20241008深度学习动手篇
文章目录
- 1.如何写一个神经网络进行训练?
- 1.1创建一个子类,搭建你需要的神经网络结构
- 1.2 加载数据集
- 1.3 自定义一些指标评估函数
- 1.4训练
- 1.5 结果展示
- 2.参考文献

1.如何写一个神经网络进行训练?
1.1创建一个子类,搭建你需要的神经网络结构
# @File: 241008LeNet.py
# @Author: chen_song
# @Time: 2024/10/8 上午8:31import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# 进行卷积操作以后,nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),nn.AvgPool2d(2,stride=2),nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(2,stride=2),nn.Flatten(),nn.Linear(16*5*5,120),nn.Sigmoid(),nn.Linear(120,84),nn.Sigmoid(),nn.Linear(84,10)
)
print(net)
print("===============================")
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
Y = X.copy_(X)
for layer in net:X = layer(X)print(layer.__class__.__name__,X.shape)print("============================")
# 输入给定以后,会进行一系列张量乘法计算
A = net(Y)
# print the last result
print(A)
result below:
Sequential( (0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1),
padding=(2, 2)) (1): Sigmoid() (2): AvgPool2d(kernel_size=2,
stride=2, padding=0) (3): Conv2d(6, 16, kernel_size=(5, 5),
stride=(1, 1)) (4): Sigmoid() (5): AvgPool2d(kernel_size=2,
stride=2, padding=0) (6): Flatten(start_dim=1, end_dim=-1) (7):
Linear(in_features=400, out_features=120, bias=True) (8): Sigmoid()
(9): Linear(in_features=120, out_features=84, bias=True) (10):
Sigmoid() (11): Linear(in_features=84, out_features=10, bias=True) )
=============================== Conv2d torch.Size([1, 6, 28, 28]) Sigmoid torch.Size([1, 6, 28, 28]) AvgPool2d torch.Size([1, 6, 14,
14]) Conv2d torch.Size([1, 16, 10, 10]) Sigmoid torch.Size([1, 16, 10,
10]) AvgPool2d torch.Size([1, 16, 5, 5]) Flatten torch.Size([1, 400])
Linear torch.Size([1, 120]) Sigmoid torch.Size([1, 120]) Linear
torch.Size([1, 84]) Sigmoid torch.Size([1, 84]) Linear torch.Size([1,
10])
============================ tensor([[-0.2278, -0.5057, -0.6303, 0.1526, -0.1510, -0.1933, -0.3120, -0.7823,
0.4070, -0.0717]], grad_fn=)
1.2 加载数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
打断点调试:


你会发现:
train_iter和test_iter都是一个torch.utils.dataLoader对象,里面包含几个成员变量,住关键的是dataset对象以及sample对象,仔细研究你就会发现,为啥需要数据加载器了,因为你用神经网络进行训练,数据格式总得对吧,再就是要给个label吧,也就是目标值target吧,所以有余力朋友可以自己设计一个数据加载器…
1.3 自定义一些指标评估函数
def evaluate_accuracy_gpu(net, data_iter, device=None): # @save"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需的(之后将介绍)=== 自然语言处理X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]
注意一下里面net.eval()和net.train()
1.4训练
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
1.5 结果展示

2.参考文献
[1]王辉,张帆,刘晓凤,等.基于DarkNet-53和YOLOv3的水果图像识别[J].东北师大学报(自然科学版),2020,52(04):60-65.DOI:10.16163/j.cnki.22-1123/n.2020.04.010.
[2]王治国,曹爽,管海燕,等.基于改进SSD的城市地下排水管道缺陷识别算法[J].测绘工程,2024,33(05):7-13.DOI:10.19349/j.cnki.issn1006-7949.2024.05.002.
[3]杨继雯.基于深度学习的监控视频中人员异常行为识别技术[D].西安工业大学,2024.DOI:10.27391/d.cnki.gxagu.2024.000829.
相关文章:
20241008深度学习动手篇
文章目录 1.如何写一个神经网络进行训练?1.1创建一个子类,搭建你需要的神经网络结构1.2 加载数据集1.3 自定义一些指标评估函数1.4训练1.5 结果展示 2.参考文献 1.如何写一个神经网络进行训练? 1.1创建一个子类,搭建你需要的神经网络结构 # File: 241008LeNet.py # Author:…...

对序列化反序列化在项目中的使用优化
文章目录 序列化是什么?常见的序列化协议使用序列化反序列化序列化List反序列化List 查看源码,分析不足进行改善 序列化是什么? 如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,…...

查看 git log的过程中看到 :说明日志输出可能超出屏幕大小,系统进入了分页模式
在命令行提示符中,通常 : 表示系统等待进一步的输入。如果你在查看 git log 的过程中看到 :,说明日志输出可能超出屏幕大小,系统进入了分页模式,默认使用 less 命令查看内容。 此时你可以: 按 q 退出日志查看。按 En…...

Linux--信号量详解
目录 一、信号量 1、信号量相关函数 2、多线程环形队列生产消费模型 3、实现代码 信号量是将整体的资源分割成多份使用 信号量本质是对资源的预定机制 一、信号量 1、信号量相关函数 创建信号量: sem_init: int sem_init(sem_t *sem, int pshared, unsigned int value); …...

【重学 MySQL】五十一、更新和删除数据
【重学 MySQL】五十一、更新和删除数据 更新数据删除数据注意事项 在MySQL中,更新和删除数据是数据库管理的基本操作。 更新数据 为了更新(修改)表中的数据,可使用UPDATE语句。UPDATE语句的基本语法如下: UPDATE ta…...

Web3与人工智能的交叉应用探索
随着数字技术的发展,Web3与人工智能(AI)之间的结合正逐渐成为一个重要的研究领域。Web3技术旨在实现更加去中心化和透明的互联网,而人工智能则在数据分析、自动化决策和增强人类能力方面展示了巨大的潜力。 1. 去中心化数据管理与…...

【springboot9736】基于springboot+vue的逍遥大药房管理系统
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 项目描述 伴随着全球信息化发展,行行业业都与计算机技…...

四.网络层(上)
目录 4.1网络层功能概述 4.2 SDN基本概念 4.3 路由算法与路由协议 4.3.1什么是路由协议? 4.3.2什么是路由算法? 4.3.3路由算法分类 (1)静态路由算法 (2)动态路由算法 ①全局性 OSPF协议与链路状态算法 ②分散性 RIP协议与距离向量算法 4.3.…...

Leecode热题100-56.合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:intervals [[1,3…...

安全帽未佩戴预警系统 劳保防护用品穿戴监测系统 YOLO
在建筑、矿山、电力等高危行业中,工人面临着各种潜在的危险,如高空坠物、物体打击等。安全帽能够有效地分散和吸收冲击力,大大降低头部受伤的严重程度。一旦工人未正确佩戴安全帽,在遭遇危险时,头部将直接暴露在危险之…...

【python机器学习】线性回归 拟合 欠拟合与过拟合 以及波士顿房价预估案例
文章目录 线性回归之波士顿房价预测案例 欠拟合与过拟合线性回归API 介绍:波士顿房价预测数据属性:机器学习代码实现 拟合 过拟合 欠拟合 模拟 及处理方法(正则化处理)导包定义函数表示欠拟合定义函数表示拟合定义函数表示过拟合 正则化处理过拟合L1正则化L2正则化 线性回归之波…...

IT招聘乱象的全面分析
近年来,IT行业的招聘要求似乎越来越苛刻,甚至有些不切实际。许多企业在招聘时,不仅要求前端工程师具备UI设计能力,还希望后端工程师精通K8S服务器运维,更有甚至希望研发经理掌握所有前后端框架和最新开发技术。这种招聘…...

一入递归深似海,算法之美无止境
最近在刷leetcode hot100,在写二叉树中最大路径和的时候,看到了一个佬对递归的理解,深受启发,感觉自己对于递归的题又行了!!! 这里给大家分享一下(建立大家先去尝试一下这道题再来看 124. 二叉树中的最大路径和 二叉树中的 路径 被定义为一条节点序列,序列中每…...

进程的状态的理解(概念+Linux)
文章目录 进程的状态并行和并发物理和逻辑 时间片进程具有独立性等待的本质运行阻塞标记挂起等待 Linux下的进程状态(一)运行状态(R - running)(二)睡眠状态(S - sleeping)ÿ…...

Apache Linkis + OceanBase:如何提升数据分析效率
计算中间件 Apache Linkis 构建了一个计算中间件层,以实现上层应用程序和底层数据引擎之间的连接、治理和编排。目前,已经支持通过数据源的功能,实现用户通过Linkis 对接并使用 OceanBase数据库。 本文详细阐述了在 Apache Linkis v1.3.2中&a…...
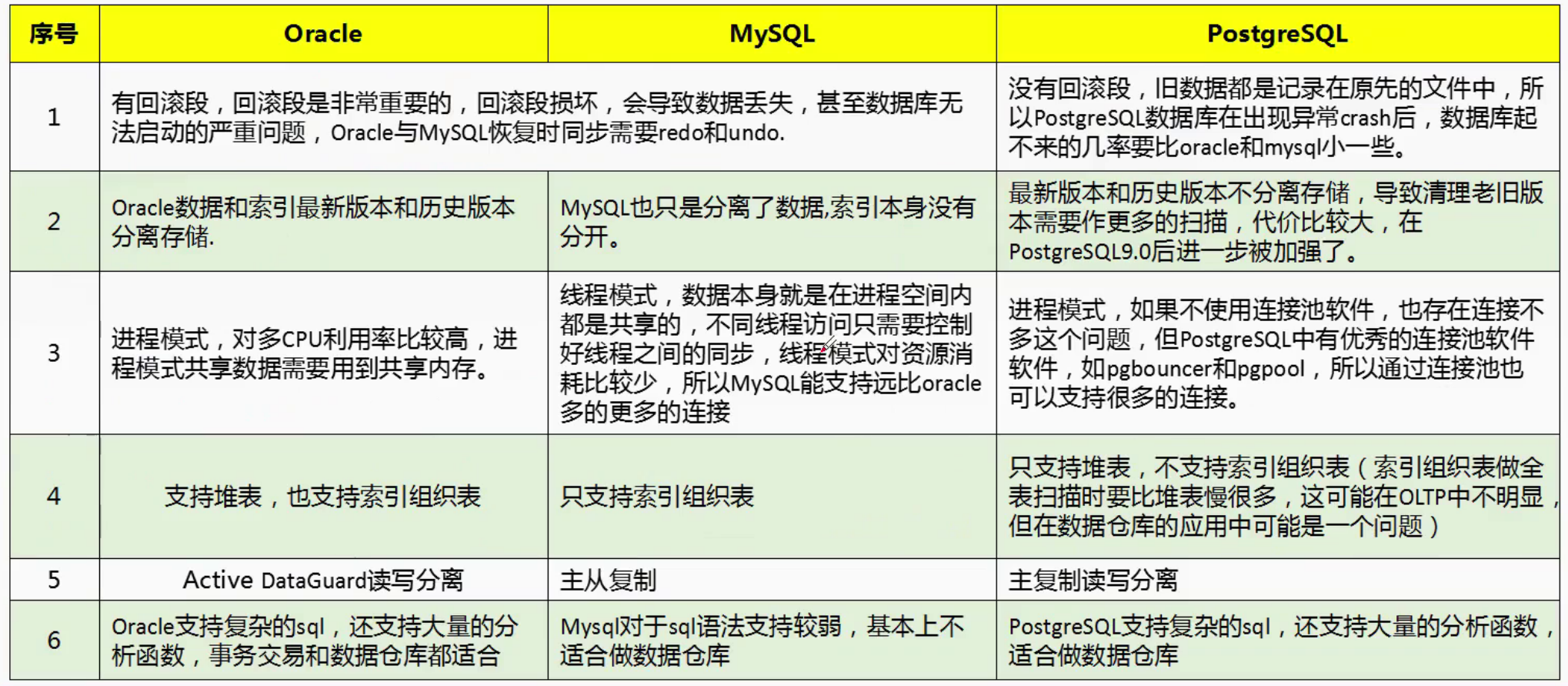
Day01-postgresql数据库基础入门培训
Day01-postgresql数据库基础入门培训 1、PostgresQL数据库简介2、PostgreSQL行业生态应用3、PostgreSQL版本发展与特性4、PostgreSQL体系结构介绍5、PostgreSQL与MySQL的区别6、PostgreSQL与Oracle、MySQL的对比 1、PostgresQL数据库简介 PostgreSQL【简称:PG】是加…...

打卡第四天 P1081 [NOIP2012 提高组] 开车旅行
今天是我打卡第四天,做个省选/NOI−题吧(#^.^#) 原题链接:[NOIP2012 提高组] 开车旅行 - 洛谷 题目描述 输入格式 输出格式 输入输出样例 输入 #1 4 2 3 1 4 3 4 1 3 2 3 3 3 4 3 输出 #1 1 1 1 2 0 0 0 0 0 输入 #2 10 4 5 6 1 …...

Jenkins Pipline流水线
提到 CI 工具,首先想到的就是“CI 界”的大佬--]enkjns,虽然在云原生爆发的年代,蹦出来了很多云原生的 CI 工具,但是都不足以撼动 Jenkins 的地位。在企业中对于持续集成、持续部署的需求非常多,并且也会经常有-些比较复杂的需求,此时新生的 CI 工具不足以支撑这些很…...

鸿蒙harmonyos next flutter混合开发之开发FFI plugin
创建FFI plugin summation,默认创建的FFI plugin是求两个数的和 flutter create --templateplugin_ffi summation --platformsandroid,ios,ohos 创建my_application flutter create --org com.example my_application 在my_application项目中文件pubspec.yaml引…...

oracle数据库安装和配置
Oracle数据库安装 一、安装前的准备 系统要求: 硬件:内存至少1GB(推荐2GB以上),硬盘至少10GB的可用空间,CPU至少2核心。 操作系统:支持Oracle版本的Windows(如Windows 10或更高版本…...

别再只调图表了!用Vue+Echarts做大屏,这5个布局与性能优化技巧才是关键
VueEcharts大屏实战:从布局到性能优化的进阶指南 当数据可视化大屏成为企业展示核心指标的标准配置,开发者们逐渐从"能实现功能"转向追求"极致体验"。本文将分享五个鲜少被系统总结的实战技巧,这些经验来自多个千万级PV项…...
)
别再只用MSE了!PyTorch中SmoothL1Loss的保姆级使用指南(附代码对比)
深度学习回归任务中SmoothL1Loss的实战应用与MSE对比解析 在目标检测、房价预测等回归任务中,选择合适的损失函数往往决定了模型的收敛速度和最终性能。许多初学者会习惯性选择最熟悉的均方误差(MSE)损失函数,但当数据中存在离群点时,MSE的二…...
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作烦恼吗&am…...
)
CodeWave项目导出实战:从云端到本地的完整避坑指南(含数据库配置与端口冲突解决)
CodeWave项目导出实战:从云端到本地的完整避坑指南(含数据库配置与端口冲突解决) 当开发者完成CodeWave平台上的应用构建后,如何将项目顺利迁移至本地环境往往成为新的挑战。不同于云端的一键部署,本地化过程涉及环境差…...

AnyVisLoc:专为低空多视角无人机定位打造的全球首个统一评测基准
一、论文背景与开创性意义 AnyVisLoc 是专为低空多视角条件下的无人机绝对视觉定位(Absolute Visual Localization,简称 AVL)设计的全球首个统一评测基准与大尺度数据集,论文题为 《Exploring the best way for UAV visual local…...

GAMES101图形学笔记:从光栅化到路径追踪,我的自学避坑路线图
GAMES101图形学自学指南:从光栅化到路径追踪的实战路线 在B站上拥有数百万播放量的GAMES101课程,已经成为计算机图形学爱好者入门的黄金标准。作为一门融合数学、物理和编程的交叉学科,图形学的学习曲线往往令人望而生畏。本文将分享我自学G…...

Perplexity症状查询功能突然失效?排查清单来了:从OpenID Connect令牌过期、UMLS MetaMap服务中断到本地缓存污染的6层故障树分析
更多请点击: https://codechina.net 第一章:Perplexity症状查询功能突然失效?排查清单来了:从OpenID Connect令牌过期、UMLS MetaMap服务中断到本地缓存污染的6层故障树分析 当Perplexity的症状查询接口返回 401 Unauthorized 或…...

【Web安全】JWT常见安全漏洞总结
文章目录前言1. JWT基础与漏洞概述2. JWT核心漏洞解析2.1 未校验签名2.1.1 漏洞原理2.1.2 利用方式2.1.3 实战脚本2.2 算法篡改漏洞2.2.1 漏洞原理2.2.2 核心说明2.2.3 攻击流程2.3 弱密钥漏洞2.3.1 漏洞原理2.3.2 利用方式2.4 垂直越权2.4.1 漏洞原理2.4.2 利用流程2.5 KID字段…...

Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30%
Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30% 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...
)
Perplexity课程查询功能全链路拆解(从API底层到UI交互逻辑)
更多请点击: https://kaifayun.com 第一章:Perplexity课程查询功能全链路概览 Perplexity 的课程查询功能并非单一接口调用,而是一套覆盖用户意图理解、多源数据协同检索、结构化结果生成与实时反馈优化的端到端系统。其核心目标是将自然语言…...