【艾思科蓝】Imagen:重塑图像生成领域的革命性突破
【连续七届已快稳ei检索】第八届电子信息技术与计算机工程国际学术会议(EITCE 2024)_艾思科蓝_学术一站式服务平台
更多学术会议请看 学术会议-学术交流征稿-学术会议在线-艾思科蓝
目录
引言
一、Imagen模型的技术原理
1. 模型概述
2. 工作流程
3. 技术创新
二、Imagen模型的应用实例
1. 创意设计
2. 虚拟角色制作
3. 概念可视化
三、Imagen模型的优势与挑战
1. 优势
2. 挑战
四、Imagen模型的未来发展方向
1. 图像生成质量的提升
2. 多模态理解能力的增强
3. 稳定性和可控性的提高
4. 跨领域的应用拓展
五、代码解析与实现细节
1. 文本编码器(Text Encoder)
2. 条件扩散模型(Conditional Diffusion Model)
3. 超分辨率模型(Super-Resolution Model)
4. 潜在扩散模型(Latent Diffusion Model, 适用于Imagen 3)
引言
随着人工智能技术的飞速发展,图像生成领域正经历着一场前所未有的变革。从最初的简单随机噪声生成图像,到如今能够生成高度逼真、细节丰富的照片级图像,这一领域的进步令人瞩目。在众多图像生成模型中,Google Research开发的Imagen模型无疑是一颗璀璨的明星,它以卓越的性能和广泛的应用前景,成为了图像生成领域的佼佼者。
一、Imagen模型的技术原理
1. 模型概述
Imagen是由Google Research开发的一种先进的文本到图像的生成模型。它结合了大型Transformer语言模型的强大能力和高保真图像生成技术,实现了前所未有的照片级真实感和深度语言理解能力。这一模型通过输入文本描述,能够自动生成与之对应的高质量图像,广泛应用于创意设计、虚拟现实、建筑设计等多个领域。
2. 工作流程
Imagen模型的工作流程可以概括为以下几个步骤:
- 文本编码:首先,输入的文本通过一个大型的固定T5-XXL编码器进行编码,生成文本嵌入(text embeddings)。这一步骤将自然语言文本转化为模型可理解的数值表示。
- 基础扩散模型:这些文本嵌入被输入到一个条件扩散模型中,该模型生成一个初始的低分辨率图像(通常为64x64像素)。条件扩散模型通过逐步添加噪声并去除噪声的方式,逐步生成图像。
- 超分辨率模型:为了将初始的低分辨率图像上采样到更高的分辨率,Imagen使用了两个超分辨率扩散模型。第一个模型将图像分辨率提升到256x256,第二个模型再将分辨率提升到最终的1024x1024。这两个模型在上采样过程中使用了噪声调节增强技术,以确保生成图像的逼真度。
- 级联扩散模型:Imagen的核心是一个级联的扩散模型,由多个U-Net网络组成。每个网络负责不同分辨率的图像生成,确保了图像在不同尺度上的连贯性和细节表现。
3. 技术创新
Imagen模型在技术创新方面主要体现在以下几个方面:
- 潜在扩散模型(Latent Diffusion Model):Imagen 3版本引入了潜在扩散模型,通过在较低维度的潜在空间中操作,提高了计算效率并减少了计算资源的需求。这种模型架构使得Imagen 3在保持高质量生成的同时,大幅提升了生成速度。
- 多阶段生成策略:Imagen采用多阶段生成策略,从低分辨率图像开始逐步上采样到高分辨率图像。这种策略确保了图像在不同阶段的连贯性和细节表现,避免了传统模型在高分辨率生成时容易出现的伪影和质量损失问题。
- 强大的语言理解能力:Imagen结合了大规模预训练的自然语言处理模型(如T5),能够准确理解复杂的文本描述,并生成与之高度一致的图像。这种能力使得Imagen在图像生成领域具有显著的优势。
二、Imagen模型的应用实例
Imagen模型在实际应用中展现出了强大的创作能力和广泛的应用前景。以下是一些典型的应用实例:
1. 创意设计
设计师可以利用Imagen模型快速生成多种设计方案,如服装、家居、建筑等。通过输入简单的文字描述或草图,Imagen便能迅速生成符合要求的高清图像,大大提高了设计效率。这种能力使得设计师能够更快速地探索不同的设计思路,并找到最优的设计方案。
2. 虚拟角色制作
在游戏、电影等领域,虚拟角色的制作至关重要。借助Imagen模型,制作人员可以根据剧本需求快速生成角色形象,为后续的制作流程奠定基础。Imagen能够准确捕捉文本描述中的细节特征,如角色的外貌、服饰、表情等,并生成与之高度一致的图像。这种能力使得虚拟角色的制作更加高效和逼真。
3. 概念可视化
对于科幻、奇幻等难以用文字描述的概念,Imagen模型能够将其转化为直观的图像。用户只需提供简短的文本描述,Imagen便能生成与之对应的图像,帮助读者更好地理解和想象。这种能力在文学创作、电影剧本编写等领域具有广泛的应用前景。
三、Imagen模型的优势与挑战
1. 优势
- 高质量的图像生成:Imagen模型能够生成高度逼真、细节丰富的照片级图像,满足专业视觉内容的需求。
- 深度文本理解能力:Imagen结合了大规模预训练的自然语言处理模型,能够准确理解复杂的文本描述,并生成与之高度一致的图像。
- 多阶段生成策略:Imagen采用多阶段生成策略,确保了图像在不同阶段的连贯性和细节表现。
- 广泛的应用前景:Imagen模型在创意设计、虚拟角色制作、概念可视化等多个领域具有广泛的应用前景。
2. 挑战
- 数据偏见:Imagen模型在训练过程中可能受到数据偏见的影响,导致生成的图像在某些方面存在偏见。为了减少这种影响,需要尽可能使用多样化的训练数据。
- 版权问题:Imagen生成的图像可能涉及版权纠纷。虽然模型能够从大量图像中学习并生成新的作品,但这些作品可能与其他艺术家的原创作品相似度较高,从而引发版权争议。
- 计算资源消耗:训练和使用Imagen模型需要大量的计算资源,包括高性能计算机和显卡。这使得普通用户难以承担其高昂的成本。
四、Imagen模型的未来发展方向
随着人工智能技术的不断演进,Imagen模型在未来仍有巨大的发展潜力。以下是一些可能的发展方向:
1. 图像生成质量的提升
Imagen模型在图像生成方面已经取得了显著的进步,但仍有进一步提升的空间。未来可以通过优化模型架构和算法,提高图像的真实感和细节表现力。例如,可以通过引入更复杂的网络结构和更精细的训练策略,来生成更加逼真和生动的图像。
2. 多模态理解能力的增强
Imagen模型结合了Transformer语言模型和高保真扩散模型,在文本到图像的合成中提供了前所未有的逼真度和语言理解能力。未来可以通过引入更多的数据源和更复杂的模型架构,提升对不同语言风格、用户提示的理解能力,以生成更符合用户需求的图像。这种多模态理解能力的增强将有助于Imagen在更多领域发挥作用。
3. 稳定性和可控性的提高
随着图像生成技术的发展,其与三维生成的强相关性将会更多地应用于视频、教育、建筑以及虚拟空间建模等领域。因此,提高Imagen模型的稳定性和可控性是未来发展的重要方向。这将有助于在这些领域中实现更广泛的应用,并提升用户体验。
4. 跨领域的应用拓展
Imagen模型在创意设计、虚拟角色制作、概念可视化等领域已经展现出了广泛的应用前景。未来可以进一步拓展其应用领域,如游戏设计、虚拟现实、电影制作等。这将为相关行业带来更多的创新和变革,推动整个行业的发展。
五、代码解析与实现细节
为了更深入地理解Imagen模型的工作原理及其在技术实现上的精妙之处,接下来我们将通过一些简化的代码示例和概念解析来探讨其内部机制。请注意,由于Imagen模型的完整实现涉及复杂的深度学习架构和大量的计算资源,以下代码将侧重于展示关键组件和概念,而非完整的可运行代码。
1. 文本编码器(Text Encoder)
Imagen模型使用了一个预训练的大型Transformer语言模型(如T5-XXL)作为文本编码器。这个编码器负责将输入的文本描述转换为模型可以理解的数值表示(文本嵌入)。以下是一个简化的文本编码器伪代码示例:
import torch
from transformers import T5Tokenizer, T5Model # 假设我们有一个预训练的T5模型和分词器
tokenizer = T5Tokenizer.from_pretrained('t5-small') # 注意:实际应使用T5-XXL,但这里为简化使用t5-small
model = T5Model.from_pretrained('t5-small') def encode_text(text): # 对文本进行分词 inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512) # 使用T5模型生成文本嵌入 with torch.no_grad(): outputs = model(**inputs) # outputs.last_hidden_state 包含文本嵌入 text_embeddings = outputs.last_hidden_state[:, 0, :] # 取第一个token(通常是CLS token)的嵌入 return text_embeddings # 示例使用
text_description = "A beautiful sunset over the ocean, with golden clouds and a reflection in the water."
text_embeddings = encode_text(text_description)
print(text_embeddings.shape) # 输出文本嵌入的维度请注意,上述代码使用了
transformers库中的T5Tokenizer和T5Model来模拟文本编码过程。然而,在实际应用中,Imagen模型使用的是更大规模的T5-XXL模型,并且可能进行了额外的调优以适应图像生成任务。
2. 条件扩散模型(Conditional Diffusion Model)
Imagen模型中的条件扩散模型负责根据文本嵌入生成初始的低分辨率图像。这个模型通过逐步添加噪声并学习去除噪声的过程来生成图像。由于条件扩散模型的实现相对复杂,这里我们将通过一个简化的伪代码来描述其工作流程:
# 假设有一个预训练的条件扩散模型
# 这里我们使用伪代码来表示其前向传播过程 def conditional_diffusion_model(text_embeddings, timesteps, noise): # text_embeddings: 文本嵌入 # timesteps: 扩散过程中的时间步 # noise: 添加到图像中的随机噪声 # 伪代码:模拟条件扩散模型的前向传播 # 实际上,这个模型会包含多个U-Net网络层,每个时间步对应一个网络层 # 初始化图像(通常是全零或随机噪声) image = torch.randn(image_size) # 假设image_size是预先定义的 # 逐步去噪过程 for t in reversed(range(timesteps)): # 这里应该有一个U-Net网络接收(text_embeddings, image_noisy_at_t, t)作为输入 # 但为了简化,我们省略了具体的网络实现 # 假设有一个函数denoise_step能够代表U-Net的一个去噪步骤 image = denoise_step(text_embeddings, image + noise[t], t) # 返回最终生成的图像 return image # 注意:上述代码中的denoise_step函数是虚构的,用于说明目的
# 在实际实现中,这个步骤会由U-Net网络及其变体来完成3. 超分辨率模型(Super-Resolution Model)
Imagen模型使用两个超分辨率扩散模型将初始的低分辨率图像上采样到更高的分辨率。这些模型同样基于U-Net架构,但针对不同的分辨率级别进行了优化。以下是超分辨率模型的一个简化表示:
# 假设有两个预训练的超分辨率模型
# 第一个模型将图像从64x64上采样到256x256
# 第二个模型将图像从256x256上采样到1024x1024 def super_resolution_model_64_to_256(low_res_image): # 这里应该有一个预训练的超分辨率模型 # 但为了简化,我们使用一个占位符函数 high_res_image = upsample_and_refine(low_res_image, target_size=(256, 256)) return high_res_image def super_resolution_model_256_to_1024(low_res_image): # 同上,这是一个将256x256图像上采样到1024x1024的模型 high_res_image = upsample_and_refine(low_res_image, target_size=(1024, 1024)) return high_res_image # 注意:upsample_and_refine函数是虚构的,用于表示上采样和精细化的过程
# 在实际中,这个过程由多个U-Net层和其他网络组件共同完成4. 潜在扩散模型(Latent Diffusion Model, 适用于Imagen 3)
Imagen 3版本引入了潜在扩散模型,以在较低维度的潜在空间中操作,提高计算效率和生成速度。潜在扩散模型通过以下步骤工作:
- 编码到潜在空间:首先,将图像编码到一个较低维度的潜在表示中。
- 在潜在空间中进行扩散和去噪:在潜在空间中进行类似于标准扩散模型的扩散和去噪过程。
- 解码回图像空间:最后,将潜在空间中的表示解码回图像空间。
由于潜在扩散模型的实现较为复杂,这里我们不再提供具体的代码示例,但可以理解为其在内部使用了类似的U-Net架构和去噪步骤,只不过这些操作是在潜在空间而非直接的图像空间中进行。
相关文章:

【艾思科蓝】Imagen:重塑图像生成领域的革命性突破
【连续七届已快稳ei检索】第八届电子信息技术与计算机工程国际学术会议(EITCE 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看 学术会议-学术交流征稿-学术会议在线-艾思科蓝 目录 引言 一、Imagen模型的技术原理 1. 模型概述 2. 工作流程 …...

java类和对象(下): 封装 static成员 内部类
前言: 在前期的知识点中,我们学习了java中this函数的使用和相关的概念。这期我们将介绍封装的概念,以及常见内部类的使用,让我们开车吧!!!! 本期目录: 6. 封装 7. st…...

外包干了3周,技术退步太明显了。。。。。
先说一下自己的情况,大专生,21年通过校招进入武汉某软件公司,干了差不多3个星期的功能测试,那年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我才在一个外包企业干了3周的功…...

VIVO算法题——数位之积
记录算法究极无敌菜菜菜鸟的垃圾思维 题目: 现给定任意正整数 n,请寻找并输出最小的正整数 m(m>9),使得 m 的各位(个位、十位、百位 … …)之乘积等于n,若不存在则输出 -1。 菜鸟…...
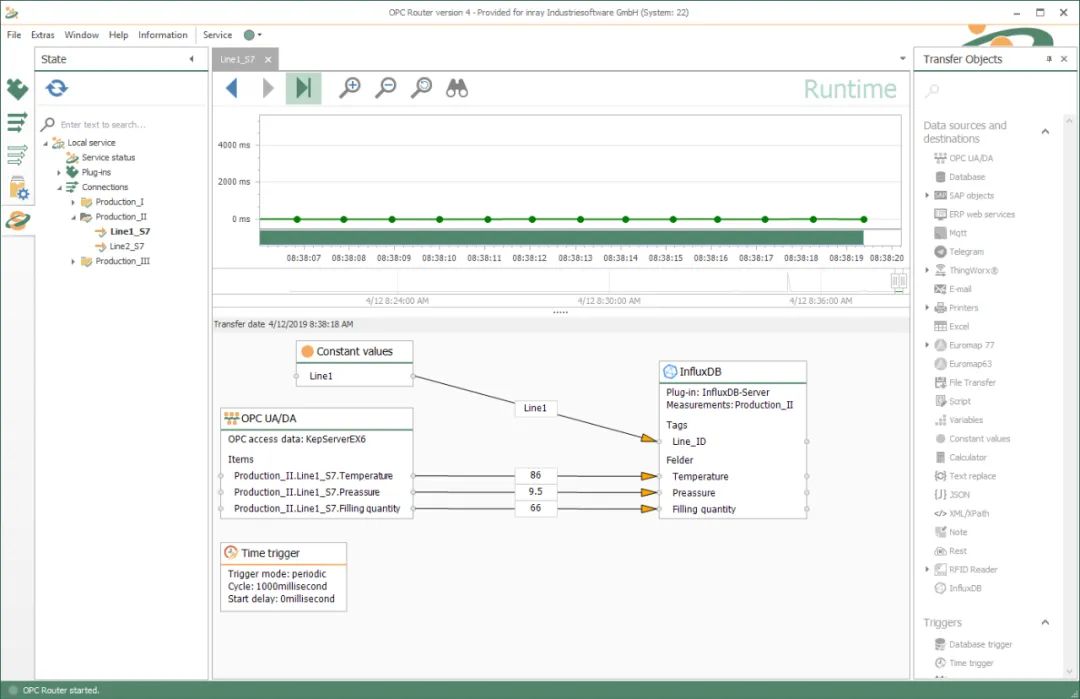
OPC Router快速打通设备层与influxDB数据通讯
随着时代演化,数据量呈几何倍数增加的情况下出现了时序数据库。时序数据库是基于时间进行存储的数据库,每一条数据中都有一个时间戳,这种数据库特别适合存储那些随着时间变化的数据,通过一些工具处理后,能够分析出数据…...

鸿蒙开发 四十四 ArkTs BuilderParam传递UI(二)
子组件多个BuilderParam,必须通过参数的方式传入,如果界面中有多个界面需要传递,可以定义多个尾随闭包,如图: 在自定义组件中调用: 在使用时候调用是作为参数传递给自定义的组件,参数是界面&…...

同期数分析-留存率
目录 同期数分析 加载数据 单月实现 统计每个月的订单量 求2月份的订单量和用户数量 求2月之前的历史订单量 筛选出2023年2月的新增的用户数 计算2023年2月在后面的留存情况 完整的2023年2月份同期群结果 遍历合并和分析 引入月份列表 遍历 调整成留存率的形式 回…...

Java前后端交互:构建现代Web应用
在现代Web应用开发中,前后端分离是一种常见的架构模式。后端通常负责数据处理和业务逻辑,而前端则负责用户界面和用户体验。Java作为后端开发的强大语言,提供了多种方式与前端进行交互。本文将探讨Java后端与前端交互的几种主要方式ÿ…...

vue3中用axios请求怎么添加cookie
在 Vue 3 中使用 axios 发起请求时,可以通过配置 axios 的请求选项来携带 Cookies。具体来说,确保跨域请求时,设置 withCredentials: true,以便发送和接收 Cookies。 1. Axios 配置携带 Cookie 首先确保你在 axios 请求中设置了…...

informer学习笔记
一、informer讲解 infomer 要解决的三大问题: Attention计算的更快Decoder要一次性输出所有预测堆叠encoder也要更快 1. Attention 在长序列中,并非每一个位置的Attention都重要,对于每一个Q来说,只有一小部分的K与其有较强的…...

Elasticsearch介绍和使用
一、Elasticsearch 强大的搜索和分析能力: Elasticsearch 是一个基于 Lucene 的分布式搜索和分析引擎。它能够快速地对大量数据进行全文搜索、结构化搜索和复杂的数据分析操作。对于大型数据集,它可以高效地处理各种查询需求,包括关键词搜索…...

【Flutter】基础入门:代码基本结构
通过这个简单的 Flutter 示例程序,我们可以快速了解 Flutter 的代码结构,理解每个部分的作用。 import package:flutter/material.dart; void main() { runApp(const MyApp()); } class MyApp extends StatelessWidget { const MyApp({super.key}…...

如何进行数据库缩容 | OceanBase应用实践
作者:关炳文,爱可生 DBA 团队成员,负责数据库相关技术支持。 本文详细介绍了OceanBase V3.2版的集群中,面对数据文件缩容的场景的一套缩容方案,作为大家的参考。 缩容场景 某银行运行的一套采用1-1-1架构的OceanBase…...

机器学习和深度学习的差别
定义和基本原理 机器学习: 定义:机器学习是一种让计算机自动从数据中学习规律和模式的方法,无需明确编程。它通过构建数学模型,利用已知数据进行训练,然后对新的数据进行预测或决策。基本原理:机器学习算…...

RAG拉满-上下文embedding与大模型cache
无论怎么选择RAG的切分方案,仍然切分不准确。 最近,anthropics给出了补充上下文的embedding的方案,RAG有了新的进展和突破。 从最基础的向量查询,到上下文embedding,再到rerank的测试准确度都有了明显的改善…...
CSS基础)
前端学习---(2)CSS基础
CSS 用来干什么? CSS 是用来指定文档如何展示给用户的一门语言——如网页的样式、布局、等等。 css语法: 选择器{ 属性名: 属性值; 属性名: 属性值; } h1 {color: red;font-size: 5em; }h1: 选择器 color: 属性 冒号之前是属性,冒号之后是值。 font-size…...
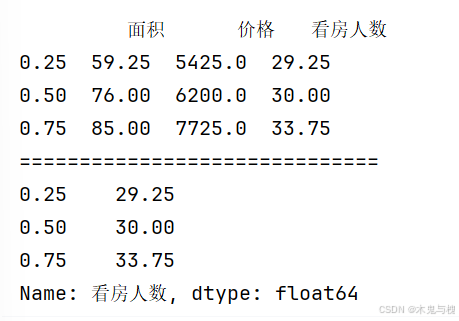
Pandas常用计算函数
目录 排序函数 nlargest函数 nsmallest函数 sort_values函数 df.sort_values Series.sort_values 聚合函数 corr函数-相关性 min函数-最小值 max函数-最大值 mean函数-平均值 sum函数-求和 count函数-统计非空数据 std函数-标准偏差 quantile函数-分位数 排序函…...

C++ | Leetcode C++题解之第473题火柴拼正方形
题目: 题解: class Solution { public:bool makesquare(vector<int>& matchsticks) {int totalLen accumulate(matchsticks.begin(), matchsticks.end(), 0);if (totalLen % 4 ! 0) {return false;}int len totalLen / 4, n matchsticks.s…...

深度解析RLS(Recursive Least Squares)算法
目录 一、引言二、RLS算法的基本思想三、RLS算法的数学推导四、RLS算法的特点五、RLS算法的应用场景六、RLS算法的局限性七、总结 一、引言 在自适应滤波领域,LMS(Least Mean Squares)算法因其计算简单、实现方便而广受欢迎。然而࿰…...

Centos 7.9NFS搭建
原创作者:运维工程师 谢晋 Centos 7.9NFS搭建 NFS服务端安装客户机访问共享配置 NFS服务端安装 SSH连接系统登录到服务端安装nfs服务 # yum -y install nfs-utils2. 安装完成后,查看需要共享的目录,这边共享的是/home目录,如…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

DRG存档编辑器终极指南:如何快速解锁《深岩银河》的全部游戏体验
DRG存档编辑器终极指南:如何快速解锁《深岩银河》的全部游戏体验 【免费下载链接】DRG-Save-Editor Rock and stone! 项目地址: https://gitcode.com/gh_mirrors/dr/DRG-Save-Editor 还在为《深岩银河》中无尽的资源收集和等级提升感到疲惫吗?DRG…...

深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构
深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构 【免费下载链接】zenodo_get Zenodo_get: Downloader for Zenodo records 项目地址: https://gitcode.com/gh_mirrors/ze/zenodo_get 在科研数据管理领域,高效的数据下载工具…...

初创公司如何通过Taotoken快速为产品原型注入多种AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken快速为产品原型注入多种AI能力 对于初创公司而言,资源有限、时间紧迫是常态。产品原型的快速…...