【图论】(一)图论理论基础与岛屿问题
图论理论基础与岛屿问题
- 图论理论基础
- 深度搜索(dfs)
- 广度搜索(bfs)
- 岛屿问题概述
- 岛屿数量
- 岛屿数量-深搜版
- 岛屿数量-广搜版
- 岛屿的最大面积
- 孤岛的总面积
- 沉没孤岛
- 建造最大人工岛
- 水流问题
- 岛屿的周长
图论理论基础
这里仅对图论相关核心概念做整理总结归纳,具体详细相关概念请参考代码随想录上的整理总结:
- 图论理论基础
- 深度优先搜索理论基础
- 所有可达路径-dfs实战
- 广度优先搜索理论基础
图的遍历方式基本是两大类:
- 深度优先搜索(dfs)
- 广度优先搜索(bfs)
dfs和bfs的区别:
- dfs是沿一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯),二叉树的前中后序遍历、以及回溯算法就是dfs过程。
- bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程,二叉树的层序遍历就是bfs的过程。
深度搜索(dfs)
dfs搜索过程是沿着一个方向搜,不到黄河不回头,举个例子,如图是一个无向图,我们要搜索从节点1到节点6的所有路径,那么dfs搜索的第一条路径是这样的(假设第一次延默认方向,就找到了节点6):

此时我们找到了节点6,(遇到黄河了,是不是应该回头了),那么应该再去搜索其他方向了,如下图:

路径2撤销了,改变了方向,走路径3(红色线), 接着也找到终点6。 那么撤销路径2,改为路径3,在dfs中其实就是回溯的过程(这一点很重要)
又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,下图图四中,路径4撤销(回溯),改为路径5:

又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,如下图,路径6撤销(回溯的过程),改为路径7,路径8 和 路径7,路径9, 结果发现死路一条,都走到了自己走过的节点:

那么节点2所连接路径和节点3所链接的路径 都走过了,撤销路径只能向上回退,去选择撤销当初节点4的选择,也就是撤销路径5,改为路径10 。 如下图:

上图演示中,其实并没有把 所有的 从节点1 到节点6的dfs(深度优先搜索)的过程都画出来,那样太冗余了,但 已经把dfs 关键的地方都涉及到了,关键就两点:
- 搜索方向,是认准一个方向搜,直到碰壁之后再换方向
- 换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。
代码框架:
vector<vector<int>> result; // 保存符合条件的所有路径
vector<int> path; // 起点到终点的路径
void dfs(图,目前搜索的节点)
{if (终止条件) {存放结果;return;}for (选择:本节点所连接的其他节点) {处理节点;dfs(图,选择的节点); // 递归回溯,撤销处理结果}
}
其实很多dfs写法,没有写终止条件,其实终止条件写在了, 下面dfs递归的逻辑里了,也就是不符合条件,直接不会向下递归
到这里,对回溯算法会有更深刻的理解,路径2 已经走到了 目的地节点6,那么 路径2 是如何撤销,然后改为 路径3呢? 其实这就是 回溯的过程,撤销路径2,走换下一个方向

广度搜索(bfs)
- 广搜的搜索方式就适合于解决两个点之间的最短路径问题。
- 因为广搜是从起点出发,以起始点为中心一圈一圈进行搜索,一旦遇到终点,记录之前走过的节点就是一条最短路。
- 当然,也有一些问题是广搜 和 深搜都可以解决的,例如岛屿问题,这类问题的特征就是不涉及具体的遍历方式,只要能把相邻且相同属性的节点标记上就行。
广搜的过程:
BFS是一圈一圈的搜索过程,我们用一个方格地图,假如每次搜索的方向为 上下左右(不包含斜上方),那么给出一个start起始位置,那么BFS就是从四个方向走出第一步

如果加上一个end终止位置,那么使用BFS的搜索过程如图所示:

正是因为BFS一圈一圈的遍历方式,所以一旦遇到终止点,那么一定是一条最短路径。
而且地图还可以有障碍,如图所示:

代码框架:
- 其实,我们仅仅需要一个容器,能保存我们要遍历过的元素就可以,那么用队列,还是用栈,甚至用数组,都是可以的。
- 用队列的话,就是保证每一圈都是一个方向去转,例如统一顺时针或者逆时针。
- 因为队列是先进先出,加入元素和弹出元素的顺序是没有改变的。
- 如果用栈的话,就是第一圈顺时针遍历,第二圈逆时针遍历,第三圈有顺时针遍历。
- 由于各种教程习惯用队列较多,这里我也使用队列来实现,只是记录并不是非要用队列,用栈也可以。
广搜代码模板,该模板针对的就是,上面的四方格的地图:
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y)
{queue<pair<int, int>> que; // 定义队列que.push({x, y}); // 起始节点加入队列visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点// 开始遍历队列里的元素while(!que.empty()) { pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素int curx = cur.first;int cury = cur.second; // 当前节点坐标// 开始想当前节点的四个方向左右上下去遍历for (int i = 0; i < 4; i++) { // 获取周边四个方向的坐标int nextx = curx + dir[i][0];int nexty = cury + dir[i][1]; // 坐标越界了,直接跳过if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 如果节点没被访问过if (!visited[nextx][nexty]) { que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问}}}
}
务必理解上述代码,在下述的岛屿问题,解决相邻的问题上也将用到相似的思路与代码。
岛屿问题概述
在图论中,有一类基础问题即是岛屿问题,其中有关岛屿问题的通识描述如下:
- 给定一个由 1(陆地) 和 0(水) 组成的矩阵,岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域,你可以假设矩阵外均被水包围。
- 孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。
输入描述:
- 第一行包含两个整数 N, M,表示矩阵的行数和列数。
- 后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输入示例:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1

岛屿数量
卡码网题目链接(ACM模式)
岛屿数量-深搜版
- 遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
- 在遇到标记过的陆地节点和海洋节点的时候直接跳过, 这样计数器就是最终岛屿的数量。
程序实现:版本一
#include <iostream>
#include <vector>using namespace std;//四个方向
int dir[4][2] = {0,1,1,0,-1,0,0,-1};
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y)
{// 开始想当前节点的四个方向左右上下去遍历for(int i = 0; i < 4; i++){// 四周的下个节点int nextx = x + dir[i][0];int nexty = y + dir[i][1];// 坐标越界了,直接跳过if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;// 没有访问过的 同时 是陆地的if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){// 标记访问过visited[nextx][nexty] = true;// 深度搜索该陆地四周相邻的陆地dfs(grid, visited, nextx, nexty);}}
}int main()
{int n,m;cin >> n >> m;//输入陆地海洋数据vector<vector<int>> grid(n,vector<int>(m,0));for(int i = 0; i < n; i++){for(int j = 0; j < m;j++)cin >> grid[i][j];}// 标记该节点是否被访问过vector<vector<bool>> visited(n,vector<bool>(m,false));int result = 0; // 记录岛屿数量for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(!visited[i][j] && grid[i][j] == 1){visited[i][j] = true; // 标记该节点已被访问result++; // 遇到没访问过的陆地,+1dfs(grid,visited,i,j); // 将与其连接的陆地都标记上 true}}}cout << result << endl;return 0;
}
- 为什么 以上代码中的dfs函数,没有终止条件呢?
- 其实终止条件 就写在了 调用dfs的地方,如果遇到不合法的方向,直接不会去调用dfs。
当然也可以这么写:版本二
// 版本二
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y)
{// 终止条件:访问过的节点 或者 遇到海水if (visited[x][y] || grid[x][y] == 0) return; visited[x][y] = true; // 标记访问过for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过//不做判断 直接递归dfs(grid, visited, nextx, nexty);}
}int main()
{int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++){for (int j = 0; j < m; j++){cin >> grid[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));int result = 0;for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (!visited[i][j] && grid[i][j] == 1) {// 遇到没访问过的陆地,+1result++; // 不先标记 直接递归dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true}}}cout << result << endl;
}
- 版本一的写法是 : 下一个节点是否能合法已经判断完了,传进dfs函数的就是合法节点。
- 版本二的写法是: 不管节点是否合法,上来就dfs,然后在终止条件的地方进行判断,不合法再 return。
- 理论上来讲,版本一的效率更高一些,因为避免了 没有意义的递归调用,在调用dfs之前,就做合法性判断。 就个人而言,版本一比版本二逻辑更清晰,更易于个人理解,因此后续都使用版本一的写法。
- 其实本题是 dfs,bfs 模板题,所以需要注重更多的细节问题,更有利于后面对程序的修改与扩展。
岛屿数量-广搜版
-
当然本题也是 bfs的一个模板题,也可以使用bfs来解决,即先搜索一个节点周围与其相邻的所有陆地
-
这里有一个广搜中的重要细节:只要加入队列就代表走过,就需要标记,而不是从队列拿出来的时候再去标记走过。
-
如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。

超时写法 (从队列中取出节点再标记,注意代码注释的地方)
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {queue<pair<int, int>> que;que.push({x, y});while(!que.empty()) {pair<int ,int> cur = que.front(); que.pop();int curx = cur.first;int cury = cur.second;visited[curx][cury] = true; // 从队列中取出在标记走过for (int i = 0; i < 4; i++) {int nextx = curx + dir[i][0];int nexty = cury + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {que.push({nextx, nexty});}}}
}
加入队列 就代表走过,立刻标记,正确写法: (注意代码注释的地方)
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {queue<pair<int, int>> que;que.push({x, y});// 只要加入队列,立刻标记visited[x][y] = true; while(!que.empty()) {pair<int ,int> cur = que.front(); que.pop();int curx = cur.first;int cury = cur.second;for (int i = 0; i < 4; i++) {int nextx = curx + dir[i][0];int nexty = cury + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {que.push({nextx, nexty});// 只要加入队列立刻标记visited[nextx][nexty] = true; }}}
}
以上两个版本其实,其实只有细微区别,就是 visited[x][y] = true; 放在的地方,这取决于我们对 代码中队列的定义,队列中的节点就表示已经走过的节点。 所以只要加入队列,立即标记该节点走过。
完整广搜代码实现:
#include <iostream>
#include <vector>
#include <queue>using namespace std;int dir[4][2] = {1,0,0,1,-1,0,0,-1};
void bfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y)
{queue<pair<int, int>> que;que.push({x,y});// 只要加入队列,立刻标记visited[x][y] = true;while(!que.empty()){pair<int, int> cur = que.front();que.pop();int curx = cur.first;int cury = cur.second;for(int i = 0; i < 4;i++){int nextx = curx + dir[i][0];int nexty = cury + dir[i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){que.push({nextx,nexty});visited[nextx][nexty] = true;}}}
}int main()
{int n,m;cin >> n >> m;vector<vector<int>> grid(n,vector<int>(m));vector<vector<bool>> visited(n,vector<bool>(m,false));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}int result = 0;for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(!visited[i][j] && grid[i][j] == 1){// 遇到没访问过的陆地,+1result++;// 将与其链接的陆地都标记上 truebfs(grid,visited,i,j);}}}cout << result << endl;return 0;
}
岛屿的最大面积
卡码网题目链接(ACM模式)
- 本题也是 dfs bfs基础类题目,就是搜索每个岛屿上 1 的数量,然后取一个最大的。
- 根据上述两种版本的写法,这里 dfs只处理下一个节点,即在主函数遇到岛屿就计数为1,dfs处理接下来的相邻陆地
程序实现(dfs)
#include <iostream>
#include <vector>using namespace std;int area; //当前面积
int dir[4][2] = {1,0,0,1,-1,0,0,-1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y)
{//遍历四周的岛屿for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;//发现没有遍历过的陆地if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){visited[nextx][nexty] = true;area++; //面积 + 1//深度搜索下一个的相连的岛屿dfs(grid,visited,nextx,nexty);}}
}int main()
{int n,m;int result = 0;cin >> n >> m;vector<vector<int>> grid(n,vector<int>(m));vector<vector<bool>> visited(n,vector<bool>(m,false));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}//遍历岛屿for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){//没有访问过的陆地if(!visited[i][j] && grid[i][j] == 1){visited[i][j] = true;area = 1;dfs(grid,visited,i,j); //标记相连的陆地为trueresult = max(result,area); //记录最大的陆地面积}}}cout << result << endl;
}
孤岛的总面积
卡码网:101. 孤岛的总面积
本题要求找到不靠边的陆地面积,那么我们只要从周边找到陆地然后 通过 dfs或者bfs 将周边靠陆地且相邻的陆地都变成海洋,然后再去重新遍历地图 统计此时还剩下的陆地就可以了。
如图,在遍历地图周围四个边,靠地图四边的陆地,都为绿色

在遇到地图周边陆地的时候,将1都变为0,此时地图为这样:

然后我们再去遍历这个地图,遇到有陆地的地方,去采用深搜或者广搜,边统计所有陆地。
程序实现(dfs):
#include <iostream>
#include <vector>using namespace std;// 本题要求找到不靠边的陆地面积,那么我们只要从周边找到陆地然后 通过 dfs或者bfs
//将周边靠陆地且相邻的陆地都变成海洋,然后再去重新遍历地图 统计此时还剩下的陆地就可以了。// 将相连的岛屿全部变成海洋
int dir[4][2] = {1,0,0,1,-1,0,0,-1};
int cnt = 0;
void dfs(vector<vector<int>>& grid, int x, int y)
{//标记变成海洋grid[x][y] = 0;//用于第二次求孤岛的面积使用 面积++cnt++;// 遍历四周是否有陆地for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];//越界if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;// 四周有陆地 深搜 将陆地标为海洋if(grid[nextx][nexty] == 1)dfs(grid,nextx,nexty);}return;
}int main()
{int n;int m;cin >> n >> m;// 输入图vector<vector<int>> grid(n,vector<int>(m));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}//遍历左右两边的岛屿 使相连的陆地全部变成海洋for(int i = 0; i < n;i++){//左侧if(grid[i][0] == 1)dfs(grid, i, 0);//右侧if(grid[i][m-1] == 1)dfs(grid, i, m-1);}//遍历上下两边的岛屿 使相连的陆地全部变成海洋for(int j = 0; j < m; j++){// 上边界if(grid[0][j] == 1)dfs(grid, 0, j);if(grid[n-1][j] == 1)dfs(grid, n-1, j);}cnt = 0;//遍历岛屿 剩下的陆地全是孤岛了for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(grid[i][j] == 1)dfs(grid,i,j);}}cout << cnt << endl;
}
沉没孤岛
卡码网题目链接(ACM模式)
- 本题和上述孤岛的总面积正好反过来了,上述是求孤岛的面积,而这题是将孤岛的1改为0,那么两题在思路上也是差不多的
- 思路依然是从地图周边出发,将周边空格相邻的陆地都做上标记(改为2),然后再遍历一遍地图,遇到 陆地 且没做过标记的,那么都是地图中间的 陆地 ,全部改成水域就行。
步骤一: 深搜或者广搜将地图周边的 1 (陆地)全部改成 2 (特殊标记)
步骤二: 将水域中间 1 (陆地)全部改成 水域(0)
步骤三: 将之前标记的 2 改为 1 (陆地)

程序实现(dfs):
#include <iostream>
#include <vector>using namespace std;int dir[4][2] = {1,0,0,1,-1,0,0,-1};
//将靠近地图周边的岛屿全部变成 2
void dfs(vector<vector<int>>& grid, int x, int y)
{grid[x][y] = 2;for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if( nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;if(grid[nextx][nexty] == 1)dfs(grid,nextx,nexty);}
}int main()
{int n, m;cin >> n >> m;vector<vector<int>> grid(n,vector<int>(m));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}//步骤一// 左右两列for(int i = 0; i < n; i++){if(grid[i][0] == 1)dfs(grid, i, 0);if(grid[i][m-1] == 1)dfs(grid, i, m-1);}//上下两行for(int j = 0; j < m; j++){if(grid[0][j] == 1)dfs(grid, 0, j);if(grid[n-1][j] == 1)dfs(grid, n-1, j);} // cout << "temp: " << endl;
// for(int i = 0; i < n;i++)
// {
// for(int j = 0; j < m; j++)
// {
// cout << grid[i][j] << " ";
// }
// cout << endl;
// }//步骤二 三 周围陆地变成1 孤岛陆地为0for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){//两个顺序不能换 否则全为0if(grid[i][j] == 1) grid[i][j] = 0;if(grid[i][j] == 2) grid[i][j] = 1;} }//输出结果for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cout << grid[i][j] << " ";} cout << endl;}
}
建造最大人工岛
卡码网题目链接(ACM模式)
给定一个由 1(陆地)和 0(水)组成的矩阵,最多可以将矩阵中的一格水变为一块陆地,在执行了此操作之后,矩阵中最大的岛屿面积是多少?
案例, 输入陆地与海洋信息如下:

对于上面的案例,有两个位置可将 0 变成 1,使得岛屿的面积最大,即 6。

思路
- 本题的一个暴力想法,应该是遍历地图尝试 将每一个 0 改成1,然后去搜索地图中的最大的岛屿面积。
- 计算地图的最大面积:遍历地图 + 深搜岛屿,时间复杂度为 n ∗ n n * n n∗n。
- 每改变一个0的方格,都需要重新计算一个地图的最大面积,所以 整体时间复杂度为: n 4 n^4 n4
优化思路
- 其实每次深搜遍历计算最大岛屿面积,我们都做了很多重复的工作,只要用一次深搜把每个岛屿的面积记录下来就好。
第一步: 一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积
第二步: 再遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。
拿如下地图的岛屿情况来举例: (1为陆地)

第一步: 遍历陆地,并将岛屿到编号和面积上的统计,过程如图所示:

统计每一块岛屿的面积,并将岛屿面积存入对应的编号map中保存,核心代码如下:
int area = 0; // 统计当前遍历岛屿的面积
int dir[4][2] = {1,0,0,1,-1,0,0,-1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int landIdx)
{// 给陆地标记新标签grid[x][y] = landIdx;//四个方向都会递归for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];//越界if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;//统计相连陆地的面积if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){area++;visited[nextx][nexty] = true;dfs(grid, visited, nextx, nexty, landIdx);}}
}unordered_map<int, int> landArea;
int landIdx = 2; //标记岛屿的编号
for(int i = 0;i < n; i++)
{for(int j = 0; j < m; j++){//遍历到新的岛屿 计算每个新陆地形成的岛屿面积if(!visited[i][j] && grid[i][j] == 1){area = 1; // 重新计算一块新的岛屿面积visited[i][j] = true;// 将与其连接的陆地都标记上 true 同时给每个岛屿编个号 landIdxdfs(grid, visited, i, j, landIdx); landArea[landIdx++] = area; // 标记每一块编号为 landIdx 的面积为 area}}
}
第二步: 遇到海洋,将0变成1后,看能形成的最大岛屿的面积(遍历海洋周围一圈是否有岛屿),有则拼接岛屿

这里要注意几个细节:
- 特殊情况: n * m 的网格全部为陆地
- 在海洋周围找到陆地后,拼接岛屿完成后需要对该岛屿进行标记,否则可能重复拼接周围的同一块岛屿
拼接岛屿核心代码如下:
int result = 0; // 记录最后结果
unordered_set<int> visitedGrid; // 标记访问过的岛屿
for(int i = 0; i < n; i++)
{for(int j = 0; j < m; j++){area = 1; // 记录连接之后的岛屿面积visitedGrid.clear(); // 每次使用时,清空//访问到海洋了 //计算这个海洋节点变成陆地后拼接周围四个方向岛屿的面积if(grid[i][j] == 0){for(int k = 0; k < 4; k++){// 计算周围的相邻坐标int nexti = i + dir[k][0];int nextj = j + dir[k][1];//越界if(nexti < 0 || nexti >= grid.size() || nextj < 0 || nextj >= grid[0].size())continue; // 添加过的岛屿不要重复添加if(visitedGrid.count(grid[nexti][nextj])) continue; //周围遇到新的陆地if(grid[nexti][nextj] > 0){area += landArea[grid[nexti][nextj]]; // 拼接面积visitedGrid.insert(grid[nexti][nextj]); // 标记该岛屿已经添加过} }//cout << area << endl;result = max(result,area);}}
}
完整代码实现如下:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>using namespace std;int area = 0; // 统计当前遍历岛屿的面积
int dir[4][2] = {1,0,0,1,-1,0,0,-1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int landIdx)
{// 给陆地标记新标签grid[x][y] = landIdx;//四个方向都会递归for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];//越界if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;//统计相连陆地的面积if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){area++;visited[nextx][nexty] = true;dfs(grid, visited, nextx, nexty, landIdx);}}
}int main()
{int n, m;cin >> n >> m;int isAllLand = true; //记录是否全部为陆地vector<vector<int>> grid(n, vector<int>(m));vector<vector<bool>> visited(n, vector<bool>(m, false));for(int i = 0;i < n; i++){for(int j = 0; j < m; j++){cin >>grid[i][j];}}unordered_map<int, int> landArea;int landIdx = 2; //标记岛屿的编号for(int i = 0;i < n; i++){for(int j = 0; j < m; j++){if(grid[i][j] == 0)isAllLand = false; //有海洋//遍历到新的岛屿 计算每个新陆地形成的岛屿面积if(!visited[i][j] && grid[i][j] == 1){area = 1;visited[i][j] = true;// 将与其连接的陆地都标记上 true 同时给每个岛屿编个号 landIdxdfs(grid, visited, i, j, landIdx); landArea[landIdx++] = area; // 标记每一块编号为 landIdx 的面积为 area}}}// 全是陆地 不用建造了if(isAllLand == true){cout << n * m << endl;return 0;}// cout << "area: " << endl;
// for(int i = 2; i < landIdx; i++)
// {
// cout << landArea[i] << endl;
// }
//
// cout << "landIdx: " << endl;
// for(int i = 0; i < n; i++){
// for(int j = 0; j < m; j++){
// cout << grid[i][j] << " ";
// }
// cout << endl;
// }
// int result = 0; // 记录最后结果unordered_set<int> visitedGrid; // 标记访问过的岛屿for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){area = 1; // 记录连接之后的岛屿面积visitedGrid.clear(); // 每次使用时,清空//访问到海洋了 //计算这个海洋节点变成陆地后拼接周围四个方向岛屿的面积if(grid[i][j] == 0){for(int k = 0; k < 4; k++){// 计算周围的相邻坐标int nexti = i + dir[k][0];int nextj = j + dir[k][1];//越界if(nexti < 0 || nexti >= grid.size() || nextj < 0 || nextj >= grid[0].size())continue; // 添加过的岛屿不要重复添加if(visitedGrid.count(grid[nexti][nextj])) continue; //周围遇到新的陆地if(grid[nexti][nextj] > 0){area += landArea[grid[nexti][nextj]]; // 拼接面积visitedGrid.insert(grid[nexti][nextj]); // 标记该岛屿已经添加过} }//cout << area << endl;result = max(result,area);}}}cout << result << endl;
}
水流问题
卡码网题目链接(ACM模式)
题目描述:
现有一个 N × M 的矩阵,每个单元格包含一个数值,这个数值代表该位置的相对高度。矩阵的左边界和上边界被认为是第一组边界,而矩阵的右边界和下边界被视为第二组边界。
矩阵模拟了一个地形,当雨水落在上面时,水会根据地形的倾斜向低处流动,但只能从较高或等高的地点流向较低或等高并且相邻(上下左右方向)的地点。我们的目标是确定那些单元格,从这些单元格出发的水可以达到第一组边界和第二组边界。
输入描述:
- 第一行包含两个整数 N 和 M,分别表示矩阵的行数和列数。
- 后续 N 行,每行包含 M 个整数,表示矩阵中的每个单元格的高度。
输出描述:
输出共有多行,每行输出两个整数,用一个空格隔开,表示可达第一组边界和第二组边界的单元格的坐标,输出顺序任意。
输入示例:
5 5
1 3 1 2 4
1 2 1 3 2
2 4 7 2 1
4 5 6 1 1
1 4 1 2 1
输出示例:
0 4
1 3
2 2
3 0
3 1
3 2
4 0
4 1
提示信息:

- 图中的蓝色方块上的雨水既能流向第一组边界,也能流向第二组边界。所以最终答案为所有蓝色方块的坐标。
思路
- 一个比较直白的想法,其实就是 遍历每个点,然后看这个点 能不能同时到达第一组边界和第二组边界。
- 遍历每一个节点,时间复杂度是 m ∗ n m * n m∗n,遍历每一个节点的时候,都要做深搜,深搜的时间复杂度是: m ∗ n m * n m∗n,那么整体时间复杂度 就是 O ( m 2 ∗ n 2 ) O(m^2 * n^2) O(m2∗n2),这是一个四次方的时间复杂度,显然时间复杂度超时。
- 那么我们可以 反过来想,从第一组边界上的节点 逆流而上,将遍历过的节点都标记上。
- 同样从第二组边界的边上节点 逆流而上,将遍历过的节点也标记上。
- 然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。
从第一组边界边上节点出发,如图:

从第二组边界上节点出发,如图:

#include <iostream>
#include <vector>using namespace std;//从第一组边界上的节点 逆流而上,将遍历过的节点都标记上。
//同样从第二组边界的边上节点 逆流而上,将遍历过的节点也标记上。
//然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。int n, m;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y)
{//统一递归返回 下面不做判断是否访问过 处理当前节点if(visited[x][y]) return;// 标记可以逆流visited[x][y] = true;for(int i = 0; i < 4; i++){// 计算周围节点int nextx = x + dir[i][0];int nexty = y + dir[i][1];//越界if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size())continue;/// 注意:这里是逆向流水if(grid[x][y] <= grid[nextx][nexty])dfs(grid, visited, nextx, nexty);}return ;
}int main()
{cin >> n >> m;vector<vector<int>> grid(n,vector<int>(m,0));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> firstBorder(n, vector<bool>(m, false));// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> secondBorder(n, vector<bool>(m, false));//左侧和右侧for(int i = 0; i < n; i++){dfs(grid, firstBorder, i, 0); // 遍历最左列,接触第一组边界dfs(grid, secondBorder, i,m-1); // 遍历最右列,接触第二组边界}//上下边界for(int j = 0; j < m; j++){dfs(grid, firstBorder, 0, j); // 遍历最上册,接触第一组边界dfs(grid, secondBorder, n-1, j); // 遍历最下列,接触第二组边界}// 遍历每一个点,看是否能同时到达第一组边界和第二组边界for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(firstBorder[i][j] && secondBorder[i][j])cout << i << " " << j << endl;}}
}
岛屿的周长
卡码网题目链接(ACM模式)
在矩阵中恰好拥有一个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
输出描述: 输出一个整数,表示岛屿的周长。
输出示例: 14
提示信息:

思路:
-
岛屿问题最容易让人想到BFS或者DFS,但本题确实还用不上。 为了避免惯性思维,所以这道题。
-
遍历每一个空格,遇到岛屿则计算其上下左右的空格情况。
-
如果该陆地上下左右的空格是有水域,则说明是一条边,如图:

-
如果该陆地上下左右的空格出界了,则说明是一条边,如图:

程序实现:
#include <iostream>
#include <vector>using namespace std;int main()
{int n, m;cin >> n >> m;int dir[4][2] = {1,0,0,1,-1,0,0,-1}; vector<vector<int>> grid(n, vector<int>(m));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}int res = 0;for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){// 遇到陆地if(grid[i][j] == 1){//计算周围节点坐标for(int k = 0; k < 4; k++){int nexti = i + dir[k][0];int nextj = j + dir[k][1];if( nexti < 0 || nexti >= n || // 越界nextj < 0 || nextj >= m || // 越界grid[nexti][nextj] == 0 // 水域){res++;}}}}}cout << res << endl;return 0;
}
相关文章:
【图论】(一)图论理论基础与岛屿问题
图论理论基础与岛屿问题 图论理论基础深度搜索(dfs)广度搜索(bfs)岛屿问题概述 岛屿数量岛屿数量-深搜版岛屿数量-广搜版 岛屿的最大面积孤岛的总面积沉没孤岛建造最大人工岛水流问题岛屿的周长 图论理论基础 这里仅对图论相关核…...
PhotoMaker部署文档
一、介绍 PhotoMaker:一种高效的、个性化的文本转图像生成方法,能通过堆叠 ID 嵌入自定义逼真的人类照片。相当于把一张人的照片特征提取出来,然后可以生成你想要的不同风格照片,如写真等等。 主要特点: 在几秒钟内…...

双十一买什么最划算?2024年双十一选购攻略汇总!
随着一年一度的双十一购物狂欢节日益临近,消费者们纷纷摩拳擦掌,准备在这个全球最大的购物盛宴中抢购心仪已久的商品。双十一不仅是一场购物的狂欢,更是商家们推出优惠、促销的绝佳时机。然而,面对琳琅满目的商品和纷繁复杂的优惠…...

Oracle架构之物理存储之审计文件
文章目录 1 审计文件(audit files)1.1 定义1.2 查看审计信息1.3 审计相关参数1.4 审计的类型1.4.1 语句审计1.4.2 权限审计1.4.3 对象审计1.4.4 细粒度的审计 1.5 与审计相关的数据字典视图 1 审计文件(audit files) 1.1 定义 审…...

DAY6 面向对象
概念 对象是一种特殊的数据结构,可以用来记住一个事物的数据,从而代表该事物,可以理解为一个模板表,总而言之万物皆对象,比如一个人、一个物体等。 怎么创建对象 先设计对象的模板,也就是对象的设计图&a…...

代码随想录 (三)—— 哈希表部分刷题
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。 数组set (集合)map(映射) 在java中有就是,hashmap, LinkedHashMap, TreeMap ,HashTable 等 总结一下,当我们遇到了要快速判断一个…...

搜维尔科技:使用 SenseGlove Nova 2 远程操作机械手,实现了对鸡蛋的精细操控
使用SenseGlove Nova 2远程操作机械手,实现了对鸡蛋的精细操控 搜维尔科技:使用 SenseGlove Nova 2远程操作机械手,实现了对鸡蛋的精细操控...

Mybatis是什么?优缺点分别有哪些?
MyBatis 是一个开源的持久层框架,它提供了将 SQL 语句和 Java 对象进行映射的功能,使得开发者可以通过简单的配置来实现数据库操作,减少了手写 SQL 的工作量。 MyBatis 的优点: 1. 简单易用:MyBatis 采用了简单的配置…...

opencascade鼠标拖拽框选功能
1.首先在OccView中添加用于显示矩形框的类 //! rubber rectangle for the mouse selection.Handle(AIS_RubberBand) mRectBand; 2.设置框选的属性 mRectBand new AIS_RubberBand(); //设置属性 mRectBand->SetLineType(Aspect_TOL_SOLID); //设置变宽线型为实线 mRe…...

docker 部署 postgres
这里以postgres:12.6为例: 1. 拉取postgres镜像 docker pull postgres:12.62. 创建挂载目录 mkdir -p /mydata/docker/postgres-1/data3. 启动postgres容器 docker run --name postgres-12.6 \-e POSTGRES_PASSWORD123456 \-p 5432:5432 \-v /mydata/docker/pos…...

【重学 MySQL】五十、添加数据
【重学 MySQL】五十、添加数据 使用INSERT INTO语句添加数据基本语法示例插入多行数据注意事项 使用LOAD DATA INFILE语句批量添加数据其他插入数据的方式注意事项 在MySQL中,添加数据是数据库操作中的基本操作之一。 使用INSERT INTO语句添加数据 使用 INSERT IN…...

硬货!Zabbix监控AIX系统服务案例
本文将介绍如何使用Zabbix自定义键值脚本方式监控AIX 系统IBM CICS中间件进程服务以及日志文件等信息。 Customer Information Control System (CICS) Transaction Server 是 IBM 针对 z/OS 的多用途事务处理软件。这是一个功能强大的应用程序服务器,用于大型和小型…...
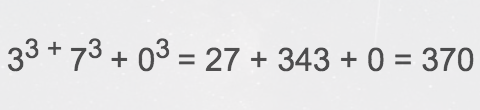
python常见面试题
1、什么是Python?为什么它会如此流行? Python是一种解释的、高级的、通用的编程语言。 Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。 它之所以受欢迎,就是因为它具有简单易用的语法。 ▍2、为什么Python执…...
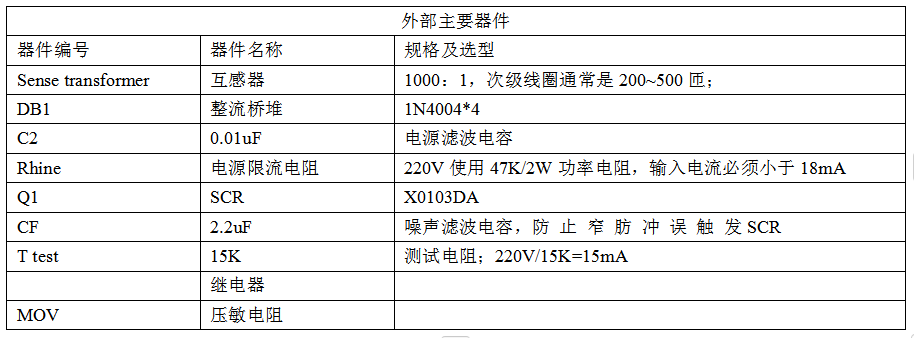
低功耗接地故障控制器D4145
一、概述 D4145 是一个接地故障断路器。它能够检测到不良的接地条件,譬如装置接触到水时,它会在有害或致命的电击发生之前将电路断开。 D4145能检测并保护从火线到地线,从零线到地线的故障.这种简单而传统的电路设计能够确保其应用自如和长时间的可靠性。…...

SpringMVC的处理流程
深入理解 SpringMVC 的请求处理流程:从用户请求到视图渲染的八个步骤 SpringMVC 是当前流行的基于 Java 的 Web 框架之一,它通过前端控制器 DispatcherServlet 将用户的 HTTP 请求统一接收并处理,随后将请求分发到具体的处理器(通…...

SpringBoot统一日志框架
在项目开发中,日志十分的重要,不管是记录运行情况还是定位线上问题,都离不开对日志的分析。 1.日志框架的选择 市面上常见的日志框架有很多,它们可以被分为两类:日志门面(日志抽象层)和日志实…...
vue-live2d看板娘集成方案设计使用教程
文章目录 前言v1.1.x版本:vue集成看板娘(暂不使用,在v1.2.x已替换)集成看板娘实现看板娘拖拽效果方案资源备份存储 当前最新调研:2024.10.2开源方案1:OhMyLive2D(推荐)开源方案2&…...

springboot接口如何支持400并发量
Spring Boot 本身并不直接限制并发量,但是你可以通过配置来优化应用以处理更多的并发请求。以下是一些关键配置和优化技巧: 服务器连接配置(application.properties 或 application.yml): # 服务器连接数配置 server.tomcat.max…...

Verilog中的: `+:` 和 `-:`
: 和 -: 标准解释 logic [15:0] down_vect; logic [0:15] up_vect;down_vect[lsb_base_expr : width_expr] up_vect [msb_base_expr : width_expr] down_vect[msb_base_expr -: width_expr] up_vect [lsb_base_expr -: width_expr]举例 reg [31:0] dword; reg [7:0] byte0…...

为何四次挥手要等待2MSL
参考文章:https://zhuanlan.zhihu.com/p/204988465 A主动关闭连接一方,B是被动关闭一方 我们假设A发送了ACK报文后过了一段时间t之后B才收到该ACK,则有 0 < t < MSL。因为A并不知道它发送出去的ACK要多久对方才能收到,所以…...

计算机科学论文降AI工具免费推荐:2026年计算机科学毕业论文降AI4.8元亲测99.26%知网达标完整指南
计算机科学论文降AI工具免费推荐:2026年计算机科学毕业论文降AI4.8元亲测99.26%知网达标完整指南 答辩前夕,AI率36%,学校要求15%以下。 用嘎嘎降AI(www.aigcleaner.com),4.8元,两小时搞定&…...

如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南
如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南 【免费下载链接】lingtrain-aligner Lingtrain Aligner — ML powered library for the accurate texts alignment. 项目地址: https://gitcode.com/gh_mirrors/li/lingtrain-aligner 平…...
)
用C++和Eigen库手把手实现UR3机械臂逆解(附完整代码与避坑指南)
从理论到实践:基于Eigen库的UR3机械臂逆运动学完整实现指南 在工业自动化和机器人研究领域,六轴协作机械臂因其灵活性和广泛的应用场景而备受关注。UR3作为Universal Robots旗下的紧凑型协作机械臂,凭借其轻量化设计和用户友好特性࿰…...

共享茶室智能系统与运营全解析:从空间设计到自动化管理
1. 项目概述:为什么“共享茶室”正在重塑传统茶饮消费如果你最近留意过城市里的新业态,可能会发现一种名为“共享茶室”的空间正在悄然兴起。它不像传统的茶馆那样需要高昂的消费和复杂的社交礼仪,也不像奶茶店那样主打快节奏的“即买即走”。…...

5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 [特殊字符]
5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而错过心仪的游戏大作?XUnity自动翻译器…...

Linux服务器文件传输服务搭建:从FTP协议到vsftpd实战部署
1. 项目概述:为什么要在Linux上搭建FTP服务器?很多刚接触Linux的朋友,尤其是从Windows转过来的,一提到搭建服务器,特别是像FTP这种“古老”但依然实用的文件传输服务,第一反应可能就是“头大”。在Windows上…...

拯救论文AI检测标红!2026实测5款降重平台,注入“真实感”的手改全攻略
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

如何通过3个步骤掌握iOS游戏修改神器H5GG
如何通过3个步骤掌握iOS游戏修改神器H5GG 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 你是否曾想在iOS设备上修改游戏数值却苦于没有越狱?是否觉得传统游戏修改工具操作…...
)
Python开发被内网卡脖子?5分钟用Docker搭个Pypiserver救急(含避坑指南)
Python内网开发救星:Docker化Pypiserver极速搭建指南 当你在客户现场调试代码时,突然发现内网环境无法连接PyPI官方源;当你在保密项目部署时,发现所有外网访问都被严格限制——这种"被卡脖子"的困境,相信不少…...

ASReview实战:用主动学习技术高效完成文献综述
1. 项目概述:当学术文献综述遇上主动学习如果你是一名研究生、科研人员,或者任何需要从海量文献中筛选出相关研究的人,那么“大海捞针”这个词你一定深有体会。面对动辄成千上万篇的论文标题和摘要,传统的人工筛选不仅耗时耗力&am…...