【AI大模型】深入Transformer架构:编码器部分的实现与解析(下)

目录
🍔 编码器介绍
🍔 前馈全连接层
2.1 前馈全连接层
2.2 前馈全连接层的代码分析
2.3 前馈全连接层总结
🍔 规范化层
3.1 规范化层的作用
3.2 规范化层的代码实现
3.3 规范化层总结
🍔 子层连接结构
4.1 子层连接结构:
4.2 子层连接结构的代码分析
4.3 子层连接结构总结
🍔 编码器层
5.1 编码器层的作用
5.2 编码器层的代码分析
5.3 编码器层总结
🍔 编码器
6.1 编码器的作用
6.2 编码器的代码分析
6.3 编码器总结
学习目标
🍀 了解编码器中各个组成部分的作用.
🍀 掌握编码器中各个组成部分的实现过程.
🍔 编码器介绍
编码器部分: * 由N个编码器层堆叠而成 * 每个编码器层由两个子层连接结构组成 * 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 * 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接。

🍔 前馈全连接层
2.1 前馈全连接层
-
在Transformer中前馈全连接层就是具有两层线性层的全连接网络.
-
前馈全连接层的作用:
- 考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
2.2 前馈全连接层的代码分析
# 通过类PositionwiseFeedForward来实现前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):"""初始化函数有三个输入参数分别是d_model, d_ff,和dropout=0.1,第一个是线性层的输入维度也是第二个线性层的输出维度,因为我们希望输入通过前馈全连接层后输入和输出的维度不变. 第二个参数d_ff就是第二个线性层的输入维度和第一个线性层的输出维度. 最后一个是dropout置0比率."""super(PositionwiseFeedForward, self).__init__()# 首先按照我们预期使用nn实例化了两个线性层对象,self.w1和self.w2# 它们的参数分别是d_model, d_ff和d_ff, d_modelself.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)# 然后使用nn的Dropout实例化了对象self.dropoutself.dropout = nn.Dropout(dropout)def forward(self, x):"""输入参数为x,代表来自上一层的输出"""# 首先经过第一个线性层,然后使用Funtional中relu函数进行激活,# 之后再使用dropout进行随机置0,最后通过第二个线性层w2,返回最终结果.return self.w2(self.dropout(F.relu(self.w1(x))))
-
ReLU函数公式: ReLU(x)=max(0, x)
-
ReLU函数图像:

- 实例化参数:
d_model = 512# 线性变化的维度
d_ff = 64dropout = 0.2
- 输入参数:
# 输入参数x可以是多头注意力机制的输出
x = mha_result
tensor([[[-0.3075, 1.5687, -2.5693, ..., -1.1098, 0.0878, -3.3609],[ 3.8065, -2.4538, -0.3708, ..., -1.5205, -1.1488, -1.3984],[ 2.4190, 0.5376, -2.8475, ..., 1.4218, -0.4488, -0.2984],[ 2.9356, 0.3620, -3.8722, ..., -0.7996, 0.1468, 1.0345]],[[ 1.1423, 0.6038, 0.0954, ..., 2.2679, -5.7749, 1.4132],[ 2.4066, -0.2777, 2.8102, ..., 0.1137, -3.9517, -2.9246],[ 5.8201, 1.1534, -1.9191, ..., 0.1410, -7.6110, 1.0046],[ 3.1209, 1.0008, -0.5317, ..., 2.8619, -6.3204, -1.3435]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
- 调用:
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)
print(ff_result)
- 输出效果:
tensor([[[-1.9488e+00, -3.4060e-01, -1.1216e+00, ..., 1.8203e-01,-2.6336e+00, 2.0917e-03],[-2.5875e-02, 1.1523e-01, -9.5437e-01, ..., -2.6257e-01,-5.7620e-01, -1.9225e-01],[-8.7508e-01, 1.0092e+00, -1.6515e+00, ..., 3.4446e-02,-1.5933e+00, -3.1760e-01],[-2.7507e-01, 4.7225e-01, -2.0318e-01, ..., 1.0530e+00,-3.7910e-01, -9.7730e-01]],[[-2.2575e+00, -2.0904e+00, 2.9427e+00, ..., 9.6574e-01,-1.9754e+00, 1.2797e+00],[-1.5114e+00, -4.7963e-01, 1.2881e+00, ..., -2.4882e-02,-1.5896e+00, -1.0350e+00],[ 1.7416e-01, -4.0688e-01, 1.9289e+00, ..., -4.9754e-01,-1.6320e+00, -1.5217e+00],[-1.0874e-01, -3.3842e-01, 2.9379e-01, ..., -5.1276e-01,-1.6150e+00, -1.1295e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
2.3 前馈全连接层总结
-
学习了什么是前馈全连接层:
- 在Transformer中前馈全连接层就是具有两层线性层的全连接网络.
-
学习了前馈全连接层的作用:
- 考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
-
学习并实现了前馈全连接层的类: PositionwiseFeedForward
- 它的实例化参数为d_model, d_ff, dropout, 分别代表词嵌入维度, 线性变换维度, 和置零比率.
- 它的输入参数x, 表示上层的输出.
- 它的输出是经过2层线性网络变换的特征表示.
🍔 规范化层
3.1 规范化层的作用
- 它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢. 因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内.
3.2 规范化层的代码实现
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):"""初始化函数有两个参数, 一个是features, 表示词嵌入的维度,另一个是eps它是一个足够小的数, 在规范化公式的分母中出现,防止分母为0.默认是1e-6."""super(LayerNorm, self).__init__()# 根据features的形状初始化两个参数张量a2,和b2,第一个初始化为1张量,# 也就是里面的元素都是1,第二个初始化为0张量,也就是里面的元素都是0,这两个张量就是规范化层的参数,# 因为直接对上一层得到的结果做规范化公式计算,将改变结果的正常表征,因此就需要有参数作为调节因子,# 使其即能满足规范化要求,又能不改变针对目标的表征.最后使用nn.parameter封装,代表他们是模型的参数。self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))# 把eps传到类中self.eps = epsdef forward(self, x):"""输入参数x代表来自上一层的输出"""# 在函数中,首先对输入变量x求其最后一个维度的均值,并保持输出维度与输入维度一致.# 接着再求最后一个维度的标准差,然后就是根据规范化公式,用x减去均值除以标准差获得规范化的结果,# 最后对结果乘以我们的缩放参数,即a2,*号代表同型点乘,即对应位置进行乘法操作,加上位移参数b2.返回即可.mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2
- 实例化参数:
features = d_model = 512
eps = 1e-6
- 输入参数:
# 输入x来自前馈全连接层的输出
x = ff_result
tensor([[[-1.9488e+00, -3.4060e-01, -1.1216e+00, ..., 1.8203e-01,-2.6336e+00, 2.0917e-03],[-2.5875e-02, 1.1523e-01, -9.5437e-01, ..., -2.6257e-01,-5.7620e-01, -1.9225e-01],[-8.7508e-01, 1.0092e+00, -1.6515e+00, ..., 3.4446e-02,-1.5933e+00, -3.1760e-01],[-2.7507e-01, 4.7225e-01, -2.0318e-01, ..., 1.0530e+00,-3.7910e-01, -9.7730e-01]],[[-2.2575e+00, -2.0904e+00, 2.9427e+00, ..., 9.6574e-01,-1.9754e+00, 1.2797e+00],[-1.5114e+00, -4.7963e-01, 1.2881e+00, ..., -2.4882e-02,-1.5896e+00, -1.0350e+00],[ 1.7416e-01, -4.0688e-01, 1.9289e+00, ..., -4.9754e-01,-1.6320e+00, -1.5217e+00],[-1.0874e-01, -3.3842e-01, 2.9379e-01, ..., -5.1276e-01,-1.6150e+00, -1.1295e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
- 调用:
ln = LayerNorm(features, eps)
ln_result = ln(x)
print(ln_result)
- 输出效果:
tensor([[[ 2.2697, 1.3911, -0.4417, ..., 0.9937, 0.6589, -1.1902],[ 1.5876, 0.5182, 0.6220, ..., 0.9836, 0.0338, -1.3393],[ 1.8261, 2.0161, 0.2272, ..., 0.3004, 0.5660, -0.9044],[ 1.5429, 1.3221, -0.2933, ..., 0.0406, 1.0603, 1.4666]],[[ 0.2378, 0.9952, 1.2621, ..., -0.4334, -1.1644, 1.2082],[-1.0209, 0.6435, 0.4235, ..., -0.3448, -1.0560, 1.2347],[-0.8158, 0.7118, 0.4110, ..., 0.0990, -1.4833, 1.9434],[ 0.9857, 2.3924, 0.3819, ..., 0.0157, -1.6300, 1.2251]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3.3 规范化层总结
-
学习了规范化层的作用:
- 它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢. 因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内.
-
学习并实现了规范化层的类: LayerNorm
- 它的实例化参数有两个, features和eps,分别表示词嵌入特征大小,和一个足够小的数.
- 它的输入参数x代表来自上一层的输出.
- 它的输出就是经过规范化的特征表示.
🍔 子层连接结构
4.1 子层连接结构:
-
如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.
-
子层连接结构图:


4.2 子层连接结构的代码分析
# 使用SublayerConnection来实现子层连接结构的类
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):"""它输入参数有两个, size以及dropout, size一般是都是词嵌入维度的大小, dropout本身是对模型结构中的节点数进行随机抑制的比率, 又因为节点被抑制等效就是该节点的输出都是0,因此也可以把dropout看作是对输出矩阵的随机置0的比率."""super(SublayerConnection, self).__init__()# 实例化了规范化对象self.normself.norm = LayerNorm(size)# 又使用nn中预定义的droupout实例化一个self.dropout对象.self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):"""前向逻辑函数中, 接收上一个层或者子层的输入作为第一个参数,将该子层连接中的子层函数作为第二个参数"""# 我们首先对输出进行规范化,然后将结果传给子层处理,之后再对子层进行dropout操作,# 随机停止一些网络中神经元的作用,来防止过拟合. 最后还有一个add操作, # 因为存在跳跃连接,所以是将输入x与dropout后的子层输出结果相加作为最终的子层连接输出.return x + self.dropout(sublayer(self.norm(x)))
- 实例化参数
size = 512
dropout = 0.2
head = 8
d_model = 512
- 输入参数:
# 令x为位置编码器的输出
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))# 假设子层中装的是多头注意力层, 实例化这个类
self_attn = MultiHeadedAttention(head, d_model)# 使用lambda获得一个函数类型的子层
sublayer = lambda x: self_attn(x, x, x, mask)
- 调用:
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
- 输出效果:
tensor([[[ 14.8830, 22.4106, -31.4739, ..., 21.0882, -10.0338, -0.2588],[-25.1435, 2.9246, -16.1235, ..., 10.5069, -7.1007, -3.7396],[ 0.1374, 32.6438, 12.3680, ..., -12.0251, -40.5829, 2.2297],[-13.3123, 55.4689, 9.5420, ..., -12.6622, 23.4496, 21.1531]],[[ 13.3533, 17.5674, -13.3354, ..., 29.1366, -6.4898, 35.8614],[-35.2286, 18.7378, -31.4337, ..., 11.1726, 20.6372, 29.8689],[-30.7627, 0.0000, -57.0587, ..., 15.0724, -10.7196, -18.6290],[ -2.7757, -19.6408, 0.0000, ..., 12.7660, 21.6843, -35.4784]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
4.3 子层连接结构总结
-
什么是子层连接结构:
- 如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构), 在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.
-
学习并实现了子层连接结构的类: SublayerConnection
- 类的初始化函数输入参数是size, dropout, 分别代表词嵌入大小和置零比率.
- 它的实例化对象输入参数是x, sublayer, 分别代表上一层输出以及子层的函数表示.
- 它的输出就是通过子层连接结构处理的输出.
🍔 编码器层
5.1 编码器层的作用
-
作为编码器的组成单元, 每个编码器层完成一次对输入的特征提取过程, 即编码过程.
-
编码器层的构成图:

5.2 编码器层的代码分析
# 使用EncoderLayer类实现编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):"""它的初始化函数参数有四个,分别是size,其实就是我们词嵌入维度的大小,它也将作为我们编码器层的大小, 第二个self_attn,之后我们将传入多头自注意力子层实例化对象, 并且是自注意力机制, 第三个是feed_froward, 之后我们将传入前馈全连接层实例化对象, 最后一个是置0比率dropout."""super(EncoderLayer, self).__init__()# 首先将self_attn和feed_forward传入其中.self.self_attn = self_attnself.feed_forward = feed_forward# 如图所示, 编码器层中有两个子层连接结构, 所以使用clones函数进行克隆self.sublayer = clones(SublayerConnection(size, dropout), 2)# 把size传入其中self.size = sizedef forward(self, x, mask):"""forward函数中有两个输入参数,x和mask,分别代表上一层的输出,和掩码张量mask."""# 里面就是按照结构图左侧的流程. 首先通过第一个子层连接结构,其中包含多头自注意力子层,# 然后通过第二个子层连接结构,其中包含前馈全连接子层. 最后返回结果.x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)
- 实例化参数:
size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
- 调用:
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)
print(el_result)
print(el_result.shape)
- 输出效果:
tensor([[[ 33.6988, -30.7224, 20.9575, ..., 5.2968, -48.5658, 20.0734],[-18.1999, 34.2358, 40.3094, ..., 10.1102, 58.3381, 58.4962],[ 32.1243, 16.7921, -6.8024, ..., 23.0022, -18.1463, -17.1263],[ -9.3475, -3.3605, -55.3494, ..., 43.6333, -0.1900, 0.1625]],[[ 32.8937, -46.2808, 8.5047, ..., 29.1837, 22.5962, -14.4349],[ 21.3379, 20.0657, -31.7256, ..., -13.4079, -44.0706, -9.9504],[ 19.7478, -1.0848, 11.8884, ..., -9.5794, 0.0675, -4.7123],[ -6.8023, -16.1176, 20.9476, ..., -6.5469, 34.8391, -14.9798]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
5.3 编码器层总结
-
学习了编码器层的作用:
- 作为编码器的组成单元, 每个编码器层完成一次对输入的特征提取过程, 即编码过程.
-
学习并实现了编码器层的类: EncoderLayer
- 类的初始化函数共有4个, 别是size,其实就是我们词嵌入维度的大小. 第二个self_attn,之后我们将传入多头自注意力子层实例化对象, 并且是自注意力机制. 第三个是feed_froward, 之后我们将传入前馈全连接层实例化对象. 最后一个是置0比率dropout.
- 实例化对象的输入参数有2个,x代表来自上一层的输出, mask代表掩码张量.
- 它的输出代表经过整个编码层的特征表示.
🍔 编码器
6.1 编码器的作用
-
编码器用于对输入进行指定的特征提取过程, 也称为编码, 由N个编码器层堆叠而成.
-
编码器的结构图:

6.2 编码器的代码分析
# 使用Encoder类来实现编码器
class Encoder(nn.Module):def __init__(self, layer, N):"""初始化函数的两个参数分别代表编码器层和编码器层的个数"""super(Encoder, self).__init__()# 首先使用clones函数克隆N个编码器层放在self.layers中self.layers = clones(layer, N)# 再初始化一个规范化层, 它将用在编码器的最后面.self.norm = LayerNorm(layer.size)def forward(self, x, mask):"""forward函数的输入和编码器层相同, x代表上一层的输出, mask代表掩码张量"""# 首先就是对我们克隆的编码器层进行循环,每次都会得到一个新的x,# 这个循环的过程,就相当于输出的x经过了N个编码器层的处理. # 最后再通过规范化层的对象self.norm进行处理,最后返回结果. for layer in self.layers:x = layer(x, mask)return self.norm(x)
- 实例化参数:
# 第一个实例化参数layer, 它是一个编码器层的实例化对象, 因此需要传入编码器层的参数
# 又因为编码器层中的子层是不共享的, 因此需要使用深度拷贝各个对象.
size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)# 编码器中编码器层的个数N
N = 8
mask = Variable(torch.zeros(8, 4, 4))
- 调用:
en = Encoder(layer, N)
en_result = en(x, mask)
print(en_result)
print(en_result.shape)
- 输出效果:
tensor([[[-0.2081, -0.3586, -0.2353, ..., 2.5646, -0.2851, 0.0238],[ 0.7957, -0.5481, 1.2443, ..., 0.7927, 0.6404, -0.0484],[-0.1212, 0.4320, -0.5644, ..., 1.3287, -0.0935, -0.6861],[-0.3937, -0.6150, 2.2394, ..., -1.5354, 0.7981, 1.7907]],[[-2.3005, 0.3757, 1.0360, ..., 1.4019, 0.6493, -0.1467],[ 0.5653, 0.1569, 0.4075, ..., -0.3205, 1.4774, -0.5856],[-1.0555, 0.0061, -1.8165, ..., -0.4339, -1.8780, 0.2467],[-2.1617, -1.5532, -1.4330, ..., -0.9433, -0.5304, -1.7022]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
6.3 编码器总结
-
学习了编码器的作用:
- 编码器用于对输入进行指定的特征提取过程, 也称为编码, 由N个编码器层堆叠而成.
-
学习并实现了编码器的类: Encoder
- 类的初始化函数参数有两个,分别是layer和N,代表编码器层和编码器层的个数.
- forward函数的输入参数也有两个, 和编码器层的forward相同, x代表上一层的输出, mask代码掩码张量.
- 编码器类的输出就是Transformer中编码器的特征提取表示, 它将成为解码器的输入的一部分.

相关文章:
【AI大模型】深入Transformer架构:编码器部分的实现与解析(下)
目录 🍔 编码器介绍 🍔 前馈全连接层 2.1 前馈全连接层 2.2 前馈全连接层的代码分析 2.3 前馈全连接层总结 🍔 规范化层 3.1 规范化层的作用 3.2 规范化层的代码实现 3.3 规范化层总结 🍔 子层连接结构 4.1 子层连接结…...

【数据结构】【栈】算法汇总
一、顺序栈的操作 1.准备工作 #define STACK_INIT_SIZE 100 #define STACKINCREMENT 10 typedef struct{SElemType*base;SElemType*top;int stacksize; }SqStack; 2.栈的初始化 Status InitStack(SqStack &S){S.base(SElemType*)malloc(MAXSIZE*sizeof(SElemType));if(…...

如何训练自己的大模型,答案就在这里。
训练自己的AI大模型是一个复杂且资源密集型的任务,涉及多个详细步骤、数据集需求以及计算资源要求。以下是根据搜索结果提供的概述: 详细步骤 \1. 设定目标: - 首先需要明确模型的应用场景和目标,比如是进行分类、回归、生成文本…...

React18新特性
React 18新特性详解如下: 并发渲染(Concurrent Rendering): React 18引入了并发渲染特性,允许React在等待异步操作(如数据获取)时暂停和恢复渲染,从而提供更平滑的用户体验。 通过时…...

汽车发动机系统EMS详细解析
汽车发动机系统EMS,全称Engine-Management-System(发动机管理系统),是现代汽车电子控制技术的重要组成部分。以下是对汽车发动机系统EMS的详细解析,涵盖其定义、工作原理、主要组成、功能特点、技术发展以及市场应用等…...
【社保通-注册安全分析报告-滑动验证加载不正常导致安全隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

初学Vue(2)
文章目录 监视属性 watch深度监视computed 和 watch 之间的区别 绑定样式(class style)条件渲染列表渲染基本列表key的原理列表过滤列表排序收集表单中的数据 v-model过滤器(Vue3已移除) 监视属性 watch 当被监视的属性变化时&am…...

ThinkPHP5基础入门
文章目录 ThinkPHP5基础入门一、引言二、环境搭建1、前期准备2、目录结构 三、快速上手1、创建模块2、编写控制器3、编写视图4、编写模型 四、调试与部署1、调试模式2、关闭调试模式3、隐藏入口文件 五、总结 ThinkPHP5基础入门 一、引言 ThinkPHP5 是一个基于 MVC 和面向对象…...

Metal 之旅之MTLLibrary
什么是MSL? MSL是Metal Shading Language 的简称,为了更好的在GPU执行程序,苹果公司定义了一套类C的语言(Metal Shading Language ),在GPU运行的程序都是用这个语言来编写的。 什么是MTLLibrary? .metal后缀的文件…...
)
第十二章 Redis短信登录实战(基于Session)
目录 一、User类 二、ThreadLocal类 三、用户业务逻辑接口 四、用户业务逻辑接口实现类 五、用户控制层 六、用户登录拦截器 七、拦截器配置类 八、隐藏敏感信息的代码调整 完整的项目资源共享地址,当中包含了代码、资源文件以及Nginx(Wi…...

华为OD机试 - 九宫格游戏(Python/JS/C/C++ 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...
详解)
Pytorch库中torch.normal()详解
torch.normal()用法 torch.normal()函数,用于生成符合正态分布(高斯分布)的随机数。在 PyTorch 中,这个函数通常用于生成 Tensor。 该函数共有四个方法: overload def normal(mean: Tensor, std: Tensor, *, generat…...
atcoder-374(a-e)
atcoder-374 文章目录 atcoder-374ABC简洁的写法正解 D正解 E A #include<bits/stdc.h>using namespace std;signed main() {string s;cin>>s;string strs.substr(s.size()-3);if(str "san") puts("Yes");else puts("No");return 0…...
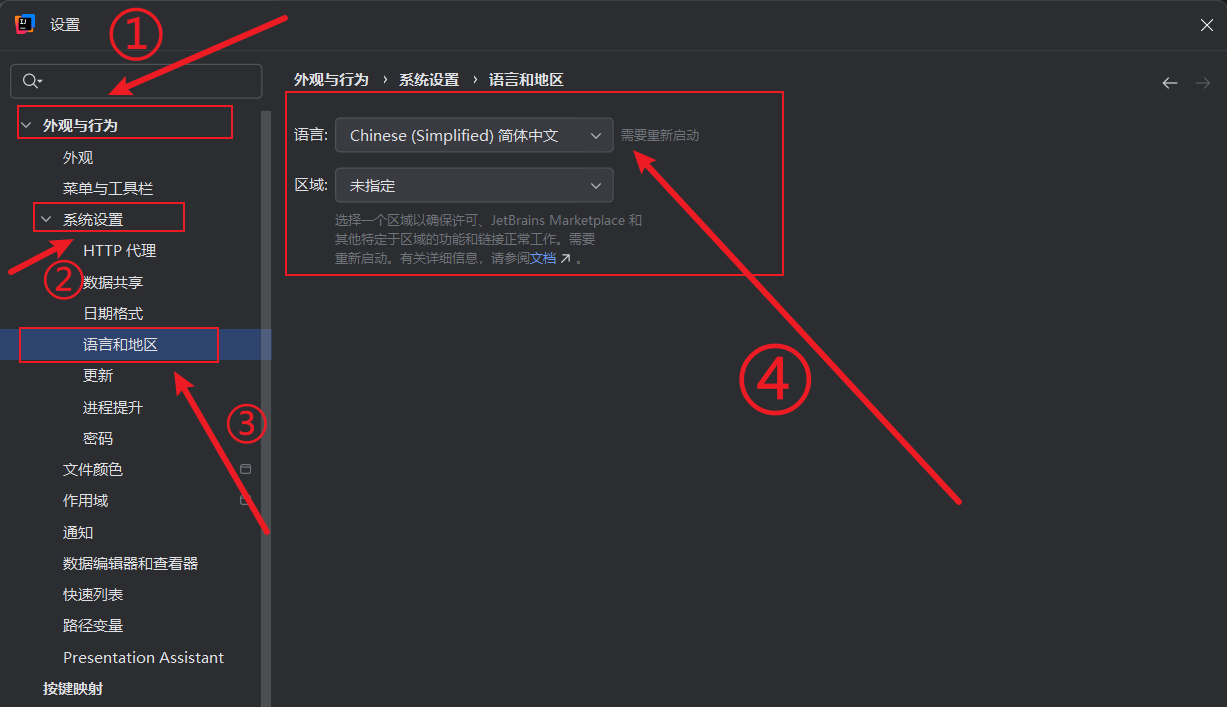
idea2024设置中文
今天下载idea2024.2版本,发现已经装过中文插件,但是还是不显示中文,找了半天原来还需要设置中文选项 方案一 点击文件 -> 关闭项目 点击自定义 -> 选择语言 方案二 点击文件 -> 设置 外观与行为 -> 系统设置 -> 语言和地区…...

跨境电商独立站轮询收款问题
想必做跨境电商独立站的小伙伴,对于PayPal是再熟悉不过了,PayPal是一个跨国际贸易的支付平台,对于做独立站的朋友来说跨境收款绝大部分都是依赖PayPal以及Stripe条纹了。简单来说PayPal跟国内的支付宝有点类似,但是PayPal它是跨国…...

[OS] 3.Insert and Remove Kernel Module
Insert and Remove Kernel Module 1. 切换到 root 账户 $ sudo su作用:Linux 内核模块的加载和卸载需要超级用户权限,因此你必须以 root 用户身份进行操作。sudo su 命令允许你从普通用户切换到 root 账户,从而获得系统的最高权限ÿ…...

updatedb命令:更新locate数据库
一、命令简介 updatedb 命令用于更新 locate 命令使用的文件数据库,以便 locate 命令能够快速定位文件。 二、命令参数 命令格式 updatedb [选项]选项 -l: 仅更新本地文件系统(默认行为)-U: 更新所有文件系统-o D…...

分布式共识算法ZAB
文章目录 概述一、ZAB算法概述二、ZAB算法的核心特性三、ZAB算法的工作流程四、ZAB算法的优势与局限 其他共识算法 概述 分布式共识算法ZAB,全称Zookeeper Atomic Broadcast(Zookeeper原子广播),是Zookeeper保证数据一致性的核心…...

程序化交易与非程序化交易者盈利能力孰优孰劣
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

【JavaEE】【多线程】进程与线程的概念
目录 进程系统管理进程系统操作进程进程控制块PCB关键属性cpu对进程的操作进程调度 线程线程与进程线程资源分配线程调度 线程与进程区别线程简单操作代码创建线程查看线程 进程 进程是操作系统对一个正在运行的程序的一种抽象,可以把进程看做程序的一次运行过程&a…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...
深入Transformer内部:LoRA到底改动了哪部分权重才让模型“学会”新任务?
深入Transformer内部:LoRA如何通过低秩更新重塑大模型能力 在自然语言处理领域,大型预训练模型的微调一直是个计算密集型任务。传统全参数微调需要更新数十亿甚至数千亿参数,这对大多数研究者和企业来说都是难以承受的负担。低秩适应(LoRA)技…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

从零构建团队技能仓库:结构化知识管理与VuePress实践
1. 项目概述:一个技能仓库的诞生与价值 最近在整理团队内部的技术资产时,我一直在思考一个问题:如何让那些散落在个人笔记、项目代码片段、会议纪要里的“隐性知识”和“最佳实践”沉淀下来,变成团队可复用、可传承的“显性资产”…...

AI智能体记忆系统设计:从RAG到长期记忆的工程实践
1. 项目概述:从“记忆”到“智能”的跨越在AI智能体(Agent)的开发浪潮中,我们常常面临一个核心挑战:如何让智能体在复杂的、多轮次的交互中,表现得像一个真正有“记忆”和“经验”的专家?传统的…...

Deep Lake:AI数据湖实战指南,解决深度学习数据管理难题
1. 项目概述:当数据湖遇上深度学习如果你在深度学习项目里被数据管理搞得焦头烂额过,那你肯定懂我在说什么。模型训练到一半,发现数据版本不对,或者想对海量图像、视频做快速查询和采样,结果被IO速度卡得死死的。传统的…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

KMS智能激活终极指南:如何一键永久激活Windows和Office
KMS智能激活终极指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次重装系统后都要重新激活Office&…...