基于深度学习的点云处理模型PointNet++学习记录
前面我们已经学习了Open3D,并掌握了其相关应用,但我们也发现对于一些点云分割任务,我们采用聚类等方法的效果似乎并不理想,这时,我们可以想到在深度学习领域是否有相关的算法呢,今天,我们便来学习一个在点云处理领域具有代表性的算法:PointNet++。
PointNet
在学习PointNet++前,我们需要学习以下它的前身:PointNet。
我们知道,点云数据具有以下特点:
- 无序性:点云的位置可以随意调换没有影响(点与点之间可以换)
- 近密远疏:扫描视角不同导致点云的稀疏性不同
- 非结构化数据:处理困难,如
NLP的处理就要比图像复杂
那么针对这种问题,该如何解决呢,其实最主要的是我们要去提取特征。
思路:对于无序性的数据,我们要考虑能否利用置换不变性来解决问题,PointNet便是采用这个思路,即对于点云数据求最值(无论是max、min还是sum,它都与点的位置没有关系)。
同时,由于点云一般只有三维(xyz),其维度太少,因此可以利用神经网络(多层感知机、全连接网络等)来升维,进而再进行处理。
下图为PointNet网络结构,其中里面的input_transform我们无需太过在意,可以看到,其输入的是所有点云,随后进行维度变换,最终输出分类或分割结果。

PointNet++网络介绍
根据其论文中给出的介绍,Point++是用于点云分割与分类的深度学习模型,由下图可知,该模型主要分为三部分,分别是点空间特征提取、分割模型以及分类模块。其中,Hierarchical Point set feature learning 由一系列点集抽象层(set abstraction)组成,而每一个set abstraction 又由三个关键层组成:sampling layer,Grouping layer,PointNet Layer。

- Sampling layer:Sampling layer的作用是从点云中选择很多个质点和围绕在这些质点的局部区域。作为输入,通过使用FPS算法(
farthest point sampling,最远点采样法)选出一系列点作为质点,与随机选取相比,这样可以更好的覆盖整个点集空间。 - Grouping layer:这一层使用Ball query方法生成N’个局部区域,根据论文中的意思,这里有两个变量 ,一个是每个区域中点的数量K,另一个是球的半径。这里半径应该是占主导的,会在某个半径的球内找点,上限是K。球的半径和每个区域中点的数量都是人指定的。这一步也可以使用KNN来进行,而且两者的对于结果的影响并不大。
- PointNet layer:输入为N’xKx(d+C),输出为N’x(d+C’),这里C’为局部特征的长度,应该是大于C的。这一步主要是将K个局部区域内的点的坐标转换为相对该区域中心点的坐标,并作为PointNet的输入,得到局部特征。
事实上,PointNet++相较于PointNet的创新便是在于数据的处理,其采用了分簇、分组的方式进行处理,这可以大幅减少计算量(PointNet是将所有点云输入PointNet网络,PointNet++是将数据分簇分组后输入PointNet网络)
分簇与分组
在这里,分簇是为了采样,即Sampling layer,而分组则是将每个簇的数据量统一,这样才能够输入卷积网络中运算,具体的,对于分组(Grouping layer)时,如果簇中数量多,那么就按照距离中心点距离进行排序,挑选近的留下(即删除远的点),对于簇中数量少,则将复制该簇内里离中心点最近的点,缺几个则复制几次)
PointNet++项目部署
源码下载
了解了PointNet++的基本原理后,接下来我们便要部署该项目来完成我们的任务,这里,应领导要求,博主并没有使用PointNet++的官方代码(官方代码是基于Tensflow框架开发的),而是使用了Pytorch的版本。
源码下载地址
环境部署
将源码下载后,便是部署环境,PointNet++所使用的包并不多且比较通用,博主直接使用了先前的conda环境,发现可以完美运行,也就没有重新创建conda环境。
S3Dis数据集介绍
在本次实验中,由于我们要做的任务是点云分割任务,因此我们使用的数据集为S3Dis,该数据集是一个室内点云分割数据集, 共有6个区域,13个类别,共计217个小区域(办公室、会议室等)其内容如下:
13个类别

6个大区域

我们以Area_1(区域1为例),其内有会议室、走廊等多个场所

再以office_9为例,office_9.txt是整个办公室点云,Annotations内的是office_9的分割点云,如里面的桌子,椅子等

我们使用CloudCompare打开可以看到其内容,数据格式为xyzrgb格式

数据格式转换
为何要进行数据格式转换呢,因为S3DIS数据集只是存储一些点,并没有标签(标签是存储在文件名上的),而collect_indoor3d_data脚本所做的事情就是将每一个Area下的每一个场景的点和标签进行合并,并且保存为.npy格式,加速读取的速度。
生成的.npy格式的数据也有217个。

.npy文件的内容如下,其实就是转成numpy的格式,从而方便运算,其相比于原本的txt多了一个维度,即第7个维度,用于表示所属类别。
import numpy as np
data=np.load("stanford_indoor3d/Area_1_WC_1.npy")
print(data)

collect_indoor3d_data代码如下,该部分主要是完成读取点云数据,并设置点云数据的保存路径,名称等
import os
import sys
from indoor3d_util import DATA_PATH, collect_point_labelBASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)anno_paths = [line.rstrip() for line in open(os.path.join(BASE_DIR, 'meta/anno_paths.txt'))]
anno_paths = [os.path.join(DATA_PATH, p) for p in anno_paths]output_folder = os.path.join(ROOT_DIR, 'data/stanford_indoor3d/')
if not os.path.exists(output_folder):os.mkdir(output_folder)# Note: there is an extra character in the v1.2 data in Area_5/hallway_6. It's fixed manually.
for anno_path in anno_paths:print(anno_path)try:elements = anno_path.split('/')out_filename = elements[-3]+'_'+elements[-2]+'.npy' # Area_1_hallway_1.npycollect_point_label(anno_path, os.path.join(output_folder, out_filename), 'numpy')except:print(anno_path, 'ERROR!!')
具体的,划分点云中的标签是通过collect_point_label方法实现的,事实上,我们并不需要读懂这部分代码,要想完成数据转换,只需要将我们的数据格式转换成与S3Dis数据集一样即可。
def collect_point_label(anno_path, out_filename, file_format='txt'):""" Convert original dataset files to data_label file (each line is XYZRGBL).We aggregated all the points from each instance in the room.Args:anno_path: path to annotations. e.g. Area_1/office_2/Annotations/out_filename: path to save collected points and labels (each line is XYZRGBL)file_format: txt or numpy, determines what file format to save.Returns:NoneNote:the points are shifted before save, the most negative point is now at origin."""points_list = []for f in glob.glob(os.path.join(anno_path, '*.txt')):cls = os.path.basename(f).split('_')[0]print(f)if cls not in g_classes: # note: in some room there is 'staris' class..cls = 'clutter'points = np.loadtxt(f)labels = np.ones((points.shape[0],1)) * g_class2label[cls]points_list.append(np.concatenate([points, labels], 1)) # Nx7data_label = np.concatenate(points_list, 0)xyz_min = np.amin(data_label, axis=0)[0:3]data_label[:, 0:3] -= xyz_minif file_format=='txt':fout = open(out_filename, 'w')for i in range(data_label.shape[0]):fout.write('%f %f %f %d %d %d %d\n' % \(data_label[i,0], data_label[i,1], data_label[i,2],data_label[i,3], data_label[i,4], data_label[i,5],data_label[i,6]))fout.close()elif file_format=='numpy':np.save(out_filename, data_label)else:print('ERROR!! Unknown file format: %s, please use txt or numpy.' % \(file_format))exit()
训练PointNet++网络
首先是模型选择,我们这里可以看到model中可供我们选择的模型,其中加了msg的代表使用了多尺度特征,其效果要比不加的好,当然,其网络也会更复杂一些,我们使用的是pointnet2_sem_seg_msg
parser.add_argument('--model', type=str, default='pointnet2_sem_seg_msg', help='model name [default: pointnet_sem_seg]')

选择使用的测试集,这里默认为Area_5
parser.add_argument('--test_area', type=int, default=5, help='Which area to use for test, option: 1-6 [default: 5]')
随后一些batch-size设置,epoch设置我们就不再赘述了(博主设置batch=16),同时需要注意的是需要修改以下num_workers的值,博主设置为0,这个看你服务器的性能,博主由于是在本地测试,因此也就设为0了,否则会报错:
UnpicklingError: pickle data was truncated
开启训练
加载数据集(训练集与验证集)

开启训练,输出最终的训练平均损失,以及训练平均准确度

测试模型
在测试模型时,我们指定加载的模型权重即可,即我们在训练时保存的log文件的地址:
parser.add_argument('--log_dir', type=str,default="pointnet2_sem_seg_msg", help='experiment root')
可以看到,测试数据集为Area_5

训练时的模型显卡使用情况如下:

最终的评估结果如下:

结语
本章主要介绍了PointNet++模型的结构以及部署问题,接下来便要进行模型的应用,我们需要使用自己的数据集来完成相应的任务。
相关文章:
基于深度学习的点云处理模型PointNet++学习记录
前面我们已经学习了Open3D,并掌握了其相关应用,但我们也发现对于一些点云分割任务,我们采用聚类等方法的效果似乎并不理想,这时,我们可以想到在深度学习领域是否有相关的算法呢,今天,我们便来学…...
详解以及深浅拷贝)
Javascript Object.assgin()详解以及深浅拷贝
Object.assign() 方法是 JavaScript 中用于将所有可枚举属性的值从一个或多个源对象复制到目标对象的方法。它将返回目标对象。这是一种浅拷贝,也就是说,如果源对象中的属性是一个对象或数组,那么这个属性的引用将被复制,而不是对…...
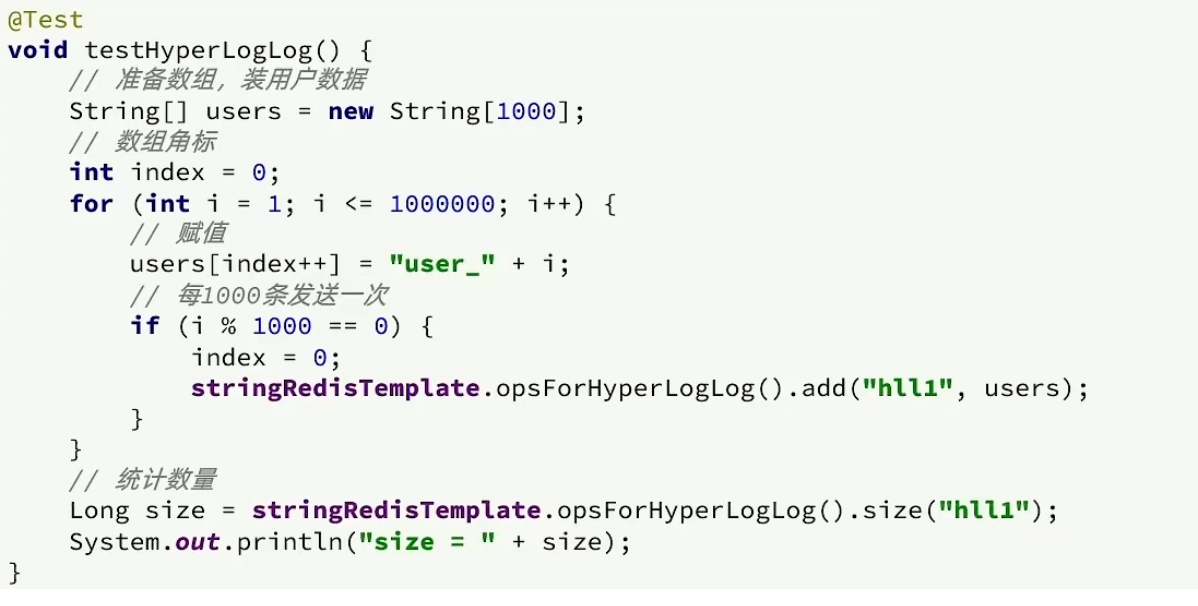
Redis篇(应用案例 - UV统计)(持续更新迭代)
目录 一、HyperLogLog 二、测试百万数据的统计 一、HyperLogLog 首先我们搞懂两个概念: UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。 1天内同一个用户多次访问该网站,只记录…...

解锁微信小程序新技能:ECharts动态折线图搭配WebSocket,数据刷新快人一步!
在微信小程序中,数据可视化展示越来越受到开发者的重视。本文将为您介绍如何在微信小程序中使用ECharts绘制折线图,并通过WebSocket实现实时更新图表数据。 一、准备工作 创建微信小程序项目 首先,我们需要创建一个微信小程序项目。如果您已…...
上交所服务器崩溃:金融交易背后的技术隐患暴露杭州BGP高防服务器43.228.71.X
一、上交所宕机事件始末 2024 年 9 月 27 日,上交所交易系统突发崩溃,这一事件犹如一颗巨石投入平静的湖面,引起了轩然大波。当天上午,众多投资者反馈券商交易出现延迟问题,随后上交所发布了《关于股票竞价交易出现异常…...

P4、P4D、HelixSwarm 各种技术问题咨询
多年大型项目P4仓库运维经验,为你解决各种部署以及标准工业化流程问题。 Perforce 官网SDPHelixCore GuideHelixSwarm GuideHelixSwarm Download...
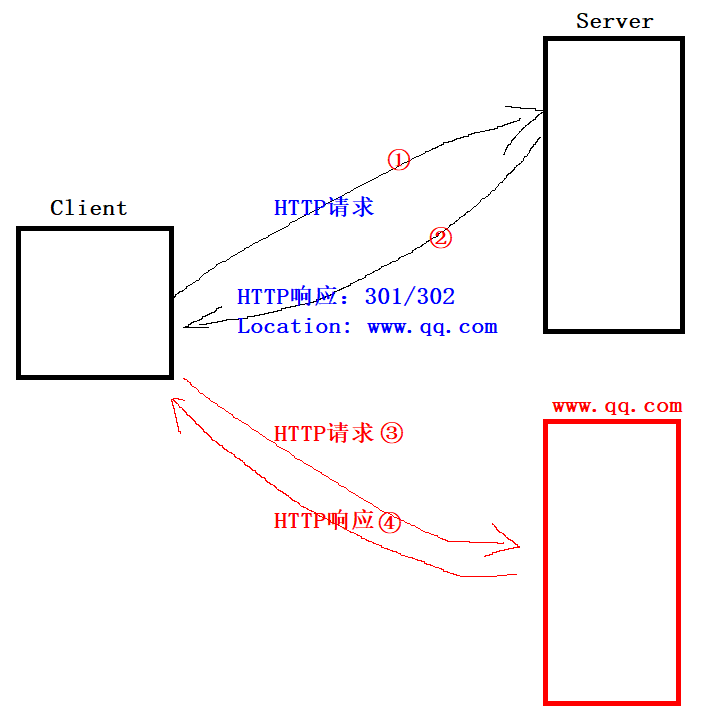
Linux 应用层协议HTTP
文章目录 一、初始HTTP协议二、URL格式网络中怎么通过URL进行定位资源呢?编码和解码 三、HTTP的请求格式和响应格式HTTP的请求格式HTTP的响应格式HTTP的请求方法GET方法POST方法GET Vs PostHTTP的封装和分用文件流操作浏览器获得一个完整的网页流程 HTTP的状态码对3…...

Python和C++混淆矩阵地理学医学物理学视觉语言模型和算法模型评估工具
🎯要点 优化损失函数评估指标海岸线检测算法评估遥感视觉表征和文本增强乳腺癌预测模型算法液体中闪烁光和切伦科夫光分离多标签分类任务性能评估有向无环图、多路径标记和非强制叶节点预测二元分类评估特征归因可信性评估马修斯相关系数对比其他准确度 Python桑…...

HTTP 协议的基本格式和 fiddler 的用法
HTTP协议格式 HTTP是⼀个⽂本格式的协议.可以通过Chrome开发者⼯具或者Fiddler抓包,分析HTTP请求/响应的细节. 抓包工具的使用 以Fiddler为例. • 左侧窗⼝显⽰了所有的HTTP请求/响应,可以选中某个请求查看详情. • 右侧上⽅显⽰了HTTP请求的报⽂内容.(切换到Raw标签⻚可以看…...

【计算机网络】详解UDP协议格式特点缓冲区
一、UDP 协议端格式 16 位 UDP 长度, 表示整个数据报(UDP 首部UDP 数据)的最大长度;如果16位UDP检验和出错,报文会被直接丢弃。 1.1、检验和出错的几种常见情况 数据传输过程中的比特翻转:在数据传输过程中,由于物理介质或网络设…...

网络安全cybersecurity的几个新领域
一、电力安全 同学们,今天我们来讨论一下为什么网络安全(Cybersecurity)和电力系统(Power Systems)这两个看似不同的领域会有交集。其实,这两个领域之间的联系非常紧密。以下我将从多个角度进行解释&#…...

android 原生加载pdf
implementation("androidx.pdf:pdf-viewer-fragment:1.0.0-alpha02") pdf加载链接...

MAE(平均绝对误差)和std(标准差)计算中需要注意的问题
一、MAE(平均绝对误差) 计算公式: yi 是第i个实际值y^i 是第i个预测值 计算方法: MAE就是求实际值与预测值之间的误差,需要给出预测值和原始的实际值 二、std(标准差) 计算公式&#x…...

03实战篇:把握667分析题的阅读材料、题目
本节你将学习到: 如何快速识别阅读材料的有效信息如何把握题目的作答方向 在正式进入具体的实战之前,我想先来讲一讲如何利用给定阅读材料、如何分析题目来确保不偏题等基础性知识。 高效利用给定阅读材料的方法 根据博主的实战经验来看,阅…...

C++系列-多态
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 多态 多态就是不同类型的对象,去做同一个行为,但是产生的结果是不同的。 比如说: 都是动物叫声,猫是喵喵,狗是汪汪&am…...
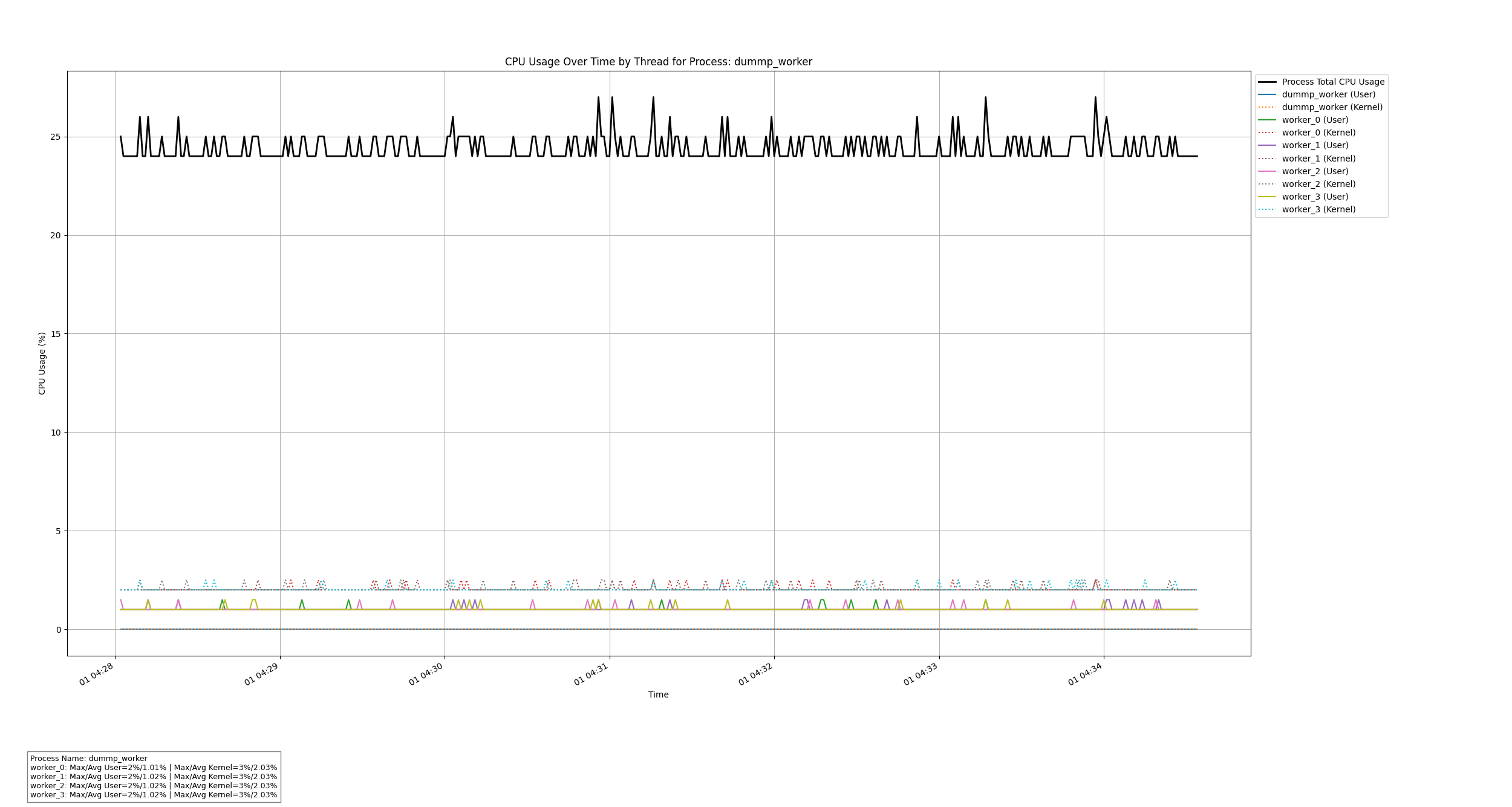
基于C++和Python的进程线程CPU使用率监控工具
文章目录 0. 概述1. 数据可视化示例2. 设计思路2.1 系统架构2.2 设计优势 3. 流程图3.1 C录制程序3.2 Python解析脚本 4. 数据结构说明4.1 CpuUsageData 结构体 5. C录制代码解析5.1 主要模块5.2 关键函数5.2.1 CpuUsageMonitor::Run()5.2.2 CpuUsageMonitor::ComputeCpuUsage(…...
fish-speech语音大模型本地部署
文章目录 fish-speech模型下载编译部署 小结 fish-speech模型 先说下fish-speech模型吧,可以先看下官网。如下: 这就是一个模型,可以根据一个样例声音,构建出自己需要的声音。其实,这个还是有很多用途的;…...

如何写出更牛的验证激励
前言 芯片验证是为了发现芯片中的错误而执行的过程,它是一个破坏性的过程。完备的验证激励可以更有效地发现芯片错误,进而缩短验证周期。合格的验证激励必须能产生所有可能的验证场景(完备性),包括合法和非法的场景,并保持最大的…...
EasyCVR视频汇聚平台:解锁视频监控核心功能,打造高效安全监管体系
随着科技的飞速发展,视频监控技术已成为现代社会安全、企业管理、智慧城市构建等领域不可或缺的一部分。EasyCVR视频汇聚平台作为一款高性能的视频综合管理平台,凭借其强大的视频处理、汇聚与融合能力,在构建智慧安防/视频监控系统中展现出了…...
如何加速上传速度)
面对大文件(300G以上)如何加速上传速度
解题思路 采用分片上传,同时每个分片多线程上传可以加速上传速度,上传速度提升10倍左右 在阿里云OSS Go SDK中,bucket.UploadStream 函数并没有直接提供,而是通过 bucket.UploadFile 或者 bucket.PutObject 等函数来实现文件上传…...

ComfyUI InstantID终极指南:3步实现人脸完美保留的AI图像生成
ComfyUI InstantID终极指南:3步实现人脸完美保留的AI图像生成 【免费下载链接】ComfyUI_InstantID 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_InstantID 你是否曾经尝试过用AI生成图像,却发现生成的人物完全不像你想要的参考对象&am…...

免费激活IDM的终极解决方案:开源脚本完整指南
免费激活IDM的终极解决方案:开源脚本完整指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否经常遇到IDM(Internet Download Mana…...

企业级AI Agent安全治理:从“能用“到“敢用“的五维框
一、为什么企业需要Agent治理框架我们公司最近在帮一家制造业客户做AI Agent数字员工的落地项目。客户之前已经自己部署了一批Agent,分别处理品质查询、物料追踪、报表生成等业务。运行三个月后,IT部门发现了三个让人头疼的问题:有个Agent累计…...

高校生必备的AI论文写作软件有哪些?
国内高校学生普遍使用的AI论文写作工具,以功能全面的本土化软件为主,结合通用大模型与专业辅助工具,覆盖选题构思、框架搭建、初稿撰写、内容降重、查重检测、格式排版等关键环节,以下是主流工具详解与对比: 一、本土全…...

AI 写的鸿蒙 ArkTS 代码能跑?我测了 37 个案例,翻车率 60%
先扔结论:如果你现在把 Claude 或 Cursor 当成 ArkTS 专家来用,大概率会掉坑里。我上周闲得慌,跑了 37 个常见开发场景的测试,结果 AI 生成的代码能直接编译通过的,不到四成。剩下的要么语法错误,要么用了废…...

告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍
告别快捷键混乱!PowerToys保姆级教程:让Win键位秒变Mac,开发效率翻倍 作为一名长期在Windows和Mac双平台切换的开发者,最令人抓狂的莫过于快捷键的差异。每次从Mac切换到Windows,肌肉记忆总会在关键时刻背叛你——当你…...

掌握AMD Ryzen硬件调试:SMUDebugTool从入门到精通的完整指南
掌握AMD Ryzen硬件调试:SMUDebugTool从入门到精通的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...
)
手把手教你用STC89C52和DS1302做一个带按键调节的电子时钟(附完整代码)
从零打造可调式电子时钟:STC89C52与DS1302实战指南 在创客和电子爱好者的世界里,能够亲手制作一个功能完整的电子时钟,无疑是检验单片机编程和硬件连接能力的绝佳项目。本文将带你使用STC89C52单片机和DS1302实时时钟芯片,配合LCD…...

为什么你的Perplexity返回过时新闻?环境时区、缓存策略与源权重配置三重校准指南
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity返回过时新闻?环境时区、缓存策略与源权重配置三重校准指南 Perplexity 的实时新闻响应延迟,常被误认为模型能力缺陷,实则源于底层检索链路中三…...

基于智能体的企业级自主决策与业务运营平台解决方案:AI智能管理驾驶舱、智能管理驾驶舱的四大功能定位、总体方案蓝图、总体规划方案
该方案提出以AI大模型与智能体为核心的“智能管理驾驶舱”,通过整合企业私有数据及业务系统,实现从信息呈现、自主决策到自动执行的业务闭环。平台支持事件驱动、可视化编排与多智能体调度,覆盖生产、供应链等典型场景,旨在降低运…...