科大讯飞嵌入式面试题及参考答案
平衡二叉树和普通二叉树的区别
平衡二叉树是一种特殊的二叉树,与普通二叉树相比有以下显著区别:
一、定义与结构
- 普通二叉树:二叉树是每个节点最多有两个子树的树结构。它没有特定的平衡要求,节点的分布可能比较随机。例如,可能出现一条分支很长而另一条分支很短的情况。
- 平衡二叉树:平衡二叉树又称为 AVL 树。它是一种二叉搜索树,其中每个节点的左子树和右子树的高度差至多为 1。这意味着平衡二叉树的结构相对更加规整,能够保证在进行插入、删除等操作后,树的高度始终保持在相对较低的水平。
二、性能特点
- 查找性能:对于普通二叉树,在最坏的情况下,查找操作可能需要遍历树的所有节点,时间复杂度为 O (n),其中 n 是树中节点的数量。而平衡二叉树由于其高度相对较低,查找操作的时间复杂度始终为 O (log n),大大提高了查找效率。
- 插入和删除操作:在普通二叉树中进行插入和删除操作可能会导致树的结构严重失衡,从而影响后续操作的性能。而平衡二叉树在进行插入和删除操作时,会通过旋转等操作来保持树的平衡性,确保树的高度不会急剧增加,从而保证操作的高效性。
三、应用场景
- 普通二叉树:在一些对性能要求不高或者数据分布比较随机的场景中可以使用。例如,简单的二叉树遍历算法演示、小型数据集合的存储等。
- 平衡二叉树:在需要高效查找、插入和删除操作的场景中非常适用。比如数据库索引结构、文件系统的目录结构等,这些场景中需要快速定位数据,并且数据的频繁插入和删除操作不能导致性能急剧下降。
口述冒泡排序
冒泡排序是一种简单的排序算法。它通过重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
具体步骤如下:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一趟比较完成后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
例如,对数列 [5, 3, 8, 4, 2] 进行冒泡排序:
- 第一次遍历:比较 5 和 3,交换得到 [3, 5, 8, 4, 2];比较 5 和 8,不交换;比较 8 和 4,交换得到 [3, 5, 4, 8, 2];比较 8 和 2,交换得到 [3, 5, 4, 2, 8]。此时最大的数 8 已在正确位置。
- 第二次遍历:比较 3 和 5,不交换;比较 5 和 4,交换得到 [3, 4, 5, 2, 8];比较 5 和 2,交换得到 [3, 4, 2, 5, 8]。
- 第三次遍历:比较 3 和 4,不交换;比较 4 和 2,交换得到 [3, 2, 4, 5, 8]。
- 第四次遍历:比较 3 和 2,交换得到 [2, 3, 4, 5, 8]。至此,数列已排序完成。
冒泡排序的优点是简单易懂,容易实现。缺点是效率相对较低,当数据规模较大时,排序时间会很长。
口述快速排序
快速排序是一种高效的排序算法。它采用分治的思想,将一个数列分成两个子数列,然后分别对这两个子数列进行排序,最后将它们合并起来。
具体步骤如下:
- 选择一个基准值。通常选择数列的第一个元素、最后一个元素或者中间元素作为基准值。
- 分区操作。将数列中小于基准值的元素放在基准值的左边,大于基准值的元素放在基准值的右边。这个过程可以通过遍历数列,使用两个指针来实现。
- 对左右两个子数列分别递归地进行快速排序。
例如,对数列 [5, 3, 8, 4, 2] 进行快速排序:
- 选择基准值为 5。
- 分区操作:从数列的两端开始,设置两个指针 i 和 j,i 从左向右移动,j 从右向左移动。当 i 指向的元素小于等于基准值时,i 继续向右移动;当 j 指向的元素大于等于基准值时,j 继续向左移动。当 i 和 j 指向的元素满足交换条件时,交换它们。最终,i 和 j 相遇,将基准值与相遇位置的元素交换,得到 [3, 2, 4, 5, 8]。
- 对左右两个子数列 [3, 2, 4] 和 [8] 分别递归地进行快速排序。
快速排序的优点是效率高,在平均情况下时间复杂度为 O (n log n)。缺点是在最坏情况下,时间复杂度会退化为 O (n²),并且实现相对复杂一些。
内存泄漏如何排查
内存泄漏是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃。排查内存泄漏可以从以下几个方面入手:
一、代码审查
- 仔细检查程序中动态内存分配和释放的地方。确保在不再需要内存时,及时调用释放内存的函数,如在 C 语言中使用 free () 函数,在 C++ 中使用 delete 或 delete [] 操作符。
- 检查是否存在循环引用或长期持有不必要的资源的情况。例如,在某些面向对象的编程语言中,如果两个对象相互引用,而没有正确的释放机制,可能会导致内存泄漏。
二、使用内存分析工具
- 许多编程语言都有专门的内存分析工具。例如,在 C 和 C++ 中,可以使用 Valgrind 工具。Valgrind 可以检测出内存泄漏、非法内存访问等问题,并给出详细的报告,包括泄漏的位置和大小。
- 在 Java 中,可以使用一些商业或开源的内存分析工具,如 JProfiler、YourKit 等。这些工具可以跟踪对象的分配和释放,帮助定位内存泄漏的位置。
三、运行时监测
- 在程序运行过程中,可以监测内存使用情况。如果发现内存持续增长,而没有相应的释放,可能存在内存泄漏。可以通过操作系统提供的工具来监测进程的内存使用情况,如在 Linux 系统中可以使用 top、ps 等命令。
- 对于一些长时间运行的服务器程序,可以定期记录内存使用情况,以便发现内存泄漏的趋势。
malloc 和 new 的区别是什么
malloc 和 new 都是用于动态分配内存的操作,但它们在不同的编程语言中有不同的用法和特点。
一、C 语言中的 malloc
- malloc 是 C 语言标准库中的函数,用于在堆上动态分配一块指定大小的内存。它的原型是 void* malloc (size_t size),其中 size 表示要分配的内存大小。
- malloc 返回一个 void* 类型的指针,需要进行类型转换才能使用。例如,int* p = (int*) malloc (sizeof (int));
- malloc 只负责分配内存,不会对分配的内存进行初始化。如果需要初始化内存,可以使用 memset 等函数。
- 在 C 语言中,使用 malloc 分配的内存需要使用 free 函数来释放。
二、C++ 中的 new
- new 是 C++ 中的操作符,用于在堆上动态分配内存并调用对象的构造函数进行初始化。例如,int* p = new int; 会分配一块足够存储一个 int 类型的内存,并调用 int 的默认构造函数进行初始化。
- new 返回一个指向对象类型的指针,不需要进行类型转换。
- new 可以根据不同的参数进行多种形式的内存分配,例如可以分配数组、调用特定的构造函数等。
- 在 C++ 中,使用 new 分配的内存需要使用 delete 或 delete [] 操作符来释放,分别用于释放单个对象和数组。
三、总结
- 主要区别在于 new 是 C++ 的操作符,它不仅可以分配内存,还可以调用构造函数进行初始化,而 malloc 只是 C 语言中的函数,只负责分配内存,不进行初始化。
- new 返回的指针类型是对象类型,不需要进行类型转换,而 malloc 返回的是 void* 类型的指针,需要进行类型转换。
- 在内存释放方面,new 和 delete 是配对使用的,而 malloc 和 free 是配对使用的。
GDB 调试过程如何发现内存泄露
在使用 GDB 进行调试时,可以通过以下方法来发现内存泄漏:
一、设置观察点
- 在程序中可能发生内存分配和释放的关键位置设置观察点。例如,在 C 和 C++ 中,可以在 malloc、free、new、delete 等函数调用处设置断点或观察点。
- 当程序执行到这些位置时,GDB 会暂停程序的执行,可以查看内存分配和释放的情况。
二、监测内存使用情况
- 在程序运行过程中,可以使用 GDB 的命令来监测内存的使用情况。例如,可以使用 info proc mappings 命令查看进程的内存映射,了解程序使用的内存区域。
- 可以使用 watch 命令来监测特定内存地址的变化,例如监测一个指向动态分配内存的指针,看它是否被正确释放。
三、分析堆内存
- 如果程序使用了动态内存分配,如 malloc 或 new,可以使用 GDB 的堆分析工具来检查堆内存的使用情况。例如,在 C 和 C++ 中,可以使用 GDB 的 ptmalloc 扩展来分析堆内存的分配和释放情况。
- 可以使用命令如 heap analyze 来检查堆内存是否存在泄漏。
四、长期运行程序
- 对于一些长时间运行的程序,可以使用 GDB 进行长时间的调试,观察内存使用情况是否随着时间的推移而不断增加。如果内存持续增长,而没有相应的释放,可能存在内存泄漏。
python 内存管理和 C 内存管理的区别是什么
Python 和 C 是两种不同的编程语言,它们的内存管理方式有很大的区别。
一、C 语言的内存管理
- C 语言中,程序员需要手动管理内存。使用 malloc、calloc、realloc 等函数进行动态内存分配,使用 free 函数释放不再使用的内存。
- 如果程序员忘记释放内存,或者释放内存的顺序不正确,就会导致内存泄漏或内存错误。例如,访问已经释放的内存或者重复释放同一块内存都可能导致程序崩溃。
- C 语言中的内存管理需要程序员对内存的分配和释放有清晰的认识,并且需要小心处理各种可能出现的错误。
二、Python 的内存管理
- Python 使用自动内存管理机制,程序员不需要手动管理内存的分配和释放。Python 的解释器负责跟踪对象的引用计数,当对象的引用计数变为 0 时,解释器会自动回收该对象所占用的内存。
- Python 还使用了垃圾回收机制来处理循环引用等情况。当对象之间存在循环引用,导致引用计数无法变为 0 时,垃圾回收器会定期运行,检测并回收这些不可达的对象。
- Python 的内存管理机制使得程序员可以更加专注于程序的逻辑实现,而不需要过多地关注内存管理的细节。但是,这也可能导致一些性能问题,例如在处理大量对象时,垃圾回收器的运行可能会影响程序的性能。
三、总结
- 主要区别在于 C 语言需要程序员手动管理内存,而 Python 使用自动内存管理机制。
- C 语言的内存管理需要程序员小心处理各种可能出现的错误,而 Python 的内存管理机制相对更加安全和方便,但可能会带来一些性能问题。
编译过程是怎样的
编译过程是将高级编程语言转化为机器语言的过程,主要包括以下几个阶段:
一、词法分析
词法分析是编译过程的第一个阶段。在这个阶段,编译器会将源代码分解成一个个的记号(token),这些记号包括关键字、标识符、常量、运算符等。例如,对于 C 语言代码 “int a = 10;”,词法分析器会将其分解为 “int”(关键字)、“a”(标识符)、“=”(运算符)、“10”(常量)等记号。词法分析器通常使用有限自动机等技术来实现,它会逐个字符地读取源代码,并根据语言的语法规则识别出不同的记号。
二、语法分析
语法分析是编译过程的第二个阶段。在这个阶段,编译器会根据语言的语法规则,将词法分析阶段生成的记号组合成语法树(syntax tree)。语法树是一种树形结构,它表示了源代码的语法结构。例如,对于 C 语言代码 “int a = 10;”,语法分析器会生成一棵语法树,其中根节点表示整个语句,子节点分别表示 “int”(类型声明)、“a”(变量名)、“=”(赋值运算符)和 “10”(常量)。语法分析器通常使用上下文无关文法等技术来实现,它会根据语法规则逐步构建语法树。
三、语义分析
语义分析是编译过程的第三个阶段。在这个阶段,编译器会对语法分析阶段生成的语法树进行语义分析,检查代码的语义是否正确。语义分析包括类型检查、作用域检查、常量折叠等。例如,对于 C 语言代码 “int a = 10; a = 'a';”,语义分析器会发现第二次赋值操作将字符常量赋给整型变量,这是不合法的,会产生编译错误。语义分析器通常使用符号表等数据结构来记录变量的类型、作用域等信息,以便进行语义检查。
四、中间代码生成
中间代码生成是编译过程的第四个阶段。在这个阶段,编译器会将语义分析阶段生成的语法树转化为中间代码。中间代码是一种与机器无关的代码表示形式,它通常比源代码更接近机器语言,但又比机器语言更容易进行优化。中间代码的形式有很多种,例如三地址码、四元式、树形表示等。例如,对于 C 语言代码 “int a = 10; int b = a + 20;”,中间代码生成器可能会生成以下中间代码:t1 = 20; t2 = a + t1; b = t2;,其中 t1 和 t2 是临时变量。
五、代码优化
代码优化是编译过程的第五个阶段。在这个阶段,编译器会对中间代码进行优化,以提高代码的执行效率。代码优化包括常量折叠、公共子表达式消除、循环优化等。例如,对于中间代码 “t1 = 20; t2 = a + t1; b = t2;”,如果在之前的语义分析阶段已经确定了变量 a 的值,那么编译器可以进行常量折叠,将中间代码优化为 “t1 = 20; t2 = a_value + t1; b = t2;”,其中 a_value 是变量 a 的已知值。
六、目标代码生成
目标代码生成是编译过程的最后一个阶段。在这个阶段,编译器会将优化后的中间代码转化为目标机器的机器语言代码。目标代码生成器通常会根据目标机器的指令集和寄存器分配等情况,生成高效的机器语言代码。例如,对于中间代码 “t1 = 20; t2 = a_value + t1; b = t2;”,目标代码生成器可能会生成以下机器语言代码:mov eax, 20; add eax, a_value; mov b, eax;,其中 eax 是目标机器的寄存器。
C 语言编译过程是怎样的
C 语言的编译过程与一般的编译过程类似,但也有一些特定于 C 语言的特点。
一、预处理阶段
预处理阶段是 C 语言编译过程的第一个阶段。在这个阶段,编译器会对源代码进行预处理,处理以 “#” 开头的预处理指令,如 #include、#define、#ifdef 等。预处理指令的作用是在编译之前对源代码进行一些文本替换和条件编译等操作。例如,“#include <stdio.h>” 指令会将 stdio.h 头文件的内容插入到当前源代码文件中。预处理阶段还会处理宏定义,将宏展开为相应的代码。预处理阶段的输出是经过预处理后的源代码文件,通常以 “.i” 为扩展名。
二、编译阶段
编译阶段是 C 语言编译过程的第二个阶段。在这个阶段,编译器会将预处理后的源代码转化为汇编语言代码。编译阶段的主要任务是进行词法分析、语法分析、语义分析和中间代码生成等操作,与一般的编译过程类似。编译阶段的输出是汇编语言代码文件,通常以 “.s” 为扩展名。
三、汇编阶段
汇编阶段是 C 语言编译过程的第三个阶段。在这个阶段,汇编器会将编译阶段生成的汇编语言代码转化为机器语言代码。汇编阶段的主要任务是将汇编语言指令翻译成机器语言指令,并进行符号解析和重定位等操作。汇编阶段的输出是目标文件,通常以 “.o” 为扩展名。
四、链接阶段
链接阶段是 C 语言编译过程的最后一个阶段。在这个阶段,链接器会将多个目标文件和库文件链接在一起,生成可执行文件。链接阶段的主要任务是解决目标文件之间的符号引用问题,将不同目标文件中的函数和变量链接在一起,形成一个完整的可执行程序。链接阶段还会进行一些优化操作,如消除重复的代码和数据等。链接阶段的输出是可执行文件,通常以可执行文件的扩展名(如 “.exe” 或 “无扩展名”)表示。
C 语言编译链接的过程(预处理、编译、汇编、链接)是怎样的
C 语言的编译链接过程包括预处理、编译、汇编和链接四个阶段。
一、预处理阶段
- 处理包含指令(#include):将指定的头文件内容插入到源代码中。例如,如果源代码中有 “#include <stdio.h>”,则编译器会将 stdio.h 头文件的内容复制到当前源代码文件中。
- 宏定义展开(#define):将源代码中的宏定义替换为相应的文本。例如,如果有 “#define PI 3.14159”,那么在源代码中出现的 “PI” 都会被替换为 “3.14159”。
- 条件编译(#ifdef、#ifndef、#endif 等):根据特定的条件决定是否编译某些代码段。例如,如果定义了某个宏,则编译一段代码,否则不编译。预处理阶段的输出是经过预处理后的源代码文件,通常以 “.i” 为扩展名。
二、编译阶段
- 词法分析:将预处理后的源代码分解成一个个的记号(token),如关键字、标识符、常量、运算符等。
- 语法分析:根据 C 语言的语法规则,将记号组合成语法树。语法树表示了源代码的语法结构。
- 语义分析:对语法树进行语义分析,检查代码的语义是否正确。包括类型检查、作用域检查等。
- 中间代码生成:将语法树转化为中间代码,中间代码是一种与机器无关的代码表示形式。编译阶段的输出是汇编语言代码文件,通常以 “.s” 为扩展名。
三、汇编阶段
- 汇编指令翻译:将汇编语言代码翻译成机器语言指令。
- 符号解析:将汇编代码中的符号(如函数名、变量名等)与实际的内存地址关联起来。
- 重定位:确定代码和数据在内存中的最终位置。汇编阶段的输出是目标文件,通常以 “.o” 为扩展名。
四、链接阶段
- 合并目标文件:将多个目标文件和库文件合并成一个完整的可执行文件。
- 符号解析和重定位:解决目标文件之间的符号引用问题,确定符号在最终可执行文件中的地址。
- 库链接:如果程序使用了库函数,链接器会将库中的代码和数据与程序的代码和数据链接在一起。链接阶段的输出是可执行文件。
内联函数和宏函数的区别是什么
内联函数和宏函数都是在 C 语言中用于提高程序性能的机制,但它们有以下区别:
一、定义和实现方式
- 内联函数:内联函数是在函数声明前加上 “inline” 关键字来定义的。内联函数在编译时会将函数体直接插入到调用处,而不是像普通函数那样进行函数调用。这样可以减少函数调用的开销,提高程序的执行效率。例如:inline int add (int a, int b) { return a + b; }。
- 宏函数:宏函数是通过 #define 指令来定义的。宏函数是一种文本替换,在预处理阶段,宏会被展开为相应的代码。例如:#define ADD (a, b) ((a) + (b))。
二、类型检查和安全性
- 内联函数:内联函数是真正的函数,会进行类型检查。编译器会检查函数参数的类型是否正确,以及函数的返回值类型是否与调用处匹配。这可以提高程序的安全性,减少因类型不匹配而导致的错误。
- 宏函数:宏函数只是简单的文本替换,不会进行类型检查。如果宏的参数类型不正确,可能会导致错误的结果,甚至可能引发严重的程序错误。此外,宏函数可能会产生意想不到的副作用,例如在宏中使用自增运算符可能会导致多次计算,从而产生错误的结果。
三、参数处理
- 内联函数:内联函数像普通函数一样处理参数,可以传递各种类型的参数,包括指针、引用等。内联函数可以正确地处理参数的作用域和生命周期,避免出现悬挂指针等问题。
- 宏函数:宏函数在展开时会直接将参数替换到代码中,可能会导致参数的意外扩展。例如,如果宏的参数是一个表达式,那么在展开时可能会出现意想不到的结果。此外,宏函数不能正确地处理参数的作用域和生命周期,可能会导致内存泄漏等问题。
四、调试和可读性
- 内联函数:内联函数在调试时可以像普通函数一样进行单步调试,可以查看函数的调用栈和变量的值。内联函数的代码通常比较清晰,易于理解和维护。
- 宏函数:宏函数在调试时比较困难,因为宏展开后的代码可能与原始代码有很大的不同,难以跟踪和理解。宏函数的代码通常比较晦涩,可读性较差。
智能指针使用过吗
智能指针是一种用于管理动态分配内存的对象,它可以自动释放所管理的内存,避免内存泄漏和悬空指针等问题。在 C++ 中,常用的智能指针有 std::unique_ptr、std::shared_ptr 和 std::weak_ptr。
我使用过智能指针,以下是对智能指针的一些介绍:
一、std::unique_ptr
std::unique_ptr 是一种独占式智能指针,它表示对一个对象的唯一所有权。当 std::unique_ptr 被销毁时,它所管理的对象也会被自动释放。std::unique_ptr 不能进行复制操作,但可以进行移动操作。这意味着一个对象只能被一个 std::unique_ptr 所拥有,当 std::unique_ptr 被移动到另一个 std::unique_ptr 时,原来的 std::unique_ptr 就不再拥有该对象。
例如:
#include <iostream>
#include <memory>class MyClass {
public:MyClass() { std::cout << "MyClass constructor called." << std::endl; }~MyClass() { std::cout << "MyClass destructor called." << std::endl; }
};int main() {std::unique_ptr<MyClass> ptr1 = std::make_unique<MyClass>();// std::unique_ptr<MyClass> ptr2 = ptr1; // 错误,不能复制std::unique_ptr<MyClass> ptr2 = std::move(ptr1); // 正确,移动所有权if (!ptr1) {std::cout << "ptr1 is null." << std::endl;}return 0;
}
二、std::shared_ptr
std::shared_ptr 是一种共享式智能指针,它表示对一个对象的共享所有权。多个 std::shared_ptr 可以同时拥有同一个对象,当最后一个 std::shared_ptr 被销毁时,它所管理的对象才会被自动释放。std::shared_ptr 使用引用计数来跟踪对象的所有权,每当有一个新的 std::shared_ptr 指向一个对象时,引用计数就会增加;当一个 std::shared_ptr 被销毁时,引用计数就会减少。当引用计数为 0 时,对象就会被自动释放。
例如:
#include <iostream>
#include <memory>class MyClass {
public:MyClass() { std::cout << "MyClass constructor called." << std::endl; }~MyClass() { std::cout << "MyClass destructor called." << std::endl; }
};int main() {std::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();std::shared_ptr<MyClass> ptr2 = ptr1;std::cout << "Use count of ptr1: " << ptr1.use_count() << std::endl;std::cout << "Use count of ptr2: " << ptr2.use_count() << std::endl;return 0;
}
三、std::weak_ptr
std::weak_ptr 是一种弱引用智能指针,它不拥有对象的所有权,只是对一个由 std::shared_ptr 管理的对象进行弱引用。std::weak_ptr 可以用来解决循环引用的问题,当一个对象被多个 std::shared_ptr 所拥有,并且这些 std::shared_ptr 之间形成了循环引用时,可能会导致对象无法被正确释放。使用 std::weak_ptr 可以打破循环引用,使得对象能够被正确释放。
例如:
#include <iostream>
#include <memory>class MyClass;class OtherClass {
public:OtherClass() { std::cout << "OtherClass constructor called." << std::endl; }~OtherClass() { std::cout << "OtherClass destructor called." << std::endl; }void setMyClass(std::shared_ptr<MyClass> ptr) { myClassPtr = ptr; }
private:std::weak_ptr<MyClass> myClassPtr;
};class MyClass {
public:MyClass() { std::cout << "MyClass constructor called." << std::endl; }~MyClass() { std::cout << "MyClass destructor called." << std::endl; }void setOtherClass(std::shared_ptr<OtherClass> ptr) { otherClassPtr = ptr; }
private:std::weak_ptr<OtherClass> otherClassPtr;
};int main() {std::shared_ptr<MyClass> myClassPtr = std::make_shared<MyClass>();std::shared_ptr<OtherClass> otherClassPtr = std::make_shared<OtherClass>();myClassPtr->setOtherClass(otherClassPtr);otherClassPtr->setMyClass(myClassPtr);return 0;
}
在实际应用中,智能指针可以大大提高程序的安全性和可靠性,避免内存泄漏和悬空指针等问题。同时,智能指针也可以提高程序的性能,因为它们可以自动管理内存,避免了手动管理内存的开销。
类继承时,构造函数和析构函数的执行顺序是怎样的
在 C++ 中,当一个类继承另一个类时,构造函数和析构函数的执行顺序有一定的规律。
一、构造函数的执行顺序
- 当创建一个派生类对象时,首先会调用基类的构造函数。这是因为派生类对象包含了基类的部分,所以必须先初始化基类部分。
- 基类构造函数执行完毕后,接着会按照派生类成员变量的声明顺序依次调用它们的构造函数。
- 最后,才会调用派生类自己的构造函数。
例如:
#include <iostream>class Base {
public:Base() { std::cout << "Base constructor called." << std::endl; }
};class Derived : public Base {
public:Derived() { std::cout << "Derived constructor called." << std::endl; }
private:int member;
};int main() {Derived d;return 0;
}
在这个例子中,当创建一个 Derived 对象时,首先会调用 Base 的构造函数,然后会调用 Derived 中成员变量的构造函数(如果有的话),最后才会调用 Derived 自己的构造函数。
二、析构函数的执行顺序
- 当销毁一个派生类对象时,首先会调用派生类自己的析构函数。
- 派生类析构函数执行完毕后,接着会按照派生类成员变量的声明逆序依次调用它们的析构函数。
- 最后,才会调用基类的析构函数。
例如:
#include <iostream>class Base {
public:~Base() { std::cout << "Base destructor called." << std::endl; }
};class Derived : public Base {
public:~Derived() { std::cout << "Derived destructor called." << std::endl; }
private:int member;
};int main() {{Derived d;}动态多态和静态多态有什么区别
动态多态和静态多态是面向对象编程中的两种不同的多态实现方式,它们有以下区别:
一、实现机制
- 动态多态:通过虚函数机制实现。在基类中声明虚函数,在派生类中重写这些虚函数。当通过基类指针或引用调用虚函数时,实际调用的是派生类中重写的函数,具体调用哪个函数在运行时根据对象的实际类型确定。
- 静态多态:通过函数重载、模板等方式实现。在编译期根据函数参数的类型、数量等信息确定调用哪个具体的函数或模板实例。
二、绑定时间
- 动态多态:在运行时绑定,即根据对象的实际类型确定调用哪个函数。这意味着在程序运行过程中,可以根据不同的对象类型动态地选择不同的函数实现。
- 静态多态:在编译时绑定,编译器在编译阶段根据函数参数的类型等信息确定调用哪个函数或模板实例。一旦编译完成,函数调用的具体实现就已经确定,不会在运行时改变。
三、内存开销
- 动态多态:由于需要使用虚函数表(vtable)来实现运行时的函数调用,会有一定的内存开销。每个包含虚函数的类都有一个虚函数表,其中存储了指向该类中虚函数的指针。对象中通常会有一个指向虚函数表的指针,用于在运行时查找正确的函数实现。
- 静态多态:通常没有额外的内存开销,因为函数调用在编译时就已经确定,不需要额外的机制来支持运行时的动态绑定。
四、灵活性和效率
- 动态多态:具有很高的灵活性,可以在运行时根据对象的实际类型动态地选择不同的函数实现。这使得程序可以更容易地适应不同的对象类型和变化的需求。但是,由于运行时的绑定机制,可能会有一定的性能开销。
- 静态多态:在编译时确定函数调用,通常具有更高的效率。但是,灵活性相对较低,一旦编译完成,函数调用的具体实现就不能再改变。
如何用 C 实现 C++ 的类以及面向对象编程
虽然 C 语言本身不支持面向对象编程的特性,但可以通过一些技巧和结构来模拟 C++ 中的类和面向对象编程。
一、封装
在 C 中,可以使用结构体来模拟类的数据成员,并通过函数指针来模拟类的成员函数。将数据和操作数据的函数封装在一起,实现一定程度的封装。
例如:
typedef struct {int data;void (*setData)(struct MyClass *this, int value);int (*getData)(struct MyClass *this);
} MyClass;void setDataImpl(MyClass *this, int value) {this->data = value;
}int getDataImpl(MyClass *this) {return this->data;
}MyClass *createMyClass() {MyClass *obj = (MyClass *)malloc(sizeof(MyClass));obj->data = 0;obj->setData = setDataImpl;obj->getData = getDataImpl;return obj;
}
二、继承
可以通过在结构体中包含另一个结构体来模拟继承关系。子结构体可以访问父结构体的成员,并可以添加自己的成员和函数。
例如:
typedef struct {int baseData;void (*setBaseData)(struct BaseClass *this, int value);int (*getBaseData)(struct BaseClass *this);
} BaseClass;void setBaseDataImpl(BaseClass *this, int value) {this->baseData = value;
}int getBaseDataImpl(BaseClass *this) {return this->baseData;
}typedef struct {BaseClass base;int derivedData;void (*setDerivedData)(struct DerivedClass *this, int value);int (*getDerivedData)(struct DerivedClass *this);
} DerivedClass;void setDerivedDataImpl(DerivedClass *this, int value) {this->derivedData = value;
}int getDerivedDataImpl(DerivedClass *this) {return this->derivedData;
}DerivedClass *createDerivedClass() {DerivedClass *obj = (DerivedClass *)malloc(sizeof(DerivedClass));obj->base.setBaseData = setBaseDataImpl;obj->base.getBaseData = getBaseDataImpl;obj->derivedData = 0;obj->setDerivedData = setDerivedDataImpl;obj->getDerivedData = getDerivedDataImpl;return obj;
}
三、多态
在 C 中实现多态比较困难,但可以通过函数指针的方式在一定程度上模拟多态。不同的结构体可以有相同的函数指针,通过这些函数指针调用不同的实现,实现类似多态的效果。
例如:
typedef struct {void (*print)(struct Shape *this);
} Shape;typedef struct {Shape base;int radius;
} Circle;void printCircle(Circle *this) {printf("Circle with radius %d\n", this->radius);
}typedef struct {Shape base;int width;int height;
} Rectangle;void printRectangle(Rectangle *this) {printf("Rectangle with width %d and height %d\n", this->width, this->height);
}void drawShape(Shape *shape) {shape->print(shape);
}
虽然用 C 模拟 C++ 的面向对象编程比较复杂,但可以在一定程度上实现封装、继承和多态的特性。然而,这种方式与真正的 C++ 面向对象编程相比,存在一些局限性,如语法不够简洁、类型安全性较低等。
C++ 的新标准有使用过吗?请讲一下
C++ 的新标准(如 C++11、C++14、C++17、C++20 等)引入了许多新的特性,这些特性使得 C++ 语言更加现代化、高效和易于使用。我使用过一些 C++ 的新标准,以下是对一些主要特性的介绍:
一、C++11 的特性
- 自动类型推导(auto 和 decltype):可以使用 “auto” 关键字让编译器自动推导变量的类型,简化代码编写。例如:auto i = 42;,编译器会自动推断出 “i” 的类型为 “int”。“decltype” 关键字可以用于获取表达式的类型。
- 范围 for 循环:提供了一种更简洁的方式来遍历容器中的元素。例如:for (auto &element : container) {... }。
- 智能指针(std::unique_ptr、std::shared_ptr 和 std::weak_ptr):用于自动管理动态分配的内存,避免内存泄漏和悬空指针等问题。
- 移动语义和右值引用:通过移动语义,可以避免不必要的复制操作,提高性能。右值引用允许函数接受临时对象,并将其资源 “窃取” 过来,而不是进行复制。
- 初始化列表:可以使用初始化列表来初始化对象,更加简洁和高效。例如:class MyClass {int a, b; public: MyClass (int x, int y) : a (x), b (y) {} };。
- Lambda 表达式:可以定义匿名函数,方便在代码中进行局部的函数式编程。例如:[](int a, int b) { return a + b; }。
二、C++14 的特性
- 泛型 lambda 表达式:允许 lambda 表达式的参数使用 auto 关键字进行类型推导,更加灵活。
- 二进制字面量:可以使用二进制字面量来表示整数,例如 0b1010 表示十进制的 10。
- 返回类型推导:对于函数模板,可以让编译器自动推导返回类型,简化函数模板的编写。
三、C++17 的特性
- 结构化绑定:可以将一个 tuple 或结构体的成员绑定到多个变量上,方便访问。例如:auto [a, b] = std::make_pair (10, 20);。
- 类模板参数推导:对于类模板,可以根据构造函数的参数自动推导模板参数的类型,简化类模板的使用。
- 折叠表达式:可以对参数包进行折叠操作,方便处理可变参数的函数。例如:template<typename... Args> int sum (Args... args) { return (... + args); }。
四、C++20 的特性
- 概念(Concepts):用于约束模板参数的类型,提高模板代码的可读性和可维护性。
- 模块(Modules):提供了一种新的代码组织方式,可以替代传统的头文件和源文件的方式,提高编译速度和代码的可维护性。
- 范围(Ranges):提供了一种新的方式来处理容器中的元素,更加简洁和高效。
- 协程(Coroutines):支持协程的编写,可以更加方便地进行异步编程。
C++ 的新标准为开发者提供了许多强大的工具和特性,使得 C++ 语言在现代编程中更加具有竞争力。使用这些新标准可以提高代码的质量、可读性和可维护性,同时也可以提高开发效率。
构造函数和析构函数什么时候会被调用
在 C++ 中,构造函数和析构函数在特定的情况下会被自动调用。
一、构造函数的调用时机
- 对象创建时:当创建一个类的对象时,构造函数会被自动调用。构造函数用于初始化对象的成员变量,为对象分配资源等。例如:class MyClass {public: MyClass () {... } }; MyClass obj;,在创建 “obj” 对象时,MyClass 的构造函数会被自动调用。
- 对象作为函数参数传递时:当一个对象作为函数的参数按值传递时,会调用该对象的复制构造函数(如果定义了的话)。如果没有定义复制构造函数,编译器会自动生成一个默认的复制构造函数。例如:void func (MyClass obj); func (myObj);,在调用 “func” 函数时,会调用 “MyClass” 的复制构造函数来创建函数参数 “obj”。
- 对象作为函数返回值时:当一个函数返回一个对象时,会调用该对象的复制构造函数(如果定义了的话)或移动构造函数(如果定义了且满足移动的条件)。如果没有定义复制构造函数和移动构造函数,编译器会自动生成一个默认的复制构造函数。例如:MyClass func () { MyClass obj; return obj;},在函数 “func” 返回时,会调用 “MyClass” 的复制构造函数或移动构造函数来创建返回值。
二、析构函数的调用时机
- 对象销毁时:当一个对象的生命周期结束时,析构函数会被自动调用。析构函数用于释放对象占用的资源,进行清理工作等。例如:{MyClass obj;},在离开这个作用域时,“obj” 对象的析构函数会被自动调用。
- delete 操作符释放动态分配的对象时:当使用 “delete” 操作符释放动态分配的对象时,析构函数会被自动调用。例如:MyClass *obj = new MyClass (); delete obj;,在调用 “delete” 操作符时,“obj” 所指向的对象的析构函数会被自动调用。
构造函数和析构函数的正确使用对于确保程序的正确性和资源的有效管理非常重要。在编写类时,应该根据需要合理地定义构造函数和析构函数,以确保对象的正确初始化和清理。
一个线程在做系统调用时,栈会发生什么变化
当一个线程在做系统调用时,栈会发生以下一些变化:
一、系统调用前
在进行系统调用之前,线程的栈通常保存着当前函数的局部变量、函数调用的返回地址以及其他运行时上下文信息。线程在执行用户空间的代码时,栈随着函数的调用和返回不断地进行压栈和出栈操作,以维护函数调用的顺序和局部变量的存储。
二、进入系统调用
当线程发起系统调用时,通常会发生从用户空间到内核空间的切换。在这个过程中,线程的执行上下文会被保存起来,包括栈指针、寄存器等信息。内核会为系统调用分配一个内核栈,用于在内核空间执行系统调用的代码。此时,线程的栈从用户栈切换到内核栈。
三、系统调用执行过程中
在内核栈中,系统调用的参数和局部变量会被存储。内核会根据系统调用的类型执行相应的操作,可能会涉及到对内核数据结构的访问、设备驱动程序的调用等。在这个过程中,内核栈会随着系统调用的执行不断地进行压栈和出栈操作,以维护系统调用的执行上下文。
四、系统调用返回
当系统调用完成后,内核会将执行上下文从内核栈恢复到用户栈,并将系统调用的返回值传递给用户空间的代码。线程会从系统调用的位置继续执行用户空间的代码,栈也会从内核栈切换回用户栈。此时,用户栈中的局部变量和返回地址等信息会被恢复,线程继续执行之前的操作。
总之,当一个线程在做系统调用时,栈会从用户栈切换到内核栈,在内核栈中执行系统调用的代码,然后再切换回用户栈继续执行用户空间的代码。这个过程中,栈的内容会根据系统调用的执行上下文进行相应的变化。
线程死锁怎么产生的?如何避免
一、线程死锁产生的原因
- 资源竞争:当两个或多个线程同时竞争多个资源时,如果每个线程都持有一部分资源并等待其他线程释放资源,就可能会发生死锁。例如,线程 A 持有资源 R1 并等待资源 R2,而线程 B 持有资源 R2 并等待资源 R1,这时就会发生死锁。
- 资源分配顺序不当:如果多个线程以不同的顺序请求资源,也可能会导致死锁。例如,线程 A 先请求资源 R1,再请求资源 R2,而线程 B 先请求资源 R2,再请求资源 R1,如果两个线程同时执行,就可能会发生死锁。
- 持有资源并等待其他资源:当一个线程持有一个资源并等待另一个资源时,如果另一个线程也持有一个资源并等待第一个线程持有的资源,就会发生死锁。这种情况通常发生在多个线程相互等待对方释放资源的情况下。
- 不可抢占资源:如果资源是不可抢占的,即一旦一个线程获得了一个资源,其他线程就不能强行夺取这个资源,那么当多个线程竞争不可抢占资源时,就可能会发生死锁。
二、避免线程死锁的方法
- 避免资源竞争:可以通过减少资源的竞争来避免死锁。例如,可以使用互斥锁来保护共享资源,确保只有一个线程能够访问资源。或者可以将资源进行复制,每个线程都有自己的副本,避免多个线程同时竞争同一个资源。
- 确定资源分配顺序:可以通过确定资源的分配顺序来避免死锁。例如,可以规定所有线程在请求资源时都按照相同的顺序进行,这样就可以避免因资源分配顺序不当而导致的死锁。
- 避免持有资源并等待其他资源:可以通过避免一个线程持有一个资源并等待另一个资源的情况来避免死锁。例如,可以在请求资源之前先释放已经持有的资源,或者可以一次性请求所有需要的资源,避免在持有资源的情况下再去请求其他资源。
- 使用可抢占资源:如果资源是可抢占的,即一个线程可以强行夺取另一个线程持有的资源,那么就可以避免死锁。但是,使用可抢占资源可能会导致其他问题,如数据不一致等,需要谨慎使用。
- 检测和恢复死锁:可以通过检测死锁的发生并采取相应的措施来恢复死锁。例如,可以使用死锁检测算法来检测死锁的发生,并通过终止一些线程或回滚一些操作来恢复死锁。但是,这种方法通常比较复杂,并且可能会导致一些数据的丢失或不一致。
线程和进程的区别是什么
线程和进程是操作系统中两个重要的概念,它们有以下区别:
一、定义和概念
- 进程:进程是操作系统进行资源分配和调度的基本单位。一个进程通常包含一个或多个线程,以及代码、数据、打开的文件等资源。进程有自己独立的地址空间,不同进程之间的地址空间是相互隔离的。
- 线程:线程是进程中的一个执行单元。一个线程通常包含自己的栈、寄存器等执行上下文,但共享进程的地址空间和其他资源。线程可以并发执行,提高程序的并发性和效率。
二、资源占用
- 进程:进程占用较多的系统资源,包括内存、文件描述符等。创建一个进程需要进行大量的系统调用和资源分配,开销较大。
- 线程:线程占用较少的系统资源,创建一个线程比创建一个进程要快得多,开销较小。由于线程共享进程的地址空间,所以线程之间的通信和数据共享也比较容易。
三、调度和并发性
- 进程:操作系统以进程为单位进行调度,不同进程之间的切换需要进行上下文切换,开销较大。进程之间的并发性相对较低,因为每个进程都有自己独立的地址空间和资源。
- 线程:操作系统以线程为单位进行调度,线程之间的切换开销较小。由于线程共享进程的
进程的切换过程是怎样的
进程切换是操作系统中一项关键的操作,它涉及到从正在运行的一个进程切换到另一个进程。以下是进程切换的详细过程:
一、保存当前进程的状态
- 当操作系统决定切换进程时,首先会保存当前正在运行的进程的状态。这包括处理器寄存器的值,如程序计数器、通用寄存器等。这些寄存器中存储着当前进程正在执行的指令地址以及各种中间数据。
- 还会保存当前进程的栈指针,栈中包含了函数调用信息、局部变量等。通过保存栈指针,可以在以后恢复该进程时,继续从上次中断的地方执行。
- 此外,操作系统还会记录当前进程的其他关键状态信息,如进程的优先级、状态标志(如运行、就绪、阻塞等)等。
二、选择新的进程
- 操作系统根据调度算法从就绪队列中选择一个新的进程准备运行。调度算法可能考虑多种因素,如进程的优先级、等待时间、预计执行时间等。
- 一旦选定了新的进程,操作系统会获取该进程的相关信息,包括它的程序计数器值、栈指针以及其他初始化状态。
三、恢复新进程的状态
- 操作系统将新进程的状态信息加载到处理器的寄存器中。这包括恢复程序计数器的值,使得处理器从新进程上次中断的地方继续执行。
- 恢复栈指针,以便新进程可以正确地访问自己的栈空间。
- 设置处理器的其他相关状态,如特权级别等,以适应新进程的执行环境。
四、开始执行新进程
- 完成状态恢复后,处理器开始执行新进程的指令。新进程从上次中断的地方继续执行,就好像它一直没有被中断过一样。
- 新进程开始运行后,它可能会进行各种操作,如访问内存、执行计算、发起系统调用等。操作系统会继续监控新进程的执行情况,并在需要时进行进一步的进程切换。
进程间的通讯方式有哪些
进程间通信(IPC)是指在不同进程之间进行数据交换和信息传递的机制。以下是常见的进程间通信方式:
一、管道(Pipe)
- 无名管道:无名管道是一种半双工的通信方式,只能在具有亲缘关系的进程之间使用,例如父子进程。它通过在内核中开辟一块缓冲区来实现数据的传递。一个进程向管道中写入数据,另一个进程从管道中读取数据。
- 有名管道:有名管道克服了无名管道只能在亲缘关系进程间通信的限制。它可以在不相关的进程之间进行通信。有名管道在文件系统中有一个对应的文件名,不同的进程可以通过这个文件名来打开管道进行通信。
二、消息队列(Message Queue)
- 消息队列是一种独立于发送和接收进程的存储机制。进程可以将消息发送到消息队列中,其他进程可以从消息队列中读取消息。消息队列中的消息具有特定的格式和类型,可以包含各种数据。
- 消息队列提供了一种异步的通信方式,发送进程可以在发送消息后继续执行其他任务,而接收进程可以在需要的时候从消息队列中读取消息。消息队列还可以实现多个发送者和多个接收者之间的通信。
三、共享内存(Shared Memory)
- 共享内存是多个进程可以共同访问的一块内存区域。进程可以将数据写入共享内存,其他进程可以从共享内存中读取数据。共享内存提供了一种非常高效的通信方式,因为数据不需要在进程之间进行复制。
- 为了确保数据的一致性和安全性,通常需要使用同步机制,如信号量或互斥锁,来协调对共享内存的访问。
四、信号量(Semaphore)
- 信号量主要用于实现进程之间的同步和互斥。它是一个整数变量,用于控制对共享资源的访问。信号量的值表示当前可以访问共享资源的进程数量。
- 进程可以通过对信号量进行操作(如 P 操作和 V 操作)来实现对共享资源的互斥访问或同步操作。例如,当一个进程需要访问一个共享资源时,它可以先对信号量进行 P 操作,如果信号量的值大于 0,则可以访问资源,并将信号量的值减 1;如果信号量的值为 0,则进程进入阻塞状态,等待其他进程释放资源。当一个进程释放资源时,它可以对信号量进行 V 操作,将信号量的值加 1,并唤醒一个等待的进程。
五、套接字(Socket)
- 套接字是一种广泛用于网络通信的进程间通信方式。它可以在不同主机上的进程之间进行通信,也可以在同一主机上的不同进程之间进行通信。
- 套接字提供了一种可靠的、面向连接的通信方式(如 TCP 套接字)和一种不可靠的、无连接的通信方式(如 UDP 套接字)。进程可以通过套接字发送和接收数据,实现不同进程之间的通信。
IP 地址如何转化成 Mac 地址
在计算机网络中,IP 地址和 MAC 地址是两种不同的地址标识,它们在不同的层次上发挥作用。IP 地址用于在网络层标识主机,而 MAC 地址用于在数据链路层标识网络设备。当一个网络数据包需要从一个主机发送到另一个主机时,需要将 IP 地址转换为 MAC 地址,这个过程通常通过地址解析协议(ARP)来实现。
一、ARP 缓存查询
- 当一个主机需要发送数据包到另一个主机时,它首先会检查自己的 ARP 缓存,看是否已经有目标 IP 地址对应的 MAC 地址。ARP 缓存是一个存储了最近解析过的 IP 地址和 MAC 地址对应关系的表。
- 如果在 ARP 缓存中找到了目标 IP 地址对应的 MAC 地址,主机就可以直接使用这个 MAC 地址来封装数据包,并将其发送到数据链路层进行传输。
二、ARP 请求广播
- 如果在 ARP 缓存中没有找到目标 IP 地址对应的 MAC 地址,主机就会发送一个 ARP 请求广播。ARP 请求是一个在本地网络中广播的数据包,其中包含了发送方的 IP 地址和 MAC 地址,以及目标 IP 地址。
- 所有在本地网络中的主机都会接收到这个 ARP 请求广播,并检查其中的目标 IP 地址是否与自己的 IP 地址匹配。如果不匹配,主机就会忽略这个请求;如果匹配,主机就会发送一个 ARP 应答。
三、ARP 应答
- 当目标主机接收到 ARP 请求广播后,它会检查其中的目标 IP 地址是否与自己的 IP 地址匹配。如果匹配,目标主机就会发送一个 ARP 应答,其中包含了自己的 IP 地址和 MAC 地址。
- ARP 应答是一个单播数据包,直接发送给发送方主机。发送方主机接收到 ARP 应答后,就可以从应答中提取出目标主机的 MAC 地址,并将其存储在自己的 ARP 缓存中,以便下次使用。
输入网址到显示页面的实现过程是怎样的
当在浏览器中输入一个网址并按下回车键后,一系列复杂的过程会在后台发生,最终导致网页在浏览器中显示出来。以下是这个过程的详细步骤:
一、域名解析
- 当输入网址后,浏览器首先会对网址进行解析。如果网址中包含域名(例如 www.example.com),浏览器需要将域名转换为对应的 IP 地址。这个过程通过域名系统(DNS)来完成。
- 浏览器会向本地 DNS 服务器发送一个 DNS 查询请求,询问目标域名对应的 IP 地址。如果本地 DNS 服务器没有缓存该域名的 IP 地址,它会向上一级 DNS 服务器继续查询,直到找到目标域名的 IP 地址或者查询失败。
- 一旦获得了目标域名的 IP 地址,浏览器就可以使用这个 IP 地址来建立与目标服务器的连接。
二、建立 TCP 连接
- 浏览器使用目标服务器的 IP 地址和默认的 HTTP 端口号(80)来建立一个 TCP 连接。TCP 是一种可靠的、面向连接的传输协议,它确保数据在网络中可靠地传输。
- 建立 TCP 连接的过程包括三次握手。首先,浏览器向服务器发送一个 SYN 数据包,表示请求建立连接。服务器接收到 SYN 数据包后,会回复一个 SYN/ACK 数据包,表示同意建立连接。浏览器接收到 SYN/ACK 数据包后,会再回复一个 ACK 数据包,表示确认建立连接。
- 一旦 TCP 连接建立成功,浏览器就可以通过这个连接向服务器发送 HTTP 请求。
三、发送 HTTP 请求
- 浏览器会构建一个 HTTP 请求报文,其中包含了请求方法(如 GET、POST 等)、请求的 URL、HTTP 版本号、请求头和请求体等信息。
- 浏览器将 HTTP 请求报文通过建立好的 TCP 连接发送到服务器。请求头中可能包含了一些重要的信息,如用户代理(表示浏览器的类型和版本)、接受的内容类型、语言偏好等。
四、服务器处理请求
- 服务器接收到 HTTP 请求报文后,会根据请求的 URL 和请求方法来处理请求。服务器可能会从文件系统中读取相应的网页文件,或者执行一个动态脚本(如 PHP、Python 等)来生成网页内容。
- 如果请求的是一个静态网页文件,服务器会直接将文件内容读取出来,并构建一个 HTTP 响应报文。如果请求的是一个动态脚本,服务器会执行脚本,并将脚本的输出作为网页内容构建 HTTP 响应报文。
五、发送 HTTP 响应
- 服务器将构建好的 HTTP 响应报文通过 TCP 连接发送回浏览器。HTTP 响应报文包含了响应状态码(如 200 OK 表示请求成功,404 Not Found 表示请求的资源不存在等)、响应头和响应体等信息。
- 响应头中可能包含了一些重要的信息,如内容类型、内容长度、缓存控制等。响应体中包含了实际的网页内容,如 HTML、CSS、JavaScript 等文件。
六、浏览器解析和渲染页面
- 浏览器接收到 HTTP 响应报文后,会首先解析响应状态码。如果状态码表示请求成功,浏览器会继续解析响应头和响应体。
- 浏览器会根据响应头中的内容类型来确定如何处理响应体。如果是 HTML 文件,浏览器会开始解析 HTML 代码,并构建一个文档对象模型(DOM)树。
- 在解析 HTML 的过程中,浏览器可能会遇到 CSS 和 JavaScript 文件的引用。它会继续发送请求来获取这些文件,并将它们应用到 DOM 树中。
- 一旦 DOM 树构建完成,浏览器会根据 CSS 规则来计算每个元素的样式,并将样式应用到 DOM 树中。然后,浏览器会根据 DOM 树和样式信息来进行布局,确定每个元素在屏幕上的位置。
- 最后,浏览器会进行绘制操作,将页面内容绘制到屏幕上,完成页面的显示。
从输入网址到显示页面的过程涉及到多个步骤,包括域名解析、建立 TCP 连接、发送 HTTP 请求、服务器处理请求、发送 HTTP 响应以及浏览器解析和渲染页面等。这个过程需要多个网络协议和软件组件的协同工作,才能最终将网页显示在用户的屏幕上。
动态库和静态库的区别是什么
动态库和静态库是两种不同类型的库文件,它们在使用方式和特点上有很大的区别。
一、定义和概念
- 静态库:静态库是在编译时被链接到可执行文件中的库文件。静态库通常以 “.a”(在 Unix/Linux 系统中)或 “.lib”(在 Windows 系统中)为扩展名。静态库中包含了目标文件的副本,这些目标文件在编译时被合并到可执行文件中,使得可执行文件可以独立运行,不需要依赖外部的库文件。
- 动态库:动态库是在运行时被加载到内存中的库文件。动态库通常以 “.so”(在 Unix/Linux 系统中)或 “.dll”(在 Windows 系统中)为扩展名。动态库在编译时并不会被合并到可执行文件中,而是在运行时由操作系统根据需要加载到内存中,并将可执行文件与动态库进行链接。可执行文件只包含了对动态库中函数和变量的引用,而实际的代码和数据在运行时从动态库中读取。
二、使用方式
- 静态库:在使用静态库时,需要在编译命令中指定静态库的路径和名称。编译器会将静态库中的目标文件与源文件一起编译,并将静态库中的代码和数据合并到可执行文件中。例如,在使用 GCC 编译器时,可以使用 “-L/path/to/library -l library_name” 选项来指定静态库的路径和名称。
- 动态库:在使用动态库时,需要在编译命令中指定动态库的路径和名称,并在运行时确保动态库能够被找到。在编译时,编译器只会生成对动态库中函数和变量的引用,而实际的代码和数据在运行时从动态库中读取。在运行时,操作系统会根据可执行文件中的引用,加载相应的动态库到内存中,并将可执行文件与动态库进行链接。例如,在使用 GCC 编译器时,可以使用 “-L/path/to/library -l library_name” 选项来指定动态库的路径和名称,并在运行时将动态库的路径添加到系统的环境变量中,或者将动态库复制到系统的默认库路径中。
三、特点和优势
- 静态库:
- 独立性:静态库编译后的可执行文件可以独立运行,不需要依赖外部的库文件。这使得静态库在部署和分发时比较方便,不用担心缺少库文件的问题。
- 性能:由于静态库中的代码和数据在编译时被合并到可执行文件中,所以在运行时不需要进行额外的加载和链接操作,因此性能相对较高。
- 安全性:静态库中的代码和数据是在编译时确定的,不容易被恶意修改。
- 动态库:
- 灵活性:动态库可以在运行时被加载和卸载,这使得程序可以根据需要动态地加载和使用不同的库文件,提高了程序的灵活性和可扩展性。
- 内存共享:多个程序可以共享同一个动态库,这可以减少内存的占用,提高系统的资源利用率。
- 更新方便:如果动态库中的代码和数据发生了变化,只需要更新动态库文件即可,而不需要重新编译和分发所有使用该库的程序。
总之,静态库和动态库各有优缺点,在实际应用中需要根据具体情况选择合适的库类型。如果需要独立运行的可执行文件,或者对性能要求较高,可以选择静态库;如果需要提高程序的灵活性和可扩展性,或者希望减少内存占用和方便更新,可以选择动态库。
了解 linux 吗
Linux 是一种广泛使用的开源操作系统,具有以下特点和优势:
一、开源性
Linux 是开源软件,这意味着其源代码是公开的,任何人都可以查看、修改和分发。开源性带来了许多好处,如:
- 安全性:由于源代码公开,许多开发者可以审查代码,发现和修复安全漏洞,提高系统的安全性。
- 定制性:用户可以根据自己的需求对 Linux 进行定制和修改,以满足特定的应用场景。
- 社区支持:庞大的开源社区为 Linux 提供了丰富的资源和支持,包括文档、教程、论坛等。用户可以从社区中获取帮助和解决问题。
二、稳定性和可靠性
Linux 以其稳定性和可靠性而闻名。它经过了长时间的开发和测试,能够在各种硬件平台上稳定运行。Linux 系统通常具有以下特点:
- 内核稳定:Linux 内核经过精心设计和优化,具有高度的稳定性和可靠性。内核的模块化设计使得可以根据需要加载和卸载不同的模块,提高系统的灵活性和可维护性。
- 错误处理:Linux 系统对错误的处理非常严格,能够及时检测和处理各种错误情况,避免系统崩溃。
- 日志记录:Linux 系统会记录各种系统事件和错误信息,方便用户进行故障排除和系统管理。
三、多用户和多任务
Linux 是一个多用户、多任务的操作系统,允许多个用户同时登录并使用系统资源。同时,Linux 可以同时运行多个任务,每个任务都可以独立地使用系统资源,提高了系统的利用率和效率。
四、命令行界面和图形用户界面
Linux 提供了强大的命令行界面(CLI)和图形用户界面(GUI)。命令行界面允许用户通过输入命令来执行各种操作,具有高效、灵活和可自动化的特点。图形用户界面则提供了直观、易用的操作方式,适合普通用户使用。
五、文件系统和权限管理
Linux 采用了层次化的文件系统结构,具有良好的组织和管理能力。同时,Linux 提供了严格的权限管理机制,确保系统的安全性和稳定性。用户和组可以被赋予不同的权限,以控制对文件和系统资源的访问。
讲一下文件系统
文件系统是操作系统中用于管理和组织文件的一种机制。它提供了一种方式来存储、检索和操作文件,使得用户和应用程序能够方便地访问和管理数据。
一、文件系统的组成部分
- 文件和目录:文件是存储数据的基本单位,它可以包含文本、图像、音频、视频等各种类型的数据。目录则是用于组织文件的一种结构,它可以包含其他目录和文件。
- 文件属性:每个文件都有一些属性,如文件名、文件大小、创建时间、修改时间、访问权限等。这些属性可以帮助用户和操作系统更好地管理文件。
- 文件操作:文件系统提供了一系列的操作,如创建文件、删除文件、读取文件、写入文件、修改文件属性等。这些操作可以通过操作系统提供的接口或者命令行工具来执行。
- 存储设备管理:文件系统需要管理存储设备,如硬盘、固态硬盘、U 盘等。它需要将存储设备划分为不同的区域,用于存储文件和目录。同时,文件系统还需要管理存储设备的空间分配和回收,以确保存储设备的有效利用。
二、常见的文件系统类型
- FAT 文件系统:FAT(File Allocation Table)文件系统是一种早期的文件系统,广泛应用于 DOS 和 Windows 操作系统中。它具有简单、易于实现的特点,但也存在一些缺点,如文件大小限制、不支持高级文件属性等。
- NTFS 文件系统:NTFS(New Technology File System)是 Windows 操作系统中常用的文件系统。它支持大文件、高级文件属性、安全性等功能,具有较高的可靠性和性能。
- EXT 文件系统:EXT(Extended file system)是 Linux 操作系统中常用的文件系统。它具有良好的性能、可靠性和可扩展性,支持大文件、日志记录等功能。
- HFS + 文件系统:HFS+(Hierarchical File System Plus)是 Mac OS X 操作系统中使用的文件系统。它具有良好的性能和可靠性,支持大文件、文件权限等功能。
三、文件系统的工作原理
- 文件存储:文件系统将文件存储在存储设备上,通常是以块为单位进行存储。每个块都有一个唯一的地址,文件系统通过这些地址来访问和管理文件。
- 目录结构:文件系统使用目录结构来组织文件。目录可以包含其他目录和文件,形成一个层次化的结构。用户和应用程序可以通过目录结构来访问文件。
- 文件操作:当用户或应用程序执行文件操作时,文件系统会根据操作的类型和文件的属性来执行相应的操作。例如,读取文件时,文件系统会从存储设备上读取文件的内容,并将其返回给用户或应用程序。
- 空间管理:文件系统需要管理存储设备的空间分配和回收。当创建文件时,文件系统会为文件分配足够的空间。当删除文件时,文件系统会回收文件占用的空间,以便后续使用。
四、文件系统的重要性
- 数据管理:文件系统提供了一种方便的方式来管理数据,使得用户和应用程序能够轻松地存储、检索和操作文件。
- 数据安全:文件系统可以通过访问权限控制、数据加密等方式来保护数据的安全。
- 系统性能:文件系统的性能对系统的整体性能有很大的影响。一个高效的文件系统可以提高数据的读写速度,减少系统的响应时间。
- 数据备份和恢复:文件系统可以提供数据备份和恢复的功能,帮助用户在数据丢失或损坏时恢复数据。
为什么选择嵌入式
选择嵌入式领域有以下几个重要原因:
一、广泛的应用领域
嵌入式系统广泛应用于各个行业,包括消费电子、汽车电子、工业控制、医疗设备、航空航天等。从智能手机、平板电脑到智能家居设备、智能汽车,嵌入式技术无处不在。选择嵌入式意味着可以参与到各种创新和有意义的项目中,为不同领域的发展做出贡献。
例如,在汽车电子领域,嵌入式系统负责控制发动机管理、车载娱乐系统、安全气囊等关键功能。在医疗设备中,嵌入式系统用于监测患者生命体征、控制医疗仪器等。这些应用不仅具有技术挑战性,还直接影响着人们的生活质量和安全。
二、技术挑战与创新
嵌入式系统开发涉及多个技术领域,包括硬件设计、软件开发、操作系统、通信协议等。这需要开发者具备广泛的知识和技能,不断学习和掌握新的技术。同时,嵌入式系统通常需要在资源受限的环境下运行,如有限的内存、处理能力和功耗要求。这就要求开发者进行优化和创新,以实现高效的系统性能。
例如,在设计嵌入式设备时,需要考虑如何在低功耗的情况下实现高性能的处理。这可能涉及到选择合适的处理器架构、优化算法、降低功耗的设计技巧等。此外,随着物联网的发展,嵌入式系统需要与其他设备进行通信和互联,这也带来了新的技术挑战和创新机会。
三、职业发展前景
随着科技的不断发展,嵌入式领域的需求持续增长。企业对嵌入式工程师的需求旺盛,提供了丰富的职业发展机会。从初级工程师到高级工程师、技术专家、项目经理等,嵌入式领域有着明确的职业发展路径。
此外,嵌入式技术的不断演进也为开发者提供了持续学习和提升的机会。例如,随着人工智能、边缘计算等新技术的兴起,嵌入式系统也在不断融合这些技术,为开发者带来了新的挑战和机遇。
四、成就感与实用性
嵌入式项目通常具有明确的目标和实际的应用场景。当成功开发出一个嵌入式产品并看到它在实际中发挥作用时,会给开发者带来巨大的成就感。与纯软件项目相比,嵌入式项目往往涉及到硬件和软件的协同工作,能够更直接地看到自己的工作成果对实际产品的影响。
例如,开发一个智能家居控制系统,能够让用户通过手机远程控制家中的灯光、电器等设备,这种实际的应用效果会让开发者感到非常满足。同时,嵌入式产品的实用性也使得开发者的工作更有意义,能够为人们的生活带来便利和改善。
讲解一下 lcd 驱动
LCD(Liquid Crystal Display)驱动是嵌入式系统中用于控制液晶显示屏的关键部分。以下是对 LCD 驱动的详细讲解:
一、LCD 显示屏的工作原理
LCD 显示屏是通过控制液晶分子的排列来实现图像显示的。液晶分子在电场的作用下会改变排列方向,从而改变光线的透过率。通过控制不同像素点的电场,可以实现不同的亮度和颜色显示。
LCD 显示屏通常由液晶面板、背光源、驱动电路等部分组成。驱动电路负责接收来自外部的信号,并将其转换为控制液晶分子的电场信号。
二、LCD 驱动的功能
- 信号接收与处理:LCD 驱动接收来自外部设备(如微控制器、图形处理器等)的图像数据和控制信号。这些信号可能包括像素数据、行同步信号、帧同步信号、时钟信号等。驱动电路对这些信号进行处理,将其转换为适合液晶面板的格式。
- 液晶面板控制:根据处理后的信号,驱动电路控制液晶面板中的每个像素点的电场,以实现图像的显示。这包括控制行驱动器和列驱动器,分别负责选择行和列,并将像素数据写入相应的像素点。
- 电源管理:LCD 显示屏通常需要多个电源供应,包括逻辑电源、模拟电源、背光源电源等。LCD 驱动负责管理这些电源,确保显示屏在正确的电压和电流下工作。
- 时序控制:LCD 驱动需要严格遵守液晶面板的时序要求,包括行同步、帧同步、像素时钟等。时序控制不当可能导致图像显示异常,如闪烁、失真等。
- 色彩管理:对于彩色 LCD 显示屏,驱动电路需要进行色彩管理,将输入的颜色数据转换为适合液晶面板的色彩格式。这可能涉及到色彩空间转换、伽马校正等操作。
三、LCD 驱动的实现方式
- 硬件驱动:硬件驱动是通过专门的集成电路(IC)来实现 LCD 驱动功能。这些 IC 通常具有高度集成化、高性能、低功耗等特点,适用于各种不同类型的 LCD 显示屏。硬件驱动可以直接与微控制器或其他外部设备连接,通过特定的接口协议进行通信。
- 软件驱动:软件驱动是通过在微控制器或其他处理器上运行的软件来实现 LCD 驱动功能。这种方式具有灵活性高、可定制性强等优点,但需要较高的处理器性能和软件复杂度。软件驱动通常使用图形库或专门的驱动程序来实现对 LCD 显示屏的控制。
四、LCD 驱动的开发流程
- 了解液晶面板的规格和特性:在开发 LCD 驱动之前,需要了解所使用的液晶面板的规格和特性,包括分辨率、色彩深度、接口类型、时序要求等。这些信息可以从液晶面板的数据手册中获取。
- 选择合适的驱动方式:根据项目需求和硬件平台的特点,选择合适的 LCD 驱动方式,如硬件驱动或软件驱动。如果选择硬件驱动,需要选择合适的驱动 IC,并了解其接口和编程方法。如果选择软件驱动,需要选择合适的图形库或开发自己的驱动程序。
- 设计驱动电路:如果选择硬件驱动,需要设计驱动电路,包括电源电路、接口电路、控制电路等。驱动电路的设计需要考虑液晶面板的电源要求、接口信号的电平转换、时序控制等因素。
- 编写驱动程序:如果选择软件驱动,需要编写驱动程序,实现对 LCD 显示屏的控制。驱动程序通常包括初始化函数、显示函数、刷新函数等。初始化函数负责设置液晶面板的参数和状态,显示函数负责将图像数据写入液晶面板,刷新函数负责定期刷新液晶面板以保持图像的稳定显示。
- 调试和优化:在完成驱动程序的编写后,需要进行调试和优化,确保 LCD 显示屏能够正常工作。调试过程中可能需要使用示波器、逻辑分析仪等工具来监测信号的时序和电平,以发现和解决问题。同时,还可以对驱动程序进行优化,提高显示性能和效率。
做项目中碰到哪些问题
在嵌入式项目开发过程中,可能会遇到各种问题,以下是一些常见的问题:
一、硬件问题
- 电路设计错误:在硬件设计阶段,可能会出现电路设计错误,如电源连接错误、信号线路短路或开路、元件选型不当等。这些问题可能导致硬件无法正常工作,甚至损坏硬件。
- 焊接问题:在焊接过程中,可能会出现焊接不良的情况,如虚焊、短路、漏焊等。这些问题可能导致电路连接不稳定,影响硬件的性能和可靠性。
- 元件故障:硬件中的元件可能会出现故障,如芯片损坏、电容漏电、电阻值变化等。这些问题可能导致硬件无法正常工作,需要进行元件更换或维修。
- 电磁干扰:在嵌入式系统中,电磁干扰可能会影响硬件的性能和可靠性。例如,电源噪声、射频干扰等可能导致系统不稳定、数据传输错误等问题。
二、软件问题
- 编译器和开发工具问题:在软件开发过程中,可能会遇到编译器和开发工具的问题,如编译器错误、调试器不工作、开发环境配置错误等。这些问题可能导致软件开发进度受阻,需要花费时间解决。
- 代码错误:在编写代码过程中,可能会出现各种代码错误,如语法错误、逻辑错误、内存泄漏、指针错误等。这些问题可能导致程序无法正常运行,需要进行调试和修复。
- 驱动程序问题:在使用硬件设备时,可能需要编写驱动程序。驱动程序可能会出现问题,如不兼容、性能低下、不稳定等。这些问题可能导致硬件设备无法正常工作,需要进行驱动程序的调试和优化。
- 操作系统问题:在使用操作系统的嵌入式系统中,可能会遇到操作系统的问题,如内核崩溃、任务调度错误、内存管理问题等。这些问题可能导致系统不稳定,需要进行操作系统的调试和优化。
三、项目管理问题
- 需求变更:在项目开发过程中,可能会出现需求变更的情况。需求变更可能会导致项目进度延迟、成本增加、设计变更等问题。需要进行有效的需求管理,确保项目按照既定的目标进行。
- 进度管理问题:在项目开发过程中,可能会出现进度延迟的情况。进度延迟可能是由于各种原因引起的,如技术难题、人员短缺、资源不足等。需要进行有效的进度管理,确保项目按时完成。
- 团队协作问题:在项目开发过程中,需要多个团队成员协作完成。团队协作可能会出现问题,如沟通不畅、分工不合理、责任不明确等。需要进行有效的团队管理,确保团队成员之间能够良好地协作。
- 风险管理问题:在项目开发过程中,可能会出现各种风险,如技术风险、市场风险、法律风险等。需要进行有效的风险管理,识别和评估风险,并采取相应的措施降低风险的影响。
在项目中怎么考虑控制的实时性
在嵌入式项目中,实时性是一个非常重要的考虑因素。以下是在项目中考虑控制实时性的方法:
一、选择合适的硬件平台
- 处理器性能:选择具有足够处理能力的处理器,以满足实时控制的要求。处理器的时钟频率、指令集、缓存大小等因素都会影响其处理能力。
- 中断响应时间:确保处理器能够快速响应中断请求,以实现实时控制。中断响应时间包括中断延迟和中断处理时间。中断延迟是指从发生中断到处理器开始执行中断服务程序的时间,中断处理时间是指执行中断服务程序所需的时间。
- 外设性能:选择具有足够性能的外设,如定时器、计数器、模数转换器等。这些外设的性能会影响实时控制的精度和响应时间。
二、优化软件设计
- 实时操作系统:使用实时操作系统(RTOS)可以提高系统的实时性。RTOS 提供了任务调度、中断管理、时间管理等功能,可以确保实时任务能够及时执行。
- 任务优先级:为不同的任务分配不同的优先级,以确保实时任务能够优先执行。实时任务通常具有较高的优先级,以保证其能够在规定的时间内完成。
- 中断服务程序:编写高效的中断服务程序,以减少中断响应时间。中断服务程序应该尽量短小精悍,只执行必要的操作,避免长时间的阻塞。
- 算法优化:选择高效的算法和数据结构,以减少计算时间。例如,使用快速排序算法代替冒泡排序算法,可以提高排序的效率。
三、进行性能测试和优化
- 性能测试:在项目开发过程中,进行性能测试是非常重要的。性能测试可以帮助我们了解系统的实时性性能,发现潜在的性能问题。性能测试可以包括响应时间测试、吞吐量测试、负载测试等。
- 优化策略:根据性能测试的结果,采取相应的优化策略。优化策略可以包括硬件优化、软件优化、算法优化等。例如,如果发现系统的响应时间过长,可以考虑优化算法、增加硬件资源、使用更高效的编程语言等。
介绍项目的软件架构是怎么设计的
在嵌入式项目中,软件架构的设计是非常重要的。以下是一个嵌入式项目软件架构设计的示例:
一、需求分析
- 功能需求:明确项目的功能需求,包括输入输出、控制逻辑、通信协议等。
- 性能需求:确定项目的性能需求,如实时性、响应时间、吞吐量等。
- 可靠性需求:考虑项目的可靠性需求,如容错性、故障恢复能力等。
- 可维护性需求:确定项目的可维护性需求,如代码可读性、可扩展性、可测试性等。
二、架构设计
- 分层架构:采用分层架构可以将软件系统分为不同的层次,每个层次负责不同的功能。常见的分层架构包括硬件驱动层、操作系统层、中间件层、应用层等。
- 模块化设计:将软件系统划分为多个模块,每个模块负责一个特定的功能。模块化设计可以提高软件的可维护性和可扩展性。
- 通信机制:设计合适的通信机制,以实现不同模块之间的通信。常见的通信机制包括函数调用、消息传递、共享内存等。
- 异常处理:设计完善的异常处理机制,以确保系统在出现异常情况时能够正确处理。异常处理机制应该包括错误检测、错误报告、错误恢复等功能。
三、实现与测试
- 编码实现:根据软件架构设计,进行编码实现。在编码过程中,应该遵循良好的编程规范,提高代码的可读性和可维护性。
- 单元测试:对每个模块进行单元测试,以确保模块的功能正确。单元测试可以使用自动化测试工具,提高测试效率。
- 集成测试:对整个软件系统进行集成测试,以确保不同模块之间的通信正常。集成测试可以使用模拟环境或实际硬件进行测试。
- 系统测试:对整个系统进行系统测试,以确保系统满足功能需求和性能需求。系统测试可以包括功能测试、性能测试、可靠性测试等。
四、维护与优化
- 软件维护:在项目上线后,需要进行软件维护,以确保系统的正常运行。软件维护包括错误修复、功能升级、性能优化等。
- 性能优化:根据系统的实际运行情况,进行性能优化。性能优化可以包括算法优化、代码优化、硬件优化等。
- 可扩展性设计:在软件架构设计中,应该考虑系统的可扩展性,以便在未来的需求变化中能够轻松地进行功能扩展。可扩展性设计可以包括模块化设计、插件机制、接口设计等。
使用过 git 吗?有没有写过自己代码的技术文档?
我使用过 Git。Git 是一个非常强大的版本控制系统,它可以帮助开发者有效地管理代码的版本、协作开发以及跟踪代码的变更历史。
在使用 Git 的过程中,我熟悉了常见的操作,如初始化仓库、添加文件、提交更改、创建分支、合并分支等。通过分支管理,我可以在不影响主分支的情况下进行新功能的开发或修复 bug,然后在合适的时候将分支合并回主分支。
关于写自己代码的技术文档,我有过这样的经历。技术文档对于代码的维护和团队协作非常重要。在编写技术文档时,我会首先对项目进行整体的介绍,包括项目的背景、目标和主要功能。然后,对于每个重要的模块或功能,我会详细描述其设计思路、输入输出、关键算法和数据结构等。对于代码中的一些复杂逻辑或特殊情况,我也会进行特别说明,以帮助其他开发者更好地理解代码。
例如,在一个嵌入式项目中,我为一个传感器数据采集和处理的模块编写了技术文档。文档中包括了传感器的类型、连接方式、数据采集的频率和精度要求等信息。对于数据处理部分,我详细描述了采用的算法和数据结构,以及如何对异常数据进行处理。此外,我还提供了一些示例代码和使用说明,以便其他开发者能够快速上手使用这个模块。
总之,使用 Git 和编写技术文档都是软件开发过程中非常重要的环节,它们可以提高开发效率、保证代码质量和促进团队协作。
了解 C++ 吗?若不了解,可说明不了解的原因。
我了解 C++。C++ 是一种广泛使用的编程语言,具有强大的功能和灵活性。
C++ 在 C 语言的基础上增加了许多面向对象的特性,如类、对象、继承、多态等。这些特性使得 C++ 在开发大型软件项目时更加方便和高效。C++ 还支持泛型编程和模板,这使得代码可以更加通用和可重用。
C++ 的标准库也非常丰富,提供了许多实用的功能,如输入输出流、容器、算法等。这些功能可以大大减少开发者的工作量,提高开发效率。
在实际应用中,C++ 被广泛用于游戏开发、操作系统开发、嵌入式系统开发等领域。它可以直接操作硬件资源,具有高效的性能和较低的内存占用。
总之,C++ 是一种非常强大的编程语言,具有广泛的应用前景。对于开发者来说,掌握 C++ 可以提高自己的竞争力和开发能力。
指针和引用的区别是什么?
指针和引用在 C++ 中都是用于间接访问对象的机制,但它们有一些重要的区别。
一、定义和语法
- 指针:指针是一个变量,它存储了另一个对象的内存地址。指针的定义需要指定指向的对象类型,例如 “int* ptr;” 定义了一个指向整数的指针。指针可以通过取地址运算符 “&” 获取对象的地址,通过解引用运算符 “*” 访问指针所指向的对象。
- 引用:引用是一个对象的别名,它在定义时必须初始化,并且一旦初始化就不能再改变指向其他对象。引用的定义不需要指定类型,只需要在变量名前加上 “&”,例如 “int& ref = var;” 定义了一个名为 “ref” 的引用,它是变量 “var” 的别名。引用可以像普通变量一样使用,不需要解引用操作。
二、内存分配和存储方式
- 指针:指针本身在内存中占用一定的空间,存储了所指向对象的地址。指针可以指向不同的对象,也可以为 nullptr,表示不指向任何对象。
- 引用:引用本身不占用额外的内存空间,它只是所引用对象的别名。引用必须始终指向一个有效的对象,不能为 nullptr。
三、功能和使用场景
- 指针:指针具有更大的灵活性,可以进行动态内存分配、指向不同的对象、进行指针运算等。指针在处理复杂的数据结构、实现动态数据结构(如链表、树等)以及与 C 语言代码交互时非常有用。
- 引用:引用主要用于函数参数传递和返回值,它可以避免对象的复制,提高函数调用的效率。引用在需要修改函数外部的对象、实现函数重载以及传递大型对象时非常方便。
四、安全性
- 指针:由于指针可以指向任意内存地址,如果使用不当,可能会导致内存访问错误、悬空指针、内存泄漏等问题。指针的使用需要开发者非常小心,进行正确的内存管理。
- 引用:引用在使用上相对更安全,因为它始终指向一个有效的对象,不会出现悬空指针的问题。引用的使用也更加直观,减少了错误的可能性。
总之,指针和引用在 C++ 中有不同的用途和特点。开发者需要根据具体的需求选择合适的方式来间接访问对象,以提高代码的效率和安全性。
static 的用法有哪些?
在 C++ 中,“static” 关键字有以下几种主要用法:
一、静态局部变量
在函数内部定义的静态局部变量,在程序执行期间只会被初始化一次,并且其生存期贯穿整个程序的运行。即使函数被多次调用,静态局部变量也会保持其值。
例如:
void func() {static int count = 0;count++;std::cout << "Count: " << count << std::endl;
}
每次调用 “func” 函数时,“count” 的值都会递增,但在不同的函数调用之间,“count” 的值会被保留。
二、静态全局变量
静态全局变量在整个程序中只有一个实例,并且只能在定义它的文件中被访问。其他文件不能直接访问静态全局变量,这有助于避免命名冲突和提高代码的封装性。
例如:
// file1.cpp
static int globalVar = 10;void func1() {std::cout << "Global var in file1: " << globalVar << std::endl;
}
// file2.cpp
// 这里无法直接访问 file1.cpp 中的 globalVar
void func2() {// std::cout << "Global var: " << globalVar << std::endl; // 错误
}
三、静态成员变量
在类中定义的静态成员变量属于整个类而不是类的某个特定对象。所有类的对象共享同一个静态成员变量。静态成员变量在类的外部进行初始化,并且可以通过类名直接访问。
例如:
class MyClass {
public:static int staticVar;
};int MyClass::staticVar = 0;void func() {MyClass obj1;MyClass obj2;obj1.staticVar = 10;std::cout << "obj2.staticVar: " << obj2.staticVar << std::endl; // 输出 10
}
四、静态成员函数
静态成员函数属于整个类而不是类的某个特定对象。它可以直接通过类名调用,不需要通过类的对象来调用。静态成员函数不能访问非静态成员变量和非静态成员函数,因为它不与特定的对象相关联。
例如:
class MyClass {
public:static void staticFunc() {std::cout << "Static function called." << std::endl;}
};void func() {MyClass::staticFunc();
}
堆和栈的区别是什么?(出现了多次,归为一类)
堆和栈是程序运行时内存中的两个不同区域,它们有以下区别:
一、内存分配方式
- 栈:栈是由编译器自动管理的内存区域。当一个函数被调用时,函数的局部变量、参数等会在栈上分配内存。栈的内存分配是自动的,并且按照先进后出的顺序进行。当函数执行完毕后,栈上的内存会自动被释放。
- 堆:堆是由程序员手动管理的内存区域。程序员可以使用动态内存分配函数(如 “new” 和 “malloc”)在堆上分配内存。堆上的内存分配是动态的,程序员需要负责在合适的时候释放堆上的内存,否则会导致内存泄漏。
二、内存大小和增长方式
- 栈:栈的大小通常是有限的,并且在不同的操作系统和编译器中可能有所不同。栈的增长方向是从高地址向低地址。当栈的空间不足时,可能会导致栈溢出错误。
- 堆:堆的大小通常比栈大得多,并且可以在运行时动态扩展。堆的增长方向是从低地址向高地址。
三、存储内容和使用场景
- 栈:栈主要用于存储函数的局部变量、参数、返回地址等。栈的访问速度非常快,因为它的内存分配和释放是由编译器自动管理的。栈适合存储临时的、小尺寸的数据。
- 堆:堆主要用于存储动态分配的对象和数据结构。堆的使用场景比较灵活,可以根据程序的需要动态地分配和释放内存。堆适合存储大尺寸的数据或者需要在程序运行过程中动态创建和销毁的数据。
四、内存管理方式
- 栈:栈的内存管理是自动的,由编译器负责。程序员不需要手动管理栈上的内存,这减少了出错的可能性。
- 堆:堆的内存管理是手动的,程序员需要使用动态内存分配函数来分配内存,并在合适的时候使用 “delete” 或 “free” 函数来释放内存。如果程序员没有正确地管理堆上的内存,可能会导致内存泄漏、悬空指针等问题。
总之,堆和栈在内存分配方式、大小和增长方式、存储内容和使用场景以及内存管理方式等方面都有很大的区别。程序员需要根据具体的需求选择合适的内存区域来存储数据。
如何用 C 实现多线程?
在 C 语言中,可以使用操作系统提供的多线程库来实现多线程编程。以下是一种在 Linux 系统下使用 POSIX 线程库(pthreads)实现多线程的方法:
一、包含头文件
首先,需要包含 “pthread.h” 头文件,这个头文件包含了 POSIX 线程库的函数和数据类型的定义。
#include <pthread.h>
二、定义线程函数
定义一个函数作为线程的执行体。这个函数的参数和返回值类型都是 “void*”,可以根据需要进行类型转换。
void* threadFunction(void* arg) {// 线程执行的代码return NULL;
}
三、创建线程
在主函数中,可以使用 “pthread_create” 函数来创建一个新的线程。这个函数接受四个参数:线程标识符、线程属性、线程函数和线程函数的参数。
int main() {pthread_t thread;int arg = 10;pthread_create(&thread, NULL, threadFunction, &arg);// 主线程执行的代码return 0;
}
四、等待线程结束
可以使用 “pthread_join” 函数来等待一个线程结束。这个函数接受两个参数:线程标识符和一个指向 “void*” 的指针,用于接收线程的返回值。
int main() {pthread_t thread;int arg = 10;pthread_create(&thread, NULL, threadFunction, &arg);void* result;pthread_join(thread, &result);// 主线程执行的代码return 0;
}
在使用多线程编程时,需要注意线程之间的同步和互斥问题,以避免数据竞争和不一致性。可以使用互斥锁、条件变量等机制来实现线程之间的同步。
总之,在 C 语言中可以使用 POSIX 线程库来实现多线程编程。多线程编程可以提高程序的并发性和性能,但也需要注意线程安全和同步问题。
用过 C++ 哪些容器?
在 C++ 中,标准库提供了多种容器类,用于存储和管理不同类型的数据。我使用过以下一些 C++ 容器:
一、vector
“vector” 是一种动态数组容器,可以存储任意类型的对象。它具有自动扩容的功能,当元素数量超过当前容量时,会自动分配更大的内存空间并将元素复制到新的空间中。“vector” 提供了随机访问、插入和删除元素等操作,非常方便。
例如:
#include <iostream>
#include <vector>int main() {std::vector<int> vec;vec.push_back(10);vec.push_back(20);vec.push_back(30);std::cout << "Vector elements: ";for (int element : vec) {std::cout << element << " ";}std::cout << std::endl;return 0;
}
二、list
“list” 是一种双向链表容器,适用于频繁进行插入和删除操作的场景。与 “vector” 不同,“list” 在插入和删除元素时不会导致其他元素的移动,因此效率较高。“list” 提供了双向迭代器,可以方便地遍历链表中的元素。
例如:
#include <iostream>
#include <list>int main() {std::list<int> lst;lst.push_back(10);lst.push_back(20);lst.push_back(30);std::cout << "List elements: ";for (int element : lst) {std::cout << element << " ";}std::cout << std::endl;return 0;
}
三、map
“map” 是一种关联容器,用于存储键值对。它根据键的大小自动进行排序,并提供了高效的查找、插入和删除操作。“map” 可以使用不同的类型作为键和值,非常灵活。
例如:
#include <iostream>
#include <map>int main() {std::map<std::string, int> myMap;myMap["apple"] = 5;myMap["banana"] = 3;myMap["orange"] = 7;std::cout << "Number of apples: " << myMap["apple"] << std::endl;return 0;
}
四、set
“set” 是一种集合容器,用于存储唯一的元素。它自动对元素进行排序,并提供了高效的查找、插入和删除操作。“set” 可以使用不同的类型作为元素,非常方便。
例如:
#include <iostream>
#include <set>int main() {std::set<int> mySet;mySet.insert(10);mySet.insert(20);mySet.insert(10); // 重复元素不会被插入std::cout << "Set elements: ";for (int element : mySet) {std::cout << element << " ";}std::cout << std::endl;return 0;
}相关文章:

科大讯飞嵌入式面试题及参考答案
平衡二叉树和普通二叉树的区别 平衡二叉树是一种特殊的二叉树,与普通二叉树相比有以下显著区别: 一、定义与结构 普通二叉树:二叉树是每个节点最多有两个子树的树结构。它没有特定的平衡要求,节点的分布可能比较随机。例如&#x…...

C Lua5.4.6 SDK开发库
下载 .lua执行 #include "lua.h" #include "lualib.h" #include "lauxlib.h"static int luaopen_ui(lua_State *L) {static const struct luaL_Reg lib_f[] = {{"saveFile", saveFile},{"loadFile", loadFile},{NULL, NULL…...
)
无线网卡知识的学习-- wireless基础知识(cfg80211)
1. 基本概念 mac80211 :这是最底层的模块,与hardware offloading 关联最多。 mac80211 的工作是给出硬件的所有功能与硬件进行交互。(Kernel态) cfg80211:是设备和用户之间的桥梁,cfg80211的工作则是观察跟踪wlan设备的实际状态. (Kernel态) nl80211: 介于用户空间与内核…...
)
Next.js 学习 - 路由系统(Routing)
Next.js 的路由系统基于文件系统,这意味着文件和文件夹的结构决定了 URL 路径。相较于传统的 React 应用中的路由配置,Next.js 的文件路由系统非常简洁和自动化。下面是对 Next.js 路由的详细介绍。 1. 目录结构 在 Next.js 13 中,app 目录…...

Unity XR PICO 手势交互 Demo APK
效果展示 用手抓取物体,调整物体位置和大小等 亲测pico4 企业版可用, 其他设备待测试 下载链接: 我标记的不收费 https://download.csdn.net/download/qq_35030499/89879333...

EM算法学习
1.EM算法的介绍 可以发现:计算出θA和θB的值的前提是知道A、B币种的抛掷情况。 所以我们需要使用EM算法:求出每轮选择硬币种类的概率 2.EM算法执行过程: 第一步:首先初始化设置一组PA和PB证明的值。然后通过最大似然估计得到每…...

019_基于python+django食品销售数据分析系统2024_4032ydxt
目录 系统展示 开发背景 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...

C语言笔记(数据的存储篇)
目录 1.数据类型的详细介绍 2.整型在内存中的存储:原码、反码、补码 3.大小端字节序介绍及判断 4.浮点型的内存中的存储解析 1.数据类型的详细介绍 下述是内置类型: char // 字符数据类型 short // 短整型 int // 整型 long …...

wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理的解决方法
前言 开头先讲讲wsl2启用代理的必要性,一般来说,会用wsl的都是开发者,那么就避免不了从网络上下载软件和应用,但是由于众所周知的原因,你使用apt,wget等工具下载国外网站的东西时,下载速度就会…...

CSS 居中那些事
一、父子元素高度确定 简单粗暴, 直接通过设置合适的 padding 或 margin 实现居中 <style>.p {padding: 20px 0;background: rgba(255, 0, 0, 0.1);}.c {width: 40px;height: 20px;background: blue;} </style> <div class"p"><div class"…...

Java项目-基于springboot框架的智能热度分析和自媒体推送平台项目实战(附源码+文档)
作者:计算机学长阿伟 开发技术:SpringBoot、SSM、Vue、MySQL、ElementUI等,“文末源码”。 开发运行环境 开发语言:Java数据库:MySQL技术:SpringBoot、Vue、Mybaits Plus、ELementUI工具:IDEA/…...

跨平台进程池背后的思想
背景是基于业务需求,需要实现一个跨平台的项目。项目中由于有部分功能存在大量计算,所以打算单独分配一个进程去进行计算。 进程池的实现与线程池的实现逻辑上如出一辙。但是实现上进程池的实现会比线程池实现复杂的多,主要比较复杂的点的就在于并发安全的任务队列。…...

前端性能优化之加载篇
前端页面加载的过程其实跟我们常常提起的浏览器页面渲染流程几乎一致: 网络请求,服务端返回 HTML 内容。 浏览器一边解析 HTML,一边进行页面渲染。 解析到外部资源,会发起 HTTP 请求获取,加载 Javascript 代码时会暂停页面渲染。 根据业务代码加载过程,会分别进入页面开始…...
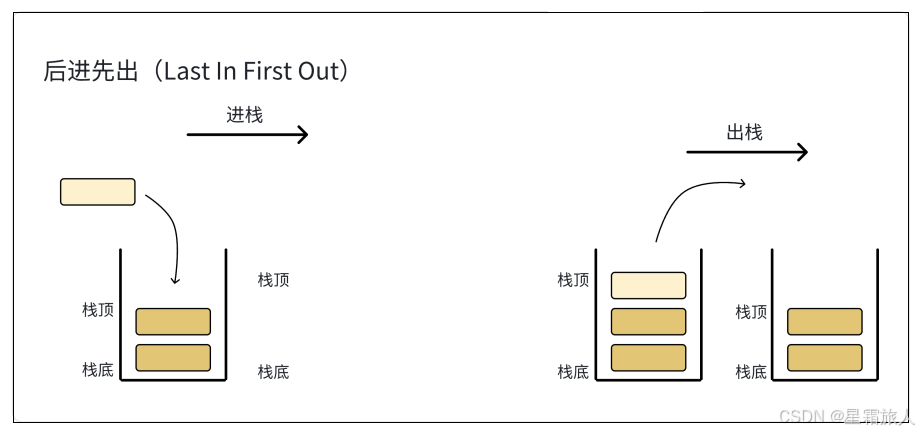
数据结构(栈)
每当误会消除冰释前嫌的时候,故事就距离结尾不远了。 栈 概念与结构 1. 栈⼀种特殊的线性表,其只允许在固定的⼀端进行插入和删除元素操作。 2. 进行数据插入和删除操作的⼀端称为栈顶,另⼀端称为栈底。 3. 栈中的数据元素遵守后进先出的原则…...
Aspose.PDF功能演示:使用 JavaScript 从 PDF 中提取文本
在数据提取、业务文档自动化和文本挖掘方面,使用 JavaScript 从PDF中提取文本非常有用。它允许开发人员自动执行从 PDF 收集信息的过程,从而显著提高处理大量文档的生产力和效率。在这篇博文中,我们将学习如何使用 JavaScript 从 PDF 中提取文…...

计算机系统简介
一、计算机的软硬件概念 1.硬件:计算机的实体,如主机、外设、硬盘、显卡等。 2.软件:由具有各类特殊功能的信息(程序)组成。 系统软件:用来管理整个计算机系统,如语言处理程序、操作系统、服…...

学习文档10/18
MySQL高性能优化规范: 数据库命名规范 所有数据库对象名称必须使用小写字母并用下划线分割所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)数据库对象的命名要能做到见名识意…...

Redis入门到精通(二):入门Redis看这一篇就够了
文章目录 一、Redis的双写一致性1.延迟双删2.添加分布式锁3.异步监听可靠消息基于MQ消息队列的异步监听基于Canal的异步通知 二、Redis的持久化持久化流程1.RDB机制1.1save1.2bgsave1.3自动触发 2.AOF机制三种触发机制3.RDB和AOF的对比 三、Redis的数据删除策略1.惰性删除2.定期…...

荒岛逃生游戏
题目描述 一个荒岛上有若干人,岛上只有一条路通往岛屿两端的港口,大家需要逃往两端的港口才可逃生。 假定每个人移动的速度一样,且只可选择向左或向右逃生。 若两个人相遇,则进行决斗,战斗力强的能够活下来ÿ…...

玫瑰花HTML源码
HTML源码 <pre id"tiresult" style"font-size: 9px; background-color: #000000; font-weight: bold; padding: 4px 5px; --fs: 9px;"><b style"color:#000000">0010000100000111101110110111100010000100000100001010111111100110…...

Fish Speech 1.5企业应用:会议纪要自动转语音播报方案
Fish Speech 1.5企业应用:会议纪要自动转语音播报方案 1. 企业会议纪要处理的痛点与解决方案 在日常企业运营中,会议纪要的整理和传达往往面临三大挑战: 效率瓶颈:人工整理会议录音平均耗时1-2小时/场,关键信息传递…...

5分钟快速上手labelCloud:轻量级3D点云标注工具的完整指南
5分钟快速上手labelCloud:轻量级3D点云标注工具的完整指南 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 你是否正在寻找一款简单易用、功能强…...
)
集合进阶二 (Set Map Steam流)
一.Set集合1.特点注意:无序不是每次执行出来的结果都是不一样的-------------(默认升序)2.HashSet集合的底层原理(基于哈希表)(1)哈希表eg.冲突是必然的 只能去降低冲突率(1…...

郭老师-人生四次开悟:错过一次,代价沉重
人生四次开悟 ——错过一次,可能一生难返“人这一生,大约只有四次开悟的机会。 开悟不了的人,就‘玩完了’。”🌿 开悟不是玄学, 而是—— 在关键年龄点上, 看清世界、认清自己、与道合一。🌱 第…...

类、实例、成员与子类:四个最容易混淆的基础概念
在知识表示、知识图谱和本体建模中,“类”“实例”“成员”“子类”是最常用的几个基础概念,也是最容易混淆的一组概念。很多初学者会把“实例”和“成员”混为一谈,把“子类关系”和“成员关系”混为一谈,甚至把“类”和“实例”…...

高效工作方法论:六大核心SOP详解
我们首先来看第一个SOP:如何正确地接收任务。这不仅仅是简单地说一句“收到”,而是一个从接收到最终交付的完整闭环管理过程。 第一步是“精准接收”,重点在于明确目标和标准,确认时限和资源,拒绝模糊指令。 第二步是…...

中兴光猫工厂模式终极开启指南:zteOnu工具完整使用教程
中兴光猫工厂模式终极开启指南:zteOnu工具完整使用教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否遇到过想要调整中兴光猫的高级设置,却发现普通用户…...

#VCS# 实战指南:利用 +fsdb+skip_cell_instance 精准控制库信号 dump 策略
1. 为什么你需要关心库信号的 dump 策略? 如果你用过 VCS 跑过稍微大一点的芯片仿真,尤其是带上了标准单元库的后仿,我猜你一定经历过这种绝望:仿真跑得比蜗牛还慢,好不容易跑完了,一看生成的 FSDB 波形文…...

Cuvil加速PyTorch模型推理:3大编译策略、2类IR优化陷阱与1套量化部署 checklist
第一章:Cuvil加速PyTorch模型推理:3大编译策略、2类IR优化陷阱与1套量化部署 checklistCuvil 是一个面向 PyTorch 生态的高性能模型编译器,专为边缘与云上低延迟推理场景设计。其核心能力在于将 TorchScript 或 FX Graph 表示的模型ÿ…...

《东方星动》“一路有你”公益行走进云南宾川县上沧完小
春风送暖,爱意流淌。4月3日,云南省大理白族自治州宾川县上沧完小校园内,一场以“爱心筑梦情暖校园”为主题的捐赠仪式温暖举行。这是《东方星动》“一路有你”公益行团队继湖南平江之后,再次跨越千里,将艺术的种子播撒…...