2、图像的特征
一、角点检测-Harris
1、cv2.cornerHarris角点检测函数
在 cv2.cornerHarris 函数中,Sobel 算子用于计算图像的梯度,这是 Harris 角点检测的第一步。
cv2.cornerHarris(src, blockSize, ksize, k, dst=None, borderType=None)
下面是各个参数的详细解释:
| 参数 | 含义 |
|---|---|
src | 输入图像。必须是灰度图像(单通道),类型为 numpy.float32。 |
blockSize | 角点检测中窗口的大小,表示在计算导数矩阵时的邻域大小。 |
ksize | Sobel 算子用于计算图像梯度的核大小,通常为 3。 |
k | Harris 角点检测方程中的自由参数,通常取值范围在 [0.04, 0.06]。 |
dst | 可选的输出图像。通常不需要指定。 |
borderType | 可选的边界模式,用于处理图像边界像素的方式。默认值为 cv2.BORDER_DEFAULT。 |
# 使用 Harris 角点检测
dst = cv2.cornerHarris(gray, blockSize=2, ksize=3, k=0.04)
返回值:
函数会返回一个浮点型矩阵(单通道),矩阵中每个像素点的值表示 Harris 响应函数的响应值,响应值越大表明角点的可能性越高。
2、Harris 角点检测过程
具体来说,Harris 角点检测的过程包括以下几个步骤:
-
计算图像梯度:
- Sobel 算子在
x和y方向上计算图像的梯度(即像素强度的变化率),这是为了找到图像中的边缘信息。 cv2.cornerHarris函数会对输入的灰度图像应用 Sobel 算子来计算两个方向的梯度: I x I_x Ix 和 I y I_y Iy。ksize参数决定了 Sobel 算子使用的卷积核大小(如 3x3 或 5x5),它影响计算梯度时的平滑程度。
梯度计算公式:
- 对于水平梯度: Sobel 算子在
x方向计算: I x = ∂ I / ∂ x I_x = ∂I/∂x Ix=∂I/∂x - 对于垂直梯度: Sobel 算子在
y方向计算: I y = ∂ I / ∂ y I_y = ∂I/∂y Iy=∂I/∂y
- Sobel 算子在
-
构建结构张量(协方差矩阵):
- 根据计算出的梯度,生成图像的结构张量(也叫协方差矩阵)。这个矩阵在 Harris 算法中用于描述一个像素点的局部邻域特性。
- 结构张量的每个元素依赖于图像的局部梯度平方和:
$
M = \begin{bmatrix} I_x^2 & I_x I_y \ I_x I_y & I_y^2 \end{bmatrix}
$ - 其中, I x I_x Ix 和 I y I_y Iy 是通过 Sobel 算子计算得到的水平和垂直梯度。
-
角点响应计算:
- 使用 Harris 角点检测公式计算角点响应:
$
R = \det(M) - k \cdot (\text{trace}(M))^2
$ - 其中
det(M)是矩阵的行列式,trace(M)是矩阵的迹(对角线元素的和),k是经验参数。
- 使用 Harris 角点检测公式计算角点响应:
-
角点检测:
- 根据计算得到的角点响应值
R,检测图像中的角点位置。响应值较大的位置被认为是角点。
- 根据计算得到的角点响应值
3、Sobel 在 Harris 角点检测中的作用:
Sobel 算子用于 Harris 算法的第一步,它计算了图像的梯度,这些梯度信息是后续角点检测的基础。具体来说:
- 通过 Sobel 算子得到的梯度图 I x I_x Ix 和 I y I_y Iy,反映了图像中每个像素在水平方向和垂直方向上的强度变化(边缘信息)。
- Sobel 算子帮助 Harris 算法判断图像中哪些区域具有显著的边缘和角点特征。
4、bsize,ksize,矩阵M
blockSize:
- 在 Harris 角点检测中,涉及到对图像的局部区域进行分析,这个局部区域的大小由
blockSize决定。- 例如,
blockSize=3表示在每个像素点的检测中会使用一个 3x3 的窗口来计算该区域的协方差矩阵。blockSize较大时,角点检测会对图像的较大区域进行平滑,容易忽略小的细节;而较小的blockSize则能捕捉更多的局部特征。
ksize:
- 这是 Sobel 算子的参数,Sobel 算子用于计算图像梯度(即像素强度的变化率),并且是角点检测的前置步骤。
ksize控制 Sobel 算子的窗口大小,例如ksize=3表示使用 3x3 的 Sobel 核来计算水平和垂直方向的梯度。ksize较大时,计算得到的梯度会更加平滑,但可能导致细节损失;较小的ksize能捕捉更多的细节边缘。
blockSize指定的区域内的所有像素点的 I x I_x Ix 和 I y I_y Iy 值都需要计算出来。这些梯度值用于构建协方差矩阵(结构张量)对于
blockSize指定的每个窗口,计算该区域内所有像素的梯度值:M = [ ∑ I x 2 ∑ I x I y ∑ I x I y ∑ I y 2 ] M = \begin{bmatrix} \sum I_x^2 & \sum I_x I_y \\ \sum I_x I_y & \sum I_y^2 \end{bmatrix} M=[∑Ix2∑IxIy∑IxIy∑Iy2]
这里的求和是针对整个 b l o c k S i z e × b l o c k S i z e blockSize \times blockSize blockSize×blockSize 的区域进行的。
img = cv2.imread('test_1.jpg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
# img.shape: (800, 1200, 3)
# dst.shape: (800, 1200)
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

二、关于高斯滤波
高斯滤波的实现:
-
高斯核:首先生成一个高斯核(即高斯滤波器),它是一个二维的权重矩阵,形状通常是正方形。高斯核的值由高斯函数决定,通常为:
G ( x , y ) = 1 2 π σ 2 e − x 2 + y 2 2 σ 2 G(x, y) = \frac{1}{2\pi\sigma^2} e^{-\frac{x^2 + y^2}{2\sigma^2}} G(x,y)=2πσ21e−2σ2x2+y2
其中, σ \sigma σ 是标准差,控制高斯分布的宽度。
-
卷积操作:使用这个高斯核与输入图像进行卷积。这一过程将高斯核的每个值与图像对应区域的像素值相乘,然后将结果相加,得到输出图像中对应位置的值。
控制步长与输出尺寸:
- 步长(Stride):步长是卷积操作中高斯核滑动的步幅。如果将步长设置为 1,则高斯核会每个像素都覆盖到,计算出的输出图像会比输入图像小。
- 填充(Padding):为了保持输出图像与输入图像大小相同,通常在输入图像周围增加额外的像素(填充)。这样,在卷积时,高斯核能够在图像的边缘上也能进行计算。
三、关于DOG
DOG(Difference of Gaussian)是一种用于图像处理和特征提取的技术,主要用于检测图像中的边缘和角点。其基本思想是通过两个不同标准差的高斯滤波器之间的差异来实现特征检测。
DOG 的主要用途:
-
边缘检测:
- DOG 可以有效地检测图像中的边缘,尤其是在具有高频细节的图像中。通过比较不同尺度下的高斯模糊效果,DOG 能够突出显示边缘特征。
-
特征提取:
- 在计算机视觉中,DOG 是许多特征提取算法的基础,例如 SIFT(Scale-Invariant Feature Transform)。SIFT 使用 DOG 来检测关键点,从而在不同尺度上提取图像特征。
-
图像平滑与噪声抑制:
- DOG 通过使用高斯滤波器,能够在不同尺度上平滑图像并减少噪声,这对于后续的图像处理步骤非常有用。
DOG 的实现步骤:
-
生成两个高斯模糊图像:
- 对原始图像应用两个不同标准差的高斯滤波器,得到两个模糊图像。
-
计算差异:
- 将两个模糊图像相减,得到 DOG 图像。这个差异图像突出显示了在这两个尺度之间显著变化的区域,通常对应于边缘和角点。
代码示例:
以下是使用 OpenCV 实现 DOG 的一个示例:
import cv2
import numpy as np# 读取图像
img = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)# 应用两个高斯模糊
sigma1 = 1.0 # 第一个高斯的标准差
sigma2 = 2.0 # 第二个高斯的标准差
blur1 = cv2.GaussianBlur(img, (0, 0), sigma1)
blur2 = cv2.GaussianBlur(img, (0, 0), sigma2)# 计算 DOG
dog = blur1 - blur2# 显示结果
cv2.imshow('DOG Image', dog)
cv2.waitKey(0)
cv2.destroyAllWindows()
总结:
DOG 是一种有效的边缘和特征检测方法,通过对不同尺度下的高斯滤波结果进行差异计算,能够突出显示图像中的重要特征,在计算机视觉和图像处理领域有着广泛的应用。
为何差异计算可以得到特征❤️
通过对不同尺度下的高斯滤波结果进行差异计算,DOG(Difference of Gaussian)能够突出显示图像中的重要特征,这主要是因为以下几个原因:
1. 尺度空间理论:
- ==图像中的特征(如边缘和角点)在不同的尺度( σ \sigma σ)上表现不同。==使用两个不同标准差的高斯滤波器,可以在多个尺度上分析图像,捕捉到不同层次的细节。
- 较小的标准差能够捕捉到图像中的细节特征,而较大的标准差则能够平滑掉这些细节,关注整体结构。
2. 边缘增强:
- 当图像中存在边缘时,边缘两侧的像素值变化较大。应用高斯滤波后,边缘的像素会在较小标准差的高斯模糊中保持较高的响应,而在较大标准差的高斯模糊中会被平滑掉。
- 通过计算这两者的差异,边缘处的响应值会变得显著,从而突出显示边缘特征。
3. 抑制噪声:
- DOG 不仅能够强调特征,还可以抑制图像中的噪声。在较大的尺度下,噪声通常会被平滑掉,因此通过差异计算能够有效减少噪声的影响,保留真正的特征信息。
4. 关键点检测:
- 在使用 DOG 进行关键点检测(如 SIFT)时,DOG 可以帮助识别图像中具有显著变化的区域,这些区域通常是角点或边缘。
- 通过对 DOG 图像进行阈值处理,可以识别出具有局部极值的点,进一步提取出重要的特征点。
总结:
差异计算能够得到特征的核心原因在于不同尺度的高斯模糊分别保留和抑制了图像的不同特征,最终通过计算这两者的差异,能够突出显示图像中最显著的变化(如边缘和角点),从而实现有效的特征检测。这种方法利用了尺度空间的优势,使得图像处理在多种应用中更具灵活性和鲁棒性。
四、SIFT原理
使用 DOG(Difference of Gaussian)进行关键点检测的过程,特别是在 SIFT(Scale-Invariant Feature Transform)算法中,分为几个主要步骤:
1. 构建高斯金字塔与 DOG 金字塔:
- 对图像进行高斯模糊,使用不同标准差 ( σ \sigma σ) 的高斯滤波器来模糊图像。模糊后的图像在不同尺度上形成高斯金字塔。
- ==计算相邻尺度之间的差分,形成 DOG 金字塔。==每一层代表不同尺度下的高斯模糊结果之间的差异。
过程:
- 对原始图像进行高斯滤波,逐渐增加 ( σ \sigma σ) 值,得到多层高斯金字塔。
- 对每一对相邻的高斯模糊图像进行差分,得到多层 DOG 金字塔。
2. 在 DOG 金字塔中检测极值点:
- 对于 DOG 金字塔中的每个像素,比较它与邻近的 26 个像素(即上下两层和当前层的 8 个邻居)。如果该像素是这 26 个像素中的最大值或最小值,则认为它是一个关键点候选。
过程:
- 每个像素与它在相邻尺度(上下层)的 8 个像素和当前尺度(同一层)的 8 个像素进行比较,找出局部极值。
3. 关键点精确定位❤️:
- 对找到的极值点进行精确定位。使用泰勒展开在尺度空间中拟合极值点,并去除对比度过低或位于边缘的点。
过程:
- 对关键点进行二次拟合,以提高检测的精度,去掉那些响应不够显著或在边缘的点。

在 SIFT 算法中,原始的关键点检测是在 DOG(高斯差分)金字塔中通过比较邻域像素值找到的局部极值点。这些极值点是在像素级别上通过简单的比较操作得到的,因此它们的定位是离散的,即受限于图像网格的整数像素位置。
为什么原来的关键点不够精确?
像素级别的限制:
- DOG 算法初步检测到的关键点位置是基于图像的整数像素坐标(即在每个像素之间进行比较)。由于图像的特征可能位于像素之间,而不是恰好在某个像素的整数坐标上,因此初步检测的关键点可能并不完全准确。
- 这种粗粒度的关键点检测只能捕捉到特征的大致位置,但在亚像素级别上可能会有偏差。
响应不显著:
- 一些初步检测到的关键点可能响应值较弱,尤其是当它们处于噪声、低对比度或平滑区域中时。这些点虽然被检测为极值,但对实际图像特征的贡献很小,容易受到噪声干扰。
边缘响应的不稳定性:
- 在 DOG 金字塔中,边缘附近的点也可能表现为局部极值。但这些边缘点通常非常不稳定,容易受到图像细微变化的影响。因此,虽然这些点可能被初步检测为关键点,但它们并不可靠,需要进一步精确定位并排除。
为什么需要精确定位?
获得亚像素级别的精度:
- 真实世界中的图像特征不一定位于整数像素位置上,可能在两个像素之间。因此,检测到的关键点如果仅停留在整数像素位置,会丢失一些重要的细节。通过泰勒展开和二次拟合,SIFT 可以将关键点的定位从整数像素位置扩展到亚像素级别,使特征点的精度更高。
提高关键点的稳定性:
- 在 DOG 金字塔中直接检测到的极值点有时可能受噪声干扰,或者由于对比度不高而不稳定。通过精确定位,可以剔除低对比度或不稳定的关键点,保证留下来的都是对图像整体结构有显著贡献的关键点。
消除边缘响应点:
- 边缘上的极值点虽然可能是初步检测到的关键点,但它们不够稳定。通过对这些点进行进一步分析(如 Hessian 矩阵),可以识别出哪些点是边缘响应,从而将其剔除,确保关键点的稳定性和可靠性。
精确定位的好处:
- 亚像素精度:通过二次拟合和泰勒展开,关键点的坐标可以在亚像素级别上得到精确确定,使得后续的特征匹配更加准确。
- 剔除无效点:通过对比度检测和边缘响应排除,去掉噪声点和边缘不稳定点,确保只保留图像中的重要特征点。
- 提升匹配的鲁棒性:更精确的关键点定位使得这些点在不同尺度、旋转和视角下更加稳定,从而提高了后续特征描述和匹配的鲁棒性。
总结:
初步检测到的关键点虽然是局部极值,但由于整数像素坐标的限制、对比度不强的点以及边缘响应的不稳定性,这些关键点往往不够精确和稳定。通过关键点精确定位步骤,SIFT 可以将关键点的定位提升到亚像素级别,并剔除不稳定的点,确保后续的特征匹配更加准确和鲁棒。
关键点精确定位的具体步骤:
拟合极值点:
- SIFT 使用泰勒展开在尺度空间中对 DOG 金字塔中的局部极值点进行二次拟合,精确确定关键点的位置(包括子像素级别的精度)、尺度和响应值。
- 使用 DOG 函数的二阶泰勒展开近似,将极值点的位置、尺度从整数精度优化到亚像素精度。
泰勒展开公式:
D ( x ) = D + ∂ D ∂ x Δ x + 1 2 Δ x T ∂ 2 D ∂ x 2 Δ x D(x) = D + \frac{\partial D}{\partial x} \Delta x + \frac{1}{2} \Delta x^T \frac{\partial^2 D}{\partial x^2} \Delta x D(x)=D+∂x∂DΔx+21ΔxT∂x2∂2DΔx
其中 D 是 DOG 金字塔中的像素值, Δ x \Delta x Δx 是位置的微小变化。
去除低对比度关键点:
- 对于那些响应较弱的关键点,即 DOG 函数的值较小的关键点,SIFT 将其过滤掉。这是为了确保选出的关键点是图像中的显著特征,而非噪声或模糊区域。
- 如果通过拟合得到的关键点响应值低于某个阈值(通常是 0.03),则该关键点会被丢弃。
去除边缘响应点:
- 边缘响应的点虽然在 DOG 图像中也表现为极值点,但它们不稳定且易受噪声影响。为了避免选择边缘上的关键点,SIFT 使用 Hessian 矩阵的主曲率来判断边缘点,并滤除这些点。
- SIFT 利用 Hessian 矩阵的特征值来衡量局部区域的曲率。如果一个点在某个方向的主曲率远大于另一个方向的主曲率,就认为该点位于边缘,从而将其舍弃。
Hessian 矩阵:
H = [ D x x D x y D x y D y y ] H = \begin{bmatrix} D_{xx} & D_{xy} \\ D_{xy} & D_{yy} \end{bmatrix} H=[DxxDxyDxyDyy]
- 通过计算 Hessian 矩阵的特征值,可以判断某个点是否是边缘点。如果主曲率的比值(即两个特征值的比值)超过某个阈值,通常是 10,那么该点会被认为是边缘点,并被舍弃。
4. 关键点方向分配❤️:
- 为了使得关键点具有旋转不变性,SIFT 为每个关键点分配一个方向。通过计算关键点邻域内的梯度方向直方图,确定主方向(最大值)。
- 为了让 SIFT 特征在不同的旋转角度下保持一致,必须为每个关键点分配一个主方向,这样即使图像发生旋转,特征点仍然可以被匹配。

- 每个特征点可以得到三个信息 ( x , y , σ , θ ) (x,y,σ,θ) (x,y,σ,θ),即位置、尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
过程:
- 在关键点周围计算梯度方向和幅度,使用这些信息构建梯度方向直方图。最大值方向被选为该关键点的主方向。
为什么要得到关键点方向?
为了让 SIFT 特征在不同的旋转角度下保持一致,必须为每个关键点分配一个主方向,这样即使图像发生旋转,特征点仍然可以被匹配。
原因:
- 旋转不变性:图像中的物体可能会因为拍摄角度的变化而旋转。如果不考虑旋转,直接使用图像中的关键点,图像旋转后相同的物体的特征将变得无法匹配。因此,为了让关键点的描述子与旋转无关,必须为每个关键点分配一个主方向。
- 统一特征表示:通过为关键点分配方向,后续生成的特征描述子可以基于这个方向进行计算。这样,当图像旋转时,特征描述子仍然会指向相同的方向,确保特征匹配不受旋转的影响。
2. 如何计算关键点方向?
SIFT 在计算关键点方向时,会选择一个以关键点为中心的局部邻域(通常是一个半径为 3 倍高斯模糊尺度的区域),并计算该区域内每个像素的梯度方向和梯度幅值。然后根据梯度信息构建方向直方图,直方图的峰值代表主方向。
具体步骤:
计算梯度方向和幅值:
- 对关键点邻域内的每个像素,计算其梯度方向和幅值。梯度是通过 Sobel 算子或者差分法得到的。
梯度幅值 m ( x , y ) m(x, y) m(x,y) 和梯度方向 θ ( x , y ) \theta(x, y) θ(x,y) 的公式如下:
m ( x , y ) = ( I ( x + 1 , y ) − I ( x − 1 , y ) ) 2 + ( I ( x , y + 1 ) − I ( x , y − 1 ) ) 2 m(x, y) = \sqrt{(I(x+1, y) - I(x-1, y))^2 + (I(x, y+1) - I(x, y-1))^2} m(x,y)=(I(x+1,y)−I(x−1,y))2+(I(x,y+1)−I(x,y−1))2
θ ( x , y ) = a r c t a n ( I ( x + 1 , y ) − I ( x − 1 , y ) I ( x , y + 1 ) − I ( x , y − 1 ) ) θ(x,y)=arctan(I(x+1,y)−I(x−1,y)I(x,y+1)−I(x,y−1)) θ(x,y)=arctan(I(x+1,y)−I(x−1,y)I(x,y+1)−I(x,y−1))
其中 I ( x , y ) I(x, y) I(x,y)是图像在 ( x , y ) (x, y) (x,y) 位置的像素值。
构建方向直方图:
- 将梯度方向分成 36 个方向(每个方向覆盖 10°),并根据每个像素的梯度幅值为这些方向加权累加,生成一个方向直方图。梯度幅值越大,说明该方向上变化越剧烈,因此该方向在直方图中的权重也越高。
- 在计算梯度时,对距离关键点较远的像素进行高斯加权,距离越远的像素权重越小。这是为了减少远离关键点的像素对方向计算的影响,保证方向主要反映关键点局部的特征。
选择主方向:
- 直方图中的最大值方向被选为该关键点的主方向。有时,若某个方向的次峰值也较大(通常大于主峰值的 80%),则该关键点会分配多个方向,从而在多个方向上增强特征点的描述能力。
3. 为什么要计算邻域?
计算邻域内像素的梯度方向和幅值,是为了确保关键点的方向能够反映局部区域内的图像变化,而不仅仅依赖于单个像素。通过这种方式,计算出的方向可以更稳定和准确,减少噪声或局部异常对方向的影响。
原因:
- 局部稳定性:单个像素的梯度方向可能会受到噪声影响,或者因为它所处的图像区域比较平滑而不够稳定。通过计算关键点邻域内多个像素的梯度方向,SIFT 能够提取出更稳定的方向信息,确保关键点方向是对局部图像变化的真实反映。
- 增强鲁棒性:邻域内的梯度方向能够更全面地反映该区域内的特征信息。通过在邻域内累加多个像素的梯度信息,SIFT 能够捕捉到该区域的主要变化方向,增强特征点的鲁棒性,尤其是在噪声或光照变化情况下。
4. 关键点方向的重要性总结:
- 实现旋转不变性:通过为每个关键点分配主方向,确保图像在旋转时,关键点的描述子不会受影响。即使图像发生旋转,基于关键点主方向构建的描述子仍然可以与其他图像中的对应特征进行正确匹配。
- 稳定关键点描述:计算邻域中的梯度信息并构建方向直方图,可以确保关键点的方向是基于局部区域的整体变化,而不是受单个像素的局部噪声干扰。
总结:
- 得到关键点方向 是为了实现旋转不变性,确保图像旋转时特征点仍能正确匹配。
- 计算邻域的梯度信息 是为了增强方向计算的稳定性和准确性,确保关键点的方向能够反映局部区域的真实变化。
5. 生成关键点描述子:
- 对每个关键点,根据它的主方向,在其周围构建一个 8x8 的窗口,将窗口划分成 4x4 的子区域。在每个子区域内计算梯度方向的直方图,最终生成 32 维的描述子。

过程:
- 每个 4x4 子区域计算 8 个方向的梯度直方图,这样 4 个子区域共生成 32 维的描述子。
旋转之后的主方向为中心取8x8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4x4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征的由4个种子点组成,每个种子点有8个方向的向量信息。

(4,4,8)
特征点方向与邻域内的方向有什么区别?
SIFT 处理关键点方向和邻域内的方向有两个层次:
- 关键点方向(主方向):这是在前面步骤中计算的,表示的是关键点的主要方向,用于实现旋转不变性。通过为每个关键点分配一个方向(或者多个方向),确保即使图像旋转,关键点描述子依然能够被正确匹配。这个方向是通过计算关键点局部区域内像素的梯度信息,生成方向直方图并选择主峰值的方向来得到的。
- 关键点方向的计算是在关键点检测之后,构建描述子之前完成的。它用于归一化关键点局部区域的方向,使得描述子与图像旋转无关。
- 邻域内的方向(用于生成描述子):在生成 SIFT 特征描述子时,对关键点邻域的每个小区域(如 4x4 子区域)都计算梯度方向和梯度幅值,并构建方向直方图。这些直方图表示的是该小区域内的局部方向信息。通过将这些局部方向的信息进行组合,生成一个反映关键点周围结构的 128 维特征向量。
- 这些方向不仅仅反映关键点的主方向,而是描述了关键点周围的多个方向上的变化。这些信息有助于生成更丰富、细致的特征描述子,使其更加鲁棒。
总结:
- SIFT 特征描述子是通过计算关键点邻域内多个小区域的梯度方向和幅值来生成的,每个区域生成一个方向直方图。
- 关键点方向是特征点的主方向,用于对邻域方向进行归一化,确保特征描述子在旋转不变的情况下依然能够有效匹配。
- 邻域方向是描述子生成过程中对关键点周围的局部方向信息进行编码的结果,它描述了关键点周围的图像特征。
6. 匹配关键点:
- 在检测到关键点及其描述子后,可以通过对比不同图像中的描述子,寻找相似的关键点以进行图像匹配。
过程:
- 通过最近邻匹配算法(如欧氏距离)将不同图像中的关键点描述子进行匹配。
SIFT 关键点检测总结流程:
- 高斯模糊与 DOG 差分:构建高斯金字塔,计算相邻尺度之间的差分,生成 DOG 金字塔。
- 极值检测:在 DOG 金字塔中检测局部极值点。
- 精确定位:拟合极值点,并去除低对比度或边缘上的关键点。
- 方向分配:为每个关键点分配一个主方向,使得关键点具有旋转不变性。
- 描述子生成:构建 128 维的特征描述子。
- 关键点匹配:通过特征描述子匹配不同图像中的关键点。
这个过程让 SIFT 能够在不同尺度、不同旋转角度下进行关键点检测和匹配,从而在图像匹配、特征识别中表现出强大的鲁棒性和稳定性。
五、SIFT实例🦄
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create() # 创建一个 SIFT 特征检测器对象
# 关键点(kp)对象
# kp 是一个包含多个 KeyPoint 对象的列表,每个 KeyPoint 对象包含以下信息:
kp = sift.detect(gray, None) # 在灰度图像 'gray' 中检测关键点
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

cv2.xfeatures2d.SIFT.compute() 和 cv2.xfeatures2d.SIFT.detect() 是 SIFT 特征检测和描述算法中非常重要的两个函数,分别用于检测图像中的关键点和计算这些关键点的特征描述符。下面是对这两个函数的详细解释。
1. sift.detect()
kp = sift.detect(gray, None)
- 功能:用于检测图像中的关键点。
- 参数:
gray:输入图像,必须为单通道灰度图像。None:可选的掩码参数,指定要检测的区域。如果没有特定区域,设置为None。
- 返回值:返回一个关键点列表(
cv2.KeyPoint对象),每个对象包含关键点的位置、尺度、方向等信息。
示例:
import cv2# 读取图像并转换为灰度图
img = cv2.imread('image.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 创建 SIFT 特征检测器对象
sift = cv2.xfeatures2d.SIFT_create()# 检测关键点
kp = sift.detect(gray, None)
2. sift.compute()❤️
keypoints, descriptors = sift.compute(gray, kp)
- 功能:计算给定关键点的特征描述符。
- 参数:
gray:输入图像,通常为灰度图像,用于计算特征描述符。kp:之前检测到的关键点列表(由sift.detect()返回的关键点)。
- 返回值:
keypoints:与输入的关键点列表相同,包含所有关键点信息。descriptors:特征描述符的数组,每个描述符对应一个关键点,通常是一个 128 维的浮点数组。
# 计算描述符
keypoints, descriptors = sift.compute(gray, kp)
使用示例:
import cv2# 读取图像并转换为灰度图
img = cv2.imread('image.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 创建 SIFT 特征检测器对象
sift = cv2.xfeatures2d.SIFT_create()# 检测关键点
kp = sift.detect(gray, None)# 计算描述符
keypoints, descriptors = sift.compute(gray, kp)# 可视化关键点
img_kp = cv2.drawKeypoints(img, keypoints, None, color=(0, 255, 0))# 显示结果
cv2.imshow('SIFT Keypoints', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()
总结:
sift.detect():用于检测图像中的关键点,并返回关键点列表。sift.compute():用于计算这些关键点的特征描述符,返回描述符数组和关键点信息。
这两个函数通常结合使用,以便在图像中提取特征并进行后续的匹配或分析。
六、特征匹配
cv2.BFMatcher
cv2.BFMatcher 是 OpenCV 中用于特征匹配的一个类,特别适用于 SIFT、SURF 等特征描述符的匹配。BFMatcher 是“Brute Force Matcher”的缩写,表示使用暴力匹配的方法来寻找匹配的特征点。
创建 BFMatcher 对象
bf = cv2.BFMatcher(normType, crossCheck)参数详解:
normType:指定用于计算距离的度量方式:
cv2.NORM_L2:用于 SIFT 和 SURF 特征描述符的平方欧几里得距离(L2 距离)。cv2.NORM_HAMMING:用于 ORB 特征描述符的汉明距离(Hamming 距离),适用于二进制描述符。
crossCheck:布尔值,用于指定是否进行交叉检查:
True:只有当特征点 A 认为特征点 B 是它的最佳匹配,同时特征点 B 也认为特征点 A 是它的最佳匹配时,才会保存匹配结果。这可以减少误匹配。False:不进行交叉检查,匹配更快但可能会有误匹配。匹配特征
使用
match()方法可以找到两幅图像之间的匹配特征点。matches = bf.match(descriptors1, descriptors2)返回值:
matches:返回的匹配对象列表,每个对象包含匹配的特征点的信息。排序和绘制匹配结果
通常在获取匹配后,使用
sorted()对匹配进行排序,以便找到最佳匹配,然后使用cv2.drawMatches()来可视化匹配结果。示例代码:
import cv2# 读取图像并转换为灰度图 img1 = cv2.imread('image1.jpg', cv2.IMREAD_GRAYSCALE) img2 = cv2.imread('image2.jpg', cv2.IMREAD_GRAYSCALE)# 创建 SIFT 特征检测器 sift = cv2.xfeatures2d.SIFT_create()# 检测关键点和计算描述符 kp1, des1 = sift.detectAndCompute(img1, None) kp2, des2 = sift.detectAndCompute(img2, None)# 创建 BFMatcher 对象 bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)# 匹配特征 matches = bf.match(des1, des2)# 按距离排序匹配 matches = sorted(matches, key=lambda x: x.distance)# 可视化匹配结果 img_matches = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)# 显示结果 cv2.imshow('Matches', img_matches) cv2.waitKey(0) cv2.destroyAllWindows()

总结:
cv2.BFMatcher是一个用于特征点匹配的类,采用暴力匹配的方法。- 可以指定距离度量方式(如 L2 距离、Hamming 距离)和是否进行交叉检查。
- 使用
match()方法查找匹配,返回的匹配结果可以进行排序和可视化,以分析图像特征的匹配情况。
k对最佳匹配
matches = bf.knnMatch(des1, des2, k=2)
# matches将是一个列表,其中每个元素都是一个包含两个匹配的列表。每个子列表中的元素表示从des2中找到的最接近的两个描述符。
good = []
for m, n in matches:if m.distance < 0.75 * n.distance:good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)

KANSAC
算法基本思想和流程
RANSAC是通过反复选择数据集去估计出模型,一直迭代到估计出认为比较好的模型。
具体的实现步骤可以分为以下几步:
- 选择出可以估计出模型的最小数据集;(对于直线拟合来说就是两个点,对于计算Homography矩阵就是4个点)
- 使用这个数据集来计算出数据模型;
- 将所有数据带入这个模型,计算出“内点”的数目;(累加在一定误差范围内的适合当前迭代推出模型的数据)
- 比较当前模型和之前推出的最好的模型的“内点“的数量,记录最大“内点”数的模型参数和“内点”数;
- 重复1-4步,直到迭代结束或者当前模型已经足够好了(“内点数目大于一定数量”)。
迭代次数推导
这里有一点就是迭代的次数我们应该选择多大呢?这个值是否可以事先知道应该设为多少呢?还是只能凭经验决定呢? 这个值其实是可以估算出来的。下面我们就来推算一下。
假设“内点”在数据中的占比为 t
t = n i n l i e r s n i n l i e r s + n o u t l i e r s t=\dfrac{n_{inliers}}{ n_{inliers}+n_{outliers}} t=ninliers+noutliersninliers
那么我们每次计算模型使用 N 个点的情况下,选取的点至少有一个外点的情况就是
1 − t N 1−t^N 1−tN
也就是说,在迭代 k 次的情况下, ( 1 − t n ) k (1−t^n)^k (1−tn)k 就是 k 次迭代计算模型都至少采样到一个“外点”去计算模型的概率。那么能采样到正确的 N 个点去计算出正确模型的概率就是
P = 1 − ( 1 − t n ) k P=1−(1−t^n)^k P=1−(1−tn)k
通过上式,可以求得
k = l o g ( 1 − P ) l o g ( 1 − t n ) k=\dfrac {log(1−P)}{log(1−t^n)} k=log(1−tn)log(1−P)
“内点”的概率 t 通常是一个先验值。然后 P 是我们希望RANSAC得到正确模型的概率。如果事先不知道 t 的值,可以使用自适应迭代次数的方法。也就是一开始设定一个无穷大的迭代次数,然后每次更新模型参数估计的时候,用当前的“内点”比值当成 t 来估算出迭代次数。
import numpy as np
import matplotlib.pyplot as plt
import random
import math# 数据量。
SIZE = 50
# 产生数据。np.linspace 返回一个一维数组,SIZE指定数组长度。
# 数组最小值是0,最大值是10。所有元素间隔相等。
X = np.linspace(0, 10, SIZE)
Y = 3 * X + 10fig = plt.figure()
# 画图区域分成1行1列。选择第一块区域。
ax1 = fig.add_subplot(1,1, 1)
# 标题
ax1.set_title("RANSAC")# 让散点图的数据更加随机并且添加一些噪声。
random_x = []
random_y = []
# 添加直线随机噪声
for i in range(SIZE):random_x.append(X[i] + random.uniform(-0.5, 0.5)) random_y.append(Y[i] + random.uniform(-0.5, 0.5))
# 添加随机噪声
for i in range(SIZE):random_x.append(random.uniform(0,10))random_y.append(random.uniform(10,40))
RANDOM_X = np.array(random_x) # 散点图的横轴。
RANDOM_Y = np.array(random_y) # 散点图的纵轴。# 画散点图。
ax1.scatter(RANDOM_X, RANDOM_Y)
# 横轴名称。
ax1.set_xlabel("x")
# 纵轴名称。
ax1.set_ylabel("y")# 使用RANSAC算法估算模型
# 迭代最大次数,每次得到更好的估计会优化iters的数值
iters = 100000
# 数据和模型之间可接受的差值
sigma = 0.25
# 最好模型的参数估计和内点数目
best_a = 0
best_b = 0
pretotal = 0
# 希望的得到正确模型的概率
P = 0.99
for i in range(iters):# 随机在数据中红选出两个点去求解模型sample_index = random.sample(range(SIZE * 2),2)x_1 = RANDOM_X[sample_index[0]]x_2 = RANDOM_X[sample_index[1]]y_1 = RANDOM_Y[sample_index[0]]y_2 = RANDOM_Y[sample_index[1]]# y = ax + b 求解出a,ba = (y_2 - y_1) / (x_2 - x_1)b = y_1 - a * x_1# 算出内点数目total_inlier = 0for index in range(SIZE * 2):y_estimate = a * RANDOM_X[index] + bif abs(y_estimate - RANDOM_Y[index]) < sigma:total_inlier = total_inlier + 1# 判断当前的模型是否比之前估算的模型好if total_inlier > pretotal:iters = math.log(1 - P) / math.log(1 - pow(total_inlier / (SIZE * 2), 2))pretotal = total_inlierbest_a = abest_b = b# 判断是否当前模型已经符合超过一半的点if total_inlier > SIZE:break# 用我们得到的最佳估计画图
Y = best_a * RANDOM_X + best_b# 直线图
ax1.plot(RANDOM_X, Y)
text = "best_a = " + str(best_a) + "\nbest_b = " + str(best_b)
plt.text(5,10, text,fontdict={'size': 8, 'color': 'r'})
plt.show()
cv2.findHomography❤️
cv2.findHomography 是 OpenCV 中用于计算两个平面之间的变换矩阵(Homography矩阵)的函数。以下是它的详细说明:
cv2.findHomography 在计算 Homography 矩阵时使用了 RANSAC 或其他方法,这些方法会进行迭代以提高估计的鲁棒性。函数内部存在迭代
函数签名
H, status = cv2.findHomography(srcPoints, dstPoints, method=cv2.RANSAC, ransacReprojThreshold=3)
参数说明
- srcPoints:输入的点集,表示源图像中的点,应该是一个形状为 ( N × 2 N \times 2 N×2) 的数组。
- dstPoints:目标点集,表示目标图像中的点,形状同样为 ( N × 2 N \times 2 N×2) 的数组。
- method(可选):使用的算法。常用的有:
cv2.RANSAC:随机采样一致性算法,用于鲁棒估计。cv2.LMEDS:最小中值平方法。
- ransacReprojThreshold(可选):RANSAC算法的重投影误差阈值,用于判断点是否是内点(单位:像素)。
返回值
- H:计算得到的3x3的Homography矩阵。如果没有足够的点匹配,会返回
None。 - status:一个数组,表示每个点是否为内点,1表示内点,0表示外点。
实际应用
cv2.findHomography 通常用于图像拼接、特征匹配、透视变换等场景。例如,在拼接两张图像时,首先通过特征匹配找到对应点,然后使用 cv2.findHomography 计算变换矩阵,将一张图像变换到另一张图像的坐标系中。
七、为什么要引入齐次坐标🦄
[计算机视觉] 什么是齐次坐标?为什么要引入齐次坐标?-CSDN博客
什么是齐次坐标? - 知乎
齐次坐标的基本概念
-
齐次坐标定义:
在二维空间中,一个点 ((x, y)) 可以用齐次坐标表示为 ((x, y, 1))。这意味着我们引入了一个额外的维度,通常称为齐次坐标的第三个分量,称为“尺度因子”。 -
点的表示:
齐次坐标使得我们可以用一个3维向量表示一个二维点。这种表示方式的优点在于,我们可以使用矩阵运算来处理平移、旋转和缩放等变换。
齐次坐标的好处
-
统一变换:
在常规二维变换中,平移变换通常需要额外的运算,例如:- 旋转 ( ( x ′ , y ′ ) = R ⋅ ( x , y ) (x', y') = R \cdot (x, y) (x′,y′)=R⋅(x,y))
- 平移 ( ( x ′ , y ′ ) = ( x + t x , y + t y ) (x', y') = (x + t_x, y + t_y) (x′,y′)=(x+tx,y+ty))
但在齐次坐标中,可以将平移与其他线性变换统一为一个矩阵运算。例如,平移和旋转可以用一个3x3的矩阵表示:
$
T = \begin{bmatrix}
1 & 0 & t_x \
0 & 1 & t_y \
0 & 0 & 1
\end{bmatrix}
$
旋转矩阵也可以用相同形式表示,结合起来后,可以通过矩阵乘法得到最终的变换。 -
避免除法:
在传统的二维变换中,特别是在透视投影时,我们需要进行除法来得到最终的坐标。这可能导致数值不稳定性。使用齐次坐标后,我们可以通过交叉相乘消除分母,从而避免直接的除法计算。例如:
$
x’ = \frac{h_{11}x + h_{12}y + h_{13}}{h_{31}x + h_{32}y + h_{33}}
$
可以转化为:$(h_{31}x + h_{32}y + h_{33}) x’ = h_{11}x + h_{12}y + h_{13}
$这样就只需要进行乘法和加法,避免了除法带来的潜在问题。
-
表示无穷远点:
齐次坐标还允许我们表示无穷远点。在传统的二维坐标中,没有一种方式可以表示无穷远的概念;而齐次坐标 ((x, y, 0)) 则可以用来表示这一点。这在计算投影变换(如透视投影)时是非常重要的。
总结
通过使用齐次坐标,计算变换变得更为统一和简洁,能够有效地处理平移、旋转和缩放等操作。同时,避免了计算中的除法问题,并可以表示无穷远点。这样,在处理图像变换时,使用齐次坐标是一个非常有效的选择。
相关文章:
2、图像的特征
一、角点检测-Harris 1、cv2.cornerHarris角点检测函数 在 cv2.cornerHarris 函数中,Sobel 算子用于计算图像的梯度,这是 Harris 角点检测的第一步。 cv2.cornerHarris(src, blockSize, ksize, k, dstNone, borderTypeNone)下面是各个参数的详细解释&…...

URL、URN和URI的区别
目录 一:URI二:URN三:URL1. URL格式 一:URI URI 是(Uniform Resource Identifier)统一资源标识符的缩写。用于唯一标识互联网上的资源。URI包含了URN和URL 二:URN URN是(Uniform …...
深入理解Spring框架几个重要扩展接口
本文介绍Spring框架的几个日常开发重要扩展接口,方便日常项目中按需扩展使用。 一、Processor 系列接口 用途: Processor 系列接口包括 BeanPostProcessor 和 BeanFactoryPostProcessor,它们的设计目的是在 Spring 容器启动过程中对 Bean 和…...

使用dotnet-counters和dotnet-dump 分析.NET Core 项目内存占用问题
在.NET Core 项目部署后,我们往往会遇到内存占用越来越高的问题,但是由于项目部署在Linux上,因此无法使用VS的远程调试工具来排查内存占用问题。那么这篇文章我们大家一起来学习一下如何排查内存占用问题。 首先,我们来看一下应用…...
1282:最大子矩阵
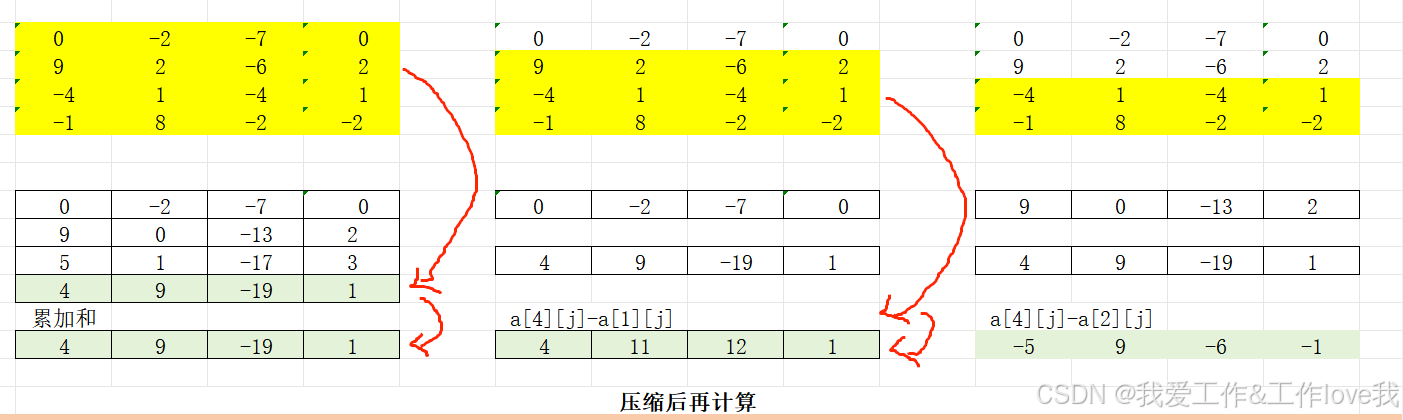
题目: 已知矩阵的大小定义为矩阵中所有元素的和。给定一个矩阵,你的任务是找到最大的非空(大小至少是1 1)子矩阵。 比如,如下4 4的矩阵 0 -2 -7 0 9 2 -6 2 -4 1 -4 1 -1 8 0 -2 的最大子矩阵是 9 2 -4 1 -1 8 这个子矩阵的大小是15。 …...
)
C++编程语言:抽象机制:特殊运算符(Bjarne Stroustrup)
第19章 特殊运算符(Special Operators) 目录 19.1 引言 19.2 特殊运算符(Special Operators) 19.2.1 下标运算符(Subscripting) 19.2.2 函数调用运算符(Function Call) 19.2.3 解引用(Dereferencing) 19.2.4 递增和递减(Increment and Decrement) 19…...
图片无损放大工具Topaz Gigapixel AI v7.4.4 绿色版
Topaz A.I. Gigapixel是这款功能齐全的图象无损变大运用,应用可将智能机拍摄的图象也可以有着专业相机的高质量大尺寸作用。你可以完美地放大你的小照片并大规模打印,它根本不会粘贴。它具有清晰的效果和完美的品质。 借助AIGigapixel,您可以…...
)
Vue中计算属性computed—(详解计算属性vs方法Methods,包括案例+代码)
文章目录 计算属性computed3.1 概述3.2 使用3.3 计算属性vs方法Methods3.4 计算属性的完整写法 计算属性computed 3.1 概述 基于现有的数据,计算出来的新属性。 依赖的数据变化,自动重新计算 语法: 声明在 computed 配置项中,…...
Python程序设计 内置函数 日志模块
logging(日志) 日志记录是程序员工具箱中非常有用的工具。它可以帮助您更好地理解程序的流程,并发现您在开发过程中可能没有想到的场景。 日志为开发人员提供了额外的一组眼睛,这些眼睛不断关注应用程序正在经历的流程。它们可以存储信息,例…...

中标麒麟v5安装qt512.12开发软件
注意 需要联网操作 遇到问题1:yum提示没有可用软件包问题 终端执行如下命令 CentOS7将yum源更换为国内源保姆级教程 中标麒麟V7-yum源的更换(阿里云源) wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Cento…...
)
每日算法一练:剑指offer——数组篇(3)
1.报数 实现一个十进制数字报数程序,请按照数字从小到大的顺序返回一个整数数列,该数列从数字 1 开始,到最大的正整数 cnt 位数字结束。 示例 1: 输入:cnt 2 输出:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,1…...

Java代码说明设计模式
以下是使用 Java 代码分别说明设计模式中的工厂模式、抽象工厂模式(这里推测你可能想说的是抽象工厂模式而非虚拟工厂模式)、建造者模式和观察者模式。 一、工厂模式 工厂模式是一种创建对象的设计模式,它提供了一种创建对象的方式…...
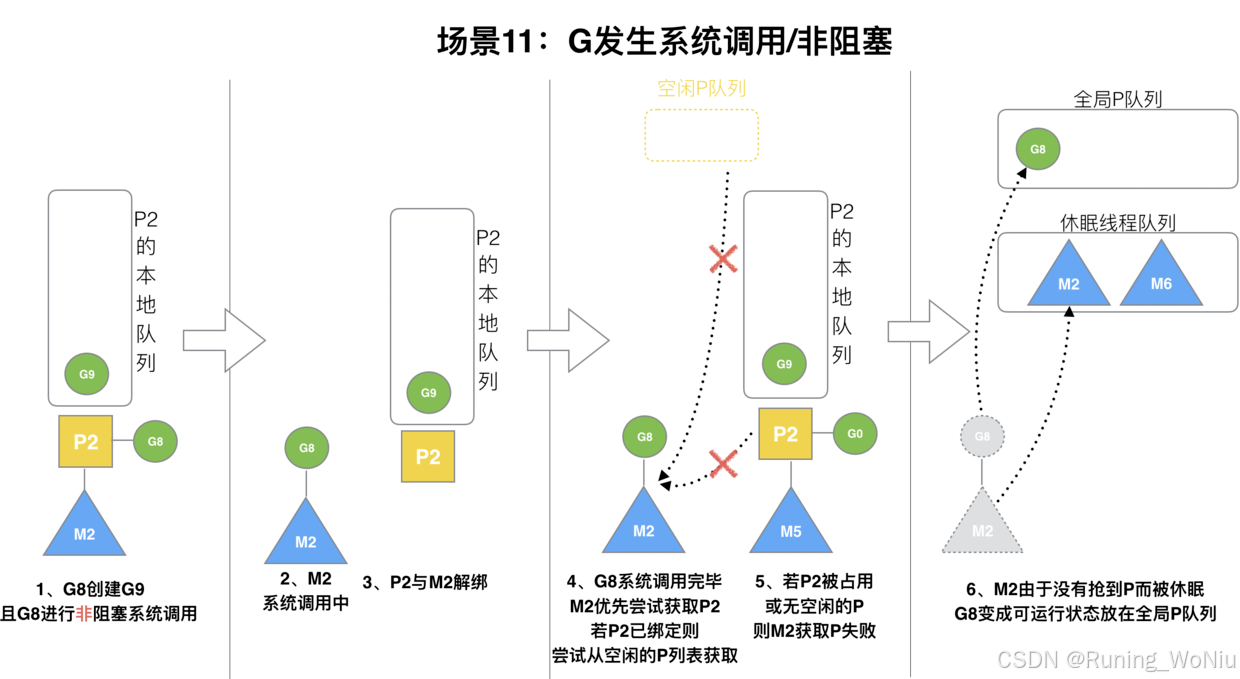
Golang笔记_day06
一、GMP 调度器 1、调度器理解思路 理解golang的调度器要从进程到协程演进来说明: 进程--->线程--->协程---> golang的协程(goroutine) 从上图可以看出,进程到多线程到协程,最终目的就是为了提高CPU的利用率…...
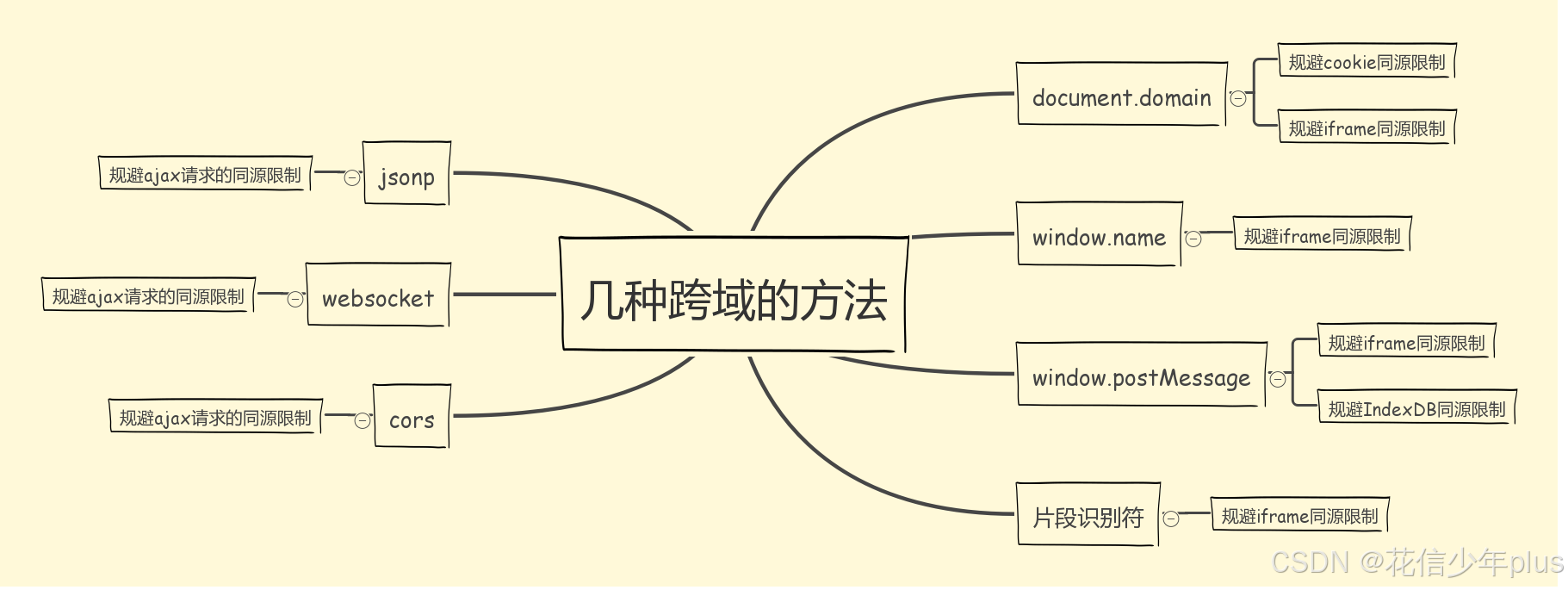
「从零开始的 Vue 3 系列」:第十一章——跨域问题解决方案全解析
前言 本系列将从零开始,系统性地介绍 Vue 3 的常用 API,逐步深入每个核心概念与功能模块。通过详尽的讲解与实战演示,帮助大家掌握 Vue 3 的基础与进阶知识,最终具备独立搭建完整 Vue 3 项目的能力。 第十一章:跨域问…...

C语言结构体数组 java静动数组及问题
1. (1)先声明,后定义:如上一天 //(2).声明时直接定义 #define N 5 typedef struct student { int num; int score; }STU; int main(void) { STU class3[N] { {10,90},{14,70},{8,95} }; …...
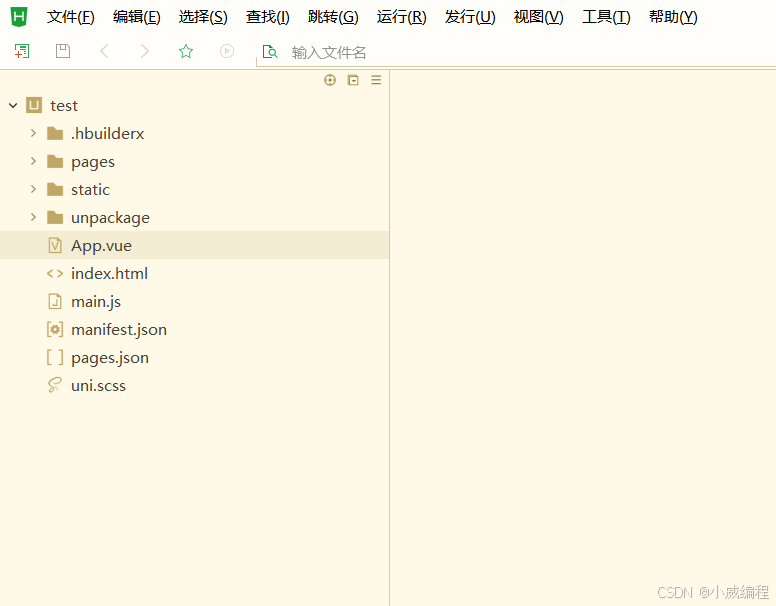
uniapp项目结构基本了解
基本结构的解释 App.vue:应用的根组件,定义全局布局和逻辑。pages/:存放各个页面的 .vue 文件,定义应用的具体页面和功能模块。main.js:应用入口文件,初始化应用,挂载 App.vue。manifest.json&…...

常见Web知识1
List item 常见Web知识1 JSON: JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人类阅读和编写,同时也易于机器解析和生成。它通常用于客户端和服务器之间的数据传输。 JSON 结构 JSON 主要由两…...
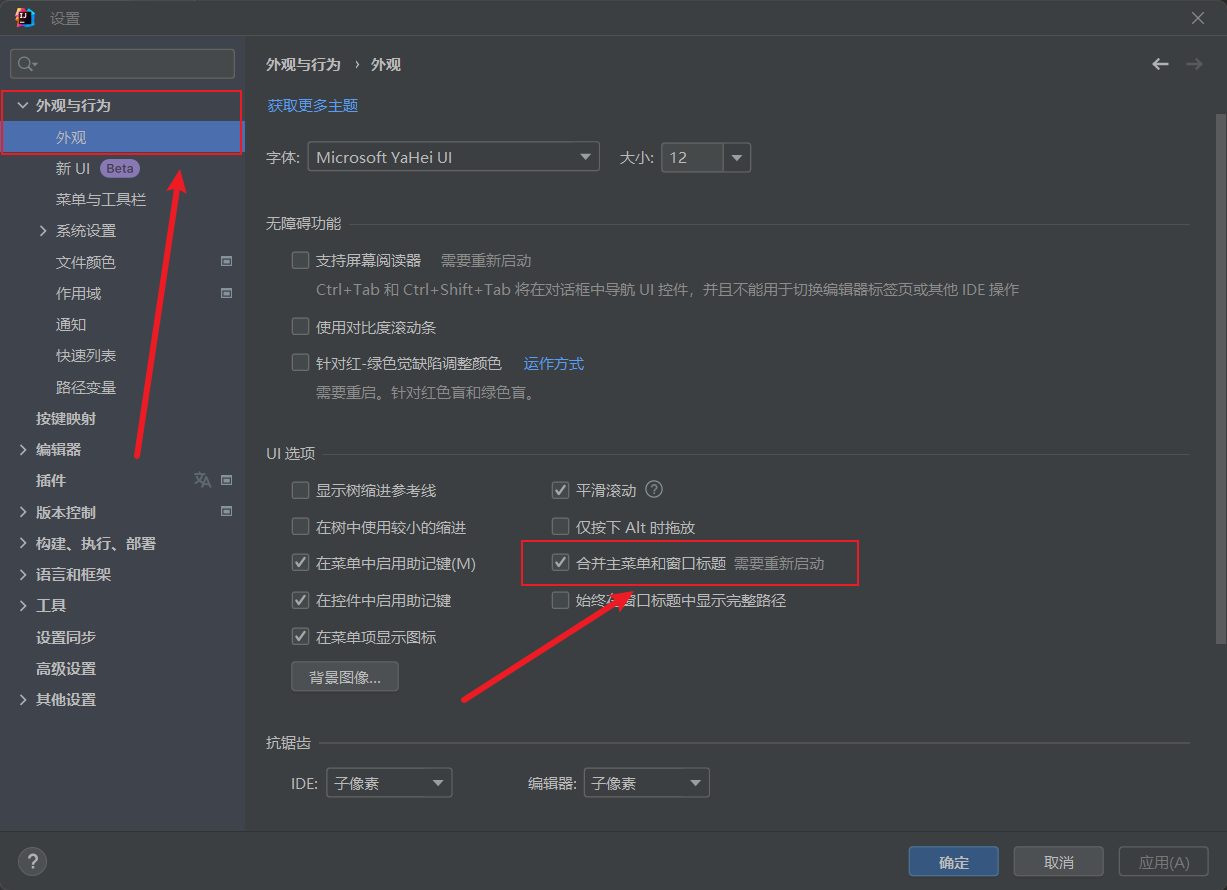
新版idea菜单栏展开与合并
新版idea把菜单栏合并了看着很是不习惯,找了半天原来在这里展开 ① 点击文件 -> 设置 ② 点击外观与行为 -> 外观 -> 合并主菜单和窗口标题 然后确定,重启即可...
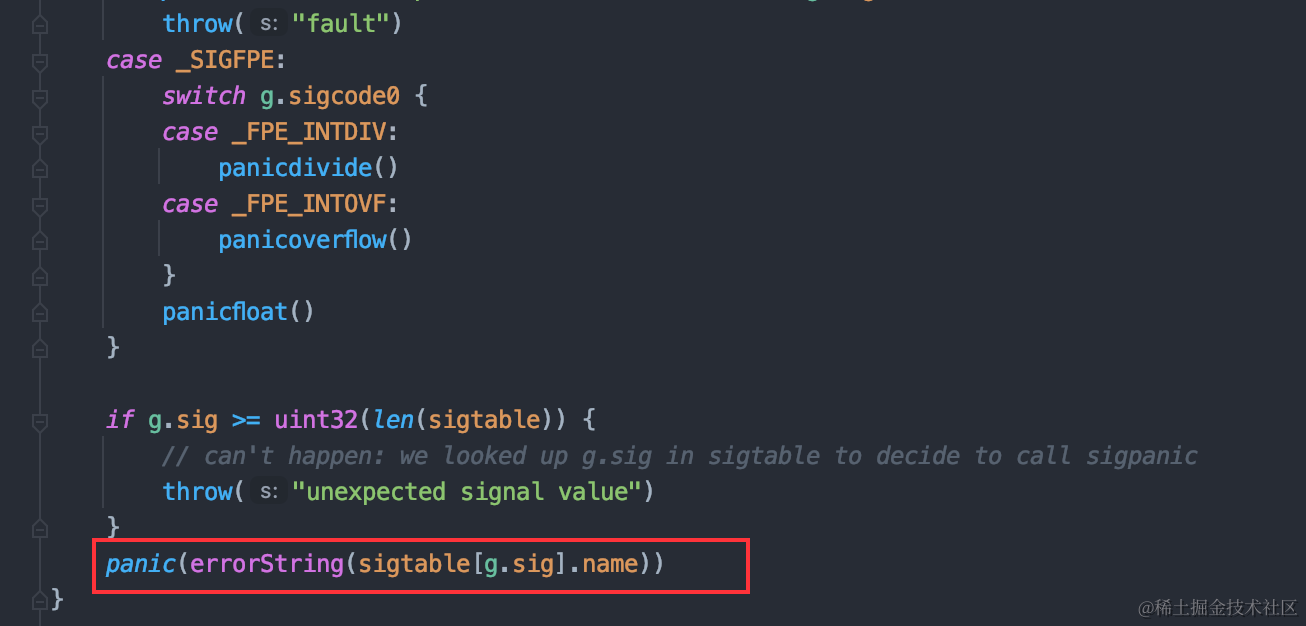
聊聊Go语言的异常处理机制
背景 最近因为遇到了一个panic问题,加上之前零零散散看了些关于程序异常处理相关的东西,对这块有点兴趣,于是整理了一下golang对于异常处理的机制。 名词介绍 Painc golang的内置方法,能够改变程序的控制流。 当函数调用了pan…...

复习:如何理解 React 中的 fiber
React 中的 Fiber 可以理解为 React 16 引入的一种新的协调(reconciliation)引擎,旨在提高 React 应用的性能和响应性。以下是对 React Fiber 的详细解释: 一、Fiber 的定义与背景 Fiber 是对 React 核心算法的一次重新实现,它将渲染工作分解成一系列小的任务单元,这些任…...

Depth Pro:重新定义单目深度估计的速度与精度边界
Depth Pro:重新定义单目深度估计的速度与精度边界 【免费下载链接】ml-depth-pro Depth Pro: Sharp Monocular Metric Depth in Less Than a Second. 项目地址: https://gitcode.com/gh_mirrors/ml/ml-depth-pro 技术原理:如何让机器真正"看…...

基于django+vue的智慧物业来访预约报修管理系统
目录功能模块划分核心业务功能特色功能设计技术实现要点扩展性设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作功能模块划分 后台管理(Django) 用户权限管理:业主、物业管理员、维修人员…...
)
从图片预览需求看H5监听浏览器返回事件的3种实现方案(含history API避坑指南)
从图片预览需求看H5监听浏览器返回事件的3种实现方案(含history API避坑指南) 在移动端H5开发中,图片预览功能几乎是标配需求。随着全面屏手势操作的普及,用户越来越习惯通过滑动返回退出预览,而非点击关闭按钮。这种交…...

Python量化投资数据接口实战指南:通达信数据获取与策略开发全流程
Python量化投资数据接口实战指南:通达信数据获取与策略开发全流程 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在量化投资领域,数据获取的效率与质量直接决定了策略的有…...

3个核心维度解析iOS数据取证:iLEAPP从入门到精通
3个核心维度解析iOS数据取证:iLEAPP从入门到精通 【免费下载链接】iLEAPP iOS Logs, Events, And Plist Parser 项目地址: https://gitcode.com/gh_mirrors/il/iLEAPP 一、核心价值:iOS数据解析的全能工具 iLEAPP(iOS Logs, Events, …...

一般非线性最优问题的迭代解法思路
1.迭代方法在经典最优化极值问题中,解析法虽然具有概念简明,计算精确等优点,但因只能适用于简单或特殊问题的寻优,对于复杂的工程实际问题通常无能为力,一般采用迭代算法,逐渐逼近最优解。 最优化问题的迭…...

计算机毕业设计springboot鲜花在线商城 基于SpringBoot的园艺花卉网络销售系统 基于Java Web的线上花店订购管理平台
计算机毕业设计springboot鲜花在线商城911yt9 (配套有源码 程序 mysql数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联xi 可分享近年来,互联网技术的迅猛发展和智能终端设备的全面普及,为传统零售行业带来…...

【忍者算法】394 字符串解码:遇到嵌套时,栈最像“现场保存器”
【忍者算法】394 字符串解码:遇到嵌套时,栈最像“现场保存器” 接上题:这次栈里要存“上一层的现场” 前两题里,我们已经见过两种栈的用法: 《有效括号》:栈存“还没配对的左括号”。 《最小栈》:栈存数据,同时顺手维护“当前最小值”。 这一题会再往前走一步。 因为…...

RK806与RK3588的电源设计最佳实践:如何优化BUCK和LDO布局布线
RK806与RK3588电源设计实战指南:从BUCK到LDO的全面优化策略 在嵌入式系统设计中,电源管理往往是最容易被忽视却又至关重要的环节。RK3588作为一款高性能处理器,其稳定运行高度依赖于RK806电源管理芯片的精准供电。我曾参与过多个采用这套方案…...

Java毕业设计基于springboot+vue的校内兼职信息管理系统
前言 Spring Boot 校内兼职信息管理系统是以 Spring Boot 框架为核心搭建的,专门用于高效管理校园内各类 兼职信息的平台。随着校园生活的多元化发展,学生对兼职机会的需求日益增长,传统的兼职信息发布与管理方式杂乱无章,存在信息…...