Openpyxl--学习记录
1.工作表的基本操作
1.1 工作表的新建打开与保存

1.1.1 创建工作簿
from openpyxl import Workbook
from pathlib import Pathfile_path = Path.home() / "Desktop" / "123.xlsx"# 1.创建工作簿
wb = Workbook()
# 2.访问默认工作簿
ws = wb.active
# 3.填充内容
ws["A4"] = 100
ws.cell(row=4, column=2, value=10)
# 4.保存工作簿
wb.save(file_path)

1.1.2 打开已经存在的工作表
一个工作表至少有一个工作簿. 你可以通过 Workbook.active 来获取这个属性
# 加载工作表
wb = load_workbook(file_path)
# 打开默认激活的工作表
ws = wb.active
# print(ws) => Worksheet "2yue">
# 打开指定的工作表
ws2 = wb["1yue"]
# print(ws2) => <Worksheet "1yue">
1.2 工作表的创建,删除与复制
1.2.1 删除工作表
# 1.加载工作簿
wb = load_workbook(file_path)
# 2.显示所有表名,列表形式
sheets = wb.sheetnames
# print(sheets) => ['1yue', '2yue']
# 3.显示所有工作表的名字
sheets_names = [i.title for i in wb.worksheets]
# print(sheets_names) => ['1yue', '2yue']
# 4.删除工作表对象
wb.remove(wb["1yue"])
# 5.保存工作簿
wb.save(file_path)1.2.2 创建新的工作表
# 1.加载工作簿
wb = load_workbook(file_path)
# 2.创建新的工作簿
wb.create_sheet("3yue")
# 3.保存工作簿
wb.save(file_path)
![]()
1.2.3 复制工作表
# 1.加载工作表
wb = load_workbook(file_path)
# 2.复制工作表
copy_sheet = wb.copy_worksheet(wb["2yue"])
# 3.保存工作表
wb.save(file_path)
1.2.4 练习
# 1.批量创建工作表100张
wb = Workbook(file_path)
for i in range(1, 10):month = 7 + int(i / 30)day = i % 30wb.create_sheet(f"{month}月{day}日")
wb.save(file_path)# 2.批量修改工作表名
wb = load_workbook(file_path)
for i in wb.worksheets:i.title = "beijing" + "-" + i.title
wb["beijing-7月1日"].title = "shanghai-7月1日"
wb.save(file_path)# 3.除了包含上海的表,其它全部删除
wb = load_workbook(file_path)
for i in wb.worksheets:if "shanghai" in i.title:continuewb.remove(i)
wb.save(file_path)2.单元格基本操作
2.1 获取单元格的值

from pathlib import Path
from openpyxl import load_workbookfile_path = Path.home() / "Desktop/123.xlsx"wb = load_workbook(file_path)
ws = wb.active
print(ws["A4"].value)
print(ws.cell(row=4,column=1).value)
2.2 获取一个区域的单元格
- 先遍历行,再遍历单元格对象
- 按列遍历,就是先遍历完一列,再遍历下一列
- list只能对整张表就行操作,但是不能对区域进行操作,但是我们可以对于list进行切片
- 可以通过iter_rows来指定行列获取区域单元格
- 可以通过rows(按行获取单元格对象),columns(按列获取单元格对象)
- 列名的数字和字母之间的转换

1)行遍历,可以使用 ws["A1:C8"]和 ws["1:8"],获取的都是行单元格对象
for rows in ws["A1:C8"]:print(rows)for rows in ws["1:8"]:print(rows)
2)列遍历,可以使用 ws["A:C"],获取的是列单元格对象
for columns in ws["A:C"]:print(columns) 3)list操作工作表
3)list操作工作表
for rows in list(ws):print(rows) 行切片
行切片
for rows in list(ws)[1:3]:print(rows)
4)iter_rows获取指定行列的单元格数据 ,也是获取行单元格数据
for rows in ws.iter_rows(min_row=1, max_row=10, min_col=1, max_col=3):print(rows)
5)rows获取行单元格数据,columns获取列单元格数据
for rows in ws.rows:print(rows)
for columns in ws.columns:print(columns)
6)数字和字母的转化,utils.get_column_letter(10),utils.column_index_from_string("J")
# 列名,通过数字获取字母
letter = utils.get_column_letter(10)
# print(letter) => J
# 列名,通过字母获取数字
num = utils.column_index_from_string("J")
# print(num) => 107)获取区域单元格的内容
from pathlib import Path
from openpyxl import load_workbook,utilsfile_path = Path.home() / "Desktop/123.xlsx"wb = load_workbook(file_path)
ws = wb.active
for rows in ws.iter_rows(min_row=1, max_row=8,min_col=1, max_col=3):for cell in rows:print(cell.value) 
2.3 动态读取数据
- 获取最大行和最大列 ws.max_row, max_column
- 获取单元格的行和列 ws["A1"].row, ws["A1"].column
- 获取一行或是一列值 [i.value for i in ws[1]], [i.value for i in ws["1"]]
from pathlib import Path
from openpyxl import load_workbookfile_path = Path().home() / "Desktop" / "test.xlsx"wb = load_workbook(file_path)ws = wb.active# 最大行和最大列
max_row = ws.max_row
max_column = ws.max_column
# print(max_row, max_column) => 5 4# 获取单元格的行和列
cell_row = ws["A1"].row
cell_column = ws["A1"].column
# print(cell_row,cell_column) => 1 1# 获取一行或是一列的值
rows_value = [i.value for i in ws[1]]
columns_value = [i.value for i in ws["1"]]
# print(rows_value,columns_value) => ['1行1列', '2行1列', '3行1列', '4行1列'] ['1行1列', '2行1列', '3行1列', '4行1列']2.4 行列的插入与删除
# 在第二行插入,插入4行
ws.insert_rows(idx=2,amount=4)
# 在第二列插入,插入3列
ws.insert_cols(idx=2,amount=3)
# 在第二行删除,删除12行
ws.delete_rows(idx=2,amount=12)
# 在第二列删除,删除6列
ws.delete_cols(idx=2,amount=6)2.5 移动与冻结单元格
- 移动单元格内容使用 ws.move_range(cell_range=f"{start_cell}:{end_cell}",rows=10,cols=5)
- 冻结单元格 ws.freeze_panes = "A2"
from pathlib import Path
from openpyxl import load_workbook, utilsfile_path = Path().home() / "Desktop" / "test.xlsx"
save_file_path = Path().home() / "Desktop" / "test2.xlsx"
wb = load_workbook(file_path)ws = wb.active# 获取有数据的单元格
cell_list = [cell for rows in ws.iter_rows() for cell in rows if cell.value is not None]# 获取数据区域范围
row_start = cell_list[0].row
column_start = utils.get_column_letter(cell_list[0].column)
start_cell = column_start + str(row_start)row_end = cell_list[-1].row
column_end = utils.get_column_letter(cell_list[-1].column)
end_cell = column_end + str(row_end)
# # 移动表里面所有的内容向下10行,向右5列
ws.move_range(cell_range=f"{start_cell}:{end_cell}",rows=-10,cols=-5)
wb.save(save_file_path)

2.6 合并单元格
-
合并单元格,ws.merge_cells("A1:A10") -
取消合并的单元格, ws.unmerge_cells("A1:A10")
3. 单元格样式操作
3.1 设置单元格行高
设置第一行数据的行高
ws.row_dimensions 是一个字典,键是行号(整数),值是 RowDimension 对象。这些对象包含关于行的尺寸和高度等信息。
workbook = openpyxl.load_workbook(sheet_name)
sheet = workbook.active
sheet.row_dimensions[1].height = 26
3.2 设置单元格数据列宽自适应
ws.column_dimensions 是一个字典,其键是列标签(如 'A', 'B', 'C' 等),值是 ColumnDimension 对象。这些对象包含关于列的宽度和其他可能的属性(如是否隐藏)的信息
根据字母来获取获取宽度,将字符宽度+1
sheet.column_dimensions[get_column_letter(cell.column)].width = len(cell.value) + 1ws = wb.activefor cell in list(ws.rows)[0]:print(len(cell.value))ws.column_dimensions[utils.get_column_letter(cell.column)].width = len(cell.value) + 33.3 填充单元格颜色
cell.fill = PatternFill(start_color="8DB4E2", end_color="8DB4E2", fill_type="solid")3.4 设置字体样式,大小,并加粗显示
cell.font = Font(name="Times New Roman", size=12, bold=True)3.5 设置字体居中显示
cell.alignment = Alignment(horizontal='center', vertical='center')3.6 设置合并单元格
sheet.merge_cells("L3:M7")3.7 设置多个单元格填充相同的样式
fill_green = PatternFill(start_color="008000", end_color="008000", fill_type="solid")
fill_green_cells = ["R3", "S3", "R6", "S6"]
for cell in fill_green_cells:ws[cell].fill = fill_green4.实践
设置首行格式,并设定内容的判定条件
def set_judgement(self, sheet_name: str) -> None:"""set header style and set judgement"""workbook = openpyxl.load_workbook(sheet_name)ws = workbook.active# Adjust title stylews.row_dimensions[1].height = 26for cell in ws[1]:ws.column_dimensions[get_column_letter(cell.column)].width = len(cell.value) + 1cell.fill = PatternFill(start_color="8DB4E2", end_color="8DB4E2", fill_type="solid")cell.font = Font(name="Times New Roman", size=12, bold=True)cell.alignment = Alignment(horizontal='center', vertical='center')# set judgement##省略判定内容fill_green = PatternFill(start_color="008000", end_color="008000", fill_type="solid")fill_yellow = PatternFill(start_color="FFFF00", end_color="FFFF00", fill_type="solid")fill_red = PatternFill(start_color="FF0000", end_color="FF0000", fill_type="solid")font_blue = Font(name="Times New Roman", size=10, color="5569FA", bold=True)fill_green_cells = ["R3", "S3", "R6", "S6"]fill_red_cells = ["R4", "S4", "R8", "S8", "R10", "S10"]fill_yellow_cells = ["R7", "S7"]font_blue_cells = ["L3", "T3", "T4", "L6", "T6", "T7", "T8", "L10"]for cell in font_blue_cells:ws[cell].font = font_bluefor cell in fill_green_cells:ws[cell].fill = fill_greenfor cell in fill_red_cells:ws[cell].fill = fill_redfor cell in fill_yellow_cells:ws[cell].fill = fill_yellowworkbook.save(sheet_name)相关文章:
Openpyxl--学习记录
1.工作表的基本操作 1.1 工作表的新建打开与保存 1.1.1 创建工作簿 from openpyxl import Workbook from pathlib import Pathfile_path Path.home() / "Desktop" / "123.xlsx"# 1.创建工作簿 wb Workbook() # 2.访问默认工作簿 ws wb.active # 3.填充…...

高边坡稳定安全监测预警系统解决方案
一、项目背景 高边坡的滑坡和崩塌是一种常见的自然地质灾害,一但发生而没有提前预告将给人民的生命财产和社会危害产生严重影响。对高边坡可能产生的灾害提前预警、必将有利于决策者采取应对措施、减少和降低灾害造成的损失。现有的高边坡监测技术有人工巡查和利用测…...

计算机毕业设计 | vue+springboot借书管理 图书馆管理系统(附源码)
1,项目背景 1.1 课题背景 随着现在科学技术的进步,人类社会正逐渐走向信息化,图书馆拥有丰富的文献信息资源,是社会系统的重要组成部分,在信息社会中作用越来越重要,在我国图书馆计算机等 信息技术的应用…...

vue3 腾讯地图 InfoWindow 弹框
1、vue项目index.html引入地图js 2、页面使用 <script setup lang"ts"> import { useMapStore } from //store;defineOptions({ name: PageMap }); const emits defineEmits([update:area, update:address, update:latitude, update:longitude]); const prop…...
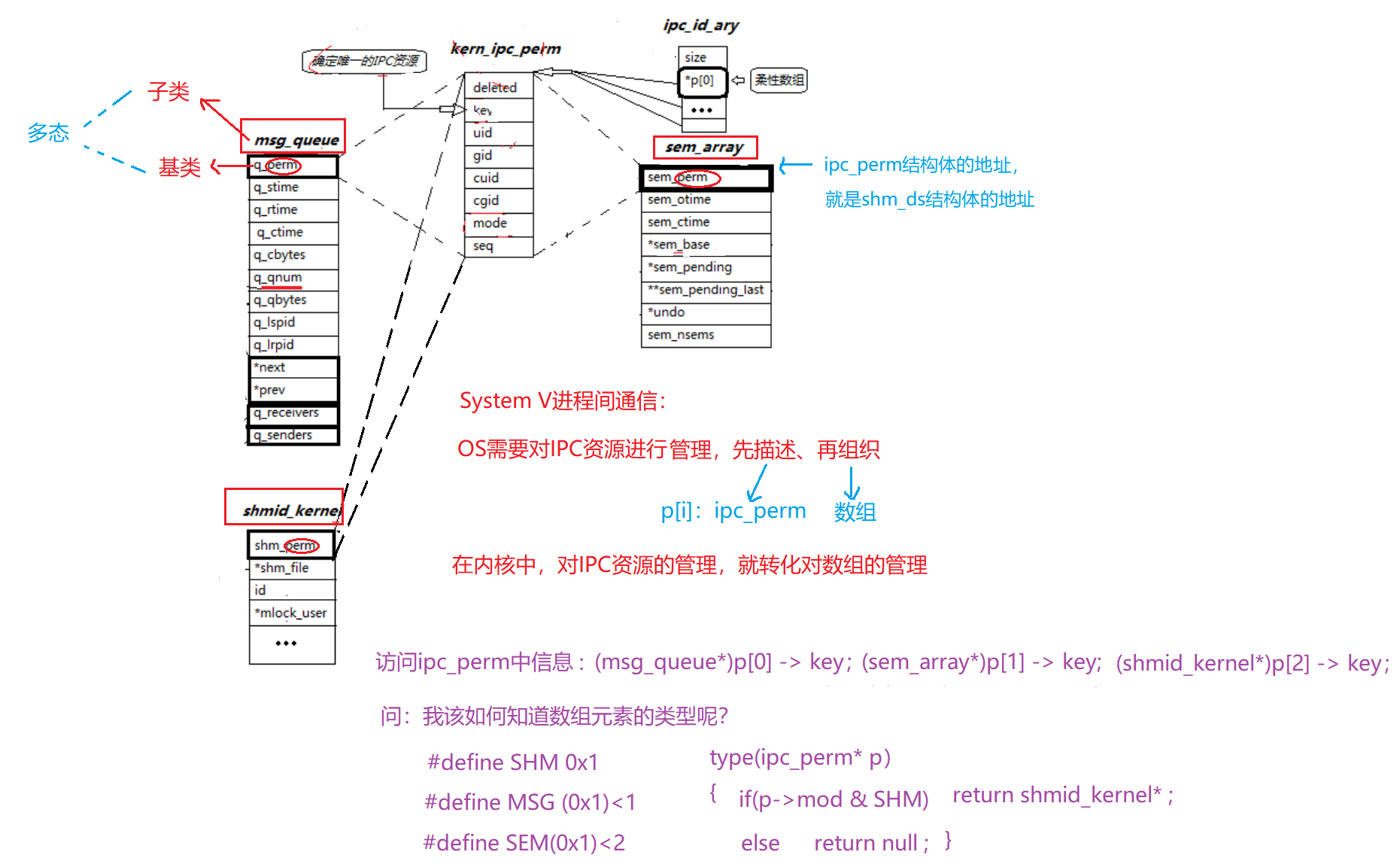
【Linux】解锁进程间通信奥秘,高效资源共享的实战技巧
管道、共享内存、消息队列、信号量 1. 进程间通信1.1. 目的1.2. 概念和本质1.3. 分类 2. 管道2.1 概念2.2. 4种情况2.3. 4种特性2.4. 匿名管道2.4.1. 原理2.4.2. 概念2.4.3. 创建 — pipe()2.4.4. 应用场景 — 进程池 2.5. 命名管道2.5.1. 概念和原理2.5.2. 创建 — mkfifo()2.…...

O1 Nano:OpenAI O1模型系列的简化开源版本
概览 O1 Nano 是一个开源项目,它实现了 OpenAI O1 模型系列的简化版本。O1 模型是一个高级语言模型,它在训练和推理过程中整合了链式思维和强化学习。这个实现版本,称为 O1-nano,专注于解决算术问题,以展示模型的能力。…...

浅谈人工智能之Llama3微调后使用cmmlu评估
浅谈人工智能之Llama3微调后使用cmmlu评估 引言 随着自然语言处理(NLP)技术的发展,各类语言模型如雨后春笋般涌现。其中,Llama3作为一个创新的深度学习模型,已经在多个NLP任务中展示了其强大的能力。然而,…...

为什么需要MQ?MQ具有哪些作用?你用过哪些MQ产品?请结合过往的项目经验谈谈具体是怎么用的?
需要使用MQ的主要原因包括以下几个方面: 异步处理:在分布式系统中,使用MQ可以实现异步处理,提高系统的响应速度和吞吐量。例如,在用户注册时,传统的做法是串行或并行处理发送邮件和短信,这…...

Flutter项目打包ios, Xcode 发布报错 Module‘flutter barcode_scanner‘not found
报错图片 背景 flutter 开发的 apple app 需要发布新版本,但是最后一哆嗦碰到个报错,这个小问题卡住了我一天,之间的埪就不说了,直接说我是怎么解决的,满满干货 思路 这个报错 涉及到 flutter_barcode_scanner; 所…...
)
RWSENodeEncoder, KER_DIM_PE(lrgb文件中的encoders文件中的kernel.py)
该代码实现了一个基于核的节点编码器 KernelPENodeEncoder,用于在图神经网络中将特定的核函数编码(例如随机游走结构编码 RWSE)与节点特征相结合。通过将预先计算的核统计信息(如 RWSE 等)与原始节点特征结合,该编码器可以帮助模型捕捉图中节点的结构信息。该代码还定义了…...

技术文档:基于微信朋友圈的自动点赞工具开发
概述 该工具是一款基于 Windows 平台的自动化操作工具,通过模拟人工点击,实现微信朋友圈的自动点赞。主要适用于需频繁维护客户关系的用户群体,避免手动重复操作,提高用户的互动效率。 官方地址: aisisoft.top 一、开发背景与技术…...

kubernetes_pods资源清单及常用命令
示例: apiVersion: v1 kind: Pod metadata:name: nginx-podnamespace: defaultlabels:app: nginx spec:containers:- name: nginx-containerimage: nginx:1.21ports:- containerPort: 80多个容器运行示例 apiVersion: v1 kind: Pod metadata:name: linux85-nginx-…...

科目二侧方位停车全流程
科目二侧方位停车是驾考中的重要项目,主要评估驾驶员将车辆准确停放在道路右侧停车位的能力。以下是对科目二侧方位停车的详细解析: 请点击输入图片描述(最多18字) 一、考试要求 车辆需在库前右侧稳定停车,随后一次性…...

2024源鲁杯CTF网络安全技能大赛题解-Round2
排名 欢迎关注公众号【Real返璞归真】不定时更新网络安全相关技术文章: 公众号回复【2024源鲁杯】获取全部Writeup(pdf版)和附件下载地址。(Round1-Round3) Misc Trace 只能说题出的太恶心了,首先获得一…...

10.24学习
1.const 在编程中, const 关键字通常用来定义一个常量。常量是程序运行期间其值不能被改变的变量。使用 const 可以提高代码的可读性和可靠性,因为它可以防止程序中意外修改这些值。 不同编程语言中 const 的用法可能略有不同,以下是一…...

社交媒体与客户服务:新时代的沟通桥梁
在数字化时代,社交媒体已成为人们日常生活中不可或缺的一部分,它不仅改变了人们的沟通方式,也深刻影响着企业的客户服务模式。从传统的电话、邮件到如今的社交媒体平台,客户服务的渠道正在经历一场前所未有的变革。社交媒体以其即…...

设置虚拟机与windows间的共享文件夹
在 VMware Workstation 或 VMware Fusion 中设置共享文件夹的具体步骤如下: 1. 启用共享文件夹 对于 VMware Workstation 打开 VMware Workstation: 启动 VMware Workstation,找到你要设置共享文件夹的虚拟机。 设置虚拟机: 选…...
微信小程序性能优化 ==== 合理使用 setData 纯数据字段
目录 1. setData 的流程 2. 数据通信 3. 使用建议 3.1 data 应只包括渲染相关的数据 3.2 控制 setData 的频率 3.3 选择合适的 setData 范围 3.4 setData 应只传发生变化的数据 3.5 控制后台态页面的 setData 纯数据字段 组件数据中的纯数据字段 组件属性中的纯数据…...
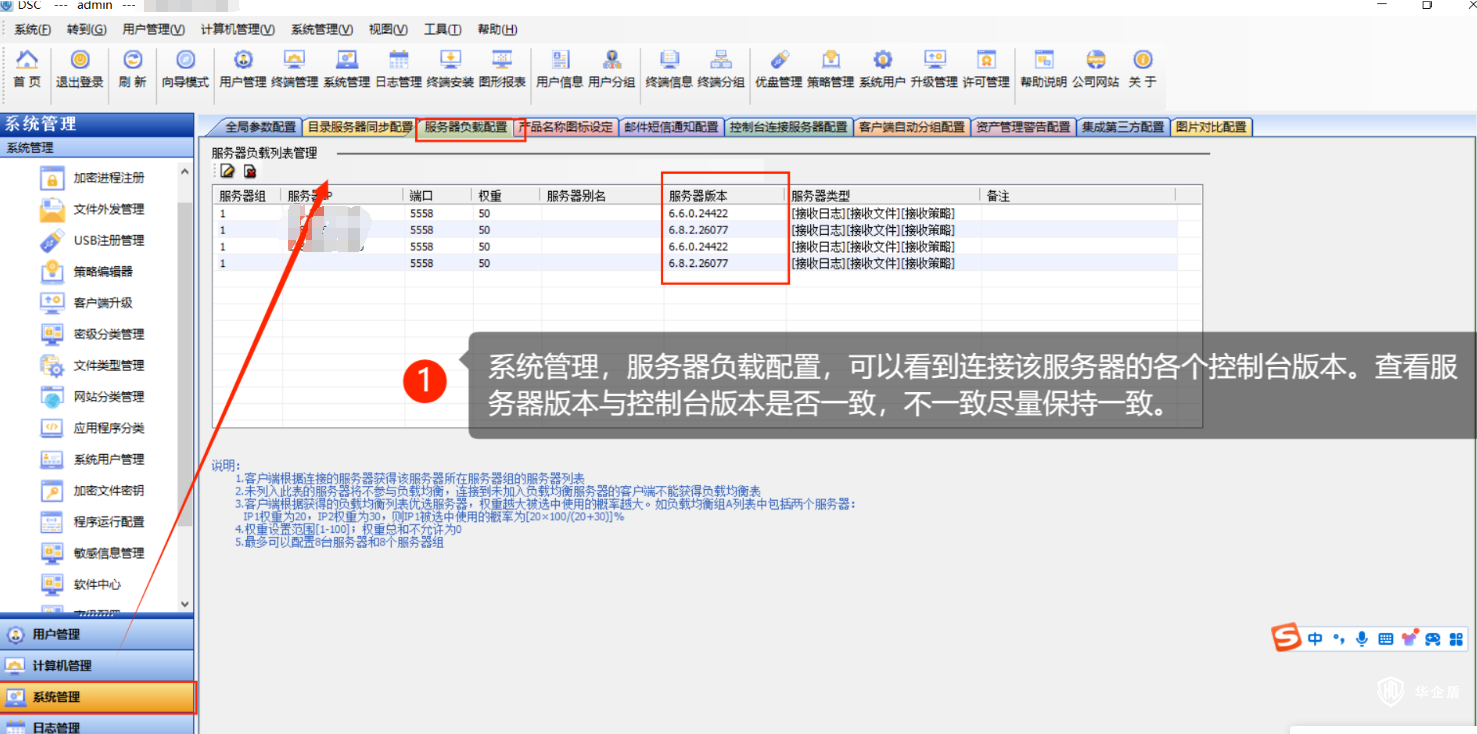
【加密系统】华企盾DSC服务台提示:请升级服务器,否则可能导致客户端退回到旧服务器的版本
华企盾DSC服务台提示:请升级服务器,否则可能导致客户端退回到旧服务器的版本 产生的原因:控制台版本比服务器高导致控制台出现报错 解决方案 方法:将控制台回退到原来的使用版本,在控制台负载均衡查看连接该服务器各个…...

直连南非,服务全球,司库直联再进一步
yonyou 在全球化经济背景下,中国企业不断加快“走出去”的步伐,寻求更广阔的发展空间。作为非洲大陆经济最发达的国家之一,南非以其丰富的自然资源、完善的金融体系和多元化的市场,成为中国企业海外投资与合作的热门目的地。 作为…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

轻量级配置管理框架zcf:多环境配置、敏感信息加密与云原生集成实践
1. 项目概述:一个面向开发者的轻量级配置管理框架最近在梳理团队内部工具链时,发现一个挺普遍的问题:不同项目、不同环境(开发、测试、生产)的配置管理总是乱糟糟的。.env文件满天飞,敏感信息一不小心就提交…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...

深度学习训练理论:初始化与梯度消失
深度学习训练理论:初始化与梯度消失 1. 技术分析 1.1 训练挑战概述 深度学习训练面临多种挑战: 训练挑战梯度消失: 梯度趋近于0梯度爆炸: 梯度过大参数初始化: 权重初始化影响激活函数选择: 影响梯度流动1.2 梯度消失原因 原因机制影响激活函数sigmoid/t…...