贪心算法c++
贪心算法C++概述
一、贪心算法的基本概念
贪心算法(Greedy Algorithm),又名贪婪法,是一种解决优化问题的常用算法。其基本思想是在问题的每个决策阶段,都选择当前看起来最优的选择,即贪心地做出局部最优的决策,以期获得全局最优解。简单来说,就像是一个贪婪的人,在每一步都只考虑眼前的最大利益,希望最终这些局部最优的选择能够堆叠出全局最优的结果。例如在找零钱问题中,如果有1元、5角、1角的硬币,要凑出8角钱,按照贪心算法,会优先选择面值大的硬币,先选5角,再选3个1角,这就是在每一步都做局部最优选择。在C++中实现贪心算法时,会充分利用C++语言高效的特性以及丰富的标准模板库(STL),其中包含了大量的数据结构和算法,方便程序员实现贪心算法 。
二、贪心算法的工作原理
-
贪心选择性质
-
原问题的整体最优解可以通过一系列局部最优的选择得到。每一步的选择都是基于当前状态下的最优解,而且这种选择不依赖于未做出的选择,只依赖于已做出的选择。例如在活动安排问题中,假设有一系列活动,每个活动都有开始时间和结束时间。按照贪心算法,我们可以选择最早结束的活动作为第一个活动,然后在剩下的活动中继续选择最早结束的活动,这个选择过程就是每一步都做出局部最优选择,而且每个选择只与当前已经选择的活动有关,不考虑未来可能的其他活动组合。
-
-
最优子结构性质
-
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。这是贪心算法能够求解问题的关键。例如在构建最小生成树的Prim算法和Kruskal算法中,原问题是构建整个图的最小生成树,子问题是构建图的一部分的最小生成树,整个最小生成树的最优解是由各个子树(子问题的最优解)组合而成的。在C++实现中,我们需要准确地识别问题是否具有这两个性质,才能正确地运用贪心算法。如果不满足这两个性质,贪心算法可能无法得到正确的全局最优解。
-
三、贪心算法在C++中的应用场景
-
硬币找零问题
-
在某些硬币组合下,贪心算法总是可以得到最优解。例如有1元、5角、1角的硬币组合,要凑出一定金额,我们可以每次选择尽可能大面值的硬币,直到凑出目标金额。在C++中实现这个过程,可以通过定义一个表示硬币面值的数组,然后按照从大到小的顺序遍历这个数组,计算需要的硬币数量。
-
-
活动安排问题
-
假设有n个活动,每个活动都有开始时间和结束时间。要安排这些活动使得在一个场地中能够进行最多的活动。按照贪心算法,可以先按照活动结束时间对活动进行排序,然后选择第一个活动(最早结束的活动),接着在剩下的活动中选择开始时间大于等于上一个活动结束时间的最早结束的活动,依次类推。在C++中,可以使用结构体来表示活动的开始时间和结束时间,然后利用STL中的排序算法(如
std::sort)对活动数组进行排序,再按照贪心策略选择活动。
-
-
最小生成树问题(Prim算法和Kruskal算法)
-
在构建图的最小生成树时,Prim算法从一个顶点开始,每次选择与当前已连接顶点集合中距离最近(权值最小)的顶点加入集合,这个过程就是贪心选择。Kruskal算法则是先将所有边按照权值从小到大排序,然后每次选择一条不会形成环的最小权值边加入最小生成树,也是贪心策略的体现。在C++中,对于图的表示可以使用邻接矩阵或者邻接表,在实现这两个算法时,要充分利用C++的特性来高效地操作数据结构,例如使用STL中的优先队列(
std::priority_queue)可以方便地在Prim算法中获取最小权值的边。
-
如何使用贪心算法
一、贪心算法C++基础介绍
贪心算法(greedy algorithm)是一种常见的解决优化问题的算法,其基本思想是在问题的每个决策阶段,都选择当前看起来最优的选择,即贪心地做出局部最优的决策,以期获得全局最优解。它就像是模拟一个“贪心”的人做出决策的过程,这个人在每一步行动时总是按某种指标选取最优的操作。
在C++中实现贪心算法时,需要确保算法满足贪心选择性质和最优子结构。贪心选择性质是指原问题的整体最优解可以通过一系列局部最优的选择得到,也就是每一步的选择在当下是最优的,并且不需要考虑整体的最优情况就能做出这个选择。最优子结构是指问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。例如在硬币找零问题中,如果硬币的面值组合是特定的(如1元、5角、1角),就可以使用贪心算法。假设要找零8角钱,贪心算法会先选择5角,再选择3个1角,这个过程中每次选择都是当下能让剩余找零金额最小的选择,并且这个问题满足最优子结构,即整体的找零最优解可以由每一步的局部最优解组成。
贪心算法简洁且高效,在许多实际问题中有着广泛的应用,比如活动安排问题、最优装载问题、单源最短路问题(Dijkstra算法)等。它和动态规划算法有一定的相似性,但又有所不同。动态规划会考虑所有可能的子问题解并进行记录,以避免重复计算,而贪心算法则更侧重于每一步的局部最优解,并不一定记录所有子问题的解。
二、贪心算法C++实例分析
(一)活动安排问题
-
问题描述
-
有一系列活动,每个活动都有开始时间和结束时间。需要在这些活动中选择出尽可能多的相互兼容的活动,使得在同一时间内最多只能进行一个活动。例如有活动A(1, 3),活动B(2, 5),活动C(4, 6),这里的数字分别表示活动的开始时间和结束时间。
-
-
算法设计
-
问题分析:要选择最多的相互兼容的活动,直观上可以按照活动结束时间的先后顺序进行选择。每次选择结束时间最早的活动,这样就能给后面的活动留出更多的时间。
-
建模:可以将活动看作一个结构体,结构体包含开始时间和结束时间两个成员变量。
-
算法描述:首先对所有活动按照结束时间进行排序。然后选择第一个活动,接着遍历剩余的活动,只要活动的开始时间大于等于上一个已选活动的结束时间,就选择该活动。
-
-
C++实现示例代码
#include <iostream> #include <vector> #include <algorithm> using namespace std; // 定义活动结构体 struct Activity { int start; int end; }; // 比较函数,用于按照活动结束时间排序 bool compare(Activity a, Activity b) { return a.end < b.end; } // 活动安排函数 int activitySelection(vector<Activity>& activities) { if (activities.empty()) return 0; // 按照结束时间排序 sort(activities.begin(), activities.end(), compare); int count = 1; int lastEnd = activities[0].end; for (int i = 1; i < activities.size(); i++) { if (activities[i].start >= lastEnd) { count++; lastEnd = activities[i].end; } } return count; }
-
时间复杂度和空间复杂度分析
-
时间复杂度:主要取决于排序算法的时间复杂度,这里使用的是标准库的
sort函数,其平均时间复杂度为O(n log n)O(nlogn),其中nn是活动的数量。遍历活动的时间复杂度为O(n)O(n),所以总的时间复杂度为O(n log n)O(nlogn)。 -
空间复杂度:只使用了几个常量级别的额外变量,所以空间复杂度为O(1)O(1)。
-
(二)硬币找零问题
-
问题描述
-
给定一定金额的找零和一些硬币的面值,用最少的硬币数量来凑出这个找零金额。例如有面值为1元、5角、1角的硬币,要找零8角钱。
-
-
算法设计
-
问题分析:对于某些硬币组合,可以每次选择面值最大的硬币,这样能使硬币数量最少。
-
建模:可以将硬币面值存储在一个数组中,找零金额作为一个变量。
-
算法描述:从最大面值的硬币开始,尽可能多地使用该面值的硬币,直到剩余找零金额小于该面值,然后再选择下一个较小面值的硬币,重复这个过程。
-
-
C++实现示例代码
#include <iostream> #include <vector> using namespace std; // 硬币找零函数 int coinChange(vector<int>& coins, int amount) { int coin_count = 0; int n = coins.size(); for (int i = n - 1; i >= 0; i--) { while (amount >= coins[i]) { amount -= coins[i]; coin_count++; } } if (amount > 0) return -1; return coin_count; }
-
时间复杂度和空间复杂度分析
-
时间复杂度:假设硬币的种类为kk,找零金额为mm,在最坏情况下,每次都只能使用1个最小面值的硬币,时间复杂度为O(km)O(km)。
-
空间复杂度:只使用了几个常量级别的额外变量,所以空间复杂度为O(1)O(1)。
-
三、贪心算法C++代码实现技巧
(一)问题建模
-
明确问题的目标和约束条件
-
在开始编写代码之前,必须清晰地理解问题的目标是什么,例如是求最大值、最小值,还是寻找某种最优的组合等。同时,也要清楚问题的约束条件,如数据的范围、元素之间的关系等。以背包问题为例,目标是在有限的背包容量下装入价值最大的物品,约束条件就是背包的容量以及每个物品的重量和价值。如果没有准确把握这些,就很难构建出正确的贪心策略。
-
-
将问题转化为数学模型
-
把实际问题转化为数学形式可以更方便地进行分析和求解。比如在活动安排问题中,可以将活动抽象为包含开始时间和结束时间的结构体,这样就可以利用数学上的比较和排序操作来处理活动之间的关系。在硬币找零问题中,把硬币面值和找零金额看作数字,通过数字之间的运算来确定找零的方案。这种数学模型的建立有助于确定数据结构的选择以及后续算法的设计。
-
(二)排序操作
-
确定排序的依据
-
根据贪心策略,确定按照什么指标对数据进行排序。在活动安排问题中,按照活动的结束时间排序是因为我们希望先选择结束时间早的活动,这样能给后面的活动留出更多的时间。如果排序依据选择错误,可能会导致贪心算法无法得到正确的结果。例如在活动安排问题中,如果按照开始时间排序,就不能保证选择到最多的相互兼容的活动。
-
-
选择合适的排序算法
-
C++标准库提供了多种排序算法,如
sort(快速排序的优化版本,平均时间复杂度为O(n log n)O(nlogn))、stable_sort(稳定排序,时间复杂度为O(n log n)O(nlogn)到O(n^2)O(n2)之间)等。在大多数情况下,sort算法就可以满足需求。但如果对排序的稳定性有要求(即相等元素的相对顺序在排序前后不变),就需要选择stable_sort。另外,如果数据规模较小且已知数据接近有序状态,插入排序等简单排序算法可能会有更好的性能。
-
(三)贪心策略的实现
-
设计每一步的最优选择规则
-
这是贪心算法的核心部分。根据问题的目标和约束条件,设计出每一步选择的规则。例如在最优装载问题中(将一些物品装入一艘船,船的载重量有限,求最多能装多少物品,假设物品重量已知),贪心策略就是按照物品重量从小到大的顺序选择物品,只要船还能装下就选择该物品。这个规则的设计是基于想要尽可能多地装载物品,而轻的物品更有利于达到这个目标。
-
-
代码中体现贪心选择
-
在代码中,要按照设计好的贪心选择规则进行逻辑编写。例如在上述最优装载问题的C++代码实现中,可以先对物品重量进行排序,然后依次检查每个物品是否能装入船中,能装就选择该物品并更新船的剩余载重量。通过这种方式在代码中实现贪心选择,确保每一步都按照贪心策略进行操作。
-
四、贪心算法C++优化方法
(一)优化贪心策略
-
深入分析问题结构
-
有时候,初始设计的贪心策略可能不是最优的。需要更深入地分析问题的结构,寻找更有效的贪心策略。例如在找零问题中,如果硬币的面值不是常规的(如1元、5角、1角),而是一些特殊的值,初始的每次选择最大面值硬币的策略可能不适用。此时,可能需要重新分析不同面值硬币之间的关系,设计新的贪心策略。比如有面值为3元、5元、7元的硬币,找零11元时,直接选择最大面值7元硬币不是最优解(会剩下4元,需要3个1元硬币,共4个硬币),而先选择5元硬币(剩下6元,再选择3元硬币,共2个硬币)才是最优解。
-
-
结合其他算法思想
-
可以结合其他算法思想来优化贪心算法。例如结合动态规划的思想,在贪心算法执行过程中,记录一些中间状态信息,避免重复计算。在某些图论问题中,如求单源最短路径的Dijkstra算法(一种贪心算法),可以结合堆数据结构(类似优先队列的思想)来优化算法的时间复杂度。堆可以快速找到当前未处理节点中的最短距离节点,从而提高算法效率。
-
(二)数据结构优化
-
选择合适的数据结构存储数据
-
根据问题的特点选择合适的数据结构。在活动安排问题中,使用结构体数组来存储活动的开始时间和结束时间是比较合适的,这样方便进行排序和遍历操作。如果问题涉及到频繁的插入和删除操作,并且需要保持元素的顺序,可能链表这种数据结构会更合适。在处理图相关的贪心算法问题时,邻接矩阵或邻接表等数据结构可以用来存储图的信息,不同的选择会对算法的时间和空间复杂度产生影响。
-
-
利用C++标准库的数据结构和算法
-
C++标准库提供了丰富的数据结构和算法,如
vector、list、map、set等容器以及各种算法函数(如排序、查找等)。合理利用这些可以提高代码的效率和可读性。例如在处理硬币找零问题时,可以使用vector来存储硬币面值,使用sort函数对其进行排序。在处理一些需要查找特定元素或者统计元素个数的问题时,map和set可能会非常有用。
-
(三)减少不必要的计算
-
避免重复计算
-
在贪心算法执行过程中,可能会有一些计算是重复的。例如在计算某个问题的局部最优解时,如果多次用到某个子问题的结果,就可以考虑将这个结果缓存起来,避免重复计算。在一些递归形式的贪心算法实现中,这种情况比较常见。比如计算斐波那契数列的一种贪心策略(每次选择当前最小的两个数相加得到下一个数),如果不进行优化,计算过程中会有大量的重复计算,可以使用一个数组来缓存已经计算过的结果,从而提高算法效率。
-
-
尽早排除不可能的选择
-
在每一步贪心选择时,如果能够尽早判断出某些选择是不可能达到最优解的,就可以提前排除这些选择,减少计算量。例如在活动安排问题中,在遍历活动时,如果某个活动的开始时间已经大于当前所能安排的最晚结束时间,就可以直接跳过这个活动,不需要再进一步判断它是否与后续活动兼容。
-
五、贪心算法C++常见错误与解决
(一)错误:贪心策略选择错误
-
问题表现
-
最常见的错误就是选择了错误的贪心策略。例如在上述特殊硬币面值(3元、5元、7元)的找零问题中,如果仍然按照常规的选择最大面值硬币的贪心策略,就不能得到最优解。在活动安排问题中,如果按照活动的开始时间而不是结束时间进行排序和选择活动,可能会导致选择的活动数量不是最多的。
-
-
解决方法
-
重新分析问题的结构和目标。仔细研究问题的约束条件和最优解的要求,尝试从不同的角度思考贪心策略。可以通过列举一些简单的实例,手动计算出正确的最优解,然后分析这个过程中应该遵循的贪心原则。例如在找零问题中,对于特殊的硬币面值组合,可以通过列举不同金额的找零情况,找到更合适的贪心策略,如先选择尽可能接近找零金额的硬币面值。
-
(二)错误:未考虑所有情况
-
问题表现
-
在设计贪心算法时,可能只考虑了部分情况而忽略了其他情况。例如在一个任务调度问题中,每个任务有不同的优先级、执行时间和依赖关系。如果只考虑任务的优先级来安排任务执行顺序(贪心策略),可能会忽略任务之间的依赖关系,导致某些任务无法执行或者整体执行时间延长。
-
-
解决方法
-
全面分析问题,列出所有可能影响结果的因素。在上述任务调度问题中,除了优先级,还要考虑任务的依赖关系和执行时间。可以构建一个更复杂的模型,例如使用有向图来表示任务之间的依赖关系,然后综合考虑各种因素来设计贪心策略。或者将问题分解为多个子问题,分别考虑每个子问题中的各种情况,再将子问题的解组合起来得到整体的解。
-
(三)错误:数据结构使用不当
-
问题表现
-
选择的数据结构可能不适合问题的操作要求。例如在一个需要频繁查找元素是否存在的数据处理问题中,如果使用
vector进行线性查找,当数据量较大时效率会非常低。或者在一个需要动态调整元素顺序的数据问题中,如果使用数组来存储数据,操作起来会很麻烦并且容易出错。
-
-
解决方法
-
根据问题的操作特点重新选择合适的数据结构。对于需要频繁查找元素的问题,可以使用
set或者map等数据结构,它们提供了高效的查找操作。对于需要动态调整元素顺序的问题,可以考虑使用list等数据结构。同时,要注意数据结构的初始化和维护,确保数据的正确性和完整性。
-
贪心算法注意事项
什么是贪心算法
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。它通常用于解决那些具有最优子结构性质的问题。
贪心算法的基本步骤
-
选择:从当前状态中选择一个最优的选项。
-
验证:验证这个选择是否满足问题的约束条件。
-
更新:根据这个选择更新问题的状态,并进入下一步。
贪心算法的注意事项
-
局部最优不一定导致全局最优:贪心算法的关键在于每一步的选择是否能保证最终结果是最优的。如果局部最优选择不能保证全局最优,那么贪心算法可能无法得到正确的解。
-
示例:在某些情况下,贪心算法可能会陷入局部最优解,而无法达到全局最优解。例如,在某些图论问题中,贪心算法可能无法找到最短路径。
-
-
问题的性质:贪心算法适用于具有最优子结构性质的问题。如果问题不具备这种性质,贪心算法可能不适用。
-
示例:背包问题(0/1背包问题)通常不适合用贪心算法解决,因为它不具备最优子结构性质。
-
-
选择策略:选择策略是贪心算法的核心。不同的选择策略可能导致不同的结果。
-
示例:在活动选择问题中,可以选择按结束时间排序或按开始时间排序,不同的排序策略可能导致不同的结果。
-
-
边界条件:在实现贪心算法时,需要注意边界条件和特殊情况的处理。
-
示例:在处理空输入或只有一个元素的输入时,贪心算法需要特别处理,以避免出现错误。
-
-
时间复杂度:贪心算法通常具有较低的时间复杂度,但需要确保选择策略的实现不会引入额外的时间开销。
-
示例:在选择排序策略时,如果排序的时间复杂度较高,可能会影响整体算法的效率。
-
总结
贪心算法是一种简单且高效的算法,适用于解决具有最优子结构性质的问题。然而,使用贪心算法时需要注意局部最优不一定导致全局最优、问题的性质、选择策略、边界条件和时间复杂度等问题。只有在充分理解问题并验证贪心策略的有效性后,才能确保贪心算法能够得到正确的解。
相关文章:

贪心算法c++
贪心算法C概述 一、贪心算法的基本概念 贪心算法(Greedy Algorithm),又名贪婪法,是一种解决优化问题的常用算法。其基本思想是在问题的每个决策阶段,都选择当前看起来最优的选择,即贪心地做出局部最优的决…...

【STM32】 TCP/IP通信协议(3)--LwIP网络接口
LwIP协议栈支持多种不同的网络接口(网卡),由于网卡是直接跟硬件平台打交道,硬件不同则处理也是不同。那Iwip如何兼容这些不同的网卡呢? LwIP提供统一的接口,底层函数需要用户自行完成,例如网卡的…...

15分钟学 Python 第39天:Python 爬虫入门(五)
Day 39:Python 爬虫入门数据存储概述 在进行网页爬虫时,抓取到的数据需要存储以供后续分析和使用。常见的存储方式包括但不限于: 文件存储(如文本文件、CSV、JSON)数据库存储(如SQLite、MySQL、MongoDB&a…...

使用Pytorch构建自定义层并在模型中使用
使用Pytorch构建自定义层并在模型中使用 继承自nn.Module类,自定义名称为NoisyLinear的线性层,并在新模型定义过程中使用该自定义层。完整代码可以在jupyter nbviewer中在线访问。 import torch import torch.nn as nn from torch.utils.data import T…...
:从前序与中序遍历序列构造二叉树)
学习记录:js算法(五十六):从前序与中序遍历序列构造二叉树
文章目录 从前序与中序遍历序列构造二叉树我的思路网上思路 总结 从前序与中序遍历序列构造二叉树 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示…...

qt使用QDomDocument读写xml文件
在使用QDomDocument读写xml之前需要在工程文件添加: QT xml 1.生成xml文件 void createXml(QString xmlName) {QFile file(xmlName);if (!file.open(QIODevice::WriteOnly | QIODevice::Truncate |QIODevice::Text))return false;QDomDocument doc;QDomProcessin…...

Oracle架构之表空间详解
文章目录 1 表空间介绍1.1 简介1.2 表空间分类1.2.1 SYSTEM 表空间1.2.2 SYSAUX 表空间1.2.3 UNDO 表空间1.2.4 USERS 表空间 1.3 表空间字典与本地管理1.3.1 字典管理表空间(Dictionary Management Tablespace,DMT)1.3.2 本地管理方式的表空…...

springboot整合seata
一、准备 docker部署seata-server 1.5.2参考:docker安装各个组件的命令 二、springboot集成seata 2.1 引入依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId>&…...
【二次向用户申请授权】程序访问控制)
鸿蒙开发(NEXT/API 12)【二次向用户申请授权】程序访问控制
当应用通过[requestPermissionsFromUser()]拉起弹框[请求用户授权]时,用户拒绝授权。应用将无法再次通过requestPermissionsFromUser拉起弹框,需要用户在系统应用“设置”的界面中,手动授予权限。 在“设置”应用中的路径: 路径…...

docker export/import 和 docker save/load 的区别
Docker export/import 和 docker save/load 都是用于容器和镜像的备份和迁移,但它们有一些关键的区别: docker export/import: export 作用于容器,import 创建镜像导出的是容器的文件系统,不包含镜像的元数据丢失了镜像的层级结构…...

明星周边销售网站开发:SpringBoot技术全解析
1系统概述 1.1 研究背景 如今互联网高速发展,网络遍布全球,通过互联网发布的消息能快而方便的传播到世界每个角落,并且互联网上能传播的信息也很广,比如文字、图片、声音、视频等。从而,这种种好处使得互联网成了信息传…...

STM32+ADC+扫描模式
1 ADC简介 1 ADC(模拟到数字量的桥梁) 2 DAC(数字量到模拟的桥梁),例如:PWM(只有完全导通和断开的状态,无功率损耗的状态) DAC主要用于波形生成(信号发生器和音频解码器) 3 模拟看门狗自动监…...

R语言绘制散点图
散点图是一种在直角坐标系中用数据点直观呈现两个变量之间关系、可检测异常值并探索数据分布的可视化图表。它是一种常用的数据可视化工具,我们通过不同的参数调整和包的使用,可以创建出满足各种需求的散点图。 常用绘制散点图的函数有plot()函数和ggpl…...

安装最新 MySQL 8.0 数据库(教学用)
安装 MySQL 8.0 数据库(教学用) 文章目录 安装 MySQL 8.0 数据库(教学用)前言MySQL历史一、第一步二、下载三、安装四、使用五、语法总结 前言 根据 DB-Engines 网站的数据库流行度排名(2024年)࿰…...
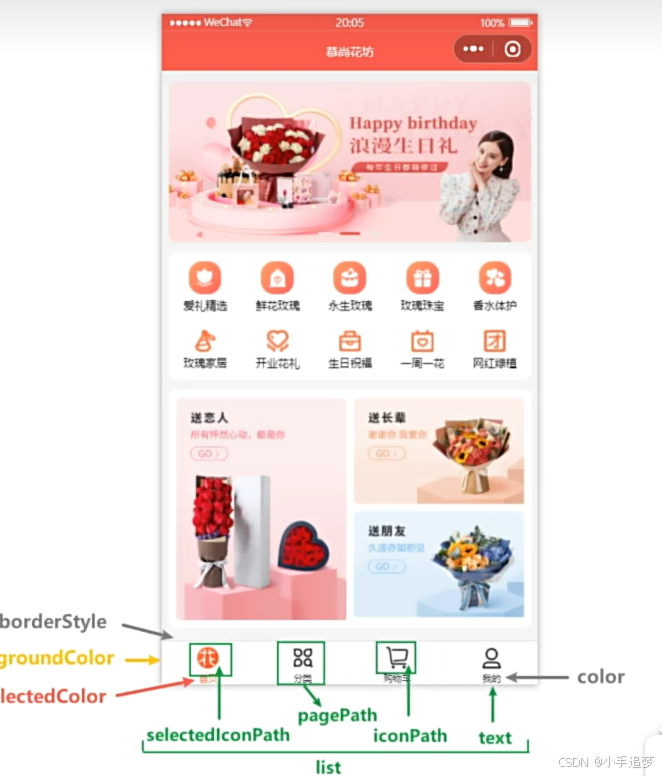
微信小程序开发-配置文件详解
文章目录 一,小程序创建的配置文件介绍二,配置文件-全局配置-pages 配置作用:注意事项:示例: 三,配置文件-全局配置-window 配置示例: 四,配置文件-全局配置-tabbar 配置核心作用&am…...

TCP/UDP初识
TCP是面向连接的、可靠的、基于字节流的传输层协议。 面向连接:一定是一对一连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端…...

【大数据】在线分析、近线分析与离线分析
文章目录 1. 在线分析(Online Analytics)定义特点应用场景技术栈 2. 近线分析(Nearline Analytics)定义特点应用场景技术栈 3. 离线分析(Offline Analytics)定义特点应用场景技术栈 总结 在线分析ÿ…...

【unity进阶知识9】序列化字典,场景,vector,color,Quaternion
文章目录 前言一、可序列化字典类普通字典简单的使用可序列化字典简单的使用 二、序列化场景三、序列化vector四、序列化color五、序列化旋转Quaternion完结 前言 自定义序列化的主要原因: 可读性:使数据结构更清晰,便于理解和维护。优化 I…...

传奇GOM引擎架设好进游戏后提示请关闭非法外挂,重新登录,如何处理?
今天在架设一个GOM引擎的版本时,进游戏之后刚开始是弹出一个对话框,提示请关闭非法外挂,重新登录,我用的是绿盟登陆器,同时用的也是绿盟插件,刚开始我以为是绿盟登录器的问题,于是就换成原版gom…...
视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用)
OpenCV视频I/O(15)视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将 4 个字符拼接成一个 FourCC 代码。 在 OpenCV 中,fourcc() 函数用于生成 FourCC 代码,这是一种用于标识视频编解码器的…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...
Adafruit Feather RP2040 SCORPIO:专为大规模NeoPixel灯光控制而生的开发板
1. 项目概述:为什么你需要一块专为大规模灯光控制而生的开发板?如果你曾经尝试过用一块普通的微控制器驱动超过几百个NeoPixel(或WS2812)LED,你很可能已经撞上了性能的天花板。CPU被时序生成任务完全占用,动…...