【机器学习-无监督学习】概率图模型

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/Python_machine_learning。
文章目录
- 一、贝叶斯网络
- 二、最大后验估计
- 三、用朴素贝叶斯模型完成文本分类
- 四、马尔可夫网络
- 五、用马尔可夫网络完成图像去噪
本文讨论无监督学习中的数据分布建模问题。当我们需要在一个数据集上完成某个任务时,数据集中的样本分布显然是最基本的要素。面对不同的数据分布,我们可能针对同一任务采用完全不同的算法。例如,如果样本有明显的线性相关关系,我们就可以考虑用基于线性模型的算法解决问题;如果样本呈高斯分布,我们可能会使用高斯分布的各种性质来简化任务的要求。上一篇文章介绍的数据降维算法,也是为了在数据分布不明显的前提下,尽可能提取出数据的关键特征。因此,如何建模数据集中样本关于其各个特征的分布,就成了一个相当关键的问题。
我们从图1的场景中看起。一群人在秋天出游,银杏满地,风光无限。但是,在同一个温度下,不同人的衣着也有差异。有人穿了厚厚的大衣,有人穿了长袖长裤,还有人穿着短袖或者裙子。可以设想,如果气温再高一些,穿短袖的人会增加;如果气温再低一些,恐怕就不会有人再穿短袖了。因此我们可以认为,人群穿衣选择的概率分布受到天气的影响。

我们先从最简单的表格数据看起。假设表1中是天气和人群中衣服选择的部分数据,我们可以直接从中写出最简单的数据分布: P ( 天气 = 热 , 衣服 = 衬衫 ) = 48 % P(天气=热, 衣服=衬衫)=48\% P(天气=热,衣服=衬衫)=48%
| 天气 | 衣服 | 概率 |
|---|---|---|
| 热 | 衬衫 | 48% |
| 热 | 大衣 | 12% |
| 冷 | 衬衫 | 8% |
| 冷 | 大衣 | 32% |
以此类推,我们可以把表中的每一行都写出来,得到样本的分布。但是,这样的做法显然过于低效。当特征的数目增加时,我们按此建模的复杂度将成指数增长。因此,我们需要设法寻找不同特征之间的相关性,降低模型的复杂度。例如,根据生活常识,我们可以认为人们选择衣服的概率应该是和天气有关的。天气热时,人们更倾向于选择衬衫,而天气冷时倾向于大衣。这样,我们可以将上面的分布转化为条件概率: P ( 天气 = 热 ) = 60 % , P ( 衣服 = 衬衫 ∣ 天气 = 热 ) = 80 % P(天气=热)=60\%, \quad P(衣服=衬衫|天气=热)=80\% P(天气=热)=60%,P(衣服=衬衫∣天气=热)=80%
通过这种方式,我们可以建立起样本不同特征之间的关系。如果用随机变量 t t t表示天气, c c c表示衣服,那么上述的关系可以表示为图2中的结构。

图2中,从 t t t指向 c c c的箭头表示随机变量 c c c依赖于 t t t。把样本的所有特征按依赖关系列出来,每个特征作为一个顶点,每对依赖关系作为一条边,就形成了一张概率图。我们可以通过概率图中体现的不同特征之间的关系,推断出数据的概率分布。像上面这样,由依赖关系构成的概率图是有向图,称为贝叶斯网络(Bayes networks)。如果我们只知道两个特征之间相关,但没有明确的单向依赖关系,就可以用无向图来建模,称为马尔可夫网络(Markov networks)。下面,我们就来介绍这两种概率图模型的具体内容。
一、贝叶斯网络
贝叶斯网络又称信念网络(belief network),与概率中的贝叶斯推断有很大关联。由于网络中的有向关系清楚地表明了变量间的依赖,我们可以根据网络结构直接写出变量的分布。例如,设变量 a a a、 b b b和 c c c构成的贝叶斯网络如图3所示。

从图中可以看出, c c c依赖于 a a a, b b b同时依赖于 a a a和 c c c,于是其联合分布 p ( a , b , c ) p(a,b,c) p(a,b,c)可以写为 p ( a , b , c ) = p ( a , c ) p ( b ∣ a , c ) = p ( a ) p ( c ∣ a ) p ( b ∣ a , c ) p(a,b,c)=p(a,c)p(b|a,c)=p(a)p(c|a)p(b|a,c) p(a,b,c)=p(a,c)p(b∣a,c)=p(a)p(c∣a)p(b∣a,c) 对于一般的有 K K K个节点 x 1 ⋯ , x K x_1\cdots,x_K x1⋯,xK的贝叶斯网络,记 ρ ( x ) \rho(x) ρ(x)为所有有边指向 x x x的节点,也即是 x x x在图上的父亲节点集,那么其概率分布为 p ( x 1 , ⋯ , x K ) = ∏ k = 1 K p ( x k ∣ ρ ( x k ) ) p(x_1,\cdots,x_K)=\prod_{k=1}^Kp(x_k|\rho(x_k)) p(x1,⋯,xK)=k=1∏Kp(xk∣ρ(xk))
根据贝叶斯网络中,我们可以清晰地判断变量之间是否独立。如图4所示,我们以3个变量 a a a、 b b b和 c c c为例来说明3种不同的依赖关系。在图4(a)中, a a a和 b b b分别依赖于 c c c,但是 a a a与 b b b之间没有直接关联。直接根据图写出三者之间的联合分布为 p ( a , b , c ) = p ( a ∣ c ) p ( b ∣ c ) p ( c ) p(a,b,c)=p(a|c)p(b|c)p(c) p(a,b,c)=p(a∣c)p(b∣c)p(c) 从上式中我们并不能直接得到这些变量间的独立性。但是,如果给定变量 c c c,上式就变为 p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ∣ c ) p ( b ∣ c ) p(a,b|c)=\frac{p(a,b,c)}{p(c)}=p(a|c)p(b|c) p(a,b∣c)=p(c)p(a,b,c)=p(a∣c)p(b∣c) 这说明变量 a a a与 b b b在给定 c c c的条件下独立,记作 a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c。本文最开始所举的天气和穿衣的例子中,把穿什么衣服看作变量 a a a,天气看作变量 c c c,如果在加上一个是否打伞的变量 b b b,他们之间就满足这样尾对尾的依赖关系。条件独立(conditional independence)是概率图模型中最重要的基本概念之一,它直接刻画了一个多变量联合分布中变量之间的依赖关系,从而影响建模的方式。

接下来我们考虑图4(b)展示的头对头关系。同样,可以根据图直接写出三者的联合分布 p ( a , b , c ) = p ( c ∣ a , b ) p ( a ) p ( b ) p(a,b,c)=p(c|a,b)p(a)p(b) p(a,b,c)=p(c∣a,b)p(a)p(b) 而根据条件概率公式,有 p ( a , b , c ) = p ( c ∣ a , b ) p ( a , b ) p(a,b,c)=p(c|a,b)p(a,b) p(a,b,c)=p(c∣a,b)p(a,b),于是我们得到 p ( a , b ) = p ( a ) p ( b ) p(a,b)=p(a)p(b) p(a,b)=p(a)p(b) 因此,在这一关系中, a a a和 b b b是天然独立的,不需要条件,记作 a ⊥ ⊥ b ∣ ∅ a\perp\!\!\!\perp b|\varnothing a⊥⊥b∣∅。然而,一旦 c c c给定, a a a与 b b b就会由 c c c产生联系,用条件概率写为 p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ) p ( b ) p ( c ∣ a , b ) p ( c ) ≠ p ( a ∣ c ) p ( b ∣ c ) p(a,b|c)=\frac{p(a,b,c)}{p(c)}=\frac{p(a)p(b)p(c|a,b)}{p(c)}\neq p(a|c)p(b|c) p(a,b∣c)=p(c)p(a,b,c)=p(c)p(a)p(b)p(c∣a,b)=p(a∣c)p(b∣c) 这种情况似乎有些反直觉,为何原本独立的 a a a和 b b b在观测到 c c c后反而不独立了?这是因为 c c c引入了额外信息,我们用带概率的逻辑与来解释这一现象。假设 a a a、 b b b和 c c c的取值都是0或1,且 a a a与 b b b的取值相互独立,都满足 P ( a = 1 ) = P ( b = 1 ) = 0.7 P(a=1)=P(b=1)=0.7 P(a=1)=P(b=1)=0.7。 c c c的取值 a a a与 b b b的关系如表2所示。
| a a a | b b b | P ( c = 1 ∣ a , b ) P(c=1\mid a,b) P(c=1∣a,b) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0.2 |
| 0 | 1 | 0.2 |
| 1 | 1 | 1 |
假如我们观测到 c = 0 c=0 c=0,那么 a a a和 b b b取0的概率是多少?我们可以进行如下简单的计算:
P ( c = 0 ) = ∑ a = 0 , 1 ∑ b = 0 , 1 P ( a ) P ( b ) P ( c = 0 ∣ a , b ) = 0.426 P ( c = 0 ∣ a = 0 ) = ∑ b = 0 , 1 P ( b ) P ( c = 0 ∣ a = 0 , b ) = 0.86 P ( a = 0 ∣ c = 0 ) = P ( c = 0 ∣ a = 0 ) P ( a = 0 ) P ( c = 0 ) = 0.86 × 0.3 0.426 ≈ 0.606 \begin{aligned} P(c=0) &= \sum_{a=0,1}\sum_{b=0,1}P(a)P(b)P(c=0|a,b)=0.426 \\[2ex] P(c=0|a=0) &= \sum_{b=0,1}P(b)P(c=0|a=0,b)=0.86 \\[3ex] P(a=0|c=0) &= \frac{P(c=0|a=0)P(a=0)}{P(c=0)}=\frac{0.86\times 0.3}{0.426}\approx0.606 \end{aligned} P(c=0)P(c=0∣a=0)P(a=0∣c=0)=a=0,1∑b=0,1∑P(a)P(b)P(c=0∣a,b)=0.426=b=0,1∑P(b)P(c=0∣a=0,b)=0.86=P(c=0)P(c=0∣a=0)P(a=0)=0.4260.86×0.3≈0.606 由于 a a a和 b b b是对称的,同样也有 P ( b = 0 ∣ c = 0 ) ≈ 0.606 P(b=0|c=0)\approx0.606 P(b=0∣c=0)≈0.606。但是,此时 a a a和 b b b已经不独立了,我们可以通过计算 P ( b ∣ a , c ) ≠ P ( b ∣ c ) P(b|a,c)\neq P(b|c) P(b∣a,c)=P(b∣c) 来验证这一观点。考虑进一步观测到 a = 0 a=0 a=0 的前提下 b = 0 b=0 b=0 的概率,计算可得
P ( b = 0 ∣ a = 0 , c = 0 ) = P ( c = 0 ∣ a = 0 , b = 0 ) P ( b = 0 ) P ( c = 0 ∣ a = 0 ) = 1.0 × 0.3 0.86 ≈ 0.349 < 0.606 ≈ P ( b = 0 ∣ c = 0 ) \begin{aligned} P(b&=0|a=0,c=0)=\frac{P(c=0|a=0,b=0)P(b=0)}{P(c=0|a=0)} \\[2ex] &=\frac{1.0\times 0.3}{0.86}\approx0.349<0.606\approx P(b=0|c=0) \end{aligned} P(b=0∣a=0,c=0)=P(c=0∣a=0)P(c=0∣a=0,b=0)P(b=0)=0.861.0×0.3≈0.349<0.606≈P(b=0∣c=0)
这一结果说明,当观测到 a = 0 a=0 a=0 时,已经有很大概率导致 c = 0 c=0 c=0, b b b是否等于0就变得没有那么重要了。也就是说,在给定 c c c的条件下, a a a的结果会影响 b b b取值的概率,从而 a ⊥̸ ⊥ b ∣ c a\not\perp\!\!\!\perp b|c a⊥⊥b∣c。
最后,我们来看图4 ( c ) (\text c) (c)的头对尾关系,这一关系比较好理解。首先, a a a可以通过 c c c影响 b b b,所以 a a a与 b b b之间不独立。用数学语言来说,它们的联合分布为 p ( a , b , c ) = p ( a ) p ( c ∣ a ) p ( b ∣ c ) p(a,b,c)=p(a)p(c|a)p(b|c) p(a,b,c)=p(a)p(c∣a)p(b∣c) 当给定 c c c后, a a a与 b b b的联系就被切断了,这时考察 a a a与 b b b的联合分布 p ( a , b ∣ c ) p(a,b|c) p(a,b∣c),有 p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ) p ( c ∣ a ) p ( c ) p ( b ∣ c ) = p ( a ∣ c ) p ( b ∣ c ) p(a,b|c)=\frac{p(a,b,c)}{p(c)}=\frac{p(a)p(c|a)}{p(c)}p(b|c)=p(a|c)p(b|c) p(a,b∣c)=p(c)p(a,b,c)=p(c)p(a)p(c∣a)p(b∣c)=p(a∣c)p(b∣c) 因此, a a a与 b b b关于 c c c是条件独立的,即 a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c。这3种依赖关系是贝叶斯网络中各种复杂依赖的基础,通过这3种依赖的拆解就可以分析更加复杂的贝叶斯网络。
二、最大后验估计
在逻辑斯谛回归一文中,我们曾用最大似然估计的思想推导出了逻辑斯谛回归的优化目标。由于贝叶斯网络中的有向边清晰地表明了先验(prior)与后验(posterior)的关系,我们可以通过它推导出类似的结果。设数据集 D = { ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } \mathcal D=\{(\boldsymbol x_1,y_1),\cdots,(\boldsymbol x_N,y_N)\} D={(x1,y1),⋯,(xN,yN)}, X \boldsymbol X X表示所有样本, y \boldsymbol y y表示所有标签。假设样本与标签服从参数为 w \boldsymbol w w的分布,但是 w \boldsymbol w w是未知的,我们的目标就是根据观测到的数据计算 w \boldsymbol w w的后验分布 p ( w ∣ X , y ) p(\boldsymbol w|\boldsymbol X,\boldsymbol y) p(w∣X,y)。例如,在上面天气与衣服选择的例子中,我们可以把每个人看成样本 x n \boldsymbol x_n xn,选择的衣服看成标签 y n \boldsymbol y_n yn,天气看成参数 w \boldsymbol w w。因此,参数 w \boldsymbol w w、样本 x n \boldsymbol x_n xn和样本标签 y n y_n yn的依赖关系可以用贝叶斯网络表示为图5的结构。

这里,图5(a)是完整的贝叶斯网络。可以看出,对每个样本和标签来说,它们之间的依赖关系都是相同的,在网络中表现为大量重复的结构。对于这样的重复,我们通常将其简写为图5(b)的形式,用一组 x n → y n \boldsymbol x_n\rightarrow y_n xn→yn 的关系代表所有相似的节点,并在外面加一个方框,框里的 N N N表示该重复的个数。此外,由于样本 x n \boldsymbol x_n xn对标签 y n y_n yn有影响,但我们无法控制或者通常不关心其分布,因此在模型中将其看作定值,图5中用橙色节点表示。此外,根据尾对尾的依赖法则,我们可以判定,不同样本的标签 y n y_n yn之间相对模型参数 w \boldsymbol w w条件独立。这样, y \boldsymbol y y和 w \boldsymbol w w的概率分布为 p ( y , w ∣ X ) = p ( y ∣ w , X ) p ( w ) = p ( w ) ∏ i = 1 N p ( y i ∣ w , x i ) p(\boldsymbol y,\boldsymbol w|\boldsymbol X)=p(\boldsymbol y|\boldsymbol w,\boldsymbol X)p(\boldsymbol w)=p(\boldsymbol w)\prod_{i=1}^Np(y_i|\boldsymbol w,\boldsymbol x_i) p(y,w∣X)=p(y∣w,X)p(w)=p(w)i=1∏Np(yi∣w,xi) 其中,参数自身的分布 p ( w ) p(\boldsymbol w) p(w)就是先验分布,而 p ( y i ∣ w , x i ) p(y_i|\boldsymbol w,\boldsymbol x_i) p(yi∣w,xi)项之间之所以可以连乘,就是因为条件独立的性质。进一步,根据贝叶斯公式,模型参数 w \boldsymbol w w的后验分布可以表示为 p ( w ∣ X , y ) = p ( y ∣ w , X ) p ( w ) p ( y ∣ X ) ∝ p ( w ) ∏ i = 1 N p ( y i ∣ w , x i ) p(\boldsymbol w|\boldsymbol X,\boldsymbol y)=\frac{p(\boldsymbol y|\boldsymbol w,\boldsymbol X)p(\boldsymbol w)}{p(\boldsymbol y|\boldsymbol X)}\propto p(\boldsymbol w)\prod_{i=1}^Np(y_i|\boldsymbol w,\boldsymbol x_i) p(w∣X,y)=p(y∣X)p(y∣w,X)p(w)∝p(w)i=1∏Np(yi∣w,xi) 上式中的分母 p ( y ∣ X ) p(\boldsymbol y|\boldsymbol X) p(y∣X)同样被数据集完全确定,属于常数。通过贝叶斯网络,我们就确定了待求参数 w \boldsymbol w w的后验分布 p ( w ∣ X , y ) p(\boldsymbol w|\boldsymbol X,\boldsymbol y) p(w∣X,y)的表达式。
如果要进一步求解该后验分布,我们必须对参数空间和样本与标签之间的关系做出假设,以写出 p ( w ) p(\boldsymbol w) p(w)和 p ( y i ∣ w , x i ) p(y_i|\boldsymbol w,\boldsymbol x_i) p(yi∣w,xi)的具体形式。我们以线性回归为例,假设参数 w \boldsymbol w w的先验分布为高斯分布,即 w ∼ N ( 0 , α 2 ) \boldsymbol w\sim\mathcal N(\boldsymbol 0,\alpha^2) w∼N(0,α2),其中 w \boldsymbol w w的每个维度相互独立,都服从均值为0、方差为 α 2 \alpha^2 α2的高斯分布,我们用 p ( w ∣ α 2 ) = N ( w ∣ 0 , α 2 I ) p(\boldsymbol w|\alpha^2)=\mathcal N(\boldsymbol w|\boldsymbol 0,\alpha^2\boldsymbol I) p(w∣α2)=N(w∣0,α2I) 来表示。样本的标签 y i y_i yi和样本 x i \boldsymbol x_i xi满足 y i ∼ N ( w T x i , σ 2 ) y_i\sim \mathcal N(\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2) yi∼N(wTxi,σ2),用 p ( y i ∣ w , x i , σ 2 ) = N ( y i ∣ w T x i , σ 2 ) p(y_i|\boldsymbol w,\boldsymbol x_i,\sigma^2)=\mathcal N(y_i|\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2) p(yi∣w,xi,σ2)=N(yi∣wTxi,σ2) 表示。由于引入了新的量 α 2 \alpha^2 α2和 σ 2 \sigma^2 σ2,我们将概率图更新为图6。

两个新引入的量都可以视为常量,因此在图中也用橙色节点表示。把上述的表达式代入后验分布,就得到
p ( w ∣ X , y ) ∝ p ( w ) ∏ i = 1 N p ( y i ∣ w , x i ) ∝ p ( w ∣ α 2 ) ∏ i = 1 N p ( y i ∣ w , x i , σ 2 ) = N ( w ∣ 0 , α 2 I ) ∏ i = 1 N N ( y i ∣ w T x i , σ 2 ) \begin{aligned} p(\boldsymbol w|\boldsymbol X,\boldsymbol y) &\propto p(\boldsymbol w)\prod_{i=1}^Np(y_i|\boldsymbol w,\boldsymbol x_i) \\ &\propto p(\boldsymbol w|\alpha^2)\prod_{i=1}^Np(y_i|\boldsymbol w,\boldsymbol x_i,\sigma^2) \\ &= \mathcal N(\boldsymbol w|\boldsymbol 0,\alpha^2\boldsymbol I)\prod_{i=1}^N\mathcal N(y_i|\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2) \end{aligned} p(w∣X,y)∝p(w)i=1∏Np(yi∣w,xi)∝p(w∣α2)i=1∏Np(yi∣w,xi,σ2)=N(w∣0,α2I)i=1∏NN(yi∣wTxi,σ2) 设样本的维度是 d d d,那么参数 w ∈ R d \boldsymbol w\in\mathbb R^d w∈Rd。上式中高斯分布的具体表达式为 N ( w ∣ 0 , α 2 I ) = 1 ( 2 π α 2 ) d e − ∥ w ∥ 2 2 α 2 d \mathcal N(\boldsymbol w|\boldsymbol 0,\alpha^2\boldsymbol I)=\frac{1}{\sqrt{(2\pi\alpha^2)^d}}\text{e}^{-\frac{\Vert\boldsymbol w\Vert^2}{2\alpha^{2d}}} N(w∣0,α2I)=(2πα2)d1e−2α2d∥w∥2 N ( y i ∣ w T x i , σ 2 ) = 1 2 π σ 2 e − ( y i − w T x i ) 2 2 σ 2 \mathcal N(y_i|\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\text{e}^{-\frac{(y_i-\boldsymbol w^{\mathrm T}\boldsymbol x_i)^2}{2\sigma^2}} N(yi∣wTxi,σ2)=2πσ21e−2σ2(yi−wTxi)2
与最大似然估计的思路类似,这里我们希望 w \boldsymbol w w让后验最大化,称为最大后验(maximum a posteriori,MAP)估计。此外,我们对后验两边取对数,让连乘变为连加,并代入高斯分布的表达式,可以计算出
arg max w p ( w ∣ X , y ) = arg max w log p ( w ∣ X , y ) = arg max w log ( N ( w ∣ 0 , α 2 I ) ∏ i = 1 N N ( y i ∣ w T x i , σ 2 ) ) = arg max w ( log N ( w ∣ 0 , α 2 I ) + ∑ i = 1 N log N ( y i ∣ w T x i , σ 2 ) ) = arg max w ( − ∥ w ∥ 2 2 α 2 d − ∑ i = 1 N ( y i − w T x i ) 2 2 σ 2 ) = arg min w ( σ 2 α 2 d ∥ w ∥ 2 + ∑ i = 1 N ( y i − w T x i ) 2 ) \begin{aligned} \arg\max_{\boldsymbol w}p(\boldsymbol w|\boldsymbol X,\boldsymbol y) &= \arg\max_{\boldsymbol w}\log p(\boldsymbol w|\boldsymbol X,\boldsymbol y) \\ &= \arg\max_{\boldsymbol w}\log\left(\mathcal N(\boldsymbol w|\boldsymbol 0,\alpha^2\boldsymbol I)\prod_{i=1}^N\mathcal N(y_i|\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2)\right) \\ &= \arg\max_{\boldsymbol w}\left(\log\mathcal N(\boldsymbol w|\boldsymbol 0,\alpha^2\boldsymbol I)+\sum_{i=1}^N\log\mathcal N(y_i|\boldsymbol w^{\mathrm T}\boldsymbol x_i,\sigma^2)\right) \\ &= \arg\max_{\boldsymbol w}\left(-\frac{\Vert\boldsymbol w\Vert^2}{2\alpha^{2d}}-\sum_{i=1}^N\frac{(y_i-\boldsymbol w^{\mathrm T}\boldsymbol x_i)^2}{2\sigma^2}\right) \\ &= \arg\min_{\boldsymbol w}\left(\frac{\sigma^2}{\alpha^{2d}}\Vert\boldsymbol w\Vert^2+\sum_{i=1}^N(y_i-\boldsymbol w^{\mathrm T}\boldsymbol x_i)^2\right) \end{aligned} argwmaxp(w∣X,y)=argwmaxlogp(w∣X,y)=argwmaxlog(N(w∣0,α2I)i=1∏NN(yi∣wTxi,σ2))=argwmax(logN(w∣0,α2I)+i=1∑NlogN(yi∣wTxi,σ2))=argwmax(−2α2d∥w∥2−i=1∑N2σ2(yi−wTxi)2)=argwmin(α2dσ2∥w∥2+i=1∑N(yi−wTxi)2) 因此,我们最终要解决的优化问题是 min w ∑ i = 1 N ( y i − w T x i ) 2 + σ 2 α 2 d ∥ w ∥ 2 \min_{\boldsymbol w}\sum_{i=1}^N(y_i-\boldsymbol w^{\mathrm T}\boldsymbol x_i)^2+\frac{\sigma^2}{\alpha^{2d}}\Vert\boldsymbol w\Vert^2 wmini=1∑N(yi−wTxi)2+α2dσ2∥w∥2
可以发现,该目标函数与线性回归中用MSE损失函数、约束强度为 λ = σ 2 / α 2 d \lambda=\sigma^2/\alpha^{2d} λ=σ2/α2d 的 L 2 L_2 L2正则化约束所得到的的结果完全一致。如果把标签 y i y_i yi关于样本 x i \boldsymbol x_i xi的分布从高斯分布改为二项分布等其他形式,就可以得到其他的朴素贝叶斯模型。对于更复杂的变量依赖结构和分布模型,我们也可以用贝叶斯网络建模,再用最大化后验的思路求解。
最大似然估计与最大后验估计是机器学习中常用的两种求解模型参数的方式,但两者有所不同。设数据集为 D \mathcal D D,模型参数为 w \boldsymbol w w。MLE考虑哪个参数生成当前数据集的概率最大,因此求解最大化的对数似然: w M L E = arg max w p ( D ∣ w ) = arg max w log p ( D ∣ w ) \boldsymbol w_{\mathrm{MLE}}=\arg\max_{\boldsymbol w}p(\mathcal D|\boldsymbol w)=\arg\max_{\boldsymbol w}\log p(\mathcal D|\boldsymbol w) wMLE=argwmaxp(D∣w)=argwmaxlogp(D∣w) 另一方面,MAP考虑最大化参数的后验分布 P ( w ∣ D ) P(\boldsymbol w|\mathcal D) P(w∣D)。利用贝叶斯公式,可以得到
w M A P = arg max w p ( w ∣ D ) = arg max w log p ( w ∣ D ) = arg max w log p ( w ) p ( D ∣ w ) p ( D ) = arg max w ( log p ( D ∣ w ) + log p ( w ) ) \begin{aligned} \boldsymbol w_{\mathrm{MAP}} &= \arg\max_{\boldsymbol w}p(\boldsymbol w|\mathcal D) \\ &= \arg\max_{\boldsymbol w}\log p(\boldsymbol w|\mathcal D) \\ &= \arg\max_{\boldsymbol w}\log\frac{p(\boldsymbol w)p(\mathcal D|\boldsymbol w)}{p(\mathcal D)} \\[2ex] &= \arg\max_{\boldsymbol w}(\log p(\mathcal D|\boldsymbol w)+\log p(\boldsymbol w)) \end{aligned} wMAP=argwmaxp(w∣D)=argwmaxlogp(w∣D)=argwmaxlogp(D)p(w)p(D∣w)=argwmax(logp(D∣w)+logp(w))
两者对比可以发现,MAP的优化目标比MLE多了一项 log p ( w ) \log p(\boldsymbol w) logp(w),也即参数 w \boldsymbol w w的先验分布的对数。因此MAP相当于在MLE的基础上引入了我们对参数的先验假设,对参数的分布添加了一定限制。从MLE的角度来考虑,这种做法等价于引入正则化约束。所以,上面我们用MAP推导出的线性回归是自然带有 L 2 L_2 L2正则化约束的。贝叶斯模型给了我们一种理解正则化约束的更自然的视角。
三、用朴素贝叶斯模型完成文本分类
朴素贝叶斯(naive Bayes)是贝叶斯公式和贝叶斯网络模型的最简单应用。顾名思义,朴素贝叶斯模型只使用基本的条件独立假设和计数方法,统计各个变量的先验分布,再由贝叶斯公式反推出参数的后验。应用到分类模型中,待求的参数就是每个样本的类别。设样本的特征是 ( x 1 , ⋯ , x d ) (x_1,\cdots,x_d) (x1,⋯,xd),类别是 y y y,那么它们之间的依赖关系可以用贝叶斯网络表示为图7中的结构。可以看出,朴素贝叶斯模型是一个生成模型(generative model),从每个样本的类别标签生成整个样本的特征。

这里,我们事实上隐含了各个特征之间相互独立的假设。具体来说,朴素贝叶斯模型假设:给定每个样本的类别 y y y,样本特征变量 x 1 , ⋯ , x d x_1,\cdots,x_d x1,⋯,xd之间是相互独立的,也即是 x i ⊥ ⊥ x j ∣ y , ∀ i , j , 1 ≤ i , j ≤ d , i ≠ j x_i\perp\!\!\!\perp x_j|y, \quad \forall i,j, \quad 1\le i,j\le d,i\neq j xi⊥⊥xj∣y,∀i,j,1≤i,j≤d,i=j 这样就有可以将特征变量的联合概率拆解为独立概率的乘积: p ( x 1 , ⋯ , x d ∣ y ) = ∏ i = 1 d p ( x i ∣ y ) p(x_1,\cdots,x_d|y)=\prod_{i=1}^dp(x_i|y) p(x1,⋯,xd∣y)=i=1∏dp(xi∣y) 虽然这一假设在实际中不甚合理,但是作为最简单的朴素模型,这一假设可以大大简化我们计算的难度。下面,我们按与上节相同的步骤,在样本特征 ( x 1 , ⋯ , x d ) (x_1,\cdots,x_d) (x1,⋯,xd)给定的前提下最大化类别 y y y的后验概率,作为对样本类别的预测:
y ^ = arg max y p ( y ∣ x 1 , ⋯ , x d ) = arg max y p ( x 1 , ⋯ , x d ∣ y ) p ( y ) p ( x 1 , ⋯ , x d ) = arg max y p ( y ) ∏ i = 1 d p ( x i ∣ y ) = arg max y log p ( y ) + ∑ i = 1 d log p ( x i ∣ y ) = arg max y ∈ { 1 , ⋯ , C } ( log P ( y ) + ∑ i = 1 d log P ( x i ∣ y ) ) \begin{aligned} \hat y &= \arg\max_y p(y|x_1,\cdots,x_d) \\ &= \arg\max_y\frac{p(x_1,\cdots,x_d|y)p(y)}{p(x_1,\cdots,x_d)} \\ &= \arg\max_y p(y)\prod_{i=1}^dp(x_i|y) \\ &= \arg\max_y\log p(y)+\sum_{i=1}^d\log p(x_i|y) \\ &= \arg\max_{y\in \{1,\cdots,C\}} \left(\log P(y)+\sum_{i=1}^d\log P(x_i|y)\right) \end{aligned} y^=argymaxp(y∣x1,⋯,xd)=argymaxp(x1,⋯,xd)p(x1,⋯,xd∣y)p(y)=argymaxp(y)i=1∏dp(xi∣y)=argymaxlogp(y)+i=1∑dlogp(xi∣y)=argy∈{1,⋯,C}max(logP(y)+i=1∑dlogP(xi∣y)) 其中 C C C是总的类别数量,由于 y y y是离散的类别,我们直接把分布 p ( y ) p(y) p(y)写成概率 P ( y ) P(y) P(y)。因此,朴素贝叶斯分类模型的核心就是统计 y y y的先验概率 P ( y ) P(y) P(y)和各个特征的概率 P ( x i ∣ y ) P(x_i|y) P(xi∣y)。
下面,我们在新闻数据集“The 20 Newsgroups”上用朴素贝叶斯分离器完成新闻分类任务。该数据集包含了20个类别的大概20000篇新闻,涵盖了计算机、科学、体育等等主题,每个主题下的新闻数量大致相等。我们的目标是根据新闻中出现的单词判断出新闻属于哪个类别。首先,我们导入必要的库和数据集,该数据集可以直接从sklearn中获取到。
考虑到文本处理不属于重点讲述范围,我们直接从sklearn中下载处理好的数据集,仅在这里简要介绍数据处理的方法。首先,我们将文本按照空白字符分隔成一个个单词,再将所有长度在2以下的单词(如I,a,单独的数字和符号)去除。对于剩下的单词,我们建立起词汇表,设其大小为 V V V,那么每个单词都可以按照它在词汇表中的位置,用一个独热向量表示。假设“the”是词汇表中的第一个单词,那么它的向量表示就是 ( 1 , 0 , ⋯ , 0 ) (1,0,\cdots,0) (1,0,⋯,0),共有 V V V维。把一篇新闻中的所有单词都用独热向量表示后,我们把这些独热向量相加,就得到表示该文章的向量。例如,词汇表中有3个单词“the”、“dog”和“cat”,其向量表示分别为 ( 1 , 0 , 0 ) (1,0,0) (1,0,0)、 ( 0 , 1 , 0 ) (0,1,0) (0,1,0)和 ( 0 , 0 , 1 ) (0,0,1) (0,0,1),那么“the cat”的向量表示就是 ( 1 , 0 , 1 ) (1,0,1) (1,0,1)。这一表示方法完全忽略了单词之间的先后顺序和文章的整体上下文结构,是一种非常粗略的表示方法,但对我们的朴素贝叶斯模型来说已经足够。由于一篇文章中包含的单词相比于整个词汇表来说非常有限,其向量表示也很稀疏,因此我们获得的数据集也是用稀疏矩阵表示的。fetch_20newsgroups_vectorized函数存储所用的是SciPy库的稀疏矩阵,输出中(i,j) k表示矩阵第 i i i行 j j j列的值为 k k k。在本例中,其具体含义为新闻 i i i中单词 j j j出现了 k k k次(省略部分程序输出内容)。
import numpy as np
from sklearn.datasets import fetch_20newsgroups_vectorized
from tqdm import trange# normalize表示是否对数据归一化,这里我们保留原始数据
# data_home是数据保存路径
train_data = fetch_20newsgroups_vectorized(subset='train', normalize=False, data_home='20newsgroups')
test_data = fetch_20newsgroups_vectorized(subset='test', normalize=False, data_home='20newsgroups')
print('文章主题:', '\n'.join(train_data.target_names))
print(train_data.data[0])

接下来,我们统计训练集中的 P ( y ) P(y) P(y)和 P ( x i ∣ y ) P(x_i|y) P(xi∣y),这里 y y y是新闻的主题, x i x_i xi是单词。对于给定离散数据,我们直接用频率代替概率,因此 P ( y ) P(y) P(y)是不同主题新闻的频率, P ( x i ∣ y ) P(x_i|y) P(xi∣y)是主题为 y y y的新闻下单词 x i x_i xi出现的频率。在上一节中,我们认为数据集中的样本先验概率与模型无关,但对于文本中的单词来说,虽然一篇文章中不可能出现所有单词,但这并不代表没有出现的单词概率就是零。一般来说,我们会为所有单词设置一个先验计数 α \alpha α,通常取 α = 1 \alpha=1 α=1,真实计数将在先验计数的基础上累加。
# 统计新闻主题频率
cat_cnt = np.bincount(train_data.target)
print('新闻数量:', cat_cnt)
log_cat_freq = np.log(cat_cnt / np.sum(cat_cnt))# 对每个主题统计单词频率
alpha = 1.0
# 单词频率,20是主题个数,train_data.feature_names是分割出的单词
log_voc_freq = np.zeros((20, len(train_data.feature_names))) + alpha
# 单词计数,需要加上先验计数
voc_cnt = np.zeros((20, 1)) + len(train_data.feature_names) * alpha
# 用nonzero返回稀疏矩阵不为零的行列坐标
rows, cols = train_data.data.nonzero()
for i in trange(len(rows)):news = rows[i]voc = cols[i]cat = train_data.target[news] # 新闻类别log_voc_freq[cat, voc] += train_data.data[news, voc]voc_cnt[cat] += train_data.data[news, voc]log_voc_freq = np.log(log_voc_freq / voc_cnt)

至此,统计的信息已经足够我们判断其他新闻的类型了。我们遍历所有主题 y y y,计算对数后验,并返回使对数后验最大的主题。
def test_news(news):rows, cols = news.nonzero()# 对数后验log_post = np.copy(log_cat_freq)for row, voc in zip(rows, cols):# 加上每个单词在类别下的后验log_post += log_voc_freq[:, voc]return np.argmax(log_post)
最后,我们在测试集的所有新闻上查看我们的分类准确率,只有当我们判断的类别与真实类别相同时才算作正确。
preds = []
for news in test_data.data:preds.append(test_news(news))
acc = np.mean(np.array(preds) == test_data.target)
print('分类准确率:', acc)

在sklearn中也提供了朴素贝叶斯分类器,对于本例中的离散特征多分类任务,我们选用MultinomialNB进行测试,并与我们自己实现的效果比较。该分类器同样有默认参数 α = 1 \alpha=1 α=1,大家可以通过调整 α \alpha α的值,观察分类效果的变化。
from sklearn.naive_bayes import MultinomialNBmnb = MultinomialNB(alpha=alpha)
mnb.fit(train_data.data, train_data.target)
print('分类准确率:', mnb.score(test_data.data, test_data.target))

四、马尔可夫网络
与贝叶斯网络不同,某些情况下,变量之间的关联是双向的。例如在KNN一文中,我们曾用到了照片中某一像素和周围像素大概率很接近这一假设。如果把每个像素看作一个变量,那么它和周围的像素就是互相影响、互相依赖的。这时,我们可以把贝叶斯网络的有向图变为无向图,构造出马尔可夫网络。
图8展示了一个简单的马尔可夫网络,其中包含5个变量 a a a、 b b b、 c c c、 d d d和 e e e,每个变量在图中为一个节点,两个节点之间的边代表这两个变量之间存在直接依赖关系。与贝叶斯网络的有向图不同,由于依赖是双向的,我们无法将这些变量的联合分布通过条件概率直接拆分。和贝叶斯网络不同,马尔可夫网络更多地用于描述几个变量之间是如何相互依赖的,在物理上更像是一种“场”的体现,因此它又称为马尔可夫随机场(Markov random fields)。例如穿衣时上衣、裤子和鞋子的搭配,三者是相互依赖的,并没有明确哪个是因、哪个是果。因此,我们需要通过其他方式分析马尔可夫网络中变量之间的依赖方式。通过观察可以发现,如果两个变量之间所有路径上的变量全部已知,那么这两个变量相互独立。例如在图8中,假如我们给定了 c c c和 d d d,它们就不再被视为变量,与其相连的边也失去了意义。这时,变量 a a a和 e e e之间不再有路径可以互相到达,它们之间的关联也就不存在了。我们记为 a ⊥ ⊥ b ∣ c , d a\perp\!\!\!\perp b|c,d a⊥⊥b∣c,d,表示在给定 c c c与 d d d时, a a a和 b b b条件独立。

我们可以从这一性质出发,继续考虑马尔可夫网络的拆分。对于网络中的任意两个不同节点 x i x_i xi和 x j x_j xj,记 x ∖ { i , j } \boldsymbol x_{\setminus\{i,j\}} x∖{i,j}为除去这两个节点以外的所有节点。当 x ∖ { i , j } \boldsymbol x_{\setminus\{i,j\}} x∖{i,j}给定时,如果 x i x_i xi与 x j x_j xj没有直接相连,那么它们之间的所有路径上的变量必然都是固定的,两者条件独立。因此,这两个变量的条件联合分布可以拆分为: p ( x i , x j ∣ x ∖ { i , j } ) = p ( x i ∣ x ∖ { i , j } ) p ( x j ∣ x ∖ { i , j } ) p(x_i,x_j|\boldsymbol x_{\setminus\{i,j\}})=p(x_i|\boldsymbol x_{\setminus\{i,j\}})p(x_j|\boldsymbol x_{\setminus\{i,j\}}) p(xi,xj∣x∖{i,j})=p(xi∣x∖{i,j})p(xj∣x∖{i,j}) 如果变量 x i x_i xi与 x j x_j xj之间有边相连,那么无论其他变量如何,它们之间必然存在依赖关系,无法通过中间变量拆分。所以,我们可以按照变量之间的连接关系,将网络拆分成一些内部紧密连接、相互条件独立的部分。
在图论中,如果一张无向图中的某些节点之间两两互相连接,我们就称这些节点组成了一个团(clique)。在图8中,大小为2的团有6个,分别是 { a , b } \{a,b\} {a,b}、 { b , c } \{b,c\} {b,c}、 { c , d } \{c,d\} {c,d}、 { b , d } \{b,d\} {b,d}、 { c , e } \{c,e\} {c,e}和 { d , e } \{d,e\} {d,e};大小为3的团有1个,是 { c , d , e } \{c,d,e\} {c,d,e}。需要注意, { a , b , c , d } \{a,b,c,d\} {a,b,c,d}不是团,因为 b b b和 c c c之间没有边连接。根据上面的推导,我们可以将团视为马尔可夫网络的基本单位,每个团之内的变量互相之间存在无法拆分的依赖关系。然而,有些较小的团是被较大的团所包含的,例如上面的团 { c , d , e } \{c,d,e\} {c,d,e}中就包含了3个大小为2的团 { c , d } \{c,d\} {c,d}、 { c , e } \{c,e\} {c,e}和 { d , e } \{d,e\} {d,e}。如果我们用函数来描述一个团中变量之间的关联,那么较小团中的关联是被较大团中的关联所包含的。因此,我们定义不被其他团包含的团为极大团(maximal clique)。在上面的例子中,极大团共有4个,分别是 { a , b } \{a,b\} {a,b}、 { a , c } \{a,c\} {a,c}、 { b , d } \{b,d\} {b,d}和 { c , d , e } \{c,d,e\} {c,d,e}。我们只需要将马尔可夫网络拆分成极大团,就可以涵盖所有存在的变量关联。
记团 C C C中所有变量为 x C \boldsymbol x_C xC,设其在整个网络的联合分布 p ( x ) p(\boldsymbol x) p(x)拆分后的因子可以用函数 ψ C ( x C ) \psi_C(\boldsymbol x_C) ψC(xC)表示。由上所述,我们只考虑极大团的因子,将 p ( x ) p(\boldsymbol x) p(x)拆分为 p ( x ) = 1 Z ∏ C ψ C ( x C ) p(\boldsymbol x)=\frac{1}{Z}\prod_C\psi_C(\boldsymbol x_C) p(x)=Z1C∏ψC(xC) 其中的乘积遍历所有极大团, Z = ∑ x ∈ x ∏ C ψ C ( x C ) Z=\sum\limits_{x\in\boldsymbol x}\prod\limits_C\psi_C(\boldsymbol x_C) Z=x∈x∑C∏ψC(xC) 是归一化因子,称为配分函数(partition function)。在图8的网络中,按此方式得到的联合分布为 p ( a , b , c , d , e ) = 1 Z ψ a b ( a , b ) ψ a c ( a , c ) ψ b d ( b , d ) ψ c d e ( c , d , e ) p(a,b,c,d,e)=\frac{1}{Z}\psi_{ab}(a,b)\psi_{ac}(a,c)\psi_{bd}(b,d)\psi_{cde}(c,d,e) p(a,b,c,d,e)=Z1ψab(a,b)ψac(a,c)ψbd(b,d)ψcde(c,d,e) 由于概率分布必须处处非负,所有的函数 ψ C \psi_C ψC都必须满足 ψ C ( x ) ≥ 0 \psi_C(\boldsymbol x)\ge0 ψC(x)≥0,我们将其称为势函数(potential function)。势函数的具体形式可以通过对问题的先验知识规定。例如,势函数
ψ a b ( a , b ) = { 1.0 , a = b 0.1 , a ≠ b \psi_{ab}(a,b)= \begin{cases} 1.0, \quad a=b \\ 0.1, \quad a\neq b \end{cases} ψab(a,b)={1.0,a=b0.1,a=b 会让变量 a a a和 b b b倾向于取值相同。
如果势函数不仅非负,而且严格为正,我们可以用能量函数 E ( x C ) E(\boldsymbol x_C) E(xC)来表示势函数,使得 ψ C ( x C ) = e − E ( x C ) \psi_C(\boldsymbol x_C)=\text{e}^{-E(\boldsymbol x_C)} ψC(xC)=e−E(xC)。这样,联合分布就由连乘转化为指数上的求和: p ( x ) = 1 Z ∏ C ψ C ( x C ) = 1 Z e − ∑ C E ( x C ) p(\boldsymbol x)=\frac{1}{Z}\prod_C\psi_C(\boldsymbol x_C)=\frac{1}{Z}\text{e}^{-\sum\limits_CE(\boldsymbol x_C)} p(x)=Z1C∏ψC(xC)=Z1e−C∑E(xC) 再利用我们已经多次使用过的求对数的技巧,将寻找 p ( x ) p(\boldsymbol x) p(x)的最大值转换为寻找 log p ( x ) \log p(\boldsymbol x) logp(x)的最大值,得到
arg max x p ( x ) = arg max x log p ( x ) = arg max x ( − ∑ C E ( x C ) ) = arg max x ∑ C E ( x C ) \begin{aligned} \arg\max_{\boldsymbol x}p(\boldsymbol x) &= \arg\max_{\boldsymbol x}\log p(\boldsymbol x) \\ &= \arg\max_{\boldsymbol x}\left(-\sum_CE(\boldsymbol x_C)\right) \\ &= \arg\max_{\boldsymbol x}\sum_CE(\boldsymbol x_C) \end{aligned} argxmaxp(x)=argxmaxlogp(x)=argxmax(−C∑E(xC))=argxmaxC∑E(xC)
该优化问题是对所有极大团的能量的和进行优化,且能量函数的取值和形式没有限制,相比于直接求解势函数的乘积方便很多。这一思想来自于物理中的势和势能,以及玻尔兹曼分布,感兴趣的可以自行查阅相关资料。下面,我们以图像去噪为例,展示马尔可夫网络的一个简单应用。
五、用马尔可夫网络完成图像去噪
在k近邻算法中我们已经讲过,对于一张有意义的图像,其每个像素点的颜色和周围像素点大概率相近,并且这一关联是双向的,符合马尔可夫网络的模型。当一张图像中存在噪点时,它们与周围像素的关联大概率比真实像素弱,反映在能量函数上,其整体的能量应当较大。因此,我们可以通过设计合适的能量函数并在图像上进行优化,还原出噪点的真实颜色。
简单起见,我们用一张只有两种颜色的图像来演示。如图9所示,上半部分是只有黑色与白色的原始图像,我们随机将其中10%的像素进行黑白反转,得到了下半部分带有噪声的图像。

为了对图像添加噪声前后的状态建模,设图像上像素的真实颜色 x i ∈ { − 1 , 1 } x_i\in\{-1,1\} xi∈{−1,1},添加噪声后观察到的颜色 y i ∈ { − 1 , 1 } y_i\in\{-1,1\} yi∈{−1,1}。由于不同像素的颜色是否翻转是相互独立的,某个像素的显示颜色 y i y_i yi只和其真实颜色 x i x_i xi有关,而与其他像素无关。对于像素间的关联,我们只考虑最简单的上下左右4个像素。这样,图像的真实颜色 x i x_i xi与显示颜色 y i y_i yi就构成了一个马尔可夫网络网络,其结构如图10所示。下层的蓝色节点表示图像的真实颜色,上层的橙色节点表示图像的显示颜色。从图中可以看出,该网络中极大团只有两种,一种是相邻像素的真实颜色的关联 { x i , x j } \{x_i,x_j\} {xi,xj},另一种是像素真实颜色与显示颜色的关联 { x i , y i } \{x_i,y_i\} {xi,yi}。这样的网格状结构中,极大团的大小都是2。接下来,我们需要为极大团设计能量函数。考虑到这些极大团的对称性,并忽略边缘处网络结构细微的不同,我们只需要为每种极大团设计一个函数,而不需要为每个极大团分别设计。

首先考虑真实像素间的关联,我们预计相邻的像素应当较为相似。由于图像中只有两种颜色-1和1,我们可以用相邻像素颜色的乘积 x i x j x_ix_j xixj来判断它们是否相同。当颜色相同时,乘积为1,反之为-1。考虑到颜色相同时能量应当较低,我们用其乘积的相反数作为能量,即 E ( x i , x j ) = − α x i x j E(x_i,x_j)=-\alpha x_ix_j E(xi,xj)=−αxixj其中, α \alpha α是常数系数,且函数只对相邻的像素有定义。对于真实像素与对应的显示像素间的关联,我们期望像素的颜色没有被反转,显示的颜色与真实颜色相同。因此,我们可以得到与上面相似的能量函数 E ( x i , x j ) = − β x i y i E(x_i,x_j)=-\beta x_iy_i E(xi,xj)=−βxiyi 其中, β \beta β是另一个常数系数。记 N ( x i ) \mathcal N(x_i) N(xi)为像素 x i x_i xi相邻像素的集合, N N N为图像中像素的总数量,将能量函数对网络中所有的极大团求和,就得到总能量为 E ( x , y ) = − α 2 ∑ i = 1 N ∑ x j ∈ N ( x i ) x i x j − β ∑ i = 1 N x i x j E(\boldsymbol x,\boldsymbol y)=-\frac{\alpha}{2}\sum_{i=1}^N\sum_{x_j\in\mathcal N(x_i)}x_ix_j-\beta\sum_{i=1}^Nx_ix_j E(x,y)=−2αi=1∑Nxj∈N(xi)∑xixj−βi=1∑Nxixj 式中的第一项由于相邻像素对的能量被计算了两遍,额外乘上了 1 2 \frac{1}{2} 21。
由于图像中像素数量 N N N往往较大,直接优化 E ( x , y ) E(\boldsymbol x,\boldsymbol y) E(x,y)较为困难。考虑到问题中变量的取值范围很小,我们每次优化一个像素 x i x_i xi,判断改变 x i x_i xi的值是否可以降低网络的总能量。下面,我们就在图9展示的图像上动手实现马尔可夫网络为图像去噪。
import matplotlib.image as mpimg
import matplotlib.pyplot as plt# 读取原图
orig_img = np.array(mpimg.imread('origimg.jpg'), dtype=int)
orig_img[orig_img < 128] = -1 # 黑色设置为-1
orig_img[orig_img >= 128] = 1 # 白色设置为1# 读取带噪图像
noisy_img = np.array(mpimg.imread('noisyimg.jpg'), dtype=int)
noisy_img[noisy_img < 128] = -1
noisy_img[noisy_img >= 128] = 1
为了在后续过程中计算去噪的效果,我们定义一个函数来计算当前图像与原图中不一致的像素比例。
def compute_noise_rate(noisy, orig):err = np.sum(noisy != orig)return err / orig.sizeinit_noise_rate = compute_noise_rate(noisy_img, orig_img)
print (f'带噪图像与原图不一致的像素比例:{init_noise_rate * 100:.4f}%')

由于图像在计算机中本身就是用二维数组存储,其结构与我们设计的马尔可夫网络相同,我们不需要再额外实现数据结构来存储马尔可夫网络。下面,我们就来直接实现逐像素优化的算法。在该算法中,优化每个像素时,能量的改变都是局部的。因此,我们只需要计算局部的能量变化,无须每次都重新计算整个网络的能量。
# 计算坐标(i, j)处的局部能量
def compute_energy(X, Y, i, j, alpha, beta):# X:当前图像# Y:带噪图像energy = -beta * X[i][j] * Y[i][j]# 判断坐标是否超出边界if i > 0:energy -= alpha * X[i][j] * X[i - 1][j]if i < X.shape[0] - 1:energy -= alpha * X[i][j] * X[i + 1][j]if j > 0:energy -= alpha * X[i][j] * X[i][j - 1]if j < X.shape[1] - 1:energy -= alpha * X[i][j] * X[i][j + 1]return energy
最后,我们定义超参数,并将图像去噪结果随训练轮数的变化绘制出来。可以看出,随着迭代进行,图中在大范围色块内的噪点基本都消失了。
# 设置超参数
alpha = 2.1
beta = 1.0
max_iter = 5# 逐像素优化
# 复制一份噪声图像,保持网络中的Y不变,只优化X
X = np.copy(noisy_img)
for k in range(max_iter):for i in range(X.shape[0]): # 枚举所有像素for j in range(X.shape[1]):# 分别计算当前像素取1和-1时的能量X[i, j] = 1pos_energy = compute_energy(X, noisy_img, i, j, alpha, beta)X[i, j] = -1neg_energy = compute_energy(X, noisy_img, i, j, alpha, beta)# 将该像素设置为使能量最低的值X[i, j] = 1 if pos_energy < neg_energy else -1# 展示图像并计算噪声率plt.figure()plt.axis('off')plt.imshow(X, cmap='binary_r')plt.show()noise_rate = compute_noise_rate(X, orig_img) * 100print(f'迭代轮数:{k},噪声率:{noise_rate:.4f}%')

如果图像的图案更复杂、色彩更丰富,我们也可以使用类似的方法去噪,但是通常需要我们使用先验知识,设计更复杂的网络结构和能量函数。例如考虑彩色图像中的颜色渐变、考虑更大范围像素之间的关联等。在上例中,当黑色与白色给出的能量相同时,我们默认将其设置为白色。对于更复杂的情况,我们可以为每个像素单独设置一个能量函数 E ( x i ) E(x_i) E(xi),表示其颜色具有的能量,以此来规定图像整体的颜色偏好。
附:以上文中的数据集及相关资源下载地址:
链接:https://pan.quark.cn/s/bfc9cea33f73
提取码:fASw
相关文章:
【机器学习-无监督学习】概率图模型
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,…...

每日学习一个数据结构-AVL树
文章目录 概述一、定义与特性二、平衡因子三、基本操作四、旋转操作五、应用场景 Java代码实现 概述 AVL树是一种自平衡的二叉查找树,由两位俄罗斯数学家G.M.Adelson-Velskii和E.M.Landis在1962年发明。想了解树的相关概念,请点击这里。以下是对AVL树的…...
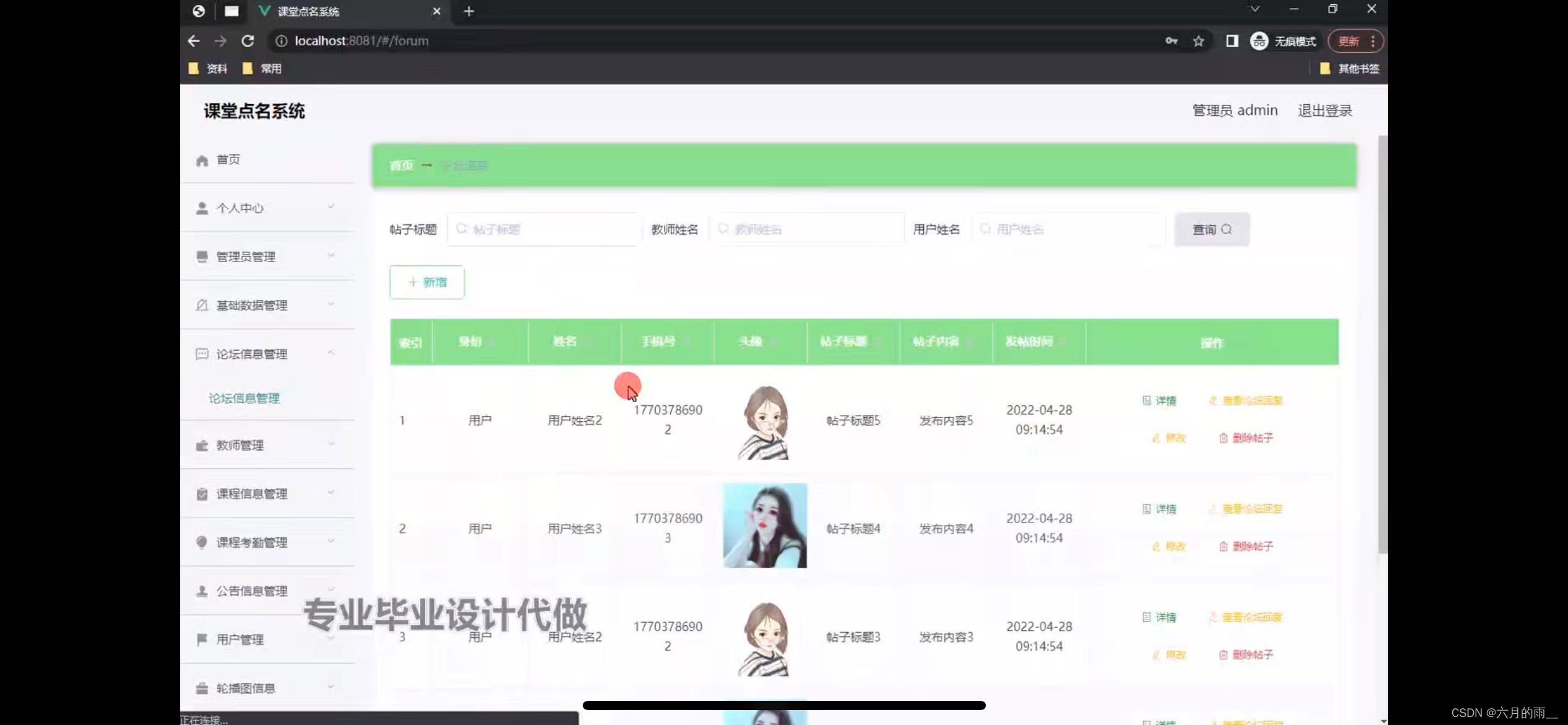
课堂点名系统小程序的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,论坛信息管理,基础数据管理,课程信息管理,课程考勤管理,轮播图信息 微信端账号功能包括:系统首页,论坛信…...
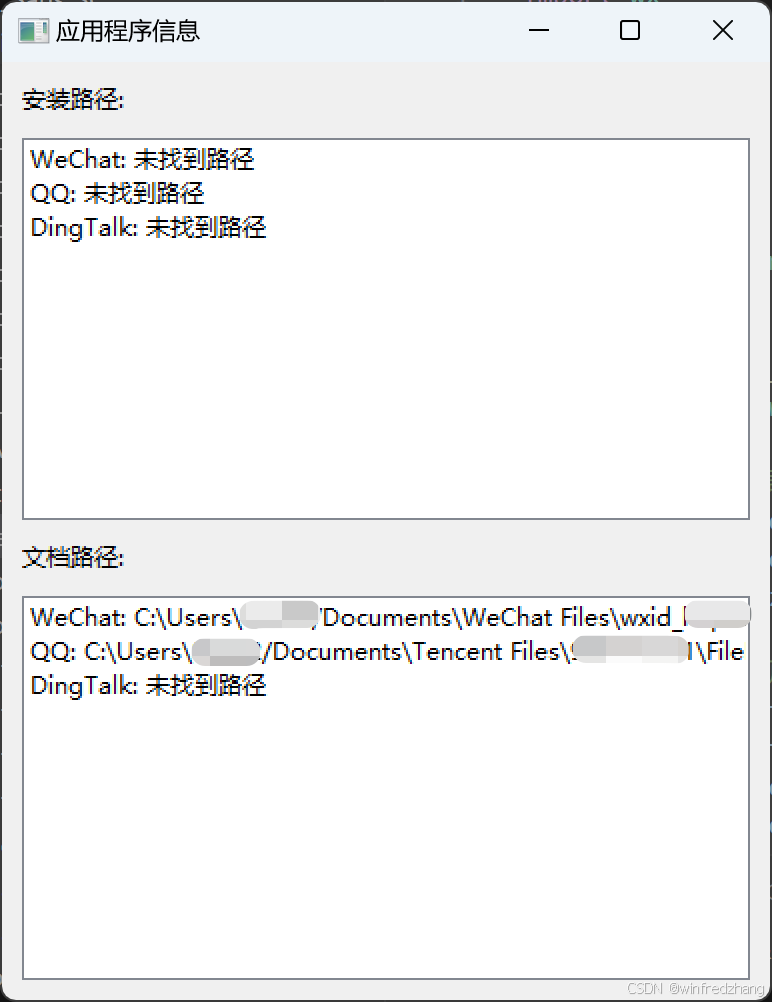
使用Python查找WeChat和QQ的安装路径和文档路径
在日常工作和生活中,我们经常需要查找某些应用程序的安装位置或者它们存储文件的位置。特别是对于像WeChat(微信)和QQ这样的即时通讯软件,了解它们的文件存储位置可以帮助我们更好地管理我们的聊天记录和共享文件。今天࿰…...

【AI大模型】深入Transformer架构:编码器部分的实现与解析(下)
目录 🍔 编码器介绍 🍔 前馈全连接层 2.1 前馈全连接层 2.2 前馈全连接层的代码分析 2.3 前馈全连接层总结 🍔 规范化层 3.1 规范化层的作用 3.2 规范化层的代码实现 3.3 规范化层总结 🍔 子层连接结构 4.1 子层连接结…...

【数据结构】【栈】算法汇总
一、顺序栈的操作 1.准备工作 #define STACK_INIT_SIZE 100 #define STACKINCREMENT 10 typedef struct{SElemType*base;SElemType*top;int stacksize; }SqStack; 2.栈的初始化 Status InitStack(SqStack &S){S.base(SElemType*)malloc(MAXSIZE*sizeof(SElemType));if(…...

如何训练自己的大模型,答案就在这里。
训练自己的AI大模型是一个复杂且资源密集型的任务,涉及多个详细步骤、数据集需求以及计算资源要求。以下是根据搜索结果提供的概述: 详细步骤 \1. 设定目标: - 首先需要明确模型的应用场景和目标,比如是进行分类、回归、生成文本…...

React18新特性
React 18新特性详解如下: 并发渲染(Concurrent Rendering): React 18引入了并发渲染特性,允许React在等待异步操作(如数据获取)时暂停和恢复渲染,从而提供更平滑的用户体验。 通过时…...

汽车发动机系统EMS详细解析
汽车发动机系统EMS,全称Engine-Management-System(发动机管理系统),是现代汽车电子控制技术的重要组成部分。以下是对汽车发动机系统EMS的详细解析,涵盖其定义、工作原理、主要组成、功能特点、技术发展以及市场应用等…...
【社保通-注册安全分析报告-滑动验证加载不正常导致安全隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

初学Vue(2)
文章目录 监视属性 watch深度监视computed 和 watch 之间的区别 绑定样式(class style)条件渲染列表渲染基本列表key的原理列表过滤列表排序收集表单中的数据 v-model过滤器(Vue3已移除) 监视属性 watch 当被监视的属性变化时&am…...

ThinkPHP5基础入门
文章目录 ThinkPHP5基础入门一、引言二、环境搭建1、前期准备2、目录结构 三、快速上手1、创建模块2、编写控制器3、编写视图4、编写模型 四、调试与部署1、调试模式2、关闭调试模式3、隐藏入口文件 五、总结 ThinkPHP5基础入门 一、引言 ThinkPHP5 是一个基于 MVC 和面向对象…...

Metal 之旅之MTLLibrary
什么是MSL? MSL是Metal Shading Language 的简称,为了更好的在GPU执行程序,苹果公司定义了一套类C的语言(Metal Shading Language ),在GPU运行的程序都是用这个语言来编写的。 什么是MTLLibrary? .metal后缀的文件…...
)
第十二章 Redis短信登录实战(基于Session)
目录 一、User类 二、ThreadLocal类 三、用户业务逻辑接口 四、用户业务逻辑接口实现类 五、用户控制层 六、用户登录拦截器 七、拦截器配置类 八、隐藏敏感信息的代码调整 完整的项目资源共享地址,当中包含了代码、资源文件以及Nginx(Wi…...

华为OD机试 - 九宫格游戏(Python/JS/C/C++ 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...
详解)
Pytorch库中torch.normal()详解
torch.normal()用法 torch.normal()函数,用于生成符合正态分布(高斯分布)的随机数。在 PyTorch 中,这个函数通常用于生成 Tensor。 该函数共有四个方法: overload def normal(mean: Tensor, std: Tensor, *, generat…...
atcoder-374(a-e)
atcoder-374 文章目录 atcoder-374ABC简洁的写法正解 D正解 E A #include<bits/stdc.h>using namespace std;signed main() {string s;cin>>s;string strs.substr(s.size()-3);if(str "san") puts("Yes");else puts("No");return 0…...
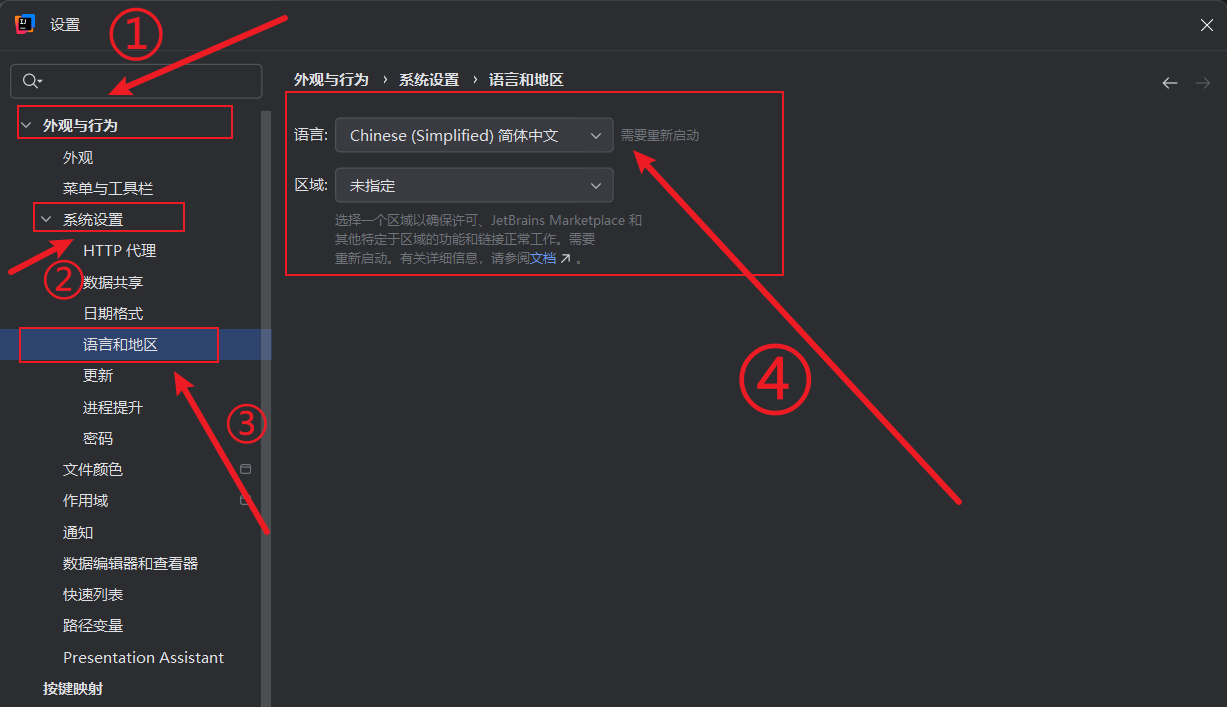
idea2024设置中文
今天下载idea2024.2版本,发现已经装过中文插件,但是还是不显示中文,找了半天原来还需要设置中文选项 方案一 点击文件 -> 关闭项目 点击自定义 -> 选择语言 方案二 点击文件 -> 设置 外观与行为 -> 系统设置 -> 语言和地区…...

跨境电商独立站轮询收款问题
想必做跨境电商独立站的小伙伴,对于PayPal是再熟悉不过了,PayPal是一个跨国际贸易的支付平台,对于做独立站的朋友来说跨境收款绝大部分都是依赖PayPal以及Stripe条纹了。简单来说PayPal跟国内的支付宝有点类似,但是PayPal它是跨国…...

[OS] 3.Insert and Remove Kernel Module
Insert and Remove Kernel Module 1. 切换到 root 账户 $ sudo su作用:Linux 内核模块的加载和卸载需要超级用户权限,因此你必须以 root 用户身份进行操作。sudo su 命令允许你从普通用户切换到 root 账户,从而获得系统的最高权限ÿ…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

Kubernetes部署Valheim游戏服务器:云原生架构实践指南
1. 项目概述:当维京英灵殿遇上Kubernetes如果你和我一样,既沉迷于《英灵神殿》(Valheim)里那种与三五好友一起伐木、采矿、建造长屋,然后被巨魔追得满地图跑的原始乐趣,又恰好是一名整天和容器、编排系统打…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

物联网安防系统故障排查与ESP8266固件刷写实战指南
1. 物联网安防系统故障排查实战做物联网安防系统,最怕的就是“哑火”。你花了好几天时间,把ESP8266、Raspberry Pi、MQTT Broker、Adafruit.IO和IFTTT像搭积木一样连起来,满心期待它能在关键时刻给你发条短信。结果,门被推开了&am…...
——原理与CUDA实现)
训练篇第9节:FlashAttention深度解析(一)——原理与CUDA实现
从 O(N) 到 O(N),FlashAttention 用一记“IO感知”的巧劲,彻底解锁了Transformer处理超长序列的能力 前言 回溯整个训练篇,我们已经系统性地打怪升级:从显存优化的“三板斧”(梯度累积、激活重计算、碎片化管理),到分布式训练的并行策略(数据并行、模型并行、流水线并…...

4.AI大模型-幻觉、记忆、参数-大模型底层运行机制
内容参考于:图灵AI大模型全栈 幻觉: 大模型的幻觉主要有两种,一种是回答的答案和问的问题不搭边,就是说回答的答案是乱编的,是没有真实性的,另一种是给了AI正确的资料,但是AI并没有根据我们给的…...
)
【负荷预测】基于LSTM-KAN的负荷预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案
PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案 【免费下载链接】PPO-PyTorch Minimal implementation of clipped objective Proximal Policy Optimization (PPO) in PyTorch 项目地址: https://gitcode.com/gh_mirrors/pp/PPO-PyTorch PPO-PyTorc…...