SparkSQL学习——SparkSQL配置与文件的读取与保存
目录
一、添加依赖
二、配置log4j
三、spark提交jar包
四、读取文件
(一)加载数据
(二)保存数据
1.Parquet
2.json
3.CSV
4.MySql
5.hive on spark
6.IDEA的Spark中操作Hive
一、添加依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><spark.version>3.1.2</spark.version><mysql.version>8.0.29</mysql.version></properties><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>${spark.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-graphx --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-graphx_2.12</artifactId><version>${spark.version}</version></dependency><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>二、配置log4j
src/main/resources/log4j.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR

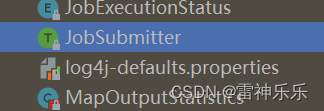
将log4j-defaults.properties复制到resources下,并重命名为log4j.properties,第19行:log4j.rootCategory=INFO, console 修改为log4j.rootCategory=ERROR, console
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}object SparkDemo {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkDemo")val sc :SparkContext= SparkContext.getOrCreate(conf)
// println(sc) // org.apache.spark.SparkContext@63998bf4val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sparkSessionDemo").getOrCreate()
// println(spark) // org.apache.spark.sql.SparkSession@682c1e93val rdd: RDD[Int] = sc.parallelize(1 to 10)rdd.collect().foreach(println)val pNum: Int = rdd.getNumPartitionsprintln("分区数量",pNum)// (分区数量,20)}
}三、spark提交jar包
[root@lxm147 opt]# spark-submit --class nj.zb.kb21.WordCount --master local[*] ./sparkstu-1.0-SNAPSHOT.jar (cjdison,1)
(spark,1)
(cdio,1)
(cjiodscn,1)
(hcuediun,1)
(hello,3)
(java,1)
(nodsn,1)
(jcido,1)
(jcndio,1)
(cjidsovn,1)
(world,1)
四、读取文件
(一)加载数据
SparkSQL 默认读取和保存的文件格式为parquetscala> spark.read. csv format jdbc json load option options orc parquet schema table text textFile如果读取不同格式的数据,可以对不同的数据格式进行设定:
scala> spark.read.format("…")[.option("…")].load("…")➢ format("…"):指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和
"textFile"。
➢ load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载
数据的路径。
➢ option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,也可以直接在文件上进行查询: 文件格式.`文件路径`
# 读取本地文件 # 方式一: spark.sql("select * from json.`file:///opt/soft/spark312/data/user.json`").show# 方式二: scala> val df = spark.read.json("file:///opt/soft/spark312/data/user.json") df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]scala> df.show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+# 读取HDFS上的文件 # 方式一: scala> spark.sql("select * from json.`hdfs://lxm147:9000/data/user.json`").show 2023-03-30 16:25:09,132 WARN metastore.ObjectStore: Failed to get database json, returning NoSuchObjectException +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+# 方式二: la> spark.read.json("hdfs://lxm147:9000/data/user.json").show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+
(二)保存数据
df.write.save 是保存数据的通用方法
scala> df.write. bucketBy formart jdbc mode options parquet save sortBy csv insertInto json option orc partitionBy saveAsTable text如果保存不同格式的数据,可以对不同的数据格式进行设定
scala>df.write.format("…")[.option("…")].save("…")➢ format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和
"textFile"。
➢ save ("…"):在"csv"、"orc"、"parquet"和"textFile"格式下需要传入保存数据的路径。
➢ option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。
有一点很重要: 这些 SaveMode 都是没有加锁的, 也不是原子操作。
SaveMode 是一个枚举类,其中的常量包括:
示例:
1.保存为指定格式文件:
scala> df.write.format("json").save("file:///opt/soft/spark312/data/output1")
如果同一个文件存储两次,会报错文件已存在
scala> df.write.format("json").save("file:///opt/soft/spark312/data/output")scala> df.write.format("json").save("file:///opt/soft/spark312/data/output") org.apache.spark.sql.AnalysisException: path file:/opt/soft/spark312/data/output already exists.at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:122)2.追加存储文件:append
scala> df.write.format("json").mode("append").save("file:///opt/soft/spark312/data/output")
3.覆盖存储文件:overwrite
scala> df.write.format("json").mode("overwrite").save("file:///opt/soft/spark312/data/output")
4.忽略原文件:ignore
scala> df.write.format("json").mode("ignore").save("file:///opt/soft/spark312/data/output")



1.Parquet
# 读取json文件
scala> spark.read.load("file:///opt/soft/spark312/examples/src/main/resources/users.parquet")
# 将json文件保存为parquet文件
scala> df1.write.mode("append").save("file:///opt/soft/spark312/data/output1")2.json
# 加载json文件
scala> val df2 = spark.read.json("file:///opt/soft/spark312/data/user.json")
df2: org.apache.spark.sql.DataFrame = [age: bigint, username: string]# 创建临时表
scala> df2.createOrReplaceTempView("user")# 数据查询
scala> spark.sql("select * from user where age > 30").show
+---+--------+
|age|username|
+---+--------+
| 40| wangwu|
+---+--------+
3.CSV
# 读取CSV文件
scala> val df = spark.read.format("csv").option("seq",";").option("inferSchema","true").option("header","true").load("file:///opt/soft/spark312/examples/src/main/resources/people.csv")
df: org.apache.spark.sql.DataFrame = [name;age;job: string]scala> df.show
+------------------+
| name;age;job|
+------------------+
|Jorge;30;Developer|
| Bob;32;Developer|
+------------------+
4.MySql
添加依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.29</version>
</dependency>package com.atguigu.bigdata.spark.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql._import java.util.Propertiesobject Spark04_SparkSQL_JDBC {def main(args: Array[String]): Unit = {// TODO 创建SparkSQL的运行环境val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._// TODO 读取MySql数据//方式 1:通用的 load 方法读取spark.read.format("jdbc").option("url", "jdbc:mysql://192.168.180.141:3306/exam").option("driver", "com.mysql.cj.jdbc.Driver").option("user", "root").option("password", "root").option("dbtable", "student").load().show()//方式 2:通用的 load 方法读取 参数另一种形式spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.180.141:3306/exam?user=root&password=root", "dbtable" -> "student", "driver" -> "com.mysql.cj.jdbc.Driver")).load().show()//方式 3:使用 jdbc 方法读取val props: Properties = new Properties()props.setProperty("user", "root")props.setProperty("password", "root")val df: DataFrame = spark.read.jdbc("jdbc:mysql://192.168.180.141:3306/exam", "users", props)df.show()// TODO 保存MySql数据df.write.format("jdbc").option("url", "jdbc:mysql://192.168.180.141:3306/exam").option("driver", "com.mysql.cj.jdbc.Driver").option("user", "root").option("password", "root").option("dbtable", "student1").mode(SaveMode.Append).save()// TODO 关闭环境spark.stop()}
}
5.hive on spark
如果想连接外部已经部署好的 Hive,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
cp /opt/soft/hive312/conf/hive-site.xml /opt/soft/spark-local/conf➢ 把 Mysql 的驱动 copy 到 jars/目录下
cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar /opt/soft/spark-local/jars➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 重启 spark-shell
scala> spark.sql("show tables").show
returning NoSuchObjectException
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
+--------+---------+-----------+# 读取本地文件
scala> val df = spark.read.json("file:///opt/soft/spark-local/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string] # 创建临时表
scala> df.createOrReplaceTempView("user")# 读取临时表
scala> spark.sql("select * from user").show
+---+--------+
|age|username|
+---+--------+
| 30|zhangsan|
| 20| lisi|
| 40| wangwu|
+---+--------++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++# 创建表并设定字段
scala> spark.sql("create table atguigu(id int)")# 读取hdfs上的文件中的数据加载到
scala> spark.sql("load data inpath '/opt/soft/hive312/warehouse/atguigu/id.txt' into table atguigu")
res5: org.apache.spark.sql.DataFrame = []# 查询默认数据库
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| atguigu| false|
| | user| true|
+--------+---------+-----------+# 查询表中的数据
scala> spark.sql("select * from atguigu").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+6.IDEA的Spark中操作Hive
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.29</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency></dependencies>相关文章:

SparkSQL学习——SparkSQL配置与文件的读取与保存
目录 一、添加依赖 二、配置log4j 三、spark提交jar包 四、读取文件 (一)加载数据 (二)保存数据 1.Parquet 2.json 3.CSV 4.MySql 5.hive on spark 6.IDEA的Spark中操作Hive 一、添加依赖 <properties><project.build.sourceEncoding>UTF-8</proje…...
, 322. 零钱兑换, 279.完全平方数)
随想录Day45--动态规划:70. 爬楼梯 (进阶), 322. 零钱兑换, 279.完全平方数
70爬楼梯这道题之前已经做过,是动态规划思想的入门,想要爬上第n层阶梯,看爬上n-1层的方法和n-2层的方法共有多少种,两个相加就是爬上n层阶梯的方法。这里扩展到每次可以爬k层,这样就是一个动态规划问题。因为每次可以爬…...

原理+案例,关于主从延迟,一篇文章给你讲明白!
前言 在生产环境中,为了满足安全性,高可用性以及高并发等方面的需求,基本上采用的MySQL数据库架构都是MHA、MGR等,最低也得是一主一从的架构,搭配自动切换脚本,实现故障自动切换。 上述架构都是通过集群主…...
QT开发笔记(Camera)
Camera 此章节例程适用于 Ubuntu 和正点原子 I.MX6U 开发板,不适用于 Windows(需要自行修改 才能适用 Windows,Windows 上的应用不在我们讨论范围)! 资源简介 正点原子 I.MX6U 开发板底板上有一路“CSI”摄像头接口。支持正点原…...
从C++的角度讲解C#容器
讲解C#容器的文章网上一搜一大把,作为一名C程序员如何高效学习C#容器呢,其实学语言如果能讲到这点就能触类旁通,举一反三,那效果是最好的问题市面上没有这样的书籍,那就跟着老白来一起从C的角度去讲解C#容器1.List<…...

React组件库实践:React + Typescript + Less + Rollup + Storybook
背景 原先在做低代码平台的时候,刚好有搭载React组件库的需求,所以就搞了一套通用的React组件库模版。目前通过这套模板也搭建过好几个组件库。 为了让这个模板更干净和通用,我把所有和低代码相关的代码都剔除了,只保留最纯粹的…...

c++ atomic
文章目录why atomic?sequentially consistent atomicRelaxed memory modelswhy atomic? 当我们有一片内存空间S,线程A正在往S里写数据,这个时候线程B突然往S中做了操作,导致线程A的操作结果变得不可预知(对线程A来说),这种情况换句话说叫做data race,我们一般的操作时上锁,在…...
要想孩子写作文没烦恼?建议家长这样做
说起语文学习,就不得不提作文。作为语文学习中的重中之重,作文写作一直是压在学生和家长身上的一块“心头大石”。发现很多孩子在写作文时,往往存在四大问题:写不出、不生动、流水账、太空洞。如今,孩子怕写作文&#…...
基于Python的高光谱图像分析教程
1、前言超光谱图像 (HSI) 分析因其在从农业到监控的各个领域的应用而成为人工智能 (AI) 研究的前沿领域之一。 该领域正在发表许多研究论文,这使它变得更加有趣! 和“对于初学者来说,在 HSI 上开始模式识别和机器学习是相当麻烦的”ÿ…...

【图神经网络】从0到1使用PyG手把手创建异构图
从0到1用PyG创建异构图异构图创建异构图电影评分数据集MovieLens建立二分图数据集转换为可训练的数据集建立异构图神经网络以OGB数据集为例HeteroData中常用的函数将简单图神经网络转换为异质图神经网络GraphGym的使用PyG中常用的卷积层参考资料在现实中需要对 多种类型的节点以…...
2023美赛春季赛思路分析汇总
将在本帖更新汇总2023美赛春季赛两个赛题思路,大家可以点赞收藏! 2023美赛春季赛各赛题全部解题参考思路资料模型代码等全部实时更新!第一时间获取全部美赛春季赛相关资料! 目前思路整理仅为部分,请大家耐心等待&…...
GPT4国内镜像站
GPT-4介绍GPT-4是OpenAI发布的最先进的大型语言模型,是ChatGPT模型的超级进化版本。与ChatGPT相比,GPT-4的推理能力、复杂问题的理解能力、写代码能力得到了极大的强化,是当前人工智能领域,最有希望实现通用人工智能的大模型。但G…...

代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III
代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III LeetCode 198 打家劫舍 题目: 198.打家劫舍 动规五部曲: 确定dp数组以及下标的含义 dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷…...
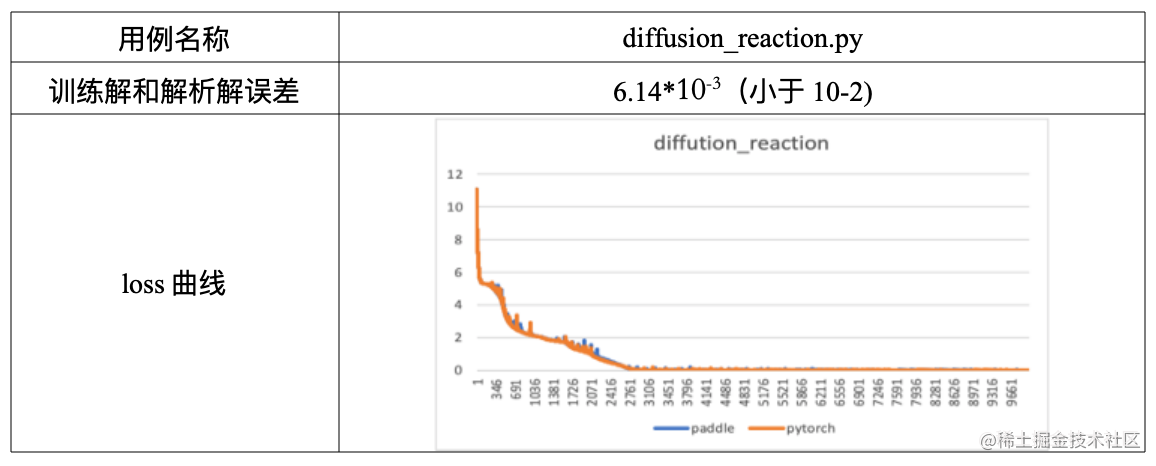
飞桨DeepXDE用例验证及评估
在之前发布的文章中,我们介绍了飞桨全量支持业内优秀科学计算深度学习工具 DeepXDE。本期主要介绍基于飞桨动态图模式对 DeepXDE 中 PINN 方法用例实现、验证及评估的具体流程,同时提供典型环节的代码,旨在帮助大家更加高效地基于飞桨框架进行…...

telegram连接本地Proxy连接不上
1.ClashX开启允许局域网连接。 2.重启ClashX和Telegram...
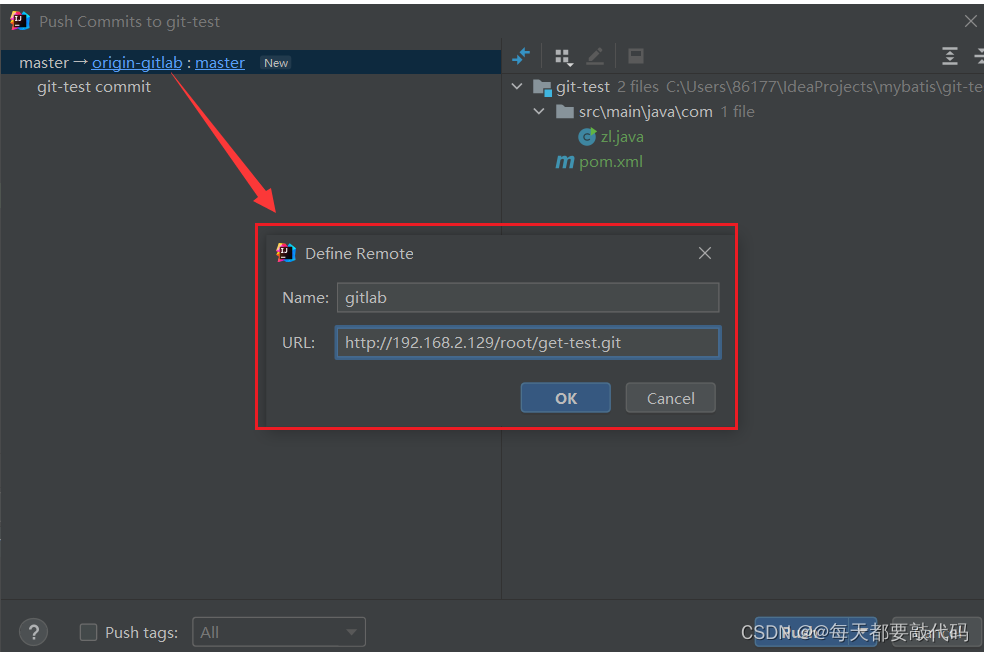
【分布式版本控制系统Git】| 国内代码托管中心-Gitee、自建代码托管平台-GitLab
目录 一:国内代码托管中心-码云 1. 码云创建远程库 2. IDEA 集成码云 3. 码云复制 GitHub 项目 二:自建代码托管平台-GitLab 1. GitLab 安装 2. IDEA 集成 GitLab 一:国内代码托管中心-码云 众所周知,GitHub 服务器在国外&…...
【面试】BIO、NIO、AIO面试题
文章目录什么是IO在了解不同的IO之前先了解:同步与异步,阻塞与非阻塞的区别什么是BIO什么是NIO什么是AIO什么NettyBIO和NIO、AIO的区别IO流的分类按照读写的单位大小来分:按照实际IO操作来分:按照读写时是否直接与硬盘,…...

C语言实现拼图求解
题目: 有如下的八种拼图块,每块都是由八块小正方块构成, 这些拼图块刚好可以某种方式拼合放入给定的目标形状, 请以C或C++编程,自动求解 一种拼图方式 目标拼图: 本栏目适合想要深入了解无向图、深度优先算法、编程语句如何实现算法、想要去接拼图算法的小伙伴。...

python --获取本机屏幕分辨率
pywin32 方法一 使用 win32api.GetDeviceCaps() 方法来获取显示器的分辨率。 使用 win32api.GetDC() 方法获取整个屏幕的设备上下文句柄,然后使用 win32api.GetDeviceCaps() 方法获取水平和垂直方向的分辨率。最后需要调用 win32api.ReleaseDC() 方法释放设备上下…...
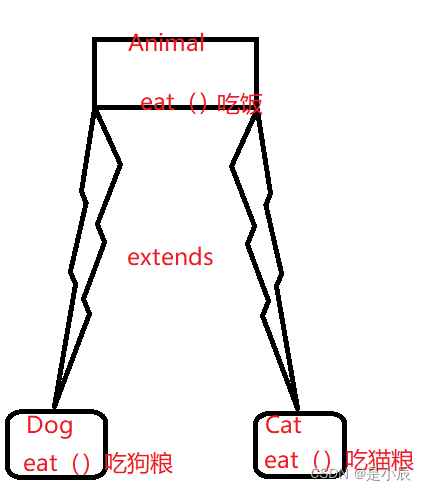
Java多态
目录 1.多态是什么? 2.多态的条件 3.重写 3.1重写的概念 3.2重写的作用 3.3重写的规则 4.向上转型与向下转型 4.1向上转型 4.2向下转型 5.多态的优缺点 5.1 优点 5.2 缺点 面向对象程序三大特性:封装、继承、多态。 1.多态是什么࿱…...

gnamiblast-skill:基于技能化与管道化的智能文本处理工具解析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫gabrivardqc123/gnamiblast-skill。光看这个名字,可能有点摸不着头脑,gnamiblast听起来像是个自造词,skill又指向了某种技能或功能。作为一名常…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

DIY智能电机推子:从闭环控制到MIDI交互的硬件实战
1. 项目概述与核心价值如果你玩过专业的音频混音台,或者在一些高端的灯光控制台上见过那种会自己“嗖”一下滑到指定位置的推子,那你一定对电机推子(Motorized Fader)不陌生。这东西的魅力在于,它既是精准的模拟输入设…...

一个产业带还值不值得押注?用 4 个生命周期阶段,对照 4 类可观察指标自己判断
你是卖设备、卖材料、卖工业服务的上游销售员。摆在你面前的是一张产业带地图:古镇灯饰、晋江运动鞋、戴南不锈钢、盛泽化纤、安平丝网……每一个都聚着成千上万家工厂。 问题来了:要在哪个产业带投入你的差旅、样品、地推团队?押错地方&…...

【2026最新】鸿蒙NEXT数据持久化实战:培训班管理系统数据存储全攻略
鸿蒙开发中数据总是丢失?本地存储和网络请求搞不定?本文用15分钟带你彻底搞懂Preferences、RDB、HTTP三大数据持久化方案,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App数据存储从此安全可靠!一、学员信息本地…...

如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南
如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南 【免费下载链接】AnuPpuccin Personal theme for Obsidian 项目地址: https://gitcode.com/gh_mirrors/an/AnuPpuccin 还在为单调的Obsidian界面而烦恼吗?想让你的笔记软件既美观又实用吗&a…...

终极指南:5分钟学会用FanControl免费掌控Windows风扇转速
终极指南:5分钟学会用FanControl免费掌控Windows风扇转速 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

保姆级教程:手把手教你用‘版本降级法’搞定PyTorch 1.9.1 + CUDA 11.1环境搭建
深度学习环境搭建实战:PyTorch与CUDA版本兼容性终极指南 引言 当你第一次尝试在Windows系统上搭建PyTorch深度学习环境时,可能会遇到各种令人困惑的错误信息。其中最常见的就是"no matching distribution found"这类版本兼容性问题。本文将以一…...

QtScrcpy终极指南:如何免费实现高清Android投屏与多设备控制
QtScrcpy终极指南:如何免费实现高清Android投屏与多设备控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtS…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...