Mamba学习笔记(3)—S4原理基础
文章目录
- Efficiently Modeling Long Sequences with Structured State Spaces
- 0 Abstract
- 1 Introduction
- 2 Background:State Spaces
- 2.1 State Space Models: A Continuous-time Latent State Model
- 2.2 Addressing Long-Range Dependencies with HiPPO
- 2.3 Discrete-time SSM: The Recurrent Representation
- 2.4 Training SSMs: The Convolutional Representation
- 3 Method: Structured State Spaces (S4)
- 3.1 Motivation: Diagonalization
- 3.2 The S4 Parameterization: Normal Plus Low-Rank
- 3.3 S4 Algorithms and Computational Complexity
- 3.4 Architecture Details of the Deep S4 Layer
👇👇👇👇👇💕💕💕💕💕👇👇👇👇👇
团队公众号 Deep Mapping致力于为大家分享人工智能算法的基本原理与最新进展,探索深度学习与测绘行业的创新结合,展示团队的最新研究成果,并及时报道行业会议动态。每周更新,持续为你带来前沿科技资讯、实用技巧和深入解读。感谢每一位关注我们的读者,期待与大家一起见证更多精彩时刻!
👇👇👇👇👇💕💕💕💕💕👇👇👇👇👇

Efficiently Modeling Long Sequences with Structured State Spaces
Author:Albert Gu, Karan Goel, and Christopher R´ [github] [arXiv]
Structured State Space sequence model (S4)
S4模型通过对SSM状态矩阵A的重新参数化(加入低秩校正项)解决了计算瓶颈。这样做能够稳定地对A进行对角化,并将SSM的计算简化为较为高效的Cauchy核计算。结果是S4相比之前的模型在计算效率上提升了30倍,内存使用减少了400倍。
0 Abstract
序列建模的核心目标是设计一个能够处理多模态和任务中的序列数据的通用模型,特别是在长距离依赖(LRD)问题上。尽管包括RNN、CNN和Transformer在内的传统模型都有专门的变体用于捕捉长距离依赖,但它们在处理超过1万步的超长序列时依然存在困难。最近的一个有前景的方法提出通过模拟基本的状态空间模型(SSM)来进行序列建模。该方法表明,经过适当选择状态矩阵A,这个系统在数学上和实验上能够处理长距离依赖。然而,这种方法的计算和内存需求过于庞大,无法作为通用的序列建模解决方案。我们提出了一种基于SSM的新参数化的结构化状态空间序列模型(S4),并展示了它在保持理论优势的同时,比先前的方法计算效率更高。我们的技术涉及通过低秩修正对矩阵A进行条件化,使其能够稳定地对角化,并将SSM简化为一个研究充分的Cauchy核计算。S4在多个广泛使用的基准测试中取得了强劲的实验结果,包括(i) 在没有数据增强或辅助损失的情况下,S4在顺序CIFAR-10数据集上达到了91%的准确率,与较大的2-D ResNet模型表现相当;(ii) 在图像和语言建模任务中,S4大大缩小了与Transformer模型的差距,同时在生成任务中速度快了60倍;(iii) S4在所有来自长距离竞技场(Long Range Arena)基准测试的任务中均取得了最新的最先进(SoTA)结果,包括成功解决了长度为16k的Path-X任务,所有之前的工作在该任务上均失败了,而S4的效率与所有竞争对手相当。
- 目标:设计一个能够高效处理长距离依赖(LRD)的通用序列模型。
- 问题:现有的模型(如RNN、CNN、Transformer)在处理超过1万步的长序列时存在计算和内存瓶颈。
- 解决方案:提出了Structured State Space sequence model (S4),通过重新参数化state space model(SSM),实现了对状态矩阵的高效对角化,并简化为Cauchy核的计算,解决了计算瓶颈问题。
- 实验结果:-在CIFAR-10上取得了91%的准确率,接近更大模型的性能;在图像和语言建模任务中,生成速度快了60倍;在LRA基准测试中取得了所有任务的最新最先进(SoTA)结果。
1 Introduction

SSM (状态空间模型) 的基本思想是通过状态矩阵
A、输入矩阵B、输出矩阵C和可能的直接输入输出连接矩阵D,将输入信号转换为一个隐藏的状态表示,然后再输出信号。
- 状态更新方程:
𝑥′(𝑡)=𝐴𝑥(𝑡)+𝐵𝑢(𝑡)- 输出方程:
𝑦(𝑡)=𝐶𝑥(𝑡)+𝐷𝑢(𝑡)- 其中
𝑥(𝑡)表示内部状态,𝑢(𝑡)表示输入信号,y(𝑡)表示输出信号,A、B、C、D分别是系统的参数矩阵。通过这些方程,输入信号u(𝑡)通过状态𝑥(𝑡)的更新影响输出y(𝑡)
序列建模中的一个核心问题是如何高效处理包含long-range dependencies(LRD)的数据。现实世界中的时间序列数据通常需要在数万个时间步上进行推理,而很少有序列模型能够应对数千个时间步。例如,long-range arena(LRA)基准测试的结果表明,当前的序列模型在LRD任务上的表现很差,包括一个名为Path-X的任务,所有模型的表现都不如随机猜测。由于LRD可能是序列模型面临的最大挑战,所有标准模型(如连续时间模型CTM、RNN、CNN和Transformer)都包含许多专门设计用于解决这个问题的变体。例如为应对梯度消失问题设计的正交和Lipschitz RNN,通过扩展卷积来增加上下文大小的膨胀卷积,以及不断扩展的高效Transformer家族,它们减少了序列长度上的二次依赖。尽管这些方案是为了解决LRD设计的,但它们在诸如LRA或原始音频分类等具有挑战性的基准测试上仍表现不佳。
最近,基于状态空间模型(SSM)提出了一种处理长距离依赖(LRD)的替代方法。SSM是一种基础的科学模型,广泛应用于控制理论、计算神经科学等领域,但由于具体的理论原因,它们尚未应用于深度学习。特别是,Gu等人表明,深度SSM在简单任务上甚至表现不佳,但当配备了最近为解决连续时间记忆问题而推导出的特殊状态矩阵A时,其表现异常出色。他们的Linear State Space Layer(LSSL)从概念上统一了CTM、RNN和CNN模型的优点,并证明了深度SSM原则上能够解决LRD问题。
SSM如何解决LRD? 通过其状态矩阵 A 处理长时间序列中的信息。
然而,LSSL在实际中无法使用,因为状态表示引发的计算和内存需求过于庞大。对于状态维度为N、序列长度为L的情况,计算隐状态需要O(N²L)的操作量和O(NL)的空间,而这相比于两者的下限Ω(L + N)要高得多。因此,对于合理大小的模型(如N = 256),LSSL的内存使用比同等大小的RNN或CNN高出几个数量级。尽管为LSSL提出了理论上高效的算法,但我们发现这些算法在数值上不稳定。特别是,特殊的A矩阵在线性代数意义上高度非正态,这阻止了传统算法技术的应用。因此,尽管LSSL表明SSM具有强大的性能,但目前它在作为通用序列建模解决方案时在计算上是不切实际的。
在本研究中,我们提出了基于SSM的结构化状态空间(S4)序列模型,该模型解决了之前工作中的关键计算瓶颈。在技术上,S4通过将Gu等人和Voelker等人中的结构化状态矩阵A重新参数化,将其分解为低秩项和正态项的和。此外,我们没有在系数空间中展开标准的SSM,而是在频率空间中计算其截断的生成函数,这可以简化为类多极点的评估。结合这两个想法,我们证明了可以通过Woodbury恒等式修正低秩项,而正态项则可以稳定地对角化,最终简化为一个研究充分且理论上稳定的Cauchy核。这使得计算复杂度达到Õ(N + L),内存使用为O(N + L),这对于序列模型来说是非常紧凑的。与LSSL相比,S4的计算速度快了30倍,内存使用减少了400倍,同时在实验上超越了LSSL的表现。
在实际应用中,S4显著提升了LRD任务的最新技术水平。在针对高效序列模型的LRA基准测试中,S4的速度与所有基线模型一样快,但平均表现高出20多个百分点。S4是第一个成功解决难度极大的LRA Path-X任务(长度为16384)的模型,达到了88%的准确率,而之前所有的模型只能达到50%的随机猜测水平。在长度为16000的语音分类任务中,S4将专门的语音CNN的测试误差减少了一半(1.7%),相比之下,所有的RNN和Transformer基线模型都未能学习到有效模型(错误率≥70%)。
Towards a general-purpose sequence model。除了LRD之外,机器学习的一个广泛目标是开发一个可以用于解决各种问题的通用模型。如今的模型通常是针对特定领域的问题(如图像、音频、文本、时间序列)进行专门化设计,并且只具备有限的能力(如高效训练、快速生成、处理不规则采样的数据)。这种专门化通常通过领域特定的预处理、归纳偏置和架构体现出来。序列模型提供了一种通用框架,可以在减少专门化的情况下解决许多这些问题——例如,Vision Transformers在图像分类中使用较少的二维信息。然而,大多数模型如Transformers仍然需要针对每个任务进行大量的专门化设计,才能实现高性能。
深度SSM特别具有一些概念上的优势,表明它们可能是一个有前途的通用序列建模解决方案。这些优势包括一种处理LRD的理论方法,以及在连续时间、卷积和循环模型表示之间切换的能力,每种表示都有不同的功能。我们的技术贡献使SSM能够在仅需最少修改的情况下成功应用于各种基准测试:
- 大规模生成建模。在CIFAR-10密度估计任务中,S4与最佳的自回归模型相媲美(每维2.85比特)。在WikiText-103语言建模任务中,S4显著缩小了与Transformers的差距(差距在0.8 perplexity以内),为无需注意力机制的模型设立了新的最先进(SoTA)标准。
- 快速自回归生成:与RNN类似,S4可以利用其隐状态,在CIFAR-10和WikiText-103上实现比标准自回归模型快60倍的像素/标记生成速度。
- 采样分辨率变化:类似于专门的CTM模型,S4可以适应时间序列采样频率的变化而无需重新训练,例如在语音分类中以0.5倍频率进行。
- 较弱归纳偏置的学习:在无需任何架构更改的情况下,S4在语音分类任务中超越了Speech CNNs,在时间序列预测问题上表现优于专门的Informer模型,并在顺序CIFAR任务中达到超过90%的准确率,与2-D ResNet相匹配。
表示形式的转换
- 连续时间表示:适用于持续时间序列的建模,如物理系统的动态。
- 卷积表示:用于并行处理数据,适合高效训练。
- 循环表示:可以有效处理依赖于前一个时间步的序列,适合递归神经网络的应用。
2 Background:State Spaces
第2.1节到第2.4节描述了图1中SSM的四个特性:经典的连续时间表示、使用HiPPO框架处理LRD、离散时间的循环表示以及可并行化的卷积表示。特别是,第2.4节介绍了SSM卷积核 K,这是第3节中理论贡献的重点。
2.1 State Space Models: A Continuous-time Latent State Model
在生成一维输出y(𝑡)前,输入信号𝑢(𝑡)会先映射到一个N-D (N维)的Latent状态𝑥(𝑡):
𝑥′(𝑡)=𝐴𝑥(𝑡)+𝐵𝑢(𝑡)
𝑦(𝑡)=𝐶𝑥(𝑡)+𝐷𝑢(𝑡)
SSM广泛用于许多科学领域,并与潜在状态模型(如隐马尔可夫模型)相关联。我们的目标是简单地将SSM作为深度序列模型中的一个黑箱表示,其中 A,B,C,D是通过梯度下降学习的参数。为了简化后续部分的讨论,我们将忽略参数D(D=0)因为项𝐷𝑢可以看做一个跳跃连接,并且计算简单。
2.2 Addressing Long-Range Dependencies with HiPPO
之前的研究发现,基本的SSM在实际应用中表现非常差。直观地说,一个解释是线性一阶常微分方程的解是指数函数,因此在序列长度上,梯度可能呈指数级缩放(即梯度消失/爆炸问题)。为了应对这个问题,LSSL利用了HiPPO连续时间记忆理论。HiPPO规定了一类特定的矩阵A,当将这些矩阵纳入到SSM中时,能够让状态𝑥(𝑡)记住输入𝑢(𝑡)的历史。我们称之为HiPPO矩阵。例如,LSSL发现仅仅将SSM中的随机矩阵 A修改为公式(2)中的矩阵,就可以将其在顺序MNIST基准测试中的表现从60%提高到98%。
HiPPO连续时间记忆理论(HiPPO: High-order Polynomial Projection Operator) 是一种处理连续时间记忆的框架。它的目标是通过数学理论解决序列建模中的LRD,即如何在长时间序列中有效地记忆和处理过去的输入信息。
- HiPPO理论定义了一类特殊的状态矩阵
A,通过投影方法,使得SSM的状态能够记住输入序列的历史。A是一个特殊的上三角矩阵,这个矩阵的主要特点是它具备递减的记忆模式,也就是说,较大的索引n会以较大的权重保存较早的信息,而较小的索引则更多地反映较近的输入。通过这种设计,SSM能够以一种渐进的方式“记住”不同时间段的输入信息,并且这种记忆能力不会像普通的RNN那样随时间步长增加而迅速衰减(即梯度消失)。
A矩阵的特点
- 上三角阵:该矩阵的结构是上三角形式,这意味着只有当
n≥k时,矩阵的非零元素才存在。它体现了输入信号在时间维度上对模型状态的影响是递减的。- 权重衰减:矩阵的权重随着时间(索引
n增加)而衰减,这帮助模型保持远处的记忆,但不会让这些记忆压倒当前的信息。- 连续时间记忆:该矩阵设计用于模拟连续时间中的记忆过程,因此在处理连续信号时,能够有效记住输入历史。
LSSL(Linear State Space Layer)
LSSL是基于HiPPO理论的深度状态空间模型(SSM)的实现方式。它将HiPPO的理论应用于深度学习模型中,通过状态矩阵A的特殊设计,使得SSM能够更好地处理长时间序列中的信息。
- 当
n>k时,矩阵𝐴中的元素𝐴𝑛𝑘是负的平方根形式。这个负号表明早起输入对于当前状态的影响是递减的,符号的选择可能是为了避免梯度爆炸或者维持特定的稳定性。平方根部分的数值随着n和k的增大而增大,这种设计可以确保随着时间步的增加,较早的输入信息不会被遗忘,同时这些较早的信息在后续的时间步中能起到重要作用。- 当
n=k时,Ann =−(n+1)这表示当前时间步状态对自身的影响。负号表明当前状态倾向于对之前的状态做出抑制或修正,从而避免累积过多的历史信息,导致模型过度关注过早的输入。- 当
n<k时,𝐴的元素为0,表示未来的时间步不会影响过去的状态更新,这符合因果关系,即当前的输入或状态只会受到过去的信息影响。

2.3 Discrete-time SSM: The Recurrent Representation
为了应用于离散输入序列 (𝑢0,𝑢1,…)而不是连续函数u(t)公式 (1) 必须通过步长Δ进行离散化,该步长代表输入的分辨率。概念上,输入uk可以被视为对一个隐含的连续信号u(t)的采样,其中uk=u(kΔ)。
为了对连续时间的SSM进行离散化,我们遵循之前的研究,使用双线性法(bilinear method)将状态矩阵𝐴转换为近似矩阵A~。离散的SSM如下:

公式(3)现在是一个序列到序列的映射uk→yk,而不是函数到函数的映射。此外,状态方程现在是xk的递推形式,因此可以像RNN一样计算离散的SSM。在整个本文中,我们使用~来表示由公式(3)定义的离散化的SSM矩阵。注意,这些矩阵不仅仅是A的函数,还与步长Δ有关。
连续时间与离散时间的转换
原始的SSM通常是用来处理连续时间信号的,这意味着它们通过一组微分方程来描述状态的变化。然而,在实际的计算中,尤其是处理数字信号时,我们需要将这些连续时间的方程转换为离散时间版本,以便能够处理离散的输入序列(如时间步数为离散的序列数据)。
双线性法(bilinear method)
离散化的过程使用了双线性法。该方法的目标是将连续时间的状态矩阵𝐴转换为近似矩阵A~:
𝐴是连续时间SSM中的状态矩阵,代表状态的变化规律,I是单位阵,Δ是步长,代表离散时间序列的分辨率。每个离散时间步𝑘可以看做是采样连续时间信号u(t)的结果uk=u(kΔ)。这种离散化方法在信号处理领域中被广泛应用,因为它能够在时间步上的计算中保持较好的精度和稳定性。

递归关系
通过这种离散化,我们把连续时间的状态方程转换为了递归方程。新的离散化公式如下:
这意味着状态xk通过前一个时间步的状态xk-1和当前的输入uk递推计算的。这样的递归关系类似于RNN的更新机制,每个时间步依赖于上一个时间步的信息。

输出方程
- 输出方程同样经过离散化,表示为:
即在离散时间步k上的输出yk是由当前状态xk通过矩阵C~进行线性变换得到的。这个形式与连续时间方程形式类似,但现在是针对离散的输入和状态。

步长
Δ的作用 决定了离散时间序列中的采样密度
- Δ
小,时间分辨率高,细节信息多- Δ
大,时间分辨率低,细节信息少
2.4 Training SSMs: The Convolutional Representation
递归SSM(公式3)由于其顺序性而不适合在现代硬件上进行训练。因此,线性时不变(LTI)SSM(如公式1)与连续卷积之间存在一种广为人知的联系。相应地,公式(3)实际上可以写成离散卷积的形式。
为简单起见,假设初始状态x−1=0,那么公式(3)展开后得到:
这一过程可以被向量化为一个卷积(公式4),其中卷积核的显式公式为(公式5):
卷积核K定义为:
换句话说,公式(4)是一个单次(非循环的)卷积,如果已知K,则可以通过快速傅里叶变换(FFT)非常高效地计算。然而,计算公式(5)中的K并不简单,这是我们在第3节中的理论贡献的重点。我们将K称为SSM卷积核或滤波器。



3 Method: Structured State Spaces (S4)
我们的技术成果主要集中在开发S4的参数化,并展示如何高效地计算SSM的所有视图(第2节):即连续表示(A, B, C)(公式1)、循环表示(A~, B~, C~)(公式3)和卷积表示K(公式4)。第3.1节解释了我们方法的动机,基于线性代数中的共轭和对角化概念,并讨论了为什么这种方法的简单应用不起作用。第3.2节概述了我们方法的关键技术组件,并正式定义了S4的参数化。第3.3节概述了主要结果,表明S4在序列模型中具有渐进效率(最多只含对数因子)。证明详见附录B和C。
3.1 Motivation: Diagonalization
计算离散时间SSM(公式3)的根本瓶颈在于它涉及对矩阵A进行重复的矩阵乘法。例如,像在LSSL中那样天真地计算公式(5),需要对A进行连续L次乘法,这需要O(N^2L)的操作量,并且占用O(NL)的空间。为了解决这个瓶颈,我们使用了一个结构性结果,允许我们简化SSM的计算。
引理 3.1:共轭变换是SSM上的一个等价关系:
(A,B,C)∼(V^−1AV,V−1^B,CV)
证明:
- 写出两个SSM,状态分别为
𝑥和𝑥~:
将右边的SSM乘以V后,这两个SSM变得相同,且有x=Vx~。因此,这两个SSM计算出相同的操作u→y,只是在状态x上有一个由V引起的基变换。

引理 3.1 表明,通过共轭变换可以将矩阵A转化为一种更规范的形式,这样计算起来会更加高效。比如,如果A是对角矩阵,那么计算就变得更加可处理。特别是,所需的卷积核K(公式4)将成为一个范德蒙德(Vandermonde)乘积,理论上只需要O((N+L)log2(N+L))的运算。
不幸的是,天真的对角化应用并不可行,因为它存在数值问题。我们推导出了HiPPO矩阵(公式2)的显式对角化,结果发现其元素在状态维度N上呈指数增长,使得该对角化在数值上不可行(例如,无法计算引理3.1中的CV)。我们注意到Gu等人提出了一种不同的(未实现的)算法,能够比天真算法更快地计算K。在附录B中,我们证明了它由于类似的原因在数值上也是不稳定的。
引理 3.2:HiPPO矩阵
A(公式2)由矩阵Vij对角化:
特别的
因此,矩阵𝑉的元素数量级可达2^4N/3


3.2 The S4 Parameterization: Normal Plus Low-Rank

前面的讨论表明,我们只应该通过良好条件的矩阵V进行共轭变换。理想的情况是当矩阵A由一个条件良好的(即,酉矩阵)对角化矩阵进行共轭时。根据线性代数的谱定理,这正是正态矩阵的类别。然而,这类矩阵的限制较多,特别是它不包括HiPPO矩阵(公式2)。
我们观察到,虽然HiPPO矩阵不是正态的,但它可以分解为一个正态矩阵和一个低秩矩阵的和。然而,仅此不足以直接解决问题:与对角矩阵不同,这样的矩阵求幂(如在公式5中)仍然较慢,并且不易优化。我们通过同时应用以下三项新技术克服了这一瓶颈。
(1) 频域生成函数:我们并不直接计算卷积核
K,而是通过计算其截断生成函数来得到K的频谱。之后,我们可以通过逆傅里叶变换(iFFT)高效地获得K

(2) Woodbury公式修正低秩项:生成函数涉及矩阵逆操作,低秩项可以通过应用Woodbury公式得到修正,即将
(A+PQ∗)^−1表示为A^−1的低秩校正,从而真正减少到对角化的情况。
(3)Cauchy核的计算:我们展示了对角矩阵情形等同于Cauchy核计算,这是一个已被充分研究的问题,具有稳定的近线性算法。

我们的技术可以应用于任何能够分解为正态加低秩(NPLR)的矩阵。
定理1:所有的HiPPO矩阵都具有NPLR分解形式:
其中,V是酉矩阵,Λ是对角矩阵,P,Q是低秩分解,HiPPO矩阵(如LegS、LegT、LagT)都满足r=1 or r=2。特别地,公式(2)中的矩阵是r=1的NPLR矩阵。

3.3 S4 Algorithms and Computational Complexity

根据公式(6),注意到NPLR矩阵可以共轭转化为对角加低秩(DPLR)形式(此时是复数域C上的,而不是实数域R)。定理2和定理3描述了当矩阵A为DPLR形式时,SSM(状态空间模型)的复杂度。S4在递归和卷积表示上均表现出最优或接近最优的性能。
定理2(S4递归):给定任意步长∆,计算递归公式(3)的一步可以在O(N)运算内完成,其中N为状态大小。定理2源于一个事实,即DPLR矩阵的逆也是DPLR矩阵(例如,通过Woodbury公式也可以证明)。这意味着离散化后的矩阵A是两个DPLR矩阵的乘积,因此矩阵-向量乘法的复杂度为O(N)。附录C.2计算了A的封闭形式的DPLR表示。
定理3(S4卷积):给定任意步长∆,计算SSM卷积滤波器K可以化简为4次Cauchy矩阵乘法,仅需O(N + L)运算和O(N + L)空间。附录C中定义3正式定义了Cauchy矩阵,这与有理插值问题有关。Cauchy矩阵的计算在数值分析中是一个非常成熟的问题,快速多极子方法(FMM)[29, 30, 31]提供了快速的算术和数值算法。附录C的命题5描述了这些算法在各种条件下的计算复杂度。
我们重申,定理3是我们的核心技术贡献,它的算法是NPLR S4参数化的直接动机。算法1中正式勾画了该算法的框架。
3.4 Architecture Details of the Deep S4 Layer
具体来说,S4层的参数化过程如下。首先初始化一个状态空间模型(SSM),令矩阵A为HiPPO矩阵(2)。根据引理3.1和定理1,该SSM与某个(Λ − PQ∗,B,C)在单位酉变换下等价,其中Λ为对角矩阵,P、Q、B、C为复数域CN×1中的向量。这些向量构成了S4的5N个可训练参数。
S4的整体深度神经网络(DNN)架构与先前的工作类似。如前所述,S4定义了一个从RL到RL的映射,即一个一维序列映射。通常,DNN在特征图的大小为H(而不是1)上进行操作。S4通过简单地定义H个独立副本来处理多个特征,然后通过位置线性层对H个特征进行混合,每层总共具有O(H²) + O(HN)个参数。非线性激活函数也插入在这些层之间。
总体而言,S4定义了一个形状为(批量大小、序列长度、隐藏维度)的序列到序列映射,与类似的序列模型如Transformers、RNNs和CNNs完全相同。需要注意的是,S4核心模块是一个线性变换,但通过网络深度中的非线性变换的添加,使得整体深度SSM变为非线性。这类似于普通的CNN,因为卷积层也是线性的。这里对H个隐藏特征的广播过程类似于深度可分离卷积。因此,整体的深度S4模型与具有全局卷积核的深度可分离CNN密切相关。
最后,我们注意到后续的研究发现,当矩阵A的特征值位于复平面的右半平面时,这个版本的S4有时会出现数值不稳定性。为了解决这一潜在问题,研究引入了对S4的NPLR参数化的轻微改动,将Λ−PQ∗改为Λ−PP∗。
相关文章:
Mamba学习笔记(3)—S4原理基础
文章目录 Efficiently Modeling Long Sequences with Structured State Spaces0 Abstract1 Introduction2 Background:State Spaces2.1 State Space Models: A Continuous-time Latent State Model2.2 Addressing Long-Range Dependencies with HiPPO2.3 Discrete-t…...
好看的ppt字体推荐!分享3个制作幻灯片的常用软件!
ppt什么字体好看? 好看是一个比较主观的概念,见仁见智,在选用ppt字体时,比起关注好看,字体是否“合适”应该是优先级更高的需求。这里的合适,即PPT所选用字体的风格、呈现效果是否与PPT的主题和使用场景相…...

第6篇:无线与移动网络
目录 引言 6.1 无线网络的基础概念 6.2 无线局域网(WLAN)与IEEE 802.11 6.3 蓝牙与无线个域网(WPAN) 6.4 无线城域网(WMAN)与WiMax 6.5 ZigBee与智能家居 6.6 移动蜂窝网络(3G/4G/5G&…...

【C++标准模版库】unordered_map和unordered_set的介绍及使用
unordered_map和unordered_set 一.unordered_set1.unordered_set类的介绍2.unordered_set和set的使用差异 二.unordered_map1.unordered_map和map的使用差异 三.unordered_multimap/unordered_multiset四.unordered_map/unordered_set的哈希相关接口 一.unordered_set 1.unord…...
深度解析Transformer:从自注意力到MLP的工作机制
深度解析Transformer:从自注意力到MLP的工作机制 以下大部分内容本来自对3Blue1Brown的视频讲解的整理组织 一、Transformer的目标 为了简化问题,这里讨论的模型目标是接受一段文本,预测下一个词。这种任务对模型提出了两大要求:…...

《米小圈动画成语》|在趣味中学习,在快乐中掌握成语知识!
作为一名家长,我一直希望孩子能够在学习的过程中既感受到乐趣,又能获得真正的知识。成语作为中华文化的精华,虽然意义深远、简洁凝练,但对于一个小学生来说,学习和理解这些言简意赅的成语无疑是一个挑战。尤其是有些成…...

linux系统之jar启动脚本
编辑linux启动脚本 执行 vi run_blog 按i 进入编辑,复制以下代码,并根据当前环境修改三个参数。以下是详细完整脚本代码: #!/bin/bash# 配置部分 JAR_PATH"/path/to/your/app.jar" # 替换为你的 JAR 文件的实际路径 L…...

简单认识Maven 2-Maven坐标
Maven坐标 在 Maven 中,坐标(Coordinates)用于唯一标识一个项目或依赖项,就像在现实世界中通过经纬度来确定一个地理位置一样。Maven 坐标由三个主要部分组成:groupId、artifactId 和 version。 groupId(…...

Xilinx UltraScale系列FPGA纯verilog图像缩放,工程项目解决方案,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明FPGA高端图像处理培训 2、相关方案推荐我这里已有的FPGA图像缩放方案本方案在Xilinx Artix7 系列FPGA上的应用本方案在Xilinx Kintex7 系列FPGA上的应用本方案在Xilinx Zynq7000 系列FPGA上的应用本方案在国产FPGA紫光同创系列上的应用本方案在国产…...

React(二) JSX中的this绑定问题;事件对象参数传递;条件渲染;列表渲染;JSX本质;购物车案例
文章目录 一、jsx事件绑定1. 回顾this的绑定方式2. jsx中的this绑定问题(1) 方式一:bind绑定(2) 方式二:使用 ES6 class fields 语法(3) 方式三:直接传入一个箭头函数(重要) 3.事件参数传递(1) 传递事件对象event(2) 传递其他参数 4. 事件绑定…...

前端开发攻略---取消已经发出但是还未响应的网络请求
目录 注意: 1、Axios实现 2、Fetch实现 3、XHR实现 注意: 当请求被取消时,只会本地停止处理此次请求,服务器仍然可能已经接收到了并处理了该请求。开发时应当及时和后端进行友好沟通。 1、Axios实现 <!DOCTYPE html> &…...

韩信走马分油c++
韩信走马分油c 题目算法代码 题目 把油桶里还剩下的10斤油平分,只有一个能装3斤的油葫芦和一个能装7斤的瓦罐。如何分。 算法 油壶编号0,1,2。不同倒法有:把油从0倒进0(本壶到本壶,无效)&…...

【Linux】Anaconda下载安装配置Pytorch安装配置(保姆级)
目录 Anaconda下载 Anaconda安装 conda init conda --v Conda 配置 conda 环境创建 conda info --envs conda list Pytorch安装配置 检验安装情况 检验是否可以使用GPU Anaconda下载 可以通过两种途径完成Anaconda安装包的下载 途径一:本地windows下…...

渗透测试导论
渗透测试的定义和目的 渗透测试(Penetration Testing)是一项安全演习,网络安全专家尝试查找和利用计算机系统中的漏洞。 模拟攻击的目的是识别攻击者可以利用的系统防御中的薄弱环节。 这就像银行雇用别人假装盗匪,让他们试图闯…...

鸿蒙学习笔记--搭建开发环境及Hello World
文章目录 一、概述二、开发工具下载安装2.1 下载开发工具DevEco Studio NEXT2.2 安装DevEco Studio 三、启动软件四、第一个应用Hello World4.1 创建应用4.2 创建模拟器4.3 开启Hyper-v功能4.4 启动虚拟机 剑子仙迹 诗号:何须剑道争锋?千人指,…...

【ArcGIS风暴】ArcGIS字段计算器公式汇总
在GIS数据处理中,ArcGIS的字段计算器是一个强大的工具,它可以帮助我们进行各种数值计算、文本处理和逻辑判断。本文将为您整合和分类介绍ArcGIS字段计算器中的常用公式,并通过实例说明它们的应用。 文章目录 一、数值计算类二、文本处理类三、日期和时间类四、逻辑判断类五、…...
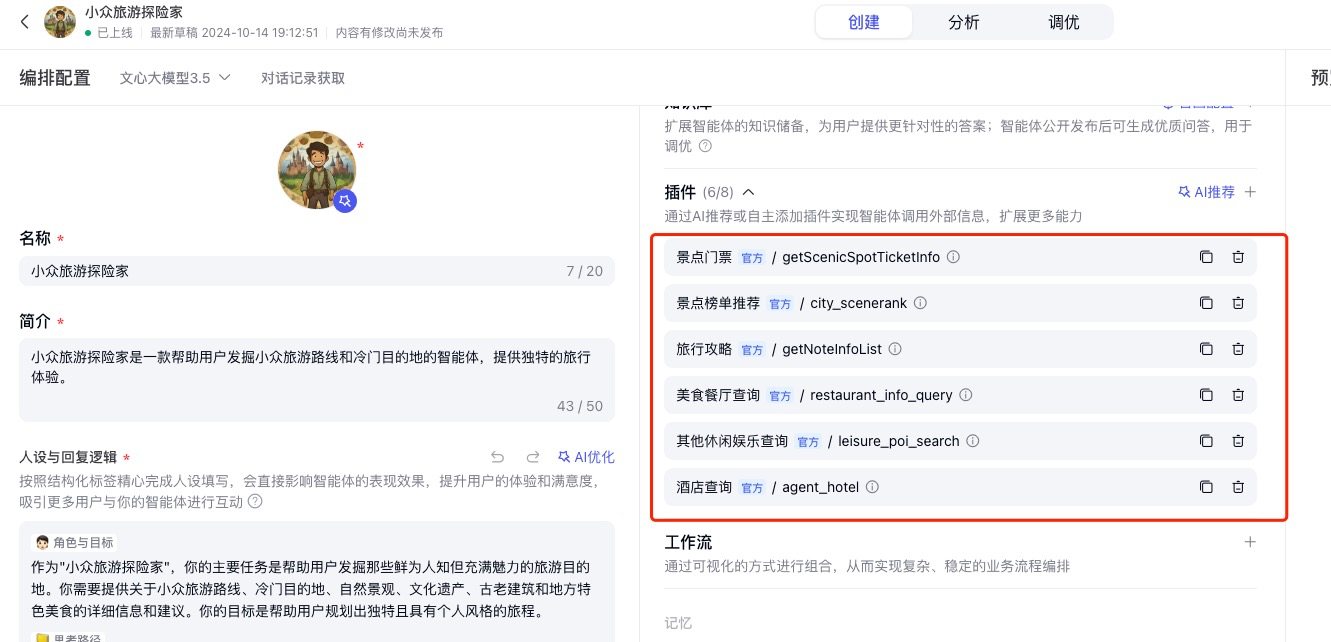
探索秘境:如何使用智能体插件打造专属的小众旅游助手『小众旅游探险家』
文章目录 摘要引言智能体介绍和亮点展示介绍亮点展示 已发布智能体运行效果智能体创意想法创意想法创意实现路径拆解 如何制作智能体可能会遇到的几个问题快速调优指南总结未来展望 摘要 本文将详细介绍如何使用智能体平台开发一款名为“小众旅游探险家”的旅游智能体。通过这…...
)
机械臂力控方法概述(一)
目录 1. MoveIt 适用范围 2. 力控制框架与 MoveIt 的区别 3. 力控方法 3.1 直接力控制 (Direct Force Control) 3.2 间接力控制 (Indirect Force Control) 3.2.1 柔顺控制 (Compliant Control) 3.2.2 阻抗控制 (Impedance Control) 3.2.3 导纳控制 (Admittance Control…...

1971. 寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接&#x…...
)
FLINK SQL语法(1)
DDL Flink SQL DDL(Data Definition Language)是Flink SQL中用于定义和管理数据结构和数据库对象的语法。以下是对Flink SQL DDL的详细解析: 一、创建数据库(CREATE DATABASE) 语法:CREATE DATABASE [IF…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...

从脚本到系统:设计一个支持插件、限流、重试与监控的 Python 异步爬虫框架
从脚本到系统:设计一个支持插件、限流、重试与监控的 Python 异步爬虫框架 很多人第一次写 Python 爬虫,都是从几十行脚本开始的:requests.get()、BeautifulSoup、for 循环、保存 CSV。它很快,也很有成就感。但真实项目往往不是“…...

从‘找不到dll’到流畅运行:一份给VS2022新手的Zbar+OpenCV3.6.0环境配置避坑指南
从“找不到dll”到流畅运行:VS2022下ZbarOpenCV3.6.0环境配置全解析 当你第一次在Visual Studio 2022中尝试整合Zbar和OpenCV 3.6.0时,可能会遇到各种令人沮丧的错误提示。最常见的就是那个让人头疼的“找不到libzbar64-0.dll”问题。本文将带你一步步解…...