【论文阅读】03-Diffusion Models and Representation Learning: A Survey
Abstract(摘要)

- 扩散模型是各种视觉任务中流行的生成建模方法,引起了人们的广泛关注
- 它们可以被认为是 自监督学习方法【通过数据本身的结构和特征来训练模型,而不是依赖外部标签】 的一个独特实例,因为它们独立于标签注释
- 本研究探讨了扩散模型与表征学习之间的相互作用
- 它提供了扩散模型的基本方面的概述,包括数学基础,流行的去噪网络架构和指导方法
- 详细介绍了与扩散模型和表征学习相关的各种方法
- 其中包括利用从预训练扩散模型中学习到的表征来完成后续识别任务的框架,以及利用表征和自我监督学习的进步来增强扩散模型的方法
- 本研究旨在全面概述扩散模型和表示学习之间的分类,确定现有关注和潜在探索的关键领域。Github链接如上
1 Introduction(引言)

- 扩散模型[68,151,154] 最近作为最先进的生成模型出现,在 图像合成[43,67,68,141] 和 其他模式(包括自然语言[9,70,77,101],计算化学[6,71]和音频合成[80,92,109]) 中显示出显著的结果。
- 扩散模型显著的生成能力表明,扩散模型可以学习其输入数据的低级和高级特征,这可能使它们非常适合于一般表征学习。
- 与生成对抗网络(GANs)[22,53,84] 和 变分自编码器(VAEs)[88,137] 等其他生成模型不同,扩散模型不包含捕获数据表示的固定架构组件[124]
- 这使得基于扩散模型的表示学习具有挑战性
- 然而,利用扩散模型进行表示学习的方法越来越受到关注,同时受到扩散模型训练和采样技术进步的推动

- 目前最先进的 自监督表示学习方法[8,24,33,55] 已经证明了很大的可扩展性
- 因此,扩散模型很可能表现出类似的缩放特性[159]。
- 用于获得最先进生成结果的 分类器制导[43] 和 无分类器制导[67] 等受控生成方法依赖于带注释的数据,这是扩展扩散模型的瓶颈
- 分类器制导(Classifier-Guided):
- 在目标检测或识别任务中,利用一个
分类器来指导目标的定位和识别过程。具体来说,分类器会预测目标的类别,并根据这些类别信息来指导目标检测或识别的过程。- 无分类器制导(Non-classifier-Guided):
- 在目标检测或识别任务中,
不使用分类器来指导目标的定位和识别过程。相反,模型会自行学习目标的特征和位置信息,而不依赖外部的分类器。- 无分类器制导的方法通常会要求模型在没有类别标签的情况下进行目标检测或识别,这需要模型具有更强的特征学习和定位能力。
- 利用表示学习的指导方法提供了一个解决方案,因此无需注释,可能使扩散模型在更大的,无注释的数据集上训练模型

- 本文旨在阐明扩散模型与表征学习之间的关系和相互作用。
- 我们强调了两个中心观点:使用扩散模型本身进行表征学习和使用表征学习来改进扩散模型
- 我们介绍了当前方法的分类法,并推导出展示当前方法之间共性的广义框架
- 自Ho等人[68]、SohlDickstein等人[151]、Song等人[154] 提出扩散模型以来,探索扩散模型的表示学习能力的兴趣不断增长

如图1所示,我们预计这一趋势今年将继续下去。- 关于扩散模型和表示学习的出版作品数量的增加使得研究人员更难以确定最先进的方法并保持当前的发展
- 这可能会阻碍该领域的进展,这就是为什么我们认为需要进行全面的概述和分类

图1所示,展示了关于扩散模型和表示学习的已发表和预印本论文的年度数量。对于2024年,绿色条表示截至2024年6月(含2024年6月)收集的论文数量,灰色虚线表示全年的预测数量

- 表征学习和扩散模型的研究还处于起步阶段。
- 许多当前的方法依赖于使用扩散模型,仅训练生成合成用于表示学习。
- 因此,我们假设未来在这一领域有进一步发展的重要机会,并且扩散模型可以越来越多地挑战当前表征学习的最新技术。
图2显示了现有方法的定性结果。我们希望这项调查能够通过澄清当前方法之间的共性和差异,为基于扩散的表征学习的进步做出贡献。- 综上所述,本文的主要贡献如下:
- 全面概述:对扩散模型和表征学习之间的相互作用进行了全面的调查,明确了扩散模型如何用于表示学习,反之亦然
- 方法分类:我们介绍了目前基于扩散的表征学习方法的分类,并强调了它们之间的共性和差异。
- 广义框架:本文推导了扩散模型特征提取和基于分配的指导的广义框架,对扩散模型和表征学习的大量工作提供了结构化的视图
- 未来方向:我们确定了该领域进一步发展的关键机会,鼓励将扩散模型和流动匹配作为表征学习的新技术进行探索

图2所示。左图:显示使用自监督制导信号条件反射的扩散模型的定性生成结果。右图:显示下游图像任务的定性结果,这些任务利用了在训练扩散模型中学习到的表征。改编自Li等人[100],Hu等人[73],Pan等人[130],Baranchuk等人[15],Yang和Wang[173]
2 BACKGROUND(背景)

- 下一节概述了扩散模型所需的数学基础。
- 我们还重点介绍了扩散模型的当前架构骨干,并简要概述了采样方法和条件生成方法
2.1 Mathematical Foundations(数学基础)

- 考虑从潜在概率分布 p ( x ) p(x) p(x)中提取的一组训练示例。
- 生成扩散模型背后的思想是学习一种去噪过程,将随机噪声的样本映射到从p(x)中采样的新图像[133]
- 为了达到这个目的,图像被逐渐添加不同程度的高斯噪声破坏
- 给定一个
未损坏的训练样本 x 0 x_{0} x0~ p ( x ) p(x) p(x),其中索引 0 0 0 表示样本未损坏,则损坏的样本 x 1 , x 2 … , x T x_1, x_2…, x_T x1,x2…,xT 是根据马尔可夫过程生成的 - 转换内核 p ( x t ∣ x t − 1 ) p(x_t|x_{t−1}) p(xt∣xt−1)的一个常见选择如下

1式中
- T T T 为扩散时间步数, β t β_t βt 为随时间变化的方差表, I I I为维数为 x 0 x_0 x0的单位矩阵[37]。
- 注意,转换核 p ( x t ∣ x t − 1 ) p(x_t|x_{t−1}) p(xt∣xt−1) 的其他参数化也以同样的方式适用[87,188]
公式1详解:
- 这个公式描述了扩散过程中的一步,从状态 x t − 1 x_{t−1} xt−1 转移到 x t x_t xt的概率
- X t X_t Xt是第t步的图像,里面左边部分就是他的均值,右半部分是他的方差, I I I是单位矩阵,表示独立的噪声
- β t β_t βt是扩散的过程时间步长 依赖的噪声参数,随着t增大,使得噪声逐渐增加 的概率分布
类比:
- 可以将图像看作是一个点球的颜色,随着时间 𝑡 的推移,球的颜色逐渐变模糊,直到最后完全变成噪声(一个随机的颜色点)。
- 公式 (1) 就是描述如何根据上一时刻 𝑥 𝑡 − 1 𝑥_{𝑡 − 1} xt−1的图像,再加上一些噪声,生成下一时刻 𝑥 𝑡 𝑥_𝑡 xt 的图像。

- 我们继续讨论ddpm[68] 中使用的参数化,以简化后续的讨论。
- 在重参数化技巧的帮助下,可以直接从 X 0 X_0 X0采样噪声图像 X t [ 151 ] X_t[151] Xt[151],方法如
式子2 - α t : = 1 − β t , α ¯ t α_t:= 1−β_t, α¯_t αt:=1−βt,α¯t:= ∏ i = 1 t α i \prod_{i=1}^t α_i ∏i=1tαi。
- 给定原始输入图像 x 0 x_0 x0,我们现在可以通过对高斯向量 ϵ t ϵ_t ϵt ~ N ( 0 , I ) N(0, I) N(0,I)采样并应用以下方法一步获得 x t x_t xt:
式子3 - 我们可以从一个维度等于数据的纯噪声图像 x T x_T xT ~ π ( x T ) = N ( 0 , I ) π(x_T) = N(0, I) π(xT)=N(0,I)开始,从 p ( x 0 ) p(x_0) p(x0) 生成新的样本,并对其进行顺序去噪
- 使得在每一步, p θ ( X t − 1 ∣ X t ) = N ( X t − 1 ; µ θ ( X t , t ) , Σ θ ( X t , t ) ) p_θ(X_{t−1}| X_t) =N (X_{t−1};µ_θ(X_t, t), Σ_θ(X_t, t)) pθ(Xt−1∣Xt)=N(Xt−1;µθ(Xt,t),Σθ(Xt,t))
公式2解释
- 这个公式可以直接从最初的无噪声图像 X 0 X_0 X0 (训练数据中的原始图像)生成第 𝑡 步的图像 X 𝑡 X_𝑡 Xt
𝛼ˉ𝑡是从 𝑡=1到 𝑡 的一系列 𝛼𝑡的累积乘积,用来控制噪声的总量- 同样,根号部分表示均值,后面部分表示方差这意味着 X t X_t Xt是 X 0 X_0 X0的带噪版本,噪声的程度取决于 𝑡
类比
- 在 t=0 时有一张非常清晰的照片,然后在经过 t个时间步之后,这张照片会变得模糊,
- 增加了随机噪声,这个过程可以通过公式 (2) 直接一步计算出来
公式3解释
- 这是一个具体的采样公式,它告诉我们如何从原始图像 X 0 X_0 X0生成 X t X_t Xt,并且加入了噪声 ϵ t ϵ_t ϵt ,其中Font metrics not found for font: .表示标准正态分布的随机噪声。
- 你可以将这个公式看作是将原始图像 X 0 X_0 X0和噪声 ϵ t ϵ_t ϵt按照一定的比例结合,生成带噪声的图像 X t X_t Xt
类比:
- 假设有一张清晰的图像 ,通过公式 (3),将一部分图像内容保留原始内容(即式子左半部分),同时加入一部分随机噪声(式子右半部分),生成一个带噪声的中间图像 x t x _t xt
- 可以想象一下后面的部分,希望能在我给了一张纯噪声的图片下,我需要把它还原成 X 0 X_0 X0,注意这个部分最后概率公式 p θ ( X t − 1 ∣ X t ) p_θ(X_{t−1}| X_t) pθ(Xt−1∣Xt) ,和式子1是完全相反的。式子1是 p ( X t ∣ X t − 1 ) p(X_t|X_{t−1}) p(Xt∣Xt−1)
式子1是增加噪声,这个部分是去除噪声

- 在实践中,这需要训练一个神经网络 p θ ( X t − 1 ∣ X t ) p_θ(X_{t−1}|X_t) pθ(Xt−1∣Xt) ,该网络在给定扩散时间步长t和噪声输入图像 x t x_t xt 的情况下预测平均值 µ 0 ( X t , t ) µ_0(X_t, t) µ0(Xt,t)和协方差 Σ θ ( X t , t ) [ 172 ] Σ_θ(X_t, t)[172] Σθ(Xt,t)[172]
- 用最大似然目标训练这种神经网络是很棘手的[37],因此将目标修改为最小化负对数似然的变分下界[68,151]
式子4 - 其中 D K L DKL DKL是KL散度。这一目标确保了当条件为 x 0 x_0 x0时,神经网络被训练成最小化 p θ ( X t − 1 ∣ X t ) p_θ(X_{t−1}|X_t) pθ(Xt−1∣Xt) 与前向过程的真实后验之间的距离
- 降噪网络一般用于参数化逆跃迁 p θ ( X t − 1 ∣ X t ) p_θ(X_{t−1}|X_t) pθ(Xt−1∣Xt) 分布的逆均值 µ θ ( X , t ) µ_θ(X, t) µθ(X,t):= N ( X t − 1 ; µ θ ( X t , t ) , Σ θ ( X t , t ) ) [ 27 ] N (X_{t−1};µ_θ(X_t, t), Σ_θ(X_t, t))[27] N(Xt−1;µθ(Xt,t),Σθ(Xt,t))[27]
公式4解释:
- 首先这个是损失函数,用来训练生成扩散模型中的神经网络 P θ ( X t − 1 ∣ X t ) P_θ(X_{t−1}|X_t) Pθ(Xt−1∣Xt),使其能够有效地逆向去噪,生成目标图像
- 为什么要这么做?是在写代码pytorch等框架当中,就必须要需要这些套路。可以理解为必要步骤:1、搭建网络模型->2、加载数据集->3、训练数据->4、计算损失函数->5、优化器优化->6、反向传播
- 该损失函数有三个部分组成,
- 第一部分:直接最大化预测 X 0 X_0 X0的对数概率。这确保网络能够生成逼近真实图像 x 0 x_0 x0的结果
- 第二部分: 用来度量模型在 T T T步时生成的噪声图像 X T X_T XT与标准高斯噪声 π ( X T ) π(X_T) π(XT)的距离。通过最小化这个散度,网络学会生成噪声 x T x _T xT是从高斯分布中采样的(确保噪声是在一定范围之内的)
- 第三部分: 这个项是模型在每一步去噪过程中的损失,网络学习如何从 x t x_t xt恢复 x t − 1 x_{t−1} xt−1并让这个过程与原始扩散过程保持一致(去除噪声和增加噪声的方式也要维持在一定范围之内)
类比
- 这个损失函数理解为一个多步“修复”任务,即你每一步都有一个模糊的照片 x t x_t xt
- 你希望通过学习逆向过程,逐步恢复这张照片,直到恢复到最初的清晰照片 x 0 x_0 x0
- 损失函数中的每一项都确保神经网络能够在不同层面上逐步优化这个修复过程

- 反向均值的真实值是 X 0 X_0 X0的函数,它在反向过程中是未知的,因此必须使用输入时间步长t和噪声数据 X t X_t Xt来估计
- 具体来说,反向均值的公式
式子5- 其中原始数据 X 0 X_0 X0在反向过程中不可用,因此必须进行估计。
- 我们将去噪网络对原始数据的预测表示为 X ^ 0 \widehat{X}_0 X 0
- 这个预测 X ^ 0 \widehat{X}_0 X 0可以用公式5得到 µ θ ( X t , t ) µ_θ(X_t, t) µθ(Xt,t)
- 在采样开始时直接使用 X ^ 0 \widehat{X}_0 X 0进行参数化是有益的,因为直接预测 X ^ 0 \widehat{X}_0 X 0有助于去噪网络学习更高层次的结构特征[115]。
公式5解释:
- 定义了在去噪过程中,从 X t X_t Xt生成 X t − 1 X_{t−1} Xt−1时的均值 µ θ ( X t , t ) µ_θ(X_t, t) µθ(Xt,t)它描述了在每一步中,如何估计 X t − 1 X_{t−1} Xt−1(也就是“更干净”的图像)
- 在这个公式中: X t X_t Xt是当前时间步t的带噪图像。两个𝛼𝑡 是用于控制噪声大小的参数,它们随着时间步长 t t t改变。
通过从当前图像 x t x_t xt 减去一些噪声部分(和 x 0 x_0 x0相关的部分),模型能够预测出较少噪声的图像 X t − 1 X_{t−1} Xt−1类比:
- 其实每个图片也好,数据也好,其本质就是一个分布(用 X t X_t Xt表示),由 µ µ µ均值还有方差决定,可以把它看成减法公式
- 公式5就是是一个被减项,可以理解为 X t X_t Xt 减去某一项 = X t − 1 X_{t−1} Xt−1。这个某一项实际上就是一个均值,因为 X t X_t Xt和 X t − 1 X_{t−1} Xt−1是由 µ µ µ均值还有方差组成
- 公式 (5) 就是在计算每一步如何减去噪声,从而逐步恢复到清晰图像。我们要的就是被减项

- [68]建议将协方差 Σ θ ( x t , t ) Σθ(x_t, t) Σθ(xt,t)固定为一个恒定值,这样可以将参数化的逆均值重写为添加噪声的函数,而不是 X 0 X_0 X0
- 这种重新参数化允许推导出目标 L v l b L_{vlb} Lvlb的简化,我们表示 L s i m p l e L_{simple} Lsimple,它测量预测噪声 ϵ θ ( x t , t ) ϵ_θ(x_t, t) ϵθ(xt,t)与实际噪声 ϵ t ϵ_t ϵt之间的距离,如
式子7 - 代替直接预测均值和协方差,网络现在被参数化来预测扩散时间步和噪声图像输入的附加噪声。
- 逆均值由
式6求得,协方差固定。 - 噪声预测网络的优点是能够通过预测零噪声在最后的采样阶段从 X t X_t Xt中恢复 X t − 1 X_{t−1} Xt−1[79]
- 这对于 X ^ 0 \widehat{X}_0 X 0的直接参数化是比较困难的。
- 因此,两者之间存在权衡,其中直接参数化对于初始采样阶段的非常嘈杂的输入可能更有利,而噪声预测参数化在后期采样阶段可能更有利[27]
这一段解释如何通过重新参数化,简化原始的生成扩散模型,对
公式4进行了简化通过这种简化,模型不再直接预测均值 μ θ ( x t , t ) μ_θ (x_t,t) μθ(xt,t)和协方差 Σ θ ( x t , t ) Σ_θ(x_t ,t) Σθ(xt,t),而是直接预测加入的噪声 ϵ θ ( x t , t ) ϵ_θ (x_t ,t) ϵθ(xt,t)
公式6理解:
- 对之前公式 (5) 中的反向均值 μ θ ( x t , t ) μ_θ (x_t ,t) μθ(xt,t)的重新参数化表示
- 现在,均值的表达不再依赖于 x 0 x_0 x0(初始未带噪声的图像),而是依赖于预测的噪声 ϵ θ ( x t , t ) ϵ_θ(x_t ,t) ϵθ(xt,t)
- 这样做的目的是为了简化计算,让神经网络直接预测噪声 ϵ θ ϵ_θ ϵθ 而非均值 μ θ μ_θ μθ,从而更容易优化模型
- x t x_t xt 是时间步 t t t时的带噪图像。两个𝛼𝑡 是控制噪声和图像混合的系数,表示噪声注入过程的不同时间步
- ϵ θ ( x t , t ) ϵ_θ(x_t ,t) ϵθ(xt,t) 是神经网络预测的噪声,这个噪声代表了生成图像时所需要去除的噪声
类比
- 假设你有一张带噪声的照片 x t x_t xt,现在你要通过去除某种特定的噪声来恢复它。
- 公式 (6) 告诉你如何根据当前带噪图像 x t x_t xt和网络预测的噪声 ϵ θ ( x t , t ) ϵ_θ(x_t ,t) ϵθ(xt,t)去计算更清晰的图像 x t − 1 x_{t−1} xt−1
- 这里网络学会了如何直接去预测噪声的大小,而不是依赖于原始图像 x 0 x_0 x0
公式7解释:
- 这是一个简化的损失函数 L s i m p l e L_{simple} Lsimple ,用来替代之前的复杂的变分下界 L v l b L_{vlb} Lvlb
- 损失函数的目标是让神经网络预测出的噪声 ϵ θ ( x t , t ) ϵ_θ(x_t,t) ϵθ(xt,t)和实际的噪声 ϵ 𝑡 ϵ_𝑡 ϵt尽可能接近,即最小化它们的差距
- ϵ t ϵ_t ϵt ∼ N ( 0 , I ) N(0,I) N(0,I):真实的噪声是从标准正态分布中采样得到的。
- ϵ θ ( x t , t ) ϵ_θ (x t ,t) ϵθ(xt,t):这是神经网络预测出的噪声
- 模型希望通过学习,让预测噪声尽可能接近真实噪声
有两个例子可以区分一下公式4、5

公式6、7


- 为了提高采样效率,Salimans和Ho[143] 引入了速度预测作为另一种参数化方法。
- 速度是去噪输入和附加噪声的线性组合,通常定义为
式子8 - 这种参数化结合了数据参数化和噪声参数化的优点,使去噪网络能够灵活地学习噪声预测以及基于信噪比的重建动态。
- 这种参数化导致扩散蒸馏方法的结果稳定[143],并且可以加速生成[19]。
- 最近,一些研究[32,133,153,154] 进一步提出从连续的角度来考虑噪声,而不是离散角度

- 这里,扩散过程表示为一个连续的随时间变化的函数σ(t)。
- 当样本x随时间向前移动时,噪声逐渐增加,当图像沿反向轨迹移动时,噪声逐渐去除
- 更具体地说,扩散过程可以用随机微分方程(SDE)来表示[83],其中在实现扩散模型时需要选择
- 向量值漂移系数 f ( ⋅ , t ) f(·,t) f(⋅,t): R d \mathbb{R^d} Rd→ R d \mathbb{R^d} Rd【描述图像在时间上的平均变化趋势】
- 标量值扩散系数 g ( ⋅ ) g(·) g(⋅): R \mathbb{R} R→ R \mathbb{R} R【扩散系数,控制噪声注入的强度】
式子9其中 w w w是标准维纳过程【高斯噪声,它负责引入随机性,增加图像的噪声】- 用于模拟扩散过程的SDE公式 有两种广泛使用的选择。
- 第一种是保方差 ( V P ) S D E (VP) SDE (VP)SDE ,用于Ho等人[68] 的工作中,它由 f ( x , t ) f(x, t) f(x,t) 和 g ( t ) g(t) g(t) 给出,其中 β ( t ) = β t β(t) = β_t β(t)=βt当t趋于无穷
- 【注意,这相当于公式1中DDPM参数化的连续式】
- 第二种是方差爆炸 ( V E ) S D E [ 153 ] (VE) SDE[153] (VE)SDE[153] ,由选择 f ( x , t ) = 0 f(x, t) = 0 f(x,t)=0和 g ( t ) g(t) g(t)产生
- 这一段讨论了生成扩散模型中的一种 连续时间参数化方法,并用随机微分方程来表示扩散过程,目的是通过这种方式更好地控制扩散过程中的噪声演变,从而提高采样效率和生成质量
- 公式8解释:
- 这里的 v v v表示的是 “速度”,它是噪声 ϵ ϵ ϵ和带噪图像 X t X_t Xt的线性组合。
- 参数化公式将噪声预测(ϵ)和图像信息( X t X_t Xt)结合在一起,用于生成过程中的预测。
- 如果单纯依赖噪声预测或图像信息预测都不够全面,速度 v v v的定义实际上是结合了这两者的优点,网络可以在生成的过程中更加精准地去噪,生成清晰的图片。
- 公式9理解:
- 假设制作一张带噪图片,每隔一段时间会在原图片上加一些噪声( 𝑔(𝑡) 作用)
- 但每次加入噪声时,还会有一个平均变化趋势( 𝑓 ( 𝑥 , 𝑡 )),比如图片可能会逐渐变模糊或变清晰。
- 整个过程由这个公式控制,描述了图像的变化规律

- VE SDE因其方差随 t t t的增加而不断增大而得名,而VP SDE的方差是有界的[154]。
- Anderson[7] 推导出一种逆转扩散过程的SDE,将其应用于方差爆炸SDE时,结果如下
式子10 - ∇ x l o g p ( x ; σ ( t ) ) ∇_x logp (x;σ(t)) ∇xlogp(x;σ(t)) 称为分数函数。这个分数函数通常是未知的,所以需要使用神经网络来近似。
- 神经网络 D ( x ; σ ) D(x;σ) D(x;σ)可以用来提取分数函数,因为 ∇ x l o g p ( x ; σ ( t ) ∇_xlog p(x;σ(t) ∇xlogp(x;σ(t)
打不出来看上面 - 这种想法被称为去噪分数匹配[161]
- 公式10理解:
- 漂移项,用来逐步逼近清晰的图像。通过梯度∇𝑥操作,公式会朝着真实图像的概率分布 𝑝 ( 𝑥 ) 方向进行调整,逐步去除噪声
- 扩散项,表示注入的随机噪声,但随着时间𝑡的变化,噪声的强度也会逐渐减小,直到完全去除噪声
2.2 Backbone Architectures(骨干架构)

- 我们在2.1节中概述了扩散模型的数学基础。
- 由于去噪预测网络通常由参数 θ θ θ参数化,我们将在下一节中讨论用几种神经网络结构来表示 θ θ θ
- 所有这些网络架构都从相同的输入空间映射到相同的输出空间
- Ho等人[68] 使用类似于未屏蔽的 PixelCNN++[144] 的 U-Net骨干 来近似分数函数。
- 这种U-Net 架构最初用于语义分割方法[30,31,113,140],它基于Wide ResNet[182],将带有噪声的图像和扩散时间步长t作为输入,将图像编码为低维表示,并输出该图像和噪声水平的噪声预测
- U-Net由一个编码器和一个解码器组成,在块之间有剩余的连接,可以保留梯度流,并帮助恢复压缩表示中丢失的细粒度细节
- 编码器由一系列残差和自关注块组成,并将输入图像下采样到低维表示
- 解码器反映了这种结构,逐渐对低维表示进行上采样以匹配输入维数
- 扩散时间步t是通过在每个残差块中添加正弦位置嵌入来指定的[68],该位置嵌入缩放和移位输入特征,增强网络捕获时间依赖性的能力

- DDMPs在像素空间中操作,使得它们的训练和推理在计算上非常昂贵。
- Rombach等人[138] 通过提出 潜在扩散模型(LDMs) 来解决这个问题,该模型在预训练的变分自编码器的潜在空间中运行
- 扩散过程应用于生成的表示而不是直接应用于图像,从而在不牺牲生成质量的情况下获得计算效益
- 虽然作者引入了额外的交叉注意机制来允许更灵活的条件生成,但去噪网络骨干网仍然非常接近DDPM U-Net架构
- 最近在视觉任务(如ViT)中使用Transformers架构的进展[45] 导致了基于Transformers的扩散模型架构的采用。
- Peebles和Xie[132] 提出了扩散ransformers(DiT),这是一种主要受ViTs启发的扩散模型主干架构,当与LDM框架结合使用时,它在ImageNet上展示了最先进的生成性能

- 在ViT之后,DiTs通过将输入图像转换成一系列补丁来工作,这些补丁被转换使用“patchify”层的令牌序列
- 在向所有输入标记添加了ViT样式的位置嵌入之后,这些标记将通过一系列转换器块进行馈送。
- 这些块相当于标准的ViT块,这些块接受附加的条件信息,如 扩散时间步长t和调节信号c 作为输入
- 其结构的详细概述
如图3 - U-ViTs[12]将U-Net和ViT骨干网合并成一个统一的骨干网。
- U-ViTs在标记时间、条件和图像输入方面遵循变压器的设计方法,但另外在浅层和深层之间采用长跳过连接
- 这些跳过连接为底层特征提供了捷径,从而稳定了去噪网络的训练[12]。
- 利用 基于U-ViTs的骨干网的工作[13,72] 取得了与 基于U-Net CNN 的架构相当的结果,证明了它们作为其他去噪网络骨干网的可行替代方案的潜力
总结:
- U-Net:
- 特点是使用编码器-解码器结构,通过残差连接帮助保持梯度流,从而保留图像中的细节信息。
- Wide ResNet 被引入进去,使其在处理较复杂的噪声情况下表现得更好
- 其核心设计思想就是编码器:将带噪声的图像 X t X_t Xt压缩到一个低维度;解码器:将低维度的图恢复成不带噪声的图片 X 0 X_0 X0
- LDM:
- 常规DDPMs直接在像素空间操作,计算量比较大。在LDM中引入潜在空间的概念,模型在一个低纬度中间中进行扩散。这样极大的提升了计算效率
- 打比方将 1024x1024 像素的图像先压缩到 128x128 的潜在表示中,然后在这个较小的空间进行噪声的去除和扩散操作,这样可以显著降低生成的计算量,而不影响最终生成的高分辨率图像质量
- Transformer类型:
- ViT:一种基于 Transformer 的图像处理架构,最早用于图像分类任务。提升图像生成质量
- DiT:基于ViT的扩散模型,通过将图像切块然后将这些序列输入 Transformer 模块,结合扩散时间步 t 和条件信号进行处理
- 打比方,使用一张图片图片会首先被切分成若干小块(patch),每个小块被看作一个 token。然后这些 tokens 会被输入 Transformer 模型,Transformer 会根据图像的全局结构(而不仅仅是局部的)来进行建模和去噪。
- U-ViT:结合U-Net和ViT, 既保留 U-Net 中强大的跨层连接机制,又利用了 ViT 对时序性信息的处理能力

图3所示。
- 左图:U-Net架构的可视化示例[140]。由一个编码器和一个解码器组成,具有保留梯度流和低级输入细节的剩余连接。改编自[135]。
- 右图:DiT架构的可视化示例。显示了高级体系结构,以及adaLN-Zero
DiT块的分解。改编自皮布尔斯和谢[132]。
2.3 Diffusion Model Guidance(扩散模型指导)

- 最近图像生成结果的改进在很大程度上是由改进的制导方法驱动的。
- 通过传递用户定义的条件来控制生成的能力是生成模型的一个重要特性,而引导描述了模型内调节信号强度的调制
- 条件反射信号可以具有广泛的模式,从类标签到文本嵌入到其他图像
- 将空间条件反射信号传递给扩散模型的一种简单方法是将条件反射信号与去噪目标简单连接,然后通过去噪网络传递[12,75]
- 另一种有效的方法是使用交叉注意机制,其中一个条件反射信号c被编码器预处理为中间投影E(c ),然后使用交叉注意注入去噪网络的中间层[76,142]
- 后面内容主要讨论是如何通过不同的策略来控制生成结果的质量。
- 通过这些方法能够控制最终生成的结果,使得最终的结果能够更加的多样性并且提升质量
Cross-Attention机制:
- 一种更复杂的方法是通过 交叉注意力机制将条件信号引入模型。条件信号 c 可以先经过编码器处理成一个中间投影 E( c ),然后再通过交叉注意力机制注入到扩散网络的中间层。
- 这种方式允许模型更灵活地处理条件信息,比如生成特定类别的图像。
- 举例:
- 在这种方法中,我们的条件信号(狗的类别)会先经过一个编码器处理,生成一个中间特征表示
- 这些表示会通过交叉注意力机制,被注入到扩散模型的中间层,使模型能够更细致地处理条件信息。
- 这种方式让模型能更精准地生成符合条件的图像

- 这些条件反射方法本身并没有留下可能性去调节模型内调节信号的强度
- 扩散模型指导是最近出现的一种更精确地权衡发生质量和多样性的方法
- Dhariwal和Nichol[42] 使用分类器引导,这是一种利用预训练的噪声抑制分类器来提高样本质量的高效计算方法
- 分类器引导是基于这样的观察,即预训练的扩散模型可以使用由 ϕ ϕ ϕ输出 p ϕ ( c ∣ x t , t ) p_ϕ(c|x_t, t) pϕ(c∣xt,t)参数化的分类器的梯度来调节
- 该分类器 ∇ x t l o g p φ ( c ∣ x t , t ) ∇_{x_t} log pφ (c|x_t, t) ∇xtlogpφ(c∣xt,t)的对数似然梯度可以用来引导扩散过程生成属于类别标签y的图像。
- p ( x ∣ c ) p(x|c) p(x∣c)的分数估计器可以写成
式子11 - 利用贝叶斯定理,可以将噪声预测网络改写为
式子12 - 其中参数 w w w调制调节信号的强度
- 分类器指导是一种提高样本质量的通用方法,但它严重依赖于噪声鲁棒预训练分类器的可用性,这反过来又依赖于注释数据的可用性,而这在许多应用程序中是不可用的
Classifier Guidance(分类器引导):
- 该方法通过预训练的噪声鲁棒分类器的梯度来指导生成过程,计算效率较高。
- 分类器的梯度引导扩散过程生成特定类别的图像。例如,给定条件信号 y(比如“猫”这个标签),模型通过分类器的梯度 ∇ x t l o g p φ ( c ∣ x t , t ) ∇_{x_t} log pφ (c|x_t, t) ∇xtlogpφ(c∣xt,t)引导扩散过程,生成符合该类别的图像(符合猫的特点)
- 通过贝叶斯公式,公式(11)和(12)展示了如何结合分类器的梯度和去噪网络的预测来估计噪声,从而生成特定类别的图像。
- 举例:
- 使用一个预先训练好的分类器,来告诉模型“这是一只狗”的信息。模型通过该分类器的梯度(也就是狗这个标签的概率梯度)来引导生成,确保生成的图片更符合“狗”这个类别。
- 分类器可能会分析生成的图片,并给出该图片是狗的概率。如果概率太低,梯度会推动模型修改图片,增加生成狗的特征,直到模型输出符合我们希望的“狗”的样子。

- 为了解决这一限制,无分类器指导(CFG)[67] 消除了对预训练分类器的需要。
- CFG的工作原理是训练一个参数为 ϵ θ ( X t , t , ϕ ) ϵ_θ(X_t, t, ϕ) ϵθ(Xt,t,ϕ) 的无条件扩散模型和一个参数为 ϵ θ ( X t , t , c ) ϵ_θ(X_t, t,c) ϵθ(Xt,t,c) 的条件模型。
- 对于无条件模型,使用一个空的输入令牌 ϕ ϕ ϕ作为条件信号 c c c。
- 网络通过随机剔除条件信号的方式进行训练。
- 然后使用条件和无条件分数估计的加权组合进行抽样
式子13 - 这种采样方法不依赖于预训练分类器的梯度,但仍然需要一个带注释的数据集来训练条件去噪网络
- 尽管最近使用扩散模型表示进行自监督引导的工作显示出希望,但完全无条件方法尚未与无分类器引导相匹配[73,100]。
- 这些方法不需要带注释的数据,允许使用更大的未标记数据集
Classifier-free Guidance(无分类器引导):
- 是一种不用预训练分类器的方法,它直接训练一个同时处理条件和无条件扩散的模型
- 在训练时,随机丢弃条件信号 c 以使模型同时学习如何在有条件和无条件下生成图像
- 在采样过程中,条件和无条件的估计会按照权重 w 进行加权组合,见公式(13),这样就不需要预先训练好的分类器
- 举例:
- 训练模型的时候,随机丢弃狗这个标签,让模型同时学会生成有条件和无条件的图像。
- 这样在生成时,我们可以直接通过控制模型内部的权重 w
- 调整生成的图片更符合“狗”的特征,而不依赖于分类器的帮助
表1显示了当前引导方法的要求。- 虽然分类器和无分类器指导可以改善生成结果,但它们需要带注释的训练数据。
- 自我指导和在线指导是完全自我监督的替代方案,无需注释即可实现竞争性性能。
- 分类器和无分类器引导是依赖于条件训练的受控生成方法。
- 无训练方法通过结合 多个扩散过程[14] 或使用 与时间无关的能量函数[179] 来修改预训练模型的生成过程。
- 其他控制生成方法采用变分视角[54,119,146,164],将控制生成视为源点优化问题[17]

- 目标是找到一个最小化损失函数 L ( x ) L(x) L(x)的样本 x x x,并且可能在模型的分布 p p p下
- 优化表示为 m i n X 0 L ( x ) min_{X0} L(x) minX0L(x),其中 X 0 X_0 X0为源噪声点。
- 对于条件采样,可以修改损失函数 L ( x ) L(x) L(x),生成属于特定类 y y y的样本

不同扩散模型引导方法的概述。自我指导[75]和[73]都不需要分类器和注释,在线指导有助于在线学习
3 METHODS (方法)

- 在介绍了扩散模型的主要基础知识之后,我们将在下一节中概述一系列与扩散模型和表示学习相关的方法。
- 在第3.1节中,我们描述和分类了当前的框架,利用预训练扩散模型学习到的表征进行下游识别任务
- 在第3.2节中,我们描述了利用表征学习的进步来改进扩散模型本身的方法
3.1 Diffusion Models for Representation Learning(表示学习的扩散模型)

- 学习有用的表示是设计VAEs[88,89]和GANs[22,84] 等架构的主要动机之一
- 对比学习方法的目标是学习相似图像的表示非常接近的特征空间,反之亦然(例如SimCLR [34], MoCo[60]),这也导致了表征学习的重大进展。
- 然而,这些对比方法并不是完全自我监督的,因为它们需要以保留图像原始内容的增强形式进行监督
- 扩散模型为这些方法提供了一个有希望的替代方案
- 虽然扩散模型主要是为生成任务设计的,但去噪过程鼓励学习语义图像表示[15],可用于下游识别任务
- 扩散模型的学习过程类似于去噪自编码器(DAE)的学习过程[18,162],它们被训练用来重建被添加噪声损坏的图像
- 主要区别在于扩散模型还将扩散时间步长 t t t作为输入,因此可以将其视为具有不同噪声尺度的多级DAEs[169]
- 由于DAEs在压缩的潜在空间中学习有意义的表示,因此扩散模型表现出类似的表示学习能力是很直观的
- 我们将在下一节中概述和讨论当前的方法
3.1.1 Leveraging intermediate activations(利用中间激活)


- Baranchuk等人[15] 研究了 U-Net网络的中间激活 ,该网络近似于DDPMs中反向扩散过程的马尔可夫步长[42]
- 他们表明,对于某些扩散时间步长,这些中间激活捕获可用于下游语义分割的语义信息。
- 作者采用在LSUNHorse[177]和FFHQ-256[84]数据集上训练的噪声预测网络 ϵ θ ( X t , t ) ϵ_θ(X_t, t) ϵθ(Xt,t),提取由网络的18个解码器块之一产生的特征映射,用于标签高效的下游分割任务。
- 选择理想的扩散时间步长和解码器块激活来提取是非常重要的。
- 为了了解不同解码器块的像素级表示的有效性,作者训练了一个多层感知器(MLP) 来预测语义标签,根据不同解码器块在特定扩散步骤t上产生的特征
- 来自预训练U-Net解码器的一组固定块B和更高扩散时间步长的表示使用双线性插值和连接将其上采样到图像大小
- 然后使用获得的特征向量来训练独立的MLP集合,这些MLP预测每个像素的语义标签。最终的预测是通过多数投票获得的
- 这种方法,称为DDPM-Seg,优于利用替代生成模型的基线,并获得与MAE竞争的分割结果[61],说明中间去噪网络激活包含语义图像特征。

- Xiang等人[169]将这种方法扩展到CIFAR-10和TinyImageNet上的进一步架构和图像识别。
- 他们研究了不同框架(DDPM和EDM[85])下不同主干(U-Net和DiT[132])提取的特征的判别效果。
- 通过网格搜索评估特征质量和层噪声组合之间的关系,其中使用线性探测确定特征表示的质量。
- 表现最好的特征位于上采样的中间,使用相对较小的噪声水平,这与DDPM-Seg[15] 得出的结论一致。

- 在CIFAR-10和Tiny-ImageNet[41] 上与HybViT[174]和SBGC[190] 等
- 基于扩散的方法进行基准比较表明,基于EDM的去噪扩散自编码器(DDAEs) 在生成和识别方面都优于之前基于监督和无监督扩散的方法,尤其是在微调之后
- 对比学习方法的基准测试表明,考虑到模型大小,基于EDM的DDAE与Sim-CLRs相当,并且在CIFAR-10和Tiny-ImageNet上优于具有可比参数的SimCLRs
- ODISE[170]是一种相关的方法,它将文本-图像扩散模型与判别模型结合起来进行全视分割[90,91],这是一种将实例和语义分割统一到一个通用框架中的分割方法,用于全面的场景理解
- ODISE提取预先训练的文本到图像扩散模型的内部特征
- 这些特征被输入到在带注释的掩码上训练的掩码生成器中
- 掩码分类模块通过将预测掩码的扩散特征与对象类别名称的文本嵌入相关联,将每个生成的二进制掩码分类到开放词汇类别中

- 作者使用稳定扩散U-Net DDPM骨干,通过计算单个前向通道和提取中间激活 f = U N e t ( X t , τ ( s ) , t ) f= UNet(X_t, τ (s), t) f=UNet(Xt,τ(s),t) 来提取特征
- 其中 τ ( s ) τ (s) τ(s) 是利用预训练的文本编码器 τ τ τ获得的图像标题 s s s的编码表示
- 有趣的是,作者使用t = 0获得了最好的结果,而以前的方法使用更高的扩散时间步长获得了更好的结果
- 为了克服对可用图像标题的依赖,Xu等人[170] 另外训练一个基于MLP的隐式标题器,该标题器从图像本身计算隐式文本嵌入。
- ODISE在开放词汇分割中建立了新的技术,是通过去噪扩散模型学习丰富语义表示的又一个例子

- Mukhopadhyay等人[125] 也提出利用无条件ADM U-Net架构[42] 中的中间激活来进行ImageNet分类
- 层和时间步选择的方法与以前的方法相似
- 此外,还评估了不同大小对特征映射池的影响,并使用了几种不同的轻量级分类架构(包括线性、MLP、CNN和基于注意力的分类头)
- 发现特征质量对池化大小不敏感,并且主要依赖于时间步长和选择的块数
- 他们的方法,我们称之为引导扩散分类(GDC),与其他统一模型,即BigBiGAN[44]和MAGE[99] 相比,具有竞争力。
- 基于注意力的分类头在ImageNet-50上表现最好,但在细粒度视觉分类数据集上表现不佳,这表明它们依赖于大量可用数据。

- 在他们之前工作的延续中,Mukhopadhyay等人[126] 通过引入两种更细粒度的块和去噪时间步选择方法扩展了这种方法。
- 第一个是DifFormer[126]
- 这是一种注意机制,用基于注意的特征融合头取代了[125] 中的固定池化和线性分类头。
- 该融合头旨在用可学习的池化机制取代GDC方法中使用的U-Net CNN生成矢量特征表示所需的固定平坦化和池化操作
- 第二种机制是DifFeed[126]
- 一种动态反馈机制,将特征提取过程解耦为两个正向通道
- 在第一次向前传递中,只存储选定的解码器特征映射
- 这些被馈送到辅助反馈网络,该网络学习将解码器特征映射到适合将它们添加到相应块的编码器块的特征空间
- 在第二次前向传递中,将反馈特征添加到编码器特征中,并且在第二次前向传递特征之上使用DifFeed注意头。
- 这些额外的改进进一步提高了学习表征的质量,提高了ImageNet和细粒度视觉分类性能

- 先前描述的扩散表示学习方法侧重于分割和分类,这只是下游识别任务的一个子集
- 对应任务是另一个子集,通常涉及识别和匹配不同图像之间的点或特征
- 问题设置如下:
- 考虑两个图像 I 1 I1 I1和 I 2 I2 I2以及 I 1 中的像素位置 p 1 I1中的像素位置p1 I1中的像素位置p1
- 对应任务包括在 I 2 中找到相应的像素位置 p 2 I2中找到相应的像素位置p2 I2中找到相应的像素位置p2

- p1和p2之间的关系可以是语义的(包含相似语义的像素)、几何的(包含对象的不同视图的像素)或时间的(包含同一对象的像素随着时间的推移而变形)
- DIFT (Diffusion Features)[157] 是一种利用预先训练的扩散模型表示来处理通信任务的方法。DIFT还依赖于扩散模型特征的提取
- 与以前的方法类似,用于提取的扩散时间步长和网络层数是重要的考虑因素。
- 作者在大扩散时间步长和早期网络层组合中观察到更多语义上有意义的特征,而在较小的扩散时间步长和较晚的去噪网络层中捕获较低级别的特征
- DIFT在一系列通信任务中表现优于其他自监督和弱监督方法,特别是在语义通信方面表现出与最先进的方法相当的性能

- Zhang等人[183] 评估了学习到的扩散特征如何在多个图像之间相互关联,而不是专注于单个图像的下游任务。
- 为了研究这一点,他们还使用了稳定扩散特征来进行语义对应。
- 作者观察到,稳定扩散特征具有很强的空间布局感,但有时会提供不准确的语义匹配
- DINOv2[128] 是一种使用知识蒸馏和视觉变换的自监督表示学习方法,它产生了更多的稀疏特征,提供了更准确的匹配
- 因此,Zhang等人[183] 提出将这两个特征结合起来,并在结合的特征上使用最近邻搜索的零射击评估,从而在几个语义对应数据集(如SPair-71k和TSS)上实现最先进的性能

- SD4Match[103] 通过使用各种提示调优和调节技术建立在这种方法的基础上
- 其中一种方法,SD4Match-Class,使用语义匹配损失对每个语义类的提示嵌入 Θ Θ Θ进行微调[102]
- 给定图像 I t A I^A_t ItA和 I t B I^B_t ItB,稳定扩散U-Net f ( ⋅ ) f(·) f(⋅) 通过 F t = f ( I t , t , Θ ) F_t = f(I_t, t, Θ) Ft=f(It,t,Θ) 提取特征映射 F t A F^A_t FtA和 F t B F^B_t FtB
- 通过归一化特征映射和计算相关映射来预测对应点,并使用 s o f t m a x 操作 softmax操作 softmax操作将其转换为概率分布
- Li等人[103] 提出使用条件提示模块(CPM)对输入图像进行条件提示,
- 该模块包括 D I N O v 2 DINOv2 DINOv2 特征提取器、线性层和自适应 M a x P o o l i n g MaxPooling MaxPooling层
- 条件嵌入 Θ c o n d Θ_{cond} Θcond 是通过连接特征表示并将它们投射到提示嵌入维度而形成的
- 最后的提示 Θ A B Θ_{AB} ΘAB 是通过将 Θ c o n d Θ_{cond} Θcond 附加到 全局提示 Θ g l o b a l Θ_{global} Θglobal 来获得的。
- 该方法在 SPair-71k[122]、PF-Willow和PF-Pascal[59] 上设置了新的基准精度,超过了DIFT[157]和SD+DINO[183] 等方法
- Luo等人[116] 引入了扩散超特征(Diffusion Hyperfeatures),
- 该框架旨在跨扩散时间步合并多个中间激活图,用于下游识别。
- 使用可解释的聚合网络整合激活,该网络将中间特征映射集合作为输入,并产生单个特征描述性特征映射作为输出
- 虽然其他方法手动选择固定的扩散时间步长,并从预定数量的中间网络层中激活,扩散超参数缓存的所有特征映射都在扩散过程中的所有层和时间步,以生成密集的激活集

- 这个高维激活集被上采样,通过瓶颈层 B B B,并对每一层和时间步组合使用一个独特的可学习混合权 w l , s w_{l,s} wl,s进行加权。最终的扩散超特征呈现如
式子14 - 其中 L L L为层数, S S S为扩散时间步数的子样本, r r r为激活特征映射
- 瓶颈层和混合权值根据特定的下游任务进行微调。与以前的方法类似,扩散超特征用于语义对应
- 作者从Stable-Diffusion中提取激活,并在SPair-71k的一个子集上调优聚合网络
- 在SPair-71k和CUB数据集上,Diffusion Hyperfeatures优于使用自监督描述符或监督超列的模型

- Hedlin等[62] 专门利用中间注意图来优化提示嵌入。给定某个输入文本提示,这些注意激活映射对应于提示的语义
- Hedlin等人[62] 没有使用语义损失优化全局或类相关提示嵌入 Θ Θ Θ,而是优化嵌入以最大化兴趣位置的交叉关注
- 定位第二图像中的对应点归结为对优化提示进行调节,并选择目标图像中像素达到最大注意图值的点
- 注意,这种方法不使用特定于语义对应的监督训练。然而,它们需要测试时间优化,这是昂贵的
- 文本提示使用现成的扩散模型进行优化,无需微调
- 基于上述方法的进一步研究[120,184] 表明,利用预先训练的扩散模型进行语义对应仍然是扩散模型的一个有前途的应用

- Zhao等人[187] 提出了基于预训练扩散模型(VDM)的视觉感知,这是一个与USCSD[62] 密切相关的框架,它采用了文本特征细化网络以及用于语义分割和深度估计的附加识别编码器
- 在这里,去噪网络被输入精细的文本表示和输入图像,得到的特征映射以及文本和图像特征之间的交叉注意映射被用来为解码器提供指导
- 为了实现这一点,预测模型被写为 p φ ( y ∣ x , S ) p_φ (y|x,S) pφ(y∣x,S),其中 S S S 表示下游任务的所有类别标签的集合。
- 预测模型实现如
式子15- 式中, F F F 为特征映射集, C C C 为文本特征。
- p ϕ 1 ( C ∣ S ) p_{ϕ1} (C|S) pϕ1(C∣S) 表示一个由两层MLP组成的文本适配器,该适配器将CLIP文本编码器应用于 “ a p h o t o o f a [ C L S ] ” “a photo of a [CLS]” “aphotoofa[CLS]”的文本模板,从而细化得到的文本特征。
- p ϕ 1 ( F ∣ x ) p_{ϕ1} (F|x) pϕ1(F∣x) 在给定输入图像 x x x和精炼文本特征集 C C C的情况下,从去噪网络中提取特征映射

- 作者使用 t = 0 t = 0 t=0将使用 VQGAN编码器[47] 生成的输入图像的潜在表示输入去噪网络,得到特征映射 F F F
- 最后, p ϕ 3 ( y ∣ F ) p_{ϕ3} (y|F) pϕ3(y∣F) 作为轻量级预测头实现为语义特征金字塔网络[90],适应下游任务
- 在语义分割和深度估计方面对VDM进行了评估,与其他预训练范式相比,VDM具有很强的竞争力和快速的收敛性

- 文本到图像扩散模型表示的一种更间接的应用是 教学图像编辑[23,51,98],其中所需的图像编辑由自然语言指令描述,而不是对所需新图像的描述[81]
- 基于提示符的图像编辑具有挑战性,因为文本提示符的微小变化可能导致截然不同的生成结果。
- [65] 提出了一种针对预训练文本条件扩散模型的文本编辑方法,该方法利用去噪主干中中间交叉注意层的语义强度
- 该方法基于[62,187] 中也采用的关键观察:交叉注意地图包含关于生成图像的空间布局和几何形状的丰富信息。
- 将生成图像I时获得的交叉注意层注入编辑图像 I ∗ I^* I∗的生成过程中,可确保编辑后的图像保留原始的空间布局。
- Hertz等[65] 利用Imagen[141] 进行实验,在纯文本局部编辑、全局编辑和真实图像编辑等方面均取得了可喜的结果。
- 随后的作品,如即插即用扩散特性[160],通过利用所有中间激活地图来实现教学图像编辑,进一步改进了这一点。
- 其他技术,如TokenFlow[52]和Yatim等人的工作[175] 将这一想法扩展到视频空间,使用扩散特性来实现基于提示的视频编辑文本驱动的动作传输
3.1.2 A general representation extraction framework(通用的表示抽取框架)

- 上一节中概述的许多方法都遵循类似的过程,利用预先训练的扩散模型的学习表征来完成下游视觉任务
- 在本节中,我们的目标是将这些方法合并为一个通用的三步框架。
- 我们这样做是为了明确扩散模型及其在下游预测任务中的使用之间的关系。
- 为了利用中间激活来完成下游任务,必须采用一种选择方法,输出理想的扩散时间步输入,以及在上采样和线性探测时激活映射具有最高预测性能的中间层数。
- 这可以是一个可训练的模型[116],一个网格搜索过程[169]或一个学习代理[173]。
- 这种方法的目标通常是选择时间步长 t ∈ t t∈t t∈t和一组解码器块数 B B B,以最大限度地提高下游任务的预测性能
- 给定一组可能的时间步长 T T T和一组解码器块 B B B,目标是找到
式子16 - 其中 L d i s c r ( t , B ) L_{discr}(t, B) Ldiscr(t,B)表示在时间步长 t t t时, B B B中的块用于下游预测时的判别损失。

- 一般来说,判别任务将需要与结构元素和形状相对应的更多高级特征,而将随机噪声映射到图像的生成任务将需要计算更低级的特征。
- 理想的中间层数以及最优扩散时间步将在很大程度上取决于确切的下游预测任务、数据集和所使用的扩散模型的架构
- 一旦确定了理想的时间步长和层数,输入图像和所选的扩散时间步长将被传递给扩散模型,并提取在前向传递中计算的所选解码块中的中间激活,并根据下游任务(例如通过上采样,池化等)进行连接和预处理。
- 最后,将从扩散模型中提取的预处理特征作为输入,在标注数据集上训练分类头。
- 这个分类头可以是MLP、CNN或基于注意力的网络,这取决于标记数据的可用性和数据集上的预测性能。
- 扩散模型权重通常在探测过程中被冻结,但额外的微调机制可以提高某些数据集和架构的判别性能(例如,Xiang等人[169])。
图4显示了广义框架的概述。

图4所示。为下游任务从预训练的扩散模型中提取表示的框架的高级概述
3.1.3 Knowledge transfer (知识转移)

- 除了利用来自预训练扩散模型的中间激活直接作为识别网络的输入外,最近的一些方法提出了一种更间接的方法,可以将学习到的表示用于下游任务。
- 我们将这些方法统称为知识转移方法
- 这反映了从预训练的扩散模型中提取表征,然后以一种不同于简单地提供聚合特征激活图作为输入的方式将它们转移到辅助网络的共同思想
- 下一节将讨论其中的几种方法
- Yang和Wang[173] 提出了 RepFusion ,这是一种知识蒸馏方法,它使用强化学习框架在不同时间步动态提取中间表示,并使用提取的表示作为学生网络的辅助监督。
- 给定一个标签为 y y y的输入 x x x,作者提取了一对特征,一个来自扩散概率模型(DPM),一个来自学生模型,其中 Z ( t ) Z(t) Z(t)是扩散模型表示并且 Z Z Z是学生模型的表示

- 在训练过程中,使用损失函数 L k d L_{kd} Lkd最小化两者之间的距离
- 在蒸馏之后,学生网络被重新应用为特征提取器,并对可用的任务标签进行微调
- 以前使用扩散模型表示的方法依赖于网格搜索来确定使用哪个扩散时间步进行特征提取
- 在这里,作者制定了一个强化学习环境,其中动作空间是可供选择的所有可能时间步长的集合t,奖励函数是负任务损失 − L t a s k ( y , g ( z ( t ) ) ; θ g ) ) −L_{task}(y, g(z^{(t)});θ_g)) −Ltask(y,g(z(t));θg))
- 给定输入 x x x,训练策略网络 π θ π ( t ∣ x ) π_{θ_π} (t|x) πθπ(t∣x)来确定使用哪个时间步t进行表示提取。
- 一旦选择了时间步长,作者使用所选时间步长 t ∗ t^∗ t∗的DPM中间块中的特征表示来获得 z ( t ∗ ) z ^{(t∗)} z(t∗)
- 在蒸馏阶段之后,学生网络被用作特征提取器,随后在任务标签 y y y上进行微调

- Li等人[96] 介绍了 DreamTeacher ,这是一种使用特征回归器模块的知识蒸馏方法,它将生成模型 G G G的学习表征提取为目标图像识别主干 f f f
- 给定一个特征数据集 D D D,由图像x和提取的特征 f i g f^g_i fig组成,通过将 f i g f^g_i fig提取为 f ( x i ) f(x_i) f(xi)的中间特征来训练 f f f
- 通过运行T个时间步的前向扩散过程并进行单个去噪步骤从U-Net主干的中间层提取 f i g f^g_i fig,从G中提取特征。
- 提取的特征使用特征回归器模块进行提取,该模块具有自顶向下的架构,包含横向跳过连接,该连接将图像主干特征与生成特征对齐
- 在第 l l l层使用中间CNN编码器特征 f l e f^e_l fle和回归量输出 f l e f^e_l fle来计算受FitNet启发的MSE特征回归损失[139]
式子17 - W W W是一个不可学习算子,实现为LayerNorm[11]
- 这种损失与基于激活的注意力转移(AT)目标相结合[181],该目标为每个空间特征提取一维“注意力图”
- DreamTeacher在一系列下游识别任务上进行评估,方法是对预训练的主干进行微调,为每个任务添加额外的分类头

- DreamTeacher在 COCO[106]、ADE20k[189]和BDD100K[178] 基准测试上优于现有的对比和基于掩膜的自监督方法
- RepFusion和DreamTeacher都受到了早期知识提炼工作的启发[66,139]。
- Li等人[95] 提出了一种略有不同的知识转移方法:
- 扩散分类器,一种利用文本到图像扩散模型的条件密度估计进行零射击分类的方法。
- 该分类器通过计算类条件似然 p θ ( x ∣ c i ) p_θ(x|c_i) pθ(x∣ci),并利用贝叶斯定理得到预测类概率 p ( c i ∣ x ) p(c_i |x) p(ci∣x) ,将扩散模型转换为分类器。
- 由于直接计算 p θ ( x ∣ c i ) p_θ(x|ci) pθ(x∣ci) 是难以处理的,他们使用证据下界(ELBO)来代替它。
- 该分类器是通过重复添加噪声,并使用蒙特卡罗方法估计每个类别的噪声重建损失而得到的。
- 虽然Diffusion Classifier 的推理时间较长,但在大多数数据集上,它通常优于DDPM-Seg Baranchuk等人[15],并且与 CLIP ResNet-50[136]和OpenCLIP vith /14[36] 竞争。
3.1.4 Reconstructing diffusion models(重建扩散模型)

- 以前的扩散表示学习技术不建议对扩散模型架构和训练方法进行根本性的修改
- 虽然这些技术通常对下游任务表现出令人鼓舞的性能,但它们无法深入了解学习有用表示所需的架构组件和技术
- 例如,扩散模型的表示学习能力是由扩散过程驱动,还是由模型的去噪能力驱动,这在很大程度上仍不清楚
- 目前还不清楚什么样的架构和优化选择可以提高扩散模型的表示学习能力

- Chen等人[35]通过解构去噪扩散模型(DDM),修改单个模型组件将DDM转变为去噪自编码器来研究这些问题。解构过程分为三个阶段。
- 在第一阶段,DDM被重新定位为自监督学习。
- 这需要去除类条件并重建DiT基线中使用的VQGAN标记器[47]。
- 感知损失和对抗损失都依赖于注释数据,因此被删除。
- 这实际上是将VQGAN转换为VAE。
- 第二阶段,包括进一步简化VAE标记器,用不同的自动编码器变体替换它
- 令人惊讶的是,作者发现使用更简单的自动编码器变体,如补丁式PCA,不会显著降低性能。
- 作者得出结论,潜在空间的每个标记的维数对探测精度的影响要比所选择的自编码器大得多
- 最后的解构步骤包括将DDM转换为预测去噪的输入而不是增加的噪声,去除输入缩放,以及改变扩散模型直接在像素空间中操作
- 最后一个阶段产生了作者所说的潜在去噪自动编码器(l-DAE)。
- 他们得出结论,表征学习能力在很大程度上是由去噪驱动的过程而不是扩散过程驱动的

- l-DAE的灵感来自于观察到扩散模型类似于具有不同噪声尺度的分层自编码器
- 这种见解也适用于DiffAE[134],它使用扩散模型通过自动编码进行表示学习
- Preechakul等[134] 将潜在表示分为紧凑语义表示和随机表示
- DiffAE由一个语义编码器组成,它生成一个语义表示 z s e m z_{sem} zsem,以及一个条件DDIM[152]
- 这个DDIM既可以作为随机编码器,将 X 0 X_0 X0映射到 X T X_T XT,也可以作为解码器,将 X T X_T XT映射到 X 0 X_0 X0
- X T X_T XT表示随机表示并捕获低级变化,而 z s e m z_{sem} zsem编码高级语义
- 在推理过程中,[134] 将第二个潜在DDIM拟合到 z s e m z_{sem} zsem,并从该DDIM和xT中采样,以方便无条件采样
- 在固定的 z s e m z_{sem} zsem下, X T X_T XT的变化会导致生成图像的微小变化,而 z z z的变化会导致不同的重建,这表明DiffAE在生成语义上有意义和可解码的表示方面的效率
- InfoDiffusion[165] 扩展了 DiffAE,支持自定义先验,并通过互信息正则化改进潜在表示

- Zhang等[186] 观察到,在扩散逆向过程中,从 X t X_t Xt进行预测时, X t − 1 X_{t−1} Xt−1的真实值与预测后验均值之间存在差距
- 分类器的引导可以看作是通过移动后验均值来填补空缺,从而重建在扩散前向过程中丢失的信息
- 他们提出了预训练DPM自动编码(PDAE),一种使DPM适应解码器进行图像重建的方法
- PDAE没有使用类标签 y y y来填补这个信息缺口,而是使用一个模型来根据编码表示 z z z来预测平均位移,确保 z z z包含尽可能多的来自 X 0 X_0 X0的信息
- 具体而言,Zhang等人[186] 使用编码器 E p h i ( x 0 ) = z E_{phi}(x0) = z Ephi(x0)=z和模拟 ∇ x t l o g ( p ( z ∣ x t ) ∇_{xt} log(p(z|x_t) ∇xtlog(p(z∣xt) 的梯度估计器 G ψ ( X t , z , t ) G_ψ(X_t, z, t) Gψ(Xt,z,t) 来修改条件DPM训练目标
- 这一修改后的目标迫使预测的均值位移填补了前面提到的后验均值差距。
- 对于训练好的 G ψ ( X t , z , t ) G_ψ(X_t, z, t) Gψ(Xt,z,t),隐式分类器 p ( z ∣ X t ) p(z|X_t) p(z∣Xt) 的分数可以类似于分类器引导抽样
- PDAE使用与[134]中使用的类似实验进行评估,并显示出改进的训练效率和性能

- Pan等[130] 提出了一种不同的DDM重建方法。
- 他们引入了一个掩蔽扩散模型(MDM),用于自监督语义分割
- MDM用屏蔽自编码器启发的屏蔽机制取代了传统的扩散过程[61]
- 根据Baranchuk等人[15] 提取预训练的MDM学习到的表示
- 所建议的MDM是时间相关去噪自动编码器的一种变体,它接受被屏蔽的输入图像,然后重建未损坏的图像。
- 而其他DDMs和MAE使用MSE重建损失,Pan等[130] 建议使用结构相似指数(SSIM)损失
- 这样做是为了缩小重建和后续分割任务之间的差距。
- MDM使用所描述的自监督方法在一组未标记的图像上进行预训练,然后提取学习到的表示,在较小的标记数据集上训练基于MLP的分类头。

- 基于特定块设置B的特征提取方法是:从每个指定块中选择激活图,对激活图进行上采样以匹配图像大小,并将激活图串联起来
- 即使只有10%的标签可用,该方法也可以在多个基准数据集上实现与现有监督分割方法相比的最先进的结果。
- DiffMAE[166] 是一种类似的方法,它使用条件生成目标,其中被遮挡像素 x 0 m x^m_0 x0m的分布以可见像素 x 0 v x^v_0 x0v为条件进行建模,并且扩散仅应用于被遮挡区域

-
Hudson等人[82] 引入了一种新的视图生成学习目标和瓶颈层来辅助表示学习
-
他们提出了SODA,一个由编码器和去噪解码器组成的自监督扩散模型
-
编码器产生一个简洁的潜在表示,该潜在表示用于通过调制解码器激活来去噪解码器引导
-
编码器E(x) 将输入视图 x x x转换为压缩的潜在表示 z z z,用于生成与输入 x x x相关的新输出视图 x ′ x ' x′
-
X ′ X ' X′是通过扩散过程产生的,扩散过程是通过特征调制以潜在表示 z z z为条件的
-
除此之外,作者使用层调制,其中潜在表示被划分,每个分区调制特定的层激活对
-
这使得潜在子向量之间能够进一步专业化,其中一些被优化以捕获比其他子向量更细的粒度级别
-
在训练过程中,Hudson等人[82] 选择随机将潜在子向量的一个子集归零,有效地实现了无分类器指导的分层泛化
-
这进一步增加了对生成过程的控制,因为训练后的模型可以使用潜在子向量的一个精心策划的子集来进行条件反射

-
SmoothDiffusion[58] 是一项致力于提高扩散模型潜空间平滑度的工作,指的是潜空间和图像空间中摄动的一致性。
-
SmoothDiffusion通过在训练中提出一种新的逐步变分正则化方法来增强潜空间的平滑性。
-
由此产生的平滑电位有利于广泛的图像插值,图像反演和图像编辑任务
3.1.5 Joint diffusion models(关节扩散模型)

- 目前许多基于扩散的表示学习方法都侧重于利用扩散模型的潜在变量来训练单独的识别网络
- 这些框架在概念上等同于构建混合模型,在预训练阶段只专注于合成,在训练后/微调阶段专注于下游识别
- 识别头和扩散去噪网络不共享一个参数化,识别头通常是单独训练的,同时保持去噪网络的权值不变
- 一个自然出现的问题是,这种分离是否必要,以及在共享参数化中同时优化生成目标和判别目标的方法是否可以改善表征学习
- HybViT[174] 是一种通过训练用于图像分类和图像生成的单一混合模型,在扩散模型和视觉转换器之间建立直接联系的方法。
- 该混合模型采用共享参数对图像进行分类和重构

- 作者使用ViT主干来训练具有组合损失 L L L的模型,该组合损失L由标准交叉熵损失来训练 p ( y ∣ x ) p(y|x) p(y∣x)和简单的去噪损失来训练 p ( x ) p(x) p(x)
- HybViT提供稳定的训练,并且在生成和判别任务上优于以前的混合模型,但在生成质量上落后于仅生成模型。
- HybViT还需要更多的训练迭代才能达到较高的分类性能,并且在推理过程中采样速度较慢

- 联合扩散模型(Joint Diffusion Models, JDM)[40] 是一项相关研究,它在生成和判别任务之间产生有意义的表征。使用U-Net骨干网,
- JDM由一个编码器 e v e_v ev、一个解码器 d ψ d_ψ dψ 和一个分类器 g ω g_ω gω 组成。
- 编码器将输入 X t X_t Xt映射到特征向量 Z t = e ν ( X t ) Z_t = e_ν(X_t) Zt=eν(Xt)
- 解码器将这些重构成去噪样本 X t − 1 = d ψ ( Z t ) X_{t−1} = d_ψ(Z_t) Xt−1=dψ(Zt),分类器预测目标类 y = g ω ( Z t ) y = g_ω(Z_t) y=gω(Zt)
- 联合训练目标包括交叉熵损失 L c l a s s L_{class} Lclass和噪声预测网络的简化目标 L t , d i f f ( ν , ψ ) L_{t,diff}(ν, ψ) Lt,diff(ν,ψ),产生的损失
如上文式子
- JDM还支持简化分类器指导。
- 通过将分类器应用于噪声图像 X t X_t Xt,有效增强了分类器对噪声的鲁棒性
- 为了将生成的样本引导到目标标签,根据分类器梯度优化表示 Z t Z_t Zt,得到 Z t ′ = Z t − α ∇ Z t l o g g ω ( y ∣ Z t ) Z^{'}_t = Z_t−α∇_{Z_t}logg _ω(y|Z_t) Zt′=Zt−α∇Ztloggω(y∣Zt)
- JDM在CIFAR和CelebA数据集上实现了联合模型的最先进性能,优于HybViT

- Tian等[158] 提出了交替去噪扩散过程(ADDP)。
- ADDP交替地去噪像素和VQ标记。给定图像 X 0 X_0 X0 ,预训练的VQ编码器[26] 将时间图像映射到VQ Tokens Z 0 Z_0 Z0
- 交替扩散过程根据扩散时间步长 t t t用马尔可夫链掩膜 Z 0 Z_0 Z0 区域,生成 Z t Z_t Zt。不可靠的token z ¯ t z¯t z¯t 由token预测器生成,并馈入VQ解码器以合成 X t X_t Xt ,替换 Z 0 Z_0 Z0 的屏蔽区域
- 然后训练像素到token生成网络来近似 z ¯ t − 1 z¯_{t−1} z¯t−1 的分布。
- 在采样期间,ADDP从一个纯不可靠标记 z ¯ T z¯_T z¯T 的表示开始,并通过预测 z ¯ t − 1 z¯_{t−1} z¯t−1 来迭代地去噪标记序列
- 对于识别,通过像素到令牌生成网络学习到的表示可以转发到不同的任务特定的识别头。
- 带有 VQGAN标记器[47]MAGE-Large[99] 标记预测器和ViT - Large[45] 像素到标记编码器的ADDP在图像分类、目标检测、语义分割和无条件生成方面优于以前的统一模型
3.1.6 Generative augmentation(生成增强)

- 许多最先进的表征学习方法[33,55,60] 依赖于一组固定的数据增强来定义学习表征的正标签
- 这种方法鼓励编码器学习将原始图像和增强图像映射到相似的嵌入空间表示[10]
- 这些增强不应该改变图像的语义,也不应该使图像在现实环境中变得不真实
- 一组标准转换可能无法充分捕获真实世界数据的分布,这就提出了如何设计转换来创建不同的图像并提高学习表征的泛化性的问题。

- Ayromlou等人[10] 提出使用 潜在扩散模型[138] 来生成保留语义内容的原始图像的新视图,同时密切关注真实图像的分布。该增广方法表示为
式子18- 其中 G G G表示以噪声向量 z z z ~ N ( 0 , I ) N(0,I) N(0,I)和条件向量 φ ( x ) φ (x) φ(x)为输入的条件生成模型。
- φ φ φ是一个预训练的图像编码器,如CLIP [136],
- p ∈ [ 0 , 1 ] p∈[0,1] p∈[0,1]是一个随机数, p 0 p_0 p0是一个指定应用增广概率的超参数。
- Ayromlou等人[10]表明,与其他表征学习技术的标准转换相比,使用生成增强可以在学习表征方面取得一致的改进

- Shipard等人[150] 将这种方法更进一步,使用Stable Diffusion生成一个完全合成的数据集,以改进与模型无关的零射击分类(MA-ZSC)
- 他们使用稳定扩散,采用几种不同的提示来增加合成数据集的多样性。
- 随后在该合成数据集上训练图像分类器,并对 CIFAR10、CIFAR100和EuroSAT[64]上的零射击分类结果进行评估
- Shipard等人[150] 在上述数据集上观察到与分类架构无关的实质性改进,实现了与最先进的零射击分类方法(如 CLIP)相当的性能

- 在分类之外,Schnell等人[148] 将类似的思想应用于涂鸦监督分割[104,129],这是一种弱监督的语义分割形式,使用在图像上涂鸦的形式进行稀疏注释。
- 他们引入了ScribbleGen,这是一个以语义涂鸦为条件的扩散模型,可以生成用于数据增强的合成训练图像
- ScribbleGen利用ControlNet[185] 去噪扩散模型在给定 X t X_t Xt和条件信号 c c c的情况下进行噪声预测
- 类的数量用RGB图像中不同颜色的涂鸦来表示,并在调理信号 c c c中补充一个文本提示,说明图像中所有的类
- Schnell等[148] 通过引入编码比 λ∈[0,1] 来权衡真实感和图像多样性。
- 该扩散参数控制加噪前向扩散阶数,其中 λ = 1 导致无变化
- λ < 1 λ < 1 λ<1导致 λ ⋅ T λ·T λ⋅T阶数变化 ,即输入图像中加入的噪声较少
- 作者评估了固定λ和自适应λ,其中编码比例逐渐增加,以在训练过程中提供越来越多样化的合成图像。
- ScribbleGen使用 Scribblesup[104] 中的涂鸦在 PASCAL VOC12分割数据集[48] 上实现了最先进的性能

- DiffuMask[167] 是另一种生成增强方法,旨在改善下游语义分割任务
- 这里的想法是利用文本提示和生成的图像之间的交叉注意映射,将图像合成扩展到语义掩码生成
- 合成生成的掩码用于数据增强,以提高下游分割性能

- 使用基于AffinityNet的自适应阈值机制,对所有层的单个令牌注意图进行平均并转换为二进制掩码[4]
- 此外,噪声学习模块对低质量的分割蒙版进行了修剪,并采用了几种提示工程和静态图像变换来进一步增强生成图像和相应分割蒙版的多样性
3.2 Representation Learning for Diffusion Model Guidance(扩散模型指导的表示学习)

- 尽管生成模型的性能显著,但条件和无条件图像生成方法在质量上存在差距[25]
- 对于GANs来说尤其如此[53],当在完全无监督的环境中训练时,GAN会出现模式崩溃[110]。
- 无条件GANs通常不能准确地模拟多模态分布,例如不能为MNIST生成所有数字[110]。
- 类条件GANs[22][123] 缓解了这个问题,但需要标记数据。
- 最近的方法,如 自条件GANs[110] 和实例条件GANs[25],试图在不需要标记数据的情况下训练条件GANs,并且能够获得竞争性的生成结果

- 扩散模型已经超越了GANs的图像生成能力[42],但在条件和完全自监督方法之间存在类似的性能差异
- 目前最先进的扩散模型是条件模型,依赖于也需要注释数据的指导方法
- 自监督引导方法可以利用更大的未标记数据集进行预训练,因此具有超越当前图像生成方法的潜力
- 利用表示学习来促进这些指导方法的一种直观方法是探索为未标记数据分配标签的方法,例如通过聚类和分类方法
- 在下一节中,我们将介绍几种方法。
图5显示了用于扩散引导的表示学习技术的拟议分类。

图5所示。利用表征学习技术进行条件生成和指导的当前扩散模型训练框架的分层概述。
3.2.1 Assignment-based guidance(Assignment-based指导)

- Sheynin等人[149] 提出了kNN-Diffusion,这是一种无需大规模图像文本配对训练的高效文本到图像扩散模型
- 为了便于在没有配对文本-图像数据的情况下生成文本引导图像,需要一个将文本-图像对映射到相同潜在空间的共享文本-图像编码器。
- 作者使用CLIP来实现这一点,这是一种使用大规模文本图像对数据集上的对比损失来训练的预训练编码器。kNN-Diffusion利用最近邻搜索从检索模型生成k个嵌入
- 检索模型在训练时使用输入图像表示,在推理时使用文本提示表示。
- 这种方法消除了对注释数据的需求,但仍然需要像CLIP这样的预训练编码器,这反过来又需要大规模的文本图像嵌入数据集进行预训练
- Blattmann等[20] 提出了检索增强扩散模型(RDM),该模型为扩散模型提供了一个图像数据库,用于根据检索到的图像组成新的场景

- 受检索增强NLP[21,168] 的启发,RDM以更少的参数和计算资源提高了性能
- 尽管RDM只在图像上进行训练,但由于CLIP的共享图像-文本特征空间,RDM允许条件合成[136]
- RDM包括一个可训练的条件潜在扩散模型 p θ p_θ pθ,一个外部图像数据库 D D D,以及一个固定的采样策略 ξ k ξ_k ξk,该策略基于查询 x x x选择D的子集 M D ( k ) M^{(k)}_D MD(k)
- 一种策略 ξ k ( x , D ) ξ_k(x,D) ξk(x,D) 是使用 距离函数 d ( ⋅ , x ) d(·,x) d(⋅,x) 检索k个最近邻
- 检索到的数据是通过一个冻结的图像编码器 φ φ φ处理,并用于条件 p θ p_θ pθ。
- 在训练过程中, ξ k ξ_k ξk 使用CLIP图像特征空间中的余弦相似度作为距离函数 d ( x , y ) d(x, y) d(x,y),为查询图像 x x x检索 k k k个最近邻。
- 这种方法确保检索到的图像表示对于生成任务是有用的,并且由于CLIP的共享特征空间,允许进行文本调节。
- 数据集 D D D 和 检索策略 ξ k ξ_k ξk 可以在测试时更改,增加了不同条件调节模式的灵活性和对其他数据分布的适应性

相关文章:
【论文阅读】03-Diffusion Models and Representation Learning: A Survey
Abstract(摘要) 扩散模型是各种视觉任务中流行的生成建模方法,引起了人们的广泛关注它们可以被认为是 自监督学习方法【通过数据本身的结构和特征来训练模型,而不是依赖外部标签】 的一个独特实例,因为它们独立于标签注…...

【深度学习】RNN的简单实现
目录 1.RNNCell 2.RNN 3.RNN_Embedding 1.RNNCell import torchinput_size 4 hidden_size 4 batch_size 1idx2char [e, h, l, o] x_data [1, 0, 2, 2, 3] # 输入:hello y_data [3, 1, 2, 3, 2] # 期待:ohlol# 独热向量 one_hot_lookup [[1, …...

每次请求时,检查 JWT Token的有效期并决定是否需要刷新
为了在每次请求时检查 access_token 的有效期,并在过期时自动刷新,可以通过以下步骤实现: 1. 解析 JWT Token 获取过期时间 JWT token 的有效期是编码在 token 本身的,你可以通过解析 token 来获取它的到期时间。JWT token 是由…...
AI大模型开发架构设计(13)——LLM大模型的向量数据库应用实战
文章目录 LLM大模型的向量数据库应用实战1 大模型的局限性大模型的4点局限性大模型的4点局限性的改进实践方法 2 向量数据库使用场景以及改建大模型向量数据库向量数据库选型知识库文档检索增强(Retrieval Augmented Generation) 3 向量数据库应用技术架构剖析向量数据库应用技…...

WPF中Grid、StackPanel、Canvas、WrapPanel常用属性
Grid常用属性 Grid 控件在 WPF 中非常强大,它提供了多种属性来定义行和列的布局。以下是一些常用的 Grid 属性: RowDefinitions 和 ColumnDefinitions: Grid 控件使用 RowDefinitions 和 ColumnDefinitions 来定义行和列的集合。每个 RowDef…...

【芙丽芳丝净润洗面霜和雅漾舒护活泉喷雾
1. 洁面产品: - 芙丽芳丝净润洗面霜:氨基酸洗面奶的经典产品,成分温和,不含酒精、香料等刺激性成分。泡沫丰富细腻,能够有效清洁皮肤的同时,不会过度剥夺皮肤的油脂,洗后皮肤不紧绷,…...

ubuntu更新Cmake
CMake 先验知识创建软链接如何删除符号链接如何找出失效链接并将其删除PATH 优先级查看当前CMake命令的位置 高版本 CMake 安装参考 先验知识 创建软链接 ln -s <path to the file/folder to be linked> <the path of the link to be created>ln 是链接命令&…...

CMOS晶体管的串联与并联
CMOS晶体管的串联与并联 前言 对于mos管的串联和并联,一直没有整明白,特别是设计到EDA软件中,关于MOS的M和F参数,就更困惑了,今天看了许多资料以及在EDA软件上验证了电路结构与版图的对应关系,总算有点收…...

从IT高管到看门大爷:53岁我的职场华丽转身
该文讲述了一位1971年出生的男士,在53岁时因日企撤资而失业。他曾是IT技术员,后晋升为IT高管兼工会主席,但失业后数百份简历石沉大海,面试也因年龄被取消。他意识到年龄是求职的障碍,开始调整心态,降低期望…...
Redis入门到精通(三):入门Redis看这一篇就够了
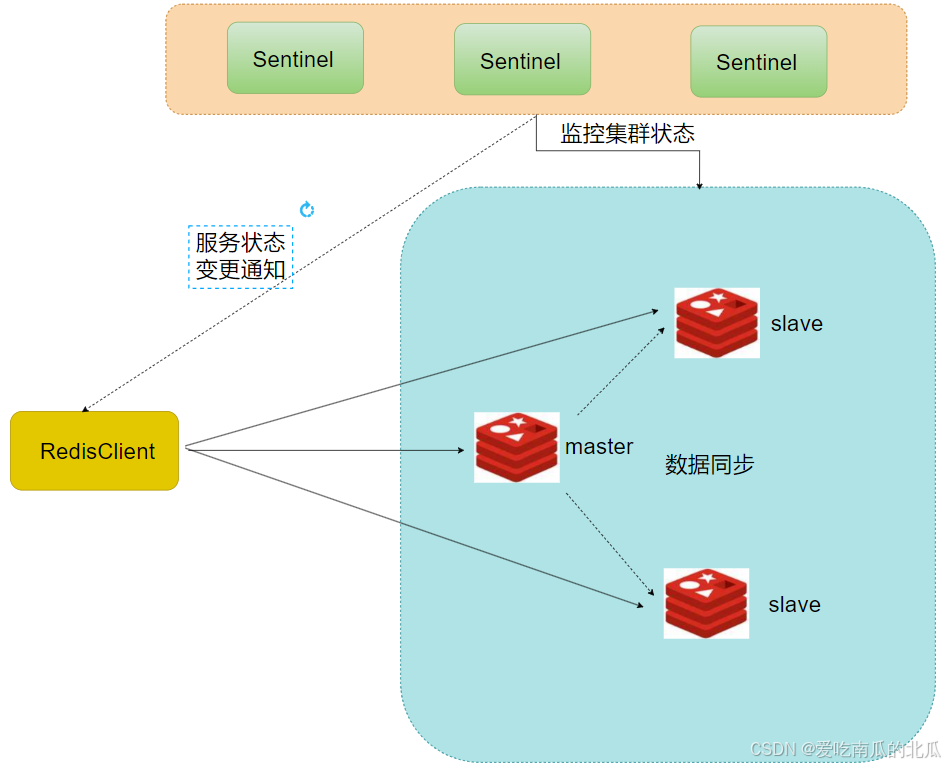
文章目录 Redis分布式锁的实现原理Redis实现分布式锁如何合理的控制锁的有效时常?**redisson实现的分布式锁**redisson实现的如何保证主从一致性 Redis的集群方案1.主从复制主从数据的同步原理全量同步增量同步 2.哨兵模式Redis的集群脑裂是什么?3.分片集…...

IP基本原理
IP的定义 当前唯一的网络层协议标准定义数据网络层的封装方式、编址方法 MTU 最大传输单元接口收发数据支持的单个包的最大长度不同二层链路类型的接口的MTU不一致。以太网接口默认MTU1500Byte。PPPoE接口默认MTU1480Byte。 IP头部封装格式 IP 头部长度不固定,2…...

数据分析题面试题系列2
一.如何估算星巴克一天的营业额 a.需求澄清:区域?节假日?产品范围? b.收入销售杯数*单价(营业时间*每小时产能*每小时产能利用率)*平均单价 Hypo该星巴克门店的营业时间为12小时(取整&#x…...

uniapp 单表、多级动态表单添加validateFunction自定义规则
uniapp 多级动态表单添加自定义规则 在uniapp制作小程序时,当涉及到需要设置validateFunction的校验规则时。可能遇到的问题 1、validateFunction不生效,没有触发 2、多层级表单怎么添加validateFunction自定义校验规则 本文将以单表单校验和多表单校…...

FPGA高端图像处理培训第一期,提供工程源码+视频教程+FPGA开发板
目录 1、FPGA图像处理培训现状分析2、本FPGA图像处理培训优势亮点架构全起点高实用性强项目应用级别细节恐怖工程源码清晰 3、本FPGA图像处理培训内容介绍图像处理基本框架图像前处理框架图像中处理框架图像前中处理框架图像后处理框架图像中后处理框架图像处理仿真框架视频教程…...
——C语言)
顺序表的实现(数据结构)——C语言
目录 1.结构与概念 2.分类 3 动态顺序表的实现 SeqList.h SeqList.c 创建SLInit: 尾插SLPushBack以及SLCheak(检查空间是否足够): 头插SLPushFront: 尾删SLPopBack 头删SLPopFront 查找指定元素SLFind 指定…...

【VUE】Vue中 computed计算属性和watch侦听器的区别
核心功能不同 computed 是一个计算属性,其核心功能是基于已有的数据属性计算得出新的属性值。当某个依赖的数据发生变化时,computed 会自动重新计算并更新自己的值。因此,可以将 computed 看做是一种“派生状态”。 watch 是一个观察者函数&…...

linux线程 | 同步与互斥 | 深度学习与理解同步
前言:本节内容主要讲解linux下的同步问题。 同步问题是保证数据安全的情况下,让我们的线程访问具有一定的顺序性。 线程安全就规定了它必须是在加锁的场景下的!!那么, 具体什么是同步问题, 我们加下来看看吧…...

Tkinter Frame布局笔记--做一个简易的计算器
#encodingutf-8 import tkinter import re import tkinter.messagebox import tkinter.simpledialog import sys import os def get_resources_path(relative_path):if getattr(sys,frozen, False):base_pathsys._MEIPASS#获取临时文件else:base_pathos.path.dirname(".&q…...

算法专题八: 链表
目录 链表1. 链表的常用技巧和操作总结2. 两数相加3. 两两交换链表中的节点4. 重排链表5. 合并K个升序链表6. K个一组翻转链表 链表 1. 链表的常用技巧和操作总结 常用技巧 画图!!! 更加直观形象, 便于我们理解引入虚拟头节点, 方便我们对链表的操作, 减少我们对边界情况的考…...
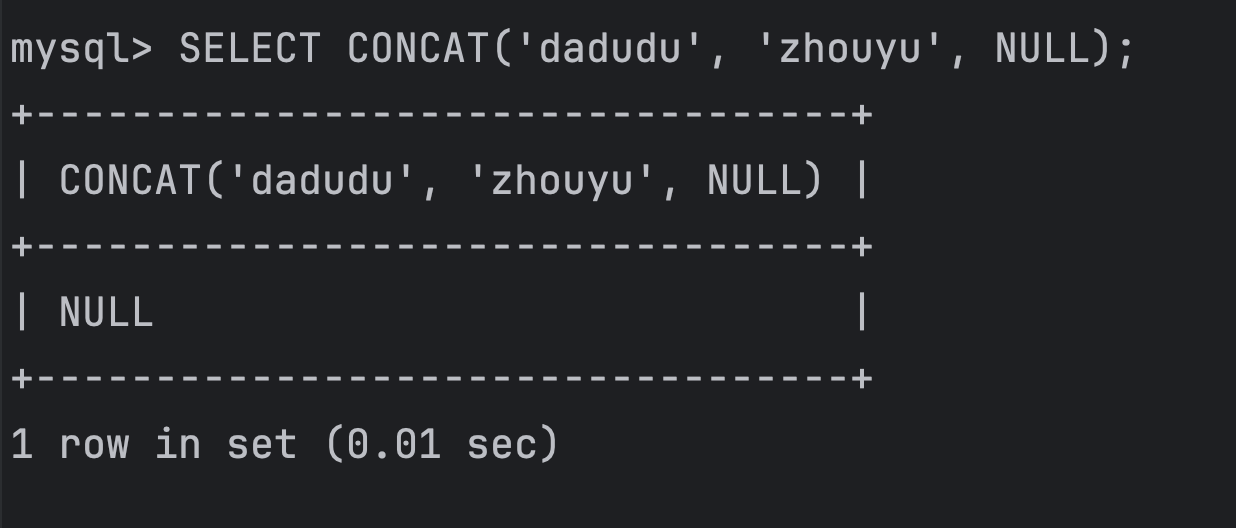
MySQL中关于NULL值的六大坑!你被坑过吗?
NULL值是我们在开发过程中的老朋友了,但是这个老朋友在MySQL中有很多坑,我通过这篇文章来总结分享一下,欢迎大家在评论区分享你的看法和踩坑经历。 1、NULL不等于NULL 在MySQL中,执行以下SQL会返回NULL 假如t表有以下数据&#…...

从MobileViT到BERT:结构化剪枝如何帮你打造“小钢炮”模型?实战案例与调参避坑指南
从MobileViT到BERT:结构化剪枝实战与调参避坑指南 在移动端和边缘计算场景中,模型小型化已成为AI落地的关键瓶颈。当我们将参数量超过1亿的ViT或BERT部署到手机、嵌入式设备甚至普通GPU服务器时,内存占用大、推理延迟高、能耗超标等问题会集中…...

从零构建MMRotate旋转检测实战:自定义数据集制作与模型调优全解析
1. 环境准备与MMRotate安装 第一次接触旋转目标检测时,我被各种坐标转换搞得头晕眼花。直到发现MMRotate这个神器,才让整个流程变得清晰可控。作为OpenMMLab家族成员,它封装了R3Det、Rotated Faster RCNN等主流旋转检测算法,特别适…...

5分钟快速上手OHIF-Viewers:零基础搭建医学影像DICOMweb阅片环境
5分钟快速上手OHIF-Viewers:零基础搭建医学影像DICOMweb阅片环境 医学影像数字化阅片已成为现代医疗信息化的核心需求。对于刚接触医疗IT的临床转技术人员或医疗信息化初学者而言,如何快速搭建一个符合DICOMweb标准的阅片环境常常令人望而生畏。本文将带…...

FastAPI子应用挂载:别再让root_path坑你一夜久
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...
)
告别传统网卡!用ESP32/ESP32-S3给树莓派或Linux主机加装WiFi/BT模块(esp-hosted实战)
用ESP32打造高性能无线网卡:esp-hosted方案实战指南 手里闲置的ESP32开发板除了吃灰还能干什么?今天我要分享一个让旧设备重获新生的技巧——将ESP32变身成为Linux主机的无线网卡。相比动辄上百元的USB无线网卡,这个方案成本几乎为零…...

5个BepInEx插件开发高级技巧:让你的Unity游戏模组更稳定可靠
5个BepInEx插件开发高级技巧:让你的Unity游戏模组更稳定可靠 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是Unity游戏模组开发的终极框架,为Mono…...

别再手动加电阻了!手把手教你用Xilinx 7系列FPGA的DCI功能搞定高速信号完整性
别再手动加电阻了!手把手教你用Xilinx 7系列FPGA的DCI功能搞定高速信号完整性 当你在设计一块高速数据采集卡时,是否曾被密密麻麻的端接电阻搞得焦头烂额?每个LVDS差分对需要两个100Ω电阻,DDR3接口每根数据线又得配一个39Ω电阻.…...
)
2026奇点智能大会前瞻:为什么92%的AI工程团队将在Q3前重构Agent框架?(Gartner未公开预警报告首曝)
第一章:2026奇点智能技术大会:大模型Agent框架 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将大模型Agent框架确立为核心技术范式,聚焦于可推理、可规划、可协作的自主智能体系统设计。与传统微调或提示工程不同,…...
的Mesh_XY路由与流量控制)
保姆级教程:用Gem5仿真NoC(片上网络)的Mesh_XY路由与流量控制
从零构建Gem5仿真环境:Mesh_XY路由与信用流量控制的NoC实战指南 为什么需要深入理解NoC仿真? 在现代多核处理器设计中,片上网络(NoC)已成为解决核间通信瓶颈的关键架构。与传统的总线结构相比,NoC通过分布式路由和分组交换提供了更…...

从极简设计到高效标注:gInk屏幕标注工具的技术解析与实践指南
从极简设计到高效标注:gInk屏幕标注工具的技术解析与实践指南 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk是一款面向Windows平台的轻量级屏幕标注工…...