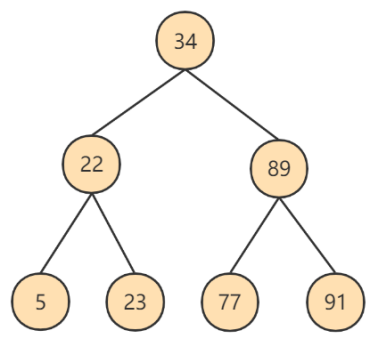
1. 二叉搜索树的特点
- 一个节点只能有两个子节点,也就是一个节点度不能超过2
- 左子节点 < 本节点; 右子节点 >= 本节点,比我大的向右,比我小的向左
2. 查找规则

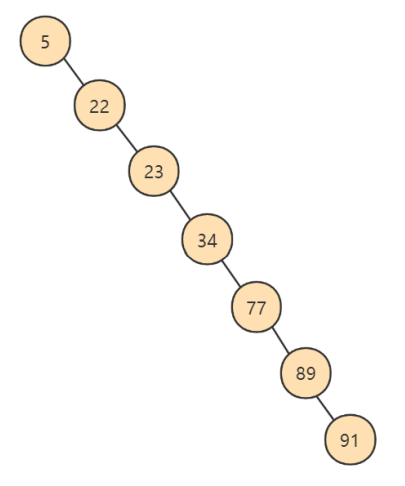
但是特殊情况,就是有时候二叉树的深度非常大,比如:
为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把 原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
6.4 AVL树

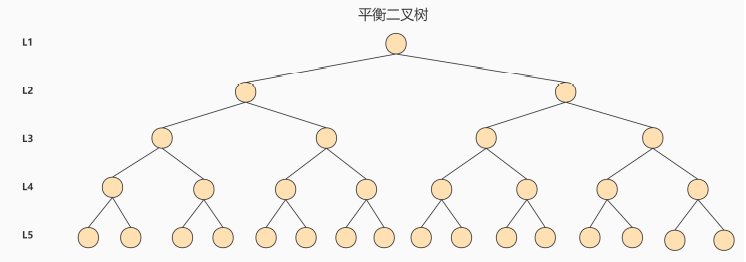
`每访问一次节点就需要进行一次磁盘 I/O 操作,对于上面的树来说,我们需要进行 5次 I/O 操作。虽然平衡二叉树的效率高,但是树的深度也同样高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面 的三叉树来进行存储:
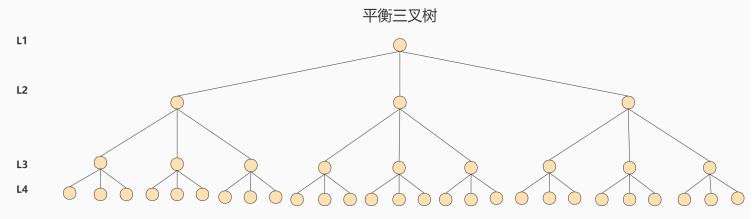
你能看到此时树的高度降低了,当数据量 N 大的时候,以及树的分叉树 M 大的时候,M叉树的高度会远小于二叉树的高度 (M > 2)。所以,我们需要把 `树从“瘦高” 变 “矮胖”。
6.5 B-Tree
B 树的英文是 Balance Tree,也就是 多路平衡查找树。简写为 B-Tree。它的高度远小于平衡二叉树的高度。
B 树的结构如下图所示:
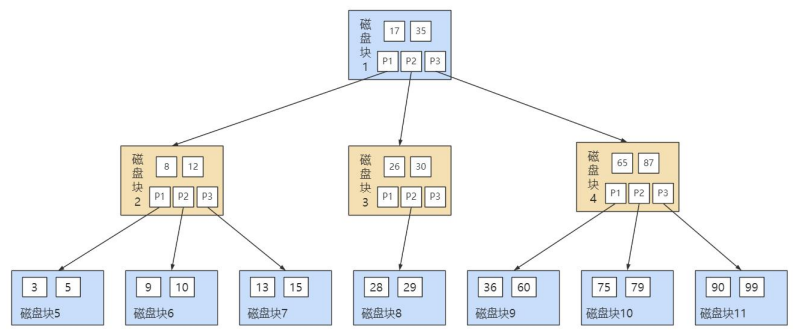

一个 M 阶的 B 树(M>2)有以下的特性:
- 根节点的儿子数的范围是 [2,M]。
- 每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为 [ceil(M/2), M]。
- 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。
- 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i]<Key[i+1]。此时 k-1 个关键字相当于划分了 k 个范围,也就是对应着 k 个指针,即为:P[1], P[2], …, P[k],其中 P[1] 指向关键字小于 Key[1] 的子树,P[i] 指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k] 指向关键字大于 Key[k-1] 的子树。
- 所有叶子节点位于同一层。
上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它 有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15) 大于 12,刚好符合刚才我们给出的特征。
然后我们来看下如何用 B 树进行查找。假设我们想要 查找的关键字是 9 ,那么步骤可以分为以下几步:
- 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
- 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
- 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比 较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行 比较所需要的时间要多,是数据查找用时的重要因素。 B 树相比于平衡二叉树来说磁盘 I/O 操作要少 , 在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。

再举例1:
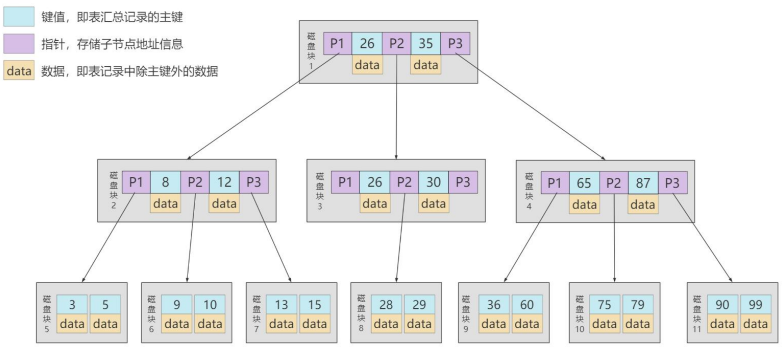
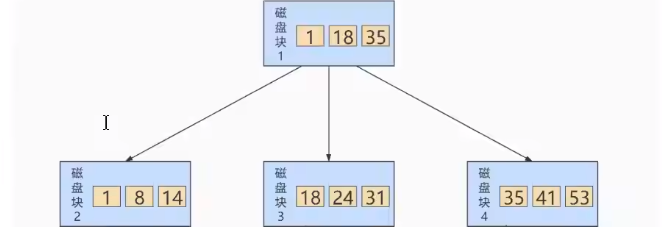
6.6 B+Tree

- MySQL官网说明:

B+ 树和 B 树的差异在于以下几点:
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最 小)。
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非 叶子节点既保存索引,也保存数据记录 。
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大 小从小到大顺序链接。



B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树。 但B树和B+树各有自己的应用场景,不能说B+树完全比B树好,反之亦然。
思考题:为了减少IO,索引树会一次性加载吗?

思考题:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO

思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?

思考题:Hash 索引与 B+ 树索引的区别

思考题:Hash 索引与 B+ 树索引是在建索引的时候手动指定的吗?

6.7 R树
R-Tree在MySQL很少使用,仅支持 geometry数据类型 ,支持该类型的存储引擎只有myisam、bdb、 innodb、ndb、archive几种。举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果 没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记 录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满 足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌、百度 地图这种超大数据库中,这种方法便必定不可行了。R树就很好的 解决了这种高维空间搜索问题 。它把B 树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解 结点的方法,保证树的平衡性。因此,R树就是一棵用来 存储高维数据的平衡树 。相对于B-Tree,R-Tree 的优势在于范围查找。
| 索引 / 存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| R-Tree索引 | 支持 | 支持 | 不支持 |
6.8 小结

附录:算法的时间复杂度
同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在 于选择合适算法和改进算法。
相关文章:
第06章_索引的数据结构
第06章_索引的数据结构 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目…...

不确定的市场,确定的增长,海尔智家2022全球再逆增
文|螳螂观察 作者| 余一 上市公司2022年年报逐渐进入密集披露期,在当前的年报季窗口,各家公司的业绩情况被高度关注。 3月30日晚,海尔智家发布了2022年财报。财报显示,2022年海尔智家实现收入2435.14亿元,同比增长7…...

测试老鸟手把手教你python接口自动化测试项目实战演示
目录 前言 一、项目准备 二、项目流程 三、完整代码 四、总结 前言 在进行接口自动化测试项目实战之前,我们需要先了解什么是接口自动化测试。接口自动化测试是通过自动化脚本模拟用户请求和服务器响应的过程,以检测接口是否符合预期,确…...
一起来学5G终端射频标准(Coherent UL-MIMO测试要求)
01 — Coherent UL-MIMO测试要求 首先什么是Coherent?它的英文释义是:(of ideas, thoughts, argument, theory, or policy) logical and consistent,翻译过来就是:(看法、思想、论证、理论或政策等&…...

计算广告(五)
Nobid Nobid(在某手有时也叫MCB,在Facebook叫Lowest Cost)是指广告主不用(也不能)对转化成本进行出价,而是出一个预算(大多数是日预算),然后投放平台的目标是在时间范围…...
排序输入的高效霍夫曼编码 | 贪心算法 3
前面我们讲到了 贪心算法的哈夫曼编码规则,原理图如下: 如果我们知道给定的数组已排序(按频率的非递减顺序),我们可以在 O(n) 时间内生成霍夫曼代码。以下是用于排序输入的 O(n) 算法。1.创建两个空队列。2.为每个唯一…...

奇异值分解(SVD)和图像压缩
在本文中,我将尝试解释 SVD 背后的数学及其几何意义,还有它在数据科学中的最常见的用法,图像压缩。 奇异值分解是一种常见的线性代数技术,可以将任意形状的矩阵分解成三个部分的乘积:U、S、V。原矩阵A可以表示为&#…...

Java如何从yml文件获取对象
目录一、背景二、application.yml三、ChinaPersonFactory.java四、使用示例一、背景 在 SpringBoot 中,我们可以使用 Value 注解从属性文件(例如 application.yml 或 application.properties)中获取配置信息,但是只能获取简单的字…...
vue使用tinymce实现富文本编辑器
安装两个插件tinymce和 tinymce/tinymce-vue npm install tinymce5.10.3 tinymce/tinymce-vue5.0.0 -S 注意: tinymce/tinymce-vue 是对tinymce进行vue的包装,主要作用当作vue组件使用-S保存到package.json文件 2. 把node_modules/tinymce下的目录&a…...

yolov4实战训练数据
1、克隆项目文件 项目Github地址:https://github.com/AlexeyAB/darknet 打开终端,克隆项目 git clone https://github.com/AlexeyAB/darknet.git无法克隆的话,把https修改为git git clone git://github.com/AlexeyAB/darknet.git修改Makef…...

第十四章 DOM的Diff算法与key
React使用Diff算法来比较虚拟DOM树和真实DOM树之间的差异,并仅更新必要的部分,以提高性能。key的作用是在Diff算法中帮助React确定哪些节点已更改,哪些节点已添加或删除。 我们以案例来说明。 使用索引值和唯一ID作为key的效果 1、使用索引…...

MySQL调优
MySQL调优常见的回答如何回答效果更好业务层的优化如果只能用mysql该如何优化代码层的优化SQL层面优化总结常见的回答 SQL层面的优化——创建索引,创建联合索引,减少回表。再有就是少使用函数查询。 回表指的是数据库根据索引(非主键&#…...
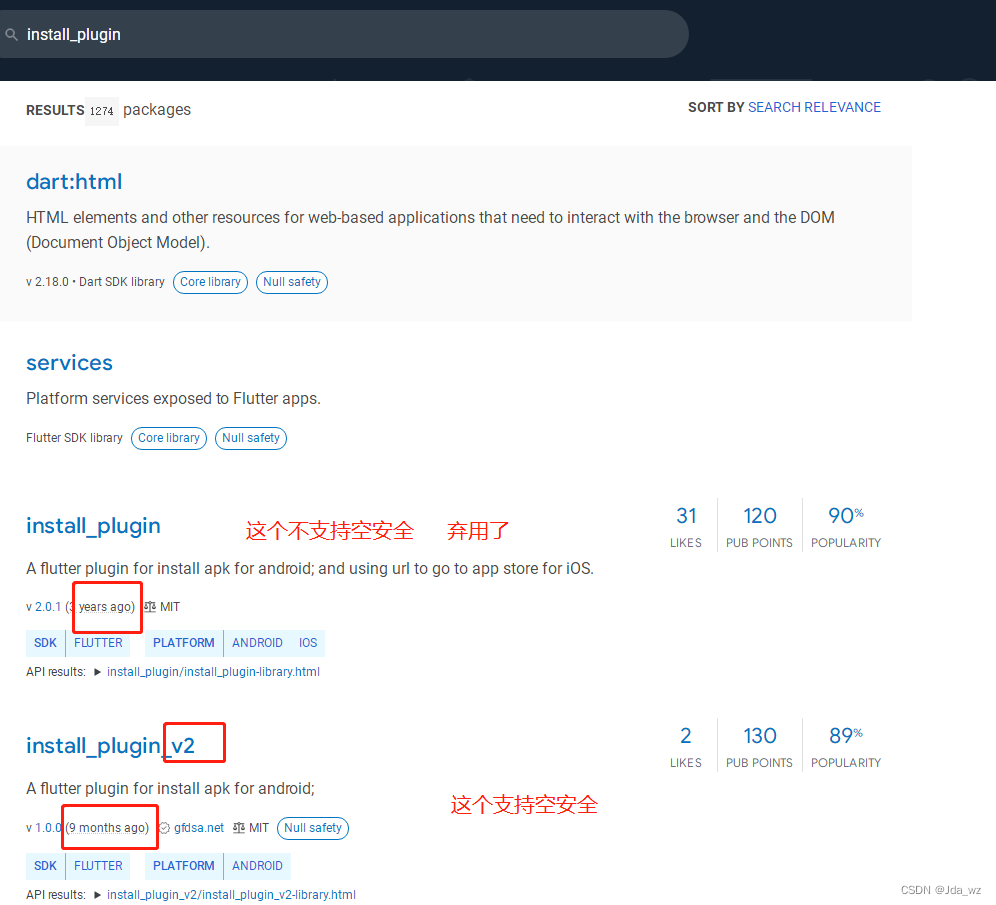
《Flutter进阶》flutter升级空安全遇到的一些问题及解决思路
空安全出来挺久了,由于业务需求较紧,一直没时间去升级空安全,最近花了几天去升级,发现其实升级也挺简单的,不要恐惧,没有想象中的多BUG。 flutter版本从1.22.4升到3.0.5; compileSdkVersion从1…...

最值得入手的五款骨传导耳机,几款高畅销的骨传导耳机
骨传导耳机是一种声音传导方式,主要通过颅骨、骨骼把声波传递到内耳,属于非入耳式的佩戴方式。相比传统入耳式耳机,骨传导耳机不会堵塞耳道,使用时可以开放双耳,不影响与他人的正常交流。骨传导耳机不会对耳朵产生任何…...
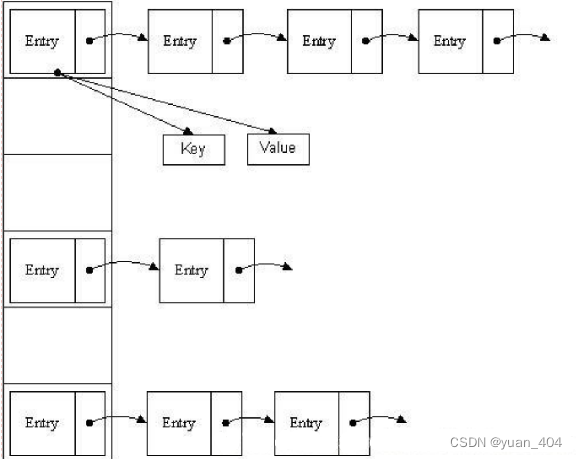
HashMap源码分析 (1.基础入门) 学习笔记
本章为 《HashMap全B站最细致源码分析课程》 拉钩教育HashMap 学习笔记 文章目录1. HashMap的数据结构1. 数组2. 链表3. 哈希表3.1 Hash1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。 1. 数组 在生成数组的时候数…...

6 使用强制类型转换的注意事项
概述 在C语言中,强制类型转换是通过直接转换为特定类型的方式来实现的,类似于下面的代码。 float fNumber = 66.66f; // C语言的强制类型转换 int nData = (int)fNumber; 这种方式可以在任意两个类型间进行转换,太过随意和武断,很容易带来一些难以发现的隐患和问题。C++为…...

Leetcode.939 最小面积矩形
题目链接 Leetcode.939 最小面积矩形 Rating : 1752 题目描述 给定在 xy平面上的一组点,确定由这些点组成的矩形的最小面积,其中矩形的边平行于 x 轴和 y 轴。 如果没有任何矩形,就返回 0。 示例 1: 输入࿱…...
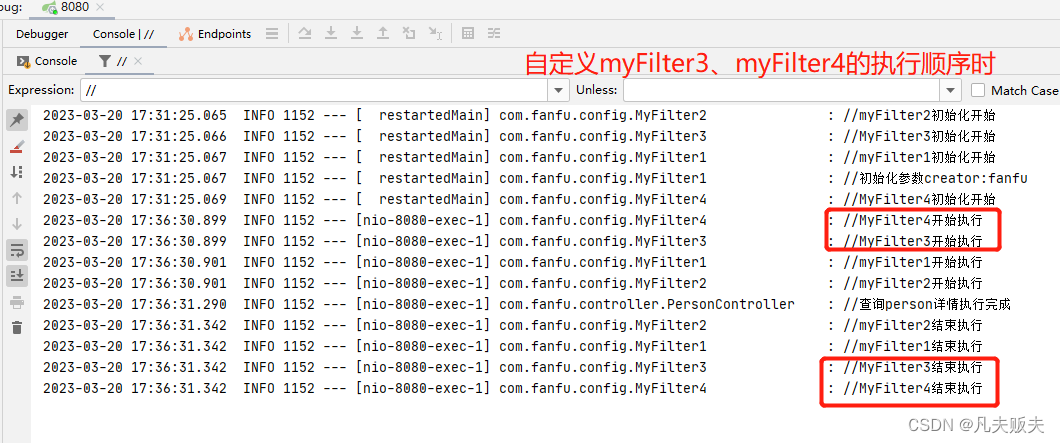
Springboot项目快速实现过滤器功能
前言很多时候,当你以为掌握了事实真相的时间,如果你能再深入一点,你可能会发现另外一些真相。比如面向切面编程的最佳编程实践是AOP,AOP的主要作用就是可以定义切入点,并在切入点纵向织入一些额外的统一操作࿰…...
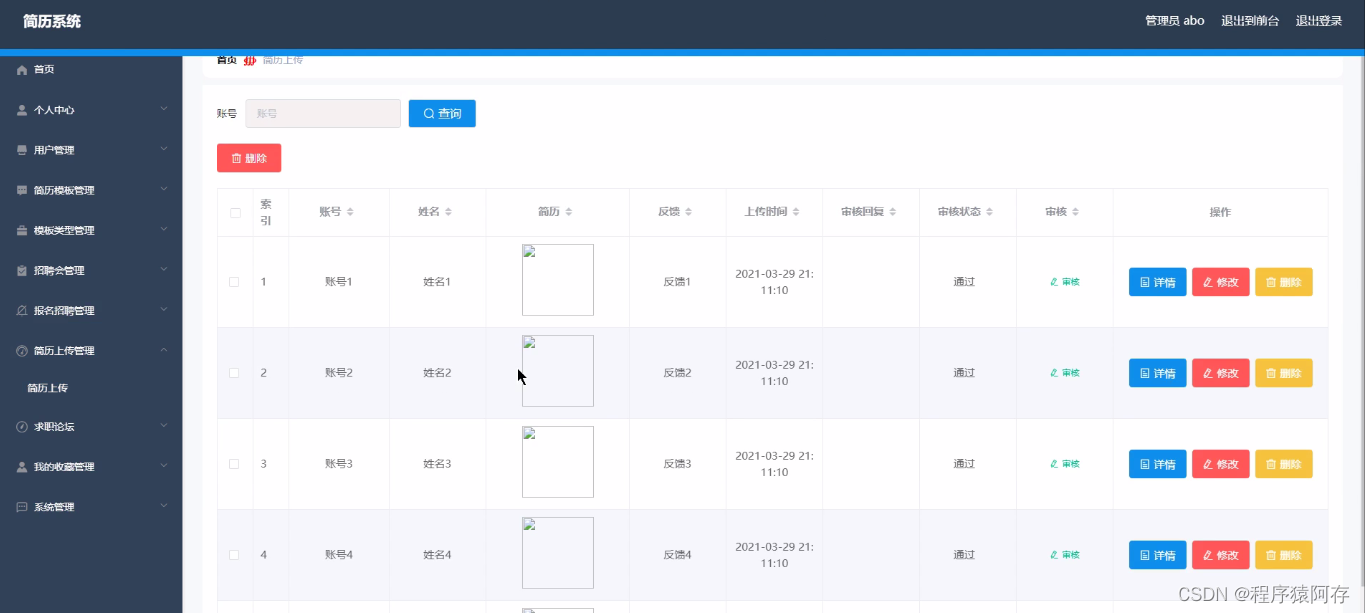
基于springboot的简历系统的实现
摘 要 随着科学技术的飞速发展,社会的方方面面、各行各业都在努力与现代的先进技术接轨,通过科技手段来提高自身的优势,简历系统当然也不能排除在外。简历系统是以实际运用为开发背景,运用软件工程原理和开发方法,采用…...

Vue3中watch的用法
watch函数用于侦听某个值的变化,当该值发生改变后,触发对应的处理逻辑。 一、watch的基本实例 <template><div><div>{{ count }}</div><button click"changCount">更改count的值</button></div> …...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

如何安全备份微信聊天记录:PyWxDump工具使用全指南
如何安全备份微信聊天记录:PyWxDump工具使用全指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 你是否曾因误删重要微信对话而懊悔不已?是否想永久保存珍贵聊天记录却不知从何下手?Py…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案
如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载缓慢而烦恼…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践
终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信作为国内主流的证券…...

智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南
智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树平台的繁琐操作而烦恼吗&#…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

智能GUI自动化:从SAG架构到实战部署的完整指南
1. 项目概述与核心价值最近在开源社区里,我注意到一个挺有意思的项目,叫openclaw-skill-sag。乍一看这个标题,可能会觉得有点抽象,但如果你对自动化、机器人流程自动化(RPA)或者智能体(Agent&am…...